CАНДЕР ХУГЕНДОРН (НИДЕРЛАНДЫ)
Ментор, тренер, архитектор программного обеспечения, программист, оратор и писатель.
Сандер работает в сфере разработки программного обеспечения более 30 лет, свою первую коммерческую программу написал в 18 лет на Паскале.
Сотрудничает с крупными консультационными IT-компаниями в течение 20 лет. В настоящее время работает в Capgemini. Многочисленные клиенты из разных стран высоко ценят его как "активатора" инноваций в разработке программного обеспечения.
Автор всемирно известной книги-бестселлера "Это Agile", а также многих книг по UML и Agile. В данный момент работает над двумя новыми книгами по архитектуре программного обеспечения, шаблонам и коду и по анти-шаблонам Agile.
Сандер является членом Консультативного совета Microsoft по Visual Studio; членом консультативного совета @Portunity (поставщика MDA), редакционных коллегий журналов Software Release Magazine и Tijdschrift voor IT Management, а также экспертом по разработке в журнале Computable magazine. Информация о тренинге Сандера в Москве.
Микросервисы. Хорошие, плохие, злые
В 1988 г., когда я впервые начал работать в компании по созданию программного обеспечения, мир был достаточно прост. Среда разработки у нас была текстовая, база данных - интегрированная и просматриваемая курсорами, и мы создали совершенно новую административную систему, охватывающую все, что только можно. Нам понадобилось пять лет, чтобы завершить проект, в основном потому, что клиент периодически менял свое мнение и каждое изменение могло нарушить код в каком-либо другом месте системы. Модульное тестирование еще не изобрели, и тестирование проводилось конечными пользователями. В производстве.
Хватит пока о монолитах. В 1994 г. я присоединился к компании, которая разрабатывала настольные приложения - всемирной паутине было всего несколько лет, и веб-приложения еще не изобрели. Мы использовали замечательный инструмент под названием PowerBuilder, и теперь у нас было два компонента, о которых нужно было беспокоиться: настольное приложение и база данных на сервере. Приложения, которые мы создавали, использовались отделами компаний, а иногда даже всей компанией. Они были не очень сложные, но и не очень масштабируемые. Ну что ж, нам было весело, пока парадигма клиент-сервер продолжала существовать.
Компонентно-ориентированная разработка
Мир стал более сложным в середине 90-х гг. Компании жаждали веб-приложений, которые работали бы в Интранете, чтобы избавиться от настольного размещения. И приложения должны были обслуживать несколько отделов, а иногда даже выходить за границы компании. Установилась новая парадигма - компонентно-ориентированная разработка , также известная как CBD. Она обещала нам повторное использование, масштабируемость, гибкость и возможность извлекать код (обычно написанный на COBOL). Мы начали разбивать наши системы на большие функциональные части и очень старались, чтобы эти компоненты начали общаться друг с другом. Была изобретена Java, и все вдруг захотели писать код на Java (очевидно, некоторые хотят и до сих пор). Компоненты работали на невероятных технологиях, таких как серверы приложений и CORBA (посмотрите в Википедии, что это значит, чтобы впечатлить коллег). Старые добрые деньки брокеров объектных запросов !
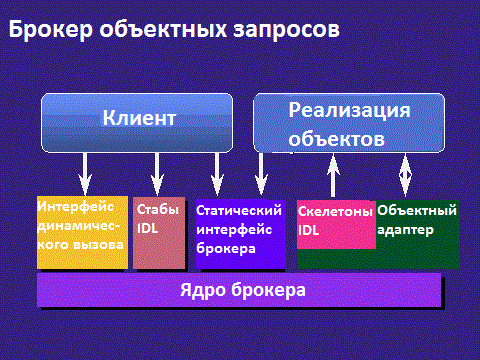
Жуткая штука - архитектура брокера объектных запросов
В то время я работал в большом международном банке, пытаясь создать методологию для компонентно-ориентированной разработки. Даже с хорошо вооруженной командой консультантов Андерсена, нам понадобилось три года, чтобы написать эту чертову штуку. В итоге и парадигма, и технология оказались слишком сложными для написания приличных и хорошо функционирующих программ. Это просто так и не заработало.
Сервис-ориентированная архитектура
В тот момент, в первые годы XXI в., я думал, что мы избавились от распределенной разработки программного обеспечения, и начал создавать веб-приложения. Похоже, все храбро игнорировали первый закон распределения объектов Мартина Фаулера - не распределять объекты. Постепенно мы перешли к следующей парадигме распределенных вычислений, заново упаковав обещания компонентно-ориентированной разработки в обновленный набор технологий. Теперь мы начали проводить моделирование бизнес-процессов (BPM) и реализовывать эти процессы на сервисной шине предприятия (ESB), а компоненты предоставляли сервисы. Мы были в эпохе сервис-ориентированной архитектуры, известной как SOA.
После CBD, SOA казалась легче. До тех пор, пока компоненты - производители - были подключены к сервисной шине предприятия, мы выяснили, как наращивать масштабируемые и гибкие системы. Теперь у нас были гораздо меньшие компоненты, которые мы могли извлекать из существующих систем (написанных не только в COBOL, но и в PowerBuilder, .NET и Java). Необходимые книги по шаблонам разработки были написаны, и мир был готов приступить к делу. В этот раз мы должны справиться!
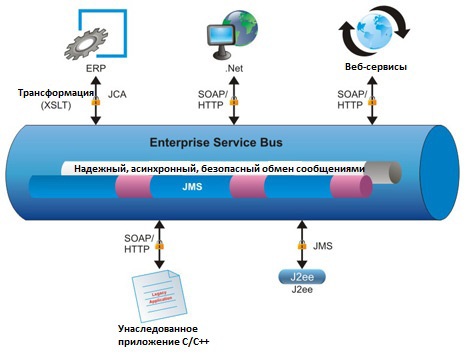
Сервисная шина предприятия (Enterprise Service Bus)
На этот раз я работал в международной транспортной компании, и мы создавали программное обеспечение вокруг промежуточного ПО SAP, поставляя инструменты и для ESB, и для BPM. Теперь нам требовались не только разработчики Java и .NET, у нас также работали и разработчики промежуточного ПО, и консультанты по SAP. И хотя для ускорения разработки и был предложен Agile (знаю, это неверный аргумент), проекты все равно были слишком медленными, более того, когда все части головоломки встали на свое место, мы начали понимать, что интеграционное тестирование и развертывание новых релизов становилось с каждым днем все сложнее.
Наконец: микросервисы!
Надеюсь, вы простите мне столь длинное и запутанное введение в тему микросервисов. Вы можете подумать: "зачем нам очередная статья на тему микросервисов, разве не достаточно уже литературы на эту тему?". В общем, да, достаточно. Но если вы внимательно посмотрите на поток статей, которые можно найти в Интернете, большинство из них описывают лишь преимущества и возможности микросервисов (поют "аллилуйя"), некоторые из них описывают немногие известные примеры новаторов (Netflix, Amazon, и Netflix, и Amazon, и Netflix…). И только несколько статей на самом деле копают немного глубже, да и те, как правило, состоят из суммирования технологий, которые используются при реализации микросервисов. Все только начинается.
И вот тут не повредит небольшой экскурс в историю. Интересно, что выгоды и возможности предшественников микросервисов все еще с нами. Микросервисы, похоже, обещают масштабируемые и гибкие системы, основанные на небольших компонентах, которые могут быть легко развернуты независимо, и тем самым способствуют выбору лучшего варианта технологии для компонента. То есть те же самые обещания, на которые мы купились с CBD и SOA в прошлом. Ничего нового здесь нет, но это не значит, что микросервисы не достойны пристального рассмотрения.
Есть ли разница на этот раз?
Итак, почему же на этот раз все по-другому? Что сделает микросервисы победной парадигмой, если предшественники явно ими не были? Что в них особенного? Как разработчик, я без сомнений в восторге от микросервисов, но я был в восторге (более или менее) и когда появились CBD и SOA.
Различия есть. Впервые у нас есть все необходимые технологии для создания архитектур такого типа. Все затейливое и сложное промежуточное ПО исчезло, и мы полагаемся исключительно на очень простые и давно существующие веб-протоколы и технологии. Просто сравните REST и CORBA. Кроме этого, мы лучше понимаем развертывание, научившись проводить непрерывную интеграцию, модульное тестирование и даже непрерывную поставку. Эти различия показывают, что на этот раз у нас может получиться.
Тем не менее, некоторого скептицизма нельзя избежать. Десять лет назад мы также сильно верили, что сервис-ориентированная архитектура будет технологически возможной, решит все наши проблемы и мы сможем быстро создавать надежные, многократно используемые вещи. Тот факт, что мы верим, что технологии готовы - не очень веский аргумент. В то же время мир также стал сложнее.
В течение последнего года я работал с компанией, которая отходит от своего мэйнфрейма (слишком дорогой) и ряда старых Java-монолитов (слишком большие и сложные для поддержки). Сроки внедрения также играют немаловажную роль. Сфера IT должна поддерживать внедрение нового продукта в течение нескольких месяцев. Поэтому мы решили быть модными и выбрали микросервисы. Вот мое резюме "хороших, плохих, и злых" аспектов микросервисной архитектуры.
Хорошие
Начнем с хороших аспектов. Мы создаем небольшие компоненты, каждый из которых обеспечивает от двух до шести сервисов. Хорошими примерами таких небольших компонентов являются компонент PDF, который всего лишь генерирует PDF из шаблона с данными, и компонент Customer, который позволяет пользователям искать существующих клиентов. Эти компоненты обладают правильным размером: объёмом кода, правильным размером для понимания и документирования, а также для тестирования и развертывания.
Хороший
Наша команда начала превращаться в набор небольших групп, разрабатывающих, внедряющих и поддерживающих отдельные компоненты. Мы не настаивали на этом, но со временем небольшие группы сами брались за работу над конкретным компонентом и начинали чувствовать себя ответственными за него.
После того как мы составили общую схему базовой архитектуры наших микросервисов, мы установили ряд принципов. Мы создаем не только небольшие компоненты, но также небольшие одноцелевые веб-приложения. Приложения могут говорить с другими приложениями и компонентами. Компоненты сами управляют собственной устойчивостью и хранением, а также могут общаться с другими компонентами. Приложения не говорят непосредственно с хранилищами. Компоненты не говорят с хранилищами. Для нас эти принципы работают.
Микросервисы выполняют некоторые из своих обещаний. Вы можете выбрать необходимые технологии и механизмы устойчивости для каждого компонента. Некоторые компоненты сохраняются в реляционных базах данных (DB2 или SQLServer), другие сохраняются в базах данных документов (в нашем случае MongoDB). Тут подходит модный термин "polyglot persistence".
Мы также решили, что у каждого приложения и компонента будет своя собственная модель домена. Мы непосредственно используем принципы и шаблоны предметно-ориентированного проектирования. У нас есть объекты домена, объекты-значения, сводные корни, хранилища и фабрики. Поскольку наши компоненты малы, модели домена довольно просты и, благодаря этому, удобны в обслуживании.
И хотя мы долго шли к тестированию наших компонентов и сервисов, от Fitnesse до рукописных тестов, сейчас мы переходим к написанию тестов тестерами в SoapUI. Тестирование мы проводим как отдельно, так и во время сборки. Мы должны были научиться понимать REST, но с этим мы уже справились. И тестерам очень нравится то, что получилось.
Когда мы начинали наше путешествие с микросервисами, команда, в которой я был, находилась в реактивном режиме - скажите нам, что программировать и как, и мы это сделаем. Думаю, не стоит объяснять, как это влияет на мотивацию членов команды. Однако для микросервисов нет готовой "книги рецептов" или заданной архитектуры. Этих вещей просто не существует. Это значит, что нам постоянно нужно было решать головоломку микросервисов, от открытия того, как проектировать микросервисы (мы применили "умные" сценарии использования), до того, как применить интерфейсы REST, как работать с совершенно новым набором сред, и как создать совершенно новый способ развертывания компонентов. Именно эта головоломка делает работу над данной архитектурой интересной. Мы каждый день учимся.
Плохие
Но, как всегда, есть и обратная сторона. Когда вы выбираете путь микросервисов - по каким бы причинам вы ни считали его полезным - вам нужно понимать, что все это очень новое. Просто подумайте: если вы не работаете на Netflix или Amazon, то знаете ли вы кого-то, кто активно развернул микросервисы в производстве под полной нагрузкой? Кого вы можете спросить?

Плохой
Вы должны понимать, что вам действительно придется копать глубоко. Вам придется очень многое изучать самим. Стандартов еще нет. Вы поймете, что любые решения, которые вы примете о техниках, протоколах, фреймворках и инструментах, вероятно, будут временными. Когда вы ежедневно учитесь, новые, лучшие варианты становятся доступными или необходимыми, и вам придется изменять ваши решения. Так что если вы ищите готовый конструктор IKEA для правильной реализации микросервисов, возможно, вам еще лет пять-семь придется подождать. Просто дождитесь крупных компаний, они довольно скоро присоединятся, поскольку дело прибыльное.
С точки зрения проектирования, вам придется начать думать по-другому. Проектирование небольших компонентов не такое простое, как кажется. Какой размер компонента правильный? Да, у него одна бизнес-цель, несомненно, но как вы определите границы вашего компонента? В какой момент вы решите разделить работающий компонент на два или более отдельных компонента? Мы столкнулись с целым рядом таких проблем в течение прошлого года. И хотя мы разделяли существующие компоненты, жестких правил, когда это нужно делать, нет. Мы принимали решение на основе интуиции, обычно тогда, когда уже не могли разобраться в структуре компонента, или когда понимали, что он выполняет несколько бизнес-функций. Это становится еще более сложным, если вы "отсекаете" компоненты от больших систем. При этом обычно нужно обрезать много "проводки", и в то же время вам нужно будет обеспечить стабильную работу системы. Кроме того, вам понадобится достаточно большой объем знаний о предметной области, чтобы провести компонентизацию существующих систем.
В целом, мы обнаружили, что компоненты не такие стабильные, как мы предполагали. Иногда мы объединяли компоненты, но гораздо чаще мы разбивали их на более мелкие, чтобы обеспечить повторное использование и более короткое время выхода на рынок. К примеру, мы выделили компонент Q&A из компонента Product, и теперь он поставляет формы опроса не только о продуктах, но и для других целей. А недавно мы создали новый компонент, который занимается исключительно проверкой и хранением заполненных анкет.
Вам также придется найти ответы на многие технические вопросы. Что такое архитектура компонента? Является ли приложение также и компонентом? Или менее очевидный вопрос, если вы думаете об использовании REST в качестве вашего протокола связи - вы, вероятно, думаете: как именно функционирует REST? Что значит "сервисный интерфейс соответствует условиям REST"? Какие коды завершения использовать и когда? Как реализовать обработку ошибок у потребителей, если что-то не обрабатывается нужным образом одним из ваших сервисов? REST не так прост, как кажется. Вам нужно будет потратить много времени и усилий, чтобы найти свой метод работы с сервисными интерфейсами. Мы выяснили, что для того, чтобы сервисы вызывались более или менее унифицировано, нам лучше создать небольшой фреймворк, который делает запросы, а также занимается ответами и ошибками. Таким образом, связь осуществляется одинаково при каждом запросе, и если нам понадобится сменить основной протокол (в нашем случае JAX-RS), то нужно будет поменять его лишь в одном месте.
И это приводит меня к следующей проблеме. Да, микросервисы выполняют обещание о том, что вы можете подобрать лучшие технологии к каждому компоненту. Мы признаем это в наших проектах. Некоторые наши компоненты используют Hibernate, некоторые MongoDB connector, некоторые основываются на дополнительных фреймворках, таких как Dozer для мэппинга, или используют какой-либо PDF-генерирующий фреймворк. Но с дополнительными фреймворками приходит и потребность в дополнительных знаниях. В этой компании мы с легкостью создадим около сотни мелких компонентов, может, даже больше. Если даже четверть из них будет использовать свои специфические фреймворки, в конечном итоге у нас будет от двадцати пяти до тридцати различных фреймворков (я упоминал, что мы работаем в Java?). Нам нужно будет знать их все. И что еще хуже, все их версии (если они, конечно, не "мертвые") тоже.
Кроме того, есть необходимость стандартизации части кода, который вы пишете. Свобода технологий - это замечательно, но если каждый компонент буквально реализован иначе, то в итоге у вас будет практически неподдерживаемая база кода, тем более что, скорее всего, никто не следит за всем пишущимся кодом. Я настоятельно рекомендую убедиться, есть ли согласованность между компонентами в вашей базе кода, которую вам можно и нужно унифицировать. Подумайте о компонентах пользовательского интерфейса (сетки, кнопки, всплывающие окна, сообщения об ошибках), проверки (моделей домена), об общении с базами данных и о том, как будут формулироваться запросы от сервисов. Кроме того, хотя я и категорически против разделенной модели домена (пожалуйста, не выбирайте этот путь), в ваших моделях домена будут элементы, которые вам, возможно, придется разделить. Мы, например, разделяем ряд перечислений и объектов-значений, таких как CustomerId и IBAN.
Если вы похожи на нас, то ваш код попадет в набор библиотек (или фреймворк, если хотите), который будет повторно использоваться вашими компонентами. Мы узнали, что с каждым новым релизом этого доморощенного фреймворка мы в конечном итоге проводим рефакторинг части кода наших компонентов. Я переписал интерфейс нашего фреймворка проверки на прошлой неделе, что было необходимо, чтобы избавиться от состояния, которое он сохранял (компоненты не должны сохранять состояние по причинам масштабируемости), и я не очень-то хочу встраивать его обратно в систему, когда вернусь на работу в понедельник. Большинство наших компонентов его используют, и их код может не скомпилироваться. Я хочу сказать, что хорошо иметь доморощенный фреймворк. При определенном уровне дисциплины он поможет сделать код более понятным и немного более однородным, но вам придется убедить себя в том, что нужно посвятить себя ему и выпускать его новые версии.
Злые
Так что насчет действительно неприятных моментов микросервисов? Начнем с конвейеров развертывания. Одно из обещаний микросервисов гласит, что микросервисы могут и должны быть индивидуально развернуты и выпущены. Если вы привыкли иметь один конвейер разработки и развертывания для одной системы, которую вы создаете или расширяете, то вам, вероятно, понравится. С микросервисами вы создаете отдельные конвейеры для отдельных компонентов.
Злой
Выпустить первую версию компонента не так сложно. Мы начали с простого конвейера Jenkins, но сейчас изучаем TeamCity. У нас четыре разные среды. Одна для разработки, одна для тестирования, одна для принятия, плюс, конечно, производственная среда. Теперь, когда мы постепенно начали выпускать наши компоненты, большинство из которых имеют собственные базы данных, мы поняли, что не сможем делать это без поддержки и сотрудничества с операционной командой. Мы ожидаем, что постепенно эволюционируем до режима непрерывной поставки, с операционной деятельностью, интегрированной в команду. Сейчас у нас уже достаточно проблем с тем, чтобы получить поддержку операционной команды. На данный момент они привыкли к квартальным релизам целой системы и уж точно не имеют никакого желания переходить на индивидуальное развертывание компонентов.
Еще одна причина для беспокойства - это контроль версий. Если уже достаточно сложно контролировать версии нескольких взаимодействующих приложений, то что вы скажете насчет сотни приложений и компонентов, каждый из которых полагается на кучу других для доставки необходимых сервисов? Конечно, ваши сервисы все независимые, так, как и обещает парадигма микросервисов. Но только будучи вместе, ваши сервисы превращаются в систему. Как избежать того, чтобы вся ваша красивая микросервисная архитектура не превратилась в версионный ад, который, похоже, является прямым потомком ада DLL?
Честно говоря, на данный момент я не могу дать вам хороший совет на эту тему, но искреннее предупреждение вам тоже пригодится. Мы начали с простой схемы трехзначной нумерации (такой, как 1.2.5). Цифра справа меняется, когда устраняются мелкие ошибки. Средняя цифра меняется, когда к компоненту добавляются небольшие новые функции, а левая меняется, когда мы выпускаем новую версию компонента с серьезными изменениями в интерфейсе. Не то, чтобы мы поощряли регулярную смену интерфейсов, но это случается.
Кроме того, мы тестируем наши сервисы во время сборки с помощью и кодированных тестов, и тестов, которые мы создаем в SoapUI. Еще мы документируем требования в "умных" сценариях использования и в моделях домена наших приложений и компонентов, используя UML. Уверен, что в будущем нам нужно будет принять больше мер предосторожности, чтобы поддерживать нашу систему в "здравом" состоянии, например, добавить Swagger для документирования кодированных сервисов, но пока еще слишком рано судить.
Модель "хоккейная клюшка"
Слишком рано судить? Да, мы идем по пути микросервисов около года. И я до сих пор не понял, идем ли мы по лестнице в небо или по дороге в ад. Полагаю, что, как и в случае с историческими предшественниками, мы окажемся где-то посередине, хотя я действительно верю, что у нас есть технологии для того, чтобы эта парадигма заработала. И я имею в виду не только Netflix, Amazon или какую-нибудь модную мобильную компанию, но и обычные компании средних размеров, в которых работаем мы с вами.
Но будет ли это целесообразным? Сократит ли сроки внедрения? Предоставит ли все те прекрасные вещи, которые нам обещает парадигма? Честно говоря, я еще не знаю - несмотря на.., или даже из-за всего ажиотажа, окружающего микросервисы. Я заметил, что учитывая всю сложность, окружающую микросервисы, требуется достаточно много времени, чтобы запустить первые сервисы, и мы только-только прошли эту черту. Несколько недель назад мы пили пиво с Сэмом Ньюменом, автором книги "Building Microservices" ("Создание микросервисов"). Сэм подтвердил мои наблюдения своими собственными примерами и назвал это моделью "хоккейная клюшка".
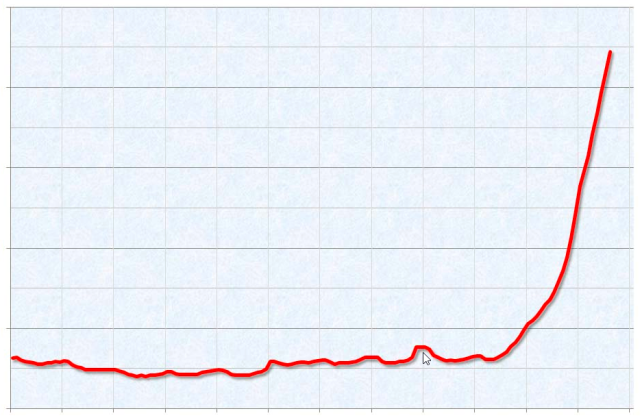
Нужно очень много сделать до того, как вы будете готовы выпустить свой первый сервис. Продумать инфраструктуру, разобраться, как правильно применить REST, настроить конвейеры развертывания и прежде всего изменить способ мышления в разработке программного обеспечения. Но как только первый сервис будет запущен и заработает, новые будут появляться все быстрее.
Запаситесь терпением
Так что если я чему и научился за последний год, так это терпению - этого слова раньше не было в моем словаре. Не пытайтесь применять стандарты организации, если они еще не существуют. Разбирайтесь по ходу процесса. Позвольте себе учиться. Делайте все постепенно. Просто попробуйте делать вещи чуточку лучше, чем вчера. И как всегда - получайте удовольствие!