Тестирование точности Data Mining-моделей
Теперь модели обработаны и исследованы. Но насколько хорошо они предсказывают ситуацию? Работает ли какая-нибудь из моделей лучше, чем другие?
Используя страницу Mining Accuracy Chart, вы можете вычислить, как хорошо каждая из моделей предсказывает результат и сравнить их между собой. Этот метод сравнения также иногда называется диаграммой роста (lift chart). На странице The Mining Accuracy Chart использует данные, отделённые от первоисточника, что позволяет сравнивать прогнозы с известными результатами. Затем результаты сортируются и отображаются на графике вместе с идеальной моделью, показывая, насколько хорошо каждая модель делает прогноз. График идеальной модели соответствует теоретической модели, предсказывающей результат со 100% точностью.
Диаграмма роста является важным инструментом, поскольку она помогает различать модели практически идентичные по структуре, показывая, какая делает лучший прогноз. Подобным образом, из её рассмотрения можно сделать вывод о том, какие типы алгоритмов делают лучшие предсказания в данной ситуации. Для более подробной информации по использованию Mining Accuracy Chart, обратитесь к разделу "Comparing Data Mining Models with the Lift Chart" в SQL Server Books Online.
Страница Mining Accuracy Chart показана на рисунке 16.
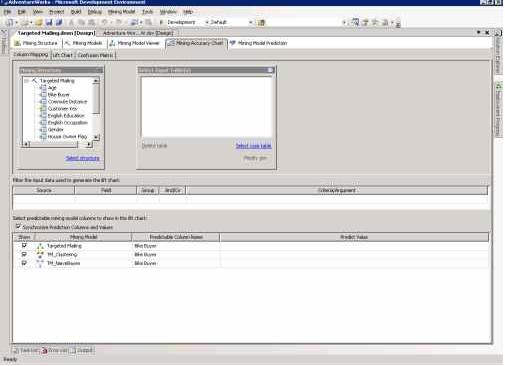
- Свяжите столбцы модели с соответствующими столбцами во входных данных.
- Установите фильтр на входные данные.
- Выберите сравниваемые модели, а также поля для которых делается прогнозирование и их значения.
Отображение входных столбцов
На первом шаге необходимо связать столбцы, используемые в модели со столбцами во входных данных. В том случае, если имена столбцов совпадают, связи создадутся автоматически.
- В поле Select Input Table(s) выберите Select case table.
Откроется диалоговое окно выбора таблицы, где вы можете выбрать таблицу, содержащую данные, которые вы хотите использовать для прогнозирования и определения точности моделей.
В этом руководстве используются те же данные, что и для обработки моделей. - В диалоговом окне Select table, раскройте базу AdventureWorks и выберите источник данных Adventure Works DW.
- Нажмите vTargetMail.
Столбцы data mining структуры автоматически будут соответствовать столбцам с теми же именами таблицы с исходными данными, как показано на рисунке 17.
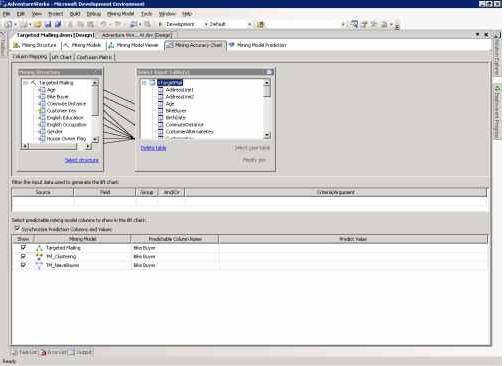
Запрос на прогноз генерируется для каждой модели Mining Structure на основании связанных столбцов. Вы можете удалить связь, выбрав линию, связывающую поля в Mining Structure и Select Input Table(s) и нажав DELETE. Также вы можете создать связь вручную, выбрав столбец в Select Input Table(s) и перетащив его на соответствующий столбец в Mining Structure.
Фильтрация входных столбцов
Для установки фильтров на входные данные вы можете использовать таблицу Filter the input data used to generate the lift chart. Вы можете перетащить столбцы из Select Input Table(s) на таблицу с результатами или выбрать значения в выпадающих списках. Например, если необходимо учитывать только те строки в столбце Income, где его значение больше х, выберите Income в поле Field, а в поле Criteria/Argument введите >x.
Для выполнения данного упражнения вам не потребуется фильтровать данные.
Выбор моделей, прогнозируемых полей и их значений
Следующий шаг заключается в выборе моделей, которые вы хотите включить в рассмотрение, и прогнозируемого поля, по которому они будут сравниваться. По умолчанию, выбраны все модели.
Вы можете создавать два типа диаграмм. Если указано значение прогнозируемого атрибута, вы увидите график вроде того, что показан на рисунке 18, из которого видно какая из моделей показывает лучший результат (lift chart). В том случае, если значение не указано, то диаграмма отобразит точность модели (см. рисунок 19).
- Для каждой модели в поле Predictable Column Name выберите Bike Buyer.
- Для каждой модели в поле Predict Value выберите 1.
- В поле Predictable Column Name, выберите Bike Buyer.
Оставьте поле Predict Value пустым.
Если установлен флаг Synchronize Prediction Columns and Values, прогнозируемый столбец синхронизируется для каждой модели в структуре Data Mining.
В некоторых более сложных случаях, вам может понадобиться создать диаграмму роста для двух моделей анализа, но в которых значения прогнозируемого атрибута берутся из разных столбцов структуры Data Mining. Если выключить флаг Synchronize Prediction Columns and Values, можно выбрать любой доступный прогнозируемый столбец и значение. Результаты отображаются вместе, вне зависимости от того как они получены.
Диаграмма роста
Кликните на закладку Lift Chart чтобы просмотреть диаграмму роста. При выполнении этого действия на сервере выполняется запрос на прогнозирование. Полученные результаты прогноза сравниваются с известными значениями и сортируются по вероятности, после чего отображаются на графике. Для более подробной информации по использованию диаграммы, обратитесь к разделу "Lift Chart" в SQL Server Books Online.
При условии указанного значения прогнозируемого столбца, диаграмма роста имеет вид показанный на рисунке 18.
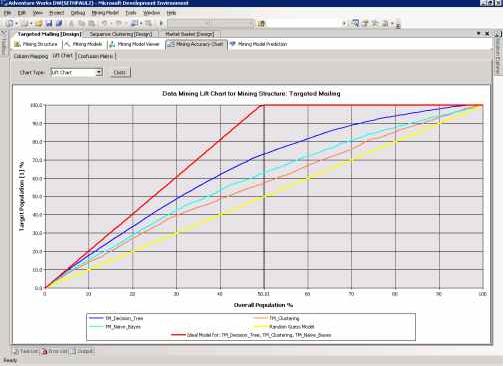
Если значение прогнозируемого атрибута не было указано, диаграмма роста показывает точность предсказаний моделей (см. рисунок 19).
