"О, нет, - воскликнете вы, - только не еще одна 'теоретическая' дискуссия!" Но, тем не менее, прочтите статью до конца - эти рассуждения о теории метапрограммирования могут помочь вам отделить факты от вымыслов, которые порой встречаются в бурных маркетинговых заявлениях разработчиков различных инструментов метапрограммирования.
В этой статье исследуются теоретические рамки возможностей метапрограммирования и архитектуры OMG's MDA. Эта архитектура отделяет бизнес-логику и логику приложений от лежащей в их основе технологической платформы. Узнайте о проблемах, которые можно решать с помощью MDA, и рассмотрите пример текстовой системы, использующей эту архитектуру.
Теоретические рамки возможностей метапрограммирования
Зная возможности, перспективы развития и неотъемлемые ограничения метапрограммирования, вы сможете подбирать нужные вам инструменты и задавать правильные вопросы их поставщикам.
Графическое и текстовое метапрограммирование
В первой и второй статьях этой серии мы рассматривали текстовые системы; тем не менее, многие существующие системы метапрограммирования являются графическими. Давайте начнем с рассмотрения программы, представленной как в текстовом, так и в графическом виде, и выясним, какие существуют сходства и отличия. В этом примере используются регулярные выражения.
Регулярные выражения по существу представляют собой небольшой подъязык для обработки текста и используются для поиска и замены символьных строк.
В листинге 1 содержится регулярное выражение на языке Perl, которое заменяет каждое вхождение подстроки <h1> значением <h2> в строке HTML-кода:
Листинг 1. Регулярное выражение Perl для замены HTML-тегов
$html_str =~ s!<(/?)h1>!<${1}h2>!g;
|
Язык, на котором написано регулярное выражение, не является языком Perl; это предметно-ориентированный язык, используемый Perl. Как бы то ни было, точный синтаксис регулярного выражения не так важен - регулярные выражения могут быть составлены многими различными способами.
Как правило, когда вы общаетесь с компьютером на полнофункциональном или на узкоспециализированном языке программирования, вы используете определенный способ передачи символов этого языка компилятору или интерпретатору. Вы можете делать это, просто набирая код, но также вы могли бы выразить вышеупомянутое регулярное выражение следующим образом:
Рисунок 1. Регулярное выражение Perl в виде диаграммы 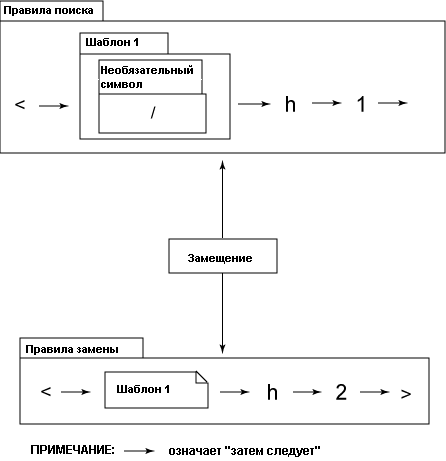
Это работает не только для предметно-ориентированных, но также и для общих языков программирования. Поскольку компиляторы оперируют символами, вы можете выражать эти символы в текстовой или графической форме. Текстовая форма используется по следующим причинам:
- Печатать текст зачастую быстрее, чем рисовать схемы.
- Большинство примеров и инструментов создано для систем программирования с текстовым интерфейсом.
- Зачастую текстовые формы легче обдумывать, а также манипулировать ими с помощью программных средств.
Что касается регулярных выражений, то вводить код с помощью графических средств оказывается, несомненно, сложнее. Каждая из двух форм представления регулярного выражения содержит одно и то же количество информации программирования . Таким образом, графическое описание концепции разработки не уменьшает объем программирования.
Если вы использовали какую-либо графическую среду разработки приложений, ваш опыт может отличаться, благодаря преимуществу предметно-ориентированных языков, но не конкретных графических методов. Давайте рассмотрим пример программирования в Windows - описание ресурсов Win32 для построения диалоговых окон:
Листинг 2. Пример описания ресурсов Win32
IDD_TEST DIALOG DISCARDABLE 0, 0, 200, 200 STYLE DS_MODALFRAME / WS_POPUP / WS_VISIBLE / WS_CAPTION / WS_SYSMENU CAPTION "Hello There!" FONT 8, "MS Sans Serif" BEGIN DEFPUSHBUTTON "OK",IDOK,108,8,50,14 END |
Код в листинге 2 требует, чтобы вы "передали" такое же количество информации, как и в случае использования графических инструментов для построения и позиционирования диалогового окна. Разница состоит в том, что выбирать экземпляры и располагать их на экране с помощью мыши намного проще, чем вручную набирать их имена и указывать координаты. Количество информации, которое вы передаете компьютеру, одинаково в обоих случаях.
Так почему же выполнение действий требует меньшего объема программирования, чем ручное написание кода на языке C? Ограниченный, предметно-ориентированный подъязык требует меньшего объема программирования независимо от того, является ли инструмент текстовым или графическим. Из этого можно сделать следующие выводы:
- Предметно-ориентированные языки могут уменьшить объем программирования.
- С некоторыми предметно-ориентированными языками проще работать в текстовой форме, а с некоторыми - в графической.
- Независимо от того, написана ли программа с использованием предметно-ориентированного языка в текстовой или графической форме, программист предоставляет компьютеру одно и то же количество информации.
- Поскольку графические языки также должны предоставлять информацию для компилятора или интерпретатора в символьной форме, требуется, чтобы графические спецификации придерживались параметров формального языка. Такие языки не могут быть более узкоспециализированными, чем формальные языки программирования. Графические формы представления имеют такие же формализованные синтаксис и семантику, как и в случае текстовых языков.
Тем не менее, в графические представления вы можете добавлять больше информации, не относящейся к программированию. Например, вы можете:
- Пространственно располагать различные компоненты, делая восприятие более наглядным для других людей.
- Добавлять схемы, рисунки и другие графические пояснительные элементы и зрительные метки непосредственно в исходный код, что помогает лучше пояснять процессы.
- Размещать код в скрытых или открытых областях в зависимости от степени детализации отображения (например, вы можете скрыть код, относящийся к проверке ошибок, когда вы анализируете только лишь алгоритм).
Графические модели выводят программирование на новый уровень не потому, что программист передает меньше информации компьютеру, а потому, что больше информации может быть передано от программиста программисту более естественным путем.
Метапрограммирование, программисты и эксперты в предметных областях
Теперь, когда мы установили, что предметно-ориентированный подъязык, уменьшающий объем программирования, не обязательно по своей природе должен являться графическим, можем ли мы достичь того, что программирование может полностью выполняться экспертом в определенной предметной области? Другими словами, можем ли мы отказаться от фактического выполнения работы программистами и просто предоставить экспертам в предметных областях инструменты метапрограммирования, с помощью которых они могут разрабатывать и писать свои приложения от начала и до конца?
Чтобы ответить на этот вопрос, подумайте о том, что делают программисты в процессе работы над проектом, помимо написания кода. Пытаясь определить все возможные сценарии для определенной операции, эксперт в предметной области может что-то упустить. Например, давайте предположим, что вы создали приложение, которое автоматически выбирает город при указании почтового индекса. Заказчик этого приложения может не знать о том, что некоторые почтовые индексы соответствуют нескольким городам. Что происходит в этом случае? Получит ли пользователь сообщение? Будет ли автоматически выбран один город? Все такие неопределенные моменты программирования называются edge cases . По своему собственному опыту я могу сказать, что самая важная роль программиста/аналитика - это выявление всех таких моментов, о которых может не задумываться эксперт в своей области. Программисты стремятся обдумывать все стороны процесса более методично, и поэтому часто находятся в более выгодном положении, помогая экспертам выявить и понять все неявные моменты.
Эксперты, пользуясь своими собственными методами, часто оставляют без рассмотрения многие аспекты работы системы, как бы они ни старались избегать этого. Разработка узкоспециализированных решений обычно является лишь частью бизнеса, а составление всеохватывающих технических требований не является повседневной задачей экспертов.
Другой задачей программистов является полное понимание синтаксиса, семантики, возможностей и ограничений языков программирования, использующихся для написания приложений. Как было упомянуто выше, к графическим языкам предъявляется не меньше требований относительно точной семантики, чем к текстовым языкам, поскольку в обоих случаях все, в конечном счете, сводится к использованию символов. По этой причине даже в самых лучших, самых упрощенных графических средах крайне необходимо иметь полное понимание используемых инструментов и их семантики.
Основываясь на этих двух наблюдениях, я уверен в том, что пока будут разрабатываться приложения, всегда будет существовать необходимость в услугах программистов. Со временем программирование может быть успешно внедрено в школьные и другие учебные программы так, что исчезнет необходимость преподавать его как отдельную дисциплину. Вместо упрощения программирования до той степени, которая позволит отказаться от услуг программистов, уровень государственного образования мог бы быть повышен так, что в таком упрощении не было бы необходимости!
Важным итогом всех этих рассуждений является то, что роль эксперта в предметной области и роль программиста всегда будут отделены друг от друга, хотя иногда эти роли исполняет один и тот же человек.
В конце концов, графические метапрограммы все еще являются программами , таким образом, они требуют от программиста их правильной реализации.
Работа с несколькими уровнями абстракции
Одной из самых больших проблем в метапрограммировании является тот факт, что программисту почти всегда приходится работать с несколькими уровнями абстракции. Он должен не просто знать обо всех деталях программы, предметно-ориентированных языках и языках общего назначения, но также должен знать следующее:
- Как реализуется каждый из этих компонентов
- Как эти компоненты взаимодействуют
- Какие несовместимости существуют между ними
Часто для выполнения поставленной задачи можно при написании кода использовать доступные инструменты метапрограммирования, но самая сложная часть наступает тогда, когда их нужно совместить. Например, если система метапрограммирования автоматически генерирует метод внутри класса, а впоследствии вам нужно будет несколько изменить этот метод, как вы реализуете нечто подобное?
В некоторых случаях, а также при использовании некоторых инструментов изменение сгенерированного кода немедленно удаляет программу из области действия системы метапрограммирования. Метапрограмма перестает быть сколько-нибудь полезной, поскольку изменение должно быть сделано на более низком уровне. Существует несколько способов решения этой проблемы, но, в конечном счете, преодолеть ее полностью очень сложно или же вообще невозможно.
Лучшими системами метапрограммирования являются те, которые позволяют вам работать с несколькими уровнями абстракции внутри самой системы. Например, во второй статье этой серии обсуждалось, как система макросов языка Scheme позволяет легко совмещать код макроса с остальным кодом. В идеале вам необходимо работать как на высоком, так и на низком уровнях внутри самой системы метапрограммирования и просто указывать ей, в каких местах требуется переходить на более низкий уровень.
Теперь давайте рассмотрим архитектуру OMG's Model Driven Architecture и те проблемы, в решении которых она может помочь.
Рассмотрение Model Driven Architecture на высоком уровне
Теперь, когда вы лучше ознакомились с возможностями инструментов метапрограммирования, давайте обратимся к концепции корпоративного метапрограммирования и посмотрим, какие она имеет сходства и отличия от других методов метапрограммирования.
Корпоративное метапрограммирование, в конечном счете, является обычным метапрограммированием. Отличия состоят лишь в следующем:
- Характер решаемых проблем
- Количество элементов отношения между исходным и конечным языками
Проблемы, решаемые с помощью MDA
Первое различие между традиционным и корпоративным метапрограммированием заключается в тех проблемах, которые решаются с их помощью. Традиционное метапрограммирование в основном решает следующие задачи:
- Сокращение цикла разработки программного обеспечения
- Обеспечение того, чтобы программы придерживались ограничений системы
- Обеспечение того, чтобы язык программирования более точно следовал модели предметной области.
Корпоративное метапрограммирование тоже затрагивает эти моменты, но также охватывает и другие. Прежде всего, всегда существовала одна проблема, когда модели часто разрабатывались в начале проекта, становясь несоответствующими по мере его развития. С точки зрения программирования это означает, что модель является не совсем точной, а ее постоянное изменение только тормозит выполнение проекта.
Разработать модель в начале проекта, а затем не использовать ее кажется расточительным. Также кажется расточительным разработать модель в программе построения диаграмм, а позже переписывать ее в виде кода. Поэтому архитектура Model Driven Architecture ставит своей целью сделать разработанные в начале проекта модели частью самого кода так, чтобы они оставались в актуальном состоянии и не были лишними в процессе написания кода.
Другой связанной проблемой является проблема передачи информации. Для человека, не являющегося программистом, очень сложно понять код программы. Однако если код представлен в графическом виде, непрограммистам оказывается существенно легче обсуждать предмет программирования. Это, конечно, может усложнить процесс написания кода, поскольку в него приходится вносить элементы эстетики, но, в конечном счете, эффективность взаимодействия между программистом и экспертом в предметной области существенно повышается, поскольку эксперт может самостоятельно комментировать код, если он представлен в графическом, удобном для восприятия виде.
Следующей проблемой является перенос программ между различными платформами. Часто различные представители бизнеса используют самые разнообразные инструменты. Это не обязательно происходит из-за технической непредусмотрительности, а просто имеет место по следующим причинам:
- Многие компании приобретаются другими компаниями, и поэтому их информационные ресурсы должны быть объединены.
- В бизнесе существует столько различных мелких потребностей, что для ИТ-подразделений не представляется возможным предложить единое, связанное решение для всех этих задач.
В силу вышесказанного, нужно просто допускать то, что в большой организации всегда будет иметься ряд различных технологий, которые должны быть объединены вместе. Поэтому система метапрограммирования должна быть настраиваемой и обеспечивать вывод результатов, которые могли бы использоваться в самых разнообразных системах.
И последней проблемой является проблема поддержки. Недостаточно просто писать приложения - их также необходимо поддерживать. Поскольку модель напрямую внедрена в сам код, поддержка упрощается. Программисты могут оставлять информацию для будущих разработчиков в графическом виде и использовать для объяснения своих программ не только текст, но также графические средства и схемы. Фактически, во многих случаях графики и схемы будут являться программой!
Платформо-ориентированные и платформо-независимые модели
Ключевой концепцией Model Driven Architecture, которая может решить или облегчить все вышеупомянутые проблемы, является платформо-независимая модель . По существу, архитектура MDA имеет три уровня:
- Код. В конечном счете все наши модели станут кодом. Этот уровень является самым нижним уровнем модели MDA.
- Платформо-ориентированная модель, или PSM (platform-specific model). Системы метапрограммирования, описанные в предыдущих статьях это серии, главным образом являются платформо-ориентированными моделями. Хотя модели существуют на более высоком уровне, чем сами языки программирования, в итоге они напрямую привязаны к этим языкам. Обычно правила трансляции и взаимосвязь между платформо-ориентированной моделью и кодом довольно очевидны. Данную модель часто называют сокращенно - PSM.
- Платформо-независимая модель, или PIM (platform-independent model). Этот уровень делает корпоративное метапрограммирование уникальным. Платформо-независимые модели, как вы могли догадаться, транслируются в платформо-ориентированные модели. Отличает их то, что модель PIM, как правило, транслируется в несколько моделей PSM и не связана жестко с определенной целевой моделью PSM или каким-либо языком программирования.
Иметь модель PIM, которую можно транслировать в несколько моделей PSM, оказывается полезным по следующим причинам:
- Возможность использования одной и той же программы на различных платформах (например, при использовании разнородных систем или в случае необходимости перехода от старой системы к более новой).
- Возможность единственной наглядной трансляции модели во множество различных компонентов системы.
Вторая причина является гораздо более важной по сравнению с первой. Давайте, например, предположим, что у вас есть модель данных, которую вы хотите использовать в программе управления базой данных, написанной на языке C++. В случае с платформо-независимой моделью вы можете написать единственный исходный файл и транслировать его во множество различных компонентов конечной системы. Например, модель данных может быть транслирована в следующие компоненты:
- Класс скелетона C++, включающий в себя операции для преобразования в последовательную форму базы данных.
- Сценарий SQL для создания базы данных, на которой основана модель данных.
- Простой пользовательский интерфейс для загрузки данных.
Итак, из одной модели PIM вы могли бы получить три отдельных модели PSM. Обратите внимание на то, что разница между моделью PSM и кодом состоит лишь в их уровне (думайте о языке программирования как о модели PSM для его объектного кода). Важная идея заключается в трансляции одного исходного файла в несколько платформо-ориентированных, каждый из которых охватывает различные аспекты системы.
Чтобы программировать в модели Model Driven Architecture, необходимо уметь программировать на всех трех ее уровнях в зависимости от поставленной задачи и, возможно, даже уметь писать транслирующие программы между исходными и конечными моделями:
- Некоторые части приложения могут быть написаны в виде модели PIM, в которой большинство рутинной работы выполняется системой метапрограммирования.
- Другие части приложения могут быть написаны в виде модели PSM, функциональные возможности которой в большой степени связаны с предназначением и возможностями языка программирования.
- Некоторые части приложения могут быть написаны в виде обычного кода.
Преимущества модели Model Driven Architecture заключаются в следующем:
- Модели для системы применимы и полезны на протяжении всего жизненного цикла программного обеспечения.
- Устраняется много избыточности, обычно присутствующей в приложениях.
- Повышается уровень взаимодействия между работающими программистами, будущими программистами и экспертами в предметной области.
Пример: построение кода из диаграмм программы Dia
Одной из наиболее интересных особенностей MDA является то, что, хотя в нее включены определенные спецификации, в своей основе она является идеей, концепцией и процессом. Инструмент является инструментом MDA в том случае, если в нем реализованы некоторые или все концепции MDA. Конечно, являясь стандартом OMG, унифицированный язык UML (Unified Modeling Language) является предпочтительным языком моделирования, однако концепция MDA в чрезвычайной степени замещает собой технологии, которые она использует.
|
В нашем примере мы создадим инструмент MDA, который на основе диаграммы класса, созданной в программе Dia, генерирует код SQL для таблиц базы данных, а также код языка C++ для простого класса C++. Это не оправдывает полных ожиданий от инструментов MDA, однако служит хорошим примером генерирования нескольких моделей PSM (в нашем случае мы сгенерируем действующий код) из одной модели PIM.
Создание диаграммы
Для создания диаграммы запустите программу Dia и используйте ее графические возможности UML. Когда вы запустите Dia, вы увидите окно, подобное изображенному ниже.
В главной панели инструментов расположено меню типов объектов. Выберите набор объектов UML. Первым объектом в этом наборе является класс UML. Выберите его и добавьте к вашей диаграмме, которая будет выглядеть примерно так, как изображено на следующем рисунке.
Рисунок 3. Класс UML в новой схеме
Если вы дважды щелкнете на значке нового класса, вы увидите следующий экран:
Рисунок 4. Основная информация о классе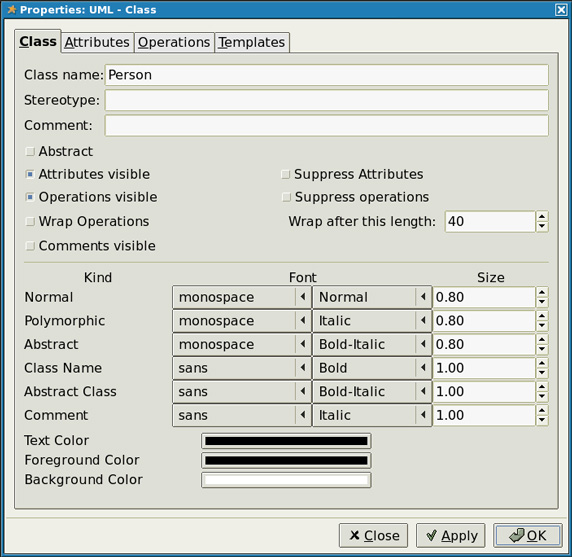
Диалоговое окно позволяет вам указать информацию о классе. Поскольку мы используем ограниченный пример, то в нашем случае используется только поле Name. Наш класс будет называться Person. Далее нужно добавить атрибуты - для этого перейдите на вкладку Attributes. Здесь мы добавим три поля: id (тип int), name (тип text) и address (тип text). Вы должны видеть на вашем экране следующее:
Рисунок 5. Редактирование атрибутов класса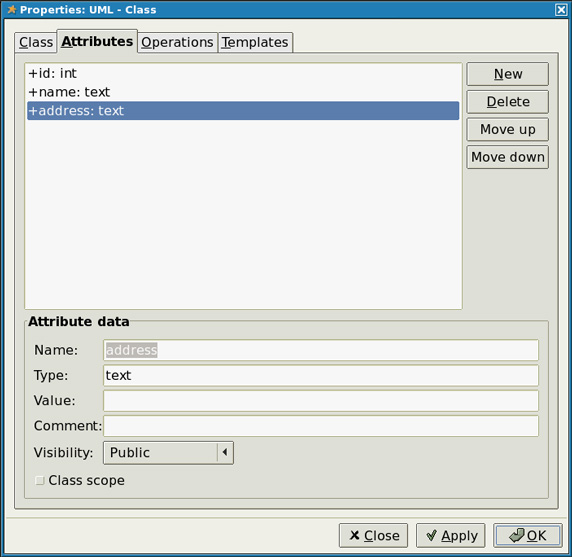
Нажмите кнопку OK диалогового окна, чтобы закончить. Если захотите, Вы можете добавить дополнительные классы. Когда вы закончите, сохраните диаграмму с помощью следующего диалогового окна:
Рисунок 6. Диалоговое окно сохранения диаграммы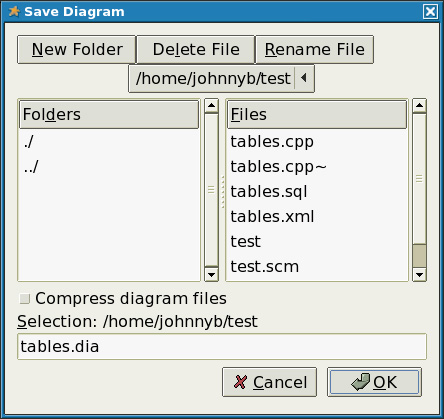
При сохранении диаграммы убедитесь, что флажок "compress diagram files" снят.
Краткий обзор формата файла программы Dia
Файл программы Dia является простым файлом формата XML, использующим собственные схему и пространство имен Dia. Этот файл может быть как сжатым, так и несжатым (наша программа имеет дело с только с несжатыми файлами). Формат файла достаточно простой. Ниже приведены некоторые фрагменты файла, который мы только что создали.
<?xml version="1.0" encoding="UTF-8"?>
<dia:diagram xmlns:dia="http://www.lysator.liu.se/~alla/dia/">
<dia:diagramdata>
<dia:attribute name="background">
<dia:color val="#ffffff"/>
</dia:attribute>
...
...
</dia:diagramdata>
<dia:layer name="Background" visible="true">
<dia:object type="UML - Class" version="0" id="O0">
<dia:attribute name="obj_pos">
<dia:point val="11.6,6.35"/>
</dia:attribute>
...
...
<dia:attribute name="name">
<dia:string>#Person#</dia:string>
</dia:attribute>
...
<dia:attribute name="attributes">
<dia:composite type="umlattribute">
<dia:attribute name="name">
<dia:string>#id#</dia:string>
</dia:attribute>
<dia:attribute name="type">
<dia:string>#int#</dia:string>
</dia:attribute>
<dia:attribute name="value">
<dia:string>##</dia:string>
</dia:attribute>
...
...
</dia:composite>
</dia:attribute>
<dia:attribute name="operations"/>
<dia:attribute name="template">
<dia:boolean val="false"/>
</dia:attribute>
<dia:attribute name="templates"/>
</dia:object>
</dia:layer>
</dia:diagram>
|
В файле содержится много информации, но только малая ее часть является для нас полезной. Обратите внимание на блоки XML, начинающиеся с тегов, подобных тегу <dia:object type="UML - Class" version="0" id="O0">. Далее, обратите внимание на имя класса, а также на имя и тип каждого атрибута.
Имя класса содержится в атрибуте с именем name . Все атрибуты содержатся в ветке с названием attributes , каждый атрибут является атрибутом класса umlatrribute с соответствующими полями name и type. По этой причине среди огромного множества тегов XML сосредоточьте внимание только на тех их них, которые представляют интерес.
Реализация MDA
Реализация MDA - это простой парсер SAX, написанный на языке Scheme с использованием модуля SSAX. Парсер считывает данные из одного файла с расширением .dia и записывает данные в файл SQL, а также в исходный файл C++. Для каждого класса создается класс C++ и таблица базы данных.
Для максимального упрощения в нашем примере поддерживаются только атрибуты (не операции), и не реализованы функции загрузки/сохранения базы данных. Тем не менее, для добавления этого функционала нужно выполнить лишь несколько дополнительных шагов, добавив их к парсеру, приведенному в листинге 4.
Ниже приведен код приложения MDA, написанный для использования с компилятором Chicken Scheme (другие схемы, вероятно, потребуют лишь незначительной модификации в строке загрузки модуля SSAX).
Листинг 4. Полный листинг программы для приложения MDA
;;Загрузка парсера Scheme SAX
(require-extension ssax)
;;Строковые значения Dia заключены в символы '#'. Следующий
;;блок удаляет эти символы.
(define (munge-dia-value val)
(let (
(str-len (string-length val)))
(if (<= str-len 2)
""
(substring val 1 (- str-len 1)))))
;; Функция парсера SAX
(define (dia-mda-parser input-port cpp-out-port sql-out-port)
(let (
;;Переменные состояния - возможно, будет более правильным
;; хранить их вместе с seed, но если поместить их
;; сюда, будет легче управлять ими
;это используется для правильной обработки списков, разделенных запятыми
(first #t)
;следующие переменные используются для хранения типа и имени атрибута,
;пока они не будут считаны для распечатки
(attr-type "")
(attr-name ""))
;;Пишем заголовок C++
(display "#include <string>" cpp-out-port)(newline cpp-out-port)
(display "using namespace std;" cpp-out-port)(newline cpp-out-port)
(display "typedef string text;" cpp-out-port)(newline cpp-out-port)
;;Макрос SSAX для создания парсера
((SSAX:make-parser
;;функция для работы с элементом
NEW-LEVEL-SEED
(lambda (elem-gi attrs namespaces expected-content seed)
;;Имя элемента - это cdr списка имен
(define element (cdr elem-gi))
;;общие атрибуты
(define name-attr (assq 'name attrs))
(define type-attr (assq 'type attrs))
;;Переключатель состояния - определяем, в каком элементе и в каком состоянии
;; мы находимся, а также состояние, в которое нам
;; предстоит переключиться (если таковое имеется)
;;
;;Обратите внимание, что возвращаемое значение этой (и других) функций
;;становится новым значением "seed", поэтому мы используем его для записи
;;текущего состояния. Дополнительную информацию о внутренних
;;обработках SSAX вы можете получить в разделе ссылок.
(cond
;Проверка с целью начать класс высшего уровня
((and (eq? seed 'top) (eq? element 'object) (equal? (cdr type-attr) "UML - Class"))
(set! first #t) ;reset the "comma" state
'object)
;Проверка того, производится ли поиск имени класса
((and (eq? seed 'object) (eq? element 'attribute) (equal? (cdr name-attr) "name"))
'class-name)
;Проверка того, готовы ли мы прочесть имя класса
((and (eq? seed 'class-name) (eq? element 'string))
'read-class-name)
;Проверка для выяснения того, переключаемся ли мы в режим атрибута
((and (eq? seed 'object) (eq? element 'attribute) (equal? (cdr name-attr)
"attributes")) 'class-attrs)
;Проверка для выяснения того, начали ли мы поиск информации об атрибуте
((and (eq? seed 'class-attrs) (eq? element 'composite) (equal? (cdr type-attr)
"umlattribute")) 'class-attribute)
;Проверка того, ищем ли мы имя атрибута
((and (eq? seed 'class-attribute) (eq? element 'attribute) (equal? (cdr name-attr)
"name")) 'class-attribute-name)
;Проверка того, считываем ли мы имя атрибута
((and (eq? seed 'class-attribute-name) (eq? element 'string))
'read-class-attribute-name)
;Проверка того, ищем ли мы тип атрибута
((and (eq? seed 'class-attribute) (eq? element 'attribute) (equal? (cdr name-attr)
"type")) 'class-attribute-type)
;Проверка того, считываем ли мы тип атрибута
((and (eq? seed 'class-attribute-type) (eq? element 'string))
'read-class-attribute-type)
(else seed)))
;завершающая функция работы с элементом
FINISH-ELEMENT
(lambda (elem-gi attrs namespaces parent-seed seed)
;;часто используемые значения
(define element (cdr elem-gi))
(define type-attr (assq 'type attrs))
(cond
;После формирования элемента umlatrribute выпишем информацию об атрибуте
((and (eq? element 'composite) (equal? (cdr type-attr) "umlattribute"))
(if first
(set! first #f)
(display ", " sql-out-port))
(display (string-append attr-name " " attr-type) sql-out-port)
(display (string-append "\t" attr-type " " attr-name ";") cpp-out-port)
(newline cpp-out-port))
;После формирования элемента объекта UML-класса запишем завершающие символы
((and (eq? element 'object) (equal? (cdr type-attr) "UML - Class"))
(display ");" sql-out-port)(newline sql-out-port)
(display "};" cpp-out-port)(newline cpp-out-port))
(else #f))
;Восстановим сведения о родительском уровне
parent-seed)
;;функция символьных данных
CHAR-DATA-HANDLER
(lambda (s1 s2 seed)
(cond
;Считываем имя класса и выписываем подходящие операторы
((eq? seed 'read-class-name)
(display "class " cpp-out-port)
(display (munge-dia-value s1) cpp-out-port)
(display " {" cpp-out-port) (newline cpp-out-port)
(display "public:" cpp-out-port) (newline cpp-out-port)
(display "create table " sql-out-port)
(display (munge-dia-value s1) sql-out-port)
(display " (" sql-out-port))
;Считываем и сохраняем имя атрибута
((eq? seed 'read-class-attribute-name)
(set! attr-name (munge-dia-value s1)))
;Считываем и сохраняем тип атрибута
((eq? seed 'read-class-attribute-type)
(set! attr-type (munge-dia-value s1)))
(else #f))
seed)
) input-port 'top)))
;;;Основная программа;;;
(let (
;;Открытие файлов;;
(tables-in (open-input-file "tables.dia"))
(cpp-out (open-output-file "tables.cpp"))
(sql-out (open-output-file "tables.sql")))
;;Обработка данных;;
(dia-mda-parser tables-in cpp-out sql-out)
;;Закрытие файлов;;
(close-input-port tables-in)
(close-output-port cpp-out)
(close-output-port sql-out))
|
Для простоты имена входного и выходных файлов жестко запрограммированы, поэтому убедитесь, что вы сохраняете файл программы Dia в ту же папку, что и файл tables.dia. Сохраните программу под именем mda.scm. Для ее запуска просто выполните команду csi mda.scm. На основе данных Dia эта программа создаст два выходных файла. Выходные данные SQL выглядят следующим образом:
Листинг 5. Выходные данные SQL, полученные в результате выполнения программы MDA
create table Person (id int, name text, address text); |
Выходные данные C++ выглядят следующим образом:
Листинг 6. Выходные данные C++, полученные в результате выполнения программы MDA
#include <string>
using namespace std;
typedef string text;
class Person {
public:
int id;
text name;
text address;
};
|
Итак, ценой почти двухсот строк кода вы можете создавать диаграммы вместо того, чтобы писать код SQL и C++. Конечно, получается еще веселее, когда программу преобразования пишет кто-то другой.
Заключение
Model Driven Architecture является мощной концепцией, основанной на крепких традициях метапрограммирования. Используя идею платформо-независимых моделей, MDA пока еще выходит за рамки традиционных методов.