Итак. "Каждая хозоперация подлежит отражению в одной и той же сумме одновременно по дебету одного счета и кредиту другого". Уберем из этого определения плохо детерминированное понятие "хозоперация" и введем понятие "проводка". Так всем будет понятнее. Получится: "Каждая проводка подлежит отражению в одной и той же сумме одновременно по дебету одного счета и кредиту другого".
Зададимся вопросом - что же означает слово "отражению"? В данном случае это означает, что проводка должна изменять остаток на обоих счетах. Точнее, она должна уменьшать остаток на одном счете и увеличивать на другом. Если мыслить примитивно, то нам понадобится ввести сущность (объект, если кому так больше нравится) "счет" и физически хранить для нее остаток. Но тут возникает вопрос, а на какую дату нужно хранить остаток? Или это должен быть остаток вообще (за весь период жизни предприятия)? Ответ - нет, так как и бухгалтеру и управленцу нужно получать остатки на определенную дату. Более того, им нужны еще и обороты. Правильно? Думаю - да. И тут нужно обратить внимание на брошенное мной по ходу дела слово: получать!
Это слово было сказано не спроста. Дело в том, что хранить остатки и обороты совершенно не нужно. Их и так можно посчитать в любой момент времени. Правильно?
Слышу тихий ропот: "при некоторых объемах эти расчеты просто несерьезно делать каждый раз пересчитывая все с самого начала. Нужны срезы..." Правильно, но это всего лишь отдельный вопрос производительности. И решать его нужно отдельно от вопроса структуры хранения информации. Индексированные/материализованные view прекрасно решают проблему производительности сервера (да и программиста). Если вы еще не перешли на SQLServer 2000 или Oracle8i (9i), то самое время сделать это. Да и на других серверах можно грамотно создать таблицы, содержащие агрегированную информацию. Главное, что это не повод для нереляционного хранения данных в реляционной СУБД.
Существует мнение, что двойная запись плохо описывается средствами реляционных БД и при попытке реализации приводит к денормализации с ограничением целостности. Такой мнение приводит к созданию систем, состоящих из огромного количества слабо связанных таблиц, например, отдельных таблиц для накладных прихода товара на склад (расхода со склада) и учета кассовых ордеров. Это приводит к существенному усложнению обобщенного анализа данных, хранящихся в таком конгломерате таблиц. В принципе, любые учетные данные полиморфны по своей природе. В них всегда можно выделить общую составляющую, позволяющую обобщенно рассматривать данные с разных точек зрения. К сожалению, при вышеописанном подходе этого очень трудно добиться. Так, в приведенном примере складские накладные и кассовые ордера скорее всего будут содержать совершенно разные поля и, скорее всего, не будет учтено, что и кассовый ордер, и накладная в конечном счете являются отражением перевода денег или товара.
Такое "потабличное" проектирование очень упрощает жизнь проектировщика. Однако это та простота, которая впоследствии выйдет боком, так как не описывает жизненных процессов предприятия, а занимается простой регистрацией документов. Системы, построенные по такому или подобному принципу можно назвать документо-ориентированными, или системами, строящимися от документа. Обычно такие системы или вообще не содержат бухгалтерии, или содержат ее в виде отдельного блока. Данные из БД попадают в бухгалтерию из таблиц документов, обычно пакетно, за отчетный период. Только после этого бухгалтер начинает работать с информацией, находясь вне связи с реальной жизнью, то есть реальной учетной ситуацией.
Является ли нормализованной таблица, описанная в листинге 2?
Каждая запись в таблице отражает информацию только об одной сущности - проводке. Данная таблица не будет иметь ни одной повторяющейся записи, из таблицы нельзя вынести данные в другие (ссылочные) таблицы. Вроде, все говорит о том, что таблица соответствует самым жестким требованиям нормализации. Значит, на первый вопрос отвечаем положительно.
Можно ли в этой таблице хранить проводки, отвечающие принципам двойной записи?
Каждая проводка содержит информацию о дебетовом и кредитовом счете (в виде ссылки), причем в ней отражены и дебетуемый, и кредитуемый счета.
Проводка содержит дату ее совершения и сумму. Совокупность даты проводки, суммы и направления перемещения денег дает нам возможность записывать таким образом нормальные бухгалтерские проводки, удовлетворяя всем требованиям двойной записи. Просто вместо учета изменения счетов мы начали учитывать изменения этих самых счетов во времени. Никто не запрещает записывать проводку как два отдельных изменения счетов (дебетового и кредитового), но тогда и появляется та самая проблема с "нереляционностью" и "ненормализованностью".
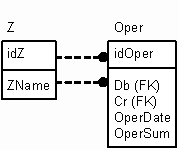
Чтобы не быть голословным, я создал маленькую тестовую базу (см. листинг 1), состоящую из двух таблиц (я буду пользоваться синтаксисом SQL Server 2000, но он довольно близок к SQL 9x). Первая хранит некие аналитические признаки. Упростим задачу и предположим, что это просто бухгалтерские счета. Вот описание этих таблиц в виде ER-диаграммы:
Листинг 1
SET QUOTED_IDENTIFIER ON
SET ANSI_NULLS ON
GO
CREATE TABLE Z
(
idZ int NOT NULL PRIMARY KEY,
ZName varchar(100) NOT NULL
)
Вторая таблица - это таблица, содержащая проводки.
Листинг 2
SET QUOTED_IDENTIFIER ON
SET ANSI_NULLS ON
GO
CREATE TABLE Oper
(
idOper int IDENTITY (0, 1) NOT NULL PRIMARY KEY,
Db int NOT NULL FOREIGN KEY REFERENCES Z,
Cr int NOT NULL FOREIGN KEY REFERENCES Z,
OperDate datetime NOT NULL,
OperSum float NOT NULL
)
Как видно из определения второй таблицы, поля Db и Cr являются ссылками на аналитическую таблицу. В принципе, каждая запись аналитической таблицы может содержать неограниченное количество дополнительных аналитических признаков, но суть от этого не изменится. Главное, что мы совершаем перевод денег с одной единицы аналитики на другую (равнозначную по глубине/уровню). Посчитать остатки/обороты для такого вида таблиц довольно просто. Для начала заполним наши таблицы данными:
Insert into Z(idZ, ZName) Values(1, 'OC') Insert into Z(idZ, ZName) Values(2, 'Амортизация ОС') Insert into Z(idZ, ZName) Values(10, 'Склад материалов') Insert into Z(idZ, ZName) Values(41, 'Товоры') Insert into Z(idZ, ZName) Values(46, 'Реализация') Insert into Z(idZ, ZName) Values(50, 'Касса') Insert into Z(idZ, ZName) Values(51, 'Расчетный счет') Insert into Z(idZ, ZName) Values(60, 'Поставщики') Insert into Z(idZ, ZName) Values(71, 'Овансовые отчеты') Insert into Z(idZ, ZName) Values(75, 'Учт.кап.') SET DATEFORMAT dmy Insert into Oper(Db, Cr, OperDate, OperSum) Values(51, 75, '01.01.2002', 1000) Insert into Oper(Db, Cr, OperDate, OperSum) Values(50, 51, '02.01.2002', 300) Insert into Oper(Db, Cr, OperDate, OperSum) Values(71, 50, '03.01.2002', 100) Insert into Oper(Db, Cr, OperDate, OperSum) Values(10, 71, '04.01.2002', 55) Insert into Oper(Db, Cr, OperDate, OperSum) Values(50, 71, '04.01.2002', 40) Insert into Oper(Db, Cr, OperDate, OperSum) Values(60, 50, '05.01.2002', 200) Insert into Oper(Db, Cr, OperDate, OperSum) Values(41, 60, '06.01.2002', 180) Insert into Oper(Db, Cr, OperDate, OperSum) Values(51, 60, '06.01.2002', 20) Insert into Oper(Db, Cr, OperDate, OperSum) Values(50, 71, '07.01.2002', 5)
Теперь можно создать упрощенный вариант расчета оборотной ведомости. Для простоты выбросим расчет остатка на промежуточную дату и обороты (их нетрудно добавить, но это усложнит понимание основного принципа).
Итак, рассчитать оборотку для некоторого уровня аналитики можно в два приема. Сначала нужно выделить уровень аналитики, для которого необходимо произвести расчет, а потом произвести агрегацию, соединив таблицу проводок и аналитики. В нашем, простейшем, случае есть только один уровень аналитики, а значит, дополнительный запрос на выборку и агрегацию аналитики не требуется. То есть мы можем рассчитывать обороты и остатки на основании данных из таблицы проводок.
Общий алгоритм совсем прост - нужно выбрать необходимые записи (за некоторый период) из таблицы проводок и посчитать их сумму для дебета и кредита каждого из счетов. К сожалению, записать это одним запросом (без подзапросов) невозможно (если кто извернется, то покажите, как). Я знаю два обхода данной проблемы. Первый известный мне способ - мы можем создать основной запрос, который будет возвращать список аналитических признаков, а обороты и остатки подсчитывать в простых подзапросах. Второй - можно произвести агрегацию отдельно для дебетовых и кредитовых признаков и соединить полученные запросы с помощью FULL OUTER JOIN. Я продемонстрирую второй подход:
SELECT IsNull(DbS.Db, CrS.Cr) AS Z,
IsNull(CrS.CrSum, 0) AS Db,
IsNull(DbS.DbSum, 0) AS Cr
FROM
(SELECT Cr, SUM(OperSum) AS CrSum
FROM Oper
GROUP BY Cr) as CrS
FULL OUTER JOIN
(SELECT Db, SUM(OperSum) AS DbSum
FROM Oper
GROUP BY Db) as DbS
ON CrS.Cr = DbS.Db
Данный запрос содержит два подзапроса (выделенных жирным), которые рассчитывают обороты по дебету и кредиту аналитических признаков.
Если нужно вычислять оборот и остаток за определенный период, нужно добавить в подзапросы фильтрацию необходимого периода. Приведенный выше запрос должен будет сам стать подзапросом. Дело в том, что для полноценной оборотки нужно рассчитать остаток на начало периода и оборот за период. Техника тут будет примерно такая же, так что вряд ли ее стоит касаться. Тот же FULL OUTER JOIN по аналитическим признакам... Остаток на конец рассчитывается путем сложения остатка на начало периода и оборота за период.
Если нужно добавить название аналитического признака, то можно сделать еще одну вложенность и JOIN со справочной таблицей. Вот вариант для нашего примера:
SELECT sb.Db, Z.ZName, sb.Cr, sb.Z
FROM Z [b]INNER JOIN[/b]
([b]SELECT IsNull(DbS.Db, CrS.Cr) AS Z,
IsNull(CrS.CrSum, 0) AS Db,
IsNull(DbS.DbSum, 0) AS Cr
FROM
(SELECT Cr, SUM(OperSum) AS CrSum
FROM Oper
GROUP BY Cr) as CrS FULL
OUTER JOIN
(SELECT Db, SUM(OperSum) AS DbSum
FROM Oper
GROUP BY Db) as DbS
ON CrS.Cr = DbS.Db[/b]
) as sb ON Z.idZ = sb.Z
В данном случае большая вложенность запросов не будет приводить к понижению производительности, так как только самые глубокие запросы занимаются действительно серьезной обработкой данных. Остальные уже работают с относительно небольшим количеством агрегированных данных.
Стоит также обратить внимание на то, что при соединении результата с записями из таблицы аналитики применяется INNER JOIN. INNER JOIN более эффективен, к тому же, если применить OUTER JOIN, в запрос попадут "лишние записи" (аналитики, для которой не было оборотов).
Однако может появиться (и появляется) вопрос:
Все это конечно очень здорово. Но вот простой пример. Я хочу получить баланс, причем не просто по счетам, но и с группировкой по аналитикам. Что-то вроде:
Товары на складе 1000
Продукты питания 200
Вобла 50
Пиво "Lowenbrau" 150
Одежда 400
Джинсы 250
Майки 150
Обувь 400
Кроссовки 200
Ласты на каблуках 200
Здесь "Товары на складе" - это счет, "Продукты питания", "Одежда", "Обувь" - аналитики типа "Вид товара", а все остальное - аналитики типа "Товар". Если данные хранятся в виде:
tblEntries ---------- entry_id entry_volume account_id analytic_0_id analytic_1_id ... analytic_N_id то написав SELECT SUM( entry_volume ) ... GROUP BY account_id, analytic_0_id analytic_1_id ... analytic_N_id
мы тут же получим нужный нам результат. А как быть в случае с более универсальным хранением аналитических атрибутов?
Первое что хочется здесь заметить - это то, что пример не очень удачен. Дело в том, что в данном примере определяются не атрибуты проводки, а атрибуты номенклатуры. Количественный учет - в некотором смысле учет в другом измерении. Не в денежном, а в количественном. Точнее в количественно-денежном.
Здесь есть смысл остановится и поподробнее разобрать общую структуру проводки. Посмотрите на следующий рисунок:
|
Дебет |
Кредит |
Дата |
Сумма |
Если оперировать не бухгалтерскими терминами, а общечеловеческими (или даже, можно сказать, объектно-ориентированными), можно сказать, что Дебет - это «место», куда пришли деньги, Кредит - откуда эти деньги ушли, Дата - момент времени, когда эти деньги перешли из одной «точки» в другую, а сумма - и есть перемещенная сумма. Но ведь деньги - это всего лишь абстрактная единица измерения (всеобщий эквивалент). По сути, это универсальная единица измерения для любых предметов и дел. По сути, сумма, с точки зрения проводки, есть не что иное, как универсальное измерение некоторого ресурса, который подвергается перемещению с одного «места» на другое. Например, перемещению могут подлежать кроссовки в количестве 10 пар, но в бухгалтерской проводке будет записана только их суммарная стоимость в определенной валюте (единице измерения), т.е. вместо 10 пар кроссовок будет записано 15 000 рублей. С алгоритмической точки зрения это - всего лишь запись в более полиморфном виде, т.е. в денежном эквиваленте, который можно обрабатывать более полиморфно (например, можно сложить обороты по продажам всех товаров). Взгляд на сумму в проводке как на количественное описание некого ресурса позволяет довести эту абстракцию до логической завершенности. Итак, и сумма проводки, и количество товара являются всего лишь измерением перемещаемого ресурса. Эта концепция прекрасно ложится на любую сферу деятельности предприятия. Например, в качестве ресурса может выступать время, затраченное работником на выполнение некоторой работы, имеющей определенную стоимость (за единицу времени), то есть появляется возможность считать сдельную зарплату универсальными учетными средствами. Путем нехитрых размышлений можно прийти к мысли, что ресурс может измеряться в разных единицах и иметь собственные атрибуты (как z-объекты). Вот новое представление проводки:
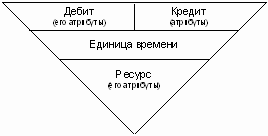
Стало быть, говоря о количественно-суммовом учете (товаре и группе, к которой он относится), мы получаем не атрибуты дебетового или кредитового z-объекта, а атрибуты единицы ресурса (тип и группу). При этом количество товара есть ни что иное, как другое измерение (отличное от денежного). Заметьте, тип товара - это аналитика именно единицы измерения! И не следует причислять ее к дебету или кредиту. Более того, я бы даже посоветовал не хранить ее в проводке. В проводке нужно хранить только сумму в деньгах (полиморфное представление). Количественный учет лучше вынести в отдельную таблицу, содержащую ссылку на проводку (связь "одна проводка ко многим детализирующим записям"). При этом можно будет добавлять несколько количественно-суммовых записей для одной проводки, а проводка будет содержать общую сумму по всем этим записям. Таким образом, проводка будет похожа на простую накладную, что очень хорошо отражает реальную жизнь. Чтобы пояснить мысль, создадим простую реализацию вышесказанного. Назовем таблицу, в которой будут лежать детали проводки, OperDet (детали операции). Номенклатура в этом случае учитывается как ссылка (поле в таблице количественно-суммового учета) на таблицу(ы) справочника номенклатуры. Вот ее описание и описание сопутствующих таблиц:
SET QUOTED_IDENTIFIER ON
SET ANSI_NULLS ON
GO
create table "Product" (
"idProd" INT IDENTITY NOT NULL PRIMARY KEY,
"ProdName" varchar(100) NOT NULL,
"ProdGroup" varchar(20) NOT NULL)
go
create table "OperDet" (
"idOper" INT NOT NULL,
"idProd" Int Not Null,
"DetCount" FLOAT NOT NULL,
"DetPrice" FLOAT NOT NULL)
go
alter table "OperDet"
add constraint "OperDet_PK"
primary key ("idOper", "idProd")
alter table "OperDet"
add constraint "Oper_OperDet_FK1"
foreign key("idOper")
references "Oper" ("idOper")
А вот ER-диаграмма:
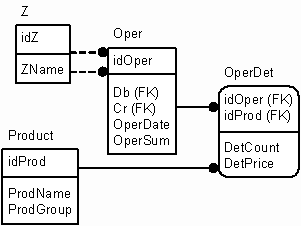
При этом, правда, появляется необходимость синхронизировать сумму операции (проводки) с суммой по соответствующим деталям операции. Это можно сделать в триггерах или в middleware.
Как ни странно, замечательное структурирование, продемонстрированное в примере выше, не порождает множества аналитических признаков. По сути, признак один - номенклатура. А нарисованное деревце - всего лишь структурирование самих признаков, и является простым (одиночным) атрибутом номенклатуры, ссылающимся на отдельный справочник групп. Можно хранить такой справочник как дерево (в виде специальной реляционной структуры) и перед агрегацией выбирать необходимые листья этого дерева (которые и являются номенклатурой), а затем делать соединение с таблицей деталей проводки и таблицей проводок, получая тем самым структуру, аналогичную приведенной выше. Агрегации по иерархии групп можно добиться, «разворачивая» ее в виде простой плоской (виртуальной) таблицы, содержащей по одной колонке для каждого уровня вложенности. Например, дерево:
Название ветки # ветки в БД
Товары на складе 1
Продукты питания 2
Вобла 3
Пиво "Lowenbrau" 4
Одежда 5
Джинсы 6
Майки 7
Обувь 8
Кроссовки 9
Ласты на каблуках 10
можно развернуть в следующую временную таблицу:
|
1 |
NULL |
NULL |
|
1 |
2 |
NULL |
|
1 |
2 |
3 |
|
1 |
2 |
4 |
|
1 |
5 |
NULL |
|
1 |
5 |
6 |
|
1 |
5 |
7 |
|
1 |
8 |
9 |
|
1 |
8 |
10 |
Для агрегации из этой таблицы нужно выделить все значения последней колонки не содержащие NULL. При формировании окончательного отчета нужно объединить (с помощь OUTER JOIN) результат агрегации с этой таблицей (по последнему полю) и подсчитать промежуточные результаты. Этот способ не требует изменения структуры БД для изменения уровней иерархии. Более того, можно создавать виртуальные иерархии (только на время построения запроса).
Но вопрос может быть связан не обязательно с количественно-суммовым учетом. Ресурс, и тем более, z-объект (ведь атрибуты применимы и к ним) может иметь различные структуру и количество атрибутов (аналитических признаков). Как быть в этой ситуации? Я вижу два выхода - создать универсальную структуру для хранения неограниченного количества аналитических признаков, или создавать (лучше всего динамически) отдельные таблицы для хранения аналитической информации для отдельных типов z-объектов. Честно говоря, до сих пор я не могу отдать предпочтение одному из вариантов. Динамические таблицы сложнее в реализации, зато дают возможность хранить атрибуты не только ссылочного типа, но и обычные атрибуты (текстовые, числовые, булевы, даты). С другой стороны, несколько усложняются полиморфные запросы, возвращающие информацию сразу по нескольким типам z-объектов или разным типам ресурсов. В любом случае, наиболее часто используемые атрибуты есть смысл хранить или непосредственно в таблице, хранящей z-объекты/ресурсы, или в таблице, описывающей их типы (например, непосредственно в z-объекте можно хранить бухгалтерский счет или тип z-объекта, а в описании типа - уже номер бухгалтерского счета). При этом для z-объекта/ресурса будет иметься полиморфная запись в универсальной таблице, хранящей z-объекты (детали операции для ресурсов), и в специализированной таблице для конкретного типа z-объектов/ресурса. Связь между этими таблицами должна быть один к одному. Собственно, это очень похоже на то, что предлагает документо-ориентированный подход (хранение информации о дебете и кредите каждого счета в отдельной таблице) только в этом случае имеется связующая таблица хранящая информацию о проводке. По сути - это то же самое, но приведенное в нормальную (нормализованную и непротиворечивую) реляционную форму.
Второй вариант тоже подразумевает наличие полиморфной таблицы z-объектов/ресурсов, но вместо динамического создания таблиц для каждого их типа использует одну универсальную таблицу. Схема, позволяющая задавать неограниченное количество атрибутов для любого z-объекта (на рисунке связующая таблица имеет название Z2Ref), показана на рисунке 1.
Ref - это упрощенная справочная таблица. В реальной жизни ее место должны занять таблицы, реализующие универсальную (необходимой сложности) модель справочников (куда можно динамически добавлять справочники и/или уровни иерархии). По сути между таблицей Ref и Z появляется связь "многие ко многим", т.е. с любым z-объектом можно ассоциировать любой элемент справочника и наоборот. Это позволяет добиться максимальной гибкости и при этом не создавать лишние таблицы (как в предыдущем случае).
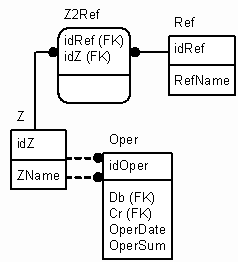
Рисунок 1
Теперь, усложнив и запутав все что можно, я попробую показать, как в этом случае можно получать агрегированные результаты в разрезе некоторого набора элементов универсального справочника.
Для начала нам нужно заполнить таблицы Ref и Z2Ref начальными значениями. Так как до реальной жизни этому всему далеко, я заполнил эти таблицы тем, что пришло к голову:
SET QUOTED_IDENTIFIER ON
SET ANSI_NULLS ON
GO
create table "Ref"
(
"idRef" INT IDENTITY NOT NULL PRIMARY KEY,
"RefName" varchar(100) NOT NULL
)
create table "Z2Ref"
(
"idRef" INT NOT NULL,
"idZ" INT NOT NULL
)
alter table "Z2Ref"
add constraint "Z2Ref_PK"
primary key clustered ("idZ", "idRef")
Insert into Ref(RefName) Values('Васек')
Insert into Ref(RefName) Values('Склад 1')
Insert into Ref(RefName) Values('Петек')
Insert into Ref(RefName) Values('Склад 2')
Insert into Ref(RefName) Values('Касса 1')
Insert into Ref(RefName) Values('Касса 1')
Insert into Ref(RefName) Values('Нюрка')
Insert into Z2Ref(idRef, idZ) Values(3, 10)
Insert into Z2Ref(idRef, idZ) Values(3, 41)
Insert into Z2Ref(idRef, idZ) Values(1, 50)
Insert into Z2Ref(idRef, idZ) Values(3, 60)
Insert into Z2Ref(idRef, idZ) Values(7, 60)
Insert into Z2Ref(idRef, idZ) Values(1, 71)
Insert into Z2Ref(idRef, idZ) Values(3, 71)
Insert into Z2Ref(idRef, idZ) Values(1, 75)
Предположим теперь, что нам нужно получить обороты для Васька и Петька, т.е. для записей 1 и 3 из таблицы Ref (в реальной жизни стоило бы добавить тип z-объекта, так как не стоит смешивать неоднородные данные, но здесь этого не делается - за неимением такового в упрощенной схеме ). Чтобы создать такой запрос, достаточно несколько модернизировать предыдущие запросы:
SELECT Agr.Z, Ref.RefName AS Name, Agr.Db, Agr.Cr
FROM (SELECT IsNull(DbS.idRef, CrS.idRef) AS Z,
IsNull(CrS.CrSum, 0) AS Db,
IsNull(DbS.DbSum, 0) AS Cr
FROM (SELECT Z2Ref.idRef,
SUM(Oper.OperSum) AS DbSum
FROM Oper INNER JOIN
Z ON Oper.Db = Z.idZ
INNER JOIN
Z2Ref ON Z.idZ = Z2Ref.idZ
WHERE (Z2Ref.idRef IN (1, 3))
GROUP BY Z2Ref.idRef
) DbS
FULL OUTER JOIN
(SELECT Z2Ref.idRef,
SUM(Oper.OperSum) AS CrSum
FROM Oper INNER JOIN
Z ON Oper.Cr = Z.idZ
INNER JOIN
Z2Ref ON Z.idZ = Z2Ref.idZ
WHERE (Z2Ref.idRef IN (1, 3))
GROUP BY Z2Ref.idRef
) CrS
ON DbS.idRef = CrS.idRef
) Agr
INNER JOIN Ref ON Agr.Z = Ref.idRef
Их основу, как и раньше, составляют два агрегирующих подзапроса, вычисляющие обороты по дебету и кредиту выбранных аналитических признаков. Задание признаков в этом примере сделано через оператор in(), в реальных запросах может быть и результатом подзапроса.