Трудно найти в компьютерном мире человека, который хотя бы на интуитивном уровне не понимал, что такое базы данных и зачем они нужны. В отличие от традиционных реляционных СУБД, концепция OLAP не так широко известна, хотя загадочный термин "кубы OLAP" слышали, наверное, почти все. Что же такое OnLine Analytical Processing, где он обитает, и с чем его едят, мы и попытаемся разобраться.
OLAP - это не отдельно взятый программный продукт, не язык программирования и даже не конкретная технология. Если постараться охватить OLAP во всех его проявлениях, то это совокупность концепций, принципов и требований, лежащих в основе программных продуктов, облегчающих аналитикам доступ к данным. Несмотря на то, что с таким определением вряд ли кто-нибудь не согласится, сомнительно, чтобы оно хоть на йоту приблизило неспециалистов к пониманию нашего предмета. Поэтому в своем стремлении к познанию OLAP мы пойдем другим путем. Для начала мы выясним, зачем аналитикам надо как-то специально облегчать доступ к данным.
Дело в том, что аналитики - это особые потребители корпоративной информации. Задача аналитика - находить закономерности в больших массивах данных. Поэтому аналитик не будет обращать внимания на отдельно взятый факт, что в четверг четвертого числа контрагенту Чернову была продана партия черных чернил - ему нужна информация о сотнях и тысячах подобных событий. Одиночные факты в базе данных могут заинтересовать, к примеру, бухгалтера или начальника отдела продаж, в компетенции которого находится сделка. Аналитику одной записи мало - ему, к примеру, могут понадобиться все сделки данного филиала или представительства за месяц, год. Заодно аналитик отбрасывает ненужные ему подробности вроде ИНН покупателя, его точного адреса и номера телефона, индекса контракта и тому подобного. В то же время данные, которые требуются аналитику для работы, обязательно содержат числовые значения - это обусловлено самой сущностью его деятельности.
Итак, аналитику нужно много данных, эти данные являются выборочными, а также носят характер "набор атрибутов - число". Последнее означает, что аналитик работает с таблицами следующего типа:
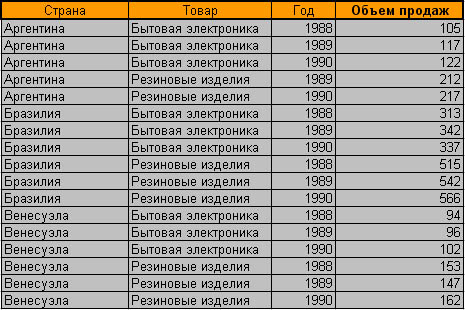
Здесь "Страна", "Товар", "Год" являются атрибутами, а "Объем продаж" - тем самым числовым значением. Задачей аналитика, повторимся, является выявление стойких взаимосвязей между атрибутами и числовыми параметрами. Посмотрев на таблицу, можно заметить, что ее легко можно перевести в три измерения: по одной из осей отложим страны, по другой - товары, по третьей - годы. А значениями в этом трехмерном массиве у нас будут соответствующие объемы продаж.
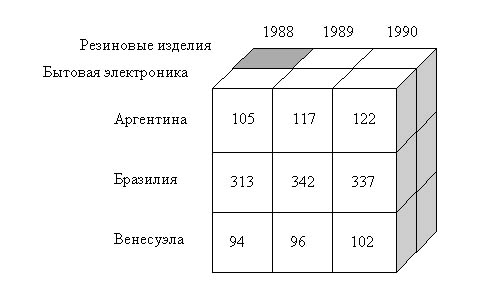 |
| Трехмерное представление таблицы. Серым сегментом показано, что для Аргентины в 1988 году данных нет |
Вот именно такой трехмерный массив в терминах OLAP и называется кубом. На самом деле, с точки зрения строгой математики кубом такой массив будет далеко не всегда: у настоящего куба количество элементов во всех измерениях должно быть одинаковым, а у кубов OLAP такого ограничения нет. Тем не менее, несмотря на эти детали, термин "кубы OLAP" ввиду своей краткости и образности стал общепринятым. Куб OLAP совсем не обязательно должен быть трехмерным. Он может быть и двух-, и многомерным - в зависимости от решаемой задачи. Особо матерым аналитикам может понадобиться порядка 20 измерений - и серьезные OLAP-продукты именно на такое количество и рассчитаны. Более простые настольные приложения поддерживают где-то 6 измерений.
Измерения OLAP-кубов состоят из так называемых меток или членов (members). Например, измерение "Страна" состоит из меток "Аргентина", "Бразилия", "Венесуэла" и так далее.
Должны быть заполнены далеко не все элементы куба: если нет информации о продажах резиновых изделий в Аргентине в 1988 году, значение в соответствующей ячейке просто не будет определено. Совершенно необязательно также, чтобы приложение OLAP хранило данные непременно в многомерной структуре - главное, чтобы для пользователя эти данные выглядели именно так. Кстати именно специальным способам компактного хранения многомерных данных, "вакуум" (незаполненные элементы) в кубах не приводят к бесполезной трате памяти.
Однако куб сам по себе для анализа не пригоден. Если еще можно адекватно представить или изобразить трехмерный куб, то с шести- или девятнадцатимерным дело обстоит значительно хуже. Поэтому перед употреблением из многомерного куба извлекают обычные двумерные таблицы. Эта операция называется "разрезанием" куба. Термин этот, опять же, образный. Аналитик как бы берет и "разрезает" измерения куба по интересующим его меткам. Этим способом аналитик получает двумерный срез куба и с ним работает. Примерно так же лесорубы считают годовые кольца на спиле.
Соответственно, "неразрезанными", как правило, остаются только два измерения - по числу измерений таблицы. Бывает, "неразрезанным" остается только измерение - если куб содержит несколько видов числовых значений, они могут откладываться по одному из измерений таблицы.
Если еще внимательнее всмотреться в таблицу, которую мы изобразили первой, можно заметить, что находящиеся в ней данные, скорее всего, не являются первичными, а получены в результате суммирования по более мелким элементам. Например, год делится на кварталы, кварталы на месяцы, месяцы на недели, недели на дни. Страна состоит из регионов, а регионы - из населенных пунктов. Наконец в самих городах можно выделить районы и конкретные торговые точки. Товары можно объединять в товарные группы и так далее. В терминах OLAP такие многоуровневые объединения совершенно логично называется иерархиями. Средства OLAP дают возможность в любой момент перейти на нужный уровень иерархии. Причем, как правило, для одних и тех же элементов поддерживается несколько видов иерархий: например день-неделя-месяц или день-декада-квартал. Исходные данные берутся из нижних уровней иерархий, а затем суммируются для получения значений более высоких уровней. Для того, чтобы ускорить процесс перехода, просуммированные значения для разных уровней хранятся в кубе. Таким образом, то, что со стороны пользователя выглядит одним кубом, грубо говоря, состоит из множества более примитивных кубов.
 |
| Пример иерархии |
Вот, кстати, мы и подошли, к одному из существенных моментов, которые привели к появлению OLAP - производительности и эффективности. Представим себе, что происходит, когда аналитику необходимо получить информацию, а средства OLAP на предприятии отсутствуют. Аналитик самостоятельно (что маловероятно) или с помощью программиста делает соответствующий SQL-запрос и получает интересующие данные в виде отчета или экспортирует их в электронную таблицу. Проблем при этом возникает великое множество. Во-первых, аналитик вынужден заниматься не своей работой (SQL-программированием) либо ждать, когда за него задачу выполнят программисты - все это отрицательно сказывается на производительности труда, повышаются штурмовщина, инфарктно-инсультный уровень и так далее. Во-вторых, один-единственный отчет или таблица, как правило, не спасает гигантов мысли и отцов русского анализа - и всю процедуру придется повторять снова и снова. В-третьих, как мы уже выяснили, аналитики по мелочам не спрашивают - им нужно все и сразу. Это означает (хотя техника и идет вперед семимильными шагами), что сервер корпоративной реляционной СУБД, к которому обращается аналитик, может задуматься глубоко и надолго, заблокировав остальные транзакции.
Концепция OLAP появилась именно для разрешения подобных проблем. Кубы OLAP представляют собой, по сути, мета-отчеты. Разрезая мета-отчеты (кубы, то есть) по измерениям, аналитик получает, фактически, интересующие его "обычные" двумерные отчеты (это не обязательно отчеты в обычном понимании этого термина - речь идет о структурах данных с такими же функциями). Преимущества кубов очевидны - данные необходимо запросить из реляционной СУБД всего один раз - при построении куба. Поскольку аналитики, как правило, не работают с информацией, которая дополняется и меняется "на лету", сформированный куб является актуальным в течение достаточно продолжительного времени. Благодаря этому, не только исключаются перебои в работе сервера реляционной СУБД (нет запросов с тысячами и миллионами строк ответов), но и резко повышается скорость доступа к данным для самого аналитика. Кроме того, как уже отмечалось, производительность повышается и за счет подсчета промежуточных сумм иерархий и других агрегированных значений в момент построения куба. То есть, если изначально наши данные содержали информацию о дневной выручке по конкретному товару в отдельно взятом магазине, то при формировании куба OLAP-приложение считает итоговые суммы для разных уровней иерархий (недель и месяцев, городов и стран).
Конечно, за повышение таким способом производительности надо платить. Иногда говорят, что структура данных просто "взрывается" - куб OLAP может занимать в десятки и даже сотни раз больше места, чем исходные данные.
Теперь, когда мы немного разобрались в том, как работает и для чего служит OLAP, стоит, все же, несколько формализовать наши знания и дать критерии OLAP уже без синхронного перевода на обычный человеческий язык. Эти критерии (всего числом 12) были сформулированы в 1993 году Е.Ф. Коддом - создателем концепции реляционных СУБД и, по совместительству, OLAP. Непосредственно их мы рассматривать не будем, поскольку позднее они были переработаны в так называемый тест FASMI, который определяет требования к продуктам OLAP. FASMI - это аббревиатура от названия каждого пункта теста:
- Fast (Быстрый). Приложение OLAP должно обеспечивать минимальное время доступа к аналитическим данным - в среднем порядка 5 секунд;
- Analysis (Анализ). Приложение OLAP должно давать пользователю возможность осуществлять числовой и статистический анализ;
- Shared (Разделяемый доступ). Приложение OLAP должно предоставлять возможность работы с информацией многим пользователям одновременно;
- Multidimensional (Многомерность). См. выше;
- Information (Информация). Приложение OLAP должно давать пользователю возможность получать нужную информацию, в каком бы электронном хранилище данных она не находилась.
Работа с OLAP-системами может быть построена на основе из двух описанных ниже схем.
Для "легковесного" применения подойдут OLAP-средства, встроенные в настольные приложения. Такие средства, как правило, имеют множество ограничений: на количество измерений, на допустимые иерархии и так далее. К подобным средствам, например, относится модуль Pivot Table, позволяющий работать с кубами в Microsoft Excel. Pivot Table входит в Microsoft Office с незапамятных времен и до недавнего времени был единственным OLAP-продуктом в его составе. В этом случае данные извлекаются модулем-клиентом непосредственно из реляционной СУБД.
В "тяжелых" случаях применяют двухступенчатую схему "клиент-сервер". Сервер обеспечивает непосредственно извлечение информации из СУБД и все прочее, необходимое для создания кубов. Специализированное же приложение-клиент предназначено для удобного (а главное - эффективного) просмотра кубов и выявления тех самых аналитических закономерностей, с которых мы начинали наш экскурс. В линейке продуктов Microsoft серверная часть представлена в лице Microsoft Analysis Services, которые входят в MS SQL Server. Сравнительно недавно в состав MS Office включен OLAP-клиент под названием Microsoft Data Analyzer.