Замечание:
Я уже дважды поднимал эту тему. Если Вы хотите послушать подкаст-версию, посетите блестящий сайт Грэга Лоу SQL Down Under. Я также представил урезанную десятиминутную версию в PASS для Simple-Talk. Первоначально их было десять, потом шесть, а сейчас опять десять. Но эти десять не те же самые десять ошибок, которые были первоначально; они отражают мое сегодняшнее понимание.
Прежде, чем я начну этот список, позвольте мне немного пооткровенничать. Я обычно имею проповедника, который прежде проповедовал сам себе столько, что был допущен к конгрегации. Когда я говорю или пишу статью, я должен прислушиваться к его тихому голосу в моей голове, который помогает отфильтровывать мои собственные плохие привычки, дабы удостовериться, что я преподаю только лучшие методы. Хотелось бы надеяться, что после чтения этой статьи, тихий голос в вашей голове будет сообщать Вам, когда Вы начинаете отклоняться от того, что является правильным в смысле методов проектирования базы данных.
Итак, список:
- Плохой проект/планирование
- Игнорирование нормализации
- Слабые стандарты именования
- Отсутствие документации
- Одна таблица для хранения всех значений домена
- Использование столбцов identity/guid в качестве единственного ключа
- Не использование средств SQL для поддержания целостности данных
- Не использование хранимых процедур для обеспечения доступа к данным
- Попытка генерировать объекты
- Недостаточное тестирование
Плохой проект/планирование
"Если Вы не знаете, куда идете, то любая дорога приведет вас туда" - Джордж Харрисон
Пророческие слова для всех областей жизни и описание проблемы, которой зачумлены многие современные проекты.
Позвольте мне спросить: Вы наняли бы подрядчика для строительства дома, чтобы потребовать от него заливать фундамент на следующий же день? Или что хуже, Вы потребовали бы, чтобы это было сделано без плана или проекта дома? Хочется надеяться, что Вы ответили "Нет" на оба вопроса. Проект необходим как гарантия, что дом, который Вы хотите, будет построен, и что земля, на которой Вы строите его, не провалится в какую-нибудь подземную пещеру. Если Вы ответили "Да", я не уверен, поможет ли Вам то, что я собираюсь рассказать.
Как и дом, хорошая база данных строится с предусмотрительностью, с надлежащей заботой и вниманием, которое уделяют характеру данных, которые будут находиться в ней. Это не может быть пущено на самотек.
Поскольку база данных - краеугольный камень почти каждого бизнес проекта, то если Вы не найдете время, чтобы определить требования к проекту и то, как база данных будет им удовлетворять, тогда, вероятно, весь проект пойдет не так и станет неуправляем. Кроме того, если Вы не сделаете правильный проект базы данных в самом начале, то тогда Вы столкнетесь с тем, что любые существенные изменения в структуре базы данных, которые потребуется сделать, будут оказывать огромное воздействие на весь проект, что значительно увеличит вероятность увеличения сроков его выполнения.
Слишком часто надлежащая фаза планирования игнорируется в пользу "получения сделанного". Когда по какому-либо направлению проект встречает преграду, и неизбежно возникают проблемы из-за нехватки надлежащего проектирования и планирования, то нет "никакого времени", чтобы вернуться, дабы исправить ситуацию должным образом, используя надлежащие методы. Поскольку когда начинается "рубка", благие обещания возвратиться и исправить кое-что позже, выполняются, на самом деле, очень редко.
По общему признанию, невозможно предсказать каждую потребность, которую ваш проект должен будет выполнить, и предвидеть каждую проблему, с которой, вероятно, придется столкнуться, однако важно ослабить воздействие потенциальных проблем в максимально возможной степени посредством тщательного планирования.
Игнорирование нормализации
Нормализация представляет собой ряд методов, разбивающих таблицы на составные части до тех пор, пока каждая таблица не будет представлять собой одну и только одну "вещь", а ее столбцы полностью описывать только одну "вещь", которую эта таблица представляет.
Концепция нормализации в течение около 30 лет является основанием, на которое опирается SQL и реляционные базы данных. Другими словами, SQL был создан для работы с нормализованными структурами данных. Нормализация - это не только некий заговор программистов баз данных против прикладных программистов (что является просто побочным эффектом!)
SQL весьма аддитивен по своей природе; это проявляется в том, что если Вы имеете биты и элементы данных, то легко создать множество значений или результатов. В предложении FROM Вы берете набор данных (таблицу) и добавляете (JOIN) его к другой таблице. Вы можете собрать вместе столько наборов данных, сколько вам угодно, чтобы произвести необходимое вам окончательное множество.
Эта аддитивная природа чрезвычайно важна не только для простоты разработки, но также и для производительности. Индексы являются наиболее эффективными, когда они могут работать со всем ключевым значением. Всякий раз, когда Вам нужно использовать SUBSTRING, CHARINDEX, LIKE и так далее, чтобы вытащить значение, которое объединено с другими значениями в едином столбце (например, чтобы вычленить фамилию человека из столбца, содержащего полное имя), парадигма SQL начинает ломаться, и данные становятся всё менее доступными для поиска.
Итак, нормализация ваших данных существенна для хорошей производительности и простоты разработки, но остался вопрос: "Какой нормализации достаточно?" Если Вы читали какие-нибудь книги по нормализации, то Вы слышали много раз, что существенной является 3-я Нормальная Форма, но действительно полезны и 4-ые и 5-ые Нормальные Формы и, как только Вы сталкиваетесь с ними, не жалейте времени, требуемого на нормализацию.
Однако в действительности часто оказывается, что не всегда даже первая Нормальная Форма создается правильно.
Всякий раз, когда я вижу таблицу с повторяющимися именами столбцов, которые отличаются лишь добавлением числа, я прихожу в ужас. И я ужасаюсь довольно часто. Рассмотрим следующий пример таблицы Customer (Клиент):

Всегда ли имеется 12 платежей (Payment)? Существенен ли порядок платежей? Имеет ли NULL-значение смысл НЕИЗВЕСТНО (пока еще не заполнен), или это означает пропущенную оплату? И когда оплата была сделана?!?
Оплата не является характеристикой Клиента и не должна храниться в таблице Customer. Детали платежей должны храниться в таблице Payment, в которую Вы можете также записывать дополнительную информацию об оплате, например, когда оплата была сделана и за что:
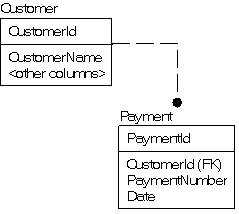
В этом втором проекте каждый столбец хранит единственную единицу информации о единственной "вещи" (оплата), и каждая строка представляет конкретный случай оплаты.
Этот второй проект потребует немного большего количества кода на ранних стадиях процесса, но более вероятно, что Вы будете в состоянии выяснить то, что происходит в системе без необходимости выслеживать программиста, который делал эту часть проекта, чтобы пнуть его в торец … простите … узнать, что он имел в виду.
Слабые стандарты именования
"То, что мы называем розой, будет также сладко пахнуть и под любым другим именем."
Эта цитата из Ромео и Джульетты Уильяма Шекспира звучит прекрасно и справедлива, с одной стороны. Если мы теперь согласимся назвать розу экскрементами, то ничего не изменится, и она будет пахнуть так же сладко. Проблема же состоит в том, что если, строя базу данных для цветочного бизнеса, проектировщик называет ее экскрементами, а клиент - розой, тогда Вам предстоят встречи, которые значительно больше походят на миниатюру Эббота и Костелло (комедийный дуэт), чем на серьезную беседу относительно хранении информации о продуктах садоводства.
Имена, хотя они и определяются личным выбором, являются первой и самой важной чатью документации для вашего приложения. Я не буду вдаваться в детали относительно того, как лучше всего именовать объекты, - это большая и темная тема. На чем я хочу акцентироваться, - это необходимая последовательность. Имена, которые Вы выбираете, не просто позволяют Вам идентифицировать назначение объекта, они должны позволить всем будущим программистам, пользователям и так далее быстро и легко понять, как должна использоваться та или иная часть вашей базы данных, и какие данные она содержит. Ни один будущий пользователь вашего проекта не должен продираться через документ в 500 страниц, чтобы определить назначение некоего дурацкого имени.
Рассмотрим, например, столбец с именем X304_DSCR. Что это может означать? Вы могли бы после некоторого умственного напряжения решить, что это означает "описание X304"(description). Возможно это и так, но DSCR может означать и дискриминатор, и дискретизатор?
Если Вы не установили DSCR как корпоративное стандартное сокращение для "описания", тогда X304_DESCRIPTION - намного лучшее название, и не оставляет простора воображению.
Осталось выяснить, что означает часть названия X304. На мой взгляд, X304 больше походит для данных в столбце, но не для его имени. Если бы я впоследствии обнаружил, что в организации были также X305 и X306, то я бы пришел к выводу, что имеется проблема с проектом базы данных. Максимальную гибкость дает хранение данных в столбцах, но не в именах столбцов.
По этим тем же самым соображениям, противьтесь искушению использовать "метаданные" в качестве имени объекта. Имена типа tblCustomer или colVarcharAddress могут показаться полезными с точки зрения разработки, однако конечного пользователя они могут только запутать. Как разработчик, Вы должны основываться на том, что в состоянии определить, что имя таблицы - это имя таблицы по контексту кода или инструмента, и предоставить пользователям ясные, простые и информативные имена типа Customer (клиент) и Address (адрес).
Практика, против которой я постоянно выступаю, - это использование пробелов и закавыченных идентификаторов в именах объектов. Вам следует избегать таких имен столбцов, как " Part Number" или - в стиле Microsoft - [Part Number], и, следовательно, требуя, чтобы Ваши пользователи также включали такие пробелы и идентификаторы в собственные коды. Это раздражает и просто не нужно.
Приемлемыми альтернативами были бы part_number, partNumber или PartNumber. Опять же, ключевым здесь является последовательность. Если Вы выбираете PartNumber, это прекрасно, если столбец, содержащий номера счетов, называют InvoiceNumber, но не одним из других возможных вариантов.
Отсутствие документации
Я намекнул во введении, что в некоторых случаях я пишу в той же мере для себя, сколь и для Вас. Для данной статьи это верно в большей степени. Тщательно продуманная система именования объектов, столбцов и так далее поможет каждому понять, что моделирует ваша база данных. Однако это только первый шаг в борьбе с документацией. К сожалению, действительность такова, что этот "первый шаг" так и остается единственным.
Мало того, чтобы хорошо разработанная модель данных твердо придерживалась принятого стандарта обозначения, необходимо также иметь такие определения таблиц, столбцов, связей, и даже ограничений типа CHECK и значений по умолчанию для того, чтобы каждому было ясно, как предполагается их использовать. Во многих случаях Вы можете захотеть включить типовые значения, возможные для объекта, и что-нибудь еще с тем, чтобы иметь возможность в будущем через год или два вернуться и внести изменения в код.
Замечание:
То, где эта документация сохраняется, в значительной степени дело корпоративных стандартов и/или удобства разработчиков и конечных пользователей. Можно сохранять эти определения непосредственно в базе данных, используя расширенные свойства. Альтернативным решением могут быть поддерживаемые инструменты моделирования данных. Можно даже хранить информацию в отдельных хранилищах данных типа Excel или другой реляционной базе данных. Моя компания поддерживает базу данных репозитория метаданных, которую мы разработали для представления этих данных конечным пользователям в доступном для поиска и пригодном для редактирования формате. Формат, удобство и простота использования важны, но первичная цель - иметь информацию доступной и в актуальном состоянии.
Ваша цель должна состоять в том, чтобы обеспечить достаточно информации, зато тогда, когда Вы передадите базу данных программисту поддержки, он может выявить ваши незначительные ошибки и устранить их (да, все мы делаем ошибки в нашем коде!). Я вспоминаю старую шутку о том, что плохо документированный код - синоним "обеспеченности работой." Хотя в этом есть доля истины, это путь к ненависти со стороны сотрудников и помеха в продвижения по службе. И никакой хороший программист из тех, кого я знаю, не захочет вернуться к переделке своих собственных кодов годы спустя. Лучше всего, если ошибки в коде сможет устранить младший программист поддержки, в то время как Вы создаете следующую новую вещь. Обеспеченность работой наряду с карьерным ростом будет достигнута, если постоянно принимать новые вызовы.
Одна таблица для хранения всех значений домена
"Одно Кольцо, чтобы управлять ими всеми и в темноте связывать их"
Это все замечательно и хорошо с точки зрения знания фантастики, но не настолько хорошо, когда речь идет о проекте базы данных в форме "управляющей" таблицы доменов. Реляционные базы данных опираются на фундаментальную идею, согласно которой каждый объект представляет одну и только одну сущность. Никогда не должно быть никакого сомнения относительно того, к какой части данных идет обращение. Отслеживание связи от имени столбца к имени таблицы, к первичному ключу, должно легким и определенно указывать, что означает та или иная часть данных.
Большой миф, созданный архитекторами, которые на самом деле не понимают архитектуру реляционной базы данных (включая и меня на заре карьеры), заключается в утверждении, что чем больше имеется таблиц, тем более сложным будет проект. Как раз наоборот, разве упаковывание таблиц в единственную "всеобъемлющую" таблицу упрощает проект?
Рассмотрим, например, следующую часть модели, где мне нужны доменные значения для:
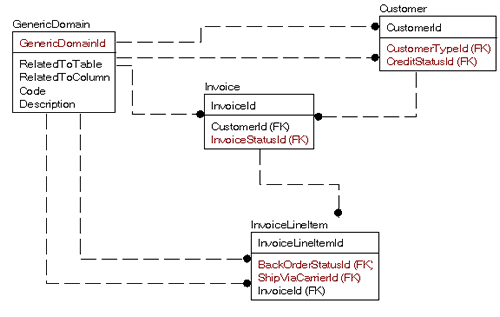
Это может показаться очень прозрачным и естественным способом проектирования таблицы со всех точек зрения, но имеется проблема в не очень естественной работе с помощью SQL. Скажем, мы хотим получить доменные значения только для таблицы Customer:
SELECT *
FROM Customer
JOIN GenericDomain as CustomerType
ON Customer.CustomerTypeId = CustomerType.GenericDomainId
and CustomerType.RelatedToTable = 'Customer'
and CustomerType.RelatedToColumn = 'CustomerTypeId'
JOIN GenericDomain as CreditStatus
ON Customer.CreditStatusId = CreditStatus.GenericDomainId
and CreditStatus.RelatedToTable = 'Customer'
and CreditStatus.RelatedToColumn = ' CreditStatusId'
Как можно увидеть, это далеко от того, что называется естественным соединением, и сводится к проблеме смешивания яблок с апельсинами. На первый взгляд, доменные таблицы - это только абстрактное понятие контейнера, содержащего текст. С точки зрения централизованного подхода, это вполне верно, но это неправильный способ строить базу данных. В базе данных процесс нормализации, как средство декомпозиции и изоляции данных, приводит каждую таблицу к такому состоянию, когда одна строка представляет одну вещь. И каждый домен значений совершенно отличен от всех других доменов (если же это не так, тогда будет достаточно одной таблицы). В сущности, то, что Вы делаете, есть нормализация данных относительно каждого использования, растягивающая работу на длительный срок, а не разовое выполнение законченной задачи.
Итак, вместо единственной таблицы для всех доменов, Вы могли бы смоделировать это так:
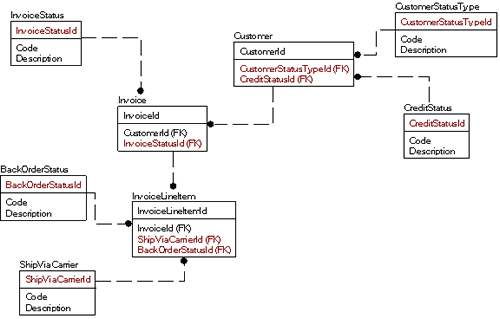
Выглядит сложнее, не так ли? Но это первоначальное впечатление. Откровенно говоря, мне потребуется больше времени, чтобы описать подробно таблицы примера. Однако появились огромные преимущества:
- Использование данных в запросе стало намного проще:
SELECT *
FROM Customer
JOIN CustomerType
ON Customer.CustomerTypeId = CustomerType.CustomerTypeId
JOIN CreditStatus
ON Customer.CreditStatusId = CreditStatus.CreditStatusId
- Использование ограничений внешних ключей для поддержания согласованного состояния данных является очень естественным, что не всегда выполнимо для другого решения, если Вы не реализуете диапазоны ключей для каждой таблицы, - ужасно тяжело поддерживать.
- Если оказывается, что Вы должны хранить больше информации о ShipViaCarrier (доставке курьером), чем только код ('UPS') и описание ( 'United Parcel Service'), то вы можете просто добавить столбец или два. Вы могли бы даже расширить таблицу, чтобы дать полную информацию о бизнесе, представленном курьерами.
- Более мелкие доменные таблицы будут умещаться на единственной дисковой странице. Это гарантирует единственную операцию чтения (и вероятное нахождение этой страницы в кэше). В противном случае, ваша доменная таблица может занимать много страниц и, если не выполнить кластеризацию для этой таблицы, обращение к ней будет более дорогостоящим при использовании некластеризованного индекса в случае большого числа значений.
- Вы по-прежнему можете иметь один редактор для всех строк, поскольку большинство доменных таблиц будет вероятно иметь одну и ту же базовую структуру/использование. Правда, вы теряете способность легко получить все доменные значения в одном запросе, но к чему вам это? (Запрос с объединением мог бы легко быть создан из этих таблиц, если это понадобится, но это представляется маловероятным.)
Я должен, вероятно, опровергнуть мысль, которая может у вас возникнуть. "Что, если мне понадобится добавить новый столбец ко всем доменным таблицам?" Например, Вы забыли, что клиенту потребуется выполнить пользовательскую сортировку по доменным значениям и ничего не предусмотрели в таблицах, чтобы иметь возможность реализовать это. Справедливый вопрос, особенно если Вы имеете 1000 таких таблиц в очень большой базе данных. Но, во-первых, это редко случается, и когда это имеет место, то в любом случае вам придется вносить существенные изменения в вашу базу данных.
Во-вторых, даже если это стало востребованной задачей, SQL имеет полный набор команд, которые Вы можете использовать, чтобы добавить столбцы в таблицы, а использование системных таблиц дает возможность довольно просто построить скрипт для добавления одного и того же столбца в сотни таблиц сразу. Это будет не столь простым изменением, но и не настолько трудным, чтобы перевесить большие выгоды.
Назначение данного совета заключается в том, что лучше делать работу добросовестно, создавая стабильные и легко поддерживаемые структуры, вместо того, чтобы попытаться выполнить наименьший объем работы для скорейшего запуска проекта. Сведение таблиц к представлению одной "вещи" означает, что большинство изменений затронет только одну таблицу, из чего следует, что в будущем вас ожидает меньше переделок.
Использование столбцов identity/guid в качестве единственного ключа
Первая Нормальная Форма диктует, что все строки в таблице должны однозначно идентифицироваться. Следовательно, каждая таблица должна иметь первичный ключ. SQL Server позволяет Вам определить числовой столбец как столбец IDENTITY, после чего автоматически генерируются уникальные значения для каждой добавляемой строки. Кроме того, Вы можете использовать NEWID() (или NEWSEQUENTIALID()) для генерации случайного 16-байтового уникального значения для каждой строки. Такие типы значений, когда они используется как ключи, называются суррогатными ключами. Слово "суррогатный" означает "что-либо для замены", и в данном случае, суррогатный ключ должен стать заменой естественного ключа.
Проблема состоит в том, что слишком много проектировщиков используют столбец суррогатного ключа в качестве единственного ключевого столбца на данной таблице. Значения суррогатного ключа не представляют никакого фактического значения в реальном мире; они предназначены исключительно для того, чтобы однозначно идентифицировать каждую строку.
Давайте рассмотрим следующую таблицу Part, в которой PartID является столбцом IDENTITY и первичным ключом таблицы:
| PartID | PartNumber | Description |
| ------------ | ------------ | ------------ |
| 1 | XXXXXXXX | Часть X |
| 2 | XXXXXXXX | Часть X |
| 3 | YYYYYYYY | Часть Y |
Сколько рядов находится в этой таблице? Ну, кажется, что три, однако не являются ли строки с PartID 1 и 2 фактически одной и той же строкой, т.е. дубликатами? Или же это две различных строки, которые должны быть уникальными, но были определены неправильно?
Эмпирическое правило, которое я использую, звучит просто. Если человек не в состоянии выбрать, какая строка таблицы ему нужна без знания суррогатного ключа, то Вы должны пересмотреть структуру вашего проекта. Вот почему должен иметься некоторый ключ в таблице, чтобы гарантировать уникальность, в нашем случае это, вероятно, PartNumber.
В качестве правила: каждая из ваших таблиц должна иметь естественный ключ, который что-то означает для пользователя и может уникально идентифицировать каждую строку в вашей таблице. В очень редких случаях, когда Вы не можете найти естественный ключ (возможно, например, для таблицы, которая обеспечивает регистрацию событий), тогда используйте искусственный/суррогатный ключ.
Не использование средств SQL для поддержания целостности данных
Все фундаментальные, неизменные бизнес-правила должны быть реализованы средствами реляционного механизма. Основные правила допустимости NULL значений, длины строки, назначения внешних ключей, и так далее, все должны быть определены в базе данных.
Есть много различных способов импортировать данные в SQL Server. Если ваши основные правила определены в самой базе данных, это сможет Вам гарантировать, что они никогда не будут обойдены, а Вы сможете писать свои запросы, совершенно не беспокоясь, отвечают ли данные, которые Вы рассматриваете, основным бизнес-правилам.
Правила, которые являются дополнительными, с другой стороны, являются верными кандидатами на то, чтобы переместить их в бизнес-слой приложения. Рассмотрим, например, такое правило: "В первую половину месяца никакая деталь не может быть продана с больше чем 20%-ой скидкой без одобрения менеджера".
В целом, эти правило звучит не очень четко, не очень хорошо контролируется, и подвержено частым изменениям. Например, что произойдет, когда на следующей неделе максимальная скидка составит 30 %? Или когда определение "первой половины месяца" изменится на "от 15 дней до 20 дней"? Наиболее вероятно, что Вы не захотите переносить трудности реализации этих сложных временных бизнес-правил в код SQL Server; бизнес-слой - лучше место, чтобы реализовать такие правила там.
Однако рассмотрите правило более внимательно. Тут есть элементы, которые, вероятно, никогда не будут изменяться. Например.
- Максимальная скидка, которая когда-либо может быть предложена
- Факт, что предлагающий ее должен быть менеджером
Эти аспекты бизнес-правила очевидно должны предписываться базой данных и схемой. Даже если сущность правила применяется в бизнес-слое, Вам все же потребуется иметь таблицу в базе данных, в которую записывается размер скидки, дата, когда она предлагалась, идентификатор личности, который ее одобрил и так далее. На столбце Discount Вы должны иметь ограничение CHECK, которое ограничит допустимые значения интервалом между 0.00 и 0.90 (или любым другим максимумом). Мало того, что это применит ваше правило "максимальной скидки", но также будет служить средством защиты от пользователя, входящего скидку 200 % или отрицательную скидку по ошибке. На столбце ManagerID Вы должны поместить ограничение внешний ключа, который ссылаются на таблицу менеджеров (Managers), и гарантирует, что введенный идентификатор соответствует личности реального менеджера (или, как альтернативу, триггер, который выбирает только те EmployeeIds, которые соответствуют менеджерам).
Теперь, по крайней мере, мы можем быть уверены, что данные удовлетворяют всем основным правилам, которым они должны подчиняться, и, таким образом, нам никогда не придется кодировать кое-что подобное, чтобы проверить, что данные хороши:
SELECT CASE WHEN discount < 0 then 0 else WHEN discount > 1 then 1…
Мы можем чувствовать себя в безопасности, т.к. данные удовлетворяют основным критериям, в каждый момент времени.
Не использование хранимых процедур для обеспечения доступа к данным
Хранимые процедуры - ваш друг. Используйте их всякий раз как метод для изоляции слоя базы данных от пользователей данных. Но не потребует ли это немного больше усилий? Первоначально конечно, но какая хорошая вещь не потребует немного больше времени? Хранимые процедуры делают разработку базы данных намного более прозрачной, и поощряют совместную разработку программистами, занимающимися вашей базой данных и функциональными возможностями. Вот несколько других интересных причин, которые демонстрируют важность хранимых процедур.
Поддержка
Хранимые процедуры обеспечивают известный интерфейс к данным, и, на мой взгляд, это главное преимущество. Когда код, который осуществляет доступ к базе данных, собран в другом слое, недостаток производительности не может быть устранен без привлечения прикладного программиста. Хранимые процедуры дают профессионалу в базах данных власть изменять характеристики кода базы данных без привлечения дополнительных ресурсов, что делает выполнение незначительных изменений или же большой модернизации (например, изменение синтаксиса SQL) более легким.
Инкапсуляция
Хранимые процедуры позволяют Вам так "инкапсулировать" любые структурные изменения, которые потребуется сделать в базе данных, чтобы влияние на пользовательские интерфейсы было минимально. Например, Вы первоначально моделировали один телефонный номер, но теперь потребовалось неограниченное число телефонных номеров. Вы могли бы оставить единственный телефонный номер в вызове процедуры, но хранить его в другой таблице в качестве временной меры, или даже постоянно, если Вы имеете "первичный" номер некоторого вида, который Вы всегда хотите показывать. Теперь могла бы быть построена хранимая процедура для обработки других телефонных номеров. При этом воздействие на пользовательские интерфейсы могло бы быть весьма незначительным, в то время как код хранимых процедур может существенно измениться.
Безопасность
Хранимые процедуры могут обеспечить специфичный и гранулированный доступ к системе. Например, Вы можете иметь 10 хранимых процедур, которые определенным образом обновляют таблицу X. Если пользователю необходимо обновить конкретный столбец в таблице, и Вам нужно гарантировать, что он никогда не обновит никакие другие столбцы, то Вы можете просто предоставить этому пользователю разрешение на выполнение только этой одной процедуры из десяти, которая и ему позволит выполнить необходимое обновление.
Производительность
Я полагаю, что есть пара причин, согласно которым хранимые процедуры увеличивают производительность. Во-первых, если новичок пишет неоптимальный код (подобно использованию курсора для построчной обработки таблицы, содержащей десять миллионов строк, чтобы найти одно значение вместо использования предложения WHERE), процедура может быть переписана без воздействия на систему (кроме возвращения системе ценных ресурсов.) Вторая причина - повторное использование плана исполнения запроса. Если Вы не используете динамические запросы SQL в вашей процедуре, SQL Server может сохранить план, а не компилировать его при каждом выполнении. Верно, что в каждой версии SQL Server, начиная с 7.0, эта причина становится все менее значимой, поскольку SQL Server все лучше справляется с сохранением планов непосредственно передаваемых SQL запросов (см. примечание ниже). Однако хранимые процедуры все еще облегчают повторное использования плана и дают прирост производительности. В случае, когда необходимо ускорить непосредственно передаваемый код SQL, он может быть закодирован в хранимой процедуре без искажения.
В 2005, есть установка базы данных "вынужденная параметризация" (PARAMETERIZATION FORCED), которая при включении заставит сохранять планы всех запросов. Это не покрывает более сложные ситуации, которые доступны процедурам, но может оказать большую помощь. Имеется также возможность, известная как plan guides, которая позволяет Вам отвергнуть план для известного типа запросов. Обе эти возможности должны помочь, когда хранимые процедуры не используются, хотя хранимые процедуры делают эту работу без всяких трюков.
Этот список можно продолжить. Имеются также и недостатки, поскольку нет ничего совершенного. Для кодировки хранимых процедур может потребоваться больше времени, чем при использовании непосредственно передаваемых запросов. Однако количество времени, необходимое на проектирование интерфейса и его реализацию, стоит того, когда все сказано и сделано.
Попытка кодировать общие объекты T-SQL
Я уже касался этого предмета ранее при обсуждении общих доменных таблиц, но данная проблема имеет более общий смысл. Каждый новый программист T-SQL, когда впервые начинает кодировать хранимые процедуры, думает: "очень жаль, что я не могу передать название таблицы как параметр в процедуру." Это действительно кажется весьма привлекательным: одна общая хранимая процедура, которая может выполнить свои операции на любой таблице, которую Вы выберете. Однако этого следует избегать, поскольку это может весьма отрицательно сказаться на производительности и фактически сделает жизнь более трудной, в конечном счете.
Объекты T-SQL не делают "общее" легко, в значительной степени потому, что основной упор при проектировании в SQL Server сделан на облегчении повторного использования плана, а не кода. SQL Server работает лучше всего, когда Вы минимизируете неизвестности, чтобы он смог произвести наилучший возможный план. Чем больше делается для обобщения плана, тем меньше это позволяет оптимизировать его.
Отметьте, что я специально не говорю о процедурах динамического SQL. Динамический SQL - великий инструмент, когда Вы имеете процедуры, которые нельзя другими способами сделать оптимизируемыми/управляемыми. Хороший пример - процедура поиска с множеством различных вариантов выбора. Предварительно откомпилированное решение с многочисленными условиями OR, возможно, даст худший план и неважные результаты, особенно если использование параметров является спорадическим.
Однако главный пункт этого совета состоит в том, чтобы избегать кодирования очень общих объектов, таких, которые берут название таблицы и двадцать пар имя/значение в качестве параметра и позволяют Вам обновлять значения в таблице. Например, Вы могли бы написать процедуру, которая начинается так:
CREATE PROCEDURE updateAnyTable
@tableName sysname,
@columnName1 sysname,
@columnName1Value varchar(max)
@columnName2 sysname,
@columnName2Value varchar(max)
Идея состоит в динамическом задании имени столбца и значения для передачи их в оператор SQL. Это решение ничем не лучше, чем простое непосредственное выполнение оператораUPDATE. Помимо этого, строя хранимые процедуры, Вы должны строить их ориентированными на каждую задачу, выполняемую для таблицы (или множестве таблиц.) Это дает Вам несколько преимуществ:
- Правильно откомпилированные хранимые процедуры могут иметь единственный привязанный к ней компилированный план, многократно используемый в дальнейшем.
- Правильно откомпилированные хранимые процедуры более безопасны, чем непосредственные SQL-запросы или даже динамические процедуры SQL, существенно уменьшая риск атак со стороны инъекции, поскольку единственными параметрами в запросах являются поисковые аргументы или выходные значения.
- Тестирование и обслуживание откомпилированных хранимых процедур намного проще, так как Вы вообще должны искать только аргументы, а не существование таблиц/столбцов/и т.д., и не обрабатывать случай, когда они отсутствуют.
Хороший метод - создать инструментарий для генерации кода на своем любимом языке программирования (даже на T-SQL), использующий метаданные SQL, для построения каждой конкретной хранимой процедуры для каждой таблицы вашей системы. Генерируйте все скучные, очевидные объекты, включая весь утомительный код для выполнения обработки ошибок, который является весьма существенным, чтобы не мучить себя многократным его написанием.
В моей книге Apress, Pro SQL Server 2005 Database Design and Optimization, я предлагаю несколько таких "шаблонов" (Главным образом, для триггеров, но и для хранимых процедур тоже), все из которых имеют встроенную обработку ошибок. Я предлагаю Вам построить свою собственную систему (возможно, основанную на моей), чтобы использовать ее, когда Вам необходимо вручную строить триггеры/процедуры или что бы то ни было еще.
Недостаточное тестирование
Когда приборная панель в вашем автомобиле говорит, что двигатель перегрет, на что Вы грешите в первую очередь? Двигатель. А почему не предположить, что сломан индикатор? Или что-то еще менее важное? Имеется две причины:
- Двигатель - самый важный компонент автомобиля, и обычно винить нужно сначала самую важную часть системы.
- Слишком часто это оказывается верным.
Поскольку профессионалы баз данных знают, первая вещь, на которую стоит грешить, когда бизнес-система работает медленно, - это база данных. Почему? Во-первых, потому, что это центральная часть большинства любых бизнес-систем, а во-вторых, потому что это также слишком часто верно.
Мы можем сыграть свою роль в рассеивании этого представления, глубоко изучив систему, которую мы создали, и поняв пределы ее применения через тестирование.
Но давайте сойдемся на том, что тестирование - это первая вещь, которая войдет в проектный план, когда пройдет немного времени. И что наиболее страдает от нехватки тестирования? Функциональные возможности? Возможно, немного, но пользователи заметят и будут жаловаться, что не работает кнопка "Save", и они не могут сохранить изменение строки, на редактирование которой они потратили 10 минут. Но что действительно становится осью во всем процессе - это глубокое испытание системы, чтобы удостовериться, что проект, над которым Вы (по-видимому) работали столь напряженно с самого его начала, фактически реализован правильно.
Но, скажите Вы, пользователи приняли работу системы, разве это не достаточно хорошо? Проблема с этим утверждением состоит в том, что то, что обычно составляет "тестирование" для пользовательского принятия, обычно представляет тыканье вокруг и около для испытания функциональных возможностей, которые они понимают, и дают Вам добро, если небольшая часть системы работает. Это адекватное испытание? Нет, в любой другой промышленности это определенно неприемлемо. Вы хотите, чтобы таким образом проверяли ваш автомобиль? "Ну, мы проехали на нем медленно один раз вокруг этого квартала солнечным днем без проблем; это хорошо!" Когда этот автомобиль впоследствии поломается в первой же поездке по автостраде, или в первый же дождливый или снежный день, то водитель будет иметь полное право очень огорчиться.
Слишком многие систем баз данных проверяются как тот автомобиль, только лишь с небольшим тыканьем вокруг, чтобы увидеть, как работают отдельные запросы и модули. Первый реальный тест совершается в рабочих условиях, когда пользователи пытаются сделать реальную работу. Это особенно верно, когда проект реализуется для единственного клиента (даже хуже, когда это - корпоративный проект, ибо управление больше заинтересовано в завершении работ, чем в качестве).
Как правило, главные ошибки находятся быстро, особенно связанные с производительностью. Если вы сразу попробовали запустить систему при полной нагрузке со стороны пользователей, фоновых процессов, технологических процессов, процедур обслуживания системы, ETL и т.д., то Вы, весьма вероятно, обнаружите, что не ожидали всех этих проблем с блокировками, которые вызываются пользователями, создающими данные, в то время как другие читают их, или проблем с аппаратными средствами, вызванными их плохой настройкой. Могут пройти недели, прежде чем заглохнут крики "SQL Server не может обработать это" даже после того, как Вы сделали надлежащую настройку.
Как только вы избавитесь от главных ошибок, крайние случаи (которые довольно редки, например, когда пользователь входит отрицательное число в качестве количества рабочих часов) начинают поднимать свои уродливые головы. То, с чем заканчивают на этом этапе, - программное обеспечение, которое время от времени терпит крах, что весьма напоминает нечто сверхъестественное (так как большое количество крайних багов обнаружатся способами, которые не очень очевидны и действительно трудно находимы).
Теперь намного тяжелее выполнять диагностику и исправлять ошибки, поскольку теперь вы сталкиваетесь с тем, что пользователи работают с реальными данными и стараются выполнить свою работу. Плюс к тому у вас, вероятно, имеется менеджер или даже два, которые сидят за вашей спиной и говорят каждые 30 секунд: "Когда это будет сделано?", -даже при том, что обнаружение такого рода ошибок, которые приводят к незначительному (но все же важному) отклонению в данных, может занимать дни и недели. Если бы надлежащее тестирование было выполнено, никогда бы не потребовались недели испытания для поиска этих ошибок, поскольку надлежащий план тестирования учитывает все возможные типы отказов, кодирует их в автоматизированный тест, который многократно запускается. Хорошее тестирование не позволит обнаружить все ошибки, но приведет вас к состоянию, в котором большинство проблем исходного проекта сведено к минимуму.
Если бы каждый настаивал на строгом плане тестирования как составной и неизменной части процесса разработки базы данных, то возможно настанет день, когда база данных не будет рассматриваться первым кандидатом для пересмотра при возникновении проблем с производительностью системы.
Резюме
Проект базы данных и его реализация - краеугольный камень любых проектов, ориентированных на обработку данных (читайте 99.9 % бизнес-приложений), и должен рассматриваться таковым, когда Вы занимаетесь разработкой. Эта статья, по-видимому, несколько нравоучительная, служит больше напоминанием мне и тому, кто ее читает. Некоторые советы типа надлежащего планирования, использования нормализации, строгого следования стандартам именования и документации вашей работы - это вещи, которые даже лучшие администраторы баз данных и архитекторы данных вынуждены заставлять себя делать. В состоянии напряжения, когда менеджер менеджера вашего менеджера ругается на то, что процесс затягивается, не легко вернуться и напомнить им, что они платят Вам сейчас, или они платят Вам позже. Эти задачи приносят дивиденды, которые очень трудно оценить количественно, поскольку чтобы оценить количество успеха, ему должна предшествовать неудача. И даже когда Вы преуспеваете в одной области, слишком часто незначительные отказы неожиданно возникают в других частях проекта, что вообще делает незамеченными ваши успехи.
Советы, которые я даю здесь, собирались многие годы; они перевели меня из разряда посредственных программистов/архитекторов базы данных в разряд хороших. Ни один из них не займет чрезмерного времени (кроме, возможно, проектирования и планирования), но все они потребуют больше времени, чем следование "легким путем". Давайте сойдемся на том, что если бы легкий путь оказался действительно легким в конечном счете, то я бы отставил более сложный путь в ту же секунду. Но этого нельзя сказать до тех пор, пока не будет получен конечный результат, и следует понять, что успех зависит от начальной точки в той же мере, что и от финальной.
Louis Davidson (оригинал: Ten Common Database Design Mistakes)
Перевод: Моисеенко С.И.
Оригинал перевода