Игорь Рубенович Агамирзян: Мы рады вас приветствовать на нашем уже ставшем традиционным экспертном семинаре. В первый раз мы собираем его в нашем относительно новом офисе, мы сюда переехали в октябре. Надеемся, в дальнейшем будем проводить его более часто и на своей площадке. Я сегодня занимаю пассивную позицию, потому что самому интересно послушать. Тема в последнее время стала чрезвычайно популярной - по большим данным, по тому, как с ними эффективно работать и их использовать. У меня самого в данном случае ни опыта, ни личного мнения особого нет, хотя я знаю, что около 10 лет назад, когда уже стало можно обеспечивать доступ к большим массивам данных посредством интернета, это стало некоторым новым толчком для развития разных направлений, в том числе и в науке. Здесь я могу сослаться на мою любовь юности - астрономию. Астрономы в конце 90-х - начале 2000-х неожиданно обнаружили, что если просто сравнить накопленные в разных обсерваториях за один период знания, можно сделать новое открытие, не проводя других наблюдений. Это был неожиданный тренд, сегодня он становится все более общепринятым и для других научных направлений. Несомненно, он оказывается глубочайшее влияние на все направления технологического бизнеса. Его приложения с обработкой данных и коммуникацией стали абсолютно новой платформой во всех секторах, индустриях и научных направлениях. Сегодня с нами заместитель министра связи и массовых коммуникаций Марк Шмулевич, который как раз в министерстве возглавляет направление, связанное с информационными технологиями. Я на этом заканчиваю и хочу передать слово Марку, который спозиционирует наш разговор с точки зрения органов власти. Спасибо.
Марк Шмулевич: Спасибо большое, Игорь Рубенович. Во-первых, начну с комплимента вашему новому офису и очень красивому и светлому бизнес-центру, где я первый раз нахожусь. Во-вторых, действительно не секрет, что большие массивы данных - это одно из тех направлений IT, которое входит в одни из самых перспективных направлений развития. Фактически, перечни направлений, в которых раздел IT будет развиваться в ближайшие три-пять лет, различны в зависимости от того, кто их составляет. Но мы смотрим разные варианты, чтобы определить наши приоритеты в развитии. У меня есть личная история, начну с нее. Когда я занимался анализом данных в аспирантуре Физтеха лет 8 назад, это было интересное направление, не очень многие им занимались, но многие думали и говорили, что оно выстрелит. Прошло не так много лет, но уже нет никаких сомнений, что направление выстрелило, что количество применений данных растет экспоненциально - так же, как и количество неструктурированных данных, которые нужно обрабатывать. Если говорить о прикладной сфере, где большие массивы данных сейчас помогают, бывают совершенно неочевидные направления. Для меня, например, было неизвестно, что технологии анализа данных активно применяются полицией, и это, естественно, помогает при раскрытии преступлений. На Амазоне продается книжка под названием "Big data analysis for CEOs", и несколько бизнес-школ рассматривают краткий курс техники анализа данных для менеджеров. Таким образом, big data сегодня - это не только область науки, но и очень быстро становящаяся частью нашей повседневной жизни область. Сейчас в Минкомсвязи России появилось отдельное направление, связанное с развитием отрасли информационных технологий, которой я и занимаюсь. Мы считаем, что развитие научных исследований в этой области - один из первых приоритетов. Так же, как и благоприятный налоговый режим для работы компаний в России, инвестиции в человеческий капитал. О науке ни в коем случае нельзя забывать. Мне будет очень интересно услышать ваше мнение про то, что сейчас происходит в России в области big data как в науке. Может, мы услышим что-нибудь в сегодняшних докладах. Но у нас было достаточно печальное ощущение, когда, стараясь понять, где находится сейчас Россия в области исследований computer science вообще, мы увидели, что в среднем ответ экспертов был такой: "в пятидесяти нет". И это беда. Мы всячески будем поддерживать, в первую очередь, исследования big data, поддерживать по-разному: популяризируя, какими-то финансовыми инструментами, грантами, когда это будет возможно. Сегодня это уже возможно - в рамках пока других программ. Мы надеемся, что, в частности, в области исследования больших данных в России скоро поменяется ситуация. Игорь Рубенович сказал про астрономию, я тоже хочу про нее сказать. Буквально сегодня смотрел некоторые новые данные. Например, если пойти на один из крупнейших сайтов, помогающих найти работу, и сравнить big data science и astronomy, мы увидим, что средняя начальная зарплата для PhD в астрономии $50000, а в data science - $100000. Количество открытых вакансий для астрономов - 335, а для data science - 140000. То есть я уверен, что в России пока такое время не пришло, но оно обязательно придет. Мне кажется правильным, что к этой теме приковывается достаточно большое внимание. Мы регулярно встречаемся с исследовательскими институтами и вузами, в которых проводятся исследования, обсуждаем и видим, что внимание растет и оно большое среди тех, кто начинает работать в этой среде сейчас. В конце выступления, наверное, покажу очень интересную картинку. Наличие такой книжки, наверное, тоже показывает, что big data быстро входит в нашу жизнь. Спасибо! И будет очень интересно послушать.
Леонид Жуков: Добрый день, я профессор Высшей школы экономики, также консультирую американские компании, занимаюсь вопросами больших данных. Во-первых, хочу сказать большое спасибо организаторам за то, что пригласили меня на этот семинар, и участникам за то, что пришли сюда послушать. Я очень рад, что тема вызвала такой большой интерес. На самом деле, она бескрайняя. Я попытаюсь осветить некоторые аспекты, поговорим об истории, откуда вообще возникла эта идея обработки больших данных, и это поможет нам понять, куда индустрия двигается. Я также постараюсь привести некоторые примеры компаний, понять, что они делают, посмотреть на основы технологий больших данных. У нас будет несколько технических слайдов. Дальше озвучу несколько мыслей по поводу того, куда вся эта индустрия будет двигаться. Если будут возникать вопросы по ходу рассказа, пожалуйста, прерывайте, пообсуждаем. Также хочу сказать, что как профессор я занимаюсь исследованиями в области больших данных, исследованиями в области машинного обучения. Мой предыдущий опыт стартапера позволяет мне на это смотреть с точки зрения потребителя больших данных. В отличие от моих замечательных коллег-докладчиков, я не произвожу системы больших данных, я использую эти системы для своей работы. Поэтому мой взгляд на эту проблему будет со стороны пользователя.
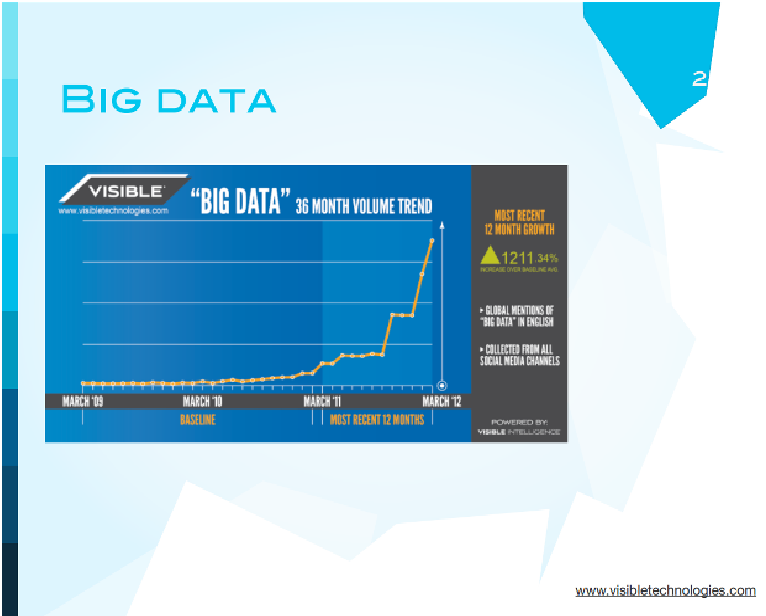
Вообще говоря, впервые термин больших данных появился в начале 2009 года, а дальше, если вы обратите внимание, начался экспоненциальный рост где-то весной 2011 года. Это связано не только с тем, что технология стала более популярной, но и с достаточно прозаическим фактом.

McKinsey опубликовала ставший знаменитым отчет о том, что big data - следующий шаг для инноваций, соревнований и повышения производительности. Они написали о том, что Facebook обрабатывает порядка 30 миллиардов элементов контента каждый месяц, Конгресс США обрабатывает порядка 240 терабайтов данных каждый месяц. Также они сделали оценку этого рынка, и именно эти данные заставили людей посмотреть внимательно на отчет. На самом деле, эта тема была, конечно, создана в какой-то момент McKinsey.

После публикации этого отчета об этом заговорила вся пресса. Все пишут о big data, о том, как это можно использовать, о том, что это будет революция. Не только термин big data, но и другие термины стали теперь популярными. Например, data driven business - и любой бизнес хочет стать именно таким. Под этим понимается, что любой бизнес хочет принимать решения, основываясь не на интуиции исполнительного директора, а на данных, которые он получает. Также появился очень популярный термин "демократизация данных". Здесь идея заключается в том, что не только аналитики и инженеры должны иметь возможность смотреть на данные, но и любой бизнес-персонал компании.
Белый Дом не остался в стороне от этого тренда, и в 2012 году они объявили инициативу: предложили всем подразделениям создать конкурсы, на которые следует пригласить людей для работы над большими данными. Это оказалось очень важным для страны.
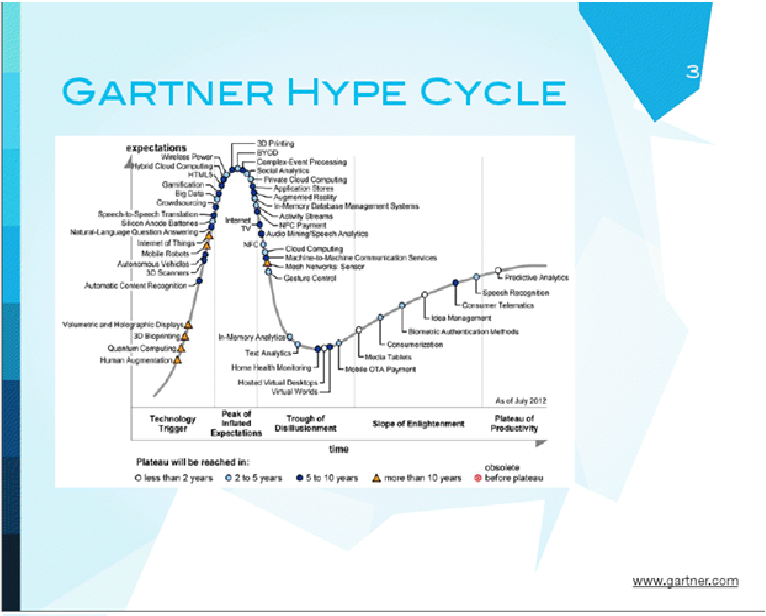
Если мы посмотрим на знаменитый цикл инноваций, который делает Gartner, то мы увидим, что big data, которая указана на этом цикле, двигается к своему пику популярности. Надо заметить, что после него обычно происходит спад, а потом, если технология хорошая, она выходит на стандартный рабочий уровень. Сейчас этот цикл написан для 2012 года, мы двигаемся на самый верх. Тема очень популярная.
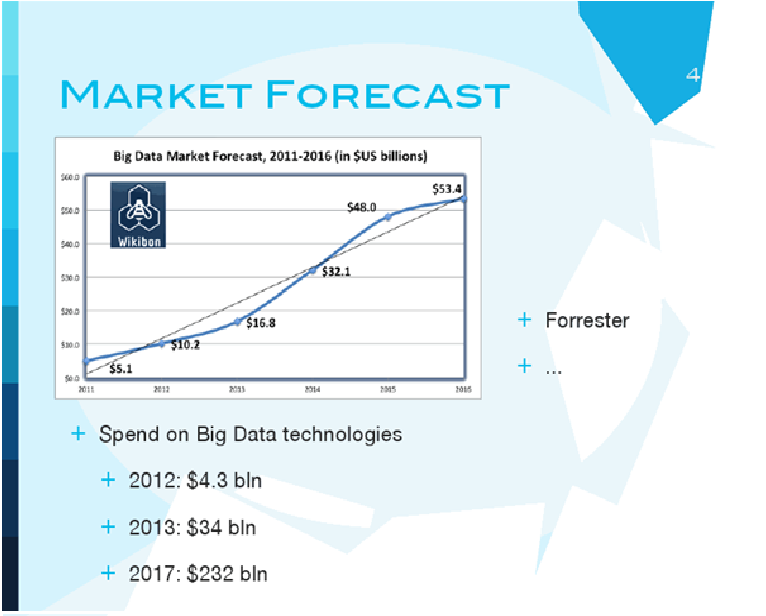
Все это, конечно, привело к фантастическим оценкам будущего этого рынка. Одно из самых скромных предсказаний - к 2016 году рынок составит порядка 53 миллиардов долларов. Есть и большие оценки - к 2017-2018 годам будет порядка 200 миллиардов долларов. Венчурные капиталисты не ждут, а вкладываются в стартапы, в которых есть слова big data. В 2009 году было примерно 1,1 миллиард вложено, в 2011 - уже 2,5 миллиарда., в 2012 уже порядка 4 миллиардов долларов венчурных денег было вложено в стартапы, которые занимаются обработкой и анализом больших данных.
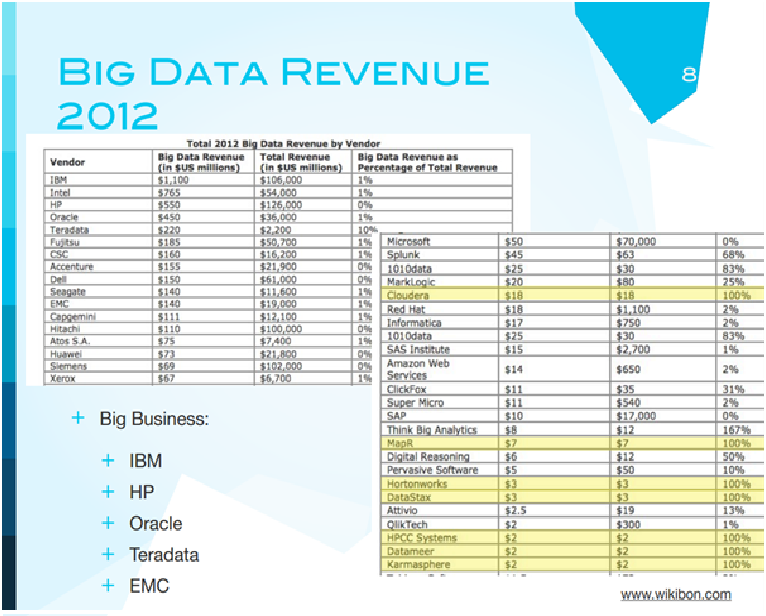
Однако, большие данные - это не только будущее, но и настоящее. Здесь, в этой таблице, собраны данные по компаниям за 2012 год, которые тем или иным образом связаны с большими данными. Наибольшие доходы, конечно, у IBM, HP, Oracle, Microsoft, и это, естественно, связано с тем, что в больших компаниях большой бизнес, они занимаются хранением и обработкой больших данных. Но более интересно посмотреть сюда. Процент от полного дохода, получаемого от big data, у IBM, например, только 1%. То есть для рынка это большой доход, а для компании - очень маленький.
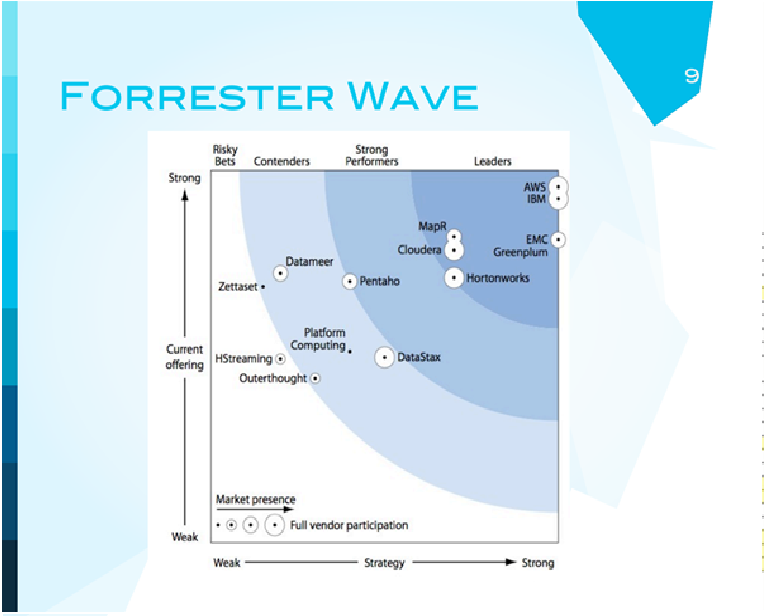
Сегодня я постараюсь говорить о компаниях, в которых 100% дохода - big data, это стартапы. Мы поговорим о том, что они делают. Нельзя говорить о ситуации в бизнесе, не показав Forrester Wave. По осям у нас показано то, насколько сильные стратегии игроков, вертикальная ось - нынешнее предложение. В самом углу мы видим как сильнейших игроков MC, IBM, и они там не случайно. Есть еще и Amazon Web Services. Нас будут интересовать эти три компании сегодня в первую очередь. Почему? Эти компании распространяют технологию Hadoop - ту технологию, которая используется для обработки больших данных. Эти компании делают и предоставляют надстройки над Hadoop, дополнительные сервисы, аналитику, визуализацию - следующий шаг.
Прежде чем говорить о big data, надо разобраться в том, что же это значит. McKinsey сами по себе дают следующее определение: Big data - данные, которые вы не можете обработать традиционными средствами. Есть другое определение, которое говорит о том, что это феномен, определяющийся быстрым, ускоряющимся развитием, расширяющимся объемом данных и их сложностью. Мне, честно говоря, наиболее близко третье определение. Big data - коллекция инструментов и технологий, которая позволяет продуктивно работать с данными независимо от масштаба этих данных. Есть еще и четвертое определение: "три V": volume - данные уже обладают объемом, variety - представлены данные самого разного типа, velocity - скорость, с которой приходят данные. Ясно, что для того, чтобы работать с большими данными, требуется их распределенная обработка, и в принципе, большие данные - это, с одной стороны, хранение данных, с другой стороны, их обработка, причем желательно все это вместе. Существует такое мнение: когда говорят о больших данных, говорят о Hadoop. Это не единственная технология, существуют более традиционные технологии, которые сейчас масштабируются. Но тем не менее, если рисовать картинку, есть пересечение big data, большой темы, есть Hadoop, технология, которая позволяет производить вычисления, и cloud computing. Big data и cloud computing - это не одно и то же, это разные вещи.

Давайте посмотрим на эту картинку просто ради интереса. Кто знает все слова, которые здесь написаны? Вы знаете? Ребята, вы инженеры. Кто знает половину слов? Это нормально. Когда создается новая индустрия, что делают люди? В первую очередь, изобретают свой сленг, свою терминологию, которую будут использовать. Это терминология, которая используется сейчас в big data, человеку непосвященному, со стороны, она вообще ничего не скажет. Это происходит потому, что это названия самых разных продуктов, которые используются в системах обработки данных. Почему они так странно названы? Половина из них создана стартаперами, другая половина создана в больших компаниях, которые представляют себя стартаперами. Я очень надеюсь, что к концу лекции некоторые названия для вас будут хоть что-то значить.
Что такое вообще big data, насколько она большая? Google обычно очень скромничает и не показывает свои цифры, но говорят, что он обычно обрабатывает около 24 петабайт данных в сутки. Твиттер - порядка 7 терабайт данных добавляется каждый день в хранилище. На Facebook 12 терабайтов контента каждый день. Именно это и есть масштабы, о которых идет речь. На самом деле, работать с большими данными и обрабатывать их люди начали очень давно. Если вспомнить, начиная с 60-х годов существовала тема под названием "суперкомпьютеры", в нее вкладывались большие деньги. Национальные лаборатории, университеты. Единственное, что задачи были немного другие. Как правило, на суперкомпьютерах обсчитывались не большие данные, а сложные вычислительные задания, когда требовалась большая мощность процессора. Но также могли и считаться большие модели с данными.
Почему суперкомпьютеры не пошли в индустрию? Все очень просто. Потому что они очень дорогие. В середине 90-х годов поток денег на суперкомпьютеры стал уменьшаться, и ученые в лабораториях решили обойтись без суперкомпьютеров, но иметь возможность справляться с большими и трудными задачами. Тогда возникла идея о кластере из большого количества маленьких компьютеров, соединенных обычной технологией, использующих ту же самую парадигму программирования, как и суперкомпьютеры. Дешево и сердито. Проблема следующая: как только вы соединяете много дешевых компьютеров, вероятность поломки одного из тысячи компьютеров очень высока. Поэтому такие системы, несмотря на их дешевизну, оказалось почти невозможно использовать.
2000-е годы - новая реальность - появляются большие компании, появляется Yahoo, Google, компании, которые работают на потребителя, собирают информацию со всего интернета, огромные количества данных. Они хотят зарабатывать деньги рекламой, они должны обрабатывать e-мейлы, e-commerce - куча всяких предпосылок. Понятно, что в то время эти компании пока еще не могут позволить себе суперкомпьютеры. Например, сейчас Google может себе позволить суперкомпьютеры, а тогда не мог. Тогда все говорили о commodity hardware - обычных дешевых pc, о том, как можно обработать огромные объемы данных на маленьких pc. Опыт суперкомпьютеров не подходил, просто потому что pc ненадежны. Google озадачился этим вопросом в 2000 году, создал у себя систему. И на удивление людям в 2003-2004 году вышли две статьи, которые перевернули все понимание.
Одна статья была о файловой системе, которая используется внутри Google, а другая статья предлагала технологии для обработки данных. Эти две статьи положили начало современной технологии обработки больших данных.
Следующие 2-3 слайда будут техническими, я постараюсь руками объяснить, что происходит, если получится, будет хорошо.
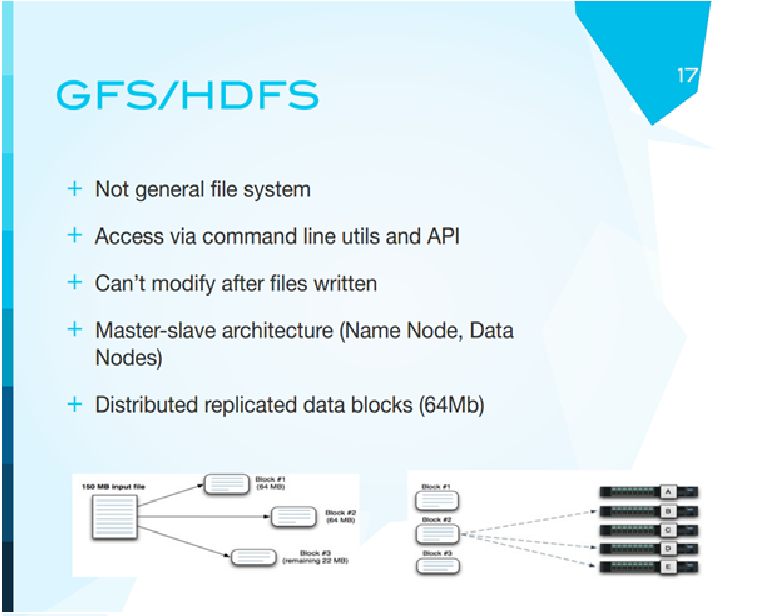
Из-за того, что наши компьютерные системы ненадежные, часто выходят из строя, как бы нам сделать так, чтобы поломка одного компьютера не мешала вычислениям? Идея была следующая: не хранить файлы на каждом компьютере. Взять файлы, разбить их на маленькие кусочки, сами кусочки разбросать по разным компьютерам с дублированием. Таким образом, что если компьютер, на котором находится обрабатываемый кусочек данных, вышел из строя, ничего страшного не произойдет, копия этих данных лежит на другой машине. И будет некий мастер-сервер, который будет говорить о том, где и что находится. Это была первая идея надежной распределенной файловой системы Google.
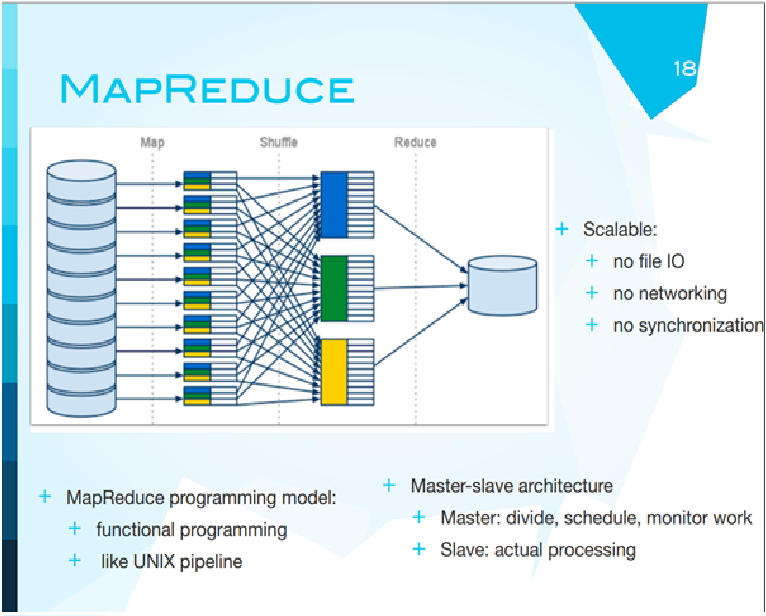
Вторая идея - map reduce, здесь идея следующая. Она хорошо работает, если к разным кускам данных можно применять одни и те же процедуры. Вам нужно посчитать, сколько раз каждое слово встречается в книге. Что можно сделать? Можно разбить эту книгу на главы, раздать эти главы на разные компьютеры. Каждый из них независимо будет считать количество определенных слов в своей главе, а в самом конце мы просто сложим эти числа. Таким образом, получится следующее: если один из компьютеров в процессе сломается и не сможет вычислить эти количества, ничего страшного. Мы просто запустим еще один с таким же кусочком работы. Самое главное, что работа всех остальных компьютеров не пропадет. Это идея map reduce. На самом деле, это очень большое упрощение по сравнению с тем, как все делалось на суперкомпьютерах. Упрощение связано с тем, что данные разбиваются на кусочки, каждый кусочек отправляется на отдельный компьютер на обработку, дальше данные собираются вместе, выводится результат.
Трюк заключается в том, что для суперкомпьютеров, для многих расчетов, например, ядерного взрыва или решения дифференциальных уравнений, эти машины должны друг с другом общаться. Если нет коммуникации, в суперкомпьютерах это называется простое параллельное программирование. Ученым это было неинтересно. Однако для бизнеса эта модель оказалась именно той, которая была нужна.
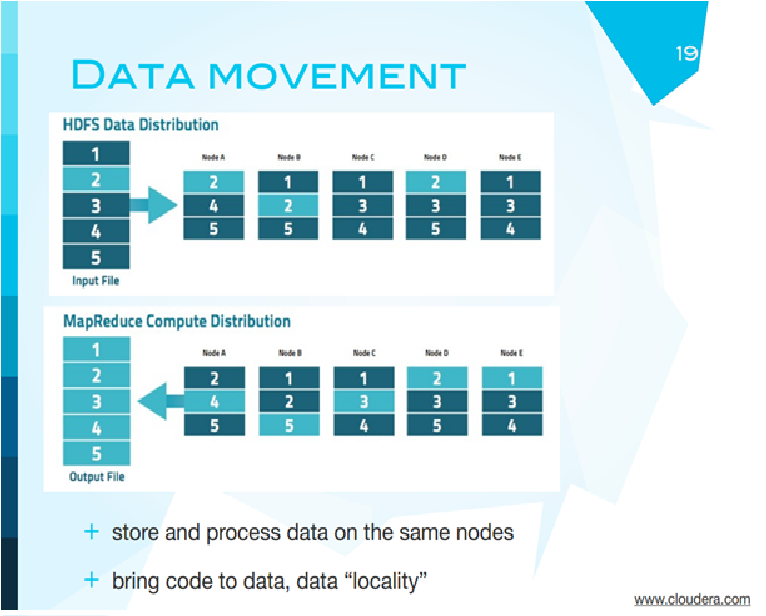
Еще раз повторюсь, чтобы было. Этот слайд очень хорошо иллюстрирует всю информацию. Представьте, что у вас есть некоторый файл с данными. Этот файл разбивается на 5 частей, эти части раздаются различным компьютерам с повторением. Дальше каждый из компьютеров выполняет обработку на конкретном данном ему участке, и результат передается обратно. Это и есть вся идея map reduce. Что случится, если умрет этот компьютер? Он работал над первой частью. Первая есть еще здесь и здесь. Когда этот второй компьютер закончит свою работу, он сможет обработать эту оставшуюся первую часть.
Важным моментом является то, что вместо того, чтобы посылать данные на компьютер, они принесли сами процессоры к данным. Данные изначально распределены, и дальше работа происходит на каждом участке отдельно. Это все насчет технологий. Я надеюсь, что это дает представление о том, какая технология лежит в основе всей системы.
Дальше события развивались очень интересным образом. Дак Каттинг, человек-оркестр, был консультантом, работал сам по себе, немного в Yahoo, занимался тем, что сам по себе писал поисковый движок. Каким-то образом он стал сотрудничать с Yahoo и решил, что надо написать еще и кроллер, систему поиска по web. Он большой поборник открытых кодов, поэтому все это был открытый код. Дальше в 2004 году ему попалась на глаза статья, написанная в Google. Он собственноручно написал Hadoop, имплементировал полностью всю систему. Hadoop, между прочим, - это имя этого слоненка, а слоненок - игрушка его ребенка. Эта система была названа так исторически, и дальше разные программные продукты люди стали называть разными именами. Например, zoo keeper - система, которая заставляет многие из этих продуктов работать вместе. То есть, фактически, Дак Каттинг - отец-основатель Hadoop.
Сейчас Hadoop, например, в Yahoo - это 40000 серверов, 170 петабайт хранилища. Там больше 100000 пользователей. Используется для фильтрации спама, категоризации, рекламы, для чего угодно.
Еще одно техническое замечание, как я и обещал, - революция так называемая NoSQL. SQL - стандартные базы данных в таблицах, к которым мы привыкли. Проблема в том, что это таблички, и когда таких данных много, и они взаимосвязаны, работать с ними тяжело. В табличку писать медленно, довольно сложно заставить ее работать с большим числом пользователей одновременно. Поэтому было предложено пожертвовать некоторыми свойствами настоящих баз данных, фактически хранить данные как простые файлы без всякой схемы.

NoSQL world - это теперь тоже большой зоопарк типов баз данных. Можно хранить как ключ и значение, как обыкновенную табличку, просто как документы, и новые графические базы данных, если вы хотите сохранить графы. Идея очень простая: уйти от баз данных, которые умеют все, но медленно и дорого, к чему-нибудь, что очень специализировано, заточено под конкретную задачу, но летает.
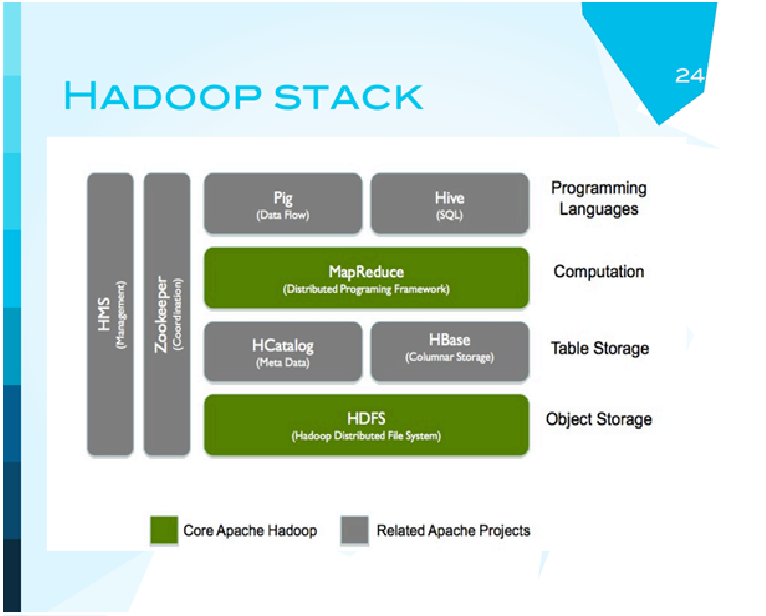
Hadoop теперь - это целый набор систем. Есть HDFS - Hadoop - файловая система, ее основание. Сверху на нее ставятся разные базы данных, причем базы как раз NoSQL, еще выше - система программирования map reduce. И сверху нее некоторые надстройки, которые позволяют людям-не-программистам работать с этой системой. Например, PIG. PIG - высокоуровневый скриптовый язык, который можно скомпилировать и превратить в MapReduced. Хайв - некоторая симуляция работы с обычными базами данных, которая также превращается в map reduced jobs. Это означает, что теперь аналитики в принципе могут пользоваться хайвом, для них это будет выглядеть более или менее как работа с обычной базой данных. Но внизу будет современная распределенная технология.
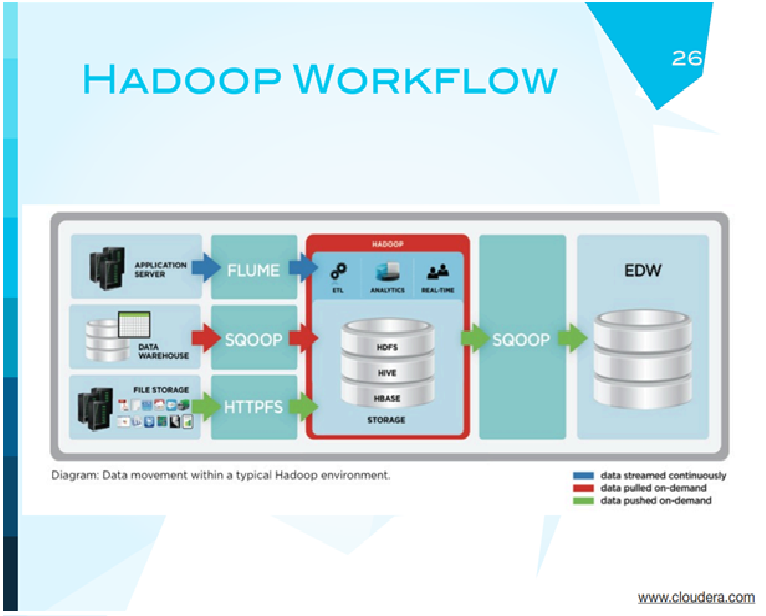
Типичный поток обработки информации на Hadoop выглядит следующим образом. Данные могут быть на каком-то сервере приложений, на классическом стандартном хранилище, и есть системы, которые позволяют перенести их в Hadoop. В Hadoop они могут обрабатываться, храниться и экспортироваться в обычные базы данных.
Для чего используется Hadoop сейчас? Для решения многих задач. Например, для нахождения и обработки текстов, создания рекомендательных систем коллаборативной фильтрации, предсказательных моделей, оценок риска, нахождения элементов в тексте, предсказания прихода/ухода клиентов, сегментации клиентов, многого другого. Все эти задачи легко разбиваемы на отдельные кусочки. Именно такие задачи прекрасно подходят для Hadoop.
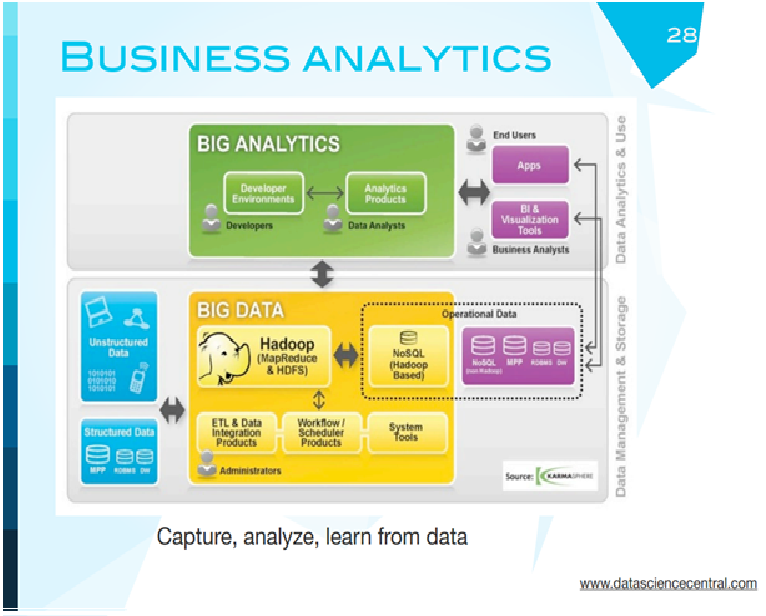
Если мы говорим о работе бизнес-аналитика, то примерная схема предприятия для перехода на работу с большими данными выглядит вот так: это новая часть, в ней появился Hadoop, дополнительные системы обработки данных. Но они связаны со стандартными классическими базами данных. Hadoop ни в коем случае не заменяет операционные традиционные базы данных, это дополнение расширяет ваши возможности. И удешевляет, потому что не все данные вечно можно хранить в Oracle, учитывая то, сколько он стоит.

Кто сейчас использует Hadoop? Это просто небольшой скриншот компаний, которые его используют. Это сейчас менйстрим. Групон, Nokia, все названия знакомы. Это только те, кто официально заявляет, что используют Hadoop. Техническая часть закончилась.
Теперь немного про бизнес вокруг Hadoop. Hadoop - это открытый продукт, и вы можете его взять и установить, так же как и linux. Проблема такая же, как и с linux. Предприятия просто не хотят брать какой-то продукт и устанавливать его, потому что это сделать сложно, они хотят поддержку, потому что они хотят гарантии качества. На этом построен бизнес Red Head.
Cloud Era, одна из первых компаний, которая поняла, что здесь кроется большой бизнес, была основана в 2008 году. На сегодняшний день у нее 140 миллионов венчурных денег. Ее сейчас оценивают довольно скромно, порядка нескольких миллиардов, там работает около 200 человек. Они поставляют Hadoop как продукт, предоставляют обслуживание, консультации и обучение. Также они стараются развивать, делать надстройки на Hadoop.
Следующая компания, которая так же построена на Hadoop, - это MapR Technologies, основаны на год позже. Гораздо меньше финансирования, гораздо меньше клиентов, но они решили немного изменить технологии, которые лежат в основе Hadoopа, и пойти по другому немного пути. При этом они решили не делать их открытыми. К этой компании отношение на рынке очень интересное, потому что, с одной стороны, они вроде как делают что-то любопытное, а, с другой стороны, всем нравится, все поддерживают Open source. Запирать компанию на какую-то отдельную технологию нельзя, потому что если устанавливающая компания умрет, кто будет поддерживать эту технологию? Поэтому все стараются смотреть на Open source.
Третья компания, Hortonworks, организована только сейчас. На самом деле, довольно поучительная история. Hadoop развился вокруг Yahoo. Yahoo сделала spin-off Hadoop как отдельную компанию спустя 6-7 лет. Не очень понятно, о чем они думали. Теперь это последний участник игры в коммерциализацию Hadoop.
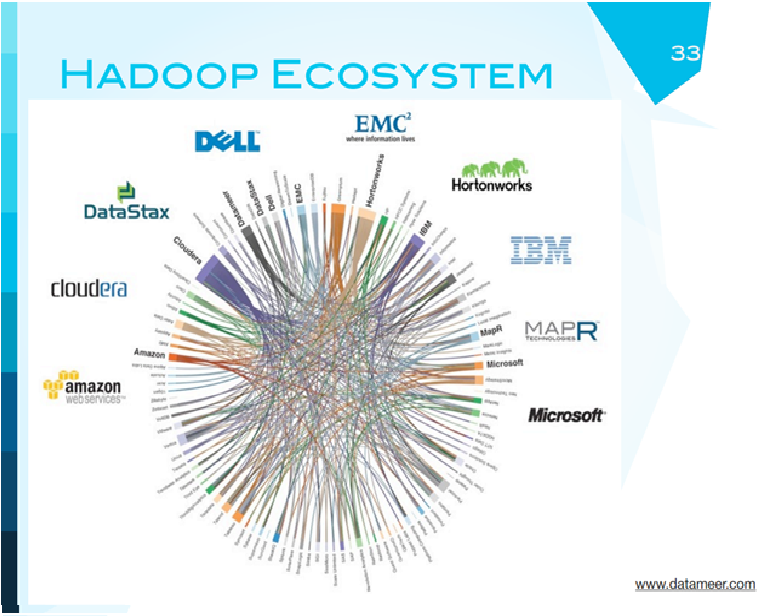
Это экосистема Hadoop. Экосистема в том смысле, что это компании, как они между собой связаны, какими контрактными отношениями, и поставщики Hadoop. Есть Cloudera, Horton works, Web-Art. А как участвуют в этом мире IBM и MC, думаю, расскажут вам потом. Обратите внимание, что Cloudera здесь, действительно, - самый мощный участник.
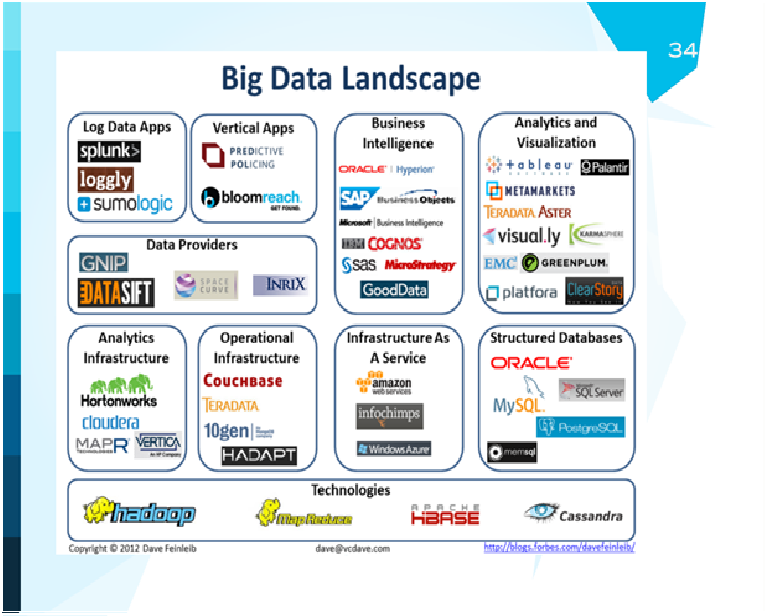
Мы с вами немного поговорили про эти компании, мы знаем, что такое Hadoop, map reduce, даже видели вот такие названия. Сейчас мы с вами просто посмотрим примеры компаний из разных квадратиков: бизнес-интеллигенция, аналитика, визуализация.
Компания Splunk - выдающаяся компания, на самом деле. Основана в 2003 году, занимается совершенно занудным делом - копается в логах, где что сломалось. Они вовремя поняли, что технология, которую они разрабатывают, должна быть масштабной, и подключились к big data. С тех пор они подняли 230 миллионов, сделали IPO, сейчас на рынке оцениваются в 3,5 миллиарда. Что они делают? Они обрабатывают машинные логи, распределенные определенным способом. Они могут подключиться к системе, проанализировать логи, выдать вам результат и сказать, что сломалось. Простая идея, простая модель - 3,5 миллиарда. Это b2b.
Следующая компания - Datameer. Довольно свежая, 2009 год, 17 миллионов - фандинг. Они работают уже с надстройкой над Hadoop. После того, как у нас уже есть Hadoop, мы умеем хранить и обсчитывать данные, знаем, как поместить и изъять оттуда данные, неплохо бы сделать какую-то аналитику на этих данных и нарисовать эти данные. Этим занимается Datameer. У них есть довольно интересная технология, по которой они берут небольшой отрывок данных из Hadoop, обрабатывают его, после этого позволяют работать с ним как с обычной таблицей Excel.
Datasift- другая интересная компания. Ее идея заключается в том, что всем нужны данные. Давайте станем центральной точкой сбора данных и будем эти данные перепродавать. Основана в 2008 году, называют себя data-платформой для social-web, фандинг около 60 миллионов, данные получают от социальных сетей, твиттера и других.
Infochimps - опять-таки, 2009 год, фандинг очень небольшой. Эти ребята несколько раз меняли свою стратегию. Cейчас они себя представляют как n2n провайдер для больших данных. Если у вас есть большие данные, вы в этом ничего не понимаете, но знаете, что рынок требует работы с большими данными, они придут, поставят Hadoop, научат им пользоваться.
Tableau Software - очень старая компания, 2003 года, с очень небольшим финансированием, долго ходили по рынку, нашли для себя интересное положение - визуализация и анализ данных.
Что касается новых, молодых компаний. Platfora - бизнес-аналитика на ходу, Sumologic - пытаются повторить успех Splunk"а и сделать анализ логов. Hadapt - некая компания, которая пытается совместить Hadoop и реляционные базы данных. Metamarkets - эти ребята понимают, что у многих компаний есть проблемы с потоками данных, они разрабатывают технологии нахождения паттернов в потоках данных. DataStux сосредоточены на консультации и обучении, Karmasphere - аналитика. Вот несколько компаний для 2013 года. 10gen разрабатывает NoSQL базу данных, она не Hadoop-овская, отдельная. ClearStory- аналитика, Continuuity - Hadoop и API, ParStream - аналитика баз данных. Climate corporation - единственная из компаний, которая имеет прикладной характер. Если вы обратите внимание, на этом слайде в основном все компании занимаются анализом и визуализацией данных.
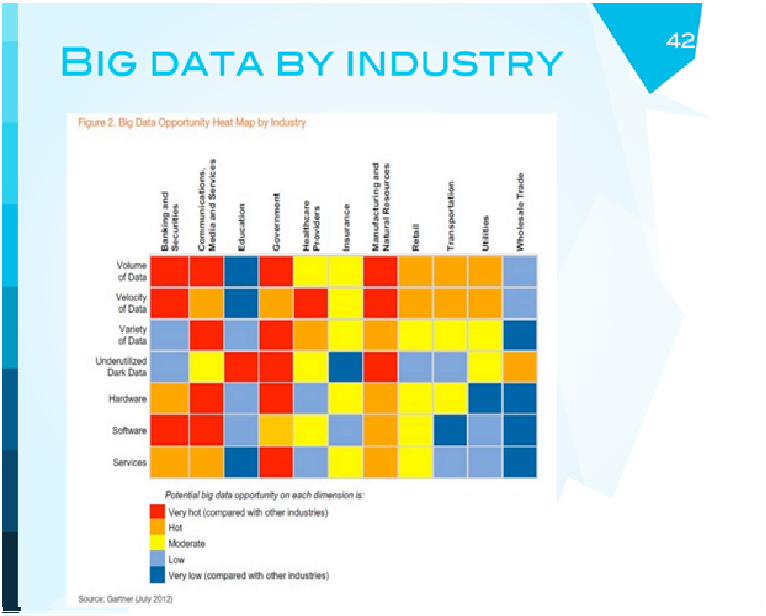
Возвращаемся к Гартнеру - это Heat Map, которая показывает, в каких областях индустрии big data сегодня интересна. Банковские сервисы, правительства, коммуникации, производство. Я немного не согласен с health care providers, потому что есть ощущение, что health care - это та область, где большие данные хорошо пойдут скоро. Я подозреваю, что выделено здесь это таким цветом потому, что в Америке очень сильно зарегулировано, не так просто пробиться в нее, нужна куча разрешений, чтобы хоть что-нибудь делать с медицинскими записями.
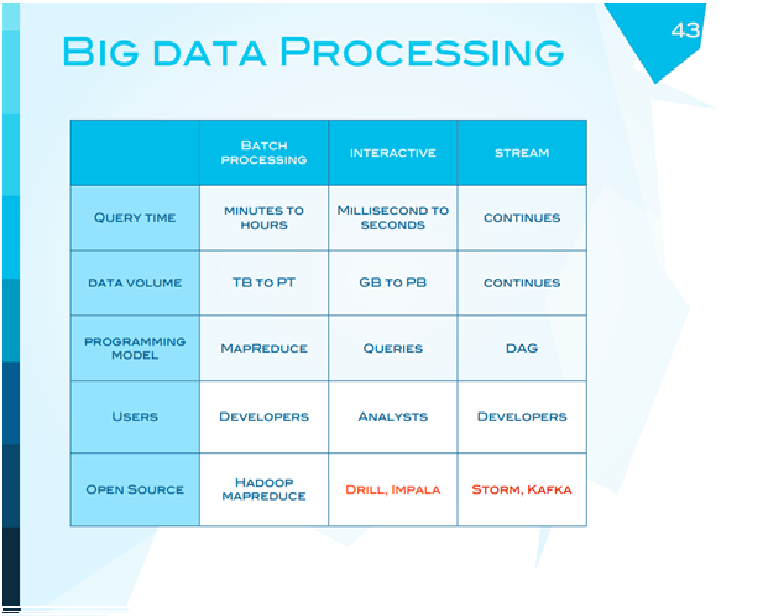
Чтобы перейти к будущему, я хочу показать сводную табличку, где обозначено, что технология map reduce предназначена для обработки данных партиями, это не интерактивная система. Для аналитиков, как правило, требуется интерактивная работа. Hadoop этого сделать не может, в Hadoop обработка должна происходить офф-лайн, как раньше суперкомпьютеры - поставили в очередь работу, утром вернулись и получили результат. Этим самым открывается возможность для разработки новых продуктов, которые могли бы работать на больших данных и быть интерактивными. В точности так же Hadoop не может работать с потоками данных.
И здесь есть возможность для разработки новых продуктов. То, что здесь показано, - новые продукты в разработке, они тоже сейчас делаются как open source, которые отвечают интерактивной системе взаимодействия с большими данными и обработке потоков.
Я особо много говорить о них не буду, но стоит заметить, что Storm (система для обработки потоков), пионер этой разработки - никто иной как твиттер, это просто их внутренняя разработка, которую они решили открыть людям. Kafka, система анализа сообщений, разработка Linkedin.
Систему работы с real time запросами очень сильно разрабатывает сейчас Cloudera в качестве дифференциатора на рынке: не просто поставлять Hadoop, но и в качестве надстройки что-то свое и интересное.
Нельзя оставить без внимания важную часть машинного обучения. К сожалению, сейчас это самое слабое место во всей системе больших данных. Мы умеем хранить данные, обрабатывать их и решать простые задачи. Писать сложные вычислительные алгоритмы, которые действительно будут делать предсказания или еще что-то, очень сложно, и для этого фактически нет технологий. Mahout - библиотека, которая сделана для работы на Hadoop, очень примитивная, и пока никто не взялся ее оттачивать. R, как язык статистического программирования, сейчас де-факто стандарт в обработке больших данных, но он нераспределенный. На самом деле, если есть место для инноваций достаточно большое, это как раз в области машинного обучения для больших данных.
Откуда пришли технологии. Гуглфайлы пришли из Google, Hadoop - из Yahoo, амазон предложил свои базы данных, Facebook предложил базы данных cassandra, HBase, твиттер - систему Storm, linkedin - еще несколько технологий.
Заканчивая, я хотел бы сказать следующее. Несколько наблюдений об эволюции технологий больших данных. Мне не хочется признавать как стартаперу, но, похоже, технологии, которые фундаментально изменяют ход дел, приходят из больших компаний. Потому что там есть ресурсы и люди, которые могут думать не только о сегодняшнем, но и завтрашнем дне. Во-вторых - очень важный момент! - эти технологии были почти что сразу сделаны open source. Их открыли для бесплатного пользования, создалось сообщество, и люди смогли туда вкладывать больше энергии и популяризовать их. Сразу же вокруг этих open source"ов возникли стартапы, которые начали их использовать разными способами. Последнее философское замечание - о том, что, на самом деле, это все компромисс, потому что ничего нового не изобретено. Просто взяли модель суперкомпьютера - и отказались от условий. Взяли модель базы данных - и упростили ее, сделали более приемлемой для бизнеса.

Тот же Gartner сказал, что в 2018 году в США будет нехватка 190000 специалистов со знаниями data analysis, data science. Что такое data scientist? Люди, которые понимают машинное обучение, которые знают, как анализировать данные, знают статистику, обладают навыками программиста, знают технологии. Главное, что этому научить не так сложно. Для людей с таким образованием научиться вот этому будет гораздо проще, чем этому.
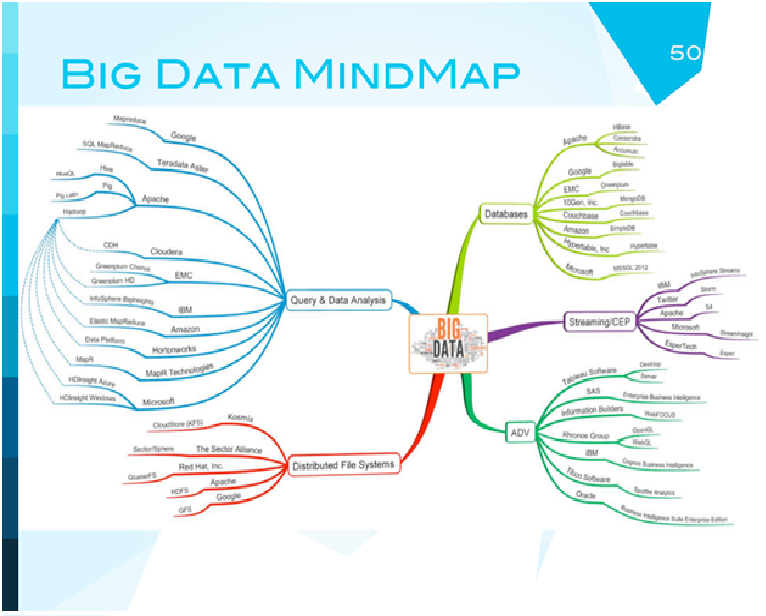
Последний слайд. Мне, честно говоря, он очень понравился. Безумный слайд с mind map. Он показывает несколько основных направлений big data, и дальше компании и технологии, которые они создали. Для того чтобы осознать весь этот зоопарк, который творится в больших данных, будет очень полезна именно такая карта.
Игорь Рубенович Агамирзян: Спасибо большое. Мне было очень интересно, несмотря на то, что я знал некоторые слова вроде map reduce из тех времен старых, когда еще занимался этим. Но много и чрезвычайно новой для меня информации. Надеюсь, что слушателям тоже было интересно и полезно. У нас сейчас предусмотрено два содоклада от представителей ведущих компаний, но так как было достаточно много содержательной информации, я могу предложить задать сейчас несколько вопросов, если есть животрепещущие. А потом, уже после выступлений представителей MC и IBM, сделаем дискуссию.
Александр Брызгалов: Короткий вопрос. На последнем слайде российских компаний совсем нет. Кто здесь у нас этим занимается?
Леонид Жуков: На самом деле, у нас есть Yandex, mail.ru и еще пара компаний, в которых используется Hadoop или технологии, похожие на Hadoop. У нас есть технологии, которые, по всей видимости, лучше, чем Hadoop, но они закрытые. Мы идем своим путем. Кстати, судя по результатам поиска Yandex"а, неплохой путь.
Ростислав Яворский: Можно уточняющий вопрос? По картинке, как выглядит рабочее место аналитика.
Леонид Жуков: Идея такая. Появился слон в посудной лавке. У нас данные могут быть известны заранее, собраны и структурированы, какие-то - нет, просто поступили к вам в компанию. Раньше, когда этой части не было, они все уходили в стандартные базы данных и хранилища. Теперь здесь у нас появился Hadoop. Во-первых, нам нужно нормализовать данные и поставить их в Hadoop. В Hadoop данные можно хранить и использовать для обработки, и это намного дешевле, это сейчас стараются делать компании. Аналитик может работать с Hadoop напрямую. Также есть связь между application и users. Если вы пользователь, вы пришли, предположим, для вас есть рекомендации, просчитанные на Hadoop с использованием данных. Вы их получаете, когда заходите на сайт. Это общая картина среднестатистического бизнеса, связанного с данными. Что насчет компаний, есть группа компаний, которые занимаются аналитикой и визуализацией. Кстати, очень интересная компания Палантин, занимается анализом больших данных, финансируется из CIA фонда. Эта коробочка - классические базы данных. Business intelligence - более или менее понятно, datacif - то, что мы обсудили, это агрегаторы и перепродавцы данных. Splunk, Logdata, Applications - те, которые анализируют логи. А эти ребята, честно говоря, не помню, что делают. Vertical applications - видимо, для какого-то сегмента рынка. Operation infrastructure - классические базы данных, которые используются в ежедневной работе компаний.
Вопрос из зала: Я так понял, что в области бизнеса будет стимул, экономическое преимущество у компаний, которые занимаются big data, по сравнению с другими компаниями. Это заставит рынок вести компании к большему использованию таких технологий. Относительно государства. Что может заставить государство заинтересоваться этими технологиями и прибегнуть к их использованию?
Леонид Жуков: Вы знаете, государство - это тоже в некотором смысле бизнес. Ясно, что стоимость хранения данных в Hadoop раз в 10, а, может быть, и в 20 дешевле, чем в базах данных Oracle, и это довольно существенная разница. Если мы сейчас пытаемся сделать электронное правительство и собрать все данные воедино, организовать систему документооборота и оборота данных, их надо где-то хранить. Можно заплатить Oracle или EMC, а можно сделать Hadoop. Hadoop позволяет обрабатывать данные. Если вы хотите найти какие-то закономерности в данных.
Александр Московский: Все-таки по поводу генеалогии, происхождения. Мне кажется, что в научном мире был ряд проектов - национальные лаборатории, академические исследования, - которые как раз больше ложатся в эту тему big data, они как-то не получили вашего внимания.
Леонид Жуков: Я полностью с вами согласен, но рассказать обо всем невозможно. Ясно, что истоки - из академии, академических исследований. Национальные лаборатории - и есть академические исследования, одно другому не противоречит. Я, наверное, неправ, что не указал конкретно астрономию, но…
Александр Московский: Тот же вопрос с адронным коллайдером…
Игорь Рубенович Агамирзян: Я прошу прощения, но вопрос с адронным коллайдером - очень близко связан, но не совсем то же самое. Здесь не прозвучала одна очень принципиальная вещь. Big data становится ценной не тогда, когда ее просто много, а когда возникает возможность сравнения ранее несравнимых данных. Сейчас стало возможным сопоставить то, что раньше было несопоставимым. И это дает некоторую новую ценность для всех участников рынка - и, кстати говоря, государства. Государству в каком-то смысле это даже более важно, чем рыночным компаниям, потому что у вторых, как правило, есть четкие фокусы, а среди задач госуправления - задача сопоставления данных из разных, несвязанных источников является чрезвычайно актуальной при принятии многих принципиально важных решений. Я на этом прервусь, хочу еще раз поблагодарить выступавшего...
Новые горизонты Big Data. Часть 2
Новые горизонты Big Data. Часть 3