
Я мирно сидел на семинаре, слушал доклад студента о статье с прошлого CVPR и параллельно гуглил тему.
- К достоинствам статьи можно отнести наличие исходного кода….
Пришлось вмешаться:
- Наличие чего, простите?
- Э-э-э… Исходного кода…
- Вы его смотрели?
- Нет, но в статье указано… (мать-мать-мать… привычно отозвалось эхо)
ㅡ Вы ходили по ссылке?
В статье, действительно, предельно обнадеживающе написано: "The code and model are publicly available on the project page …/github.io/...", - однако в коммите двухлетней давности по ссылке значится вдохновляющее "Код и модель скоро выложим":
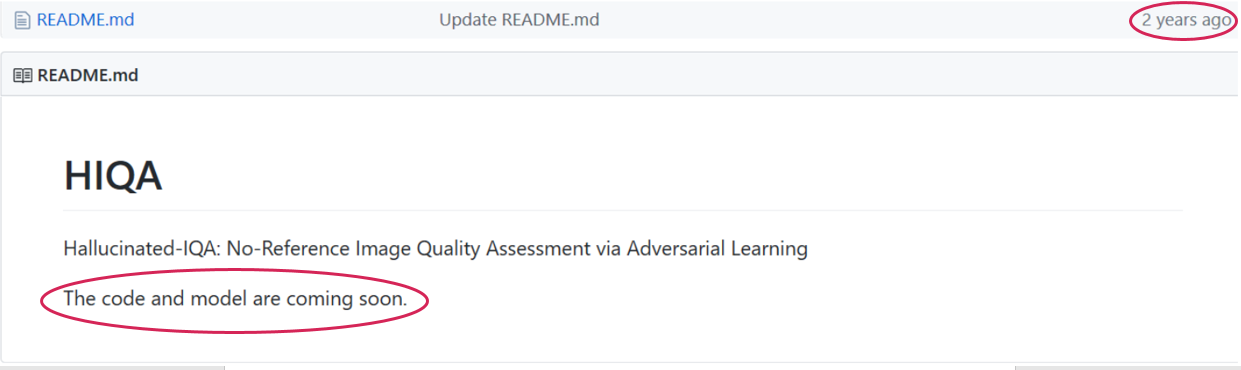
Ищите и обрящете, стучите и откроется… Может быть… А может быть и нет. Я бы, исходя из печального опыта, ставил на второе, поскольку ситуация в последнее время повторяется ну уж о-о-очень часто. Даже на CVPR. И это только часть проблемы! Исходники могут быть доступны, но, к примеру, только модель, без скриптов обучения. А могут быть и скрипты обучения, но за несколько месяцев с письмами к авторам не получается получить такой же результат. Или за год на другом датасете с регулярными скайп-звонками автору в США не удается воспроизвести его результат, полученный в наиболее известной лаборатории в отрасли по этой теме… Трындец какой-то.
И, судя по всему, мы пока видим лишь цветочки. В ближайшее время ситуация кардинально ухудшится.
Кому интересно, что стало со студентом куда катится научный мир, в том числе по "вине" глубокого обучения, добро пожаловать под кат!
Кризис воспроизводимости
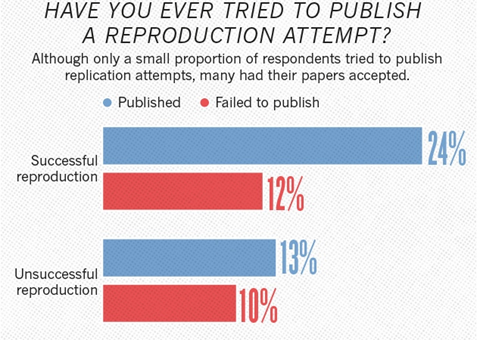
В 2016 году в журнале Nature вышла статья IS THERE A REPRODUCIBILITY CRISIS? (Происходит ли сейчас кризис воспроизводимости)?, в которой привели результаты опроса 1576 исследователей:
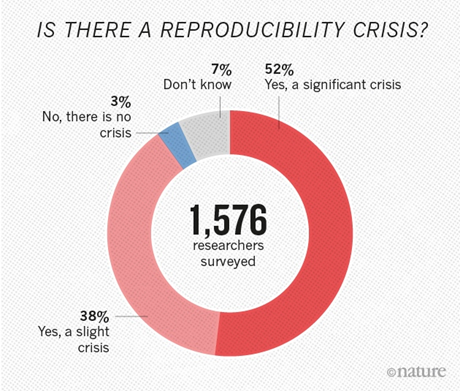
Источник: Этот и следующие графики этого раздела - статья в Nature
По итогам опроса 52% исследователей считают, что имеет место существенный кризис, 38% - легкий кризис (итого 90% суммарно!), 3% - что кризиса нет и 7% - не определились.
Конспирологическая версия автора - учитывая масштабы бедствия, последние просто не хотят привлекать "излишнее" внимание к вопросу:
Если посмотреть по дисциплинам, получается, что на первом месте химия, на втором - биология, на третьем - физика:
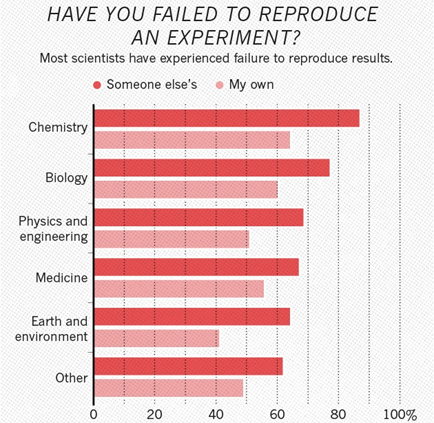
Интересно, что в химии, например, более 60% исследователей сталкивались с невозможностью воспроизвести свое собственное исследование. В физике таких тоже более 50%.
Также очень интересно, что именно с точки зрения исследователей вносит наибольший вклад в кризис невоспроизводимости:
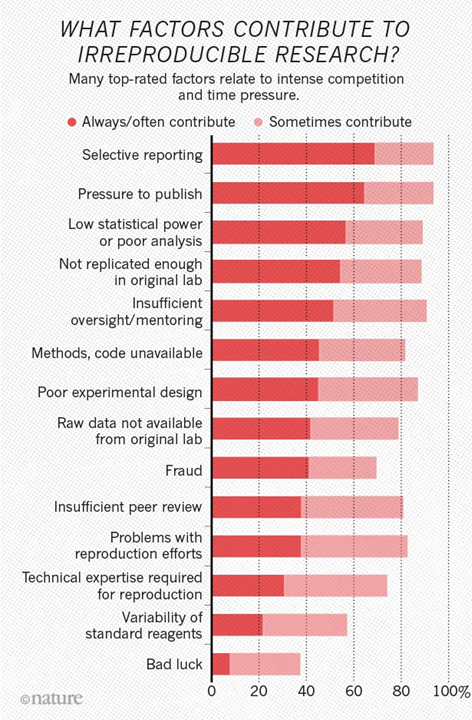
На первом месте идет "Selective reporting". Для Computer Science это ситуация, когда автор, например, выбирает для публикации лучшие примеры, на которых работает алгоритм, и не описывает подробно, где и что не работает.
Интересно, что на втором "Pressure to publish". Это очень хорошо известный принцип "Publish or perish". Статья в англоязычной википедии неплохо описывает проблему. Статьи в русской википедии на эту тему нет, хотя в местах с высокой оплатой за научную работу проблема становится актуальной. Например, в одном топовом вузе с хорошей зарплатой (увы, я не о родном МГУ) для переаттестации критичны высокие публикационные баллы, и, если хочешь продолжать работать - изволь публиковаться. Тушкой, чучелком, как угодно, но чтобы баллы были.
Также обратите внимание, что "недоступность кода" ("Methods, code unavailable") встречается в 45% случаев часто и в 82% - иногда. Ну и непосредственно мошенничество как причину указывают в 40% случаев, т.е. довольно часто. Недавно я общался с китайским профессором, работающим в области алгоритмов сжатия видео. Он говорил, что внутри Китая статей результатов с сознательными подтасовками очень много, они стали просто бичом каким-то. За внешние публикации с мошенничеством там быстро увольняют, поэтому они стараются соответствовать, но внутри творится кошмар (см., например, статью "Publish or perish in China" в Nature). Кошмар, в том числе и по следующей в списке причине "Insufficient peer review" - не хватает сил на качественное кросс-рецензирование.
Отдельная большая проблема, о которой упомяну только вскользь: если результат не получилось воспроизвести, то статью об этом почти невозможно опубликовать…
Всех интересуют новые достижения, новый вклад и новые идеи, а что там старое не работает - какая разница. Это естественным образом увеличивает долю невоспроизводимых результатов, в том числе сознательное мошенничество. Разбираться, скорее всего, никто не будет - не принято. Очевидно, что когда на одном фейковом результате начинают базироваться другие, то вся система становится неустойчивой, что в итоге бьет по всем:
Ваши ставки - успеет увернуться или его придавит?
Итого:
Воспроизводимость в Computer Science
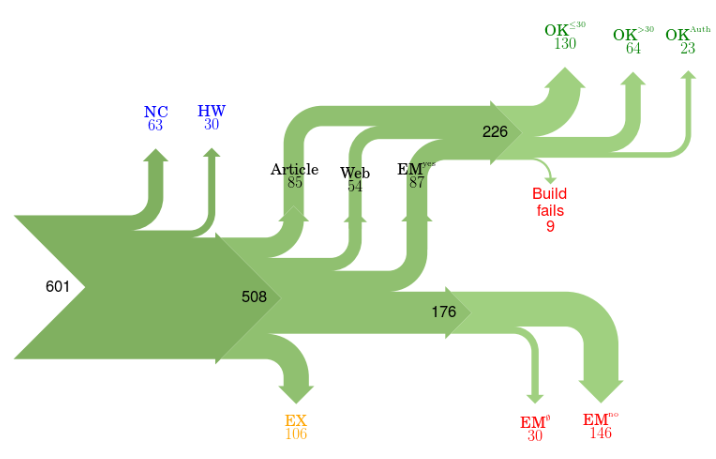
В Arizona State University (который по количеству студентов, к слову, в 2 раза больше МГУ) на программистском факультете сделали специальный сайт http://repeatability.cs.arizona.edu/, посвященный проведенному у них исследованию воспроизводимости результатов в 601 статье из журналов и конференций ACM. Получилась такая картина:

Источник: Repeatability in Computer Science
106 статей они не проверили, поскольку не хотели нарушать чистоту эксперимента (они писали авторам и запрашивали код), в оставшихся:
- в 93 статьях (19%) нет кода, либо было железо, с которым они не могли сравниться,
- в 176 статьях (35%) авторы не предоставили код,
- в 226 статьях (46%) код был, в 9 (2%) его не удалось собрать, а у 87 статей (18%) на сборку ушло больше получаса.
Должен сказать, что по нашему опыту после сборки самое интересное только-только начинается, но в исследовании они на этом этапе решили остановиться, и при таком количестве их можно понять. В любом случае, статистика очень показательная, и 35% отказов предоставить код довольно близки со строкой "Methods, code unavailable" предыдущего исследования (третий график).
Вообще, тема прокопана довольно хорошо. В частности, "Золотым стандартом" считается доступность кода и данных, на которых легко полностью повторить результат, а самым плохим подходом считается представление только статьи:

Источник: Conceptualizing, Measuring, and Studying Reproducibility
Почему же так происходит?
Причин, как у любого сложного явления, несколько:
- На западе сильно влияет упоминавшийся "Publish or perish". На семинарах и воркшопах молодых зеленых аспирантов совершенно серьезно и недвусмысленно ориентируют - "Пришла идея, первым делом опубликуй ее! И только потом проверяй!" (Кто сказал дикость? Суровая реальность, господа!) Приоритет в науке реально важен (в том числе для пресловутого цитирования), поэтому, когда приходит какая-то интересная идея - ее сначала публикуют (иногда с фейковыми данными, иногда нет) и только потом начинают что-то там долго мучительно программировать, зачастую натягивая сову на глобус. Статья, приведенная в качестве первого примера в начале этого текста, похоже, как раз из таких (галлюциногенные нейросети… интересно, что они курили? Но на CVPR зашло!). В итоге получается страдающий избыточным весом белый пушной зверек, поскольку ситуация продолжает ухудшаться:
- Условно, половину денег на исследования дает государство (где-то больше, где-то меньше). И государственные деньги провоцируют публикационное безумие (когда публикуются, лишь бы опубликовать). Другую половину денег дают компании и компании явно проговаривают ограничения на публикации. Особенно известна была своими
негритянскимиусловиями для институтов и университетов одна популярная корейская компания, которая предлагала российским ученым работать, по меткому выражению коллеги, "за бусы". Да, сейчас они в области нейросетей даже рынок поломали в гонке зарплат, но вообще предложение первым делом ужасного договора - фирменный стиль таких азиатских компаний. И когда отлично написанную статью не разрешают опубликовать, а потом еще одну, и еще - это сильно демотивирует, конечно. Такое даже через несколько лет не забывается.
В итоге результат идет в патенты при минимуме статей. Интересно, что я общался с коллегами из Финляндии, США, Франции и т.д. Там многие плотно сидят на грантах, но те, у кого много компаний, тоже публикуют далеко не все результаты, а если и публикуют, то так или иначе сокращают (культурно выражаясь) описание подхода, закономерно усложняя воспроизведение. За это уже уплачено.
Итого:
- Даже после настоятельных просьб код присылают максимум в 46% случаев (кстати, почитайте исследование, там интересны примеры "отмазок", по нашему опыту ровно такие в основном и присылают).
- Сама система финансирования науки либо мотивирует публиковать непроверенные результаты как можно быстрее, либо ограничивает публикации, в том числе в плане полного раскрытия. И в том, и в другом случае воспроизводимость падает.
Почему машинное обучение резко ухудшает ситуацию
Но и это не все! В последнее время стремительно распространяется машинное обучение вообще и нейросети в частности. Это круто. Оно обалденно работает. Совершенно невозможное вчера становится возможным уже сегодня! Просто праздник какой-то! Так?
Нет. Нейросети добавили Computer Science новый виток погружения в пучину невоспроизводимости.
Вот простой пример, так выглядит функция потерь для ResNet-56 без skip connections (визуализация пары параметров из нескольких десятков миллионов). Наша задача за разумное число итераций (эпох) найти самую глубокую точку:
Источник: Visualizing the Loss Landscape of Neural Nets
Хорошо видно море локальных минимумов, в которые радостно "проваливается" наш градиентный спуск и "не может" оттуда выбраться. Да, понятно, что именно для ResNet этот пример используют как великолепную иллюстрацию, что дают skip connections (после введения которых обучаемость сети кардинально улучшается):
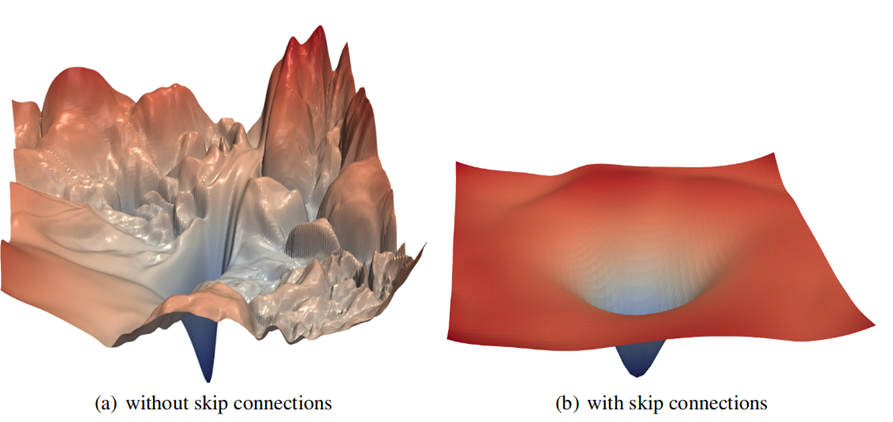
Ибо одно дело - пытаться в сложном ландшафте нащупать минимум (и помогает только запредельная общая размерность пространства поиска), и совсем другое дело - явный относительно легко находимый градиентами глобальный минимум.
История красивая, но в нашей суровой реальности с большим количеством слоев снова и снова приходится сталкиваться с тем, что сеть не обучается. Вообще.
И даже интереснее - в какой-то момент ее удается обучить (ошибка резко падает), но через какое-то время при попытке с нуля воспроизвести результат (например, при потере данных коэффициентов) повторить фокус не удается, и идет явное мучительное путешествие сети вдалеке от минимума. Сотни эпох сменяют друг друга, а воз остается на месте. Не выходит Каменный Цветок у Данилы-мастера.
Раньше представить себе ситуацию, что у исследователя не получится воспроизвести собственные результаты в Computer Science, было довольно сложно. Сегодня это стало обыденным, как уже давно в физике, химии, биологии и далее по списку. С нейросетями Computer Science внезапно стала экспериментальной наукой! Welcome to this wonderful world. Теперь вы все чаще будете сталкиваться с невозможностью воспроизвести свой собственный результат (как и 64% химиков, 60% биологов, см. второй график этой статьи).
Но и это не все радости. Дальше будет веселее!
Вообще, я довольно долго с изрядным скепсисом относился к нейросетям, поскольку алгоритмы на их основе не работали. Ну как… Они как-то работали, конечно, но проигрывали на больших выборках "классическим" state-of-the-art алгоритмам (что не мешало их массово публиковать). Происходило это потому, что нейросети крайне удобны для разного рода махинаций. Главное - достаточно грамотно подобрать обучающую выборку под примеры и можно натуральным образом демонстрировать чудеса. Получаются красивейшие картинки (а иногда и красивейшие графики), и статья отлично заходит. Можно даже код выложить (это вроде модно стало), сути это не меняет. Оно не работает. Но когда сзади маячит большой красный PoP-петух с огромным острым клювом… статья фигак-фигак и уходит в печать.
Отдельная крупная проблема - области, где нет больших обучающих выборок. Коллеги из медицины жалуются - полный кошмар творится. Они наборы данных собирали годами. И там даже десятки тысяч примеров. Но приходят аспиранты с глубокими нейросетями. Фигак-фигак и всех обогнали… Красавцы! Гиганты науки! И с довольными светлыми ликами докладывают результаты. У них спрашивают:
- А что вы сделали, чтобы не было overfitting?
- Чего, простите?
- Почему у вас нет переобучения?
И человек абсолютно серьезно рассказывает, как он правильную сеть взял и строго по методичке ее обучил, и поэтому у него все хорошо. Т.е. молодые люди (массово!) вообще не понимают, что такое переобучение! Не один, не два, а прямо уже заметная доля аспирантских докладов. Вот она, новая волна молодых нейросетевых революционеров. Вспоминаем профессора Преображенского, тяжело вздыхаем о традиционной для молодых революционеров неграмотности. Делаем выводы.
Но это ладно. На недавнем ИТиС-2019 Михаил Беляев приводил чудные примеры, как этот подход вполне себе добирается и до медицинского продакшена! В реальные компании, предлагающие анализ с использованием нейросетей, сдали контрольные анализы и получили неожиданно печальный результат. Причина в том, что инвесторы тоже почуяли революцию, и если человек обещает новые горизонты на основе нейросетей, то они дают ему денег (проницательный Анатолий Левенчук предупреждал об этом еще в 2015 году, через полгода после изобретения батчнорма, и за полгода до ResNet, когда много слоев еще плохо обучались). А платить за это вам, дорогие господа! И, да, было бы лучше сначала поэкспериментировать на мышках, но у мышек, как выразился один знакомый циник, нет кошельков! Поэтому данные для обучения сейчас собирают (культурно выражаясь) на деньги потребителей, т.е. на ваши деньги. Люди, будьте бдительны!
Понятно, что не нейросети виноваты. Большой вопрос в том, как получить достаточное количество смежных данных, зафайнтюнить их на имеющейся небольшой выборке, избежать catastrophic forgetting и вот это вот все. Но, даже если у вас грамотные исследователи, - потребуется время. А инвестор хочет результат здесь и вчера . Так что, радовались волне успехов нейросетей?
Получаем большую пену большой волны , когда неработающие по факту методы дотащило прибоем крупных волн до реального применения. Оплатите счет, пожалуйста!
Итого: Нейросети ухудшают ситуацию в Computer Science по трем направлениям:
- С обучением нейросетей CS более прежнего становится экспериментальной наукой со всеми вытекающими минусами.
- Подгонка обучающей выборки под тестовую позволяет продемонстрировать любой сколь угодно чудесный результат (усугубление главной причины невоспроизводимости - selective reporting).
- И, наконец, в областях, где обучающие выборки малы, крайне сложно избежать переобучения, отлавливать и работать с которым сегодня многие не умеют (формально на датасете результат великолепен, но фактически алгоритм не работает).
Что можно сделать?
Если вы (счастливый человек!) работаете в хорошо прокопанных областях, то часто вообще вся работа - готовить датасеты да скармливать их сетям. Разве что стоит за архитектурами следить. В этом случае вообще пропадает смысл смотреть статьи без кода. И это настоящий праздник! Почувствуйте свое счастье, не всем так повезло!
Есть даже такой сайт PapersWithCode.com, который в области машинного обучения целенаправленно собирает статьи, автоматически парсит рейтинг их репозиториев с GitHub, приводит все по категориям и добавляет бенчмарки и датасеты. В общем - все для людей! К слову, по их подсчетам сейчас код доступен только для 17-19% статей:
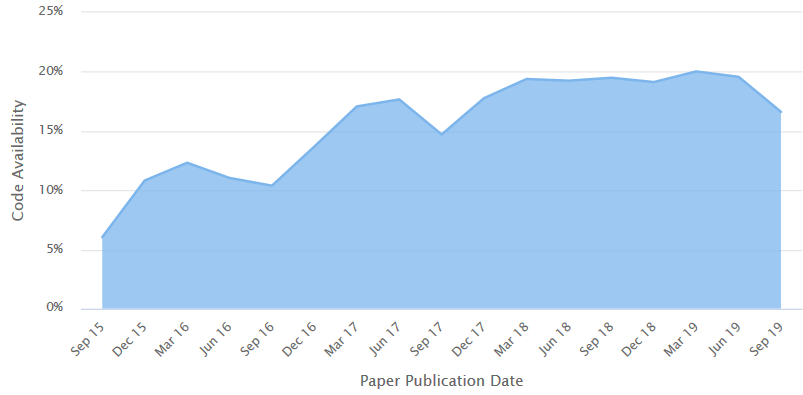
Источник: Percentage of published papers that have at least one code implementation
У них же, если отвлечься на секунду (и еще прорекламировать этих правильных ребят), есть весьма любопытный график изменения популярности ML/DL фреймворков за последние 4 года:
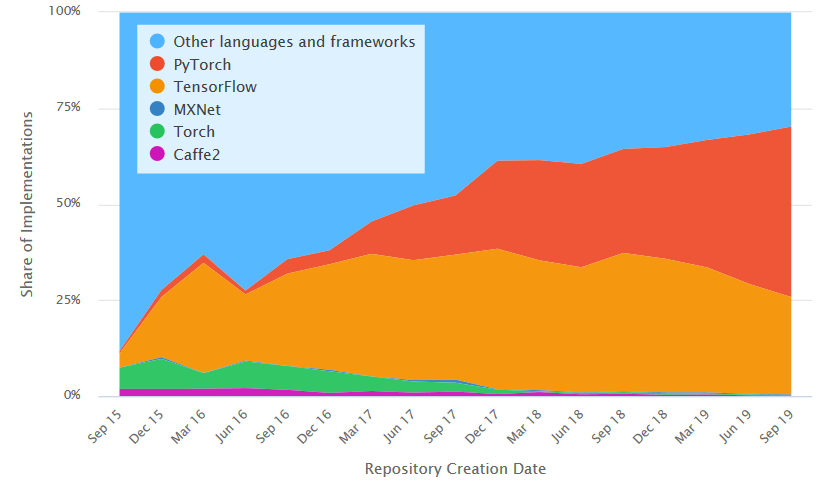
Источник: Paper Implementations grouped by framework
Торч на коне, TF (кто бы мог подумать еще недавно!) сдает позиции. Впрочем, это другая история…
Из опыта понятно, что у этих 17-20% статей с кодом тоже (по описанным причинам) не все волшебно, но, по крайней мере, проверить их работу можно на порядок быстрее. И это - классно.
Другой реально работающий рецепт - это создание достаточно крупных датасетов и бенчмарков. Взлет нейросетей не зря начался с ImageNet с 14 миллионами изображений, разбитых на 20000+ классов. Да, это сложно, но с глубоким обучением можно работать только с действительно большими наборами. Даже если их создание идет мучительно и трудно.
Например, какое-то время назад мы создали бенчмарк для выделения полупрозрачных объектов в видео (шерсть, волосы, ткани, дым и прочие нетривиальные радости жизни). Изначально планировалось уложиться при его создании в 3 месяца. Были найдены сервоприводы, экран, хорошая камера, куплена синяя изолента, у всех знакомых девушек был реквизирован миллион мягких игрушек, найден манекен с реальными волосами, на котором тренируются в укладке волос парикмахеры. И…

Источник: материалы автора… Синяя изолента, как хорошо видно, выполняет ключевую несущую роль
Все (нет, не так… ВСЕ!) шло не так. Вибрации пола от проходившего мимо человека хватало, чтобы волосы смещались (прогоны записи были перенесены на ночь), волосы колыхало потоками воздуха (был сооружен короб), в коробе сервоприводы начали перегреваться (пришлось модифицировать программу и при достижении определенной температуры ждать, пока они остынут). И т.д. и т.п. В итоге отличный датасет был построен через год с лишним (его создание достойно отдельной эпичной саги), а технологию его производства мы уже продали дороже, чем сделанные с его помощью алгоритмы. В чудном новом мире рулят данные, господа! И внезапно выясняется, что нужны человеко-годы квалифицированного труда, чтобы данные были хорошие, чистые и пригодные для обучения.
Базовый тренд на сегодня - создание датасетов внутри компаний. Ценность данных осознана, и в их подготовку вкладываются значительные средства. К счастью, многие компании понимают, что в одиночку со сложными задачами не справиться, и финансируют создание открытых датасетов (см. например, поисковик по 25 тысячам датасетов на Kaggle).
Итого:
- Если есть такая возможность - смотрите только статьи с кодом.
- Помните, что многие алгоритмы на глубоких нейросетях рулят в публикациях только потому, что пока не открыты в широкий доступ или не созданы действительно большие датасеты.
- Если начальство душит жаба открывать датасеты - можно финансировать бенчмарки, вы всегда будете в курсе лучших алгоритмов в своей области. Причем лучше делать бенчмарк в кооперации с университетами (или развить имеющийся), чтобы ваш бенчмарк не висел пустой.
Выводы и прогнозы
Из текста выше могло показаться, что автор считает, что все плохо, все пропало и вообще… Это не так. Хотя бы потому, что большое количество невоспроизводимых работ вокруг формирует устойчивый спрос на работы автора и его коллег, и ухудшение ситуации означает, что
Кроме того, надо четко понимать, что ситуация с невоспроизводимостью в точных науках не идет ни в какое сравнение с масштабами бедствия в гуманитарных. В статье Википедии Replication crisis (русской версии у нее, увы, опять нет) основное внимание уделено как раз гуманитарным дисциплинам, в первую очередь - психологии, ситуация в которой печальна уже давно:
Источник: The Reproducibility Crisis in Psychological Science: One Year Later, к слову, там приведены великолепные примеры, как некорректно используется, например, условная вероятность… увы, в Computer Science подобное тоже встречается...
Короче! Когда придется через 20 лет заниматься психологией андроидов, и теплая ламповая математическая Computer Science станет не только экспериментальной, но и в изрядной степени гуманитарной (разница в подходах воспитания домашних и промышленных роботов и все такое), вот тогда-то настоящие проблемы с воспроизводимостью и начнутся. А пока - можно и нужно радоваться текущему положению дел, не идеализируя его и ясно видя негативные тренды.
И последнее. Я обещал сказать, что стало со студентом. Он был жестоко наказан тем, что готовил материалы и картинки для этой статьи. Дабы неповадно было!
Всем побольше воспроизводимых исследований на вашем пути!
Читайте также:
- Наш прогноз развития аппаратных акселераторов нейросетей в ближайшие годы и
- Недавнюю отличную статью аспиранта-физика про проблемы Publish or Perish в науке на личном опыте человека
Благодарности
В заставке использованы рисунки с семинара The replication crisis и из статьи Science for Sale: The Other Problem With Corporate Money.
Кроме того, хотелось бы сердечно поблагодарить:
- Лабораторию Компьютерной Графики и Мультимедиа ВМК МГУ им. М.В.Ломоносова за вклад в развитие глубокого обучения в России и не только,
- наших коллег, Михаила Ерофеева, Алексея Федорова, Михаила Беляева и Галину Ивановну Рожкову, чьи примеры использованы выше,
- персонально Константина Кожемякова и Дмитрия Коновальчука, которые сделали очень много для того, чтобы эта статья стала лучше и нагляднее,
- и, наконец, огромное спасибо Кириллу Малышеву, Дмитрию Клепикову, Егору Склярову, Николаю Оплачко, Ивану Молодецких, Андрею Москаленко, Евгению Ляпустину, Александру Яковенко и Айдару Хатиуллину за большое количество дельных замечаний и правок, сделавших этот текст намного лучше!