Обзор сервера
Microsoft SQL Server - прямой потомок Sybase SQL Server, с которым его до сих пор связывает много общего, в первую очередь язык программирования Transact-SQL (далее T-SQL). Однако в версии 7.0, как заявляет Microsoft, сервер переписан полностью и больше не содержит кода от Sybase. Главным достоинством Microsoft SQL Server является его тесная интеграция с Windows NT и семейством продуктов Back Office - общая модель защиты, базирующаяся на защите Windows NT, единая консоль администрирования (Microsoft Management Console), единый набор программных интерфейсов для доступа к данным (OLE DB). Текущая версия сервера на момент написания этой книги - Microsoft SQL Server 2000. Сервер выпускается в следующих редакциях:
- Personal - версия, работающая под управлением Windows 95 и Windows NT Workstation. Предназначена в основном для отладки при разработке приложений. Поддерживает до двух процессоров. Реально можно работать (имея загруженным сервер, Query Analyzer и Enterprise Manager) на конфигурации Pentium-100/40 Мбайт под управлением Windows 95.
- Standard - стандартная редакция. Работает под управлением Windows NT Server. Поддерживает до четырех процессоров.
- Enterprise - расширенная редакция. Поддерживает до 32 процессоров, включает в себя некоторые дополнительные возможности.
- Developer - редакция для разработчиков. По функциональности приблизительно соответствует Enterprise.
Кроме того, существует версия SQL Server для Windows CE, предназначенная для портативных компьютеров. Она совместима с остальными версиями сервера по языку для написания серверного кода и имеет возможности репликации данных с ними.
Таким образом, сервер работает на всей линейке операционных систем Microsoft на процессорах Intel и Alpha.
Нельзя не упомянуть и такой продукт, как Microsoft Data Engine (MSDE), - это версия Microsoft SQL Server без графических средств администрирования и с ограничениями по размеру базы данных (2 Гбайт) и количеству пользователей (5). MSDE предназначен для построения встраиваемых систем, которые при необходимости легко могут быть перенесены на полнофункциональную редакцию сервера, а также, например, использованы для создания демонстрационных версий продуктов. Администрирование MSDE может производиться при помощи утилиты osql, клиентских утилит от Microsoft SQL Server либо из Microsoft Access 2000. MSDE поставляется в составе Microsoft Office 2000 Professional и Microsoft Visual Studio.
Из дополнительных возможностей следует отметить:
- OLAP-сервер - средство для создания и представления многомерных кубов данных, использующихся в аналитических системах. На сегодня Microsoft SQL Server является одним из самых дешевых, представленных на рынке решений подобного рода. OLAP Services входят в стандартную поставку и не требуют дополнительных отчислений.
- Полнотекстовый поиск по базе данных. В сервер включена специальная версия Microsoft Index Server, с помощью которой можно построить по текстовым (включая BLOB) полям полнотекстовый индекс и расширения SQL, позволяющие строить запросы по этому индексу, например:
SELECT ProductName FROM Products WHERE CONTAINS(ProductName, 'spread NEAR Boysenberry')
- English Query - инструмент для формирования запросов на естественном английском языке, например: "How many blue Fords were sold in 1996?" В настоящее время существуют решения российских фирм, позволяющие выполнять полнотекстовый поиск на русском языке с учетом словоформ и формировать запросы на русском языке. Ознакомиться с ними можно по адресу: http://www.microsoft.com/rus/sql.
- Data Transformation Services (DTS) - универсальный инструмент для перемещения данных между гетерогенными источниками. Единственное требование, предъявляемое к такому источнику данных, - наличие ODBC-драйвера, а лучше - OLE DB-провайдера. DTS позволяет создавать сложные сценарии переноса данных. Инструмент полезен не только при переносе данных на Microsoft SQL Server, но и для любой другой СУБД.
- Встроенную в сервер поддержку XML, позволяющую использовать XML-документ в качестве источника данных в запросе и выдавать результаты запроса в виде XML-документа.
Клиентская часть Microsoft SQL Server реализована на платформе Win32. В стандартный комплект поставки входят драйверы, работающие под управлением Windows 95 и Windows NT. Таким образом, в качестве клиента Microsoft SQL Server могут выступать все платформы, поддерживаемые Delphi.
Все перечисленное делает Microsoft SQL Server привлекательным решением для реализации баз данных на платформе Windows NT.
Особенности реализации клиентской части
До версии 6.5 основным интерфейсом доступа к Microsoft SQL Server со стороны клиента была библиотека DB-Library. Она реализовывала набор низкоуровневых интерфейсов, позволяющих организовать взаимодействие с сервером. Однако в версии 7 был введен новый интерфейс доступа - OLE DB. В связи с этим развитие DB-Library было прекращено, и теперь библиотека служит лишь для обеспечения обратной совместимости. Доступ через нее не поддерживает новых расширений сервера (Unicode, текстовые поля до 8 Кбайт, тип данных GUID). Тем не менее старые приложения, не использующие этой функциональности, сохраняют работоспособность, однако в связи с изменениями в 7-й версии может понадобиться некоторая их переделка. Драйвер SQL Links реализует доступ при помощи DB-Library, поэтому воспользоваться этими расширениями с его помощью невозможно. Для обеспечения полноценного доступа к Microsoft SQL Server 7.0 и выше необходимо использовать в приложении новый набор компонентов ADOExpress, включенный в Delphi 5. Возможно также применение BDE, но при этом сервер доступен в объеме возможностей версии 6.х. Cуществует также ODBC-драйвер, посредством которого возможен полнофункциональный доступ к серверу. При работе с сервером версии 2000 на применение BDE накладываются дополнительные ограничения, связанные с использованием индексов по вычисляемым полям.
Доступ при помощи ADOExpress
ActiveX Data Objects (ADO) - надстройка над интерфейсом OLE DB, позволяющая обеспечить бизнес-приложениям высокоуровневый доступ к данным. Эта технология включена в Windows 2000, а для остальных версий Windows доступна в виде бесплатного обновления. ADO автоматически инсталлируется на компьютер при установке клиента Microsoft SQL Server.
Начиная с 5.0-й версии в Delphi (в редакции Enterprise) включен набор компонентов, позволяющих работать с ADO. Пользователи Delphi Professional могут приобрести эти компоненты в виде отдельного продукта. ![]()
В качестве драйверов баз данных ADO использует так называемые OLE DB-провайдеры, которые представляют собой COM-серверы, реализующие предопределенный набор COM-интерфейсов. Например, для доступа к набору данных служит интерфейс IRowset, возвращаемый OLE DB при открытии этого набора данных. Для того чтобы указать, какой провайдер и с какими параметрами должен использоваться ADO, предусмотрена так называемая строка подключения (Connection String), содержащаяся в свойстве ConnectionString компонентов ADOExpress.
Для ее построения Delphi использует соответствующий диалог: ![]()
Для подключения к Microsoft SQL Server необходимо указать тип провайдера "Microsoft OLE DB Provider for SQL Server" и в следующем окне заполнить информацию, необходимую для подключения: ![]()
После этого можно использовать компоненты ADO в качестве обычных наследников класса TDataSet.
Следует отметить, что технология ADO в значительной мере оптимизирована для использования совместно с Microsoft SQL Server 7.0. Полностью поддерживается модель работы Prepare-Execute, позволяющая эффективно кэшировать планы запросов, серверные курсоры (свойства CursorLocation и CursorType), возможность возврата запросом или хранимой процедурой нескольких наборов данных, прямой доступ к таблицам на сервере (без промежуточной генерации запроса). Например, задав в TADOQuery.SQL следующий код:
SELECT * FROM One SELECT * FROM Two
можно в приложении получить два набора данных:
ADOQuery1.Open; ADODataSet1.RecordSet := ADOQuery1.NextRecordSet;
Решена проблема, возникающая при попытке выполнить запрос при не до конца загруженных данных другого запроса. В этом случае ADOExpress автоматически открывает новое временное соединение с сервером и выполняет запрос, используя это соединение.
В исходной версии Delphi 5 технология ADOExpress содержит ряд серьезных ошибок, которые делают работу при помощи вышеупомянутых компонентов практически невозможной. Поэтому настоятельно рекомендуется установка пакетов обновления Delphi и последнего обновления ADO (AePatch.exe), доступного с сайта http://community.borland.com из раздела Code Central.
Доступ посредством BDE
Этот способ доступа не является рекомендуемым, однако для многих приложений, написанных еще для версии 6.х, он может понадобиться из соображений обратной совместимости.
В составе BDE поставляется драйвер SQL Link для Microsoft SQL Server, использующий библиотеку DB-Library, что исключает полноценный доступ к возможностям сервера. При работе с помощью этого драйвера, например, нельзя использовать символьные данные в кодировке Unicode, а также некоторые системные функции. Если необходимо получить доступ к таким данным, в запросе необходимо явно преобразовать их в один из поддерживаемых типов данных, например:
SELECT CAST(USER_NAME() AS VARCHAR(255))
При работе с сервером при помощи BDE и драйвера SQL Link необходимо помнить следующее: ![]()
- В зависимости от кодовой страницы сервера он может воспринимать дату в различных форматах. Например: ‘1 Apr 1999’ для английской и ‘1 Апр 1999’ для русской. DB-Library пытается распознать кодовые страницы клиента и сервера и преобразовать дату в нужный вид, что, однако, не всегда удается сделать правильно. Для исключения возникающей ошибки необходимо проверить язык, установленный на сервере по умолчанию (SET LANGUAGE) и в программе Client Network Utility на закладке "DB Library Options" отключить флажок "Use International Settings", если на нем установлен us_english или включить, если установлен русский. Другой способ избежать данной проблемы - передавать даты на сервер в виде текстовой строки вида ‘yyyymmdd’. При преобразовании 8-символьной строки в дату сервер всегда интерпретирует ее таким образом и исключает возможность ошибки. Сделать это можно так:
Params[0].AsString := FormatDateTime(‘yyyymmdd’, DateTimeVariable);
- При выполнении запроса на выборку данных сервер предполагает, что клиентская программа проведет считывание всех запрошенных данных до посылки на сервер следующего оператора. Однако BDE загружает записи с сервера только по мере необходимости (например, открыв в TDBGrid большую таблицу, мы прочтем с сервера только записи, которые поместятся на экран в ее видимой части). Остальные записи считываются по мере необходимости, например при прокрутке таблицы. Если в такой ситуации попытаться выполнить еще один запрос, BDE принудительно выполнит FetchAll для всех открытых, но не считанных до конца запросов. Это может привести к неожиданной задержке выполнения приложения.
- При использовании индексов по вычисляемым полям, появившимся в Microsoft SQL Server 2000, необходимо, чтобы для сессии были установлены параметры:
ANSI_NULLS ON ANSI_PADDING ON ANSI_WARNINGS ON ARITHABORT ON CONCAT_NULL_YIELDS_NULL ON QUOTED_IDENTIFIER ON NUMERIC_ROUNDABORT OFF
В противном случае таблица, для которой определен индекс по вычисляемому полю, будет доступна только для чтения. Приведенный набор настроек соответствует значениям по умолчанию для сессий OLE DB и ODBC. DB-Library инициализирует их по-другому, поэтому вы должны явно задать требуемые значения после соединения с сервером.
Особенности реализации серверной части
Microsoft SQL Server имеет встроенный язык программирования Transact SQL, являющийся процедурным расширением стандарта ANSI SQL 92 entry level. T-SQL имеет полный набор средств для написания хранимых процедур и триггеров. Кроме того, реализованы некоторые расширения стандартного языка SQL, которые необходимо знать разработчику.
SELECT
В ранних версиях внешнее объединение таблиц задавалось выражением *= и =* в предложении WHERE. Этот синтаксис поддерживается, но не рекомендуется и в очередных версиях будет исключен. Начиная с версии 6.5 сервер поддерживает стандартный синтаксис {LEFT/RIGHT/FULL} [OUTER] JOIN.
При выполнении SELECT в таблицу (SELECT INTO) функция IDENTITY(data_type[, seed, increment]) позволяет создать в этой таблице автоинкрементное поле IDENTITY и заполнить его. Посредством этой функции и временных таблиц можно пронумеровать результаты запроса.
SELECT IDENTITY(INTEGER, 1, 1) AS Counter, Name INTO #Temp FROM MyTable ORDER BY Name SELECT * FROM #Temp
Начиная с версии 7.0 оператор SELECT имеет модификаторы TOP n [PERSENT] [WITH TIES], позволяющие вывести первые n записей или n процентов записей. Указав WITH TIES, можно заставить сервер включить в результат все записи с таким же значением сортируемого поля, как и у последней из n записей. Если SELECT не имеет фразы ORDER BY, то набор записей не обязательно будет одинаковым.
В качестве одной из таблиц в запросе можно использовать вложенный запрос:
SELECT A.Name, A.Population, B.AvgPop FROM City A INNER JOIN (SELECT Country, AVG(Population) AS AvgPop FROM City GROUP BY Country ) AS B ON A.Country = B.Country
Этот запрос для каждого города выведет его название, количество жителей, а также среднее количество жителей на город в той стране, где он находится.
Функции OPENQUERY и OPENROWSET позволяют использовать в качестве одной из таблиц в запросе выборку из любого OLE DB-совместимого источника данных.
В Microsoft SQL Server 2000 можно в запросе указать выражение FOR XML, в результате чего будет возвращена строка, содержащая XML-представление выборки. Например, запрос:
SELECT O.OrderID, O.CustomerID, O.OrderDate, O.ShipName, O.ShipAddress, O.ShipCity, O.ShipRegion, P.ProductName, OD.UnitPrice, OD.Quantity FROM Orders O INNER JOIN [Order Details] OD ON O.OrderId = OD.OrderId INNER JOIN Products P ON OD.ProductId = P.ProductId WHERE O.OrderId = '10248' FOR XML AUTO
вернет результат:
<O OrderID="10248" CustomerID="VINET" OrderDate="1996-07-04T00:00:00" ShipName="Vins et alcools Chevalier" ShipAddress="59 rue de l'Abbaye" ShipCity="Reims"> <P ProductName="Queso Cabrales"> <OD UnitPrice="14.0000" Quantity="12"/> </P> <P ProductName="Singaporean Hokkien Fried Mee"> <OD UnitPrice="9.8000" Quantity="10"/> </P> <P ProductName="Mozzarella di Giovanni"> <OD UnitPrice="34.8000" Quantity="5"/> </P> </O>
Предусмотрено как автоматическое форматирование XML-результатов запроса, так и задание способа форматирования программистом.
Кроме того, возможно использование XML-данных в качестве таблицы в запросе. Рассмотрим, например, хранимую процедуру, выдающую данные по заранее неизвестному количеству записей. Идентификаторы записей передаются в нее в виде XML-документа:
CREATE PROCEDURE XMLParam @Ids VARCHAR(8000) AS
DECLARE @idoc int EXEC sp_xml_preparedocument @idoc OUTPUT, @Ids SELECT O.* FROM Orders O INNER JOIN OPENXML (@idoc, '/ROOT/Ids', 1) WITH (ID INT) AS T ON .OrderId = T.Id EXEC sp_xml_removedocument @idoc GO
Вызов этой процедуры выглядит следующим образом:
DECLARE @S VARCHAR(8000) SET @S = '<ROOT> <Ids ID="10250"/> <Ids ID="10257"/> <Ids ID="10258"/> </ROOT>' EXECUTE XMLParam @S
Очевидно, что соответствующая строка параметров может быть легко построена и клиентским приложением.
INSERT
В дополнение к стандартным возможностям Microsoft SQL Server позволяет вставить в таблицу набор данных, полученный в результате выполнения хранимой процедуры, при помощи синтаксиса:
INSERT author_sales EXECUTE get_author_sales
UPDATE и DELETE
Сервер поддерживает расширенный синтаксис
UPDATE MyTable
SET Name = ‘Иванов’ FROM MyTable T INNER JOIN AnotherTable A ON T.Id = A.MyTableId AND A.SomeField = 20
CREATE TABLE
В версии 7.0 поддерживаются следующие типы данных:
| Тип | Синоним | Примечание |
|---|---|---|
| BIT | Целое число, равное 0 или 1. В Delphi возможно обращение к полю этого типа при помощи свойства AsBoolean (1 = True, 0 = False) | |
| INT | INTEGER | 32-битное целое число в диапазоне от - 2 147 483 648 до 2 147 483 647 |
| SMALLINT | 16-битное целое число в диапазоне от 32 768 до 32 767 | |
| TINYINT | 8-битное целое число в диапазоне от 0 до 255 | |
| DECIMAL[(P[, S])] | NUMERIC, DEC | Десятичное число с фиксированной точностью в диапазоне от - 1038 -1 до 1038 - 1. P - максимальное количество знаков в числе S - количество знаков после запятой |
| MONEY | Денежный тип данных. Целое 64-битное число, младшие 4 разряда которого отведены под дробную часть. Может хранить числа в диапазоне от -922 337 203 685 477,5808 до 922 337 203 685 477,5807. В Delphi соответствует типу данных Currency | |
| SMALLMONEY | Аналогичен Money, но 32-разрядный и ограничен диапазоном от -214 748,3648 до 214 748,3647 | |
| FLOAT | DOUBLE PRECISION | Число с плавающей точкой в диапазоне от -1.79E + 308 до 1.79E + 308 |
| REAL | Число с плавающей точкой в диапазоне от -3.40E + 38 до 3.40E + 38 | |
| DATETIME | Дата и время в диапазоне от 1 января 1753 г. до 31 декабря 9999 г. с точностью 3.33 мс | |
| SMALLDATETIME | Дата и время в диапазоне от 1 января 1900 г. до 6 июня 2079 г. с точностью до 1 мин | |
| TIMESTAMP | Уникальный идентификатор в пределах базы данных. Этот тип данных НЕ СОДЕРЖИТ времени и лишь гарантирует, что поле этого типа уникально в рамках базы данных | |
| UNIQUEIDENTIFIER | Глобальный уникальный идентификатор. Статистически уникальное 16-битное значение. Над этим типом данных определены лишь операции =, <>, IS NULL и IS NOT NULL | |
| CHAR[(N)] | CHARACTER, VARYING VARCHAR |
Строка фиксированной длины. N - длина строки. Максимальная длина - 8 тыс. символов |
| VARCHAR[(N)] | CHARACTER VARYING(N) | Строка переменной длины. N - длина строки. Максимальная длина - 8 тыс. символов |
| TEXT | Строка произвольной длины (до 2 147 483 647 символов) | |
| NCHAR[(N)] | NATIONAL CHARACTER, NATIONAL CHAR |
Строка фиксированной длины в формате Unicode. N - длина строки. Максимальная длина - 4 тыс. символов |
| NVARCHAR[(N)] | NATIONAL CHARACTER VARYING(N), NATIONAL CHAR VARYING(N) |
Строка переменной длины в формате Unicode N - длина строки. Максимальная длина - 4000 символов |
| NTEXT | NATIONAL TEXT | Строка произвольной длины (до 1 073 741 823 символов) |
| BINARY[(N)] | VARYING VARBINARY | Двоичные данные фиксированной длины (до 8000 байт) N - длина данных |
| VARBINARY[(N)] | Двоичные данные переменной длины (до 8000 байт) N - длина данных | |
| IMAGE | Двоичные данные произвольной длины (до 2 147 483 647 байт) |
В версии SQL 2000 дополнительно предусмотрены следующие типы данных:
| Тип | Синоним | Примечание |
|---|---|---|
| BIGINT | 64-битное целое число | |
| SQL_VARIANT | Может хранить данные произвольного типа |
В версии 7.0 поддерживается создание вычисляемых полей
CREATE TABLE MyTable ( Direction BIT NOT NULL, Amount MONEY, CASE Direction WHEN 1 THEN Amount ELSE -Amount END AS SignedAmount )
Выражение не должно содержать подзапросов. В версии Microsoft SQL Server 2000 по вычисляемому полю может быть построен индекс.
Написание триггеров
Триггеры в Microsoft SQL Server срабатывают после обновления и лишь один раз на оператор (а не на каждую обновленную запись). Количество триггеров на таблицу не ограничено. В триггере доступны обновленная таблица и две виртуальные таблицы Inserted и Deleted.
В них находятся:
| Inserted | Deleted | |
|
INSERT |
Вставленные записи | Нет записей |
|
UPDATE |
Новые версии записей | Старые версии записей |
|
DELETE |
Нет записей | Удаленные записи |
Основываясь на содержании этих таблиц, триггер может осуществить дополнительную модификацию данных либо отменить транзакцию, вызвавшую этот оператор. Например:
CREATE TRIGGER T1 ON MyTable FOR INSERT, UPDATE AS BEGIN -- Заносим в поля: -- LastUserName - имя пользователя, последним обновившего запись -- LastDateTime - дату и время последнего обновления UPDATE MyTable SET LastUserName = SUSER_NAME(), LastDateTime = GETDATE() FROM Inserted I INNER JOIN MyTable T ON I.Id = T.Id END
CREATE TRIGGER T2 ON MyTable FOR DELETE AS BEGIN -- Этот триггер откатывает и снимает всю транзакцию -- вызвавшую ошибку IF EXISTS (SELECT * FROM Deleted WHERE Position = ‘Boss’) BEGIN RAISERROR(‘Нельзя удалять начальника’, 16, 1) ROLLBACK END END
CREATE TRIGGER T3 ON MyTable FOR DELETE AS BEGIN -- А этот просто не дает удалить запись -- позволяя продолжить транзакцию IF EXISTS (SELECT * FROM Deleted WHERE Position = ‘Programmer’) BEGIN INSERT INTO MyTable SELECT * FROM Deleted WHERE Position = ‘Programmer’ RAISERROR(‘Программиста удалить тоже не получится’, 16, 1) END END
Поскольку триггер срабатывает после обновления таблицы, в нем нельзя реализовывать каскадные обновления данных при наличии внешних ключей. Например, если есть две таблицы:
CREATE TABLE Main ( Id INTEGER PRIMARY KEY ) CREATE TABLE Child (
Id INTEGER PRIMARY KEY,
MainId INTEGER NOT NULL REFERENCES Main(Id) )
то при удалении записи из Main, на которую имеются ссылки в Child, триггер на Main не сработает. Чтобы обойти эту проблему, рекомендуется создать хранимую процедуру
CREATE PROCEDURE DeleteFromMain @Id INTEGER AS BEGIN DECLARE @Result INTEGER BEGIN TRANSACTION SAVE TRANSACTION DeleteFromMain DELETE Child WHERE MainId = @Id DELETE Main WHERE Id = @Id SET @Result = @@ERROR IF @Result <> 0 ROLLBACK TRANSACTION DeleteFromMain COMMIT END
Другой способ - реализация ограничений ссылочной целостности только при помощи триггеров.
Кроме того, в версии Microsoft SQL Server 2000 возможно создание триггеров INSTEAD OF, которые выполняются вместо вызвавшей их операции. При этом ответственность за запись данных в таблице полностью лежит на программисте. Такие триггеры могут быть созданы на представлениях (VIEW), что позволяет сделать обновляемым любое представление, независимо от его сложности.
Пакеты команд
Операторы могут быть отправлены на сервер не поодиночке, а пакетами. Пакетом (batch) называется группа команд, отправленная клиентским приложением на сервер одновременно. Весь пакет компилируется в единый план исполнения. Такая техника позволяет уменьшить сетевой трафик и увеличить эффективность приложения. Типичный пакет может выглядеть следующим образом:
BEGIN TRANSACTION INSERT One (SomeField) VALUES (:1) INSERT Two (AnotherField) VALUES (:2) IF @@ERROR = 0 COMMIT ELSE ROLLBACK
Внутри пакета возможно объявление переменных. Область их видимости ограничена пакетом, в котором они объявлены.
Весь пакет не выполняется в случае синтаксической ошибки в любом из операторов пакета. Однако в случае ошибки выполнения любого оператора остальные операторы продолжают исполняться до окончания пакета.
Разделителем пакетов команд служит оператор GO.
Обработка ошибок
Для того чтобы проинформировать клиентское приложение об ошибке, Microsoft SQL Server использует функцию RAISERROR. При этом необходимо помнить, что:
- выполнение процедуры этой функцией не прерывается, транзакции не откатываются. Если в этом есть необходимость, используйте ROLLBACK или RETURN;
- ошибки с параметром severity ниже 10 являются информационными и не вызывают исключения компонентов работы с данными.
При возникновении ошибки в каком-либо из операторов внутри пакета выполнение пакета продолжается, а функция @@ERROR возвращает код ошибки, который можно обработать.
INSERT MyTable (Name) VALUES (‘Петров’) IF @@ERROR != 0 PRINT ‘Ошибка вставки’.
После успешного оператора @@ERROR возвращает 0, поэтому если значение ошибки может понадобиться впоследствии, то его необходимо сохранить в переменной.
DECLARE @ErrCode INTEGER SET @ErrCode = 0 BEGIN TRANSACTION INSERT MyTable (Name) VALUES (‘Иванов’) IF @@ERROR != 0 @ErrCode = @@ERROR INSERT MyTable (Name) VALUES (‘Петров’) IF @@ERROR != 0 @ErrCode = @@ERROR IF @ErrCode = 0 COMMIT ELSE BEGIN ROLLBACK RAISERROR(‘Не удалось обновить данные’, 16, 1) END
Если оператор обновления данных не нашел ни одной записи, ошибки не возникает. Проверить эту ситуацию можно при помощи функции @@ROWCOUNT, которая возвращает количество записей, обработанных последним оператором.
UPDATE MyTable SET Name = ‘Сидоров’ WHERE Name = ‘Петров’ IF @@ROWCOUNT = 0 PRINT ‘Петров не найден’
Блокировки
Microsoft SQL Server поддерживает блокировку на уровне записи для всех операций модификации данных. Если оптимизатор решит, что количество блокируемых записей в таблице слишком велико, то он может произвести эскалацию блокировок на группу страниц или на всю таблицу. Это происходит, например, при одновременном обновлении значительного количества записей. В подобном случае гораздо удобнее заблокировать таблицу (или группу страниц в ней), внести изменения, а затем разблокировать ее, вместо того, чтобы накладывать блокировку на каждую запись. Сервер не предоставляет средств для управления эскалацией блокировок и осуществляет ее автоматически.
Другой важной проблемой является модель обеспечения уровней изоляции транзакций REPEATABLE READ и SERIAZABLE. При выполнении транзакции с этим уровнем изоляции сервер блокирует диапазоны значений полей, по которым осуществляется выборка данных для предотвращения вставки "фантомных" значений. Например, если в транзакции с уровнем изоляции SERIAZABLE будет выполнен запрос
SELECT * FROM MyTable WHERE Name BETWEEN ‘A’ AND ‘C’
то сервер наложит блокировку по записи (Shared Lock) на диапазон значений, попавших в результат запроса, предотвращая тем самым вставку "фантомных" записей другими транзакциями. Блокировка будет удерживаться до конца транзакции. На измененные транзакцией записи накладывается блокировка по чтению (Exclusive Lock), предотвращающая чтение их другими транзакциями. Поэтому транзакции с высокими уровнями изоляции необходимо тщательно планировать и делать их максимально короткими.
Обработка транзакций
В Microsoft SQL Server поддерживаются все определенные стандартом ANSI SQL 92 уровни изоляции транзакций:
| READ UNCOMMITTED | Позволяет транзакции читать неподтвержденные данные других транзакций |
| READ COMMITTED | Предотвращает считывание транзакцией данных, не подтвержденных другой транзакцией |
| REPEATABLE READ | Все блокировки удерживаются до конца транзакции, гарантируя идентичность повторно считанных данных прочитанным ранее |
| SERIALIZABLE | Гарантирует отсутствие "фантомов". Реализуется за счет блокирования диапазонов записей, внутри которых эти "фантомы" могут появиться |
Для установки текущего уровня изоляции используется оператор
SET TRANSACTION ISOLATION LEVEL
{
READ COMMITTED
/ READ UNCOMMITTED
/ REPEATABLE READ
/ SERIALIZABLE
}
Момент начала транзакции регулируется установкой
SET IMPLICIT_TRANSACTION ON/OFF
По умолчанию она установлена в ON, и каждый оператор выполняется в отдельной транзакции. По его завершении неявно выполняется COMMIT. Если необходимо выполнить транзакцию, состоящую из нескольких операторов, ее надо явно начать командой BEGIN TRANSACTION. Заканчивается транзакция оператором COMMIT или ROLLBACK.
Например:
INSERT MyTable VALUES (1)
-- Выполнился внутри отдельной транзакции BEGIN TRANSACTION -- Начали явную транзакцию INSERT MyTable VALUES (2) INSERT MyTable VALUES (3) COMMIT -- завершили явную транзакцию
При выдаче команды
SET IMPLICIT_TRANSACTION OFF
сервер начинает новую транзакцию, если она еще не начата и выполнился один из следующих операторов:
|
ALTER TABLE |
FETCH |
REVOKE |
|
CREATE |
GRANT |
SELECT |
|
DELETE |
INSERT |
TRUNCATE TABLE |
|
DROP |
OPEN |
UPDATE |
Транзакция продолжается до тех пор, пока не будет выдана команда COMMIT или ROLLBACK.
Возможно создание вложенных транзакций. При этом функция @@TRANCOUNT показывает глубину вложенности транзакции. Например:
BEGIN TRANSACTION SELECT @@TRANCOUNT -- Выдаст 1 BEGIN TRANSACTION SELECT @@TRANCOUNT -- Выдаст 2 COMMIT SELECT @@TRANCOUNT -- Выдаст 1 COMMIT SELECT @@TRANCOUNT -- Выдаст 0
Вложенный BEGIN TRANSACTION не начинает новую транзакцию. Он лишь увеличивает @@TRANCOUNT на единицу. Аналогично вложенный оператор COMMIT не завершает транзакцию, а лишь уменьшает @@TRANCOUNT на единицу. Реальное завершение транзакции происходит, когда @@TRANCOUNT становится равным нулю. Такой механизм позволяет писать хранимые процедуры, содержащие транзакцию, например:
CREATE PROCEDURE Foo AS BEGIN BEGIN TRANSACTION INSERT MyTable VALUES (1) INSERT MyTable VALUES (1) COMMIT END
При запуске вне контекста транзакции процедура выполнит свою транзакцию. Если она запущена внутри транзакции, внутренние BEGIN TRANSACTION и COMMIT просто увеличат и уменьшат счетчик транзакций.
Оператор ROLLBACK ведет себя по-иному. Он всегда, независимо от текущего уровня вложенности, устанавливает значение переменной @@TRANCOUNT равным нулю и отменяет все изменения, от начала самой внешней транзакции. Если в хранимой процедуре возможен откат ее действий исходя из какого-то условия, можно использовать точки сохранения (savepoint)
CREATE PROCEDURE Foo AS BEGIN BEGIN TRANSACTION -- Этот оператор не может быть отменен вне контекста -- основной транзакции INSERT MyTable VALUES (1) SAVE TRANSACTION InsideFoo -- Операторы, начиная отсюда, могут быть отменены -- без отката основной транзакции INSERT MyTable VALUES (2) INSERT MyTable VALUES (3) IF (SELECT COUNT(*) FROM MyTable) > 3 ROLLBACK TRANSACTION InsideFoo -- Отменяем изменения, внесенные после -- последнего savepoint COMMIT END
Отдельного обсуждения заслуживает команда ROLLBACK, вызванная в триггере.
В этом случае не только откатывается транзакция, в рамках которой произошло срабатывание триггера, но и прекращается выполнение пакета команд, внутри которого это произошло. Все операторы, следующие за оператором, вызвавшим триггер, не будут выполнены. Рассмотрим эту ситуацию на примере:
CREATE TABLE MyTable (Id INTEGER) GO CREATE TRIGGER MyTrig ON MyTable FOR INSERT AS BEGIN
IF (SELECT MAX(Id) FROM Inserted) >= 2 BEGIN ROLLBACK RAISERROR(‘Id >= 2’, 17, 1) END END GO INSERT MyTable VALUES (1) INSERT MyTable VALUES (2) - Вызовет ROLLBACK в триггере -- Операторы, начиная отсюда, не выполнятся INSERT MyTable VALUES (3) INSERT MyTable VALUES (4)
Соответствие стандарту ANSI SQL 92
В Microsoft SQL Server имеются настройки, позволяющие изменять степень соответствия сервера стандарту ANSI SQL 92.
SET ANSI_NULLS {ON/OFF} - регулирует результат сравнения значений, содержащих NULL. Если ANSI_NULLS = OFF, то запрос
SELECT * FROM MyTable WHERE MyField = NULL
вернет все строки, в которых MyField установлено в NULL. Если ANSI_NULLS = OFF, то в соответствии со стандартом ANSI SQL92 сравнение с NULL возвращает UNKNOWN. Другие установки, на которые следует обратить внимание:
| SET CURSOR_CLOSE_ON_COMMIT | Устанавливает режим закрытия курсоров по завершении транзакции |
| SET ANSI_NULL_DFLT_ON и SET ANSI_NULL_DFLT_OFF |
Устанавливают возможность принятия значения NULL полем по умолчанию при создании таблицы |
| SET IMPLICIT_TRANSACTIONS | Устанавливает режим Autocommit |
| SET ANSI_PADDING | Устанавливает режим "отсечения" концевых пробелов для вновь создаваемых полей |
| SET QUOTED_IDENTIFIER | Разрешает выделение идентификаторов двойными кавычками |
| SET ANSI_WARNINGS | Устанавливает реакцию на математические ошибки |
Рассмотрение этих параметров выходит за рамки данной статьи, однако при чтении документации необходимо обратить на них внимание.
Параметр SET ANSI_DEFAULTS устанавливает режим максимальной совместимости с ANSI SQL 92. При установке SET ANSI_DEFAULTS ON устанавливаются в ON следующие параметры:
| SET ANSI_NULLS | SET CURSOR_CLOSE_ON_COMMIT |
| SET ANSI_NULL_DFLT_ON | SET IMPLICIT_TRANSACTIONS |
| SET ANSI_PADDING | SET QUOTED_IDENTIFIER |
| SET ANSI_WARNINGS |
По умолчанию ANSI_DEFAULTS = ON для клиентов ODBC и OLE DB (ADO) и OFF для клиента DB-Library (BDE). Поскольку предпочтительным (и поддерживаемым в будущем) методом доступа является OLE DB, то при разработке клиентской части, использующей BDE, рекомендуется явно устанавливать SET ANSI_DEFAULTS ON. С различиями в значении этого параметра связана и проблема, возникающая при разработке запросов посредством Query Analyzer. Если в нем и в клиентском приложении имеются разные настройки совместимости с ANSI, одни и те же запросы могут выдавать разные результаты. Поэтому рекомендуется проверять настройки Query Analyzer на предмет их соответствия тем, которые предполагаются в клиентском приложении.
Модель безопасности
Роли
Вместо групп пользователей, которые фигурировали в предыдущих версиях, версия 7.0 использует роли пользователей. Права могут даваться или отниматься у роли, и это отражается на правах всех ассоциированных с ней пользователей. При этом пользователь может быть ассоциирован одновременно с несколькими ролями.
Для облегчения управления сервером и базами данных поддерживаются встроенные серверные роли и роли баз данных. Так, например, серверная роль serveradmin дает право на настройку конфигурации и остановку сервера, а роль базы данных db_securityadmin позволяет управлять правами доступа пользователей. Набор встроенных ролей дает возможность не предоставлять административных привилегий пользователям, нуждающимся в каких-либо специфических правах. Так, роль db_securityadmin не предоставляет своим членам прав на чтение или модификацию пользовательских таблиц.
Интегрированная безопасность
Сильной стороной Microsoft SQL Server является его тесная интеграция с системой безопасности Windows NT. Права на доступ к серверу и базам данных можно давать пользователям и группам Windows NT. Механизм делегирования полномочий позволяет пользователям, подключившимся к одному из серверов, иметь доступ к другим серверам в сети со своими правами, отличающимися от прав сервера, к которому они подключились. Также возможна прозрачная для пользователя проверка его полномочий при доступе к серверу через Microsoft Internet Information Server или Microsoft Transaction Server.
Оптимизатор запросов Microsoft SQL Server
В версии 7.0 существенно переработан оптимизатор запросов. Сервер может использовать несколько индексов на каждую таблицу в запросе; один запрос может исполняться параллельно на нескольких процессорах. В SQL Server 7.0 реализованы три метода выполнения операции слияния таблиц (JOIN):
- LOOP JOIN - для каждой записи в одной из таблиц производится цикл по связанным записям второй таблицы. Этот метод наиболее эффективен для малых результирующих наборов данных.
- MERGE JOIN - требует, чтобы оба набора данных были отсортированы по сливаемому полю (набору полей). В этом случае сервер осуществляет слияние за один проход по каждому из наборов данных. Поскольку они уже упорядочены, нет необходимости просматривать все записи, достаточно выбирать их начиная с текущей, пока значение поля не изменится. Это самый быстрый метод слияния больших наборов данных.
- HASH JOIN используется, когда невозможно использовать MERGE JOIN, а наборы данных велики. По одному из наборов строится хэш-таблица, а затем для каждой записи из второго набора вычисляется та же хэш-функция и производится ее поиск в таблице. В случае больших неотсортированных наборов данных этот алгоритм существенно эффективнее, чем LOOP JOIN.
При фильтрации по индексу сервер не осуществляет сразу выборку данных из таблицы. Вместо этого строится набор "закладок" (Bookmark), а затем производится выборка данных в одной операции (Bookmark Lookup). Это позволяет резко снизить количество обращений к диску.
Новые стратегии оптимизации требуют учета при проектировании базы данных и структуры индексов. Например, для следующей структуры таблиц:
CREATE TABLE T1 ( Id INTEGER PRIMARY KEY, ... ) CREATE TABLE T2 ( Id INTEGER PRIMARY KEY, ... ) CREATE TABLE T3 ( Id INTEGER PRIMARY KEY, T1Id INTEGER REFERENCES T1(Id), T2Id INTEGER REFERENCES T2(Id), ... )
запрос
SELECT * FROM T1 INNER JOIN T3 ON T1.Id = T3.T1Id INNER JOIN T2 ON T2.Id = T3.T2Id WHERE ...
может быть существенно ускорен созданием индексов:
CREATE INDEX T3_1 ON T3(T1Id, T2Id)
После слияния T3 с T1 он позволяет получить упорядоченный по T2Id набор данных, который может быть слит с T2 путем эффективного алгоритма MERGE JOIN. Впрочем, лучший эффект, возможно, даст индекс:
CREATE INDEX T3_2 ON T3(T2Id, T1Id)
Это зависит от количества записей в T1, T2 и распределения их сочетаний в T3. В OLAP-системе (или в слабо загруженном OLTP-приложении) лучше построить оба этих индекса, в то время как при интенсивном обновлении таблицы T3, возможно, от одного из них придется отказаться. Сервер может сам выдать рекомендации по построению индексов - для этого в него включен Index Tuning Wizard, доступный через Query Analyzer. Он анализирует запрос (или поток команд, собранный при помощи SQL Trace) и выдает рекомендации по структуре индексов в конкретной базе данных.
В процессе работы с Microsoft SQL Server в оптимизаторе запросов автором были обнаружены два "тонких" места , которые рекомендуется учитывать.
- Алгоритм выбора способа объединения таблиц не всегда выдает оптимальный результат. Это обычно бывает связано с невозможностью определить точное количество записей, участвующих в объединении на момент генерации плана запроса.
DECLARE @I INTEGER SET @I = 10 SELECT * FROM History H INNER JOIN Objects O ON O.Id = H.ObjectId WHERE H.StatusId = @I
Сервер сгенерировал следующий план исполнения:
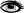
Внимание: в качестве параметра выступает переменная, при этом сервер не может точно оценить, в какой диапазон статистики она попадет. В этом случае он делает предположение, что количество записей, полученных из History, будет равно средней селективности по используемому полю, помноженной на количество записей в таблице (в данном случае - 10 151). Исходя из этого выбирается алгоритм слияния HASH JOIN, требующий значительных накладных расходов на построение хэш-таблицы. В случае если реальное количество записей ощутимо меньше (реально этот запрос выбирает 100-200 записей, имеющих соответствующий StatusId за последний день), алгоритм LOOP JOIN дает во много раз большую производительность. Итак, если вы точно знаете, что фильтрация по конкретному полю даст ограниченный набор данных (не более нескольких сотен записей), а сервер об этом "не догадывается", - укажите ему алгоритм слияния явно.
SELECT * FROM History H INNER LOOP JOIN Objects O ON O.Id = H.ObjectId WHERE H.StatusId = @I
Делать это надо, только если вы уверены, что этот запрос будет выполняться со значениями параметра, имеющими высокую селективность. На больших наборах данных выполнение LOOP JOIN будет гораздо медленнее.
- Цена операции Bookmark Lookup (извлечение данных из таблицы по известным значениям индекса) явно завышена. Поэтому иногда, даже при наличии подходящего индекса, вместо INDEX SCAN (поиск по индексу) с последующим Bookmark Lookup (выборка из таблицы) сервер принимает решение о полном сканировании таблицы (TABLE SCAN или CLUSTERED INDEX SCAN). Пример такого запроса приведен на рисунке. Обратите внимание на предполагаемую стоимость запроса (Estimated subtree cost) для случая, когда для таблицы явно задан поиск по индексу: она чрезвычайно завышена. Видно, что 100% расчетной стоимости выполнения дает операция Bookmark Lookup. Реально же этот запрос быстрее выполняется при индексном доступе, чем при сканировании таблицы. В этом случае рекомендуется попробовать явно указать индекс для доступа к таблице.

Однако необходимо предостеречь пользователей от слишком частого использования подсказок оптимизатору. Их можно использовать, только если вы уверены, что этот запрос будет выполняться в конкретных условиях и вам лучше, чем оптимизатору, известно распределение данных в таблице. В большинстве случаев оптимизатор запросов сам хорошо планирует его выполнение. Предпочтительным способом оптимизации представляется грамотное планирование структуры индексов.
Другие особенности Microsoft SQL Server
Получение уникальных идентификаторов
Сервер имеет средства для автоматической генерации уникальных идентификаторов, которые могут использоваться в качестве первичного ключа. Такими идентификаторами могут служить целые числа либо новый тип данных UNIQUEIDENTIFIER.
Для получения целочисленного уникального идентификатора записи в Microsoft SQL используется ключевое слово IDENTITY [(seed, increment)].
Здесь:
seed - начальное значение
increment - приращение
По умолчанию seed и increment равны 1.
Чтобы создать в таблице автоинкрементный столбец, необходимо записать:
CREATE TABLE TableName ( Id INTEGER NOT NULL IDENTITY )
Иметь атрибут IDENTITY в таблице может только одна из колонок: TINYINT, SMALLINT, INT или DECIMAL(p,0). После этого при вставке новых записей поле Id будет получать новое значение счетчика. Если таблица имеет поле с установленным IDENTITY, то к этому полю можно обратиться при помощи ключевого слова IDENTITYCOL. Например, запрос
SELECT IDENTITYCOL FROM TableName
эквивалентен
SELECT Id FROM TableName
если поле Id создано с атрибутом IDENTITY.
Значение последнего поля с IDENTITY, вставленного текущей сессией, можно получить функцией @@IDENTITY. Например, следующий скрипт добавляет записи в главную и дочернюю таблицы:
DECLARE @IdentityValue INTEGER INSERT MainTable (Name) VALUES (‘Петров’) SELECT @IdentityValue = @@IDENTITY INSERT ChildTable (MainId, Data) VALUES (@IdentityValue, ‘Первая’) INSERT ChildTable (MainId, Data) VALUES (@IdentityValue, ‘Вторая’)
Следует обратить внимание, что если значение ключевого поля нужно для нескольких вставок, то его необходимо сохранить в переменной; в противном случае при наличии у таблицы ChildTable своего поля с IDENTITY после первой вставки в нее @@IDENTITY вернет уже значение для ChildTable.
Использование вышеописанной техники требует соблюдения осторожности при написании триггеров. Если триггер на MainTable сам производит вставку в какие-то таблицы с IDENTITY, то после
INSERT MainTable (Name) VALUES (‘Петров’)
функция @@IDENTITY уже не вернет значения для MainTable.
В версии Microsoft SQL Server 2000 появилась функция SCOPE_IDENTITY(),аналогичная @@IDENTITY, однако возвращающая значение, вставленное в текущем контексте (триггере, хранимой процедуре, пакете команд). Например, в предыдущем примере SCOPE_IDENTITY() вернет значение, вставленное в MainTable, независимо от операций в триггере, поскольку они выполняются уже не в текущем контексте.
Значения seed и increment можно использовать, например, для предоставления диапазонов значений первичного ключа в распределенной базе данных. Например, один филиал может генерировать значения, начиная с 1, другой - с 1 000 000 и т.д.
По умолчанию в поле с IDENTITY не может быть вставлено явное значение. Однако Microsoft SQL Server позволяет разрешить такую вставку путем установки
SET IDENTITY_INSERT [database.[owner.]]{table} {ON/OFF}
Вставка может быть разрешена только для одной таблицы в сессии. Если в таблицу вставляется число, большее максимального значения, сервер использует это число как основу для генерации последующих значений IDENTITY.
Другим способом генерации уникальных идентификаторов, появившемся в Microsoft SQL 7.0, является тип данных UNIQUEIDENTIFIER. Физически это 16-байтовое число. Этот тип аналогичен GUID (Global Unique Identifier), активно использующемуся в технологии COM. Над этим типом данных определены только операции =, <>, IS NULL и IS NOT NULL. Сравнение >, < или т.п. не допускается. Для генерации значений используется функция NEWID()
CREATE TABLE MyUniqueTable (
UniqueColumn UNIQUEIDENTIFIER DEFAULT NEWID(),
Characters VARCHAR(10)
)
GO
INSERT INTO MyUniqueTable(Characters) VALUES ('abc')
INSERT INTO MyUniqueTable VALUES (NEWID(), 'def')
Приведенные операторы вставки эквивалентны, и оба создают записи с уникальными значениями UniqueColumn. Аналогично, значение может быть предоставлено клиентским приложением посредством функции CoCreateGUID при помощи свойства AsGUID классов TField и TParam, без опасения, что оно окажется неуникальным.
Временные таблицы
Для промежуточной обработки данных клиентское приложение может создавать временные таблицы. Временной называется таблица, имя которой начинается с # или ##. Таблица, имя которой начинается с #, является локальной и видима только той сессии, в которой она была создана. После завершения сеанса временные таблицы, созданные им, автоматически удаляются. Если временная таблица создана внутри хранимой процедуры, она автоматически удаляется по завершении процедуры. Если имя таблицы начинается с ##, то она является глобальной и видима всеми сессиями. Таблица удаляется автоматически, когда завершается последняя из использовавших ее сессий.
Для примера рассмотрим хранимую процедуру, которая выдает значения продаж по месяцам. Если в данном месяце продаж не было, выводится имя месяца и NULL.
CREATE PROCEDURE AmountsByMonths AS BEGIN DECLARE @I INTEGER CREATE TABLE #Months ( Id INTEGER, Name CHAR(20) ) SET @I = 1 WHILE (@I <= 12) BEGIN INSERT Months (Id, Name) VALUES (@I, DATENAME(month, '1998' + REPLACE(STR(@I,2),' ','0')+'01')) SET @I = @I + 1 END SELECT M.Name, SUM(P.Amount) FROM #Months M INNER JOIN Payment P ON M.Id = DATEPART(month, P.Date) DROP TABLE #Months END
В версии Microsoft SQL 2000 появилась возможность создавать переменные типа table, представляющие собой таблицу. Работа с такой переменной может выглядеть следующим образом:
DECLARE @T TABLE (Id INT) INSERT @T (Id) VALUES (10250) INSERT @T (Id) VALUES (10257) INSERT @T (Id) VALUES (10259) SELECT O.* FROM Orders O INNER JOIN @T AS T ON O.OrderId = T.Id
Переменные типа table более предпочтительны для использования, чем временные таблицы, поскольку последние приводят к невозможности кэширования плана запроса (он генерируется при каждом выполнении), а в случае использования переменных этого не происходит.
Создание хранимых процедур и триггеров
Если логика работы процедуры или триггера требует установки каких-либо SET-параметров в определенные значения, процедура или триггер могут установить их внутри своего кода. По завершении их выполнения будут восстановлены исходные параметры, которые были на сервере до запуска процедуры или оператора, вызвавшего срабатывание триггера. Исключением являются SET QUOTED_IDENTIFIER и SET ANSI_NULLS для хранимых процедур. Сервер запоминает их на момент создания процедуры и автоматически восстанавливает при исполнении.
Microsoft SQL Server использует отложенное разрешение имен объектов и позволяет создавать процедуры и триггеры, ссылающиеся на объекты, не существующие при их создании.
Кластерные индексы
Microsoft SQL Server позволяет иметь в таблице один кластерный (CLUSTERED) индекс. Данные в таблице физически расположены на нижнем уровне B-дерева этого индекса, поэтому доступ по нему является самым быстрым. По умолчанию такой индекс автоматически создается по полю, объявленному первичным ключом. Все остальные индексы в качестве ссылки на запись хранят значение кластерного индекса этой записи, поэтому не рекомендуется строить его по полям большого размера. Кроме того, для оптимизации операции вставки записей рекомендуется строить этот индекс по полю с монотонно возрастающими значениями. Исходя из этих рекомендаций лучший кандидат на построение кластерного индекса - поле INTEGER (минимальный размер), IDENTITY (возрастание), объявленное как первичный ключ (заведомо уникальное, частый доступ по этому индексу).
Определяемые пользователем функции
В версии MicrosoftSQL 2000 предусмотрена возможность создавать функции в базе данных. Функции могут быть трех типов:
- Скалярные функции - возвращают скалярную величину. Они аналогичны функциям в любом языке программирования
CREATE FUNCTION FirstWord (@S VARCHAR(255)) RETURNS VARCHAR(255)
AS BEGIN DECLARE @I INT SET @I = CHARINDEX(' ', @S) RETURN CASE @I WHEN 0 THEN @S ELSE LEFT(@S, @I-1) END END GO SELECT dbo.FirstWord ('Hello world !') - Inline-табличные функции - состоят из одного оператора SELECT и возвращают его результат в виде таблицы
CREATE FUNCTION OrdersByCustomer (@S VARCHAR(255)) RETURNS TABLE AS RETURN SELECT * FROM Orders WHERE CustomerId = @S GO SELECT * FROM OrdersByCustomer('VINET') AS T INNER JOIN [Order Details] OD ON OD.OrderId = T.OrderId - Многооператорные табличные функции. Эти функции наиболее интересны, поскольку позволяют динамически сформировать таблицу с требуемыми данными, которую затем можно использовать в запросе.
В качестве примера рассмотрим функцию, генерирующую таблицу, которая содержит номера и названия месяцев года. Параметр позволяет сгенерировать эту таблицу за один квартал.
CREATE FUNCTION Months (@Quoter INT) RETURNS @table_var TABLE (Id int, Name VARCHAR(20)) AS BEGIN DECLARE @Start INTEGER, @End INTEGER SET @Start = CASE WHEN @Quoter = 2 THEN 4 WHEN @Quoter = 3 THEN 7 WHEN @Quoter = 4 THEN 10 ELSE 1 END SET @End = CASE WHEN @Quoter = 1 THEN 3 WHEN @Quoter = 2 THEN 6 WHEN @Quoter = 3 THEN 9 ELSE 12 END WHILE (@Start <= @End) BEGIN INSERT @table_var (Id, Name) VALUES (@Start, DATENAME(month, '1998' + REPLACE(STR(@Start,2),' ','0')+'01')) SET @Start = @Start + 1 END RETURN END GO
SELECT T.Name, SUM(O.Freight) FROM dbo.Months(NULL) AS T INNER JOIN Orders O ON DATEPART(month, O.OrderDate) = T.Id GROUP BY T.Name
При помощи подобных функций можно также легко раскрывать иерархии и выполнять прочие задачи, которые в предыдущих версиях сервера требовали временных таблиц.
Советы по работе с Microsoft SQL Server
- Устанавливайте SET NOCOUNT ON. При установке OFF после каждого оператора сервер посылает клиенту сообщение DONE_IN_PROC с количеством обработанных записей. Запретив это, вы кардинально сократите сетевой трафик и существенно увеличите производительность.
- При необходимости изменить режим блокирования какой-либо таблицы без изменения уровня изоляции транзакций используйте подсказки режима блокирования. Так, в приведенном ниже примере оператор SELECT накладывает блокировку на запись, предотвращая изменение ее другими сессиями до окончания транзакции, несмотря на то что установленный уровень изоляции не предусматривает этого:
SET TRANSACTION ISOLATION LEVEL READ COMMITED BEGIN TRANSACTION SELECT * FROM City WHERE Name = ‘Ленинград’ WITH (HOLDLOCK) -- Какие-то операторы, во время их выполнения -- запись остается заблокированной UPDATE City SET Name = ‘Санкт-Петербург’ WHERE Name = ‘Ленинград’ COMMIT
- Явно указывайте параметры в запросах. Это поможет серверу более эффективно кэшировать планы выполнения. При динамическом формировании текста запроса не подставляйте параметры в текст, а используйте хранимую процедуру sp_executesql.
- Не начинайте названия своих хранимых процедур с префикса "sp_". Сервер ищет процедуры с такими именами в первую очередь в базе данных Master, а затем уже в текущей базе данных. Это приводит к дополнительным накладным расходам.
- Если ваше приложение интенсивно использует базу данных tempdb (например, создает много временных таблиц), увеличьте ее минимальный размер. В противном случае при старте сервера создается tempdb малого размера, которая затем динамически расширяется, непроизводительно загружая компьютер.
КомпьютерПресс 6'2001