Игорь Рубенович Агамирзян: …Давайте, мы тогда сейчас послушаем последнее выступление Сергея Лихарева из IBM и потом уже перейдем к этой дискуссии. Хорошо, что такие моменты обозначаются.
Сергей Лихарев: Я теорию, наверное, не буду рассказывать. На самом деле, чем хорошо работать в большой компании - это слайд 34 в первой презентации. Институт бизнес-ценностей - это организация, которую IBM финансирует, и мы проводим много исследований, разговариваем с руководителями организаций, что они делают с большими данными сейчас.
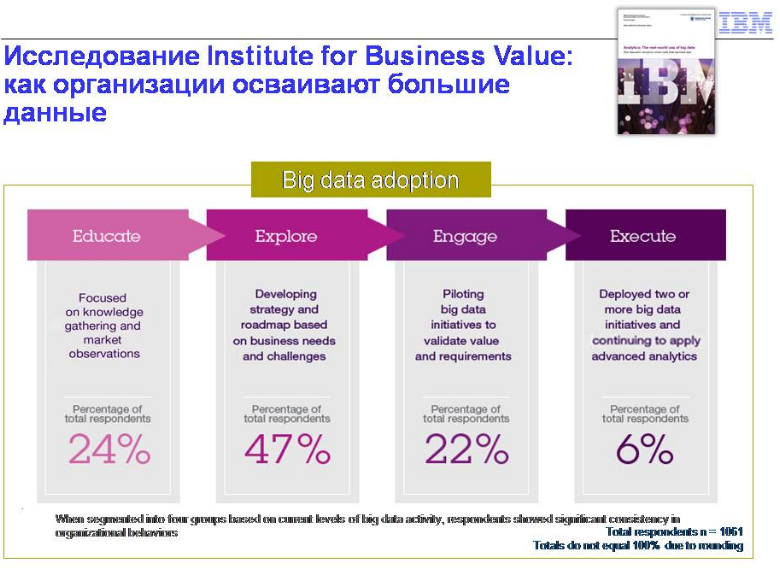
Вот картинка, которая была последней получена нами. 6% делают что-то - 1-2 инициативы в области больших данных, которые работают. 22% пилотируют, то есть пытаются понять, что из этого может быть. 47% строят бизнес-кейс. Они еще считают, что большие данные могут им принести. 24% самообразовываются. С точки зрения тендеров, почему все туда побежали? Здесь мало что уже можно продать, именно это есть рынок. Рынок компаний, которые еще не приняли решение, которые думают, как из этого можно извлечь бизнес-ценность.
С точки зрения платформы. Какие требования можно предъявить, когда компания говорит, что хочет работать с большими данными? В первую очередь, понимание навигации. Когда у нас много этого хозяйства есть, нужно понять, как это и где находится. Во-вторых, Hadoop, многие говорят, что он - это большие данные. Это одна из частей. Место, куда я сложу информацию в огромных объемах, но это еще не все. Потому что традиционные хранилища никто не отменял. Те самые 100-200-терабайтные хранилища, которые есть и требуют очень быстрого ответа. На Hadoop этот ответ получить сейчас невозможно. Традиционные хранилища не умирают, им предъявляются немного другие требования. Люди хотят, чтобы сотни терабайт быстро обрабатывались, чтобы они были легкие, по возможности более дешевые. Огромный пласт задач вот здесь, потоковых данных. Почему? Потому что мы начали работать с видеоинформацией. Идет поток, постоянная телевизионная картинка, из этого можно что-то выхватывать. Один из примеров проекта, который я видел в Штатах, - это ураган. Идет ураган, а они на ходу обсчитывают траекторию движения урагана, что происходит в этот момент. Они пытаются понять риск поражения территории, они обсчитывают потенциальный ущерб, оптимизируют цепочки поставок, чтобы если ураган будет продолжать двигаться по этой территории, максимально быстро насытить этот район товарами, которые потребуются в результате этого катаклизма. Очень много вещей. Statoil, нефтяная компания, они фотографируют со спутника льдины, как они тают, у них стоят датчики везде, и за счет того, что они немного продлевают период добычи нефти, они экономят 200 миллионов долларов. Чем ближе к реальному времени, тем круче. Неструктурированные данные. Опять же, мы о себе очень много говорим, из этого надо извлекать пользу. Если платформа не позволяет этого делать, значит, с большими данными будут проблемы. В силу того, что мы их накапливаем, политики удаления, сохранения, обеспечения больших данных должны существовать в платформе.
IBM пытается коммерциализировать эти вещи, поэтому я приведу, может быть, пару примеров из медицины, но тем не менее. Области, в которых, мы видим, большие данные принесут огромную пользу. В данном случае, мы взяли четыре. Новый взгляд на клиента - это то, что мы видели на слайде. Компании пытаются лучше понять своего клиента, безопасность, анализ операций и расширение традиционных хранилищ данных. Теперь по каждому из них немного более подробно.

Глубже понимать настроение клиента из внешних и внутренних источников. Я позвонил, мой голос записался, я могу распознать, о чем говорю, сейчас это достаточно легко, сохранили текст моего сообщения, потом его анализируем. Всю информацию везде я добровольно о себе сообщаю. Если я умею что-то извлекать из этой информации, это здорово, потому что я могу выявить тенденции, что заставляет моих клиентов принимать эти решения, рекомендовать или нет мою компанию, у них есть общие черты, либо нет. Мало того, я хочу это сделать не постфактум, я хочу приблизить это к моменту, когда я непосредственно звоню. Когда я положил трубку, возможность закончилась. Поэтому если я могу выяснить потребность в момент, когда человек со мной разговаривает, это еще более интересный вариант. Компании пытаются с помощью больших данных понять, как лучше взаимодействовать с клиентом, что ему в этот момент предложить, как потом выяснить его реакцию. В мдм (менеджменте) содержится вся базовая информация обо мне. У нас в России компании могут себе позволить создавать с нуля систему. Если это западная компания, 20 лет разработок, 15 хранилищ информации о клиенте, они как-то все-таки к этому приходят.
Давайте подумаем вот о чем. В Киев многие летали? Приезжаем в аэропорт, вставляем карточку в банкомат, через 5 минут нам звонок о том, что мы попали в страну, где есть повышенные риски. Классически сработала система безопасности. С другой стороны, я в Москве, проходит транзакция по моей карточке, для банка это вроде бы не рисковая страна. При этом я о себе в твиттере в этот момент пишу "как здорово находиться на Мальдивских островах, вот фотография". Если я эту информацию сопоставлю, моя транзакция моментально станет более рисковой. Мы это просто иногда отбрасываем, потому что раньше не думали, что это возможно обрабатывать, или не хотели. То есть здесь можно думать за рамками того, что сейчас происходит. Можно ли принимать новые решения на основании того, что стал доступен новый источник информации? Если да, то, возможно, большие данные нам помогут эту задачу решать.

Безопасность. Здесь очень много интересных моментов. Компании типа Splunk. Логи - огромное количество информации, которая поступила, а дальше что? Дальше нужно проанализировать, были ли угрозы безопасности. Я с одним администратором разговаривал, он сказал, что идут логи, я их вижу, при этом у меня все равно стоит камера, которая снимает серверную комнату. Туда зашел человек, что-то поделал, я увидел, что по логам что-то прошло, а с другой стороны, он не выполнил то, что должен был по должностным инструкциям. Сопоставив информацию, он мог сказать, что было сделано что-то, что было, возможно, потенциально плохо для безопасности этого банка.
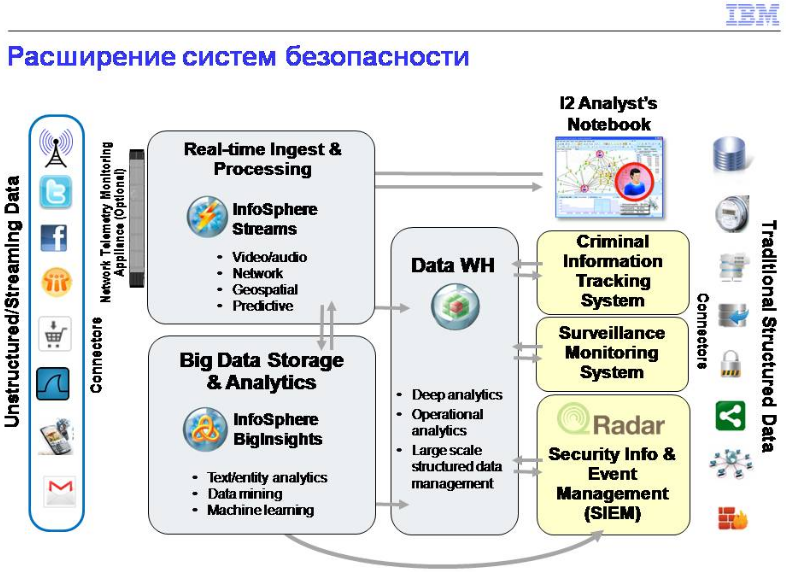
Предсказание и предотвращение атак. Опять же, постфактум понять, что что-то было плохое, не здорово, хочется в реальном времени. Когда пошло событие, которое потенциально может связаться с неблагоприятными вещами, лучше сразу это выяснить.
Социальные данные и коммуникации. Опять же, все провайдеры нашей и других стран имеют регулярные запросы от наших ведомств о предоставлении информации и CDR. Это все из области больших данных, их нужно сопоставить, принять решение, выявить какие-то сложные вещи, это большой рынок для подобных решений и компаний.
Традиционные системы, департамент полиции Нью-Йорка. Ребята говорят, что если в течение 30 минут они не поймали преступника, шанс поймать его резко падает, это нужно сделать моментально. У них сценарий работы такой: когда происходит преступление, в момент, когда полицейский приезжает на место, система ему уже выдает список потенциальных подозреваемых. Как могут быть расширены традиционные системы? Все фотографии, свидетельства очевидцев, прошлые преступления - это доступно. Идет информация преступления с видео, мы можем сопоставить лицо преступника, это дополнительные моменты, которые позволяют нам быстрее раскрывать преступления.

Анализ операций. Машинных данных много, наша задача - сопоставить это с бизнес-операциями. Не просто сказать, что у нас упала сетка, а сказать, что падение сетки в этот момент повлияет на 20% наших самых ценных абонентов, поэтому это допустить нельзя. Вещи, которые позволяют бизнесу лучше обслуживать своих клиентов. Что нам нужно для этого? Проанализировать инфраструктуру, сопоставить это с бизнес-транзакциями. Опять же, огромный объем, и желательно побыстрее.
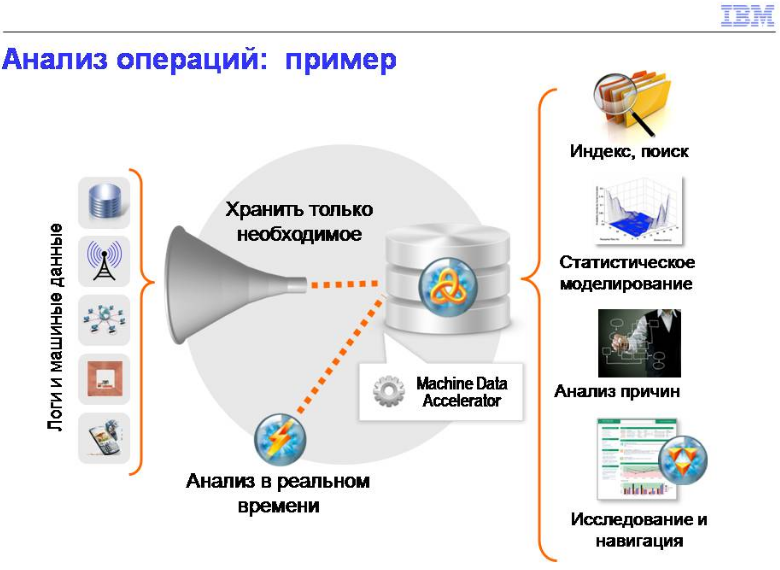
Еще один момент здесь. На Западе очень актуально, у нас постепенно актуальность нарастает. Регуляторы заставляют нас хранить данные как можно дольше, поэтому встает вопрос: а все ли данные нужно сохранять? Или я могу положить в хранилище только ту информацию, которая мне действительно понадобится? То есть снизить стоимость хранения за счет предобработки, желательно - в реальном времени. Задача, с первого взгляда, неочевидная, но, тем не менее, очень полезная.

Традиционное хранилище данных когда становится большим и дорогим, встает вопрос, что делать. Вроде как, данные хочется проанализировать, но следующий счет на развитие инфраструктуры становится таким большим, что мы начинаем сомневаться. Из-за этого мы видим ситуации, когда очередь из проектов на бизнес-аналитику на ближайшие два года расписана, и IT говорит, что мы не можем так быстро расти. Данные переполняют инфраструктуру, а на IT не дают денег. Что можно в этом случае делать? Hadoop может очень здорово разгрузить, есть технологии, которые сейчас позволяют делать запросы по этим данным.
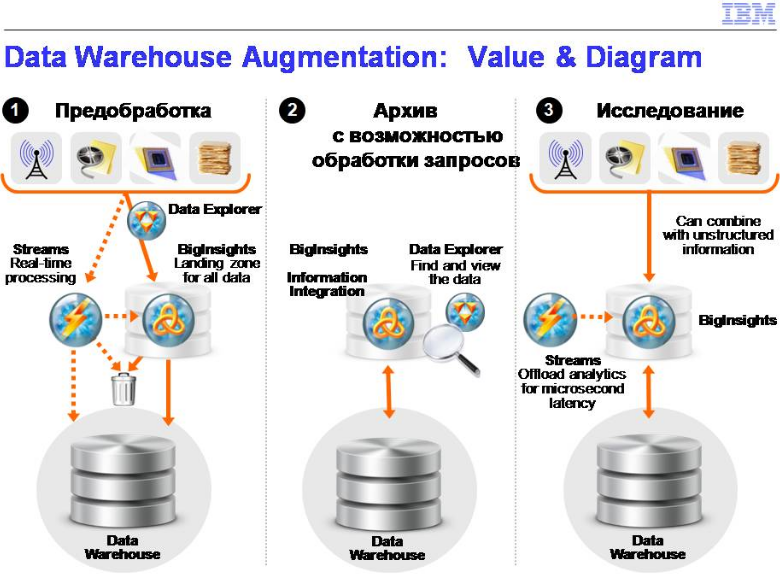
Здесь несколько сценариев, я просто привел пример. Можно делать предобработку, архивы с возможностью запросов по ним. Или можно делать исследования. У меня появился новый источник данных, я научился его сохранять. Вопрос, мусор там или не мусор, что с этим делать? Сейчас я могу это сбрасывать в Hadoop, относительно дешевый способ хранения, а потом решать, что делать с данными. Вещи, которые позволяют управлять ростом традиционного хранилища, но при этом сохранять бизнес-ценность от новых источников данных.

IBM. Он, конечно, покрыл всю платформу от и до. Что хорошего, мы считаем, мы делаем для проектов? С точки зрения Hadoop, мы ориентируемся полностью на open source. Удобная установка в масштабах предприятия, администрирование, средства разработки, визуализации. Для понимания, что такое средства разработки. Много лет назад мы изобрели SQL, язык традиционных запросов к базам данных. Сейчас для всех этих продуктов мы сделали декларативные языки, то есть языки высокого уровня для обработки текстов и потоковых данных.
Акселераторы - это шаблоны приложений, решений, которые позволяют быстрее реализовывать определенные проекты. Например, акселератор для работы с машинными данными. Или шаблоны для работы с акустическими данными.
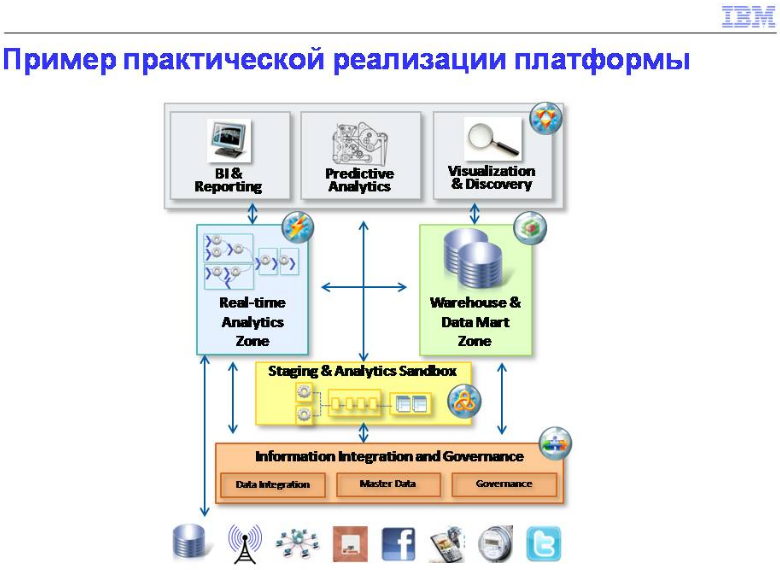
То, что мы видим у заказчиков, когда они начинают говорить про платформы. То, откуда многие пришли, здесь получается Hadoop. Потоковые данные, немногие сейчас об этом говорят. Мне понравился пример - я разговаривал с ритейлером. Я ему сказал: "Хорошо, Hadoop - здорово, хранилища - понимаю. Но я не вижу для вас бизнеса в ритейле". Он говорит: "Подожди. В любом магазине стоит камера, она фиксирует вход людей в магазин. Если ты видишь очередь людей на кассе, ты разворачиваешься и уходишь. Я вижу, что вошло 20 человек, и я знаю, что мне понадобится еще 1 человек в торговом зале, чтобы с ними работать. Через 10 минут мне потребуется дополнительный человек на кассе, чтобы не создавать очередь и ушедших клиентов". По сути дела, в рамках больших магазинов вся эта инфраструктура уже есть, просто надо научиться анализировать на ходу и подстраивать свои операции, не просто сохранять поток информации. Для меня это было откровением. Моя посылка здесь - сейчас мы пришли в состояние, когда стало технологически возможно обрабатывать любые объемы разнородных данных, поступающих с разной скоростью. Надо теперь придумать, как это применить к бизнесу, чтобы он рос. На самом деле, решений очень много.
Пример из медицины, достаточно известный. Канадский неонатальный институт. Идея такая. Организм человека, когда ребенок рождается, у него очень сильно скачут показатели. Как только возникает угроза жизни человека, организм резко выравнивает все показатели, он резко бросает все силы на выздоравливание. Прибор способен за 24 часа до наступления события сказать, что именно с этим ребенком будет, возможно, что-то не так. Смертность в контрольной группе упала на 20% только из-за того, что они научились использовать и внедрять такие технологии.
Из азиатских проектов. Снимки, идет флюорография. Человек, просматривая снимки день за днем, начинает ошибаться. Они научились прогонять эти снимки через алгоритмы и выявлять случаи, типично попадающие под определенный сценарий. Человек принимает участие в меньшем количестве операций. Сценариев не только для бизнеса, но и для здравоохранения достаточно много. В этом случае снимки лежат в Hadoop. Все. Спасибо большое за внимание.
Игорь Рубенович Агамирзян: Спасибо большое, коллеги. Предлагаю один-два вопроса конкретно по этой реплике, потом переходим к обсуждению. Да, пожалуйста.
Вадим Сухомлинов: У меня такой вопрос. Какие вы предложите технологии по работе с неструктурированными данными? Видео, аудио, смысловая текстовая информация. Есть вообще какие-то серьезные прорывы в этой области?
Сергей Лихарев: Текст. Язык мы разработали, который позволяет выделять объекты, шаблоны, оценивать оттенки текста. С точки зрения видео-аудио. Сейчас в платформе используются open source библиотеки, в которых можно дорабатывать. В лабораториях IBM есть проекты, когда эти библиотеки дотачиваются под нужды конкретных заказчиков.
Александр Брызгалов: Когда IBM Research поможет решению московских пробок?
Сергей Лихарев: Мы выходили с этим делом. Просто до правительства не донесли. Мы готовы к диалогу, на самом деле, потому что в Осло проект реализован, там общественный транспорт обвешен этими датчиками, мы собираем информацию, кто куда поехал. За счет этого, исходя из ситуации на дорогах, мы можем сказать, что во вторник автобус от такой до такой точки будет идти чуть дольше, а вообще это приведет к 10-тибалльным пробкам.
Игорь Рубенович Агамирзян: На самом деле, IBM занимается темой Smart city очень активно. Вопросов больше нет...
________________________________________________________________________________________________
Игорь Рубенович Агамирзян: …Переходим к дискуссии. Я не знаю, может, предложить выступавшим выйти сюда, чтобы быть в процессе дискуссии лицом к лицу с публикой. Кстати говоря, к вопросу big data могу сказать, что, судя по всему, у нас налажен стриминг в интернет. Потому что я в Facebook уже увидел публикацию с фотографией из этой комнаты, а автора здесь, в этой аудитории не вижу. Кто хочет выступить?
Эдуард Пройдаков: У меня просто общий вопрос к каждому из выступающих. Вы все рассказывали о том, что сделано в больших данных. Вопрос мой в том, что не сделано, и в чем проблема? В чем состоит проблема применения?
Леонид Жуков: В области больших данных? Во-первых, вы абсолютно правы, практическое применение. Сами по себе большие данные, если хранятся, тут вопрос цены. Вопрос в извлечении смысла, информации и знаний. Если вы говорите, что вы можете извлечь информацию из потока видео, увидеть лица, - как понять, мужское или женское это лицо? Как понять, кто это? Технологии разрабатываются, это та грань науки, над которой все сейчас работают.
Вячеслав Нестеров: Я думаю, серьезная задача еще связана с тем, что нужно сопоставлять эту самую аналитику, взятую из совершенно разных мест. Совместить информацию с камеры и с кассового аппарата, плюс посмотреть еще на что-нибудь, что вообще находится вне магазина, сложнее, потому что это большая аналитика.
Комментарий из зала: Это вопрос кастомизации.
Сергей Лихарев: Еще это вопрос инвестиций. Почему сейчас многие строят бизнес-кейсы? Они действительно пытаются понять: если сейчас вложат определенную сумму денег, получат ли они отдачу.
Марк Шмулевич: Мне кажется, что важно сейчас, новая идеология открытых данных, еще то время, когда стоит вопрос, какие именно данные будут открытыми. Это вопрос дискуссионный. Здесь важно, с чего начинать, потому что пройдет много времени, прежде чем все государственные данные станут открытыми. Но если хорошо понимать, что более эффективно для экономики, какие наборы данных должны быть открыты в первую очередь, будет хорошо.
Вячеслав Нестеров: Еще есть, конечно, проблема, связанная с теми данными, которые хранятся. Приведу один пример из области биоинформатики. На данный момент генетическая информация хранится в разных исследовательских базах данных в разном формате. А что такое данные в этой области? Это информация о геноме и фенотипе, о том, как особенности генома проявляются на человеке - какие у него заболевания, особенности, предрасположенности и т.д. Чтобы это объединить и получить действительно большие данные, нужно все это вместе слепить, а это очень сложно.
Константин Скрябин: Не могу удержаться после этой фразы. Я хотел просто сказать о том, что если вы возьмете венчурное финансирование, которое было в 2012 году на производство лекарств, оно в 2 раза упало. А венчурное финансирование на digital, половину которого занимает big data, увеличилось в 4 раза.
Игорь Рубенович Агамирзян: Коллеги, я хотел бы тоже здесь прокомментировать. Я еще раз хочу подчеркнуть то, что уже прозвучало несколько раз из разных источников. Реально большие данные становятся полезными и интересными тогда, когда возникает возможность сравнивать исходно несравнимые вещи. Причем это не только в области больших данных. Во многих технологиях возникает новое качество при добавлении дополнительных источников. Microsoft показывал компанию, которая занимается распознаванием речи. Вроде бы как в алгоритмах распознавания речи ничего особенного нет, но они к этому добавили обработку видеопотока, которая следит за губами, - и качество повышается от традиционных 92-94% до 98-99%, где уже можно реально работать. Но это просто пример того, что сопоставление оригинально несопоставимых вещей дает новые возможности. Второе. Есть одна область, которая тоже уже упоминалась, но, на мой взгляд, незаслуженно обходилась вниманием. Это все, что связано со всякими гридами - и не только в энергетике. Насколько я знаю, по Евросоюзу есть директива, по которой к 2020 году 80% домохозяйств должны быть оборудованы smart meters. Огромный поток данных, собираемый со всего континента, по энергопотреблению в каждой конкретной точке с точностью до домовладения. Имея эту информацию, возможность ее аналитически обрабатывать и на ее основе принимать решения в реальном времени, можно повысить энергоэффективность на 15-20%. Это то, ради чего делается смарт грид. Он становится реально влияющим на всю систему, когда он доходит до конечного потребителя, до самого низа. Скорее всего, то же самое будет во всех процессах, связанных с применением цифровой обработки информационных технологий в реальном секторе экономики, в производстве. Потому что управление большим сложным производственным комплексом генерит огромное количество данных со всех датчиков.
Вячеслав Нестеров: Есть одно замечательное приложение у смарт гридов в нашей стране, оно обсуждалось недавно. Это предотвращение воровства электроэнергии. Если есть хорошая сеть трансмиттеров, то выявить точку, из которой вытекает электроэнергия, не представляет абсолютно никакого труда.
Вадим Сухомлинов: А безопасность данных? Если я в реальном времени могу анализировать их показатели, я могу тогда сказать, кто пришел домой, кто ушел из дома.
Анджей Аршавский: Вы, когда рассказывали историю, говорили о том, что компьютинг, связанный с большими данными, пришел на смену коммодити компьютинг. Но на самом деле, они живут в параллели. Один занимается моделированием, второй, big data, занимается обработкой больших данных. Не могли бы коллеги привести примеры, где эти две области сейчас встречались бы? Где можно было бы обрабатывать большие данные и одновременно заниматься моделированием.
Игорь Рубенович Агамирзян: Одно из известных приложений high performance computing"а - это системы краш-тестинга. Их моделируют в автомобильной промышленности, во всем машиностроении. Я не специалист в этом, но знаю, что всегда ведутся и натурные эксперименты, потоки данных собираются уже с конкретного физического объекта. Могу предположить, что, скорее всего, в какой-то точке это должно сходиться.
Леонид Жуков: Например, финансовые рынки. С одной стороны, обсчет формы Блэк-Шульца, вычисление ожидаемых стоимостей, с другой стороны, мы накапливаем огромные объемы данных. Геология - когда идет расчет дифференциальных уравнений, расчет породы, структуры, с другой стороны, получены сейсмические данные. Метеорология. На самом деле, довольно много пересечений. Я пытался сравнить тему суперкомпьютинга, потому что она известна, и те алгоритмы оказались неприменимыми, есть большая вероятность того, что компьютеры ломаются.
Анджей Аршавский: Вы говорили о задачах, где нужно в реальном времени принимать какие-то решения. В то время как big data - это не задача реального времени.
Леонид Жуков: Не совсем так. Hadoop, его нынешняя технология - это бэтч-обработка. То, что сейчас делает Cloudera, их новая технология, связано с тем, чтобы обрабатывать данные в реальном времени и делать запросы к ним. Они оставляют Hadoop как файловую надежную систему, но собирают парадигму map reduce.
Сергей Абрамов:Впечатления. Во-первых, приятно узнать, что ты всю жизнь говорил прозой. Во-вторых, big data - это огромная область, и то, что произошло, что обсуждалось в первом докладе, - это снятие первых результатов в очень легкой пародии. Там, где их было легко и просто снять. Область намного богаче. Я думаю, что 90% проблем с большими данными не решаются этими технологиями. На самом деле, прозвучало несколько подходов: map reduce, потоковый подход, третий связан с дорогими, но эффективными способами хранения. Я думаю, что технологий будет больше. Важно, что проблема обозначена, но нет панацеи. Обозначены несколько точек роста, но, на самом деле, проблем и подходов будет больше. Еще интересен самый первый график из первого доклада, что мы находимся рядом с вершиной, надо успеть, чтобы поучаствовать. Все будет, когда снимутся первые очевидные сливки: map reduce, потоки. Невозможна, если мы говорим про разнородные данные, работа map reduce. Если мы говорим про мама грид, то сначала надо свести разнородные куски, чтобы потом получить возможность абсолютно параллельно их прорабатывать.
Вячеслав Нестеров: Не все задачи big data сводятся к разнородным данным. Иногда это однородные данные.
Игорь Рубенович Агамирзян: Если можно, я добавлю. На самом деле, надо понимать, что если данные потоковые, а у нас очень большой объем таких данных сегодня, то там есть еще одна такая специфическая вещь, как время. Синхронизация для обеспечения сравнимости. А это, кстати говоря, может приводить в больших масштабах к определенным проблемам. Это первое. Второе, я совершенно согласен с тем, что есть некая поляна, и в ней еще не определены фокусные точки. Вообще-то, все относительно. Когда начинается разговор о реальном времени, не могу не вспомнить анекдот, лично со мной произошедший. Еще в советские времена у меня был программистский кооператив, и ко мне пришли люди на тему автоматизации из мелиораторов. Они долго нам рассказывали про сложные задачи управления оборудованием, а потом они сказали, что все это должно происходить в реальном времени. Меня дернуло спросить, какие у них ограничения по времени. Они и сказали "часов 12", у них свое реальное время. На самом деле, это тоже задача реального времени, но она совсем другая. Поэтому просто так на этой оси есть некое положение. Практика бизнес-развития разных технологий показывает, что на этом поле возможностей всегда есть одна или несколько потенциальных ям, куда все и сваливается, где будет точка прорыва, наиболее эффективные приложения. У меня такое ощущение, что в области, связанной с big data, топология этого поля, нахождение этих потенциальных ям на данный момент пока еще не определено. И это, наверное, как раз и есть главная задача с точки зрения того, куда наука будет двигаться дальше.
Сергей Карелов: Я хотел добавить три момента, которые так или иначе звучали, но стоило бы на них особо обратить внимание. Момент первый - все-таки , что такое big data. Говорилось про то, что это 3 V - объем, скорость, вариабельность данных. На самом деле, это всего лишь данность. Очень много данных набирается в мире, в индустрии и бизнесе. Этих данных стало так много, что возникла мысль делать с ними нечто иное, чем делали до того. На самом деле, big data - это не эволюционное развитие процессов быстрой обработки информации. Фишка заключается в том, что это новая парадигма обработки информации, IT. Если раньше до big data была задача, которую надо решить, надо делать алгоритмы, которые ее будут решать, надо искать данные, то здесь меняется сама парадигма. Данных так много, и они настолько разнообразны, что там черт знает что лежит. Можно найти тот самый стратегический инсайд и процесс принятия решений. К сожалению, это очень мало звучало. Но на самом деле, вся история big data - для принятия решений на новом качественном уровне на основании той информации, тех знаний. Здесь big data появилась как новая парадигма. Нет рынка big data. Все спекуляции по поводу того, что сейчас 28 миллиардов, потом 53 миллиарда - нет такого рынка, для которого появилось много данных, и появились инструменты. Инструменты, из которых Hadoop - вообще 0,5-1%. А инструментов же море! На самом деле, фишка в той самой аналитике, которая позволит вынуть стратегический инсайд и процесс принятия решений. Сейчас сошлись на том, что к 2020 году не будет понятия big data вообще. Потому что все будет big data. Это перейдет в новую парадигму, а старая вообще уйдет. Существует две проблемы. Первая, про которую мы говорили, но она заслуживает того, чтобы быть повторенной еще раз. Все упирается в людей. Big data - это люди. Если нет вертикальной профессиональной экспертизы, если нет бизнес-кейса, забудьте про big data. Суперкомпьютеры вообще из другой области, тут нет проблемы суперкомпьютеров. Тут есть проблема, что нет людей, нет тех самых аналитиков, и нет бизнес-кейсов. Если вы посмотрите на халф-цикл big data, то вы обнаружите, что он состоит не только из технологий. Еще из новых бизнес-кейсов, из новых источников и способов работы с информацией. Именно в этом и будет прорыв. Последняя проблема. Дело в том, что свалить много параллельно распределенной информации и абсолютно разнородной информации - уже сейчас это кое-как решают. Никак не могут решить проблему, каким образом эти данные разнородного формата затачивать под один бизнес-кейс. Упоминалась компания Palantin. На самом деле, это, пожалуй, единственная на сегодняшний день компания, которая научилась это делать. Научилась сливать потоки информации, идущие от обработки кредитных карточек, от отпечатков пальцев, от операций с транспортом, из health care. Но их живенько погребли, и около 90% они сейчас работают исключительно на Пентагон и ЦРУ. А эта задача - super challenge для big data, потому что еще раз big data - это не big data, а big money. И это даже не те технологии, о которых идет речь. Как суметь вынуть стратегический инсайд, перевести процесс принятия решений на совершенно другой уровень. Но это находится в самом младенчестве. Говорить о том, что состояние big data есть, - никакого нет, только начали. На эту парадигму надо переходить. К 2020 году обещают начать переходить.
Сергей Кербер: В продолжение последнего комментария. Хотел задать вопрос собственно бизнесу. У меня возникал тот же вопрос. Коллеги, а как вы это продаете? Вы сегодня говорите, что у вас 1% продаж - big data. Как вы ее продаете? Если вы продаете серверы, понятно, все пользователи знают, что им нужны серверы. И кто к кому приходит, с чем приходит, какие есть стандартные решения.
Игорь Рубенович Агамирзян: Можно на правах модератора и человека с 15 годами опыта работы в multinational отвечу сначала я? Потому что я не связан корпоративной политкорректностью. Мое представление о том, почему это стало интересно крупным корпорациям. Исключительно по одной интересной логике. Если есть что-то такое, что ты не можешь предотвратить, то единственный способ правильно себя вести - это возглавить.
Леонид Жуков: Я могу привести пример не о продаже, а о покупке. В компании, где я сейчас консультирую, есть следующая ситуация: 11 петабайт данных хранятся в обычных SQL базах под Microsoft-серверами. Microsoft решил изменить политику и брать деньги не за процессор, а за ядро. Неожиданно компания залетает, ну очень сильно. Компания дальше говорит "нет, так дело не пойдет, давайте искать варианты", приходят Cloudera и все эти ребята и говорят "не вопрос, в 50 раз дешевле".
Сергей Абрамов: Было сказано, что подходы были не для Oracle. Oracle пришли не для big data.
Игорь Рубенович Агамирзян: Это было бы очень странно, если бы это было не так.
Леонид Жуков: EMC и IBM тоже очень хорошо с Hadoopом работают.
Сергей Лихарев: Есть хороший пример с ветряками. Чтобы ткнуть в место на карте, где ветряк будет установлен (а это огромные инвестиции), они анализируют погоду в этой точке, кучу всякой информации. Их единственная задача - выбрать место. Они пробовали решить эту задачу разными способами, они не могут сопоставить данные и в разумное время обработать без big data. Хотя вопрос в несколько месяцев, не лет. Нужно быстрее, заказчики требуют быстрых решений. Другие примеры, любой банк. Информации о заказчиках много, а вот почему они это делают, в чем причина - непонятно. Давайте проанализируем, что они пишут о нас, о наших конкурентах, почему они это делают. Это продается, когда мы можем объяснить, как из новых данных или обработки большого объема в конце получатся деньги - либо меньше затрат.
Вопрос из зала: В первую очередь, как я понимаю, все равно клиент приходит к вам с проблемой?
Сергей Лихарев: В этом случае не так, на самом деле. Вот то, что сейчас происходит. Часто клиент, наслушавшись этого всего, говорит: "Помогите мне, объясните, что такое big data и где возможные области применения". Мы приходим и рассказываем, а дальше они начинают думать, или мы вместе с ними. Есть возможность говорить про стриминг, быструю обработку больших объемов разнородных данных. У клиента есть математика в голове, но он пока не может это поддержать и просит рассказать о технологиях.
Я говорил про это, компания TerraEchos в Америке защищает периметры. Они анализируют звук, прокладывают оптоволоконный кабель по периметру объекта. В конце они могут сказать, что сейчас идет человек, вот это пробежала собака. Просто анализируя изменения. Они используют нашу обработку, принимают решение и разрабатывают его.
Вячеслав Нестеров: Я, конечно, ничего не продаю. Но насколько я знаю, как проходят продажи. Есть инженеры, data-аналитики, они снабжены необходимыми средствами и пониманием, как это надо делать. Потом эти люди идут к заказчику, вникают в его бизнес, довольно много там проводят времени - и предлагают свое решение.
Игорь Рубенович Агамирзян: Тогда у меня вопрос. От IBM и EMC прозвучало то, что это direct sales проекты. До сих пор не появилось перепродажников?
Сергей Лихарев: Почему? На самом деле, это тенденция… Партнеры тоже видят этот рынок. И они говорят о том, что хотят создать центр компетенций big data, например, по энергетике. Будем искать кейсы и предлагать решения, потому что, в конце концов, абстрактный Hadoop никому не нужен. Hadoop направлен на обработку определенных данных, чтобы получить определенную ценность. Идет процесс, когда интеграторы выбирают, как играть.
Александр Брызгалов: У меня короткий вопрос. А можно пустить всю интеллектуальную мощь big data на прозаический процесс, идеальный подбор мужчин и женщин? Это решит все.
Леонид Жуков: Это называется алгоритм marriage. В Америке так работают алгоритмы для людей, закончивших институты, по подбору госпиталей, где они будут проходить ординатуру. Госпиталя выбирают, кого они хотят принять, а студенты дают выбор из нескольких госпиталей, где бы они хотели работать и дальше учиться. Дальше проверяются разные комбинации и делается выбор. Это оптимальный подбор персонала, и он работает уже, наверное, лет 20.
Сергей Карелов: Хотел добавить несколько слов по поводу продажи big data. Она не продается как технология вообще, продаются только кейсы. У вас есть кейс, вы знаете, как сделать это , повысить качество решений. Еще один момент, который не прозвучал, но достаточно важный: соотношение между продажами софта и консалтинга в big data - 1 к 20. На каждый доллар софта 20 долларов консалтинга. Проблема заключается в том, что у партнеров, например, в России нет опыта, кейсов. А поскольку все привязывается к вертикальной отраслевой экспертизе, то здесь получается ловушка 22. Дело в том, я сейчас просто хочу сказать, если вы поговорите с американцами, они сейчас снова потирают руки и говорят, что пришла их игра. У них как раз есть тысячи компаний, маленьких, которые все это делают. А крупные киты типа IBM всасывают эту экспертизу в себя вместе с партнерской сетью. Cloud social, mobile - новая революция, ребята все под себя подгребут.
Леонид Жуков: Подождите секундочку. Я хочу просто напомнить, что технологии открытые. Это значит, что любая компания в России может взять эту технологию и завтра пойти и продавать ее. Я говорю про технологии вокруг big data. Скажите мне неоткрытую технологию.
Игорь Рубенович Агамирзян: Не надо! Пример уже звучал от Славы.
Леонид Жуков: Это не технологии, это appliance.
Сергей Карелов: Помимо технологии хранения, вся аналитика закрыта.
Леонид Жуков: Кому она закрыта? Алгоритмы машинного обучения всем известны, половина из них работает в России.
Сергей Карелов: Послушайте, autonomy за 14 миллиардов была куплена за ее открытые алгоритмы? Да вы что!
Леонид Жуков: Байесовские оценки нельзя самому написать, алгоритм Байеса? Я студентов учу Байесовским алгоритмам. Вы понимаете, я пытаюсь объяснить следующее, что алгоритмы известны и не запатентованы. Приложения сделать можно. Я просто хотел сказать, что здесь нет никакого секрета. Американцы смогли это сделать и пойти вперед, это их заслуга, но ничего не мешает сделать то же самое.
Игорь Рубенович Агамирзян: У меня здесь есть некое принципиальное соображение. Я слышу то, что вы говорите, однако, в данном случае я склонен быть согласным с Сергеем. То, что есть известные алгоритмы, совершенно не значит, что будет работоспособное решение. То, что когда-то Microsoft сделал Microsoft Windows, не значит, что можно сделать новую операционную систему в России. В точности та же самая ситуация. То, что сделана система аналитики на профессиональном уровне, совершенно не значит, что можно ее воспроизвести. Я могу привести массу примеров. Когда той же компании, которая разработала серьезный продукт, не удалось сделать на него реинжиниринг.
Леонид Жуков: Подождите, сделали Linux, и он лучше, чем Windows.
Сергей Карелов: Сделали visual data mining - это один из главных кусков аналитики big data. С тех пор появилось что-то у нас в этой области? Там все просто. Там вообще все алгоритмы известны, но разве хоть что-нибудь у нас появилось? Посмотрите, что за это время появилось в Штатах. Там сменилось три поколения, три разных подхода. Поэтому алгоритмы все известны.
Леонид Жуков: В чем тезис нашего спора? В том, что на открытых идеях ничего нельзя сделать, или в том, что мы ничего сделать не можем? Сейчас в компаниях, где я консультирую, data scientists - 10 человек команда, из них 8 человек русских.
Игорь Рубенович Агамирзян: Это совершенно не удивительно. Раз уж на эту тему разговор зашел, в Microsoft есть компонент для витрин данных, это точно российская компания, которая через Израиль попала в Америку. Ничего не значит, что у нас нельзя сделать. Просто есть артефакты, которые невозможно скопировать. Можно сделать другой артефакт, как Вы привели пример с Linux, который оказывается конкурентным, сопоставимым. Честно, я не согласен, когда говорят, если все алгоритмы известны, можно сделать. На практике это не так.
Леонид Жуков: Yandex - успешный пример разработки больших технологий.
Олег Юхно: Это вопрос несколько другого характера. Мы решаем сложную задачу, но способом, который приемлем для нас. Потому что даже Hadoop обладает рядом недостатков, которые для нас неудобны. Мне кажется, в свое время был компьютер не для простого человека. По мере роста количества data scientists, у нас появится качественный перелом, когда появится продукт, аналогичный Windows. Он позволит достаточно просто моделировать ситуации, пусть и не совсем корректно. Когда это будет, будет много очередей в магазины, связанные с этим.
Сергей Абрамов: Маленькое извлечение. Как любая горячая отрасль, я уже на семинаре увидел два примера, что называется, нано-асфальта. Коллеги, пульс младенцев - это не big data. Проводится просто проверка сигнала , корреляционный анализ прямо на месте. Точно так же big data начинается и заканчивается на видеоанализе лиц покупателей, после этого идет пальцевый отсчет - 20 вошло. Это тоже не big data, поэтому в этой области будут нано-бетоны, асфальты и прочие вещи. Второе, что действительно было существенно, - это новая парадигма. Нам мой взгляд, есть действительно серьезная вещь, которая дистанцирует big data и не big data. Раньше были алгоритмы, писались программы, а потом под них собирались данные. А теперь есть данные, а что решать - не знаем. Давайте придумаем, что при помощи этого надо порешать.
Игорь Рубенович Агамирзян: Напомню, лет 30, может, 25 назад было довольно много работ по программированию от данных. Потом это направление с развитием традиционного классического мейнстрима просто сошло на нет. Может быть, сейчас это возрождается, но последние лет 15 я вообще не видел ни одной публикации.
Марк Шмулевич: 8 лет назад, занимаясь data clastering, одной из самых больших проблем было найти хорошие данные. Правильно понимаю, что сейчас все наоборот?
Леонид Жуков: Нет, тоже проблема найти чистый data-set.
Вячеслав Нестеров: Во-первых, чистый, во-вторых, они обычно находятся в собственности у людей. Нужно их как-то доставать у тех людей, у которых они есть, которые в этом не заинтересованы. Третье - регуляция, конечно. Очень много что связано с персональными данными, по закону этот data-set нельзя никому отдавать. Возьмите поликлиники, хорошо бы собрать big data по поликлиникам, их надо обезличивать, специальные технологии обезличивания существуют.
Игорь Рубенович Агамирзян: Это вопрос о регуляторном воздействии на работу с данными, очень важный, он не менее важен, чем вопрос с безопасностью. Опять, по моему опыту в EMC. У них есть один продукт, Синтерра, по-моему, который является нестираемым storage. Я когда узнал об этом сам, недоумевал, а потом оказалось, что это связано с регуляторными воздействиями. По американскому законодательству определенные типы данных должны храниться всегда. У нас до сих пор никто ничего близкого не использует. Например, данные о корпоративной переписке, hr-данные хранятся. Период определенный длительный.
Олег Симаков: Когда мы говорим о персональных данных, мы, по-моему, преувеличиваем. Достаточно разнести персональные данные, демографические данные, которые не являются секретом, и данные семантические, медицинские, любые другие, на два хранилища, между ними связать таблицы, мы получим разнесение.
Вячеслав Нестеров: Решения существуют, но они не такие прямолинейные.
Вадим Сухомлинов: Имеет ли смысл вводить ограничения на то, что можно получить из тех данных, которые доступны и легальны? Потому что в принципе можно сопоставить информацию - и предположить о том, что у человека в настоящий момент времени что-то происходит, а для человека это может быть нежелательно. Хотя все информация открыта, и он согласился со всеми доступами.
Игорь Рубенович Агамирзян: Слава Богу, что еще мониторинга по мобильным телефонам в открытом доступе нет. При триаргуляции станции можно получить столько информации!
Комментарий из зала: Сколько разводов будет.
Константин Скрябин: По английскому законодательству, когда человек выходит из тюрьмы, вы обязаны уничтожать его генетические данные, когда он приходит в тюрьму, вы их берете.
Леонид Жуков: Я тоже немного хотел высказаться и встать на защиту пульса младенцев. И сказать по поводу того, причем здесь big data. Большие данные не в том, что мы анализируем каждый удар и т.д. Если мы знаем, что мы ищем, это не big data. Вопрос в том, что мы не знаем, как выглядят эти записи у младенцев, которым потом стало плохо. Это как раз big data. То же самое относится к соцсетям и предсказаниям. Если вы знаете зарплату окружающих вас друзей, ваша зарплата будет среднестатистической, возраст - также. Это очевидно: вы дружите с людьми примерно одинакового с вами статуса и бэкграунда. На самом деле, big data позволяет находить паттерны, о которых вы не знали.
Сергей Лихарев: Здесь есть хорошая аналогия одна, простите. Вспомните, как золото раньше добывали. Человек видел самородок, возводились города вокруг, чтобы добывать дальше. Я точно знаю, что эти данные полезные, я строю город, хранилища, туда их складываю, очищаю, создаю инфраструктуру. Раньше не рыли соседнюю гору, а город уже надо строить. Сейчас мы можем себе позволить перемалывать эту руду в надежде, что мы там что-то найдем, и сейчас это действительно можно делать относительно дешевым способом. Мы сейчас пришли к ситуации, когда технологии позволяют, действительно не делая мегазатрат, обрабатывать всю доступную информацию и доставать оттуда возможно необходимую нам руду. Мы можем себе это позволить, получается разница между тем, что было, и тем, что сейчас есть. То же самое сейчас происходит с данными. Мы говорим, что не будем строить эти хранилища, не будем очищать каждый кусочек данных. Мы возьмем его, как он пришел к нам, и потом пороемся в нем. Самое интересное, что современные золотодобывающие компании не выбрасывают руду. Они через несколько лет откроют новый способ из нее что-то дополнительное получить. Она лежит, то же самое мы сделаем с данными. Через 5 лет мы потом подумаем, что это для нас ценное, когда возникнет новый паттерн. Это как раз про большие данные.
Сергей Карелов: Есть темная энергия и темная материя, а это темная информация . Ее сейчас 80%, посчитали.
Игорь Рубенович Агамирзян: Коллеги, уже 9 часов, я заметил. Хочу выразить глубочайшую признательность выступавшим и надеюсь, что такая интересная встреча происходит не в последний раз.
Новые горизонты Big Data. Часть 1
Новые горизонты Big Data. Часть 2