Основные понятия и терминология
Читателям, которым приходилось работать с Eclipse, IBM Rational Application Developer или продуктами IBM WebSphere (предшественниками Rational Application Developer) уже знакомы некоторые термины, используемые в данной статье.
Рабочие области, проекты и типы проектов
Возможно, вы уже знаете, что в Eclipse файлы размещаются в проектах, эти проекты могут быть различных типов (или, в терминологии Eclipse, проекты имеют характер ( natures )), а также группировка и управление проектами происходит рабочих областях . Задачи нашей статьи не предполагают подробного описания всех типов проектов, доступных в Rational Application Developer, и всех инструментов Rational для UML-моделирования на базе Eclipse. Нас, в основном, интересуют две категории проектов:
- UML-проекты, представляющие собой базовые проекты, содержащие UML-модели;
- проекты реализации, которые содержат специализированные типы проектов, а именно: проект корпоративного приложения (Enterprise Project), проект корпоративного bean-компонента Java (EJB) (Enterprise Java Beans Project), Web-проект (Web project), Java-проект (Java Project) и проект C++ (C++ Project)
Унифицированный процесс IBM Rational (IBM Rational Unified Process, RUP) определяет модель как "завершенную спецификацию предметной области проблемы или решения с конкретной точки зрения". Предметная область проблемы или система могут быть описаны несколькими моделями, которые представляют разные точки зрения на эту предметную область или систему. Например, традиционное руководство по процессу RUP предлагает конкретный набор UML-моделей:
- модель бизнес-анализа;
- модель бизнес-прецедента;
- модель прецедента;
- модель проекта;
- модель анализа (может входить в модель проекта);
- модель реализации;
- модель развертывания;
- модель данных.
Кроме того, процесс RUP не зависит от применяемых инструментов. Следовательно, модель для RUP может представлять собой схему, изображенную на салфетке или белой доске, набросок в инструменте для моделирования или даже мысленный образ. С точки зрения RUP, модель - это логическая концепция, в отличие от физической; именно этой точки зрения мы и будем придерживаться в данной статье.
В контексте изучаемых продуктов модели бывают двух общих типов: концептуальные и конкретные .
- Концептуальные модели представляют собой идеи и манипулируют идеями. Отличным примером могут служить типичные UML-модели. Концептуальные модели не имеют автоматизированной привязки к исполняемой реализации. Примечание: существуют продукты, например, IBM Rational Rose RealTime, которые поддерживают выполнение, отладку и тестирование UML- моделей в среде исполнения, предназначенной для этой цели. Такие UML-модели следует считать конкретными.
- Конкретные модели представляют собой способ графического изображения и прямого манипулирования артефактами реализации, которые могут быть автоматически преобразованы в исполняемый файл. Характерные примеры - Java-модели и C++-модели. Конкретные модели иногда называют просто моделями кода, если в их основе лежит семантика языков 3GL. Еще один класс конкретных моделей строится на декларативных языках. Характерный пример - физические модели данных, которые напрямую оперируют языком определения данных (Data Definition Language) SQL.
В рассматриваемых продуктах мы взаимодействуем с моделями, в основном, через диаграммы и панель обозревателя проектов Eclipse Project Explorer.
Примечание
Различие между концептуальными и конкретными моделями и различие, которое управляемая моделями архитектура (Model Driven Architecture, MDA) Object Management Group (OMG) проводит между платформенно-зависимыми и платформенно-независимыми моделями - это не одно и то же. Модель может быть платформенно-зависимой и в то же время концептуальной.Файлы моделей (механизмы хранения для моделей)
Рассматриваемые продукты хранят модели в виде файлов. В Eclipse файл считается видом ресурса. Ресурсы в среде Eclipse могут обладать дополнительными свойствами и поведением, следовательно, понятие ресурс шире, чем файл . Описываемые здесь файлы моделирования реализованы в виде ресурсов Eclipse. Следовательно, термины ресурс моделирования и файл моделирования здесь и в других материалах обозначают одно и то же.
В более широком смысле программное обеспечение поддерживает два вида файлов моделирования:
- файлы концептуальной UML-модели хранятся в проектах Eclipse и имеют расширение имени файла .emx и .efx (о различиях между этими типами файлов мы поговорим позже). Перечисленные файлы содержат два вида контента:
- семантические элементы UML (классы, деятельности, отношения и т. д.);
- элементы нотации UML, организованные в диаграммы, которые описывают семантические элементы UML (эти диаграммы могут также отражать визуальные ссылки на другие понятия в других семантических предметных областях, например, Java, C++ или DDL).
- файлы конкретного моделирования (например, Java, C++, DDL) также хранятся в проектах Eclipse в рабочей области Eclipse и содержат комбинацию семантической и нотационной информации, но в этом случае семантическое и нотационное содержимое более четко разделяются:
- семантические элементы конкретной модели хранятся в артефактах реализации. Например, для Java семантическая модель сериализуется и хранится в виде коллекции файлов исходного кода Java. (Когда мы запускаем инструмент, семантическая модель размещается в памяти как абстрактное синтаксическое дерево Java);
- каждая диаграмма хранится в отдельном файле. Файлы диаграмм могут иметь различные расширения, но чаще всего используется расширение .dnx. Диаграммы конкретного моделирования могут использовать как нотацию UML, так и другие нотации (например, IDEF1X, нотации информационной инженерии для визуализации данных или фирменные нотации IBM , которые используются для проектирования Web-слоев).
Наши рекомендации по структурированию моделей касаются, в основном, структурирования артефактов и контента концептуальных моделей. Рекомендации по организации контента конкретных моделей (то есть, проектов реализации) можно найти в других источниках, например в справке (Help) в Rational Software Architect, Rational Application Developer, и Eclipse. До некоторой степени организация конкретных моделей определяется соглашением о типах проектов Eclipse. Тем не менее, общие принципы, относящиеся к логической организации решений и рассматриваемые в разделе "Вопросы коллективной разработки и управления моделями" этой статьи, применимы и концептуальным моделям, и к артефактам реализаций.
В рассматриваемых продуктах мы взаимодействуем с файлами моделирования, главным образом, через панель обозревателя проектов Eclipse Project Explorer.
Файлы UML-модели: логические единицы и фрагменты
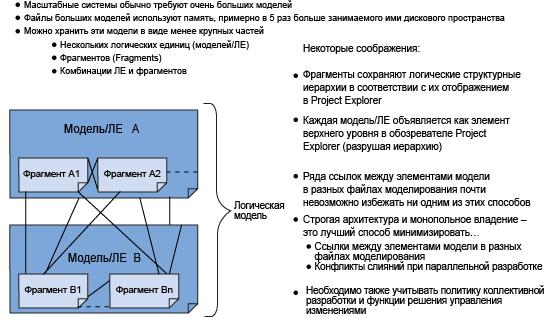
Иногда UML-модели становятся настолько большими, что возникает необходимость их хранения в виде меньших по размеру частей. Кроме того, когда коллективы специалистов по моделированию совместно работают над контентом модели с высокой степенью взаимосвязанности, необходимо управлять проблемами противоречий и владения. Для этого рассматриваемые продукты предоставляют два пути разбиения логического контента UML-модели на физические контейнеры хранения:
- логические единицы (Logical Units);
- фрагменты (Fragments).
Перечисленные ниже атрибуты описывают поддержку логической единицы (далее ЛЕ) в версии ПО, которая доступна на момент написания данной статьи (в будущих версиях программы описанные соглашения и ограничения могут изменяться).
- В пользовательском интерфейсе программы логическая единица (ЛЕ) называется UML Model (UML-модель). Следовательно, когда мы выбираем в меню команды New > UML Model, на самом деле мы создаем ЛЕ.
- UML-модель (а следовательно, ЛЕ) представляет собой наименьшую единицу UML-контента, которую можно "открыть" и "закрыть" при помощи команд в меню File и в меню обозревателя проектов Project Explorer. (Существует возможность открыть фрагмент (Fragment), выбрав его в представлении Navigator, но в результате этого действия все равно открывается ЛЕ, содержащая этот фрагмент.)
- Каждая логическая единица имеет корневой элемент, который представляет собой пакет самого верхнего уровня. Корневой элемент логически содержит другие UML-элементы (владеет ими или является для них родительским элементом) , которые зависят от него в отношении предоставления требований на контейнер и пространство имен. Таким образом, в этом отношении поведение корневого элемента не отличается от любого другого UML-пакета. Однако корневой элемент имеет особое свойство: он также хранит информацию о ЛЕ в целом, а именно:
- набор UML-функций, которые задействованы при работе с ЛЕ;
- UML-профили, которые применяются к ЛЕ.
- ЛЕ существует в виде файла с расширением .emx (см. рисунок 1).
- В этом файле, как минимум, содержится корневой элемент. В нем также могут храниться и другие элементы, но можно рассматривать любой UML-классификатор или диаграмму, которой логически владеет корневой элемент, как фрагмент (Fragment), хранящийся в отдельном .efx -файле.
- UML-модель (ЛЕ) в представлении Project Explorer всегда отображается как конструкция верхнего уровня. Другими словами, в текущем пользовательском интерфейсе Rational логические единицы нельзя наглядно упорядочить в произвольные логические структурные иерархии. Существует возможность создать произвольные структурные иерархии в чистом виде при помощи отношений
<<ElementImport>>и<<PackageImport>>. Однако это по-прежнему не отражается на изображении иерархий в Project Explorer, в которых UML-модель/ЛЕ всегда является элементом самого верхнего уровня.Кроме того, программа поддерживает концепцию фрагментов модели, имеющих следующие свойства:
- фрагмент хранится в файле с расширением .efx;
- хотя фрагмент существует самостоятельно, в смысле логических структур хранения и пространства имен он полностью зависит от ЛЕ, которой принадлежит;
- другими словами, как и ЛЕ, фрагмент может содержать произвольное подмножество логической модели;
- в отличие от ЛЕ, фрагмент не обязательно определяет логическую структуру хранения или пространство имен. По сути, фрагмент можно определить на уровне UML-классификатора или диаграммы. Например, фрагмент может включать только один класс, одну деятельность или один компонент, но он также может быть определен на уровне пакета, и в этом случае он соотносится с пространством имен и может содержать другие элементы. Но и в этом случае вся структура, определяемая таким фрагментом, остается дочерним элементом содержащей ее ЛЕ;
- вследствие зависимости от структуры хранения и пространства имен, фрагмент нельзя открыть вне контекста. Другими словами, чтобы открыть фрагмент, необходимо открыть ЛЕ, которой он принадлежит.
В рассматриваемых продуктах можно создать несколько ЛЕ (как UML-модели). В одном проекте можно создать одну или более логических единиц, а несколько проектов в рабочей области могут содержать несколько ЛЕ. Одновременно может быть открыто и доступно для редактирования любое количество логических единиц. Можно определить отношения, которые будут существовать между элементами, содержащимися в разных ЛЕ.
Миграция между Rational XDE и Rational Rose
Rational XDE поддерживает многомодельную парадигму, аналогичную используемой в программах для управления архитектурой Rational . Кроме того, программа поддерживает также структуры, аналогичные фрагментам (Fragments) в Rational, которые называются subunits .
В Rational Rose, в отличие от Rational XDE и ПО Rational для управления архитектурой, в любой момент времени может быть открыта только одна модель. Следовательно существует только один способ совместного использования контента в разных моделях - это изолировать нужный контент в файлах с расширением .cat, а затем включить эти .cat-файлы в несколько моделей. В Rational Rose .cat-файлы также используются как механизм разбиения хранилища модели. Следовательно, в терминах Rational, .cat-файлы Rose можно использовать либо как логические единицы, либо как фрагменты.
Как уже говорилось ранее, мы взаимодействуем с логическим контентом UML-моделей через диаграммы и через обозреватель проектов Project Explorer. Если речь идет об UML-модели, то элементы, содержащиеся в ЛЕ и фрагментах (логический контент модели) отображаются в представлении Project Explorer, а реальные файлы .emx и .efx (физические механизмы хранения) не отображаются. Эти моменты важны по следующим причинам:
- способ, предполагающий использование нескольких ЛЕ для физического разбиения контента модели, является логически непрозрачным. То есть, мы ясно видим, что ЛЕ отображаются в представлении Project Explorer, потому что они всегда отображаются как элементы верхнего уровня;
- способ, предполагающий использование фрагментов для физического разбиения контента модели, является логически прозрачным. То есть, по умолчанию, единственный способ увидеть какое-либо обозначение фрагментов заключается в том, что UML-элементы, соответствующие фрагментам, помечаются графическими символами, видимыми в Project Explorer (см. рисунок 1).
До сих пор мы рассматривали логические единицы и фрагменты, которые представляют собой механизм разбиения модели. В разделе "Вопросы коллективной разработки и управления моделями", мы расскажем о том, как использовать эти механизмы в стратегии разбиения модели.
В предыдущем разделе мы определили модель как логическую конструкцию (в соответствии с RUP). Затем мы дали определение файлу моделирования. Далее мы точно определили логическую единицу как физический механизм хранения для единиц логического контента модели. В текущей версии программы, когда мы создаем, открываем, закрываем, переименовываем, удаляем или объединяем "UML-модели," мы на самом деле осуществляем эти операции с логическими единицами. В следующих версиях будет можно объединять ЛЕ в виртуальные структурные иерархии, в результате понятия "UML - модели" и ЛЕ будут разделены. Поскольку в текущем проекте понятия UML-модели и ЛЕ сливаются, мы воспользуемся более строгим термином модель/ЛЕ для обозначения ЛЕ в текущей реализации. Это позволит вам точно понять, когда в статье говорится о модели или UML-модели в чисто логическом смысле, в отличие от модели/ЛЕ.
Далее в рекомендациях по структурированию моделей используются следующие термины в следующих значениях:
файл моделирования: если не указано иное (например, "файл конкретного моделирования"), термин используется в общем смысле для обозначения файлов с расширением .emx или .efx;
логическая единица: используется для обозначения логической единицы как инструмента для физического разбиения логического контента моделей;
модель или UML-модель: используется при рассмотрении моделей вообще, и UML-моделей в частности, в чисто логическом смысле;
модель/ЛЕ: используется для обозначения логической единицы как физического артефакта, над которым выполняются операции при создании, открытии, закрытии, переименовании, удалении или объединении "UML-моделей" в рамках пользовательского интерфейса.
Как уже говорилось ранее, платформа Eclipse поддерживает несколько типов проектов, а рассматриваемые продукты поддерживают два вида моделей:
- UML-модели (разновидность концептуальной модели), сохраняемые в виде логических единиц;
- конкретные модели (различных видов), сохраняемые как проекты Eclipse, включающие:
- файлы различных типов, которые содержат семантическую информацию, основанную на нескольких технологически-специфических метамоделях (например, в Web-диаграммах) или абстрактных синтаксических деревьях (например, в Java™);
- файлы с расширением .dnx, которые содержат нотационную информацию и ссылки на семантические элементы (то есть, диаграммы).
При включении моделей в проекты следует помнить следующие рекомендации:
- Конкретные модели не требуют особого внимания, потому что, по сути, [конкретная модель] = [проект Eclipse].
- При использовании UML-моделей для преобразований Java, C++ или C#, поставляемых с рассматриваемыми продуктами:
- Если используются итеративные повторные применения преобразования UML - 3GL или прямые и обратные преобразования вместе с функцией Reconcile, поместите модель/ЛЕ в проекты Eclipse, в которые не включены соответствующие конкретные модели (сгенерированный код).
- Если преобразования используются для замены элементов, и при этом вы обычно практикуете комбинированное моделирование (при котором UML-элементы и 3GL-элементы изображаются на одних и тех же диаграммах), поместите модель/ЛЕ в те же проекты Eclipse, что и сгенерированный код. В этих случаях в моделях/ЛЕ должен храниться только контент проектирования (моделирования на уровне классов), а остальной контент (прецеденты, аналитика, взаимодействия на уровне проекта или модели состояний и т. д.) должны храниться в отдельных моделях/ЛЕ в других проектах Eclipse.
В ряде случаев это может оказаться невозможным. Например, существуют конкретные соглашения для использования нескольких проектов Eclipse разных типов (например, Java, Web и корпоративные bean-компоненты Java™ (EJBs)) для хранения контента реализации корпоративного Java-решения.
- В остальных случаях (когда преобразования не используются), можно поместить концептуальные (UML) модели, которые тесно связаны с определенными конкретными моделями, в папку с именем Conceptual Models в том же проекте Eclipse. Это отражение архитектурного принципа высокой функциональной сцепленности , к которому мы постоянно будем возвращаться в следующих рекомендациях по структурированию моделей.
- Как правило, проекты Eclipse используются, в том числе, в качестве грубо детализированных единиц управления конфигурацией. Из этого следует, что, если конкретная модель/ЛЕ была структурирована для поддержки строгого владения конкретным исполнителем, она должна представлять собой отдельный проект Eclipse. Вариантом этой темы может быть ситуация, в которой один исполнитель строго владеет коллекцией моделей/ЛЕ, которая относится к определенному функциональному аспекту, но этот исполнитель моделирует указанные аспекты на протяжении всего жизненного цикла и желает использовать отдельные модели/ЛЕ для моделирования прецедентов, анализа и на уровне проекта с учетом этого функционального аспекта. В подобных случаях имеет смысл поместить эти несколько моделей/ЛЕ в один функционально-ориентированный проект Eclipse и хранить все концептуальные модели для всего жизненного цикла разработки в одном проекте. Однако предыдущая рекомендация об использовании преобразований имеет приоритет перед данной рекомендацией.
- Модели/ЛЕ, которые отражают общие аспекты и на которые должны ссылаться несколько других высокосцепленных и слабосвязанных моделей/ЛЕ, необходимо хранить в UML-проектах, которые инкапсулируют такие общие аспекты. Например, если на модель прецедента ссылается содержимое нескольких проектов, то эта модель не должна быть размещена ни в одном из этих ссылающихся на нее проектов. Ее необходимо разместить в отдельном проекте или в проекте, который объединяет несколько других общих аспектов.
Миграция между Rational XDE и Rational Rose
Методики работы с Rational Rose и Rational XDE используют метод итеративного уточнения модели проекта до тех пор, пока не будет достигнут уровень абстракции, эквивалентный коду, а затем используется технология синхронизации модели кода, позволяющая сохранить согласованность семантики этой модели с самим кодом. Таким образом, например, в Rational XDE модели реализации существуют не только в виде кода и диаграмм в проектах, но и в виде файлов модели кода, которые содержат UML-семантику и хранятся независимо от артефактов реализации. По существу, это дополнительные резервные копии семантики кода, представленные на языке UML. Кроме того, в Java-версии Rational XDE действует правило, согласно которому UML-модели Java-кода должны размещаться в тех же проектах, что и сам Java-код.
Рассматриваемые продукты не поддерживают режим автоматической синхронизации (Autosync mode) Rational Rose и Rational XDE. Вместо этого на уровне абстракции кода вы просто компонуете диаграммы (при помощи UML-совместимых нотаций), которые непосредственно изображают семантику кода (как и раньше, мы относим это к конкретному моделированию).
В рассматриваемых продуктах UML-модели не являются строго типизированными, но вы можете соблюдать соглашение об использовании нескольких слаботипизированных моделей/ЛЕ. Задать использование слабой типизации можно двумя способами:
- создать пустую модель/ЛЕ; в этом случае, чтобы задать ее тип, необходимо просто назвать модель соответствующим образом и поместить в нее соответствующий контент (включая и UML-профили, которые будут к ней применяться);
- создать модель/ЛЕ на основе предопределенного шаблона, который соответствует определенному типу модели. Рассматриваемые продукты по умолчанию предоставляют набор шаблонов моделей для типов моделей, описанных в этой статье. Вы можете также создать пользовательскую модель/ЛЕ и использовать ее в качестве шаблона.
В любом случае, когда мы говорим о "типе" модели, на самом деле мы просто имеем в виду соглашение о наименовании и контенте модели/ЛЕ и, возможно, UML-профили, которые к ней применяются. Например, инструмент не будет препятствовать созданию модели/ЛЕ, которая, в соответствии с соглашением, получена из модели прецедента и, кроме того, содержит классы, которые реализуют прецеденты (что, по рекомендациям RUP, считалось бы частью модели анализа или проекта).
Предположим, что у нас есть несколько рабочих групп, которые работают над коллекцией приложений, являющихся частью корпоративной системы для крупной, интегрированной сети поставщиков услуг здравоохранения, которая (хотя это маловероятно) решила самостоятельно разработать большую часть своих основных приложений. В данной ситуации необходимо учитывать следующие факторы (и, вероятно, многие другие):
- несколько рабочих групп работают над основными или общими функциями, вроде нижеперечисленных, которые используются несколькими решениями:
- сервисы, демонстрирующие и обслуживающие согласованность кодовых словарей, которые используются в приложениях для здравоохранения;
- сервисы, представляющие доступ к основным объектам (пациентам, поставщикам, плательщикам и т. д.), которые используют эти приложения;
- совместно используемые приложения, которые контролируют, кто из пользователей системы имеет доступ к конкретным функциям определенных приложений.
- несколько рабочих групп работают над различными подсистемами решения Информационной системы лаборатории (Laboratory Information System, LIS), которая выполняет следующие задачи:
- обработка заказов на услуги лаборатории;
- управление и выдача результатов лабораторных анализов.
- Одна рабочая группа работает над решением Информационной системы радиологической лаборатории (Radiology Information System, RIS), которая выполняет следующие задачи:
- обработка заказов на услуги радиологической лаборатории;
- обслуживание и выдача результатов лабораторных анализов;
- составление расписания услуг радиологической лаборатории.
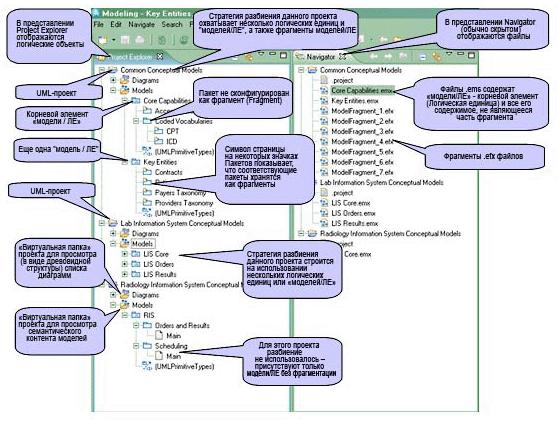
На рисунке 1 показано несколько способов, которые могут выбрать данные коллективы для разбиения своих моделей таким образом, чтобы они отражали их владение конкретными функциональными возможностями. В данный момент мы игнорируем вопрос о типах концептуальных моделей и не пытаемся показать, как могут выглядеть соответствующие проекты реализации. Вместо этого нам необходимо сосредоточиться на различных стратегиях разбиения моделей, которые они могут выбрать.
Рисунок 1. Примеры способов разбиения моделей разными рабочими группами
Важное примечание:
для краткости на рисунке 1 все проекты показаны в одной рабочей области. В реальной ситуации более вероятно, что рабочие области каждой рабочей группы будут выглядеть по-разному. Для примера предположим, что между системами Радиологической лаборатории и Лаборатории не существует прямых зависимостей, рабочие области коллективов, работающих над LIS и RIS, могут содержать только общие проекты Eclipse, от которых они зависят, и их собственные проекты Eclipse. Рабочая область коллектива, имеющего общие кодовые словари, может содержать только модель/ЛЕ основных функций в собственном проекте Eclipse. Кроме того, вполне вероятно, что рабочая группа LIS разместит каждую из своих нескольких моделей/ЛЕ в отдельном проекте Eclipse, что позволит работать с ними, а также управлять конфигурациями, как с независимыми единицами, а, значит, и с большей эффективностью.В этом сценарии мы получим следующие результаты:
- рабочая группа RIS решила не выполнять разбиение своей модели. Вероятно, это отражает ситуацию в данном коллективе, при которой один специалист создает модели, а все остальные занимаются созданием кода;
- рабочая группа LIS выбрала разбиение на несколько моделей/ЛЕ. Возможно, это сигнализирует о том, что архитектура LIS является весьма строгой и состоит из некоторого количества высокосцепленных подсистем, которые имеют слабые взаимозависимости, так что у отдельных сотрудников редко возникает необходимость просмотреть контент, которым они "владеют" в контексте всего контента LIS;
- рабочие группы, занимающиеся общими функциями, в своей стратегии разделения используют модели/ЛЕ и фрагменты. Возможно, причина заключается в том, что если бы они использовали исключительно разбиение на фрагменты, единственная модель/ЛЕ могла бы оказаться неудобной в качестве основы для публикации модели. Или, может быть, это решение отражает их предпочтения в отношении глубины логической структуры, которую они используют, чтобы упорядочить контент своей модели.
Вопросы коллективной разработки и управления моделями
Миграция между Rational XDE и Rational Rose
Обозреватель моделей Model Explorer в Rational Rose и в Rational XDE обеспечивает только логическое представление UML-моделей, тогда как обозреватель проектов Project Explorer в рассматриваемых продуктах позволяет увидеть логические представления различных видов моделей (UML, Java, Web и т. д.) в одном программном представлении.
Фундаментальная проблема коллективов, совместно работающих над любым типом спецификаций, будь то набор документов, набор моделей или базовый код, заключается в необходимости контролировать изменения.
В случае спецификаций на основе документов, группа имеет возможность выбора из нескольких вариантов.
- Специалисты, отвечающие за конкретные аспекты спецификации, включаемые в общий документ, выполняют свою работу последовательно. Вы просто включаете функцию мониторинга изменений и передаете документ от одного исполнителя к другому. Периодически специально назначенные специалисты анализируют и принимают или отклоняют изменения для создания релиза (базовой линии).
- Исполнители работают параллельно. Чтобы создать релиз, специалист должен выполнить слияние нескольких копий от разных исполнителей в общий документ (при помощи специальной функции текстового процессора или средств слияния инструмента управления конфигурацией).
- Спецификация разбивается на несколько документов, владение которыми строго распределяется между сотрудниками рабочей группы, которые могут работать параллельно, не создавая потребности в слияниях. Но часто (чтобы избежать создания избыточных копий некоторых фрагментов спецификации) может быть назначен владелец (по типу строгого владения) общего контента, который будет вносить изменения по требованию других сотрудников коллектива. В качестве альтернативы при помощи стратегии слияний можно управлять только общими фрагментами.
В любом случае должно существовать правило относительно того, каким образом и с какой периодичностью версии документа сохраняются, защищаются и, при необходимости, объединяются и согласовываются.
Проблемы базового кода аналогичны. Однако здесь нет возможности использовать мониторинг изменений в исходных файлах (в редакторах программного кода и IDE такой функции не предусмотрено). Следовательно, когда строгое владение исходными файлами не имеет места, и с файлами параллельно работает несколько сотрудников, рабочей группе необходимо использовать средства для отслеживания промежуточных состояний и слияния текстовых файлов системы управления конфигурацией. Часто при работе с базовым кодом возникает проблема работы с несколькими версиями или потоками одного и того же кода, представляющего разные параллельные версии одного релиза. Потребность в переносе некоторых изменений из одного потока в другой - это задача, с которой в определенных ситуациях можно справиться при помощи средств слияния инструмента управления конфигурацией.
С моделями могут быть связаны те же проблемы, что и с кодом, особенно когда они начинают отражать уровень детализации, который выражается кодом. Более абстрактные модели могут использовать более облегченный принцип управления изменениями, возможно, более близкий к тому, который практикуется при работе с документами спецификаций. Но и сами модели могут вызывать особые проблемы:
- количество и направленность связей (взаимозависимостей) в моделях отличаются большей сложностью, чем базовый код;
- если код реализует зависимость, просто ссылаясь на имя поставщика, модели реализуют отношения как реальные семантические элементы в соответствии с определением метамодели (например, Ассоциация, Обобщение, Реализация). Этими элементами необходимо тщательно управлять, чтобы предотвратить взаимное наложение сложных моделей;
- модели поддерживают более полный набор типов отношений, чем программный код. Следовательно, могут, к примеру, иметь место ситуации, при которых элемент модели не просто использует или специализирует другой элемент (аналогично использованию или расширению одного Java-класса другим), но и уточнять другие элементы (в терминах уровня абстракции);
- на семантические элементы модели могут ссылаться в общей сложности несколько диаграмм, изображающих различные аспекты общей спецификации.
- в моделях перенос-рефакторинг изменений может оказывать существенное влияние, потому что пакет и отношение включения пространства имен определено более строго, чем в коде. В моделях это выполняется персистентным (статическим) образом с использованием реальных логических связей, тогда как в коде обработка выполняется динамически ядром сборки на основе полных уточненных имен;
- еще одна проблема связана с тем, что модели часто используют элементы высшего порядка (например, ассоциации и абстракции) там, где в коде использовались бы обычные ссылки по имени. Эти элементы следует внимательно контролировать, в противном случае они могут привести к возникновению путаницы в моделях.
Если в вашей практике используется параллельная коллективная разработка файлов моделей (совместное владение), то в файлы, которые требуют слияния, могут быть внесены нескоординированные изменения. Можно привести следующие примеры процессов параллельной разработки, в рамках которых это может происходить:
- файл моделирования может быть снят с контроля для немонопольного доступа;
- с файлом моделирования параллельно работают несколько исполнителей в параллельных потоках разработки.
Если оказывается, что некоторые из изменений конфликтуют с другими, то слияние считается нетривиальным , потому что необходимо принять решение по поводу того, какое из конфликтующих изменений должно превалировать. ( Тривиальным называют слияние, при котором нескоординированные изменения не находятся в состоянии конфликта, а инструмент слияния моделей может выполнить слияния без вмешательства человека.) Рассматриваемые продукты предоставляют эффективные средства для поддержки как тривиального, так и нетривиального слияния моделей, но нетривиальные слияния могут стать нетривиальной работой для выполняющего их специалиста.
Совет:
предотвращение случаев нетривиального слияния моделей должно стать основной целью при формулировании стратегии организации модели в поддержке коллективного моделирования.Моделирование в коллективе: общие принципы
Прежде, чем приступить к обсуждению методов организации моделей, мы должны рассмотреть общие принципы, которые должны направлять стратегию разбиения модели. Учитывая нашу цель - предотвращение нетривиальных слияний - можно выделить два основных принципа: строгая архитектура и строгое владение. Эти два принципа идут рука об руку, поскольку строгая архитектура делает возможным строгое владение.
Принцип 1: строгая архитектура
В данном контексте термин строгая архитектура относится, главным образом, к декомпозиции. Применяемые здесь принципы архитектурной декомпозиции - это те же принципы, которые лежат в основе объектно-ориентированной разработки, проектирования на основе компонентов и сервис-ориентированной архитектуры.
- Стремитесь к максимальной функциональной сцепленности.
- Стремитесь к минимальной связанности бизнес-функций.
- Те функции, которые должны оставаться жесткосвязанными, сгруппируйте, а затем изолируйте такие группы от остальных функций.
Если результат декомпозиции все еще слишком детализирован, то, в зависимости от модели подбора персонала (помните: строгая архитектура и строгое владение идут рука об руку) вы, возможно, захотите сгруппировать эти детали в агрегаты с высокой степенью сродства (в терминах UML- моделирования это пакеты).
При этом всегда будут некоторые элементы, которые должны входить в несколько единиц декомпозиции (а в некоторых случаях, во все единицы). Сгруппируйте такие элементы в общие подкатегории или группы и запланируйте каждую итерацию разработки таким образом, чтобы она включала некоторую свободу действий в начале итерации, которая была бы направлена на стабилизацию общих элементов.
Существует также элемент времени. По мере того, как вы продвигаетесь от более абстрактного понимания решения к более конкретному, ваше представление о наилучшей организации архитектуры (и модели) будет изменяться. Поэтому необходимо планировать выполнение рефакторинга (реорганизации) модели на регулярной основе.
Если при взгляде на решение все выглядит слишком взаимозависимым и жесткосвязанным, то либо вам необходимо еще поработать над архитектурой, либо в характере проблемной предметной области есть что-то, что мешает вам выполнить декомпозицию проблемы. В любом случае у вас есть только два варианта:
- примите решение о передаче проекта очень малой группе, которая работает в одном физическом пространстве, и сотрудники которой очень активно общаются друг с другом по поводу любых изменений, которые могут повлиять на другие артефакты (применяйте принципы agile- разработки в отношении ваших действий по моделированию);
- приготовьтесь к тому, что придется выполнять множество нетривиальных слияний.
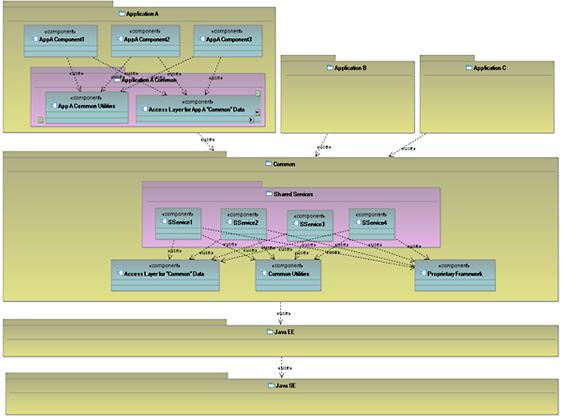
Хороший способ оценить строгую архитектуру модели - это проверить, насколько эта строгая архитектура проявляется в базовом коде. Здесь мы четко видим принципы стабилизации общих фрагментов, а затем успешного разделения на уровни более специализированных фрагментов. Рассмотрим гипотетическую архитектуру для решения на базе технологии Java™ 2 Platform, Enterprise Edition (J2EE), изображенную на рисунке 2.
Рисунок 2. Гипотетическая архитектура решения на базе J2EE
Итак, мы видим, что API Java™ Platform, Standard Edition (Java SE) достаточно стабильны. API Java 2 Platform, Enterprise Edition (J2EE) почти так же стабильны, как в Java SE. И те, и другие используются всеми сервисами и приложениями. Поверх базовой инфраструктуры J2EE мы видим такие элементы, как Access Layer for "Common" Data and Common Utilities (Уровень доступа для "общих" данных и общих утилит"). Они также используются всеми сервисами и приложениями, поэтому изолированы от них и стабилизируются на ранних стадиях проекта. Поверх них имеется уровень совместно используемых, или общих, сервисов (или компонентов , если вы предпочитаете этот термин). Эти уровни зависят от уровней, расположенных под ними, и все приложения, которые их используют, также зависят от них, поэтому, в идеале, они достаточно стабильны к тому моменту, когда поверх них надстраиваются приложения.
Описанные принципы переносятся в модели понятным большинству специалистов способом. Но если речь идет о коде, то интуитивно понятно (по меньшей мере разработчику), что поставщики в архитектуре (поставляющие нечто такое, что используют другие стороны) - это интерфейсы (API), а потребители (использующие то, что поставляется) - реализации. В моделях нет такого разделения. В соответствии с ограничениями метамодели UML, любой элемент модели может быть поставщиком, потребителем, или поставщиком и потребителем одновременно. Использование соглашений об организации и взаимозависимостях модели осуществляется по усмотрению рабочей группы по моделированию.
Принцип 2: строгое владение
Не говоря уже о формировании набора специализированных квалификаций, после того, как вы утвердили использование строгой архитектурной декомпозиции, строгое владение отдельными исполнителями архитектурными компонентами представляется довольно очевидным. Если над каждой единицей структуры модели может работать только один исполнитель, возможность возникновения конфликтов ограничивается только теми моментами, в которых необходимы отношения между разными единицами (уточнение или использование другой зависимости, ассоциации, изображение на диаграммах и т. д.). При наличии строгого владения, независимо от того, состоят ли структурные единицы из целых моделей/ЛЕ или пакетов в одной модели/ЛЕ и от того, сконфигурированы ли пакеты как фрагменты, слияния будут по большей части тривиальными, а, следовательно, быстрыми и относительно безболезненными. То же можно сказать и для ситуации, когда над каждой структурной единицей может работать только небольшой коллектив, располагающийся в одном локальном подразделении, члены которого могут координировать свою работу, чтобы избежать возникновения конфликтующих изменений в своих вложенных единицах.
Миграция между Rational XDE и Rational Rose
Еще одно различие заключается в том, что Rational Rose из-за отсутствия поддержки нескольких логических моделей стимулирует (а, по сути, вынуждает) к использованию структурирования моделей как набора иерархий в одной логической модели. Таким образом, пользователям Rational Rose может показаться удобным использовать тот же подход в программах Rational для управления архитектурой, чтобы остаться в "комфортабельной зоне". Но отказ от изучения дополнительной гибкости более новых программ Rational может привести к менее позитивному опыту в коллективном моделировании при помощи Rational.
Моделирование в коллективе: разбиение моделей
Из раздела "Основные понятия и термины", мы узнали, что ПО Rational для управления архитектурой предлагает два способа разбиения физического воплощения UML-модели: модели/ЛЕ и фрагменты. (Важно: если вы пропустили этот раздел, вернитесь и прочитайте его сейчас.) В этом разделе даются ответы на следующие вопросы:
- Когда следует выполнять разбиение модели?
- Какой механизм лучше использовать для разбиения - модели/ЛЕ или фрагменты?
Принимая решение, следует учесть следующие факторы:
- размер и сложность модели. По мере того, как модели становятся (или обещают стать) громоздкими либо из-за своего размера, либо из-за глубины логической структуры (пакета), может возникнуть необходимость в их разбиении на несколько моделей/ЛЕ или фрагментов для повышения производительности или для удобства выполнения отдельных операций (например, генерации отчетов).
- структура моделей. Модели, имеющие строгую архитектуру и использующие строгое владение, с меньшей вероятностью потребуют разбиения. Архитектурная строгость структуры модели также может повлиять на выбор решения для управления конфигурацией, третий фактор в принятии решения.
- выбор программного обеспечения для управления конфигурацией (configuration management, CM). Некоторые CM-инструменты отличаются лучшей поддержкой разбиения моделей по сравнению с другими инструментами.
- применение преобразований. Принцип работы некоторых преобразований налагает ограничения, которые могут влиять на принятие решения о разбиении модели. Например, стандартное преобразование Java - UML, поставляемое с некоторыми рассматриваемыми продуктами, позволяет использовать в качестве цели только модели/ЛЕ. Следовательно, если существует потребность в преобразовании нескольких Java-проектов по отдельности, возможно, лучше создать отдельную модель/ЛЕ для каждого из них.
На самом деле не так уж сложно понять, когда необходимо выполнить разбиение моделей по причинам сложности или размера. Разбиение необходимо, в основном, в тех случаях, когда файлы разрастаются до слишком больших размеров для машин, которые используются в данном сообществе пользователей. Например, с моделью, которая занимает 30 Мбайт дискового пространства, становится очень трудно выполнять повседневные операции на компьютере с 1 Гбайт оперативной памяти. Рекомендуется разбить такую модель, чтобы в любой данный момент времени в оперативной памяти размещалось от 5 до 10 Мбайт. В качестве альтернативы можно увеличить размер оперативной памяти, что дает преимущества не только для моделирования. Компьютер с оперативной памятью 2 Гбайт без файла подкачки выполняет почти все операции Eclipse быстрее. Он также заставляет работать очень быстро очень большие модели.
Вопрос о том, когда применять разбиение моделей из соображений эффективности коллективной работы, также требует небольшого обсуждения. Попробуйте поступать так только в тех случаях, когда над файлами моделей (модели/ЛЕ или фрагменты), которые вы создаете, можно, как правило, работать с монопольным доступом (только один член коллектива снимает файл с контроля в каждый конкретный момент времени) и изолированно (большинство изменений в файл могут быть внесены без необходимости доступа к другим файлам, содержащим связанные элементы модели). Здесь мы имеем дело с компромиссом. Разбиение сужает объем логического контекста, доступного в процессе сеанса слияния. Поскольку логического контекста становится меньше, оператор, принимая решение о слиянии, должен в большей степени полагаться на предположения и допущения. Проще говоря, небольшие фрагменты модели - это лучший контекст для слияний.
Часто возникает следующий вопрос: можно ли избежать нетривиальных слияний путем разбиения моделей на несколько моделей/ЛЕ или фрагментов? Можно ответить одним словом: нет.
Но со следующей оговоркой: Если вы используете CM -решение, которое эффективно поддерживает пессимистическую схему блокировки, то физическое разбиение может помочь избежать слияний. Кроме того, она ограничивает диапазон возможных действий. Например, работая с дискретной частью модели, вы не можете выполнить рефакторинг-переименование, не снимая с контроля и не изменяя все другие части, которые должны быть обновлены в результате этой операции.
Архитектурные взаимозависимости - это не физический, а логический феномен. Если вы разбиваете модель на несколько моделей/ЛЕ или фрагментов, то представление взаимозависимостей элемента из ссылок внутри файла превращается в обычные ссылки между файлами. Это ни в коей мере не облегчает разрешение конфликтов (скорее, наоборот, затрудняет). Когда мы добавляем ссылки между файлами, мы добавляем потенциальные точки сбоев (см. врезку).
И все же в некоторых случаях разбиения невозможно избежать. Если вам приходится использовать разбиение, возможно, вы захотите узнать, по какому принципу следует делать выбор между использованием моделей/ЛЕ или фрагментов в качестве физического механизма разбиения. Рекомендуем учитывать следующие моменты, относящиеся к моделям/ЛЕ и фрагментам:
- в фрагментах сохраняется отображение иерархической структуры организации модели в Project Explorer;
- модели/ЛЕ отображаются в Project Explorer в виде отдельных контейнеров верхнего уровня и не могут (в текущей версии) быть вложенными в другие логические структуры организации модели;
- фрагменты замедляют работу CM-системы, потому что приходится обрабатывать больше файлов;
- кроме того, фрагменты могут замедлять некоторые операции обработки моделей, например, генерацию отчетов, но зато они могут ускорить некоторые другие операции;
- можно выполнять слияние фрагментов, но при их слиянии доступно не слишком много информации о контекстуальном контенте модели, поэтому конфликты изменений увеличивают вероятность нарушения целостности модели после слияния;
- при использовании моделей/ЛЕ, как правило, имеется адекватный объем контекста для поддержки сложного и безопасного слияния в процессе параллельной постановки на контроль в CM-системе, если только по какой-либо причине ваши модели не отличаются слишком малым размером (как, например, в случае, если вы пытаетесь использовать модели для хранения малых количеств UML-контента, который вы считаете многократно используемым активом);
- механизм слияния моделей/ЛЕ оснащен удаленным клиентским пользовательским интерфейсом IBM®Rational® ClearCase®. Он предохраняет контекст от распространения конфликтующих изменений, но также замедляет процесс слияния;
- модели/ЛЕ в полной мере поддерживаются механизмом унифицированного управления изменений (Unified Change Management, UCM); тогда как для фрагментов существуют ограничения;
- с моделями/ЛЕ можно работать через интерфейс ClearCase и командную строку; тогда как для фрагментов и здесь есть ограничения.
Учитывая все вышесказанное, рекомендуем выбирать следующие варианты:
- если вся рабочая группа размещается в одном локальном подразделении и предпочитает избегать использования слияний (и особенно если модели очень большие), используйте Rational ClearCase с динамическими представлениями, использующими один поток интеграции и резервирование постановок на контроль, и разбейте модель на фрагменты;
- если речь идет о глобально рассредоточенной рабочей группе, лучше использовать один из следующих альтернативных вариантов:
- используйте IBM® Rational® ClearCase MultiSite®, и осуществляйте работу над основными моделями/ЛЕ в каждом локальном подразделении, выполняя централизованные слияния при помощи UCM-системы (этот метод лучше всего работает в тех ситуациях, когда сами модели/ЛЕ не разбиты на фрагменты);
- используйте систему управления параллельными версиями (Concurrent Versions System, CVS) и разбиение на несколько моделей/ЛЕ;
- используйте CVS-систему и разбиение моделей на фрагменты. Для этого необходимо использовать строгое владение, чтобы, по возможности, избежать слияний, потому что слияния не следует выполнять при отсутствии адекватного контекста.
Ссылки между элементами модели в разных файлах моделирования
Если два элемента моделирования размещаются в разных файлах моделирования, и вы создаете между ними отношение, значит, вы создаете ссылку между файлами моделирования. Поскольку файлы моделирования (.emx-файлы) существуют в файловой системе базовой ОС и могут быть перемещены, переименованы или каким-либо иным образом изменены за пределами среды Eclipse , то такие ссылки представляют собой потенциальные сбойные точки. Однако до тех пор, пока файлы моделирования изменяются исключительно в среде Eclipse и в этой же среде осуществляется управление изменениями, до тех пор, пока вы соблюдаете наши рекомендации, сбоев не должно быть.
При любых операциях (редактировании) с группой связанных файлов моделирования (то есть, коллекцией файлов моделирования, которые ссылаются друг на друга), можно попытаться разместить все эти файлы моделирования в одной рабочей области. Это необязательно означает, что все файлы моделирования из такой группы должны размещаться в одном проекте. Тем не менее, использование одного проекта, как правило, гарантирует, что все модели будут в наличии, потому что, в типичных рабочих потоках СМ-системы все файлы модели передаются совместно в рамках одного проекта. Но если это не делается по причине того, что у вас нет доступа к моделям, которые создают ваши "потребители", то при внесении изменений не следует думать, что можно выполнить рефакторинг всего остального контента, который зависит от вашего. Следовательно, перемещение элемента из одного ресурса (файла .efx или .emx) в другой может дорого обойтись вашим потребителям. Программное обеспечение Rational для управления архитектурой предоставляет поддержку таких операций, но это будет стоить вашим потребителям потери ценного времени, поскольку они должны будут запустить функцию Validation, выделить каждую испорченную ссылку и исправить ее, и все это проделать не один раз.
Перемещение элементов модели из одного фрагмента в другой может нарушить внутренние ссылки на перемещаемые элементы. По этой причине рекомендуется структурировать общие модели (которые используются многими другими ориентированными на функции моделями) как не разбитые на фрагменты модели/ЛЕ. В тех ситуациях, когда это оказывается непрактичным из-за объема контента общей модели, некоторые исполнители создают так называемые "интерфейсные" модели/ЛЕ. Эти модели/ЛЕ выделяют из остального общего контента только те элементы, на которые необходимо ссылаться потребителям.
Давайте понаблюдаем, как рассмотренные нами до этого момента принципы коллективного моделирования применяются в определенных сценариях. Мы упорядочим описание сценариев в соответствии с первым принципом: Являются ли модели строго структурированными, используется ли строгое владение объектами? Вторым вопросом будет: Какое СМ-решение выбрано?
Хорошо продуманная архитектура модели:
Характеристики модели:
- структура пакета отражает высокую функциональную сцепленность, слабую связанность и строгое владение файлами отдельными исполнителями;
- пакеты, используемые в нескольких функциональных областях (а, значит, имеющие нескольких исполнителей в качестве потребителей или совладельцев) изолируются от контента, характеризующегося строгим владением, рано стабилизируются, а вносимые в них изменения жестко контролируются соглашениями процесса.
Ниже перечислены методы, которые обычно оказываются эффективными (в порядке убывания эффективности).
- Использование одной не разбитой на фрагменты модели/ЛЕ. Слияния будут выполняться, но нетривиальные слияния не должны быть частыми и, если в них возникает необходимость, должны выполняться с учетом всего контекста модели.
- Использование взаимосвязанной группы моделей/ЛЕ с ссылками между файлами. Слияния выполняются мене часто, при этом доступен достаточно адекватный контекст.
- Использование одной модели/ЛЕ с тонкодетализированным разбиением на фрагменты. Использование решения для управления конфигурацией (например, ClearCase), с общими динамическими представлениями в потоке интеграции с резервированием снятия с контроля), которое эффективно блокирует файлы с изменениями (фрагменты).
- Использование системы управления конфигурацией, например, ClearCase или CVS, которая может синхронизировать всю рабочую область и допускает выполнение слияний отдельных фрагментов при возникновении редких конфликтов на этом уровне.
Менее продуманная архитектура модели:
характеристики модели:
- пакеты отличаются высокой взаимозависимостью;
- связанные элементы не являются строго сгруппированными и не находятся в строгом владении.
возможные варианты (в порядке от наиболее предпочтительного к наименее предпочтительному):
- использование одной модели/ЛЕ с тонкодетализированным разбиением на фрагменты в сочетании с решением для управления конфигурацией типа ClearCase, которое блокирует файлы с изменениями при помощи разделяемых динамических представлений в потоке интеграции и принудительного применения зарезервированных снятий с контроля;
- использование одной модели/ЛЕ без разбиения на фрагменты. Использование ClearCase с частными представлениями (статичными или динамичными). Использование перебазировки и поставки в UCM для сохранения целостности частной копии каждого исполнителя до завершающего момента интеграции. UCM также обеспечивает возможность атомарной поставки, что позволяет легко вернуться к предыдущему состоянию после неудачного слияния. Слияния становятся проблематичными и затяжными с увеличением размера набора конфликтов. Этот набор увеличивается в периоды между интеграциями, поэтому необходимо выполнять интеграцию как можно чаще;
- использование группы взаимосвязанных моделей/ЛЕ. В этом случае слияния станут более сложными, а контекста для них будет меньше, но зато место, занимаемое моделью/ЛЕ в памяти, тоже сократится, а конфликты будут возникать гораздо реже. В этом случае также необходимо часто выполнять интеграцию, чтобы уменьшить вероятность возникновения конфликтов изменений на этом уровне.
Еще раз подведем итог сказанному.
Для обеспечения параллельной работы над файлом модели нескольких исполнителей и предотвращения возникновения конфликтов изменений разбиение моделей на несколько файлов далеко не так важно, как логическое структурирование моделей. Строгая архитектура и строгое владение файлами - это ключи, позволяющие добиться наибольшей эффективности при работе с описанными инструментами при соблюдении следующих условий:
- если у вас нет строгой архитектуры или есть строгая архитектура, но нет строгого владения, то вы будете часто сталкиваться с необходимостью выполнения нетривиальных слияний, и этому не смогут помочь никакие разбиения моделей;
- если у вас есть строгая архитектура и строгое владение, то вы в значительной степени уменьшите частоту нетривиальных слияний (но совсем избежать их вам не удастся). Вы не сможете избавиться от них потому, что взаимозависимость между компонентами существует всегда. Вышеупомянутые общие элементы - это один из примеров, но далеко не единственный.
Есть и хорошая новость - рассматриваемые продукты выполняют слияние моделей гораздо быстрее и эффективнее, чем любые другие доступные инструменты моделирования.
Рисунок 3. Соображения, которые следует учитывать при управлении моделями и их разбиении
Для управления моделями и их разбиения существуют следующие методы:
- создание новой модели/ЛЕ в проекте;
- удаление пакета существующей модели/ЛЕ, в результате чего пакет превращается в отдельную модель/ЛЕ;
- объединение двух имеющихся моделей/ЛЕ в одну модель/ЛЕ (это называется сплавление (fusing) );
- разбиение модели/ЛЕ на фрагменты;
- включение фрагментов в модели/ЛЕ (операция, обратная созданию фрагментов).
Информацию о меню, диалоговых окнах и мастерах, которые используются для подобных операций, можно найти в справке Help.
Другие полезные инструменты и методы
Если над каждой единицей структуры модели может работать только один исполнитель, то возможность возникновения конфликтов ограничивается только теми моментами, в которых необходимы отношения между разными единицами (уточнение или использование другой зависимости, ассоциации, изображения на диаграммах и т. д.). Многие из отношений между логическими единицами в типичной модели являются результатом изображения одних и тех же семантических элементов на нескольких диаграммах, которые выражают разные аспекты проблемы или решения. Перечисленные ниже методы могут быть полезными для минимизации отношений такого типа и управления ими.
Диаграммы по запросам
В отличие от обычных диаграмм, на которых элементы, которые нужно изобразить, размещаются вручную, контент диаграмм по запросам определяется в результате выполнения запроса к текущему состоянию контента модели, что позволяет нанести элементы на диаграмму с учетом семантических изменений, которые были сделаны с момента последнего просмотра диаграммы. Использование диаграмм по запросам вместо диаграмм, нарисованных вручную, может уменьшить количество конфликтов слияния, связанных с диаграммами, которые в противном случае могли бы иметь место. Рассматриваемые продукты поддерживают два типа диаграмм по запросу: Актуальные (Topic) диаграммы и Обзорные (Browse) диаграммы.
- Актуальные диаграммы: чтобы создать актуальную диаграмму, выделите актуальный элемент или набор элементов модели, а затем определите, какие еще элементы вы хотите видеть на диаграмме, исходя из типов отношений, которыми они связаны с актуальными элементами. При изменении контента модели актуальные -диаграммы, отображающие изменяющиеся семантические элементы, будут соответствующим образом изменены. Определение именованной актуальной диаграммы может храниться в памяти, чтобы один и тот же запрос можно было в любое время выполнить еще раз. Актуальные диаграммы могут храниться в файлах UML-модели, и, кроме того, непосредственно в проекте Eclipse. Тот факт, что их визуализация выполняется автоматически, означает, что при слияниях моделей о них можно не думать, благодаря чему они становятся заманчивой альтернативой диаграммам, нарисованным вручную (с точки зрения рабочей группы по моделированию).
- Обзорные диаграммы: они похожи на актуальные диаграммы тем, что здесь также сначала выбираются актуальные элементы, а затем определяются фильтры, которые управляют тем, какие из связанных элементов будут изображены на диаграмме. Однако обзорные диаграммы не имеют хранимого определения. Их задача - способствовать обнаружению и осмыслению контента модели путем предоставления возможности навигации по модели. После того, как обзорная диаграмма с выбранным центральным элементом будет визуализирована, мы можем выполнить двойной щелчок мышью на любом из связанных элементов и создать еще одну обзорную диаграмму , в которой этот элемент будет центральным. Это можно повторять бесконечно. При навигации по модели можно также сбрасывать фильтры для отношений. Кроме того, вы можете переходить по стеку сгенерированных диаграмм в прямом и обратном направлении (или возвращаться обратно к исходной диаграмме), как это видно из ее имени.
Модель обзора архитектуры (Architecture Overview Model)
При выполнении работ по моделированию, вам, возможно, покажется полезным определить модель обзора архитектуры Architecture Overview Model для фиксации высокоуровневого представления об архитектуре, которое поможет понять, как организовать и выполнить разбиение других моделей (это только одно из возможных применений). Момент создания такой модели и способ ее переделки по мере развития проекта может зависеть от ряда факторов, в том числе, от общего процесса разработки и выбранного принципа моделирования (например, стандартный подход RUP или принцип разработки, управляемой бизнесом). Фактически все подробные описания их применения представлены в разделах данного руководства, посвященного конкретным стилям.
Миграция между Rational XDE и Rational Rose
В руководстве по структурированию моделей в Rational XDE в качестве устройства, представляющего обзор реализации на уровне подсистемы, рекомендовалось использовать модель обзора реализации (Implementation Overview model). Детализация каждой подсистемы затем определялась в модели кода проекта, реализующего эту подсистему.
Назначение модели обзора архитектуры (Architecture Overview Model) в программном обеспечении Rational для управления архитектурой несколько иное и больше ориентировано на осмысление общей архитектуры ПО как средства планирования разбиения моделей и организационной стратегии. (Обратите внимание на то, что ни модель Implementation Overview model, ни модель Architecture Overview Model не описываются традиционным RUP.)
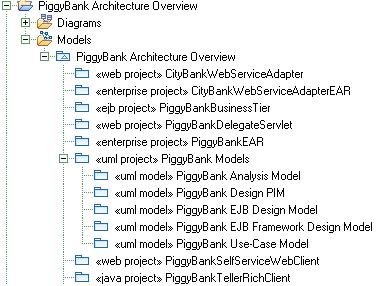
Чтобы понять, какой охват и уровень абстракции может отображать такая модель, рассмотрим рисунок 4. На этом рисунке показано, что базовый код делится на модули для реализации строгой архитектуры и строгого владения. Однако из рисунка также понятно, какого типа обзор архитектуры (модулей и их зависимостей) можно выразить в модели обзора архитектуры (Architecture Overview Model).
Модель Architecture Overview Model можно также использовать для того, чтобы создать эскиз предполагаемой структуры рабочей области, как показано на рисунке 4.
Рисунок 4. Пример модели обзора архитектуры Architecture Overview Model
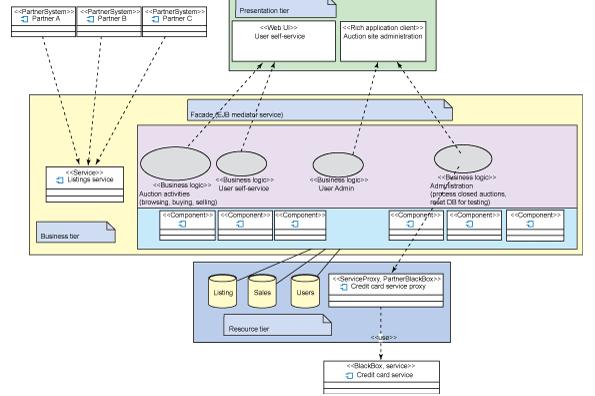
Еще одно возможное применение Architecture Overview Model - это запись неформальных схем и диаграмм различных аспектов решения, например, высококонцептуальной схемы системы аукциона на рисунке 5.
Рисунок 5. Схема архитектуры системы аукциона
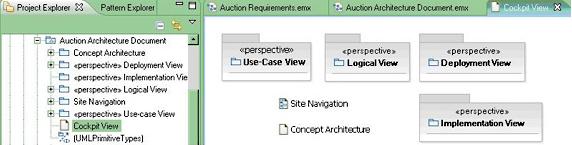
Безусловно, модель Architecture Overview Model можно использовать для любого сочетания подобных задач. Ее можно также использовать как место для сбора диаграмм из более детализированных моделей решения, чтобы можно было отобразить различные архитектурно значимые точки зрения этого решения. В более формальном смысле ее можно считать эквивалентом документа RUP Software Architecture Document. Учитывая наличие инструментов для организации моделей в рассматриваемых продуктах (например, поддержка нескольких файлов моделей с ссылками между файлами и ссылками на диаграммы), эта модель становится почти обычным способом для выполнения подобных задач ( эти инструменты описываются в следующем разделе "Общие методы организации логического контента моделей"). Например, если нужно создать модель, которая отображает "4+1 представления архитектуры", вы можете выполнить это так, как показано на рисунке 6.
Примечание
В примере не показан пакет для представления процесса Process View, потому что система в этом примере демонстрирует не слишком много параллелизма.
- Просто создайте модель/ЛЕ и заполните ее обычным набором пакетов, соответствующих 4+1 представлениям (пакеты
<<perspective>>также описываются в следующем разделе).- Затем создайте диаграммы в модели Software Architecture Document, используя следующие принципы:
- создавайте диаграммы, скомпонованные при помощи семантических элементов UML из других файлов моделей и отображающие новые представления, которые не были обнаружены в файлах других моделей, но необходимы для составления архитектурного документа;
- создавайте диаграммы, составленные из геометрических фигур или специальных UML-элементов, которые хранятся в файле модели Software Architecture Document. (Такие UML -элементы должны использоваться только для документирования или разъяснения и не должны быть семантически значимыми для реальной реализации описываемого решения.);
- создавайте диаграммы, которые просто содержат ссылки на имеющиеся в других файлах моделей диаграммы. Этот метод будет хорошо работать, если файл модели архитектурного документа должен быть передан читателям вместе с другими файлами модели. Если архитектурный документ будет опубликован на Web-сайте, то выберите какой-нибудь другой подход).
Дополнительная информация о моделировании в коллективе
Если вы готовитесь приступить к коллективному моделированию, то неиссякаемым источником знаний для вас будет серия статей "Comparing and merging UML models in IBM Rational Software Architect" (Сравнение и слияние UML-моделей в IBM Rational Software Architect (части 1 - 7) Кима Леткемана (Kim Letkeman), которая опубликована на Web-сайте developerWorks. Часть 5 представляется нам особенно ценной. Части с 1 по 4 и Часть 6 тоже полезны, но они написаны несколько раньше и не отражают самых последних усовершенствований средств коллективного моделирования в ПО Rational, например, усовершенствований функций сравнения-слияния и поддержки фрагментов моделей. В части 7 Ad-hoc modeling: Fusing two models with diagrams (Особый случай моделирования: сплавление двух моделей, содержащих диаграммы) описывается сценарий, при котором два исполнителя независимо друг от друга разработали модели предполагаемого решения, а после этого решили выполнить их слияние (что бывает не так редко, как можно было бы подумать).
Если вас интересует дополнительная информация об общих принципах управления зависимостями, позволяющих добиться строгой сцепленности и низкой связанности, рекомендуем прекрасный источник - книгу Роберта С. Мартина (Robert C. Martin) Designing C++ Applications Using the Booch Method (Проектирование приложений на С++ при помощи метода Буча) (издательство Prentice Hall, 1995 г.), глава 3, разделы, посвященные сцепленности, взаимосвязанности и многократному использованию.
Общие методы организации логического контента моделей
Основными средствами организации логического контента UML-моделей являются модели/ЛЕ (о которых рассказывалось в предыдущих разделах) и UML-пакеты. UML-пакеты служат, в основном, двум главным целям:
- логическое разбиение и организация информации о модели путем группировки элементов, соответствующих определенным аспектам предметной области проблемы или решения;
- разделение разных типов информации, например, интерфейсов, реализаций, диаграмм и т. д.:
- группировка элементов с целью определения и управления их зависимостями от других элементов;
- группировка диаграмм, которые предоставляют альтернативные представления одной и той же модели
- создание пространств имен;
- для элементов моделей;
- для реализации артефактов, сгенерированных из элементов моделей (для этого может потребоваться создание отображений между пространствами имен языков модели и реализации);
- для единиц многократного использования.
Рассматриваемые продукты поддерживают также дополнительные инструменты организации моделей, которые могут помочь, главным образом, в определении способов навигации и группировки диаграмм. (Одно из средств навигации, обзорные диаграммы, рассматривались в предыдущем разделе.)
Выражение точек зрения при помощи пакетов <<perspective>>
В тех случаях, когда желательно видеть элементы, организованные несколькими способами, можно создать дополнительные пакеты, содержащие диаграммы, изображающие альтернативные схемы организации. Этот же метод можно использовать и во всех случаях, когда есть потребность в отображении конкретного представления контента модели, который противоречит общей схеме пакетов модели. Рассматриваемые продукты для поддержки этого метода предоставляют стереотип пакета <<perspective>> в составе базового UML-профиля. Стереотип <<perspective>> можно, в принципе, считать эквивалентом RUP для области управляемой моделями разработки систем (Model-Driven Systems Development), или IEEE 1471- 2000.
При применении стереотипа <<perspective>> к пакету происходит следующее:
- данный пакет визуально распознается как пакет, отображающий конкретную точку зрения;
- обеспечивается поддержка правила проверки корректности модели, которое предупреждает нас в случае, если семантические элементы помещаются в пакет
<<perspective>>;
- особые пакеты, которые должны быть проигнорированы преобразованиями Rational.
По большей части, пакеты <<perspective>> предназначены для хранения только тех диаграмм, которые отображают представления на основе альтернативных факторов организации или точек зрения на приложение. Тем не менее, существует ряд ситуаций, в которых вы, возможно, захотите разместить семантические элементы в пакетах <<perspective>>:
- чтобы оградить эти элементы от обработки в процессе преобразований;
- чтобы изобразить поведение в пакете
<<perspective>>. Рассматриваемые продукты считают диаграммы поведения (или "машинные" диаграммы) "каноническими", что означает всего лишь, что контент таких диаграмм должен в полной мере и исключительно отражать семантику семантических элементов UML, которые владеют диаграммой:- владельцем диаграммы деятельности (Activity) должна быть Деятельность; при этом диаграмма должна отображать только семантику этой Деятельности;
- диаграмма последовательности или диаграмма взаимодействия должна принадлежать Взаимодействию и в полной мере и исключительно отображать семантику этого Взаимодействия;
- диаграмма автомата должна принадлежать конечному автомату и в полной мере и исключительно отображать семантику этого конечного автомата.
<<perspective>>Деятельность, выражающую детали семантики, которые вы хотите видеть в этой<<perspective>>.
В подобных случаях мы просто игнорируем правило проверки корректности, которое предупреждает о семантическом контенте в стереотипе пакета <<perspective>> Package .
Использование навигации между диаграммами
В рассматриваемых продуктах имеется два механизма поддержки переходов между диаграммами.
- Можно перетащить при помощи мыши узел диаграммы из панели Project Explorer на какую-нибудь другую "целевую" диаграмму. После этого можно выполнить двойной щелчок на получившемся значке этой диаграммы, чтобы открыть диаграмму, на которую она ссылается.
- Любой пакет в UML-модели Rational может иметь диаграмму по умолчанию. Диаграмма пакета по умолчанию демонстрирует особое поведение: если поместить сам пакет в область любой диаграммы в любой модели, то после этого можно открыть диаграмму по умолчанию этого пакета при помощи двойного щелчка на значке пакета.
Примечание:
можно настроить свойства диаграммы таким образом, чтобы при создании в модели нового UML-пакета автоматически создавалась главная диаграмма, которая становилась бы диаграммой по умолчанию для этого пакета. По умолчанию в свойствах (Preferences) для рассматриваемых продуктов используются следующие настройки: создается диаграмма в свободной форме, которая становится диаграммой по умолчанию для всех новых пакетов. Однако настройки по умолчанию можно изменить, чтобы можно было создавать другие виды диаграмм, а создаваемые диаграммы не становились диаграммами по умолчанию для пакета. Кроме того, в качестве диаграммы по умолчанию для пакета можно выбрать произвольную диаграмму из любого пакета.
Эти механизмы поддерживают следующие рекомендации по организации моделей, которые можно применить к моделям любых типов:
- скомпонуйте главную диаграмму (или другую диаграмму по умолчанию) для каждой модели/ЛЕ таким образом, чтобы она отображала:
- все пакеты верхнего уровня в модели/ЛЕ;
- значки диаграмм для всех остальных диаграмм, которые размещаются в корневом пакете модели/ЛЕ). Другими словами, не изображайте значок для самой диаграммы по умолчанию.
- скомпонуйте главную диаграмму (или другую диаграмму по умолчанию) для каждого пакета верхнего уровня; на этой диаграмме должно быть изображены:
- пакеты, для которых данный пакет содержит значки диаграмм;
- любые другие диаграммы, которые он содержит.
- выполните этот алгоритм последовательно для всех пакетов более низкого уровня.
Что должно быть смоделировано и какую модель можно считать "достаточной"
Это самый короткий и, тем не менее, самый важный раздел в данной статье.
Когда речь идет о предоставлении рекомендаций по моделированию, мы сталкиваемся с довольно сильным противоречием. Новички в моделировании хотят получить рекомендации в виде подробных инструкций, чтобы можно было быстро освоиться в этой области. Но, получив такие рекомендации, они становятся их заложниками и вынуждены уделять моделированию больше времени и сил, чем это на самом деле необходимо.
В следующих статьях данной серии мы представим как раз такие рекомендации по поводу того, как структурировать модели при использовании конкретных стилей моделирования, например, "классического" RUP, управляемой моделями разработки для SOA (Business-Driven Development for SOA) или управляемой моделями системной разработки (Model Driven Systems Development). Это будет полезно для широкого круга читателей, но важно помнить, что необходимо понять смысл описываемых возможностей, а не воспринимать их как набор правил. С их помощью мы пытаемся сказать вам: "Вот как вы могли бы сделать это," а не "Вот так вы должны это делать."
Примечание
Из этого правила есть одно важное исключение, которое заключается в том, что вы можете применить преобразование, которое требует на входе модели, скомпонованной совершенно определенным способом. Если вы планируете использовать такие преобразования, то сформулируйте, опубликуйте и разъясните сотрудникам своего коллектива доступные и подробные рекомендации по поводу того, как создать такую исходную модель.
Львиная доля ценности модели заключается в абстрагировании от деталей, что позволяет сосредоточиться на выделенных аспектах. Насколько ваша модель зависит от уровня абстракции, необходимого для понимания предметной области проблемы или решения, как вы используете автоматизацию в своем процессе разработки и насколько эффективно взаимодействуете с заинтересованными в проекте лицами. Вот самая лучшая рекомендация по моделированию:
Моделируйте только то, что имеет очевидную ценность для бизнеса.
В соответствии с этим утверждением, рекомендации для конкретных стилей моделирования, публикуемые в этой серии, стремятся обозначить бизнес-ценности для конкретных действий по моделированию и, тем самым, помогают вам решить, насколько применима рекомендация в вашей ситуации.