Введение
В СУБД Microsoft SQL Server 2005 в полной мере реализована работа с кодировкой Юникод и языком XML, которые появились в версии SQL Server 2000. Их поддержка расширена за счет новых мощных инструментов для разработки и работы с запросами, входящих в состав SQL Server Management Studio и Business Intelligence Development Studio. Надежная работа с национальными языками делает SQL Server 2005 актуальным продуктом для работы с базами данных и прикладной платформой, обеспечивающей поддержку международного взаимодействия и многоязычных сред.
В настоящем документе дается обзор этих возможностей в общем контексте. Перечисляются возможности, связанные с требованиями международной и многоязычной среды, и объясняется, как проектные решения могут влиять на разные аспекты функционирования проекта.
Примечание. Для отображения некоторых знаков национальных алфавитов в документе используются следующие шрифты: Arial Unicode MS, Latha, Mangal, PmingLiu, Gulim, SimSun и MS-Mincho. Отсутствие этих шрифтов не накладывает существенных ограничений на понимание документа.
Поддержка Юникода в SQL Server 2005
В основе всех средств поддержки языков в SQL Server 2005 лежит поддержка кодировки Юникод.
Юникод - это стандарт, созданный консорциумом Unicode - организацией, содействующей использованию единого набора символов для любых языков. SQL Server 2005 поддерживает стандарт Юникода версии 3.2. Версия 3.01 стандарта идентична кодировке ISO-10646, -международному стандарту, соответствующему Юникоду по всем кодовым позициям.
Принцип работы Юникода заключается в том, что для каждого символа, независимо от платформы, программы или языка, предусмотрена уникальная кодовая позиция. Программа, поддерживающая Юникод, может обрабатывать данные на любом языке. Поскольку кодировка предназначена для того, чтобы охватить все символы всех языков мира, необходимость в различных кодовых страницах для работы с различными наборами символов отпадает.
Поскольку все использующие Юникод системы всегда используют одни и те же двоичные последовательности, чтобы представлять все символы, не возникает проблем, связанных с неправильным преобразованием символов при переходе от одной системы к другой.
Простейший способ работы с символьными данными в многоязычных базах данных заключается в том, чтобы всегда применять основанные на Юникоде типы данных nchar, nvarchar и nvarchar(max), а не соответствующие им типы char, varchar и text, использующие другие кодировки. Тогда каждый клиент увидит в данных те же символы, что и все остальные клиенты. Если, кроме того, все приложения, работающие с многоязычными базами данных, будут использовать переменные в Юникоде, необходимости в преобразовании символов не будет возникать.
Примечание. Тип данных ntext в следующей версии Microsoft SQL Server поддерживаться не будет.
Следует отличать кодовые позиции кодировки Юникод и представляемые ими символы от глифов, используемых для визуального представления. Стандарт ISO (ISO/IEC 9541-1) определяет глиф как "распознаваемый абстрактный графический символ, независимый от конкретного графического представления" . Следовательно, символ не обязательно бывает представлен одним и тем же глифом, а этот глиф не обязательно должен быть уникален. Какой глиф будет использован для представления определенного элемента кода или их последовательности, определяется выбранным шрифтом.
Дополнительные сведения см. на веб-узле консорциума Unicode.
Кодировки
Юникод устанавливает соответствие между кодовыми позициями и символами, но не указывает, как данные будут представлены в памяти, базе данных или на веб-странице. Именно здесь вступает в действие кодирование данных в формате Юникод. Для Юникода существует много различных способов кодирования. В большинстве случаев можно просто выбрать использующий Юникод тип данных и не уделять внимания этим подробностям. Однако важно иметь представление о кодировках в следующих ситуациях:
- когда вы имеете дело с приложением, которое может кодировать символы Юникода по-разному;
- когда производится пересылка данных на другие (отличные от Microsoft Windows) платформы или на веб-серверы;
- когда импортируются или экспортируются данные в других кодировках.
Стандарт Юникод определяет несколько кодировок для единого набора символов - UTF-7, UTF-8, UTF-16 и UTF-32. В этом разделе описаны следующие распространенные кодировки
- UCS-2
- UTF-16
- UTF-8
Как правило, SQL Server хранит символы Юникода с помощью схемы кодирования UCS-2. Однако многие клиенты обрабатывают Юникод в других схемах кодирования, например, UTF-8. Так часто бывает в случае веб-приложений. В приложениях на языке Microsoft Visual Basic строки обрабатываются в схеме кодирования UCS-2. Поэтому нет необходимости описывать в явном виде преобразования схем кодирования между приложениями Visual Basic и экземпляром SQL Server.
XML-данные SQL Server 2005 кодирует с помощью Юникода (UTF-16). Чтобы обеспечить такие возможности модели XML, как порядок документа и рекурсивные структуры, данные в столбце типа xml хранятся во внутреннем формате в виде больших двоичных объектов (BLOB). Поэтому XML-данные, получаемые от сервера, поступают в кодировке UTF-16. Если приложению требуются данные в другой кодировке, оно само должно выполнить необходимые преобразования.
Кодировка UTF-16 используется благодаря своей поддержке двухбайтовых и четырехбайтовых символов. Она обрабатывается в соответствии с побайтовым протоколом. Эти свойства обеспечивают удобство использования кодировки UTF-16 для передачи данных между разными компьютерами, использующими разные кодировки и порядок байтов. Поскольку XML-данные обычно широко распространяются в сетях, имеет смысл придерживаться принятой по умолчанию для XML-данных кодировки UTF-16 в базе данных и при их экспортировании к клиентам.
Кодировка UCS-2
Кодировка UCS-2 - предшественник UTF-16. Она отличается от UTF-16 тем, что представляет собой кодировку с фиксированной длиной, в которой все символы представлены в виде 16-битовых значений (2 байтов), и, следовательно, не поддерживает добавочные символы. UCS-2 часто путают с UTF-16, которая используется для внутреннего представления текста в операционных системах Microsoft Windows (Windows NT, Windows 2000, Windows XP и Windows CE), хотя возможности UCS-2 более ограничены.
Для хранения информации в Юникоде в Microsoft SQL Server 2000 и Microsoft SQL Server 2005 используется кодировка UCS-2, отводящая для хранения каждого символа два байта вне зависимости от самого символа. Поэтому латинская буква "A" обрабатывается так же, как кириллическая "Ш", еврейская "ламед" (м), тамильский знак "Rra" (?) или знак японской хираганы "E" (‚¦). Каждому из таких символов соответствует уникальная кодовая позиция (для перечисленных это U+0041, U+0248, U+05DC, U+0BB1 и U+3048 соответственно, причем каждое четырехразрядное шестнадцатеричное число представляет два байта кодировки UCS-2).
Поскольку с помощью кодировки UCS-2 можно закодировать только 65 536 различных кодовых позиций, сама по себе она не позволяет пользоваться добавочными символами и воспринимает их как пары не определенных в Юникоде символов-заместителей (суррогатов), определяющих дополнительный символ в сочетании друг с другом. Однако SQL Server может хранить добавочные символы без риска их утраты или повреждения. Расширить возможности SQL Server, обеспечив его работу с суррогатными парами, можно путем создания собственных функции среды CLR. Дополнительные сведения о работе с суррогатными парами и добавочными символами см. в разделе "Добавочные символы и суррогатные пары" ниже.
Примечание. Добавочный символ определяется как символ в кодировке Юникод, имеющий добавочную кодовую позицию . Добавочные кодовые позиции находятся в диапазоне от U+10000 до U+10FFFF.
Кодировка UTF-8
Кодировка UTF-8 представляет собой схему кодирования, предназначенную для обработки данных в формате Юникод, причем кодирование осуществляется способом, не зависящим от порядка следования байтов на конкретном компьютере. Эта кодировка полезна при работе с системами на основе кодировки ASCII и другими системами, ориентированными на побайтовую обработку, для которых требуются 8-битовые кодировки. К числу таких систем относятся почтовые серверы, которые должны обслуживать большое количество компьютеров с различным порядком байтов, использующих различные кодировки и различные языки. Хотя SQL Server 2005 не хранит данные в формате UTF-8, он поддерживает эту кодировку при обработке XML-данных. Дополнительные сведения см. в разделе Поддержка XML в SQL Server 2005 ниже в настоящем документе.
Другие системы управления базами данных, такие как Oracle и Sybase SQL Server, обеспечивают поддержку Юникода, используя хранение в формате UTF-8. В зависимости от реализации сервера это может оказаться более легко выполнимым решением для ядра базы данных, поскольку не потребует значительных изменений существующего на сервере кода, обеспечивающего обработку текста, для побайтовой работы с данными. Однако в среде Windows хранение в формате UTF-8 имеет несколько недостатков.
- Интерфейсы модели COM, включая API, поддерживают только кодировку UTF-16/UCS-2. Следовательно, если данные хранятся в формате UTF-8, требуется их постоянное преобразование. Эта проблема имеет место, только когда используется модель COM, но обычно ядро базы данных SQL Server к ее интерфейсам не обращается.
- Ядро операционной системы как в Windows XP, так и в Windows Server 2003 используют Юникод. Для Windows 2000, Windows XP и Windows Server 2003 в качестве стандартной кодировки используется UTF-16. Однако эти операционные системы распознают и UTF-8. Поэтому использование в качестве формата хранения данных кодировки UTF-8 требует множества лишних преобразований. Обычно лишние затраты ресурсов, необходимые для таких преобразований, не влияют на работу ядра базы данных SQL Server, но могут оказать влияние на многие операции, выполняемые на стороне клиента.
- Использование UTF-8 может приводить к замедлению многих операций со строками. Сортировка, сравнение и, фактически, любые другие операции со строкам могут работать медленнее из-за того, что символы не имеют фиксированной ширины.
- Часто для кодировки UTF-8 требуется более 2 байтов, а увеличение размера может вести к увеличению используемого дискового пространства и памяти.
Несмотря на эти издержки, а также с учетом того, что формат XML завоевал серьезные позиции как стандарт обмена информацией в Интернете, использование кодировки UTF-8 по умолчанию может быть полезным.
Примечание. Предыдущие версии СУБД Oracle и языка Java также используют формат UCS-2 и не способны распознавать суррогатные символы. Корпорация Oracle ввела поддержку Юникода в качестве набора символов для баз данных начиная с версии Oracle 7. В настоящее время СУБД Oracle поддерживает два метода хранения данных в формате Юникод: первый - кодировка UTF-8 для символьных типов данных CHAR и VARCHAR2 и для всех имен и литералов SQL; второй - кодировка UTF-16 для хранения типов данных Юникод NCHAR, NVARCHAR и NCLOB. СУБД Oracle позволяет использовать оба метода одновременно.
Кодировка UTF-16
UTF-16 принята в качестве стандартной кодировки в корпорации Майкрософт. Она расширяет возможности ОС Windows для кодирования дополнительных 1 048 576 символов. Потребность в диапазоне суррогатный символов назрела еще до публикации стандарта Юникод 2.0, поскольку стало ясно, что достичь преследуемой при разработке Юникода цели - обеспечить отдельную кодовую позицию для каждого символа каждого из языков, - используя только 65 536 символов, невозможно. Так, для некоторых языков, например китайского, для кодирования исторических и литературных идеограмм, которые, хотя и редко используются, важны в издательской и научной деятельности, потребовалось бы использовать все возможные символы этого диапазона. В следующем разделе диапазон символов-суррогатов описан более подробно.
В кодировке UTF-16, как и в UCS-2, в соответствии с общим правилом для ОС Windows используется прямой порядок следования байтов. Прямой порядок (в отличие от обратного) означает, что младший байт хранится в памяти по младшему адресу. Порядок байт имеет значение на уровне операционной системы. Подобно другим приложениям, выполняемым на платформе Windows, SQL Server использует прямой порядок байтов. Таким образом, шестнадцатеричное слово, например 0x1234, хранится в памяти в виде 0x34 0x12. В некоторых случаях, чтобы правильно прочесть кодировку символа, бывает необходимо менять порядок байт явным образом. В состав служб SQL Server Integration Services входят функции изменения порядка байтов текста в формате Юникод. Дополнительные сведения см. в разделе Службы SQL Server 2005 Integration Services этого документа.
Добавочные символы и суррогатные пары
Обычно для представления символьных данных ОС Microsoft Windows использует кодировку UTF-16. Использование 16 битов позволяет представить 65 536 уникальных символов. Однако даже этого числа недостаточно, чтобы охватить все символы человеческих языков. В кодировке UTF-16 определенные кодовые позиции используют другие позиции, следующие непосредственно за первыми двумя байтами, чтобы определить символы в диапазоне суррогатов.
Стандарт Юникод включает 16 плоскостей символов, позволяющих определить 1 114 112 знаков. Плоскость 0, или Базовая многоязыковая плоскость (Basic Multilingual Plane, BMP), может представлять большинство письменностей мира, символов, используемых в издательском деле, математических и технических символов, знаки препинания, геометрические формы и все пиктограммы шрифта Zapf Dingbats уровня 100.
За пределами плоскости BMP символы, входящие в большинство плоскостей, по-прежнему не определены, но могут использоваться для представления добавочных символов. Добавочные символы используются в основном для исторических документов и произведений классической литературы, чтобы обеспечить кодирование богатого литературного наследия, существующего на китайском, корейском и японском языках. Сюда также входят руны и другие исторически использовавшиеся виды письма, музыкальные символы и тому подобное.
В кодировке UTF-16 для представления символов, не входящих в основной набор символов (BMP) используется пара кодовых позиций, называемая суррогатной парой. Область символов-суррогатов - диапазон Юникода от U+D800 до U+DFFF, включающий 1 024 младших значений суррогатов и 1 024 старших. Старший суррогат (в диапазоне от U+D800 до U+DBFF) и младший (от U+DC00 до U+DFFF) объединяются, что обеспечивает возможность доступа к более чем миллиону возможных символов.
Половина суррогатной пары не считается действительной. Действительная суррогатная пара всегда должна быть последовательностью старшего символа-суррогата, за которым следует младший. Это сводит проверку того, принадлежит ли символ к числу суррогатов, к проверке попадания в диапазон, что гораздо проще системы правил, необходимой для распознания DBCS (двухбайтовой системы символов).
Как SQL Server 2000, так и SQL Server 2005 могут хранить суррогатные пары, несмотря на то, что кодировка UCS-2 не предусматривает их. SQL Server обрабатывает такие пары как два неопределенных символа Юникода, а не как один символ. Обычно подобные приложения называют нейтральными к суррогатам или безопасными по отношению к суррогатам , подразумевая, что они не обладают встроенной способностью взаимодействовать с такими данными, но, по крайней мере, могут хранить их без потерь.
Поддерживающие суррогаты приложения, напротив, не только учитывают наличие суррогатных пар, но, кроме того, способны обрабатывать несамостоятельные символы и другие символы, требующие специальной обработки. Хорошо написанное приложение может распознавать разделенные суррогаты и воссоединять их с помощью всего нескольких подпрограмм. Среди поддерживающих суррогаты приложений - текстовый редактор Microsoft Word и веб-обозреватель Internet Explorer 5 и более поздних версий.
При работе с добавочными символами в SQL Server следует учитывать следующие обстоятельства.
- Поскольку суррогатные пары рассматриваются как две отдельных кодовых позиции Юникода, размер значения типа nvarchar(n) должен быть равен 2, чтобы в него поместился один добавочный символ (иными словами, в нем должна помещаться суррогатная пара).
- Не поддерживается использование добавочных символов в метаданных, например, в именах объектов баз данных. В целом, используемый в метаданных текст должен соответствовать правилам для идентификаторов.
- Стандартные строковые операции не поддерживают добавочные символы. Такие операции, как SUBSTRING(nvarchar(2),1,1) возвращают только старший суррогат суррогатной пары добавочного символа. Функция LEN увеличивает значение счетчика на два для каждого встреченного добавочного символа: на единицу для старшего суррогата и на единицу для младшего. Однако можно создать специальные функции, поддерживающие дополнительные символы.
- Обработка добавочных символов при сортировке и поиске может меняться в зависимости от параметров сортировки. С помощью новых параметров 90_ и BIN2 сравнение добавочных символов дает правильные результаты, тогда как при использовании параметров более старых версий и стандартных параметров сортировки Windows любой добавочный символ при сравнении оказывается равным любому другому добавочному символу. Например, применяемые по умолчанию параметры сортировки Japanese и Korean не способны обрабатывать добавочные символы, а режимы Japanese_90 и Korean_90 - способны.
Несамостоятельные символы
Несамостоятельные символы представляют собой символы, используемые совместно с другими символами для изменения вида или значения последних. Объединенные, они образуют единый глиф. Например, диакритические знаки в европейских языках - это несамостоятельные символы. Диакритика может представляться в виде либо последовательности обычного символа и несамостоятельного, либо составного символа.
В платформе .NET Framework последовательность несамостоятельных символов обрабатывается как элемент текста - то есть, как единица текста, отображаемая в виде единого символа. Элемент текста не тождественен элементу сортировки. Например, для некоторых параметров буквы "CH" не являются несамостоятельными символами. Они представляют собой два отдельных элемента текста, но могут рассматриваться как один элемент сортировки.
Примечание. Функции SQL, напротив, обычно обрабатывают несамостоятельные символы так же, как добавочные символы - как две отдельных кодовых позиции Юникода.
Соответствие между несамостоятельными символами и элементами сортировки зависит как от стандарта Юникода, так и от параметров сортировки. Некоторые несамостоятельные символы всегда считаются эквивалентными всем своим вариантам вне зависимости от того, сколько кодовых позиций те включают (например, латинская буква "a" с диакритическим знаком рассматривается как эквивалент составного символа, уже включающего такой же диакритический знак), тогда как при некоторых параметрах сортировки можно сортировать или сравнивать строки по-разному в зависимости от того, присутствует ли в них диакритика.
Впервые несамостоятельные символы были определены в стандарте Юникод 2.0. Дополнительные сведения см. в разделе спецификации Юникода 4.0.1, посвященном специальным областям и символам форматирования. Консорциум Unicode публикует также "вопросы и ответы" (FAQ), посвященные несамостоятельным символам и их обработке.
Поддержка стандарта GB18030
GB18030 (GB18030-2000) - это отдельный стандарт, который Китайской народной республикой (КНР) предписывается использовать для кодирования китайских символов. Он устанавливает как расширенную кодовую страницу, так и таблицу сопоставления символам Юникода. На 1 августа 2006 г. официально требуется, чтобы все программные продукты, продаваемые в КНР, поддерживали этот набор символов. Соответствие стандарту GB18030 подразумевает также наличие поддержки некоторых ранее не поддерживавшихся языков, например тибетского, монгольского, ицзу и уйгурского.
В кодировке GB18030 символы могут быть длиной 1, 2 или 4 байта. Чтобы обеспечить сопоставление 4-байтных последовательностей GB18030 кодировкам Юникода, используются суррогатные пары.
SQL Server 2005 поддерживает символы в кодировке GB18030, распознавая их в момент поступления на сервер от приложения на стороне клиента. Они преобразуются и сохраняются в стандартном для него формате Юникод. После того, как символы сохранены на сервере, при любых последующих операциях над ними они обрабатываются как символы Юникода. Для кодировки GB18030 не установлено региональных стандартов, предусмотрен лишь идентификатор кодовой страницы, необходимый для преобразований в Юникод и из него. Идентификатор кодовой страницы для кодировки GB18030-2000, принятый корпорацией Майкрософт, равен 54936.
При использовании символов GB18030 следует помнить, что их можно использовать в операциях упорядочивания и сравнения, но при использовании параметров сортировки, предшествовавших таковым в SQL Server 90, производятся только сравнения на основании кодовых позиций символов, и при этом не используются никакие другие лингвистически значимые характеристики. Поэтому следует проявлять осторожность при использовании символов GB18030 в таких операциях, как ORDER BY, GROUP BY и DISTINCT, особенно если в одной операции участвуют и символы GB18030, и символы других кодировок. Чтобы сделать возможным осмысленное сравнение строк символов GB18030, используйте новые версии параметров сортировки SQL Server 90, обозначенные добавлением к их именам суффикса "90". Так, вместо параметров Chinese_PRC используйте Chinese_PRC_90.
Для включения поддержки стандарта GB18030 можно установить пакет поддержки, который можно загрузить с портала Справки и поддержки продуктов корпорации Майкрософт, и который включает файл шрифта и библиотеки, поддерживающие преобразование между кодировками GB18030 и Юникод. Пакет поддержки представляет собой единственный двоичный файл в международной версии, который способен работать под ОС Windows XP или Windows 2000. Однако в системе должны быть установлены средства поддержки восточно-азиатских языков. В ОС Windows Vista поддержка стандарта GB18030 включена изначально. В ней есть шрифты и раскладки клавиатуры для таких языков китайских национальных меньшинств, как тибетский, ицзу, монгольский и уйгурский. Для этих языков в качестве регионального стандарта устанавливается "Китайский (КНР)".
Примечание. Некоторые функции преобразования байт GB18030 в символы Юникода, например BytesToUnicode, в ОС Vista не поддерживаются. Для такого преобразования используйте функцию MultiByteToWideChar.
Типы данных в SQL Server 2005
В этом разделе описаны новые для SQL Server 2005 типы данных и затронуты вопросы, связанные с использованием типов данных SQL Server 2005 для хранения многоязычных данных.
Текстовые типы, не поддерживающие Юникод: char, varchar, text, varchar(max)
При работе с текстовыми данными, которые хранятся в виде типов char, varchar, varchar(max) или text, главное ограничение, которое следует учитывать, состоит в том, что системой может быть проверена информация, относящаяся только к одной кодовой странице. (Хранить данные, принадлежащие к нескольким кодовым страницам, не рекомендуется, хотя и возможно.) Какая именно кодовая страница будет использована для проверки и хранения данных, зависит от параметров сортировки столбца. Если эти параметры на уровне столбца не были определены, будет использованы параметры сортировки базы данных. Для определения кодовой страницы, которая будет использована для конкретного столбца, можно использовать функцию COLLATIONPROPERTY, как показано в следующем примере кода:
SELECT COLLATIONPROPERTY('Chinese_PRC_Stroke_CI_AI_KS_WS', 'CodePage')
936
SELECT COLLATIONPROPERTY('Latin1_General_CI_AI', 'CodePage')
1252
SELECT COLLATIONPROPERTY('Hindi_CI_AI_WS', 'CodePage')
0Последний пример возвращает в качестве кодовой страницы для хинди значение 0 (Юникод). Пример иллюстрирует тот факт, что многим региональным языковым стандартам, таким как грузинский и хинди, не соответствуют кодовые страницы, поскольку эти языки имеют параметры сортировки только для Юникода. Такие параметры не подходят для столбцов, использующих типы данных char, varchar или text, а некоторые из параметров были признаны устаревшими.
Важно! В SQL Server 2005 вместо типа данных text следует использовать varchar(max). Тип данных text не будет поддерживаться в следующей версии Microsoft SQL Server.
При необходимости вставить данные формата Юникод в столбцы с иными кодировками осуществляется внутреннее преобразование столбцов из кодировки Юникод с помощью функции WideCharToMultiByte и кодовой страницы, соответствующей параметрам сортировки. Если символ не может быть представлен с помощью данной кодовой страницы, он заменяется вопросительным знаком (?). Поэтому появление среди данных вопросительных знаков в случайных местах служит хорошим признаком того, что произошло искажение данных из-за неопределенного преобразования. Это также очертит преимущества, которые получило бы приложение от перехода на работу с данными в Юникоде.
Если используется строковый литерал не поддерживаемого параметрами сортировки типа, не использующего Юникод, строка сначала преобразуется с помощью кодовой страницы по умолчанию для базы данных. Определение этой кодовой страницы осуществляется на основании установленных по умолчанию параметров сортировки базы данных.
Другая проблема, которая может возникнуть - невозможность хранить данные в случае, когда в кодовой странице содержатся не все символы, поддержку которых необходимо обеспечить.. Во многих случаях Windows подбирает кодовую страницу, которая лишь подходит наилучшим образом, что означает отсутствие гарантированной возможности обработать с ее помощью весь текст. Эта кодовая страница - всего лишь лучшая из тех, что имеются. Примером может служить арабский набор знаков. Он поддерживает множество языков, включая балучи, берберский, фарси, кашмирский, казахский, киргизский, курдский, пушту, синдхи, уйгурский, урду и другие. Во всех этих языках есть дополнительные символы помимо символов арабского языка, входящих в кодовую страницу Windows 1256. При попытке сохранить эти дополнительные символы в столбце с кодировкой, отличной от Юникода, и арабскими параметрами сортировки, они будут преобразованы в вопросительные знаки.
Текстовые типы, поддерживающие Юникод: nchar, nvarchar, nvarchar(max), ntext
Спецификация SQL-92 определяет типы данных, начинающиеся с "N" (буква обозначает "национальные" типы данных), но не предписывает, чтобы эти типы данных использовались для Юникода. Фактическое определение этих типов оставлено платформе базы данных или разработчикам. В версиях SQL Server 2000 и SQL Server 2005 эти типы данных определены как эквивалентные UCS-2, которая представляет собой кодировку Юникода. Однако при работе с другими серверами баз данных важно знать, что типы данных, начинающиеся на "N", не обязательно подразумевают использование Юникода. Определение типов данных, начинающихся на "N", как использующих Юникод - это особенность СУБД Microsoft SQL Server.
Тип данных nvarchar(max), появившийся в SQL Server 2005, может содержать до2 гигабайт (ГБ) данных. Это предпочтительная альтернатива типу данных ntext.
Важно! В SQL Server 2005 вместо типа данных ntext следует пользоваться типом nvarchar(max). Тип данных ntext не будет поддерживаться в следующей версии Microsoft SQL Server.
При хранении сложного письма, такого как хинди или тамильского языка, удостоверьтесь, что данные правильно упорядочены. Многие языки, например тамильский, требуют изменения порядка расположения определенных символов при отображении текста. Поэтому логический порядок текста в том виде, в каком он хранится в памяти, может отличаться от порядка при визуальном представлении в интерфейсе пользователя. Для любых языков со сложным письмом, в число которых входят все индоарийские языки, арабский, фарси, иврит и многие другие, данные всегда должны храниться в правильном логическом порядке. Реальное отображение таких данных - это отдельный вопрос (см. раздел Многоязычные данные в пользовательском интерфейсе этого документа).
Хотя столбцы "N"-типов могут поддерживать использование данных на любом языке или сочетании языков, при сортировке данных можно выбрать только одни параметры сортировки. Более подробно этот вопрос описывается в разделе Параметры сортировки настоящего документа. Никакие из упомянутых выше ограничений, связанных с кодовыми страницами, не относятся к столбцам в Юникоде.
В SQL Server 2005 можно создавать дополнительные функции, позволяющие улучшить обработку строк и работу параметров сортировки с добавочными символами. Так, образец StringManipulate для SQL Server 2005 показывает пример обработки строк с учетом добавочных символов. В нем приводится реализация пяти строковых функций Transact-SQL. Новые функции обеспечивают те же возможности обработки строк, что и встроенные, но наряду со строками в Юникоде поддерживают обработку строк с добавочными символами.
Типы данных CLR
Microsoft SQL Server дает возможность расширить систему типов SQL, определив пользовательский тип данных, который можно использовать в программировании для SQL Server. Эти определяемые пользователем типы удобны для создания специальных типов даты, времени, валюты и расширенных численных типов, а также для закодированных или зашифрованных данных.
Определяемый пользователем тип (user-defined type, UDT) можно использовать для определения типа столбца таблицы или же переменных и параметров процедур в языке Transact-SQL. Экземпляром такого типа может быть столбец таблицы, переменная в пакете, функция или хранимая процедура, а также аргумент функции или хранимой процедуры. Определяемый пользователем тип реализуется в виде управляемого класса на любом из языков CLR, а затем регистрируется SQL Server.
Определяемые пользователем типы используются для расширения системы скалярных типов данных сервера, что позволяет хранить в базе данных SQL Server объекты CLR. Эти типы могут содержать более одного элемента и поддерживать определенные пользователем особые режимы работы. Это отличает их от традиционных псевдонимов типов данных, состоящих из единственного системного типа данных SQL Server. К примеру, образец Currency UDT, приведенный в электронной документации по SQL Server 2005, поддерживает обработку денежных сумм в денежной системе, связанной с определенной культурой. Вы должны определить два поля: значение типа string, CultureInfo, указывающее страну валюты (например en-us), и значение типа decimal, CurrencyValue, хранящее сумму.
Поскольку доступ к UDT осуществляется как к единому целому, их использование для сложных типов данных может плохо сказаться на производительности. Как правило, сложные схемы данных легче поддаются моделированию с помощью традиционных строк и таблиц. В электронную документацию по SQL Server 2005 входит несколько образцов, показывающих, как создавать определяемые пользователем типы и работать с ними. Образец UTF8String для SQL Server 2005 показывает, как реализовать определяемый пользователем тип данных, дополняющий систему типов базы данных для того, чтобы обеспечить хранение значений в кодировке UTF8. В новом типе также реализован код для преобразования строк Юникода в кодировку UTF8 и обратно.
Тип данных XML
Тип данных XML позволяет хранить в базах данных SQL Server фрагменты или документы формата XML. Экземплярами типа данных XML могут быть столбцы таблицы, аргументы функций и хранимых процедур, а также их переменные. Кроме того, можно сделать тип данных XML специализированным, указав XML-схему, обеспечивающую как ограничения при проверке, так и информацию о типе данных для экземпляра XML.
Действия над экземпляром типа данных XML можно осуществлять, используя встроенные методы для запросов к XML. Эти методы принимают запросы и инструкции обработки, предназначенные для таких данных. Можно осуществлять запросы (XQuery) к данным XML, хранимым в переменной или столбце типа данных XML, а также вносить в них изменения (с помощью инструкций insert, update и delete). Можно также использовать схему XSD для создания индекса столбца XML, что позволит улучшить производительность запросов.
Дополнительные сведения о типе данных xml и средствах поддержки обработки данных XML в SQL Server 2005 см. в разделе Поддержка XML в SQL Server 2005 этого документа.
Типы даты и времени: datetime, smalldatetime
Используемые в SQL Server 2000 и SQL Server 2005 типы даты и времени определены следующим образом:
datetime
Дата и время по григорианскому календарю в диапазоне от 1 января 1753 г. до 31 декабря 9999 г. с точностью до одной трехсотой доли секунды (что равно 3,33 миллисекундам, или 0,00333 секундам).
smalldatetime
Дата и время по григорианскому календарю в диапазоне от 1 января 1900 г. до 6 июня 2079 г. с точностью до одной минуты. Значения типа smalldatetime, заканчивающиеся на 29,998 или меньшее количество секунд, округляются до ближайшей минуты вниз, а значения, заканчивающиеся на 29,999 или большее количество секунд, округляются до ближайшей минуты вверх.
Microsoft SQL Server отклоняет данные, выходящие за эти пределы. Сами данные хранятся во внутреннем представлении в виде двух целых чисел, представляющих соответствующие дату и время (4-байтовые целые для типа datetime и 2-байтовые для smalldatetime).
Хранимые данные не указывают, относятся ли они к местному времени или ко всемирному, и не содержат информации о часовом поясе. Если вам необходимо перевести данные в значение всемирного времени, можно использовать одну из функций времени UTC. Текущее время UTC определяется на основании текущего местного времени и настройки часового пояса в операционной системе компьютера, на котором запущен данный экземпляр Microsoft SQL Server. Поскольку значение не имеет собственного форматирования, соответствующего региональным стандартам, определение необходимых преобразований ложится на разработчика. SQL Server поддерживает множество соответствующих различным языкам преобразований, которые могут осуществляться на сервере и служат альтернативой собственным решениям разработчиков. К таким стилям дат можно обращаться с помощью функции CONVERT, которая использует в качестве аргументов тип данных, выражение и, при необходимости, стиль из числа приведенных в следующей таблице.
|
С веком |
Без века |
Стандартная схема |
Ввод (преобразование к типу datetime) |
|---|---|---|---|
| 0 или 100 | - | По умолчанию | мес дд гггг чч:мм AM (или PM) |
| 101 | 1 | США | мм/дд/гг |
| 102 | 2 | ANSI | гг.мм.дд |
| 103 | 3 | Британская/фарнцузская | дд/мм/гг |
| 104 | 4 | Немецкая | дд.мм.гг |
| 105 | 5 | Итальянская | дд-мм-гг |
| 106 | 6 | - | дд мес гг |
| 107 | 7 | - | Мес дд, гг |
| 108 | 8 | - | чч:мм:сс |
| 9 или 109 | - | По умолчанию + миллисекунды | мес дд гггг чч:мм:сс:ммм AM (или PM) |
| 110 | 10 | США | мм-дд-гг |
| 111 | 11 | Японская | гг/мм/дд |
| 112 | 12 | ISO | ггммдд |
| 13 или 113 | - | Европейская по умолчанию + миллисекунды | дд мес гггг чч:мм:сс:ммм (24-часовой формат) |
| 114 | 14 | - | чч:мм:сс:ммм (24-часовой формат) |
| 20 или 120 | - | Каноническая для ODBC | гггг-мм-дд чч:мм:сс (24-часовой формат) |
| 21 или 121 | - | Каноническая для ODBC + миллисекунды | гггг-мм-дд чч:мм:сс:ммм (24-часовой формат) |
| 126 | - | ISO8601 (без пробелов) | гггг-мм-дд Tчч:мм:сс:ммм |
| 130 | - | Кувейтская (хиджра) | дд мес гггг чч:мм:сс:ммм AM (или PM) |
| 131 | - | Кувейтская (хиджра) | дд/мм/гг чч:мм:сс:ммм AM (или PM) |
Следующий пример демонстрирует использование функции CONVERT для представления текущей даты в указанном стиле:
SELECT CONVERT(char, GETDATE(), 100) AS [100] RETURNS: Aug 16 2000 11:50AM
Подобным же образом можно преобразовать данные из строки в значение даты:
SELECT CONVERT(datetime, 'Aug 16 2000 11:50AM', 100) AS [100] RETURNS: 100 2000-08-16 11:50:00.000
Если даты стиля 130 (Кувейт, хиджра) преобразуются в тип данных char, они могут быть повреждены, если параметры сортировки не относятся к арабским, использующим для преобразований Юникода кодовую страницу 1256. Например, на рис. 1 показаны столбцы, один из которых был преобразован в тип char, а второй - в тип nchar. В этом примере клиентский компьютер использует в качестве региональных параметров EN-US. Поэтому при попытке использовать тип данных char арабские символы преобразуются в вопросительные знаки, тогда как при использовании типа nchar они отображаются правильно.

Рис. 1. Использование функции CONVERT с данными в формате даты/времени
Однако даже строки, представленные с использованием типа nchar из-за ограничений редактора запросов отформатированы неправильно, - иначе, чем это было бы на арабском клиентском компьютере. На рис. 2 показано, как в действительности должна выглядеть дата по хиджре.

Рис. 2. Строка даты по хиджре
Причина невозможности правильного отображения арабского заключается в том, что для языков со сложным письмом, к которым он относится, существуют особые правила формирования, контролирующие отображение данных. В случае языков с двунаправленным (BIDI) письмом, таких как иврит, формирование вызывает обратное отображение всех данных. В случае арабского языка воздействие формирования выражено еще сильнее, поскольку фактические начертания букв могут меняться в зависимости от того, какие буквы их окружают. Проблема с таким отображением решена в версиях ОС Windows начиная с Windows 2000, а также в более ранних версиях со включенной поддержкой арабского языка.
Помимо этого, возвращаемая строка даты при необходимости двунаправленного отображения может вызывать проблемы, когда правила расположения двунаправленного текста, используемые приложением, например обозревателем Internet Explorer, приводят к отображению даты в виде, показанном на рис. 3.

Рис. 3. Пример двунаправленной строки даты
Такой порядок при отображении (дд чч:мм:сс гггг мес :), очевидно, не соответствует ожидаемому. Эту проблему можно считать общим ограничением стиля 130 при применении функции CONVERT. Обходным путем решения этой проблемы может быть добавление нужного управляющего символа Юникода впереди строки, как в следующем запросе:
SELECT NCHAR(8207) + CONVERT(nchar, GETDATE(), 130)
Функция NCHAR возвращает символ на основе переданной ей кодовой позиции Юникода. 8207, или шестнадцатеричное 0x200F, представляет собой маркер записи справа налево (RLM), использование которого позволяет отобразить строку правильно.
Производительность и пространство для хранения
Если столбец определен как относящийся к одному из типов данных Юникода, могут возникнуть следующие проблемы, связанные с пространством для хранения и скоростью работы.
Увеличение используемого пространства для хранения
В типах данных, использующих Юникод, каждый символ кодируется двумя байтами или более, в то время как не использующие Юникод типы данных представляют любой символ с помощью одного байта, а символы азиатских языков в двухбайтовой кодировке - с помощью двух. Поэтому, если данные не используют одну из азиатских кодовых страниц, при преобразовании в Юникод для их хранения потребуется в два раза больше места. Увеличение требований к пространству следует учитывать как при модернизации существующих баз данных, так и при выборе подходящих типов данных для нового проекта. Если вы храните данные только в столбце, использующем единственную (и не азиатскую) кодовую страницу, возможно, имеет смысл отказаться от использования Юникода для экономии пространства на диске и в памяти. Однако преимущества, связанные с преобразованием данных в Юникод, обычно перевешивают влияние этого преобразования на пространство для хранения.
Примечание. При хранении данных в азиатской двухбайтовой кодировке используемый SQL Server 2005 метод кодирования UCS-2 обычно оказывается более эффективным, чем метод UTF-8, используемый многими другими программами для работы с базами данных. Так происходит потому, что в кодировке UTF-8 на хранение большинства знаков азиатских языков расходуется три байта, а в кодировке UCS-2, за исключением добавочных и несамостоятельных символов, только два. С другой стороны, для языков, не использующих двухбайтовую кодировку, например языков на основе символов кодировки ASCII, кодировка UTF-8 обычно использует только по одному байту на символ, тогда как UCS-2 использует два.
Влияние на скорость
Влияние типов данных, использующих Юникод, на производительность имеет сложный характер. Следует учитывать следующие аспекты.
- При работе в Windows XP, Windows Server 2003 или Windows Vista операционная система ожидает данные в формате Юникод. Поэтому в большинстве случаев при отображении данных или обращении к службам операционной системы должно производиться преобразование столбцов, не использующих Юникод.
- При работе с форматом данных в двухбайтовой кодировке для загрузки большого количества данных может потребоваться дополнительное время.
- При обмене данными между экземплярами СУБД, различными серверами баз данных или с другими приложениями, количество преобразований может негативно отразиться на производительности.
- При работе с азиатскими языками, Юникод оказывается быстрее, чем двухбайтовая кодовая страница, предназначенная для конкретного языка. Так происходит потому, что двухбайтовые данные не имеют фиксированной длины, а представляют собой смесь двухбайтовых и однобайтовых символов.
- При работе с неазиатскими языками, сортировка данных в формате Юникод может оказаться медленнее, чем сортировка данных в другой кодировке.
- Двоичный порядок сортировки самый быстрый. Он учитывает регистр, но может привести к неожиданным результатам. Если выбрать его, станут недоступными параметры "С учетом регистра", "С учетом диакритических знаков", "С учетом типа японской азбуки" и "С учетом ширины символов".
Важно! Для реалистичной оценки производительности следует протестировать как вариант с использованием Юникода, так и вариант без него.
Миграция метаданных системных таблиц
Системные таблицы в SQL Server 2005 хранят все находящиеся в них данные, включая идентификаторы объектов, в формате Юникод. Это минимизирует опасности, которые могут возникнуть, когда параметры сортировки для баз данных и столбцов отличаются.
При осуществлении миграции с SQL Server 2000 на SQL Server 2005, единственное значительное изменение состоит в том, что SQL Server 2000 для списка применимых в идентификаторах символов использует стандарт Юникод 2.0, тогда как SQL Server 2005 поддерживает стандарт Юникод версии 3.2.
Возможно непосредственное обновление экземпляров SQL Server 2000 с пакетом обновления 3 (SP3) или более поздних версий, а также экземпляров SQL Server 7.0 с пакетом обновления 4 (SP4) или более поздних версий до SQL Server 2005. Большинство операций обновления можно выполнить с помощью программы установки. Однако некоторые компоненты требуют миграции приложений и решений после ее выполнения.
Параметры сортировки
Порядок сортировки - критически важная часть определения базы данных. Тем не менее, ей часто не уделяют достаточного внимания. Пользователи склонны воспринимать сортировку на основе привычного для них алфавита как что-то само собой разумеющееся. Однако для некоторых языков, например для греческого, русского и тайского, используются иные алфавиты. В некоторых, например, в японском, используется несколько алфавитов и сложные правила упорядочивания. Даже в европейских языках существует множество различий в том, как обрабатываются отдельные символы. Например, испанские пользователи ожидают, что сочетание букв "ch" при сортировке будет восприниматься как единая буква, следующая за буквой "h".
Основная сортировка использует параметры сортировки, которые, наряду с прочими моментами, управляют порядком сортировки. Сортировку можно оптимизировать, создавая индексы.
Сортировка работает совместно с техникой, называемой нормализацией строк. Такой вид нормализации отличается от нормализации в том смысле, к которому привыкли разработчики баз данных. Под нормализацией строк подразумевается метод сравнения двух строк таким образом, чтобы их можно было подвергнуть сортировке. Например, можно указать, следует ли рассматривать различные типы каны как эквивалентные, или следует ли игнорировать диакритические знаки.
Для столбцов, не использующих Юникод, параметры сортировки имеют второе и очень важное значение - они указывают кодовую страницу для данных и, тем самым, определяют, какие символы могут быть в нем представлены. Между столбцами, использующими Юникод, данные можно перемещать без преобразования или сопоставления символов; данные, перемещаемые между столбцами, не использующими Юникод, часто оказываются поврежденными или искаженными - или, по меньшей мере, их не удается отобразить.
Параметры сортировки в SQL Server 6.5 и более ранних версиях
В SQL Server версии 6.5 и более ранних параметры сортировки использовались для указания кодовой страницы, которую следует использовать для языка в целом. Существовали многочисленные ограничения, связанные с различными порядками сортировки. Например, поддержку западноевропейских языков можно было обеспечить только при использовании страницы Latin-1. Параметры сортировки также ограничивали количество различных региональных стандартов, которые можно было представить в одном экземпляре SQL Server. Другими словами, хранить или отображать можно было только язык, используемый в конкретном регионе. Чтобы использовать другой язык, было необходимо создать отдельную базу данных или даже отдельный сервер.
Эти же проблемы имеют место при работе с не использующими Юникод полями в более поздних версиях SQL Server.
Параметры сортировки в SQL Server 7.0
SQL Server 7.0 предусматривал по одному режиму сопоставления для Юникода и одному - без использования Юникода для каждого сервера. Параметры сортировки, не использующие Юникод, определялись как сочетание кодовой страницы и порядка сортировки. Часто каждая кодовая страница поддерживает более одного порядка сортировки. Например, романские языки обычно допускают сортировку как с учетом, так и без учета регистра. Упрощенное китайское письмо позволяет сортировку как по количеству штрихов, так и фонетическую.
Для параметров сортировки, использующих Юникод, в столбец может быть включен любой символ любого языка, а имеющиеся разнообразные параметры сортировки разработаны с учетом правильной обработки любых различий между собой. Иными словами, вы выбираете "наилучшее соответствие", чтобы предоставить пользователям ожидаемые ими данные. Например, общие параметры сортировки для Юникода позволяют сортировать данные на фарси.
Параметры сортировки для Юникода состоят из регионального стандарта и нескольких стилей сравнения. Региональным стандартам обычно даются названия стран или культурных областей. Символы сортируются в соответствии со стандартом, действующим в этой области. Параметры сортировки для Юникода предусматривают порядок сортировки для всех символов стандарта Юникод, но преимущество отдается указанному региональному стандарту. Для любого регионального стандарта, не имеющего поддерживаемых уникальных параметров сортировки для Юникода, должны использоваться общие параметры сортировки Юникода.
Общий порядок сортировки Юникода обеспечивает не только обработку данных, но и сортировку следующих языков: албанского, английского, арабского, африкаанс, баскского, белорусского, болгарского, греческого, грузинского (традиционного), иврита, индонезийского, малайского, русского, сербского, суахили, урду, фарерского, фарси и хинди.
Важным нововведением в SQL Server 7.0 была независимая от операционной системы модель сравнения строк, обеспечивавшая единообразность параметров сортировки для всех ОС от Windows 95 до Windows 2000. Этот код сравнения строк был основан на том же коде, который использует для нормализации строк сама ОС Windows 2000. Он инкапсулирован для обеспечения единства поведения на всех компьютерах и во всех версиях SQL Server.
Параметры сортировки в SQL Server 2000
В СУБД SQL Server 2000 модель сортировки была изменена, чтобы исключить несоответствия между различными системами сортировки - Windows и SQL Server Для удовлетворения всех возникших требований к параметрам сортировки нужна была более гибкая модель. Новые параметры сортировки в SQL Server 2000 требовались также для работы с кодовой страницей столбцов, в которых не используется формат Юникод.
В связи с этим была разработана единая, согласованная модель, позволяющая выполнять сортировку как в формате Юникод, так и в других кодировках. Каждый набор параметров сортировки был снабжен суффиксами, позволяющими определить, учитываются ли при сортировке регистр, диакритические знаки, ширина или тип каны. В Приложении A приведена таблица, в которой перечислены такие суффиксы. Эти 17 суффиксов в сочетании с 40 поддерживаемыми SQL Server 2000 языками дают 680 наборов параметров сортировки Windows.
Названия языков, которыми были обозначены параметры сортировки, были выбраны произвольно. Они должны были представлять каждую из уникальных поддерживаемых кодовых страниц для данных в кодировках, отличных от Юникода, а также порядок сортировки для всех данных. Во многих случаях одна кодовая страница представляет несколько языков, или же они могут обрабатываться с помощью порядка сортировки, используемого для другого языка. В этих случаях дополнительные языки были исключены из списка.
Параметры сортировки в SQL Server 2005
СУБД SQL Server 2005 поддерживает все языки, поддерживаемые операционными системами Microsoft Windows. Это означает, что в SQL Server 2005 была добавлена поддержка параметров сортировки, впервые появившихся или обновленных в Windows Server 2003 и Windows XP. (Эти параметры сортировки задаются во время установки SQL Server 2005. Выбор параметров сортировки для сервера и базы данных осуществляется во время их настройки. Обновления операционной системы не влияют на параметры сортировки, используемые SQL Server.)
Важным дополнением к параметрам сортировки стали параметры сортировки для восточноазиатских языков с поддержкой добавочных символов. Была также добавлена поддержка сравнения строк добавочных символов на основе кодовой позиции. Для обеспечения возможности истинного сравнения кодовых позиций был введен двоичный флаг (BIN2).
При двоичных параметрах сортировка и сравнение данных SQL Server производятся на основе последовательностей битов для каждого символа. Каждый набор параметров двоичной сортировки в SQL Server соответствует конкретному региональному языковому стандарту и кодовой странице ANSI, и каждый обеспечивает сортировки данных с учетом регистра и диакритических знаков. Параметры двоичной сортировки обеспечивают самую быструю сортировку данных.
Параметр «Двоичный» (_BIN) обеспечивает сортировку и сравнение данных в таблицах SQL Server на основе последовательностей битов, определенных для каждого символа. Порядок двоичной сортировки учитывает регистр и диакритические знаки. Он также является самым быстрым. Если этот параметр не выбран, SQL Server следует правилам сортировки и сравнения, которые используются в словарях для соответствующего языка или алфавита.
Параметр «Двоичный-кодовая позиция» (_BIN2) для данных в Юникоде обеспечивает сортировку и сравнение данных в таблицах SQL Server на основе кодовых позиций. Для данных в других кодировках параметр «Двоичный-кодовая позиция» будет использовать сравнения, тождественные двоичным сортировкам. Преимущество использования порядка сортировки «Двоичный-кодовая позиция» заключается в том, что в приложениях, сравнивающих отсортированные данные SQL Server, не требуется повторная сортировка данных. В результате порядок сортировки «Двоичный-кодовая позиция» упрощает разработку приложений и может повышать производительность.
В Приложении E приведен список параметров сортировки, обновленных в SQL Server 2005. За исключением случая, когда нужно обеспечить обратную совместимость с SQL Server 2000 или более ранними версиями, лучше пользоваться обновленными параметрами.
Параметры сортировки в SQL Server 2005 могут быть следующих типов: параметры сортировки Windows и параметры сортировки SQL Server.
Параметры сортировки Windows
Параметры сортировки Windows определяют правила хранения символьных данных на основе соответствующего регионального языкового стандарта Windows. (Существует больше региональных стандартов Windows, чем параметров сортировки Windows для SQL Server.) Правила базовых параметров сортировки Windows определяют, какой алфавит или язык используется, когда применяется словарная сортировка, а также какая кодовая страница используется для хранения символьных данных в кодировках, отличных от Юникода. В СУБД SQL Server параметры сортировки Windows дополняются рядом суффиксов, чтобы дополнительно определить правила сортировки и сравнения с учетом чувствительности к регистрам, диакритических знакам, типу каны и ширине. Полное название набора параметров сортировки Windows состоит из обозначения параметров сортировки и этих стилей сравнения.
Параметры сортировки Windows реализуют сравнение и сортировка данных в кодировках, отличных от Юникода, на основе того же алгоритма, что и для данных в формате Юникод. Это обеспечивает согласованность для разных типов данных, представленных в экземпляре SQL Server, а также дает разработчикам возможность сортировать в своих приложениях строки с помощью тех же правил, что используются SQL Server - т.е. вызывая функцию CompareStringW интерфейса Microsoft Win32 API.
Параметры двоичной сортировки
Параметры двоичной сортировки сортируют данные на основе последовательности кодированных значений, определяемых региональным языковым стандартом и типом данных. Набор параметров двоичной сортировки в SQL Server определяет, какой языковой стандарт и какую кодовую страницу следует использовать, и принудительно применяет двоичный порядок сортировки. Параметры двоичной сортировки полезны, когда необходимо добиться повышенной производительности приложения, поскольку такие режимы сравнительно просто реализуются. Для типов данных, не использующих Юникод, сравнение данных основано на кодовых позициях, определенных в кодовой странице ANSI. Для типов данных, использующих Юникод, сравнение данных основано на кодовых позициях Юникода. Для параметров двоичной сортировки типов данных, использующих Юникод, региональные языковые стандарты при сортировках данных не учитываются. Например, режимы Latin_1_General_BIN и Japanese_BIN2 при применении к данным формата Юникод дают идентичные результаты сортировки. Это происходит потому, что параметры сортировки определяют сравнение данных в формате Юникод как Юникод, а данные иного формата - как двоичные.
В SQL Server 2000 параметры двоичной сортировки для данных в формате Юникод приводили к неполному попарному сравнению кодовых позиций. Первый символ сравнивался как значение типа WCHAR, а за этим следовало побайтовое сравнение. Для сохранения обратной совместимости существующая семантика параметров двоичной сортировки изменена не будет.
Параметры двоичной сортировки в SQL Server 2005 включают как параметры сортировки BIN предыдущей версии, так и новый набор параметров сортировки для чистого сравнения кодовых позиций. Потребители могут предпочесть переход на новые параметры двоичной сортировки, чтобы воспользоваться возможностью истинного сравнения кодовых позиций. При разработке новых приложений должны использоваться новые параметры двоичной сортировки. Новый суффикс BIN2 обозначает имена параметров сортировки, реализующих новую семантику параметров сортировки на основе кодовых позиций. Кроме того, добавлен новый флаг сравнения, соответствующий суффиксу BIN2 для новой двоичной сортировки.
СУБД SQL Server автоматически предлагает параметры сортировки по умолчанию на основе языка системы. Настройки параметров сортировки Windows по умолчанию следует изменять только если установка SQL Server должна соответствовать настройкам параметров сортировки, используемым другим экземпляром SQL Server, или если параметры сортировки должны соответствовать системному языку другого компьютера.
При необходимости обрабатывать добавочные символы измените набор параметров сортировки по умолчанию на один из более новых, поддерживающих операции упорядочения и сравнения для добавочных символов. Сравнение производится только на основании кодовых позиций, а не каких-либо других лингвистически значимых характеристик. Эти операции поддерживают только параметры сортировки версий 90, обозначенные добавлением суффикса 90 к их именам. Так, вместо параметров сортировки Japanese следует использовать параметры Japanese_90. Если вы не пользуетесь параметрами сортировки, учитывающими добавочные символы, будьте внимательны при использовании этих символов в таких операциях, как ORDER BY, GROUP BY и DISTINCT, особенно если в одной операции используются и обычные символы, и добавочные.
Параметры сортировки SQL Server
Параметры сортировки SQL Server обеспечивают совместимость на уровне порядка сортировки с предыдущими версиями SQL Server. Параметры сортировки SQL Server основаны на устаревших порядках сортировки SQL Server для данных в формате, отличном от Юникода (например, для типов данных char и varchar), в том виде, в каком эти порядки определяет СУБД SQL Server. Правила словарной сортировки для данных в формате, отличном от Юникода, несовместимы ни с какими процедурами сортировки, предоставляемыми операционными системами Windows. Однако сортировка данных в формате Юникод совместима с одной из версий правил сортировки Windows. Поскольку в параметрах сортировки SQL Server используются разные правила сравнения для данных в формате Юникод и других данных, можно обнаружить, что сравнения одних и тех же данных дают разные результаты. Они зависят от базового типа данных.
При обновлении экземпляра SQL Server в целях обеспечения совместимости с существующими экземплярами SQL Server можно указать параметры сортировки SQL Server. Поскольку для экземпляра SQL Server параметры сортировки по умолчанию выбираются во время установки, важно тщательно определить настройки параметров сортировки в следующих случаях:
- код приложения тем или иным образом зависит от поведения предыдущих параметров сортировки SQL Server;
- необходимо использовать репликацию SQL Server 2005 совместно с существующими установками SQL Server 6.5 или SQL Server 7.0;
- необходимо хранить символьные данные на нескольких языках.
Если в базе данных находятся как столбцы в кодировке Юникод, так и столбцы в других кодировках, следует в первую очередь пользоваться параметрами сортировки Windows. Параметры сортировки Windows применяют правила сортировки на основе Юникода к данным как в кодировке Юникод, так и в других кодировках. Это означает, что для выполнения операций сравнения СУБД SQL Server производит внутреннее преобразование в Юникод данных, кодировка которых отлична от Юникода. Это позволяет обеспечить согласованность сравнения для разных типов данных, представленных в экземпляре SQL Server, а также дает разработчикам возможность сортировать строки в своих приложениях с помощью тех же правил, которые используются и в SQL Server.
С другой стороны, параметры сортировки SQL применяют к данным типов, не использующих Юникод, правила сортировки, не поддерживающие Юникод, а к данным формата Юникод (с помощью соответствующего поддерживающего Юникод набора параметров сортировки Windows) - правила, поддерживающие Юникод. Такое различие может привести к несогласованным результатам при сравнениях одних и тех же символов. Поэтому при обработке в базе данных сочетания столбцов в формате Юникод и других форматах все эти столбцы должны быть определены с помощью параметров сортировки Windows, чтобы и к данным Юникода, и к другим данным применялись одни правила сортировки.
Обратная совместимость параметров сортировки
В СУБД SQL Server 2000 параметры двоичной сортировки BIN для данных в формате Юникод задавали выполнение неполного попарного сравнения элементов кода. При таких параметрах двоичной сортировки первый символ сравнивался как значение типа WCHAR, а за этим следовало побайтовое сравнение. Это могло приводить к тому, что сортировка символьных данных в формате Юникод происходила непредсказуемым образом.
Для обеспечения обратной совместимости существующая семантика параметров двоичной сортировки изменена не будет. Однако новые параметры сортировки могли стать функциональнее старых. В приложении перечислены параметры сортировки, сохраненные ради обратной совместимости с версиями SQL Server 2000 и SQL Server 7.0.
Получить сведения о параметрах сортировки в базе данных можно с помощью следующих системных представлений:
|
Представление каталога |
Описание |
|---|---|
| sys.databases | Возвращает сведения о параметрах сортировки базы данных. |
| sys.columns | Возвращает сведения о параметрах сортировки столбца в таблице или представлении. |
| COLLATIONPROPERTY | Возвращает сведения о параметрах сортировки в SQL Server 2005.
Вы можете передать значение CodePage или LCID, чтобы получить код языкового стандарта, или Null для параметров сортировки SQL. Вы можете также указать атрибут Windows ComparisonStyle (возвращает Null как для параметров двоичной сортировки, так и для параметров SQL). Атрибут ComparisonStyle можно использовать, чтобы убедиться в эквивалентности для параметров сортировки Windows нормализации строк в Windows и в SQL Server. |
| fn_helpcollations | Возвращает список доступных параметров сортировки в SQL Server 2005.
SELECT * FROM ::fn_helpcollations() В SQL Server 2005 этот запрос возвращает 1011 наборов параметров сортировки. (В SQL Server 2000 - 753 набора.) |
| SERVERPROPERTY | Возвращает параметры сортировки, заданные для сервера.
SELECT CONVERT(char, SERVERPROPERTY('collation')) |
| DATABASEPROPERTYEX | Определяет параметры сортировки базы данных, например:
SELECT CONVERT(char, DATABASEPROPERTYEX('pubs', 'collation')) |
Добавить дополнительные параметры сортировки невозможно, если они не будут добавлены в пакетах обновления или в следующих версиях.
Параметры сортировки и сортировка данных
Как правило, каждый набор параметров сортировки, определенный в экземпляре SQL Server для столбца в формате Юникод, будет производить сортировку всех определенных символов Юникода. Однако существует множество разных параметров сортировки, поскольку есть много различий в способах сортировки данных. Хорошим примером может служить современная сортировка грузинского языка. Хотя при традиционной сортировке грузинского текста все символы располагаются в определенном порядке, в наше время обычно некоторые редко используемые буквы помещают в конец. Это - буквы HE (), HEI (), WE () и HAR (). Таким образом, существует два способа сортировки грузинского алфавита: традиционный и современный.
Рис. 4. Традиционный грузинский порядок сортировки
Рис. 5. Современный грузинский порядок сортировки
Существование этих параметров сортировки не мешает сортировке других данных в формате Юникод в соответствии с порядком сортировки, предусмотренным параметрами сортировки Latin1_General. В действительности все параметры сортировки сортируют грузинский текст традиционным образом, а параметры сортировки Georgian_Modern_Sort представляют собой единственное исключение. Иными словами, ко всем параметрам сортировки применимы одни общие правила, и только исключения меняются от режима к режиму.
Уровни параметров сортировки
СУБД SQL Server 2005 поддерживает определение параметров сортировки на следующих уровнях экземпляра SQL Server 2005:
- уровень сервера;
- уровень базы данных;
- уровень столбца;
- уровень выражения.
В этом разделе показано, что представляют собой уровни параметров сортировки и как они взаимодействуют, когда используется несколько режимов.
Параметры сортировки на уровне сервера
Параметры сортировки по умолчанию для экземпляра SQL Server задаются во время установки. Параметры сортировки по умолчанию для системных баз данных совпадает с параметрами по умолчанию для экземпляра сервера. После того как любому объекту, за исключением столбца или базы данных, назначены параметры сортировки, изменить их, иначе как удалив и создав заново объект, невозможно. Вместо изменения параметров сортировки экземпляра SQL Server можно задать параметры сортировки при создании новой базы данных или столбца базы данных.
В предыдущих версиях параметры сортировки всегда устанавливались на уровне сервера, и во многих случаях это был единственный набор параметров сортировки, который приходилось когда бы то ни было устанавливать. Параметры сортировки сервера действуют как параметры по умолчанию при каждом создании на сервере новой базы данных. Этого не происходит только если параметры сортировки задаются явным образом на уровне базы данных. Поскольку для каждой базы данных задаются собственные параметры сортировки, обращение к параметрам сортировки уровня сервера происходит только когда создается новая база данных.
В SQL Server 2000 можно менять для сервера параметры сортировки по умолчанию, не запуская вновь программу установки. Для этого используется служебная программа Rebuild Master (RebuildM.exe), расположенная в каталоге Program Files\Microsoft SQL Server\80\Tools\BINN. В SQL Server 2005 эта программа не поддерживается. Вместо нее следует использовать программу установки Setup.exe с параметром REBUILDDATABASE. Однако поскольку параметры сортировки для сервера используется редко, вместо изменения параметров по умолчанию экземпляра SQL Server 2005 можно указывать параметры сортировки по умолчанию для каждой новой базы данных.
Если необходимо изменить параметры сортировки по умолчанию для экземпляра SQL Server 2005, следует сначала создать сценарий или резервную копию базы данных и удалить все базы данных пользователей. После этого нужно перестроить главную базу данных, задав новые параметры сортировки в свойстве SQLCOLLATION команды установки:
start /wait setup.exe /qb INSTANCENAME=MSSQLSERVER REINSTALL=SQL_Engine REBUILDDATABASE=1 SAPWD=test SQLCOLLATION=SQL_Latin1_General_CP1_CI_AI
Параметры сортировки на уровне базы данных
При создании базы данных можно указать для нее параметры сортировки по умолчанию с помощью предложения COLLATE инструкции CREATE DATABASE. Если этого не сделать, новой базе будут назначены параметры сортировки базы model. По умолчанию они те же, что и параметры сортировки по умолчанию для текущего экземпляра SQL Server.
У каждой базы данных могут быть собственные параметры и порядок сортировки. На рис. 6 показана установка параметров сортировки с помощью среды SQL Server Management Studio.
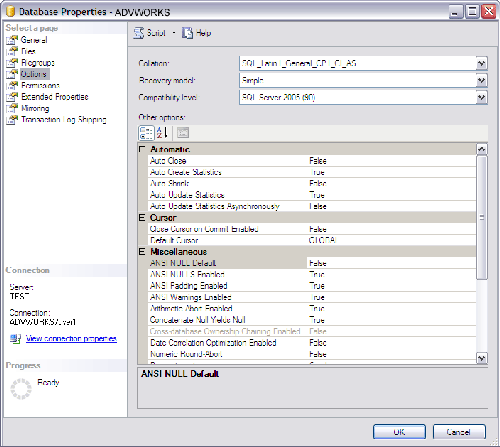
Рис. 6. Установка параметров сортировки базы данных на вкладке «Параметры» окна «Свойства базы данных»
Установить порядок параметров сортировки можно и с помощью Transact-SQL. Например, следующая инструкция создаст новую базу данных с порядком сортировки, соответствующим чешскому языку и учитывающим регистр и диакритические символы:
USE master GO CREATE DATABASE Products ON ( NAME = products_dat, FILENAME = 'c:\program files\microsoft sql server\mssql\data\products.mdf' ) COLLATE Czech_CS_AS GO
В SQL Server 2005 с помощью среды SQL Server Management Studio можно изменить параметры сортировки и существующей базы данных. В SQL Server 2000 в среде SQL Server Enterprise Manager такой возможности не было. Вместо нее приходилось использовать инструкцию ALTER DATABASE. Например, следующая инструкция изменяет параметры сортировки базы данных Products с Czech_CS_AS на Czech_CI_AI (то же, но без учета регистра и диакритики):
ALTER DATABASE Products COLLATE Czech_CI_AI
Особенности изменения параметров сортировки базы данных
Если поле имеет тип text, varchar или char и ему не присвоены собственные параметры сортировки, то изменение параметров сортировки базы данных изменит способ интерпретации кодировки данных этого поля, в результате чего знаки за пределами диапазона ASCII будут выглядеть поврежденными.
Ввиду этого следует избегать изменения параметров сортировки базы, содержащей текстовые данные не в формате Юникод, если только поля, содержащие их, не имеют явно заданных собственных параметров сортировки.
Изменить параметры сортировки базы удастся только при выполнении всех следующих условий:
- никто больше не должен использовать базу данных;
-
ни один привязанный к схеме объект не должен зависеть от параметров сортировки базы данных. К таким объектам относятся:
- определенные пользователем функции и представления, созданные с параметром SCHEMABINDING;
- вычисляемые столбцы;
- ограничения CHECK;
- возвращающие табличные значения функции, в результатах которых присутствуют текстовые столбцы с параметрами сортировки, унаследованными от базы данных.
- в результате изменения параметров сортировки базы не должны возникать дубликаты среди системных имен. В противном случае генерируется ошибка, а изменение не производится.
Объекты, которые могут вызвать появление дубликатов:
- имена объектов (процедур, таблиц, триггеров, представлений);
- имена схем (группа, роль, пользователь);
- имена скалярных типов данных (определенных пользователем или системных);
- имена полнотекстовых каталогов;
- имена столбцов и параметров в рамках одного объекта;
- имена индексов в рамках одной таблицы.
Пусть, например, в базе данных содержится две таблицы, Table1 и TABLE1, а вы пытаетесь изменить параметры сортировки с French_CS_AS (учитывает регистр и диакритику) на French_CI_AS (не учитывает регистр, учитывает диакритику). При использовании первого набора параметров сортировки две эти таблицы могут существовать одновременно. Но при попытке перехода на второй набор параметров их имена станут неразличимыми.
Параметры сортировки на уровне столбцов
В SQL Server 2005 правила сортировки текста можно задать для каждого столбца. Это очень удобно, если, например, требуется различать регистр хранящихся в столбце паролей. Другой пример - когда столбцы одной таблицы хранят текст на разных языках. Так, столбцу с именами клиентов лучше всего подошла бы кодировка Юникод с параметрами сортировки Latin1_General, тогда как столбец с названиями товаров, всегда содержащий текст на греческом, сочетался бы с греческими же параметрами сортировки. На рис. 7 показано, как указать параметры и порядок сортировки при создании таблицы.

Рис. 7. Выбор параметров сортировки
Если параметры сортировки столбца еще не были выбраны, при щелчке на нем в поле Параметры сортировки будет <значение по умолчанию для базы данных>. Чтобы его изменить, нажмите кнопку с многоточием (...). Откроется диалоговое окно Параметры сортировки, где можно выбрать параметры сортировки из имеющихся в Windows и SQL Server и задать порядок сортировки.
При выборе «Параметры сортировки Windows» можно указать, следует ли учитывать регистр, диакритические знаки, тип каны и ширину.
Параметры сортировки столбца можно указать и с помощью Transact-SQL, добавив предложение COLLATE к определению столбца в инструкции CREATE TABLE.
Следующий код демонстрирует использование Transact-SQL для задания таких параметров сортировки для столбца с описаниями должностей: арабский, не чувствительный к регистру и диакритическим символам, чувствительный к типу каны.
CREATE TABLE jobs
(
job_id smallint
IDENTITY(1,1)
PRIMARY KEY CLUSTERED,
job_desc varchar(50)
COLLATE Arabic_CI_AI_KS
NOT NULL
DEFAULT 'New Position - title not formalized yet',
)Для изменения параметров сортировки столбца можно использовать инструкцию ALTER TABLE (кроме столбцов ntext и text). Если предложение COLLATE не указано, изменение типа данных столбца приведет к установке для него параметров сортировки, принятых по умолчанию в базе данных.
В SQL Server 2005 параметры сортировки можно изменить в программном коде, используя свойство column.collation объектов SMO.
Предложение COLLATE можно использовать для изменения параметров сортировки столбцов только следующих типов данных: char, varchar, nchar и nvarchar. Чтобы изменить параметры сортировки столбца с определяемым пользователем псевдонимом типа данных, необходимо тремя отдельными инструкциями ALTER TABLE изменить тип данных на системный, изменить параметры сортировки и вернуть обратно псевдоним типа данных.
Нельзя включать в инструкцию ALTER COLUMN изменение параметров сортировки в любом из следующих случаев:
- если на изменяемый столбец ссылаются ограничения CHECK или FOREIGN KEY, либо вычисляемый столбец;
- если столбец фигурирует хотя бы в одном индексе, статистике или полнотекстовом индексе. Статистика, созданная для столбца автоматически, при изменении параметров сортировки удаляется;
- если на столбец ссылается привязанное к схеме представление или функция.
Можно вставлять и обновлять значения текстовых столбцов, в параметрах сортировки которых используется иная кодовая страница, нежели принятая по умолчанию для базы данных. SQL будет неявно применять для таких данных параметры сортировки столбца.
Указание параметров сортировки в выражениях
Параметры сортировки на уровне выражения устанавливаются во время его выполнения и влияют на возвращаемые результаты. Это позволяет отсортировать результирующий набор данных, указав используемый для сортировки язык в предложении ORDER BY.
При установке SQL Server предлагается выбрать параметры двоичной сортировки либо параметры сортировки Windows. Этот выбор повлияет на способ сравнения данных и их сортировку в рамках данного экземпляра Microsoft SQL Server.
Довольно часто доступ к данным приходится предоставлять людям из разных стран, для чего требуется сортировка, подходящая для определенного языка. В SQL Server 2000 и 2005 можно указывать параметры сортировки непосредственно в выражении. С помощью этой удобной возможности можно определять поведение ORDER BY в зависимости от нужного языка.
Например, следующий запрос в базе данных AdventureWorks сортирует таблицу Person.Address по городу, входящему в адрес. Порядок сортировки, соответствующий литовскому языку, неплохо демонстрирует различия в параметрах сортировки благодаря особенностям обработки буквы Y.
SELECT * FROM Person.Address ORDER BY City COLLATE Lithuanian_CI_AI
В следующем примере предполагается, что в таблице Table1 не назначены параметры сортировки на уровне столбцов. Тогда оба столбца будут сравниваться, исходя из турецкого порядка сортировки.
SELECT * FROM Table1 WHERE Field1 = Field2 COLLATE Turkish_ci_ai
Использование параметров сортировки при сравнениях описывается далее в разделе «Приоритет параметров сортировки».
Ключевое слово COLLATE
Параметры сортировки можно определить на уровне базы данных, столбца или выражения. При этом используется такой синтаксис:
COLLATE [<Windows_Collation_name>/<SQL_Collation_Name]
Если в столбце не используется Юникод (типы данных ntext, nvarchar, nvarchar(max) и nchar), параметры сортировки преобразуются в кодовую страницу.
Ключевое слово COLLATE позволяет использовать два следующих типа параметров сортировки:
Параметры сортировки Windows
Определяются в Windows. Можно выбрать чувствительность к регистру, диакритическим символам, типу каны и ширине, а также двоичный порядок сортировки.
Параметры сортировки SQL
Эти параметры предоставляются для обратной совместимости. Настроить порядок сортировки нельзя.
Обычно по возможности следует использовать параметры сортировки Windows. В следующем примере представлен список кодов и названий стран, по-разному отсортированный в зависимости от параметров сортировки. Список в верхней части окна запроса отсортирован с параметрами сортировки по умолчанию. В нижней части - тот же список, отсортированный с литовскими параметрами сортировки.
В первом случае Y оказывается между X и Z. Во втором - между I и J.
Рис. 8. Влияние литовских параметров на сортировку
Приоритет параметров сортировки
Поскольку указать параметры сортировки можно на уровне сервера, базы данных, столбцов и выражений, важно иметь представление об их взаимодействии. Приоритет параметров сортировки определяет, какие параметры применяются к выражениям, вычисляемым как строка, и какие параметры используются операторами, принимающими строковый ввод, но не возвращающими строк, такими как LIKE и IN.
Приоритеты параметров сортировки в SQL Server 2005 применимы только к строковым типам данных - char, varchar, text, nchar, nvarchar и ntext. Объекты с другими типами данных не участвуют в определении параметров сортировки.
От параметров сортировки зависят операторы сравнения, а также операторы MAX, MIN, BETWEEN, LIKE и IN. Строкам, используемым как их аргументы, назначаются параметры сортировки операнда, имеющего наивысший приоритет. Оператор UNION также выполняется с учетом этих параметров, и всем строковым операндам также назначаются параметры сортировки операнда, имеющего наивысший приоритет. Для этого оператора приоритет определяется для каждого столбца отдельно.
Оператор присваивания не чувствителен к параметрам сортировки. Правая часть выражения приводится к параметрам сортировки левой.
Оператор сцепления строк не чувствителен к параметрам сортировки. Строкам-аргументам и результату назначаются параметры сортировки операнда, имеющего наивысший приоритет. Операторы UNION ALL и CASE не чувствительны к параметрам сортировки. Всем строковым операндам и результату назначаются параметры сортировки операнда, имеющего наивысший приоритет. Для оператора UNION ALL приоритет определяется для каждого столбца отдельно.
Поскольку у объектов могут быть разные параметры сортировки на разных уровнях, в SQL Server 2005 введены метки параметров сортировки , помогающие управлять сложным взаимодействием параметров. Такая метка описывает категорию, к которой относится объект, принимающий параметры сортировки. Правила применения параметров описываются в форме взаимодействия меток.
Если в выражении используется только один строковый объект, выражению присваивается его метка. Если операндов два и их метки одинаковы, такая же метка присваивается выражению.
Если в сложном выражении присутствуют два операнда с разными параметрами сортировки, метка результата определяется набором правил приоритета параметров сортировки.
В следующем списке приведены типы меток параметров сортировки. Далее показана диаграмма, обобщающая возможные взаимодействия между ними.
Явные
Параметры сортировки выражения либо явно заданы, либо явно приведены к определенным параметрам сортировки (X) предложением COLLATE.
Неявные
В выражении участвует столбец. Даже если столбцу были назначены параметры сортировки предложением COLLATE инструкции CREATE TABLE или CREATE VIEW, при упоминании его в выражении параметры считаются неявными.
Приводимые по умолчанию
Для всех строковых переменных, параметров и литералов Transact-SQL, для результатов встроенных функций каталога и встроенных функций, которые возвращают строку, но не принимают строковых параметров, применяются параметры сортировки уровня базы данных.
Если объект объявляется в определенной пользователем функции, хранимой процедуре или триггере, ему назначаются параметры сортировки по умолчанию базы данных, в которой создана функция, хранимая процедура или триггер. Если объект объявляется в пакете, ему назначаются параметры сортировки по умолчанию текущей базы данных подключения.
Без параметров сортировки
Когда значение выражения представляет собой результат операции между двумя строковыми операндами, имеющими конфликтующие неявные метки, этот результат помечается как не имеющий параметров сортировки.
|
Явные ПС1 |
Неявные ПС1 |
По умолчанию |
Без параметров | |
|---|---|---|---|---|
| Явные ПС2 | Ошибка времени выполнения | Явные ПС2 | Явные ПС2 | Явные ПС2 |
| Неявные ПС2 | Явные ПС1 | Без параметров | Неявные ПС2 | Без параметров |
| По умолчанию | Явные ПС1 | Неявные ПС1 | По умолчанию | Без параметров |
| Без параметров | Явные ПС1 | Без параметров | Без параметров | Без параметров |
Из таблицы видно, что SQL Server не может обработать выражение только если в нем конфликтуют явно заданные разные параметры сортировки или когда сравниваются два элемента, для которых нет общей основы для сравнения.
Рассмотрим следующую инструкцию Transact-SQL, создающую таблицу:
CREATE TABLE TestTab ( id int, GreekCol nvarchar(10) COLLATE greek_ci_as, LatinCol nvarchar(10) COLLATE latin1_general_cs_as ) INSERT TestTab VALUES (1, N'A', N'a') GO
Одному столбцу этой таблицы назначается нечувствительные к регистру, чувствительные к диакритическим символам греческие параметры сортировки, а второму - чувствительные к обоим этим элементам параметры General Latin1.
Попытаемся сравнить два столбца в запросе:
SELECT * FROM TestTab WHERE GreekCol = LatinCol
Это приведет к ошибке:
Msg 468, Level 16, State 9, Line 1 Cannot resolve the collation conflict between "Latin1_General_CS_AS" and "Greek_CI_AS" in the equal to operation.
Она возникает потому, что сервер не может сравнить два участка текста, имеющие разные параметры сортировки. Но если использовать ключевое слово COLLATE для явного создания выражения с совместимыми параметрами сортировки, запрос выполнится успешно:
SELECT * FROM TestTab WHERE GreekCol = LatinCol COLLATE greek_ci_as
Хотя для столбца LatinCol регистр учитывается, нечувствительные к регистру параметры сортировки из выражения имеют более высокий приоритет, так что прописная и строчная "A" будут рассматриваться как одинаковые буквы.
Зависимость функции от параметров сортировки определяется типом данных ее аргументов. Функции CAST, CONVERT и COLLATE зависят от этих параметров, если принимают типы char, varchar и text. Если на входе и на выходе функций CAST и CONVERT - строки, возвращаемой строке присваивается метка параметров сортировки строки на входе. Если на входе не строка, возвращаемой строке присваивается метка «Приводимые по умолчанию». Ей назначаются параметры сортировки текущей базы данных подключения или базы данных, содержащей определяемую пользователем функцию, хранимую процедуру или триггер, из которых вызывается функция CAST или CONVERT.
Результатам всех встроенных функций, которые возвращают строку, но не принимают строковых параметров, присваиваются метка «Приводимые по умолчанию» и параметры сортировки текущей базы данных или базы данных, которая содержит определяемую пользователем функцию, хранимую процедуру или триггер, из которых вызывается данная встроенная функция.
Ограничения ключевого слова COLLATE
Ключевое слово COLLATE и связанные с ним возможности - гибкий и мощный инструмент для разработчика многоязычных баз данных. Но у него есть и свои ограничения. Они перечислены ниже вместе с соответствующими способами обойти эти ограничения.
Возвращается не весь список параметров сортировки
Функция fn_helpcollations возвращает список всех параметров сортировки, предоставляемых в SQL Server. Исключение составляют три устаревшие параметра сортировки, которые эта функция не поддерживает. Параметры сортировки хинди в SQL Server 2005 помечены как устаревшие, поскольку в этом выпуске SQL Server используется таблица сортировки из Windows 2000 бета-версии 2. Эти параметры не удалены из сервера, но в будущих выпусках поддерживаться не будут. Параметры сортировки хинди и Lithuanian_Classic в SQL Server 2005 помечены как устаревшие. Они не удалены из сервера, но в будущих выпусках поддерживаться не будут.
Если необходимо использовать параметры сортировки в программном коде, пользовательский интерфейс для этого придется разработать самостоятельно.
Неявное преобразование
Неявное преобразование из одних параметров сортировки в другие для строковых данных не в формате Юникод является недетерминированным. Неявное преобразование из одних параметров сортировки в другие для строк не в формате Юникод также считается недетерминированным, если только значение уровня совместимости не равно 80 или менее.
В более ранних версиях SQL Server системные объекты и имена системных типов сопоставлялись с использованием параметров сортировки базы данных master. В SQL Server 2005 они автоматически приводятся в соответствие с параметрами сортировки текущей базы данных. Если ссылки на эти объекты из сценариев или приложений не совпадают с таковыми в каталоге, и виной тому параметры сортировки, то сценарий или приложение могут завершиться неудачно. К примеру, инструкция EXEC SP_heLP не будет выполнена, если в текущей базе данных действуют параметры сортировки, чувствительные к регистру.
Проблемы с определением параметров сортировки на уровне столбцов
Иногда может возникнуть ситуация, когда для базы данных используются одни параметры сортировки (например Latin1_General), а для отдельных столбцов - другие (например греческие). Или, например, база содержит данные на многих языках, сортировать которые нужно с применением более чем одного набора параметров сортировки, так что указать универсальные параметры не получается. В обоих случаях возможность определить несколько наборов параметров сортировки, каждый из которых может использоваться в индексации, означала бы возможность обратиться к данным на нужном языке путем выбора соответствующих параметров сортировки. Например, легко просмотреть данные на греческом, указав греческие параметры сортировки.
Более того, задав дополнительные параметры сортировки, можно воспользоваться преимуществами индексированного поиска по этим данным. Возможность проиндексировать столбец с точки зрения поиска является ключевой. В примере из предыдущего раздела выражение COLLATE в предложении ORDER BY обеспечивает необходимый способ сортировки, однако индекс при сортировке использоваться не будет, так что возвращение объемных результатов запроса займет больше времени. По этой причине указание параметров сортировки на уровне столбцов приобретает смысл только если в столбце содержатся данные не на одном языке или если база денормализована для хранения данных на разных языках в разных столбцах.
Параметры сортировки и база данных tempdb
База данных tempdb создается при каждом запуске SQL Server. Ей всегда назначаются те же параметры сортировки по умолчанию, что и базе данных model. Как правило, они совпадают с параметрами сортировки по умолчанию для текущего экземпляра сервера. Если создать новую базу данных и назначить ей иные параметры сортировки, нежели в базе model, параметры сортировки новой базы будут отличаться от таковых в tempdb. Все временные хранимые процедуры и таблицы создаются и хранятся в tempdb. В итоге все столбцы без явно заданных параметров сортировки из временных таблиц, а также все константы, переменные и параметры с метками «Приводимые по умолчанию» во временных хранимых процедурах будут иметь параметры сортировки, отличные от параметров сортировки сравниваемых объектов из постоянных таблиц и хранимых процедур.
Это может привести к проблемам, связанным с несовпадением параметров сортировки у пользовательских баз данных и объектов в системной базе данных. Пусть, например, экземпляру SQL Server 2005 назначены параметры сортировки Latin1_General_CS_AS. Выполним следующую инструкцию:
CREATE DATABASE TestDB COLLATE Estonian_CS_AS; USE TestDB; CREATE TABLE TestPermTable (PrimaryKey int PRIMARY KEY, Col1 nchar ); INSERT TestPermTable VALUES (1, 'a')
Затем создадим временную таблицу, используя то же описание столбцов, что и для только что созданной TestPermTab:
CREATE TABLE #TestTempTable (PrimaryKey int PRIMARY KEY, Col1 nchar ) INSERT #TestTempTable SELECT * FROM TestPermTable GO
В этой ситуации в базе данных tempdb будут использоваться параметры сортировки SQL_Latin1_General_CP1_CI_AS (кодовая страница 1252), а в базе данных TestDB и столбце TestPermTable.Col1 - параметры Estonian_CS_AS (кодовая страница 1257).
Теперь запросим строки, которые, казалось бы, должны быть одинаковыми:
SELECT * FROM TestPermTable t1 JOIN #TestTempTable t2 ON t1.Col1 = t2.Col1
Поскольку в tempdb используются параметры сервера по умолчанию, а для столбца TestPermTable.Col1 они другие, SQL Server возвращает ошибку:
"Msg 468, Level 16, State 9, Line 1 Cannot resolve the collation conflict between "SQL_Latin1_General_CP1_CI_AS" and "Estonian_CS_AS" in the equal to operation."
Предотвратить ее можно одним из следующих способов:
- назначить столбцу во временной таблице параметры по умолчанию пользовательской базы данных, а не базы tempdb. Это позволит при необходимости сопоставлять временную таблицу с другими таблицами похожей структуры, в том числе находящимися в разных базах данных;
- явно назначить столбцу из #TestTempTable нужные параметры сортировки. Это делается с помощью ключевого слова COLLATE в определении столбца.
Код языка и параметры сортировки
Код языка (LCID) используется в Windows для определения порядка сортировки. Если код неизвестен, можно использовать код по умолчанию, который равен 1024, или форматировать данные с помощью функций форматирования платформы Microsoft .NET. В ASP-приложении для Интернета можно использовать функцию VBScript SetLocale, которая изменяет форматирование даты, времени, чисел и денежных единиц в соответствии с любыми региональными стандартами. Но поскольку не существует однозначного соответствия между кодом языка и параметрами сортировки, определить нужные параметры для конкретного кода нельзя.
Это неудобно, если требуется автоматически назначать для пользователей наиболее подходящий порядок сортировки, основываясь на текущем коде языка. Например, на многоязычном веб-узле, посещаемом людьми из разных стран для просмотра информации о продукции, можно получать из переменной HTTP_ACCEPT_LANGUAGE, предоставляемой обозревателями, код языка для форматирования дат и цен с помощью свойства Session.LCID. Из соображений удобства использования можно было бы использовать эту информацию и при сортировке.
Для создания собственной функции сопоставления, которая позволит справиться с этой проблемой, можно использовать список обозначений параметров сортировки, выводимый программой установки. Обозначение указывает связь между конкретными и стандартными параметрами сортировки.
Вот несколько примеров сопоставления стандартных параметров сортировки:
- Latin1_General может использоваться для набора символов «Английский (США)» (кодовая страница 1252);
- Modern_Spanish применяется для всех диалектов испанского языка, использующих тот же набор символов, что и «Английский (США)» (кодовая страница 1252);
- Arabic подходит для всех диалектов арабского, которые используют набор символов «Арабский» (кодовая страница 1256);
- Japanese_Unicode используется для версии японского языка в формате Юникод, поскольку в ней используется иной порядок сортировки, чем в Japanese, а кодовая страница - та же (932).
Наряду с выбором обозначения параметров сортировки можно указать ее порядок. Двоичный - самый быстрый. Он чувствителен к регистру. Если выбрать его, станут недоступными параметры «С учетом регистра», «С учетом диакритических знаков», «С учетом типа японской азбуки» и «С учетом ширины символов».
Строки ISO и параметры сортировки
Переменную HTTP_ACCEPT_LANGUAGE можно получить с помощью языка VBScript следующим образом:
Dim stLang
stLang = Request.ServerVariables("HTTP_ACCEPT_LANGUAGE")Поскольку многие веб-разработчики хранят в этой переменной информацию о языке, функция VBScript SetLocale была разработана так, чтобы принимать это значение напрямую, а не только значения кода языка. Это избавляет от промежуточного шага, определяющего значение кода языка на основе значения переменной. Для каждой строки, представляющей язык (например «en-us» для «Английский (США) или «vi» для «Вьетнамский»), следует определить подходящие параметры сортировки, такие как Latin1_General или Vietnamese соответственно.
Пользовательские параметры сортировки
Разработчикам часто требуется определить свои собственные параметры сортировки. Но поскольку все новые параметры сортировки SQL Server унаследованы от параметров сортировки Windows, создавать новые нельзя.
Кроме того, при разработке параметров сортировки необходимо задать правила обработки каждого символа, определенного в стандарте Юникод. Пользовательского интерфейса для создания параметров сортировки также не существует.
Параметры сортировки и добавочные символы
Добавочные символы используются в операциях упорядочения и сравнения только для параметров сортировки версии _90. Сравнение основывается только на позициях кода символа, а не каких-либо лингвистических методиках. Будьте внимательны при использовании добавочных символов в операциях ORDER BY, GROUP BY и DISTINCT, особенно если в одной операции используются и обычные символы, и добавочные.
Поскольку добавочные символы хранятся в виде пар двухбайтовых символов Юникода, функция LEN() возвращает значение 2 для каждого из добавочных символов, содержащихся в строке аргумента. Функции CHARINDEX и PATINDEX также неправильно определяют наличие добавочных символов в строке, а функция NCHAR возвращает символ, представляющий только первую половину добавочного символа. Преобразование значения типа binary или varbinary в добавочный символ также дает в результате только половину добавочного символа.
Функции LEFT, RIGHT, SUBSTRING, STUFF и REVERSE могут разорвать добавочный символ на два обычных, что может привести к непредвиденным результатам.
В SQL Server 2005 можно обойти ограничения системных функций сервера, работая с добавочными символами с помощью определяемых пользователем функций CLR. Дополнительные сведения о создании и использовании функций, учитывающих добавочные символы, с использованием общеязыковой среды выполнения .NET Framework приводятся в примерах, поставляемых с SQL Server 2005. В одном из них, StringManipulate, демонстрируется корректная обработка строк с добавочными символами, а также реализация строковых функций LEN(), LEFT(), RIGHT(), SUBSTRING() и REPLACE(), правильно работающих как с такими строками, так и с обычными строками в формате Юникод. Пример содержит сценарии на языке C# или Visual Basic .NET, а также сценарий Transact-SQL, загружающий сборку и создающий функции в SQL Server.
Взаимодействие сервер-клиент (технологии доступа к данным)
Приложениям, использующим базы данных, недостаточно только средств SQL Server, таких как среды SQL Server Management Studio. Обычно сервер взаимодействует с другими серверами и клиентами, используя определенные стандарты доступа к данным. Применительно к этой ситуации, приложение или слой, соединяющийся с SQL Server, называется клиентом . Для целей данного обсуждения клиенты можно разделить на два типа:
- клиенты, работающие с Юникодом - собственный клиент SQL, OLE DB и ODBC 3.7 и более поздних версий (MDAC 2.8 и более поздних версий);
- клиенты, не работающие с Юникодом - ODBC 3.7 и более ранних версий и DB-Library (MDAC 2.xx)
В этом разделе приводятся доступные технологии доступа к данным и кратко рассматриваются трудности, которые могут возникнуть при работе с многоязычными данными в клиент-серверной среде.
DB-Library
Хотя ядро SQL Server 2005 все еще поддерживает подключения из ранее написанных приложений с использованием DB-Library и API-интерфейсов Embedded SQL, документация и необходимые файлы для программирования таких приложений уже не предоставляются. В будущих версиях ядра базы данных SQL Server эта поддержка будет прекращена. Кроме того, версии DB-Library для работы с Юникодом не существует.
Вывод прост - не использовать DB-Library для разработки новых приложений. А изменяя существующие, удалить все зависимости от этой технологии. Вместо нее следует использовать пространство имен SQLClient или такие API-интерфейсы, как OLE DB и ODBC.
В SQL Server 2005 не входят библиотеки DB-Library, необходимые для запуска соответствующих приложений. Для работы последних нужно взять эти библиотеки из SQL Server 6.5, SQL Server 7.0 или SQL Server 2000.
Объекты SQL-DMO
Объекты распределенного управления SQL (SQL-DMO) - COM-уровень, инкапсулирующий управление базой данных и репликацией SQL Server. Поскольку это COM, к SQL-DMO применимы те же правила, что и к ADO и OLE DB. Помимо этого, SQL-DMO содержит свойства для работы с возможностями, обсуждавшимися ранее, например свойство Collation объектов SQLServer2, Database2, Column2, SystemDateType2 и UserDefinedDataType2.
OLE DB
OLE DB - центральная часть компонентов доступа к данным (MDAC). Этот интерфейс основан на COM, и потому все строки в нем имеют формат Unicode BSTR (кодировка UTF-16 в Windows XP, Windows Server 2003 и Windows 2000; кодировка UCS-2 во всех остальных операционных системах). Однако в версиях MDAC до 2.8 с пакетом обновления SP1 отсутствует поддержка именованных экземпляров. В результате приложения могут оказаться не в состоянии подключиться к именованным экземплярам SQL Server 2005. Чтобы более полно использовать возможности сервера, следует обновить компоненты доступа к данным до версии 2.8 с пакетом обновления SP1.
|
Версия |
Библиотека доступа к данным |
|---|---|
| SQL Server 7.0 | MDAC версии 2.1 |
| SQL Server 2000 | MDAC версии 2.6 |
| SQL Server 2005 | MDAC версии 2.8 |
При работе с SQL Server поставщиком данных является Microsoft OLE DB Provider for SQL Server (SQLOLEDB). При необходимости данные преобразуются в Юникод с использованием правильных параметров сортировки.
ADO
Объекты данных Microsoft ActiveX - ADO - это удобный в использовании из языка Visual Basic и сценариев интерфейс, представляющий собой оболочку для OLE DB. Он также является COM-компонентом, благодаря чему обеспечивает тот же уровень поддержки формата Юникод. Способа провести границу между ADO и OLE DB так, чтобы при ее пересечении происходили изменения состояния, соответствующие этим интерфейсам, не существует. Таким образом, если возникают трудности, причину их всегда следует искать на уровне OLE DB.
ODBC
Некоторые версии ODBC поддерживают Юникод. Одна из существенных проблем с данными не в формате Юникод при использовании ODBC - то, как они преобразуются между кодовыми страницами или в Юникод и из Юникода. Если версия ODBC ниже 3.7, данные преобразуются из формата Юникод в ANSI с использованием системной кодовой страницы, применяемой по умолчанию. Ядро Jet 3.5 будет выполнять такое преобразование даже после установки более поздней версии ODBC.
Существует два возможных состояния атрибута SQL_COPT_SS_TRANSLATE для передачи их в SQLSetConnectAttr:
- SQL_XL_OFF
Драйвер не преобразует передаваемые между клиентом и сервером символьные данные из одной кодовой страницы в другую.
- SQL_XL_ON
Драйвер преобразует передаваемые между клиентом и сервером символьные данные из одной кодовой страницы в другую. Он автоматически настраивает преобразование, определяя кодовые страницы, установленные на сервере и используемые клиентом.
По умолчанию используется атрибут SQL_XL_ON. Установить его в SQL-DMO также можно с помощью метода TranslateChar объекта SQLServer. Чаще всего такое значение по умолчанию обеспечивает необходимое поведение (а именно включение автоматического преобразования) при каждой обработке данных не в формате Юникод.
Отключать автоматическое преобразование следует, только если вы готовы к возможным последствиям. Разработчики часто отключают его в надежде, что это позволит клиенту и серверу обмениваться данными без сопоставления кодовых страниц. Однако такой вариант взаимодействия не поддерживается. Более того, для сортировки и поиска данных не в формате Юникод, определенных с параметрами сортировки Windows, SQL Server преобразует данные в Юникод до начала операции. Если при этом автоматический перевод будет отключен, преобразованные в Юникод данные не смогут быть возвращены в свою исходную кодовую страницу при получении на клиенте.
Собственный клиент Microsoft SQL
Собственный клиент Microsoft SQL (раньше назывался собственным клиентом SQL) разрабатывался с целью получения упрощенного способа собственного доступа к данным SQL Server через OLE DB или ODBC. Он объединяет технологии OLE DB и ODBC в одну библиотеку и открывает путь к развитию и усовершенствованию новых возможностей доступа к данным без изменения текущих компонентов MDAC, которые уже стали частью платформы Microsoft Windows.
Если новые возможности SQL Server 2005 использовать не планируется, нет нужды и в поставщике OLE DB собственного клиента SQL - можно продолжать использовать текущий поставщик данных (обычно это SQLOLEDB). Если же для усовершенствования приложения требуются эти новые возможности, следует использовать поставщик OLE DB собственного клиента SQL.
Собственный клиент SQL частично использует компоненты MDAC, но не привязан к какой-то конкретной их версии.
При разработке новых приложений с помощью управляемого языка программирования, например Microsoft Visual C#.NET или Visual Basic.NET, наиболее эффективный доступ к данным SQL Server 2005 и его новым возможностям предоставляет поставщик данных .NET Framework для SQL Server, являющийся частью .NET Framework для Visual Studio 2005.
Разрабатывая приложение, основанное на COM и нуждающееся в новых возможностях SQL Server 2005, используйте собственный клиент SQL. Он поддерживает доступ и к более ранним версиям баз данных SQL Server, начиная с версии 7.0 и выше.
Основной вопрос, который следует решить для существующих приложений OLE DB и ODBC, - нужен ли им доступ к новым возможностям SQL Server 2005. Если полноценное, хорошо отлаженное приложение не нуждается в них, оно может продолжать использовать MDAC. Однако такие типы данных, как varchar(max), nvarchar(max), varbinary(max), xml, UDT или другие большие объектные типы не могут возвращаться клиентам версий ниже, чем SQL Server 2005. Если требуется возвращать такие типы данных, следует использовать собственный клиент SQL.
Как MDAC, так и собственный клиент SQL предоставляют собственный доступ к базам данных SQL Server, но собственный клиент SQL спроектирован в расчете на использование именно новых возможностей SQL Server 2005, не теряя совместимости с более ранними версиями. Кроме того, хотя в состав MDAC входят компоненты для использования OLE DB, ODBC и объектов данных ActiveX (ADO), собственный клиент SQL реализует только OLE DB и ODBC.
Для получения доступа к новым возможностям, появившимся в SQL Server 2005, существующие приложения, в которых используются объекты данных ActiveX (ADO), должны использовать поставщик OLE DB собственного клиента SQL.
Конфигурации серверов и клиентов, поддерживающих и не поддерживающих Юникод
В этом разделе рассмотрен ряд проблем, о которых следует помнить при работе с устаревшими системами, не полностью совместимыми с Юникодом.
Сервер и клиент поддерживают Юникод
Это идеальная схема. Постоянное хранение данных в формате Юникод без всяких преобразований обеспечивает наилучшую производительность и предотвращает их повреждение. Этот вариант соответствует использованию ADO и OLE DB или собственного клиента SQL Server.
Сервер поддерживает Юникод, один или несколько клиентов - нет
В подобном случае проблем с хранением данных не будет, но возникают серьезные ограничения по доставке их на клиент и использованию там. В какой-то момент данные придется преобразовать из формата Юникод с использованием кодовой страницы клиента.
Пример такого хода событий - подключение к SQL Server 2005 с компьютера, использующего DB-Library. DB-Library - интерфейс, позволяющий приложениям на языке C получать доступ к SQL Server. Со времен SQL Server версии 6.5 этот интерфейс не претерпел значительных изменений, поэтому его ограничения соответствуют серверу этой версии. Данные могут основываться только на одной кодовой странице - системной кодовой странице OEM по умолчанию. Можно указать, будет ли информация о языковых стандартах базироваться на языковых настройках клиента. Программа SQL Server Client Network Utility предоставляет на выбор два не исключающих друг друга способа преобразования информации для DB-Library - автоматическое преобразование из ANSI в OEM и использование международных настроек. Оба они по умолчанию выбраны.
Поскольку обрабатывать данные в иных кодовых страницах нельзя, использовать DB-Library следует лишь на уровне доступа к данным в устаревших системах, работающих с выборками данных с SQL Server. Эта технология поддерживается только в целях обратной совместимости, но по-прежнему доступна для поддержки многоязычных данных в устаревших приложениях.
Другой пример не поддерживающего Юникод клиента - ранние версии СУБД Microsoft Office Access. Подключившись к базе данных SQL Server с помощью такой версии Office Access, можно обнаружить, что текст в формате Юникод преобразуется в знаки вопроса, как показано на рис. 9.

Рис. 9. Японские названия таблиц, показанные знаками вопроса
Это происходит потому, что по умолчанию в ODBC 3.7 данные автоматически преобразуются в системную кодовую страницу. А поскольку японские символы не входят в кодовую страницу «Английский (США)» (1252) клиентского компьютера, они заменяются на знаки вопроса.
Более того, не удастся даже подключиться к этим таблицам. Все попытки будут завершаться сообщением об ошибке. Ядро Jet и ODBC пытаются подключиться к таблице dbo.????, что им не удается ввиду отсутствия такой таблицы. Та же ошибка будет возникать во всех случаях, когда данные не в той кодовой странице, что выбрана в клиентской системе.
Данные, преобразованные в неверную кодовую страницу и замененные знаками вопроса, преобразовать обратно уже нельзя. Например, если клиент, не поддерживающий Юникод, подключается к таблице, содержащей корейский текст в формате Юникод, этот текст заменяют знаки вопроса, как показано рис. 10.
Рис. 10. Текст, который нельзя отобразить в базе данных с клиентом, не поддерживающим Юникод
Все три устаревших клиента (DB-Library, ODBC и Jet 3.5) одинаково неспособны работать с данными в формате Юникод, за исключением тех символов, которые можно преобразовать в системную кодовую страницу по умолчанию. Избегайте использования этих компонентов при разработке клиентского программного обеспечения, если только точно не знаете, что данные можно будет преобразовать в системную кодовую страницу по умолчанию.
Кроме того, поскольку COM в Office Access предоставляет точки доступа к данным SQL Server, для интерпретации данных используются языковые настройки клиента. Может измениться формат ввода даты и времени, чисел и денежных единиц. Дополнительные сведения об этой проблеме см. далее в разделе «Устранение влияния языковых настроек COM».
Если в качестве интерфейса для SQL Server используется СУБД Office Access, для доступа к новым возможностям и поддержки формата Юникод рекомендуется обновить Office Access до версии Microsoft Office 2003 Access или Microsoft Office System 2007 Access. Справочная система Office Access содержит руководства по обновлению существующих приложений Office Access. Обратите внимание, что поддержка формата ADP после Microsoft Office Access 2000 была прекращена.
Сервер не поддерживает Юникод, клиент поддерживает
Это неудачная конфигурация для многоязычных данных, поскольку хранить их на сервере не удастся. Так как и SQL Server 2000, и SQL Server 2005 поддерживают Юникод, эта конфигурация маловероятна, если только связанный сервер в ней не будет определен как база данных SQL Server 6.5. От экземпляра SQL Server 6.5 можно будет получать корректные данные, но не следует пытаться передать ему что-либо, отсутствующее в его кодовой странице по умолчанию.
Преобразование многоязычных данных ранних версий SQL Server
Некоторые устаревшие приложения, созданные до реализации полной поддержки формата Юникод в SQL Server, используют собственные схемы кодировки многоязычных данных. Для предохранения этих данных можно использовать программу массового копирования (средство bcp), которая во избежание ошибок преобразования сохранит их в двоичном виде. Затем ту же программу можно использовать для повторного импорта данных с использованием нужной кодовой страницы, задаваемой параметром -C командной строки. Дополнительные сведения о средстве bcp содержатся в разделе Использование средств командной строки для работы с многоязычными данными настоящего документа.
Многоязычные данные в интерфейсе пользователя
Средства администрирования и управления SQL Server были обновлены для более полной поддержки многоязычных данных. В этом разделе описаны некоторые из изменений, реализованных в интерфейсе SQL Server 2005.
Общие изменения интерфейса пользователя
Новый интерфейс среды SQL Server Management Studio позволяет удобно сочетать в одной оболочке разнообразные текстовые редакторы, редакторы запросов, диалоговые окна управления, мастера, конструкторы и обозреватели. С помощью этой оболочки можно указать язык текущего подключения к серверу и управлять отображением следующих элементов:
- язык, используемый для сообщений об ошибках и других системных сообщений;
- формат отображения даты и времени;
- названия дней и месяцев, включая сокращения;
- первый день недели;
- символы валют и форматы отображения денежных значений.
Для смены шрифта, используемого в среде SQL Server Management Studio, в меню Сервис выберите пункт Параметры, затем Среда и, наконец, страницу Шрифты и цвета, где настройте начертание, размер и цвет выбранного шрифта, а также цвета отображения отдельных окон средств, у которых в SQL Server Management Studio есть панели вывода. Если вы изменили шрифт, в текущем сеансе работы изменения не будут отражены. Но можно оценить сделанные изменения, запустив еще одну копию среды SQL Server Management Studio.
В качестве текущего можно выбрать один из 34 языков. Их полный список приведен в статье sys.syslanguages (Transact-SQL) в электронной документации по SQL Server 2005.
Можно также изменить настройки текста и отображения для работы с пакетами служб Integration Services или многомерными объектами и объектами интеллектуального анализа данных служб Analysis Services с помощью центра разработки бизнес-аналитики. Используя страницы Среда диалогового окна Параметры, можно определить язык, используемый в интерфейсе и интерактивной справочной системе, шрифты и схему назначений клавиш клавиатуры. После завершения настройки среды разработки все параметры сохраняются в файле с расширением SUO в папке решения и могут повторно использоваться.
Примечание. Для отображения добавочных символов следует установить шрифт, поддерживающий их.
Для отображения списка языков, для которых доступно полнотекстовое индексирование и запросы, используется представление sys.fulltext_languages. Это представление каталога содержит одну строку на каждый язык. Каждая строка содержит понятное представление доступных полнотекстовых лингвистических ресурсов, зарегистрированных в Microsoft SQL Server. Имя или код языка можно использовать в полнотекстовых запросах и при создании полнотекстовых индексов с помощью языка DDL.
- используйте SET LANGUAGE для установки языка сеанса работы со стороны сервера;
- этот язык можно задать и со стороны клиента при помощи OLE DB, ODBC или ADO.NET;
- для OLE DB используйте свойство SSPROP_INIT_CURRENTLANGUAGE;
- для ODBC используйте ключевое слово LANGUAGE;
- для ADO.NET используйте параметр Current Language объекта ConnectionString.
Поддержка сложных сценариев
SQL Server 2005 благодаря ядру базы данных и внешним инструментам поддерживает ввод, хранение, изменение и отображение сложных сценариев. Это сценарии с двунаправленным написанием, например на арабском языке; сценарии, символы в которых меняют форму в зависимости от своего положения, например на индоарийских и тайском языках; а также сценарии, требующие применения словарей для распознавания слов, поскольку между ними нет промежутков, например написанные на тайском.
Приложения баз данных, взаимодействующие с SQL Server, должны использовать элементы управления, поддерживающие подобные сценарии. Для этого подходят стандартные элементы управления Windows Forms, создаваемые в управляемом коде. Но файлы, необходимые для поддержки сложных сценариев, необходимо установить на компьютер, используя языковые и региональные настройки.
Форматирование в конструкторе запросов
Большую часть данных в конструктор запросов можно ввести с помощью панели с сеткой, настройки которой соответствуют языковым параметрам компьютера по умолчанию. Можно также явно использовать функцию CONVERT для обработки строк в произвольном формате.
С региональными параметрами связано несколько ограничений конструктора, о которых следует помнить:
- длинные форматы даты не поддерживаются;
- обозначения валют не должны вводиться в сетку, хотя знак американского доллара ($) и может быть использован. В любом случае на панели результатов будет отображен символ валюты, соответствующий региональным параметрам;
- унарный минус вне зависимости от формата, предписываемого региональными параметрами, всегда должен находиться слева от числа, скобок быть не должно. То есть, «минус один» следует вводить как -1, а не как 1-, (1) или любым иным образом, доступным для выбора в диалоговом окне Региональные параметры.
Эти ограничения, необходимые для поддержки большого количества языков в конструкторе запросов, не станут серьезным препятствием для использования данных, зависящих от языковых параметров.
Любая информация, введенная на панели сетки, преобразуется в не зависящую от языка форму на панели SQL. Так, «03.09.65» на немецком компьютере будет преобразовано в { ts ' 1965-09-03 00:00:00 }. Все данные, вводимые на панели SQL напрямую, должны либо быть в таком формате, либо включать явный вызов функции CONVERT.
Порядок сортировки
Сортировка данных, отображаемых на панели результатов, и интерпретация предложения ORDER BY, зависит не от региональных параметров, а от параметров сортировки.
Многоязычный Transact-SQL
При отправке на сервер SQL-инструкции, содержащей данные на нескольких языках, на ее успешную доставку влияет два фактора: кодировка самой инструкции и кодировка строковых литералов внутри нее.
Кодировка инструкции SQL
Существуют ограничения на символы, которые можно использовать в инструкциях Transact-SQL. Допускается использовать символы DBCS для строковых литералов, имен объектов базы данных, псевдонимов, имен параметров и символов маркеров параметра. Однако нельзя использовать такие символы для элементов языка SQL, таких как имена функций и ключевые слова. Так, вводя ключевое слово SQL, например SELECT, следует использовать символы половинной ширины «SELECT», а не японские полноширинные «‚r‚d‚k‚d‚b‚s».
Если в строке SQL используется Юникод (как, например, в любой строке SQL, передаваемой через ADO), можно передать любой тип символа. Если Юникод в строке не используется (если строка, например, получена из пакетного или SQL-файла не в формате Юникод), в определенный момент должно быть выполнено ее преобразование. Осуществляя его, следует во избежание проблем с многоязычными приложениями тщательно все спланировать и принять во внимание кодовую страницу по умолчанию компьютера, осуществляющего преобразование.
Кодировка строковых литералов в инструкции SQL
Строковые константы в формате Юникод, находящиеся в коде, исполняемом на сервере (например в хранимых процедурах и триггерах), должны помечаться префиксом в виде заглавной буквы N. Если строковый литерал не в формате Юникод (не имеет префикса N), строка будет преобразована к кодовой странице базы данных по умолчанию, в результате чего некоторые символы могут пропасть. При работе с многоязыковыми данными лучше всего использовать типы данных и строковые литералы в формате Юникод.
В следующем примере показана строка в формате Юникод, отмеченная префиксом «n»:
SELECT n'??????'
На рис. 11 показана та же строка - а это название языка хинди на этом же языке - так, как она выглядела бы на компьютере с установленным шрифтом хинди.

Рис. 11. Символы хинди на клиенте, поддерживающем хинди
Если бы префикса «n» в начале строки не было, она была бы преобразована в ??????. То же самое происходит с данными, кодовая страница которых не соответствует системным параметрам по умолчанию.
Внимание! Использование префикса «n» перед строковыми литералами и в именах типов данных (nchar, nvarchar и ntext) для представления данных в формате Юникод - отличительная особенность SQL Server. Спецификации SQL ANSI-92 описывают «национальные» типы символьных данных, но не предписывают использование для них формата Юникод. Спецификации SQL ANSI-99 вводят набор типов данных в формате Юникод, обозначаемых префиксом «u» (например utext, uchar и uvarchar). Эти типы данных в SQL Server недоступны.
Чтобы обеспечить передачу строки в формате Юникод, всегда используйте перед ней префикс N. Это поможет избежать непредвиденных проблем с преобразованиями, возникающими при использовании кодовой страницы по умолчанию сервера.
Если приложение не отправляет данные на SQL Server в формате Юникод, а кодовая страница ANSI клиента совпадает с таковой в SQL Server, нужды в префиксе N нет. В этом случае потерь данных, если его опустить, не будет.
Если используется связанный сервер SQL Server 7.0, нужно помнить о следующем. SQL Server 7.0 позволяет во время установки выбрать параметры сортировки формата Юникод, отличные от порядка сортировки. В некоторых случаях это приводит к тому, что строки с префиксом N дают в операциях иные результаты, нежели строки без этого префикса.
Функции работы со строками
В Transact-SQL есть встроенные функции, имеющие большое значение в многоязычном контексте.
ASCII
Возвращает позицию кода первого символа строки, используя текущую системную кодовую страницу по умолчанию. Если символ в ней отсутствует, возвращается число 63 (позиция кода знака вопроса). Эта функция схожа с функцией Asc() из языков Visual Basic и VBScript.
CHAR
Возвращает символ, соответствующий позиции кода ANSI. Эта функция обратна предыдущей. Ее аналог в языках Visual Basic и VBScript - Chr(). Если позиция кода символа находится вне диапазона 0-255, возвращается Null.
NCHAR
Возвращает символ, соответствующий кодовой позиции в наборе символов Юникод. Это эквивалент предыдущей функции, поддерживающий Юникод. Функция схожа с функцией ChrW() языков Visual Basic и VBScript.
UNICODE
Возвращает кодовую позицию в наборе символов Юникод первого символа строки. Это эквивалент функции ASCII, поддерживающий Юникод. Функция схожа с функцией AscW() языков Visual Basic и VBScript.
Пример использования функции NCHAR приведен ранее в этом документе (см. «Типы даты и времени: datetime, smalldatetime»), где одна использовалась для добавления RLM (пометки «справа налево») перед датой хиджры. Добавление этой пометки обеспечивает правильное форматирование даты.
Поддержка языков в SQL Server 2005
SQL Server 2000 поддерживал 33 различных языка. В SQL Server 2005 добавлена поддержка всех языков, поддерживаемых операционными системами Microsoft Windows. В Приложении B содержится список всех поддерживаемых языков вместе с их кодами.
Для просмотра всех этих языков и информации о них можно использовать хранимую процедуру sp_helplanguage. Обратите внимание, что хотя каждая версия SQL Server хранит всю информацию обо многих перечисленных ниже элементах, получать переведенные системные сообщения можно только установив локализованную версию сервера.
Информация о языках хранится в таблице syslanguages, за исключением сообщений, которые хранятся в таблице sysmessages.
Языковые параметры
Для каждого экземпляра SQL Server должен быть язык по умолчанию, используемый в таких ситуациях, как выдача сообщений и форматирование дат. Эта информация хранится для каждого созданного имени входа на сервер. Хотя язык по умолчанию для сервера изначально выбирается во время его установки, этот выбор можно изменить на вкладке Дополнительно диалогового окна Свойства SQL Server, как показано на рис. 12. (В SQL Server 2000 этот пункт находится на вкладке Параметры сервера.)

Рис. 12. Выбор языка по умолчанию для сервера
Для той же цели можно использовать хранимую процедуру sp_configure. Например, следующая инструкция изменит язык по умолчанию сервера на итальянский:
sp_configure "language", 6
Настройки языка по умолчанию могут быть переопределены настройками входа с помощью хранимой процедуры sp_addlogin или в диалоговом окне Свойства имени входа, показанного на рис. 13.
Рис. 13. Выбор языка по умолчанию для имени входа
Язык по умолчанию может быть переопределен на уровне сеанса инструкцией SET LANGUAGE:
SET LANGUAGE French
SET LANGUAGE иeљtina
SET LANGUAGE ЗС±№ѕо
SET LANGUAGE N'"ъ-{Њк'Работа со строками
Отдельные методы доступа к данным предоставляют свои собственные методы указания языковых настроек вне вызова SET LANGUAGE:
- ADO может передавать понятные поставщику данных ключевые слова в строке ConnectionString;
- OLE DB позволяет задать зависящее от поставщика свойство SSPROP_INIT_CURRENTLANGUAGE;
- ODBC может указать язык в описании источника данных или с помощью ключевого слова LANGUAGE в строке подключения;
- в DB-Library можно использовать dblogin для размещения LOGINREC, а затем DBSETNATLANG для указания необходимых языковых параметров.
Языковые параметры (указанные на уровне сервера, входа или сеанса) влияют на следующие компоненты:
- сообщения;
- дата и время;
- первый день недели;
- обозначение денежной единицы и финансовых величин;
- названия дней и месяцев, аббревиатуры названий месяцев.
Сообщения
SQL Server 2000 и SQL Server 2005 поддерживают использование нескольких вариантов сообщений о системных ошибках и других системных сообщений на разных языках. Эти сообщения хранятся в таблице sysmessages базы данных master. При установке локализованной версии SQL Server эти системные сообщения выводятся на соответствующем языке. По умолчанию также устанавливается набор этих сообщений на английском языке (США). Используйте Set Language для указания языка серверной сессии. По умолчанию сообщения отправляются на языке установленной версии.
Когда сервер SQL Server отправляет сообщение на соединение, он использует локализованное сообщение, если код языка language ID Set соответствует одному из кодов языка в столбце msglangid таблицы sysmessages. Эти коды в десятичном формате отражают идентификатор языкового стандарта (LCID) сообщения. Если в таблице sysmessages нет сообщения с тем же кодом LCID, отправляются сообщения на английском языке (США).
Вы можете добавить определенные пользователем сообщения в таблицу sysmessages, используя параметр @lang системной хранимой процедуры sp_addmessage. Номер ошибки должен быть больше 50000, и вы должны указать параметр @lang как язык или другое название кода LCID для сообщения. Поскольку на сервере могут быть установлены многоязычные системные ошибки и сообщения, значение language указывает язык, на котором должны записываться сообщения в таблицу sysmessages. Когда значения language нет, используется значение языка для серверного сеанса по умолчанию. Определения поддерживаемых языков хранятся в master.dbo.syslanguages.
Если необходимо установить несколько языковых версий sysmessages, дополнительные шаги и требования можно найти на веб-узле справки и поддержки корпорации Майкрософт. Установка различных языковых версий экземпляров SQL Server на один компьютер не поддерживается. Например, на одном и том же компьютере нельзя установить отдельные экземпляры SQL Server 2005 с языками «Немецкий» и «Португальский (Бразилия)».
Примечание. Многие системные таблицы из предыдущих версий SQL Server реализованы в качестве набора представлений SQL Server 2005. Эти представления называются представлениями для совместимости и предназначаются исключительно для обеспечения обратной совместимости. Представления для совместимости содержат те же метаданные, что и сервер SQL Server 2000. Однако в них не содержатся метаданные для новых функций, введенных в SQL Server 2005.
Дата и время
Для каждого языка существует соответствующий краткий формат даты, используемый по умолчанию: мдг, дмг или гмд. Этот формат можно переопределить с помощью команды SET DATEFORMAT («Задать формат даты»). Получение формата даты, используемого по умолчанию, осуществляется посредством хранимой процедуры sp_helplanguage, его значение хранится в столбце dateformat.
Первый день недели
В разных языковых стандартах первые дни недели различны; для тридцати трех языков таблицы syslanguages это 1 (понедельник) или 7 (воскресенье). Первый день недели в данном языковом стандарте можно получить с помощью хранимой процедуры sp_helplanguage, это значение хранится в столбце datefirst.
Валюта и символы валют
Любой столбец типа money или smallmoney может содержать символ валюты. Символ может отличаться от указанного в диалоговом окне Regional Options («Региональные стандарты»), можно выбрать один из символов приведенных в следующей таблице.
|
Символ валюты |
Название символа валюты |
Код символа в Юникоде (шестнадцатеричный) |
|---|---|---|
| $ | Знак доллара (США) | 0024 |
| Ј | Знак фунта (Великобритания) | 00A3 |
| ¤ | Знак валюты (универсальный) | 00A4 |
| Ґ | Знак йены | 00A5 |
| ? | Знак бенгальской рупии | 09F2 |
| ? | Знак бенгальской рупии | 09F3 |
| Я | Знак таиландского бата | 03EF |
| ? | Знак колона | 20A1 |
| ? | Знак крузейро | 20A2 |
| ? | Знак французского франка | 20A3 |
| Ј | Знак лиры | 20A4 |
| ? | Знак найры | 20A6 |
| P | Знак песеты | 20A7 |
| ? | Знак рупии | 20A8 |
| ? | Знак вона | 20A9 |
| ¤ | Знак нового шекеля | 20AA |
| ю | Знак донга | 20AB |
| Ђ | Знак евро | 20AC |
Обратите внимание на различие символов евро (шестнадцатеричный код 20AC) и ?, экю (ECU) (шестнадцатеричный код 20A0). При использовании символа? с типом money возникнет ошибка.
Названия дней и месяцев, сокращенные названия месяцев
Названия дней и месяцев содержатся в таблице syslanguages. Получение этих названий осуществляется посредством хранимой процедуры sp_helplanguage, при этом будут выведены следующие столбцы:
months
Разделенный запятыми список названий месяцев с января по декабрь
shortmonths
Разделенный запятыми список сокращенных названий месяцев с января по декабрь
days
Разделенный запятыми список названий дней недели с понедельника по воскресенье
Устранение влияния языковых настроек COM
Несмотря на то, что SQL Server располагает мощными возможностями для работы с данными типа время, дата и валюта, необходимо учитывать влияние используемых для доступа к серверу служб COM, таких как ADO.
Например, возможны проблемы при распознавании приложениями Visual Basic числа с предшествующим символом валюты из таблицы, приведенной выше, как денежного значения. Служба COM может неправильно использовать значения времени или даты в строках.
Для решения данных проблем необходимо четко осознавать, в каких случаях ваше приложение преобразует строку в данные типа время, дата или валюта. Перед тем как выбрать правила преобразования, необходимо установить, где оно происходит, на стороне клиента или на стороне сервера.
Примером преобразования значений времени, дат и денежных значений является средство Office Access 2000 ADP. Поскольку СУБД Access использует OLE DB, все операции Office Access 2000 подчиняются правилам COM, в которых учитываются региональные параметры клиентского компьютера.
Поставщики данных OLE DB, например поставщик Microsoft OLE DB для SQL Server, правильно преобразуют допустимые значения даты в формате COM в формат и из формата SQL Server. Всегда, когда возможно, следует избегать использования формата даты в строках. В противном случае при смене языкового стандарта у клиента функциональность может быть нарушена.
Службы интеграции SQL Server 2005
Службы интеграции SQL Server 2005 пришли на замену службам трансформации данных (DTS) SQL Server 2000. Службы интеграции предлагают больше возможностей для импорта, экспорта и преобразования многоязыковых данных. Службы интеграции предусматривают синтаксический анализ и обработку многоязыковых данных, поддержку всех языковых стандартов Windows и специальные сравнительные функции для сортировки и сравнения строковых данных.
Региональные настройки в пакетах служб интеграции
Службы интеграции поддерживают языковые стандарты на уровне объекта пакета, контейнера, задачи и компонента потока данных. Кроме того, языковой стандарт можно задать для обработчика событий и некоторых источников и назначений.
Пакет может использовать несколько языковых стандартов. Например, пакет может использовать языковой стандарт английский (США), в то время одна задача пакета использует немецкий (Германия) языковой стандарт, а другая задача - японский (Япония).
В пакетах служб интеграции можно использовать любой языковой стандарт Windows Его можно задать при создании пакета. Если настройки пакета не предусматривают обновления свойств языковых стандартов, пакет гарантированно будет работать так же, как если бы он был запущен на компьютере с региональными и языковыми настройками, отличными от настроек среды разработки.
Задание языкового стандарта
В службах интеграции не используется кодовая страница для определения правил сортировки и распознавания даты, времени и десятичных чисел для каждого языкового стандарта. Вместо этого преобразование считывает свойство LocaleID компонента потока данных, задачи «Поток данных», контейнера или пакета.
По умолчанию языковой стандарт преобразования наследуется из задачи «Поток данных», а он, в свою очередь, наследуется из пакета. Если задача «Поток данных» содержится в контейнере, например контейнере «цикл по элементам», она наследует языковой стандарт от контейнера.
Можно также указать языковой стандарт для диспетчера соединений с плоскими файлами и диспетчера соединений с несколькими плоскими файлами.
С помощью редактора объекта потока данных или объекта потока управления можно изменить кодовую страницу или языковой стандарт объекта. Для объекта пакета необходимо задать такие свойства как LocaleID в окне Свойства.
Рис. 14. Выбор языкового стандарта пакета
Обратите внимание, что свойство CodePage для объекта пакета недоступно, поскольку оно относится только к источникам, назначениям и преобразованиям.
Работа с данными плоских файлов
При работе с данными источника вида «плоский файл» необходимо понимать, как диспетчер соединений с плоскими файлами интерпретирует данные плоского файла. Если кодировка источника «плоский файл» - Юникод, диспетчер соединений с плоскими файлами присваивает данным всех столбцов тип [DT_WSTR] и задает ширину столбцов по умолчанию равную 50. Если кодировка источника «плоский файл» - ANSI, диспетчер соединений с плоскими файлами присваивает данным всех столбцов тип [DT_STR] и задает ширину столбцов равную 50. Вам, вероятно, необходимо будет изменить эти настройки в соответствии с данными, которые вы собираетесь использовать. Для этого определите тип данных назначения, куда будут записываться данные, а затем выберите соответствующий тип данных в диспетчере соединений с плоскими файлами.
Следует иметь в виду, что при импорте данных из плоского файла или экспорте в плоский файл некоторые свойства пакета, соединение и задачи преобразования данных выбираются автоматически, на основе настроек языкового стандарта. Эти настройки можно легко изменить. Кроме того, такое изменение может потребоваться, если настройки языкового стандарта могут повлиять на обработку данных. Если языковой стандарт источника и назначения плоского файла оставить без изменений, могут последовать непредвиденные результаты.
В руководстве служб интеграции, прилагавшемуся к SQL Server 2005, имеется пример импорта данных из плоского файла. Файл содержит столбец BirthDate в одном из используемых по умолчанию форматов языкового стандарта EN-US. Если открыть этот пример на компьютере с другим языковым стандартом, пакет, импортирующий данные, может не запуститься из-за невозможности синтаксического анализа данных. Для того чтобы исправить ситуацию, достаточно изменить языковой стандарт самого пакета, объектов потока данных и соответствующих источников и назначений.
Рис. 15. Выбор языкового стандарта пакета и кодовой страницы плоского файла
Синтаксический анализ текстовых данных
При загрузке текста из плоского файла службы интеграции проводят его синтаксический анализ. При этом используется один из двух готовых наборов процедур синтаксического анализа, быстрый или стандартный анализ.
Быстрый анализ - это упрощенный и более скоростной набор процедур, поддерживающий только наиболее распространенные форматы времени и даты. Не производится синтаксический анализ на основе выбранного языкового стандарта, не распознаются специальные символы в денежном формате и не преобразуются шестнадцатеричный и инженерный формат целых чисел.
Стандартный анализ - это богатый набор процедур, поддерживающих все преобразования типов данных, предусмотренные в прикладных программных интерфейсах автоматизации преобразования данных, доступных в Oleaut32.dll и Ole2dsip.dll.
При создании потока данных можно выбрать метод синтаксического анализа столбцов результатов преобразования: более скоростной, но не учитывающий языковые стандарты, или же стандартный набор процедур с учетом языковых стандартов.
Если требуется синтаксический анализ потока данных в пакете с у четом языковых стандарта, то стандартный анализ предпочтительнее. В частности, при быстром анализе не распознаются форматы языковых стандартов, содержащие разделители целой и дробной части (например, запятую), форматы даты, отличные от год-месяц-число и символы валют.
Быстрый анализ указывается на уровне столбцов. В источнике «плоский файл» и в редакторе преобразования «конвертация данных» можно выбрать быстрый анализ для столбцов с результатами. На входе и на выходе могут содержаться столбцы, обрабатываемые как с учетом, так и без учета языковых стандартов, однако быстрый анализ доступен только с помощью источника «плоский файл» и редактора преобразования «конвертация данных».
Сравнение
Языковой стандарт предусматривает основные правила сравнения строковых данных в потоке. Например, в языковом формате задано расположение каждой буквы при сортировки по алфавиту. Но этих правил может оказаться недостаточно. Службы интеграции предлагают набор расширенных функций сравнения. Например, если выбрать функцию «не учитывать непробельные символы», при сравнении символы «a» и «б» будут эквивалентны.
Сравнение строк - неотъемлемая часть множества преобразований, выполняемых службами интеграции. Сравнение строк также применяется при оценке выражений, содержащихся в переменных, и выражений свойств. Например:
- при преобразовании "условное разбиение" производится сравнение строк в выражениях для определения выхода, на который посылается строка данных;
- при преобразовании «производный столбец» производится сравнение строк в выражениях для создания новых значений столбцов;
- с помощью преобразований «сортировка», «статистическая обработка», «нечеткое группирование» и «нечеткий уточняющий запрос» можно настроить метод сравнения строк на уровне столбцов. При поиске можно игнорировать регистр, но различать диакритические и недиакритические знаки.
В зависимости от типа данных и настроек преобразования в процессе сравнения могут произойти следующие изменения данных:
- преобразование строковых данных в кодировку Юникод. Если данные источника представлены в другой кодировке, перед сравнением они преобразуются в Юникод;
- применение правил определенного языкового стандарта для интерпретации даты, времени и десятичных чисел и порядка сортировки;
- применение настроек сравнения на уровне столбцов с целью изменения учитываемых параметров при сравнении.
Изменение настроек сравнения
Службы интеграции предусматривают набор функций расширенного сравнения, которые применяются на уровне столбца. Например, имеется если выбрать функцию «не учитывать непробельные символы», при сравнении буквы «a» и «б» с разными диакритическими символами будут эквивалентны.
Для преобразований «сортировка», «статистическая обработка», «нечеткое группирование» и «нечеткий уточняющий запрос» можно выбрать следующие настройки:
- не учитывать регистр;
- не учитывать тип японской азбуки;
- не учитывать ширину символов;
- не учитывать непробельные символы;
- не учитывать символы;
- сортировать знаки препинания как символы.
В преобразованиях «нечеткое группирование» и «нечеткий уточняющий запрос» имеется также функция FullySensitive («Учитывать все»). Этот флаг, доступный только в расширенном редакторе, означает, что применяются все настройки сравнения.
Источники и назначения данных
В большинстве случаев службы интеграции правильно определяют кодовую страницу источника данных. В случае неправильного определения кодовой страницы или в случае доступа пакета к источнику посредством поставщика, который не предоставляет необходимых сведений о кодовой странице, можно указать кодовую страницу, используемую по умолчанию, в источнике и в назначении OLE DB. Такие кодовые страницы используются вместо страниц, предоставляемых службами интеграции.
У файлов нет кодовых страниц. Вместо этого в диспетчере соединений с плоскими файлами и диспетчере соединений с несколькими плоскими файлами, которые используются для подключения пакета к данным файла, имеется свойство, указывающее кодовую страницу для файла. Кодовая страница устанавливается только на уровне файлов (не на уровне столбцов).
В зависимости от операций и настроек преобразования строковые данные могут быть конвертированы в тип DT_WSTR, представление строк в кодировке Юникод.
Строки с данными типа DT_STR преобразуются в кодировку Юникод посредством кодовой страницы столбца. Службы интеграции поддерживают кодовые страницы, применяемые на уровне столбца, при этом разным столбцам могут соответствовать разные кодовые страницы, посредством которых происходит преобразование.
Явное преобразование строковых данных в кодировку Юникод
Входящие в пакеты потоки данных извлекают и загружают данные. Потоки данных могут осуществлять доступ к данным, находящимся в гетерогенных хранилищах, в которых может использоваться множество стандартных и пользовательских типов данных. В пределах потока данных действия по извлечению данных, выполнению синтаксического анализа строковых данных и преобразованию данных в тип данных служб интеграции Integration Services выполняются источниками служб Integration Services. С помощью последовательных преобразований можно выполнить синтаксический анализ данных, чтобы преобразовать их в другой тип данных или создать копии столбцов, содержащих различные типы данных. Используемые в компонентах выражения могут также приводить аргументы и операнды к различным типам данных. И, наконец, когда данные загружаются в хранилище, место назначения может выполнять синтаксический анализ данных для их преобразования в тот тип, который используется этим конечным хранилищем.
Когда данные поступают во входящий в пакет поток данных, источник, извлекающий их, преобразует эти данные в тип данных служб Integration Services. Числовым данным присваивается числовой тип, строковым данным присваивается символьный тип, а датам присваивается тип «дата». Остальным данным, например идентификаторам GUID и блокам данных BLOB (binary large object block - большой двоичный объект), также присваиваются соответствующие типы данных служб Integration Services. Если данные имеют тип, который невозможно преобразовать в тип данных служб Integration Services, то возникает ошибка.
Преобразование Data Conversion (преобразование данных) позволяет управлять процедурой преобразования, чтобы явным образом изменять код страниц, формат или преобразовывать данные входного столбца в другой тип данных. К одному входному столбцу можно применить несколько преобразований. Преобразованные данные могут заместить исходные данные, или их можно скопировать в новый выходной столбец, чтобы потом использовать в компонентах следующего уровня.
Например, пакет может извлекать данные из источников на разных языках и затем использовать это преобразование для приведения столбцов к типу данных, который требуется для конечного хранилища.
Используя преобразование Data Conversion (преобразование данных), можно выполнять следующие виды преобразования данных:
- изменять тип данных;
- устанавливать длину столбца строковых данных или точность и масштаб числовых данных;
- определять кодовую страницу.
Преобразование Character Map (таблица символов) является еще одним компонентом, который полезен для выполнения преобразований символьных данных. Это преобразование применяет строковые функции, например преобразование символов верхнего регистра в символы нижнего регистра, к данным строкового типа.
Преобразование Character Map (таблица символов) позволяет преобразовывать данные столбца на месте или добавлять столбец к результатам преобразования и помещать преобразованные данные в этот новый столбец. К одному входному столбцу можно применять различные совокупности операций отображения и помещать результаты в различные столбцы. Например, можно преобразовать все символы данных в одном столбце в символы верхнего регистра, поместив их в другой столбец, и в символы нижнего, поместив результаты в третий столбец.
Преобразование Character Map (таблица символов) поддерживает следующие операции отображения:
|
Операция |
Описание |
|---|---|
| Byte reversal (обратный порядок байтов) | Меняет порядок байтов на обратный |
| Full width (полная ширина) | Отображает полуширинные символы в полноширинные |
| Half width (половинная ширина) | Отображает полноширинные символы в полуширинные |
| Hiragana (хирагана) | Отображает символы катакана в символы хирагана |
| Katakana (катакана) | Отображает символы хирагана в символы катакана |
| Linguistic casing (смена регистра по правилам языка) | Применяет смену регистра по правилам языка, а не по правилам системы. Смена регистра по правилам языка - это функциональная возможность, обеспечиваемая интерфейсом Win32 API для простого отображения регистра для кодировки Юникод применительно к тюркскому и другим языковым стандартам |
| Lowercase (все строчные) | Преобразует символы в строчные |
| Simplified Chinese (китайский - упрощенное письмо) | Отображает китайские символы (традиционное письмо) в китайские символы (упрощенное письмо) |
| Traditional Chinese (китайский - традиционное письмо) | Отображает китайские символы (упрощенное письмо) в китайские символы (традиционное письмо) |
| Uppercase (все прописные) | Преобразует символы в прописные |
В ходе преобразования может выполняться несколько операций. Однако некоторые операции отображения являются взаимоисключающими. В большинстве случаев эти исключения продиктованы здравым смыслом, например, нельзя отображать символы катакана в символы хирагана одновременно с отображением символов хирагана в символы катакана.
Примечание. В некоторых случаях выполнение отображения может приводить к усечению данных. Например, усечение может происходить при отображении однобайтовых символов в символы, имеющие многобайтовое представление. При осуществлении преобразований данных для отслеживания изменений используйте средства просмотра данных, а для направления усеченных и ошибочных данных в отдельный выход используйте выходы ошибок.
Поддержка в службах SSIS дополнительных символов
Службы Integration Services обрабатывают суррогатные пары прозрачно. Т.е., если источник данных, место назначения данных или преобразование не изменяют размер строки, то символы в виде суррогатных пар должны обрабатываться так же, как и любые другие символы Юникода. Функции и возможности, возвращающие размер строки, должны обрабатывать символы в виде суррогатных пар как два отдельных, неопределенных символа Юникода. Такие операции выполняются строковыми функциями LEN и SUBSTRING.
Для отображения дополнительных символов пользователь должен настроить среду Business Intelligence Development Studio на использование шрифта, поддерживающего расширения для этих символов. Однако из-за того что дополнительные символы поддерживаются приложением SQL Server только в качестве данных, а не метаданных, потребность отображения этих символов ограничивается предварительным просмотром данных, предложениями WHERE запросов и т.д.
Динамическое изменение языкового стандарта с помощью настроек
Если при развертывании на различных серверах пакет должен использовать различные языковые стандарты, то можно создать настройки, которые обеспечивают использование при выполнении пакета обновленных языковых стандартов.
Настройки - это пары атрибут-значение, которые позволяют устанавливать свойства и переменные времени выполнения извне пределов среды разработки. Используя при разработке настройки, можно создавать пакеты, развертывание и распространение которых будет гибким и простым процессом. Службы Integration Services предоставляют следующие типы настроек:
- XML-файл настроек;
- переменная среды;
- запись реестра;
- переменная родительского пакета;
- таблица сервера SQL Server.
Для обеспечения дополнительной гибкости службы Integration Services поддерживают использование косвенных настроек. Это означает, что можно использовать переменную среды для определения местонахождения настройки, которая в свою очередь определяет фактические значения.
XML-файл настроек может включать настройки различных свойств, и при некоторых условиях в нем могут храниться настройки для нескольких пакетов.
Недавно было выпущено несколько новых учебных руководств по службам Integration Services, в которых подробно описан процесс создания и тестирования настроек, а затем построения служебной программы развертывания, которая позволит создавать новые пакеты, содержащие динамические настройки. Рекомендуется попробовать использовать эти учебные руководства для изучения процесса динамического обновления кодовых страниц, параметров преобразования или других международных параметров с помощью настроек и последующего развертывания пакетов.
Учебное руководство по созданию простого пакета ETL
В документе Учебное руководство по созданию простого пакета ETL рассматриваются следующие вопросы
- Создание простого пакета служб Integration Services и затем добавление циклического выполнения.
- Описание мастера настроек пакетов и формата XML-настроек.
- Создание настройки пакета, выполняющей изменение каталога, который содержит текстовые файлы, требующие циклической обработки.
- Тестирование настройки путем изменения значения переменной извне пределов среды разработки и направления измененного свойства на новую папку с данными, используемую в качестве примера. При повторном запуске пакета файл настроек обновляет каталог, содержащий файлы.
Учебное руководство по развертыванию пакетов
Документ Учебное руководство по развертыванию пакетов полезен для изучения следующих вопросов.
- Применение сочетания XML-файлов настроек и косвенных настроек для обновления строк подключения к файлам журналов регистрации, тестовым файлам и местам размещения XML-файлов и XSD-файлов, используемых пакетом во время выполнения.
- Создание комплекта развертывания, предназначенного для установки пакетов. Комплект развертывания состоит из файлов пакетов и других элементов, которые были добавлены в проект служб Integration Services, взаимосвязанных с пакетами элементов, которые добавляются службами Integration Services автоматически, и созданной служебной программы развертывания.
- Запуск мастера установки пакетов для установки пакетов и взаимосвязанных с пакетами элементов. Пакеты будут установлены в базу данных msdb приложения SQL Server, а вспомогательные файлы будут размещены в файловой системе.
- Обновление настройки для использования новых значений, позволяющих осуществлять успешное выполнение пакетов в новой среде.
Использование служебных программ командной строки с разноязычными данными
В этом разделе приводится информация о некоторых служебных программах командной строки, поставляемых с приложением SQL Server 2005. Служебная программа bcp была обновлена и теперь включает функции, полезные в случаях наличия разноязычных данных, а также поддержку XML-форматов. Служебная программа sqlcmd является новым средством, упрощающим процесс написания сценариев и позволяющим управлять кодовой страницей файлов сценариев.
bcp
В случаях необходимости импортировать или экспортировать данные с использованием конкретной кодовой страницы можно продолжать использовать служебную программу bcp. Служебная программа bcp выполняет массовое копирование данных между экземпляром сервера Microsoft SQL Server и файлом данных в указанном пользователем формате.
В приложении SQL Server 2005 служебная программа bcp заставляет выполнять новые проверки и контроль данных, что может приводить к ошибкам при выполнении существующих сценариев, если они будут выполняться для недопустимых данных, содержащихся в файлах. Например, теперь программа bcp проверяет:
- является ли исходное представление типов данных float или real допустимым;
- равна ли длина данных в кодировке Юникод четному числу байтов.
Примечание. Формы недопустимых данных, которые можно было массово импортировать в предыдущих версиях приложения SQL Server, теперь могут не загружаться. В предыдущих версиях ошибка происходила после того, как клиент пытался осуществить доступ к недопустимым данным. Причина добавления этой проверки заключается в том, что проверка данных до загрузки сокращает число непредсказуемых результатов при запросе данных после выполнения массовой загрузки.
Служебная программа bcp поддерживает следующие флаги, предназначенные для преобразования данных без потерь.
|
Флаг |
Назначение |
Пояснение и примечания |
|---|---|---|
| -C xxx | Определитель кодовой страницы | xxx может указывать кодовую страницу или значение ANSI, OEM или RAW. Этот параметр поддерживается для обеспечения совместимости с более ранними версиями приложения SQL Server. Для приложения SQL Server 7.0 и более поздних версий. Корпорация Майкрософт рекомендует указывать в файле формата название параметров сортировки для каждого столбца. ANSI: Microsoft Windows (ISO 1252).OEM: используемая клиентом кодовая страница по умолчанию. Это кодовая страница, используемая по умолчанию, если параметр -C не определен.RAW: преобразования одной кодовой страницы в другую не происходит. Это самый быстродействующий параметр.code_page: используется только в том случае, если данные содержат столбцы типов char, varchar или text, значения символов в которых больше 127 или меньше 32 |
| -N | Использовать исходный формат кодировки Юникод | Приводит к использованию исходных типов данных (типов базы данных) для всех данных, не являющихся символьными, и формата символов кодировки Юникод для всех символьных данных. Этот параметр является обеспечивающей более высокое быстродействие альтернативой параметра -w и предназначен для передачи данных от одного экземпляра сервера SQL Server другому с использованием файла данных. Этот параметр не приводит к выдаче запроса для каждого поля. Его следует использовать при передаче данных, содержащих расширенные символы стандарта ANSI, и желании воспользоваться преимуществами высокой производительности собственного режима. Нельзя использовать с приложением SQL Server 6.5 или более ранними версиями |
| -w | Использовать формат символов кодировки Юникод | Этот параметр обеспечивает использование в качестве формата данных символы кодировки Юникод для всех столбцов. Этот параметр не приводит к выдаче запроса для каждого поля. В качестве типа для хранения данных используется nchar, префиксы не используются, в качестве разделителя полей используется \t (символ табуляции), а в качестве конца строки используется \n (символ перехода на новую строку). Нельзя использовать с приложением SQL Server 6.5 или более ранними версиями |
Также существует возможность использования файлов формата и определения параметров сортировки на уровне столбцов. Если параметры -C, -N или -w не определены, то перед выполнением импортирования или экспортирования программа bcp запросит информацию о параметрах сортировки и кодовой странице для каждого столбца. Затем будет предложено сохранить эту информацию в файле формата, пример которого приведен ниже.
9.0 9 1 SQLCHAR 0 11 ""1 au_id Latin1_General_CI_AI 2 SQLCHAR 0 40 "" 2 au_lname Latin1_General_CI_AI 3 SQLCHAR 0 20 "" 3 au_fname Latin1_General_CI_AI 4 SQLCHAR 0 12 "" 4 phone Latin1_General_CI_AI 5 SQLCHAR 0 40 "" 5 address Latin1_General_CI_AI 6 SQLCHAR 0 20 "" 6 city Latin1_General_CI_AI 7 SQLCHAR 0 2 "" 7 state Latin1_General_CI_AI 8 SQLCHAR 0 5 "" 8 zip Latin1_General_CI_AI 9 SQLBIT 0 1 "" 9 contract ""
В приложении SQL Server 2005 впервые для служебной программы bcp используются XML-файлы формата. XML-файлы формата обладают множеством преимуществ. Они содержат описание соответствующих столбцов таблицы, а также типы данных для конечных столбцов. XML-файлы легко читать, создавать и расширять. XML-файл формата можно создать с помощью служебной программы bcp. Для этого используется параметр -x. После того как файл формата создан, его можно использовать для импортирования или экспортирования данных с помощью программы bcp с параметром -f.
В приведенной ниже таблице перечислены типы данных, которые могут быть импортированы или экспортированы с помощью служебной программы bcp. Параметрами сортировки являются определенные для столбца по умолчанию правила, которые могут быть унаследованы от базы данных или сервера.
|
Тип |
Полное название |
|---|---|
| C | char |
| T | text |
| I | int |
| S | smallint |
| T | tinyint |
| F | float |
| M | money |
| B | bit |
| D | datetime |
| X | binary |
| I | image |
| D | smalldatetime |
| r | real |
| M | smallmoney |
| n | numeric |
| E | decimal |
| W | nchar |
| W | ntext |
| U | uniqueidentifier |
Обратите внимание, что типы данных varchar и nvarchar в эту таблицу не включены. Для служебной программы bcp вместо них должны использоваться типы char и nchar соответственно.
И, наконец, служебная программа bcp поддерживает параметр -R, означающий «включить региональные настройки». Он действует так же, как и параметр Использовать региональную настройку ODBC, который влияет на интерпретацию данных о датах и времени, числах и денежных единицах, которые хранятся в нетекстовых полях.
Программа sqlcmd
Служебная программа sqlcmd является новой для приложения SQL Server 2005 и обеспечивает функциональные возможности, которые ранее были доступны при совместном использовании служебных программ osql и isql, пакетных файлов и языка VBScript. Для выполнения пакетов инструкций языка Transact-SQL она использует OLE DB.
Используя эту программу, можно запускать оперативные запросы из окна командной строки, а также выполнять сценарии, содержащие инструкции языка Transact-SQL или системные процедуры. Можно создавать файлы сценариев и затем запускать эти сценарии из командной строки, в работающем в режиме SQLCMD редакторе запросов Query Editor, в файле сценария системы Windows или в шаге задания операционной системы (Cmd.exe), являющемся частью задания агента SQL Server Agent.
Для указания кодовой страницы входных данных и кодовой страницы выходных данных можно воспользоваться параметром -f.
Номер кодовой страницы должен быть числовым значением, определяющим кодовую страницу установленной операционной системы Windows. Если кодовые страницы не указаны, то служебная программа sqlcmd использует кодовую страницу текущей системы как для входных файлов, так и для выходных. Однако можно использовать параметр -u, чтобы указать, что выходной файл должен сохраняться в формате кодировки Юникод независимо от формата входного файла.
Этот синтаксис показан в приведенных ниже примерах. Файл сценария MyScript.sql содержит следующий запрос:
'USE AdventureWorks; GO; SELECT * FROM Production.vProductAndDescription; ORDER BY CultureID;'
В первом примере этот запрос запускается и выходные данные сохраняются в файл в кодировке Юникод. Во втором примере выполняется этот же запрос, но выходной файл сохраняется в формате кодовой страницы, имеющей идентификатор 950. Если данная кодовая страница недоступна, то может произойти ошибка.
sqlcmd -i C:\Temp\MyScript.sql -o C:\temp3\MyOutput1.txt -u sqlcmd -i C:\ Temp\MyScript.sql -f1252 -o C:\temp3\MyOutput2.txt -f950
Служебная программа sqlcmd автоматически распознает входные файлы в кодировке Юникод как с обратным (Big Endian), так и с прямым (Little Endian) порядком байтов. Если был указан параметр -u, то выходные данные всегда будут в кодировке Юникод с прямым порядком байтов (Little Endian).
Предполагается, что при наличии нескольких входных файлов они все имеют одинаковую кодовую страницу. Возможно одновременное использование входных файлов в кодировке Юникод и не в кодировке Юникод.
Сценарии программы sqlcmd можно создавать и редактировать с помощью редактора запросов Query Editor среды SQL Server Management Studio (SSMS). Однако в среде SSMS для исполнения используется Microsoft .NET SqlClient, а программа sqlcmd при запуске сценариев из командной строки использует поставщик OLE DB. Следовательно, при выполнении одинакового запроса в среде SQL Server Management Studio, работающей в режиме SQLCMD, и в служебной программе sqlcmd возможны различные результаты.
Международные параметры в службах SQL Server Analysis Services
Службы Microsoft SQL Server 2005 Analysis Services поддерживают всех языки, поддерживаемые операционными системами Microsoft Windows. Для указания выбранного для экземпляров и объектов служб Analysis Services языка этими службами используются идентификаторы языка операционной системы Windows. Идентификатор языка операционной системы Windows соответствует паре идентификаторов основного языка и разновидности языка системы Windows. Например, если при установке выбрать язык «Английский (США)», то в элементе Language файла настроек для экземпляра служб Analysis Services будет указан соответствующий идентификатор языка операционной системы Windows 0x0409 (или 1033).
Перевод
Кроме указания используемого по умолчанию языка и параметров сортировки, которые применяются экземпляром служб Analysis Services, также можно обеспечить для отдельных объектов служб Analysis Services, включая кубы, группы показателей, измерения, иерархии и атрибуты, многоязычную поддержку, определив связанный с объектом служб Analysis Services перевод.
Для определения перевода типов подписей, описаний и учетных записей базы данных служб Analysis Services можно воспользоваться средой Business Intelligence Development Studio. При использовании перевода клиентские приложения могут получать объекты служб Analysis Services на различных языках и с различным параметрами сортировки.
Используемые по умолчанию язык и параметры сортировки экземпляра служб Analysis Services определяют настройки, которые применяются к данным и метаданным в том случае, если для какого-либо объекта служб Analysis Services не предоставлен перевод для определенного идентификатора языка или если при подключении к экземпляру служб Analysis Services клиентское приложение не указывает идентификатор языка.
Обратите внимание, что хотя перевод содержит отображаемую информацию для имен объектов служб Analysis Services, идентификаторы не переводятся. Для обеспечения переносимости между системами с разными языками для объектов служб Analysis Services следует использовать идентификаторы и параметры, а не переведенные подписи и имена. Например, в инструкциях и сценариях многомерных выражений (MDX) следует использовать ключи элементов, а не их имена.
Если клиентское приложение запрашивает информацию для определенного идентификатора языка, то экземпляр служб Analysis Services пытается разрешить для объектов Analysis Services данные и метаданные, предоставив соответствующие наиболее близкому идентификатору языка. Если клиентское приложение не определяет язык по умолчанию или задает нейтральный идентификатор языка (0) либо идентификатор языка процесса по умолчанию (1024), то службы Analysis Services, чтобы вернуть данные и метаданные для объектов служб Analysis Services, используют язык по умолчанию для экземпляра.
Если клиентское приложение задает идентификатор языка, отличающийся от идентификатора языка по умолчанию, то экземпляр последовательно рассматривает все доступные переводы для всех доступных объектов. Если указанный идентификатор языка соответствует идентификатору языка перевода, службы Analysis Services возвращают этот перевод. Если соответствие не найдено, службы Analysis Services пытаются использовать один из следующих методов, чтобы вернуть перевод с идентификатором языка, ближайшим к указанному.
Для следующих идентификаторов языка службы Analysis Services пытаются использовать альтернативный идентификатор языка, если перевод для указанного идентификатора языка не определен.
Указанный идентификатор языка Альтернативный идентификатор языка
Параметры сортировки в службах Analysis Services
Для указания выбранных для экземпляров и объектов служб Analysis Services параметров сортировки этими службами используются параметры сортировки Windows. При указании параметров сортировки Windows для служб Analysis Services, экземпляр Analysis Services использует те же кодовые страницы, а также правила сортировки и сравнения, что и работающее на компьютере приложение, для которого вы указали соответствующий региональный стандарт Windows. Например, параметры сортировки Windows French для Analysis Services соответствуют свойствам параметров сортировки французского языка для Windows.
Число языковых стандартов Windows больше количества параметров сортировки Windows, определенных для служб Analysis Services. Название языкового стандарта Windows использует идентификатор основного языка, например English (английский язык), и идентификатор разновидности языка, например United States (США) или Australia (Австралия). Однако многие языки используют одинаковые алфавиты и правила сортировки и сравнения символов.
Например, 33 языковых стандарта Windows, включая языковые стандарты португальского и английского языков, используют кодовую страницу Latin1 (1252) и следуют единому набору правил сортировки и сравнения символов. Параметры сортировки Windows Latin1_General сервера SQL Server, использующие эту кодовую страницу и соответствующие правила сортировки, поддерживают все эти 33 языковых стандарта . Кроме того, языковые стандарты содержат атрибуты, не входящие в параметры сортировки Windows в Analysis Services, например, форматы отображения валют, дат и времени. Поскольку отдельные страны и регионы, например Австралия и США, имеют разные форматы валюты, даты и времени, для них необходимо использовать различные параметры сортировки Windows. Однако, поскольку они используют один и тот же алфавит и правила сортировки и сравнения символов, для них не нужно применять различные параметры сортировки Windows в Analysis Services.
Хотя для объектов служб Analysis Services можно указать несколько идентификаторов языка, все эти объекты, за одним исключением, независимо от идентификатора языка используют одни и те же параметры сортировки Windows Analysis Services. Это исключение - свойство CaptionColumn атрибута измерения базы данных, которому можно назначить параметры сортировки Analysis Services Windows для сортировки членов указанного атрибута.
Порядок сортировки в службах Analysis Services
Если все пользователи данного экземпляра служб Analysis Services используют один язык, следует выбрать параметры сортировки, поддерживающие указанный по умолчанию язык этого экземпляра. Если используется несколько языков, следует указать параметры сортировки, которые лучше всего поддерживают несколько языков. Например, если пользователи текущего экземпляра обычно говорят на языках стран Западной Европы, выберите параметры сортировки Latin1_General.
Выбранные параметры сортировки Windows Analysis Services могут использовать несколько различных порядков сортировки, чтобы более точно определять правила сортировки и сравнения в зависимости от чувствительности к регистру, диакритических знакам, типу каны и ширине символов. Такие же настройки порядка сортировки используются в ядре SQL Server: можно так же задать чувствительность к регистру, ширине, диакритике и типу каны.
Если в качестве принятого по умолчанию языка для экземпляра Analysis Services используется идентификатор языка «Английский (США)» (0x0409, он же 1033), можно получить дополнительный выигрыш в производительности, установив свойство конфигурации EnableFast1033Locale. Это дополнительное свойство доступно только для этого идентификатора языка. Установка для него значения true позволяет службам Analysis Services использовать более быстрый алгоритм хеширования и сравнения строк.
Примечание. Возможность использования разных параметров сортировки в различных частях иерархических структур данных, из которых состоит хранилище данных, не поддерживается. Хотя обычно эта возможность не используется при анализе данных, в некоторых случаях, например при создании разделов данных, соответствующих алфавитам, она может быть полезна. В этих случаях при разделении данных необходимо использовать другой способ, позволяющий в явном виде определять упорядочивание и создание разделов и избегать использования алфавитного порядка. Это также помогло бы при отображении иерархических данных. Если требуется подобная функциональность, следует сортировать часть данных, полученных из источника OLAP.
Поддержка нескольких валют
Службы Analysis Services предоставляют поддержку для преобразования валют в кубах OLAP, содержащих несколько валют. Прежде чем задать преобразование валют в кубе, необходимо определить не менее одного измерения в валюте, не менее одного измерения во времени и не менее одной группы мер курсов . Из этих объектов мастер бизнес-аналитики может получать данные и метаданные, используемые для создания отчета о валютных измерениях и написания MDX-сценария, реализующего преобразование валют.
Прежде чем реализовать преобразование валют, необходимо определить следующее:
|
Термин |
Определение |
|---|---|
| Основная валюта | Валюта, по отношению к которой обменные курсы вводятся в группу меру курсов. |
| Местная валюта | Валюта, используемая для хранения транзакций, на которых основаны меры, подлежащие конвертации.
Местную валюту можно определить по одному из следующих признаков:
|
| Валюта отчета | Валюта, в которую транзакции конвертируются из основной валюты. |
| Направление обменного курса | Указывает, к чему применяется множитель: к основной валюте или валюте образца. Комбинация направления обменного курса и типа преобразования валют определяет, какая операция должна выполняться с конвертируемыми показателями. |
| Конвертированные члены | Результат преобразования валют. |
| Тип конвертации |
Указывает, как хранятся транзакции и сколько валют используется при преобразовании.
|
После этого можно использовать мастер бизнес-аналитики для создания MDX-сценария, использующего комбинацию данных и метаданных из измерений, атрибутов и групп показателей для преобразования денежных данных.
Работа со значениями даты и времени в службах SSAS
При выполнении сравнений и операций с месяцами и днями недели рекомендуется использовать числовой формат даты и времени вместо строкового. Строки, содержащие дату или время, частично определяются с помощью идентификатора языка, указанного для данного экземпляра, и текущего перевода строк, предоставленного эти экземпляром для членов измерения времени.
Для работы с измерениями времени рекомендуется использовать различные функции времени и даты многомерных выражений. Кроме того, для возврата даты и времени в числовом формате вместо строк имени удобны функции даты и времени языка Visual Basic for Applications (VBA). Для клиентских приложений при возврате результатов, которые будут выведены пользователю, используйте литеральные строки с разделами даты и времени поскольку обычно строки более понятны, чем представление в цифровой форме. В то же время не следует писать код, чья логика зависит от особенностей отображения на конкретном языке.
Поддержка XML в SQL Server 2005
В SQL Server 2005 используется SQLXML 4.0, предоставляющая те же функциональные возможности, что и версия 3.0, а также дополнительные обновления для поддержки новых функций, введенных в Microsoft SQL Server 2005.
SQL Server 2005 поддерживает тип данных xml, позволяющий хранить документы и фрагменты XML в базе данных SQL Server. Фрагмент XML - это экземпляр типа XML, не содержащий обязательный элемент верхнего уровня. Можно создавать столбцы и переменные типа xml и хранить в них экземпляры XML, размеры которых не превышают 2 ГБ. Этот тип и связанные с ним методы облегчают интеграцию XML в реляционную инфраструктуру SQL Server.
XML и Юникод
Тип данных SQL Server 2005 xml реализует тип данных xml стандарта ISO SQL-2003 . Поэтому в нем можно хранить правильно сформированные документы XML версии 1.0, а также так называемые фрагменты содержимого XML с текстовыми узлами. Система проверяет, чтобы данные были правильно сформированы, не требуя привязки столбца к схемам XML, и отклоняет данные, если они сформированы неправильно.
В SQL Server 2005 можно создать XML различными способами: преобразованием из строкового типа, инструкцией SELECT с предложением FOR XML, массовой загрузкой или с помощью строковой константе.
Документы XML можно закодировать с помощью различных кодировок, например UTF-8, UTF-16 или Latin-1252. Указать кодировку в XML можно разными способами:
- преобразуя данные в формат XML в объекте ADO Stream с последующим сохранением, можно указать выходную кодировку, информация о которой тогда появится в XML;
- указав ее в URL;
- с помощью шаблонов XML.
Даже если не использовать ни один из этих методов, по умолчанию будет корректно поддерживаться кодировка Юникод.
Примечание. Тип данных xml в SQL Server 2005 обрабатывает пробелы иначе, чем это описано в спецификации XML 1.0. В SQL Server пробельный символ внутри содержимого элемента считается несущественным, если он появляется в последовательности, состоящей только из пробельных символов, ограниченной символом разметки (открывающими или закрывающими тегами) и не создающей сущности. (Разделы CDATA пропускаются.) Это связано с тем, что синтаксический анализатор XML в SQL Server распознает только ограниченное число подмножеств DTD, как это определено в XML 1.0.
Updategram
В базе данных Microsoft SQL Server 2005 можно изменять (вставлять, обновлять или удалять) данные из существующего документа XML с помощью updategram или функции OPENXML Transact-SQL. Updategram поддерживает многоязычные тексты и позволяет задавать кодировку.
Функция OPENXML разбирает существующий документ XML на составляющие и предоставляет набор строк, пригодный для передачи его инструкциям INSERT, UPDATE или DELETE, которые и вносят изменения в базу. С помощью этой функции операции выполняются непосредственно на таблицах базы данных Поэтому она больше всего подходит в тех случаях, когда в качестве входных данных используется набор строк, например таблица.
Updategram, как и OPENXML, позволяет вставлять, обновлять или удалять данные в базе данных. Однако она работает с представлениями XML, полученных от аннотированной XSD- или XDR-схемы. Пусть, например, обновляется представление XML, полученное от схемы сопоставления. Схема сопоставления, в свою очередь, содержит необходимые сведения для сопоставления элементов и атрибутов XML соответствующим таблицам и столбцам базы данных. Updategram использует эту информацию для обновления таблиц и столбцов базы данных.
Доступ к данным для XML-клиентов
Для использования SQLXML 4.0 необходимо также иметь собственный клиент Microsoft SQL и MDAC версии 2.6 или более поздней. Для развертывания приложения, зависящее от собственного клиента SQL, необходимо распространить клиент с ним. В отличие от компонентов доступа к данным (MDAC), которые стали частью операционной системы, собственный клиент SQL - часть SQL Server 2005. Поэтому его необходимо устанавливать на компьютерах разработчиков и распространять с приложением.
В предыдущих версиях SQLXML обработка запросов, основанных на HTTP, поддерживалась с помощью виртуальных каталогов SQLXML IIS и фильтра SQLXML ISAPI. В версии 4.0 SQLXML эти компоненты удалены, поскольку в SQL Server 2005 собственные веб-службы ч поддержкой XML предоставляют сходную, перекрывающуюся с ними функциональность. Если решение полагается на усовершенствованные возможности SQL Server 2005 в области типов данных, например на тип xml или определяемые пользователем типов (UDT), а также на веб-доступ, необходимо перейти на управляемые классы SQLXML или другой тип обработчика HTTP, как, например, собственные веб-службы с поддержкой XML SQL Server 2005.
Если эти нововведения SQL Server 2005 в области типов использовать не требуется, для доступа можно продолжать применять SQLXML 3.0. Поддержка SQLXML 3.0 в ISAPI позволит соединяться с SQL Server 2005, но тип данных xml, а также определяемые пользователем типы поддерживаться и распознаваться не будут.
Усовершенствования полнотекстового поиска
Полнотекстовый поиск SQL Server 2005 включают в себя обновление службы Microsoft Search (MSSearch) до версии 3.0. В число усовершенствований входят:
- значительно повышенная производительность заполнения полнотекстового индекса;
- наличие отдельного экземпляр MSSearch 3.0 на каждый экземпляр SQL Server, что позволяет одновременно устанавливать обработчик полнотекстовых запросов на отдельные экземпляры SQL Server;
- улучшенные запросы, включающие возможность указания языка;
- поддержка полнотекстового индексирования и поиска в типе данных xml.
Несколько экземпляров обработчика полнотекстовых запросов
Служба полнотекстовых запросов SQL Server (MSFTESQL) основывается на службе Microsoft Search (MSSearch). Для каждого экземпляра SQL Server 2005 устанавливается отдельная служба полнотекстового поиска. В результате SQL Server больше не должен делить эту службу с другими серверными продуктами, использующими ее. Кроме того, наличие отдельных экземпляров обработчика полнотекстовых запросов упрощает процесс управления и обновления серверов. Можно установить другие продукты, использующие службу MSSearch, например сервер Microsoft SharePoint Portal Server, и не беспокоиться о том, что более новые версии этой службы будут оказывать влияние на поведение обработчика полнотекстовых запросов.
Обновление службы MSSearch до новой версии выполняется в процессе установки SQL Server 2005. Экземпляр новой версии сервера устанавливается параллельно со старой, затем осуществляется миграция данных. Если в имевшейся версии SQL Server средство полнотекстового поиска было установлено, то его новая версия устанавливается автоматически.
Изменение форматов в полнотекстовых каталогах
В SQL Server 2005 формат полнотекстовых каталогов значительно изменен. Эти изменения приводят к необходимости перестроения полнотекстовых каталогов предыдущих версий SQL Server. Перестроение выполняется автоматически и не препятствует процессу обновления Оно может продолжаться еще некоторое время после завершения обновления.
После завершения перестроения полнотекстового каталога будет создана новая папка по тому же пути, по которому находился первоначальный каталог. В нее будут помещены файлы, связанные с перестроенным полнотекстовым каталогом.
Отражающие специфику языка параметры полнотекстового поиска
В Microsoft SQL Server 2005 полнотекстовые запросы могут использовать для поиска полнотекстовых данных другие языки, помимо языка по умолчанию. Если язык поддерживается и если для него установлены необходимые ресурсы, для разделения слов, очистки основы, тезауруса и удаления лишних слов в запросах CONTAINS, CONTAINSTABLE, FREETEXT и FREETEXTTABLE используется параметр LANGUAGE language_term.
При создании полнотекстового индекса для столбца необходимо выбрать язык столбца. Выбор языка определяет параметры разметки текста и его индексирования обработчиком полнотекстовых запросов. Эти параметры перечислены ниже.
- Использование разделителя слов, отражающего специфику языка, или нейтрального разделителя слов
- Очистка основы с учетом специфики языка
В Приложении E содержится список языков, поддерживающих разделение слов и очистку основы с учетом специфики языка. Для всех других языков используется обработчик, нейтральный по отношению к языку. В этом случае для разделения слов используется пробел, а очистка основы не проводится.
Разделители слов в основном предназначаются для обработки обычного текста, и поэтому если в тексте используется разметка (например, HTML), лингвистическая точность при индексировании и поиске может оказаться небольшой. В этой ситуации есть два варианта действий. Предпочтительный вариант - сохранить текстовые данные в столбце varbinary(max) и указать тип документа, чтобы его можно было отфильтровать.
В случае невозможности сохранить данные в столбце varbinary(max) следует использовать нейтральный разделитель слов. По возможности в перечень лишних слов также следует добавить данные разметки (например, тег 'br' кода HTML). Если данные не хранятся в столбце varbinary(max) специальная фильтрация не производится. Вместо этого текст проводится через компонент разбивки слов без изменений.
Параметр сортировки идентификатора языкового стандарта в Unicode используется для всех типов данных, для которых может использоваться полнотекстовая индексация (например, char, nchar, и т.д.). Если указать порядок сортировки для столбца char, varchar или text, используя язык, отличающийся от языка, установленного идентификатором параметра сортировки языкового стандарта Unicode, идентификатор параметра сортировки языкового стандарта Unicode все равно будет использоваться для полнотекстовой индексации и запроса столбцов char, varchar и text.
Расширение синтаксиса запросов для полнотекстового поиска
Синтаксис полнотекстового запроса SQL Server 2005 для предложений CONTAINS, CONTAINSTABLE, FREETEXT и FREETEXTTABLE поддерживает новый параметр LANGUAGE <lcid>, который может использоваться для замены полнотекстового языка, установленного по умолчанию для столбцов, языком, установленным в предложении. Язык, установленный в предложении, определяет, какие разделители слов, правила очистки основы и список лишних слов используются для всех терминов полнотекстового запроса. Идентификатор LCID указывается как число или как текстовая строка. Значение параметра LANGUAGE <lcid> также можно указать в качестве переменной Transact-SQL при использовании в полнотекстовом запросе в хранимой процедуре.
Например, можно указать строку поиска и значение языка на уровне запроса в качестве параметра хранимой процедуры, получающего строку поиска из поля ввода текста и язык запроса из перечня поддерживаемых языков.
В предыдущих версиях сопоставление идентификаторов DocIds со значениями полнотекстовых ключей выполнялось обработчиком полнотекстовых запросов. В SQL Server 2005 этот процесс выполняется обработчиком баз данных, где могут применяться более эффективные и единообразные стратегии кэширования. В дополнение к улучшению механизма обработки такая миграция должна ускорить выполнение полнотекстовых запросов по сравнению с предыдущими версиями.
Полнотекстовый поиск данных в формате XML
В SQL Server 2005 введен новый тип данных xml, позволяющий сохранять фрагменты или документы в формате XML. Теперь полнотекстовый поиск в SQL Server поддерживает создание полнотекстовых индексов и полнотекстовых запросов данных, хранящихся в типе данных xml.
Сложность запросов соответствует значениям в столбцах. Полнотекстовые предикаты, соответствующие полнотекстовым индексированным столбцам XML,выводят строки, где искомый текст присутствует где угодно в содержимом столбца.
Взаимодействие с другими продуктами баз данных
При работе с другими системами баз данных наиболее важная задача для интернациональных приложений заключается в том, чтобы определить кодовую страницу и правила для этих систем. Многие из методов доступа к данным в SQL используют COM и поэтому используют данные Unicode. Собственный клиент SQL также использует Unicode. Поэтому для определения качества запуска интернационального приложения наиболее важной является информация относительно того, как хорошо будут поддерживать Unicode другие продукты баз данных.
Например, такие базы данных как Oracle и Sybase SQL Server поддерживают Unicode, используя кодировку UTF-8. Обычно это не влияет ни на что, потому что данные необходимо преобразовывать в формат UTF-16 с помощью ADO/OLE DB еще до того, как вы увидите информацию. Однако различия необходимо учитывать при попытках непосредственно взаимодействовать с данными в таких продуктах.
Некоторые продукты поддерживают типы данных с национальными языковыми символами, но не обрабатывают их как типы данных Unicode. В таких базах данных поля nchar и nvarchar могут использоваться для хранения данных на японском языке в базе данных с основным языком «Английский (США)». Использование типов данных языковых символов для определения текста Unicode является особенностью Microsoft SQL Server.
В связи с этим, при использовании таких команд как OPENROWSET необходимо отправлять запросы другим продуктам или импортировать данные из других систем, и при этом очень важно знать, как обрабатывается многоязычный текст в других базах данных.
Информацию о подключении к внешним источникам данных в SQL Server 2005 для целей разработки приложений можно найти в следующих разделах электронной документации по SQL Server 2005:
- Службы SQL Server Analysis Services (службы SSAS)
- SQL Server Integration Services (службы SSIS)
- Службы SQL Server Reporting Services
- Репликация SQL Server
- Описание драйвера JDBC
- Работа с источниками данных (службы SSAS)
- Соединения служб Integration Services
- Источники данных, поддерживаемые службами Reporting Services
- Гетерогенная репликация базы данных
- Доступ к данным из объектов баз данных CLR
Заключение
В Microsoft SQL Server 2005 используется весь функционал по поддержке различных языков из SQL Server 2000, в сочетании с улучшенной и единообразной поддержкой Unicode и интеграцией многоязычных возможностей операционной системы Windows и среды выполнения CLR. В SQL Server 2005 сочетаются наденжная поддержка многоязычных баз данных и разнообразные средства разработки, обеспечивающие высокую скорость и надежность разработки международных решений в области финансов, электронной коммерции и связи.
Благодарность
Этот документ был первоначально написан Майклом Капланом (Michael Kaplan) для SQL Server 2000 с помощью Майкла Канга (Michael Kung) менеджером программы SQL Server; Питером Карлином (Peter Carlin), менеджером по разработке реляционного механизма SQL Server и Фернандо Каро (Fernando Caro), старшего менеджера по международным программам. Дополнительную информацию представили Майкл Рис (Michael Rys), Юэн Гарден (Euan Garden), Фэди Фахури (Fadi Fakhouri), Джеймс Хоуи (James Howey) и Маргарет Ли (Margaret Li). Информация по поддержке параметров сортировки в SQL Server 7.0 и 2000 была предоставлена Джулией Беннетт (Julie Bennett), Кэти Уиссинк (Cathy Wissink) и Джоном , Макконнелом (John McConnell).
Обновленная информация по возможностям SQL Server 2005 была предоставлена группой по подготовке пользователей SQL Server User Education при участии Фернандо Каро (Fernando Caro) и Нобухико Киши (Nobuhiko Kishi).
Приложение A: Суффиксы параметров сортировки
|
Суффикс |
Значение |
|---|---|
| _BIN | двоичная сортировка |
| _CI_AI | без учета регистра, без учета ударения, без учета типа каны, без учета ширины |
| _CI_AI_WS | без учета регистра, без учета ударения, без учета типа каны, с учетом ширины |
| _CI_AI_KS | без учета регистра, без учета ударения, с учетом типа каны, без учета ширины |
| _CI_AI_KS_WS | без учета регистра, без учета ударения, с учетом типа каны, с учетом ширины |
| _CI_AS | без учета регистра, с учетом ударения, без учета типа каны, без учета ширины |
| _CI_AS_WS | без учета регистра, с учетом ударения, без учета типа каны, с учетом ширины |
| _CI_AS_KS | без учета регистра, с учетом ударения, с учетом типа каны, с учетом ширины |
| _CI_AS_KS_WS | без учета регистра, с учетом ударения, с учетом типа каны, с учетом ширины |
| _CS_AI | с учетом регистра, без учета ударения, без учета типа каны, без учета ширины |
| _CS_AI_WS | с учетом регистра, без учета ударения, без учета типа каны, с учетом ширины |
| _CS_AI_KS | с учетом регистра, без учета ударения, с учетом типа каны, без учета ширины |
| _CS_AI_KS_WS | с учетом регистра, без учета ударения, с учетом типа каны, с учетом ширины |
| _CS_AS | с учетом регистра, с учетом ударения, без учета типа каны, без учета ширины |
| _CS_AS_WS | с учетом регистра, с учетом ударения, без учета типа каны, с учетом ширины |
| _CS_AS_KS | с учетом регистра, с учетом ударения, с учетом типа каны, без учета ширины |
| _CS_AS_KS_WS | с учетом регистра, с учетом ударения, с учетом типа каны, с учетом ширины |
Примечание. По умолчанию тип каны не учитывается. Другими словами, по умолчанию катакана и хирагана обрабатываются одинаково. Ширина по умолчанию также не учитывается. Другими словами, символы полной ширины и половинной ширины обрабатываются одинаково.
Приложение B: Языки, поддерживаемые в операционной системе Windows
| Английский (us_english) | Словацкий (slovenиina) |
| Немецкий (Deutsch) | Словенский (slovenski) |
| Французский (Franзais) | Греческий (еллзнйкЬ) |
| Японский ("ъ-{Њк) | Болгарский (български) |
| Датский (Dansk) | Русский |
| Испанский (Espaсol) | Турецкий (Tьrkзe) |
| Итальянский (Italiano) | Британский английский (British) |
| Голландский (Нидерланды) | Эстонский (eesti) |
| Норвежский (Norsk) | Латышский (latvieљu) |
| Португальский (Portuguкs) | Lithuanian (lietuviш) |
| Финский (Suomi) | Бразильский (Portuguкs - Brasil) |
| Шведский (Svenska) | Китайский (традиционное письмо, БcЕ餤¤е) |
| Чешский (иeљtina) | Корейский (ЗС±№ѕо) |
| Венгерский (magyar) | Китайский (упрощенное письмо, ?‘М’†•¶) |
| Польский (polski) | Арабский (Arabic) |
| Румынский (romвnг) | Тайский (д·В) |
| Хорватский (hrvatski) |
Приложение C: Порядок сортировки в SQL
Порядки сортировки SQL также входят и в SQL Server 2000. Эти порядки сортировки SQL показаны в следующей таблице. Многие из них поддерживают различные части суффиксов, описанные выше, но поддерживаются не все суффиксы.
| SQL_1xCompat_CP850 | SQL_Estonian_CP1257 | SQL_Latin1_General_Pref_CP437 |
| SQL_AltDiction_CP1253 | SQL_Hungarian_CP1250 | SQL_Latin1_General_Pref_CP850 |
| SQL_AltDiction_CP850 | SQL_Icelandic_Pref_CP1 | SQL_Latvian_CP1257 |
| SQL_AltDiction_Pref_CP850 | SQL_Latin1_General_CP1 | SQL_Lithuanian_CP1257 |
| SQL_Croatian_CP1250 | SQL_Latin1_General_CP1250 | SQL_MixDiction_CP1253 |
| SQL_Czech_CP1250 | SQL_Latin1_General_CP1251 | SQL_Polish_CP1250 |
| SQL_Danish_Pref_CP1 | SQL_Latin1_General_CP1253 | SQL_Romanian_CP1250 |
| SQL_EBCDIC037_CP1 | SQL_Latin1_General_CP1254 | SQL_Scandinavian_CP850 |
| SQL_EBCDIC273_CP1 | SQL_Latin1_General_CP1255 | SQL_Scandinavian_Pref_CP850 |
| SQL_EBCDIC277_CP1 | SQL_Latin1_General_CP1256 | SQL_Slovak_CP1250 |
| SQL_EBCDIC278_CP1 | SQL_Latin1_General_CP1257 | SQL_Slovenian_CP1250 |
| SQL_EBCDIC280_CP1 | SQL_Latin1_General_CP437 | SQL_SwedishPhone_Pref_CP1 |
| SQL_EBCDIC284_CP1 | SQL_Latin1_General_CP850 | SQL_SwedishStd_Pref_CP1 |
| SQL_EBCDIC285_CP1 | SQL_Latin1_General_Pref_CP1 | SQL_Ukrainian_CP1251 |
| SQL_AltDiction_CP1253 | SQL_Hungarian_CP1250 | SQL_Latin1_General_Pref_CP850 |
Приложение D: Языки, поддерживаемые в SQL Server 2005
Вы можете посмотреть этот же список в SQL Server 2005, выполнив следующую команду:
select langid, alias, lcid, msglangid from sys.syslanguages
|
Название (на английском языке) |
Код Windows LCID |
Код сообщения |
|---|---|---|
| English | 1033 | 1033 |
| German | 1031 | 1031 |
| French | 1036 | 1036 |
| Japanese | 1041 | 1041 |
| Danish | 1030 | 1030 |
| Spanish | 3082 | 3082 |
| Italian | 1040 | 1040 |
| Dutch | 1043 | 1043 |
| Norwegian | 2068 | 2068 |
| Portuguese | 2070 | 2070 |
| Finnish | 1035 | 1035 |
| Swedish | 1053 | 1053 |
| Czech | 1029 | 1029 |
| Hungarian | 1038 | 1038 |
| Polish | 1045 | 1045 |
| Romanian | 1048 | 1048 |
| Croatian | 1050 | 1050 |
| Slovak | 1051 | 1051 |
| Slovene | 1060 | 1060 |
| Greek | 1032 | 1032 |
| Bulgarian | 1026 | 1026 |
| Russian | 1049 | 1049 |
| Turkish | 1055 | 1055 |
| British English | 2057 | 1033 |
| Estonian | 1061 | 1061 |
| Latvian | 1062 | 1062 |
| Lithuanian | 1063 | 1063 |
| Brazilian | 1046 | 1046 |
| Traditional Chinese | 1028 | 1028 |
| Korean | 1042 | 1042 |
| Simplified Chinese | 2052 | 2052 |
| Arabic | 1025 | 1025 |
| Thai | 1054 | 1054 |
Приложение Е: Полнотекстовые языки, добавленные в SQL Server 2005
Для отображения списка языков, для которых доступно полнотекстовое индексирование и запросы, используется представление sys.fulltext_languages.
|
Идентификатор параметра сортировки языкового стандарта Unicode |
Язык для хранения полнотекстовых данных |
|---|---|
| Китайский (Тайвань) | Китайский - традиционное письмо |
| Китайский - пунктуация | Китайский - упрощенное письмо |
| Китайский - количество штрихов | Китайский - упрощенное письмо |
| Китайский - количество штрихов (Тайвань) | Китайский - традиционное письмо |
| Голландский | Голландский |
| Английский (Великобритания) | Английский (Великобритания) |
| Французский | Французский |
| Unicode (общий) | Английский (США) |
| Немецкий | Немецкий |
| Немецкий - телефонная книга | Немецкий |
| Итальянский | Итальянский |
| Японский | Японский |
| Японский (Unicode) | Японский |
| Корейский | Корейский |
| Корейский (Unicode) | Корейский |
| Испанский (Испания) | Испанский |
| Шведский/финский | Шведский |
Приложение F: Обновленные параметры сортировки в SQL Server 2005
Полный список параметров сортировки, поддерживаемых экземпляром SQL Server 2005, можно получить с помощью команды fn_helpcollations ().
|
Прежнее имя параметра сортировки |
Новое имя параметра сортировки |
|---|---|
| Japanese | Japanese_90 |
| Chinese | Chinese_PRC_90
Chinese_PRC_Stroke Chinese_PRC_Stroke_90 Chinese_Taiwan_Bopomofo Chinese_Taiwan_Bopomofo_90 Chinese_Taiwan_Stroke Chinese_Taiwan_Stroke_90 |
| Korean | Korean_90 |
| Hindi | (удален в этой версии) |
| Indic | General_90 |