Игорь Рубенович Агамирзян: …Следующим хочу предложить выступить Вячеславу Нестерову, руководителю центра разработок корпорации EMC в Санкт-Петербурге.
Вячеслав Нестеров: Здравствуйте! Я надеюсь, что мне удастся быстро добавить несколько штрихов к очень интересному докладу, который мы только что прослушали. Эти штрихи будут с позиции индустрии, потому что я представляю компанию EMC, она неоднократно упоминалась здесь. Компания, которая позиционирует себя как сильный игрок на этой арене.
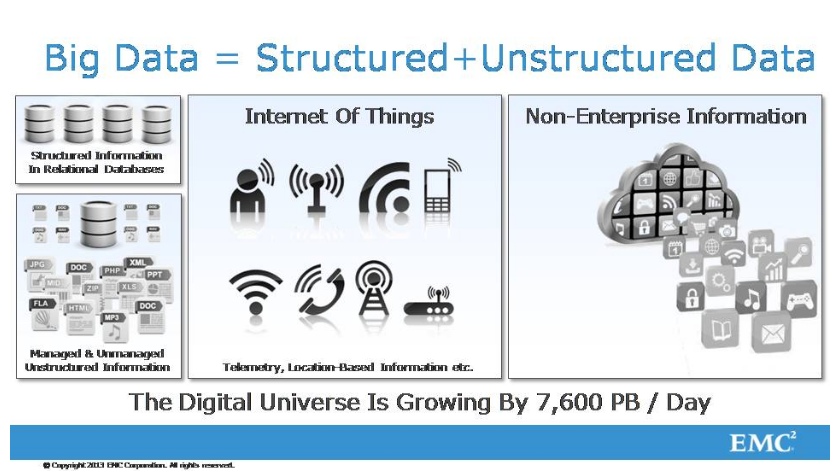
Сейчас буквально в двух словах о том, где мы находимся. Понятно, что касается big data, ландшафт этот можно представить как место, где производят большие данные, где они генерируются, на другом конце находятся компании и люди, которые потребляют эти данные и то, что из них удается получить. Посередине находится некая структура, которая, собственно, и осуществляет этот самый анализ. Внизу находится железная платформа - те хранилища данных, которые способны справиться с хранением данных, те вычислительные мощности, которые способны обработать эти данные. Дальше - платформа поверх железа, которая позволяет обрабатывать данные. Этот стек состоит из большого количества слоев. Наверху map reduce, Hadoop и другие системы, о которых мы говорили, а на самом верху applications, которые позволяют аналитикам больших данных работать с ними. Компания EMC - это компания, которая позиционирует себя как несколько нижних слоев этого стека, начиная с устройств хранения информации, плюс нижние слои средств ее обработки, и до определенного места. Applications - то, что создается на базе наших продуктов.
Я все-таки еще раз скажу несколько вещей, часть из них неслучайна. Понятно, что данные сейчас генерятся в очень большом количестве мест. Здесь даже написано, что данных каждый день появляется около 7000 петабайт. Надо что-то делать, это можно как-то использовать. Уже было сказано, не буду повторяться, данные есть структурированные и нет. Вроде бы как есть оценки, что на сегодняшний день не больше 10% данных структурированы, и эта пропорция продолжает увеличиваться в пользу неструктурированных данных. Очень большой объем данных генерится интернет-приложениями - как телефонами, так и девайсами, обрабатывающими огромные объемы данных. Часть данных в общем объеме, которая генерится интернет-вещами, - это 15%. К 2020 году предполагается, что интернет-продукты будут генерить около 40% всех данных. Собственно, эти данные являются одним из важнейших источников информации.
И еще одна тенденция, которая хорошо известна, - это то, что личная информация хранится не в личных хранилищах, а в облачных или физических местах, которые относятся к enterprise. Люди хранят свои фотографии не в своем компьютере, а в облаках.

Здесь несколько картинок, я не буду, конечно, обо всем этом рассказывать. Откуда берутся большие данные? - тенденция очень интересная. Я буквально о нескольких вещах скажу. Очень много данных в общей пропорции генерятся всякого рода сетями, промышленными сетями, в частности - сетями передачи радиоэнергии. И оттуда поступает очень много данных, из которых тоже можно извлекать очень полезную информацию. Еще один пример, кстати, было сказано в докладе о health care, но там прозвучала немного другая мысль о том, что можно извлечь полезную информацию, обрабатывая медицинские записи большого количества людей.
Есть еще один аспект, связанный со здравоохранением, а именно - геномная информация. И эта вещь развивается сейчас очень быстро, и это связано с одним очень простым фактом, что стоимость получения генома одного человека падает быстрее, чем экспонента. Соответственно, количество информации, которое в ближайшее время будет получаться путем исследования генома конкретного человека, будет расти тоже быстрее, чем экспонента.
Геном человека - это три миллиарда пар нуклеотидов. Казалось бы, не так много информации. Но суть в том, что помимо той информации, которая уже собрана, там хранится много сырой информации, на тех аппаратах, которые этим делом занимаются. Информацию сырую тоже полезно хранить из разных соображений.
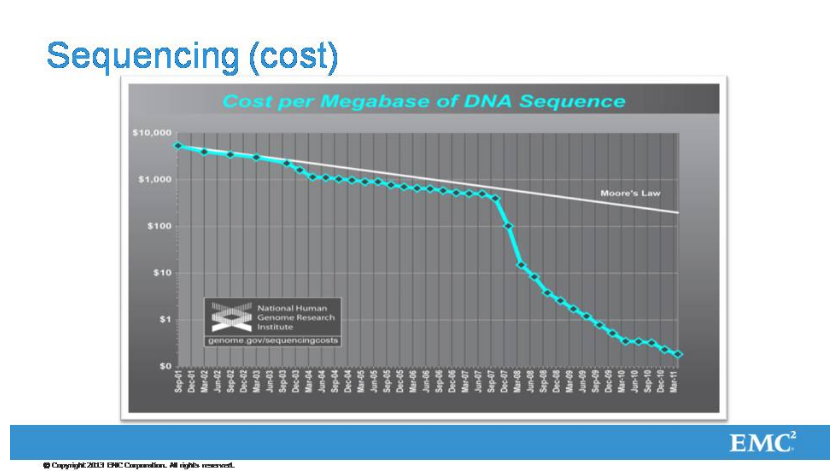
Интересная, кстати, зависимость, с которой мы столкнулись, - это как падает стоимость получения геномной информации. Это, заметьте, логарифмическая шкала. Это сентябрь 2001 года, это март 2011 года. Первый геном вообще был синтезирован за 6 миллиардов долларов, это был международный проект. На сегодняшний день стоимость получения одного генома в районе 1000 долларов. Я такой закономерности вообще нигде не видел. Это даже не экспонента, потому что экспонента на логарифмической шкале выглядит как прямая. Отсюда будет появляться гигантский объем информации - будет, потому что сейчас это все только начинается.
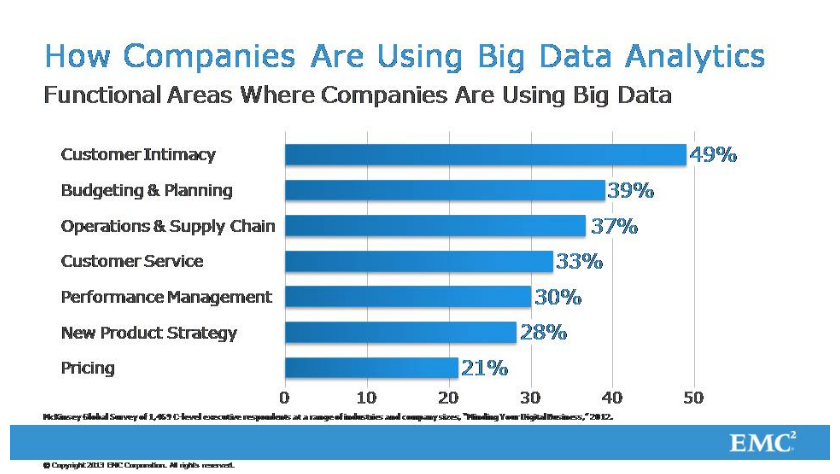
Для чего компании собираются использовать данные, полученные путем применения технологии больших данных? Вы видите. Был проведен опрос около 1500 менеджеров больших компаний. Их спросили, для чего им нужны большие данные. 49% сказали, что им эти большие данные нужны, чтобы лучше понимать своих заказчиков, чувствовать, что им нужно, анализировать потребности рынка. 39% - для того, чтобы более эффективно заниматься планированием и бюджетированием. И так далее.
Не буду на этом останавливаться, это те же самые 3 V. Это характеристики больших данных. Объем, разнообразие и скорость, с которой их нужно обрабатывать.
Здесь мы уже переходим к следующему. Почему компания EMC всего 1% бизнеса использует на большие данные? Почему, несмотря на то, что так немного это все приносит, мы беремся за это дело? Это некая иллюстрация к причинам того, что большие компании из других областей двигаются в эту область. Выясняется, что существующая инфраструктура, те слои стека, о которых я говорил, совершенно не удовлетворяют потребностям анализа больших данных по самым разным причинам. По причине низкой производительности, объемов, если говорить о хранении данных, по причине тех примитивов, которые они предоставляют для доступа к данным, по тем параметрам, которые связаны с возможностью масштабирования систем, которые сейчас существуют. Короче говоря, более или менее очевидно, что для того, чтобы успешно заниматься анализом данных, необходимо строить новую инфраструктуру, которая через некоторое время вызовет новый сектор IT-бизнеса. Компания EMC - классический бизнес, основная часть которого - хранение информации. Это высоконадежные, большого объема системы для хранения информации, которые последние 30 лет используются достаточно активно всевозможными компаниями, банками и т.д. Поэтому естественно, раз текущая инфраструктура для растущего сектора не годится, пойти в соседний сектор бизнеса и сделать продукцию, удовлетворяющую новым потребностям.

Эта мысль тоже уже была, я с ней полностью согласен. Для того чтобы все это развивалось, необходим принципиально новый человек - специалист для работы с большими данными. Можно сделать такое соотношение того, что было, и того, что стало. Раньше были бизнес-аналитики, теперь есть data scientists. Согласно данным нашей компании, бизнес-аналитики - это те люди, которые исследовали данные и делали из них какие-то выводы из прошлого, а анализируя набор какой-то информации за какой-то промежуток времени, могли сделать выводы о том же самом промежутке времени, какую-то визуализацию этой информации, дать суммарные результаты. А аналитики больших данных - это люди, которые, скорее, могут отвечать на вопросы "а что если?". Они смотрят вперед, анализируют те данные, которые обращены в будущее. Совершенно согласен с тем моментом, что таких людей, которые владеют всеми необходимыми знаниями, имеют представления о той предметной области, о которой идет речь, таких людей не хватает. Это еще одна составляющая той инфраструктуры, про которую я говорил в самом начале.
Я слышал такое мнение, что настолько дефицитна эта специальность в мире, я не говорю уже о России, что в Калифорнии это единственная специальность, по которой человек, сразу закончив университет и не имея опыта работы, может зарабатывать 100 тысяч долларов в год, а это считается недостижимым для других IT-специальностей без опыта работы.
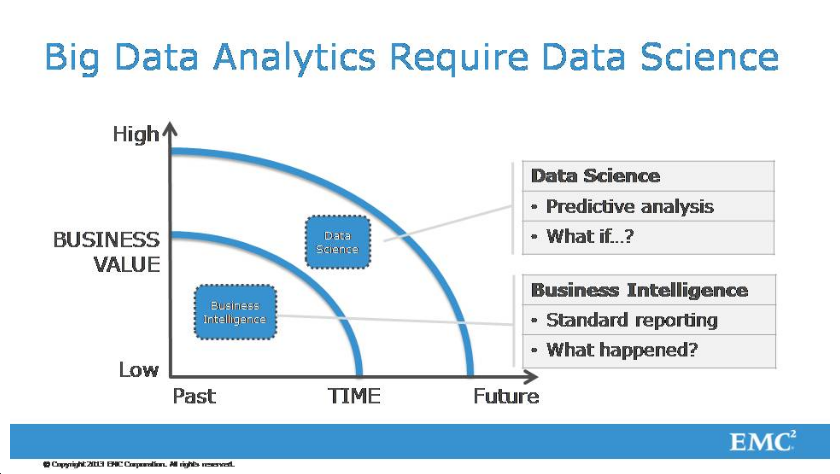
Это иллюстрация к тому, чем data-аналитик отличается от того, что называется бизнес-аналитикой. У нас есть система координат, по одной оси - польза от специалиста, по другой координате просто отложено время. С течением времени нужно смещаться в область аналитики больших данных, чтобы приносить максимальную пользу.
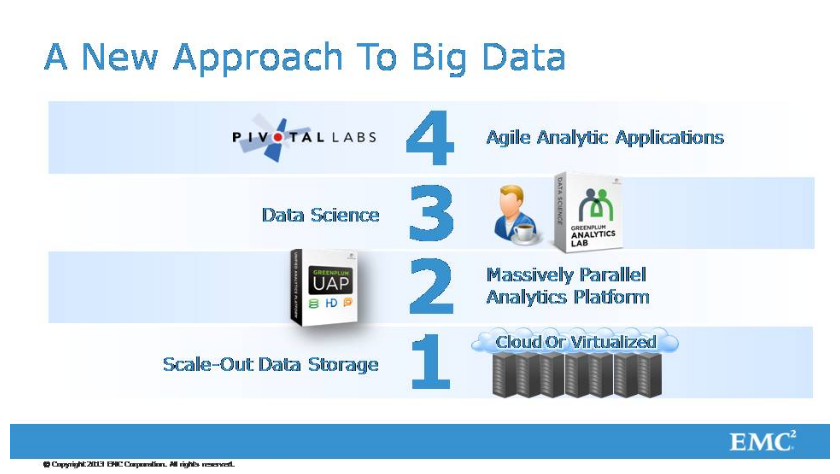
Из чего же складывается этот ландшафт, с которого я начал, инфраструктура? В самом низу - устройство для хранения больших данных, которое может активно расти и масштабироваться. Такие устройства могут быть физическими, на классическом принципе построены, просто стоимость инфраструктуры заставляет это все делать виртуализованным и достигать масштабированности. Во-вторых, чтобы все это было достаточно эффективно и было на высоте.
Следующий этап - это платформа, которая является параллельной. Тут один из продуктов, который принадлежит нашей компании, изображен. Это некоторая аналитическая платформа, без которой анализ больших данных невозможен.
Дальше присутствуют люди, без которых тоже ничего не бывает, с инструментами, которыми они умеют пользоваться. Ну и, наконец, на самом верху находятся гибкие аналитические приложения, которые реализуют ту бизнес-логику, которая требуется. Вот, собственно, все, что я хотел сегодня сказать. Вывод такой. Думаю, что после первого доклада не осталось никаких сомнений в том, что большие данные трансформируют большие области бизнеса и понимание, как значительные сектора бизнеса могут жить и развиваться. Подход к обработке больших данных отличается от того подхода, который был классическим, который был раньше. Наконец, необходимо для успехов бизнеса уметь успешно работать с этими самыми большими данными.
Игорь Рубенович Агамирзян: Коллеги, если есть вопросы, давайте еще один-два вопроса зададим и перейдем к следующему участнику.
Сергей Абрамов: Не знаю, насколько он будет кратким, произошла расфокусировка. В первом докладе говорилось, что идея была использовать очень простое ненадежное железо для хранения, а вы сказали, что EMC предлагает высоконадежное, качественное железо.
Вячеслав Нестеров: Ну да, EMC считает именно так. Специально для этого мы купили компанию, которая предлагает именно такое высоконадежное, хорошо масштабируемое файловое хранилище.
Игорь Рубенович Агамирзян: Это, на самом деле, тема для дискуссии, потому что подходы, явно видно, здесь разные. Давайте, мы тогда сейчас послушаем последнее выступление Сергея Лихарева из IBM и потом уже перейдем к этой дискуссии…
Новые горизонты Big Data. Часть 1
Новые горизонты Big Data. Часть 3