Четыре серьезных довода в пользу того, чтобы опробовать эту платформу с открытым исходным кодом для анализа данных
R - это универсальный язык программирования, разработанный для применения в таких областях, как разведочный анализ данных, классические статистические тесты и высокоуровневая графика. Благодаря своей обширной и непрерывно расширяющейся библиотеке пакетов язык R занимает ведущие позиции в статистике, в анализе данных и в добыче данных. Язык R доказал, что является действительно полезным инструментом в развивающейся области больших данных, и был интегрирован в ряд коммерческих пакетов, таких как IBM SPSS® и InfoSphere®, а также Mathematica. В данной статье ценность языка R рассматривается с точки зрения специалиста по статистике.
Вы наверняка слышали о R. Возможно, вы читали соответствующую статью Сэма Сиверта (Sam Siewert) под названием Большие данные в облаке. Вы знаете, что R - это язык программирования и что он имеет определенное отношение к статистике, но подходит ли он вам?
Доводы в пользу R
R - язык, ориентированный на статистику. Его можно рассматривать в качестве конкурента для таких аналитических систем, как SAS Analytics, не говоря уже о таких более простых пакетах, как StatSoft STATISTICA или Minitab. Многие профессиональные статистики и методисты в правительственных организациях, в коммерческих компаниях и в фармацевтической отрасли решают свои задачи с помощью таких продуктов, как IBM SPSS или SAS, без написания какого-либо кода на языке R. Таким образом, в значительной степени решение об изучении и использовании R - это вопрос корпоративной культуры и профессиональных предпочтений применительно к рабочим инструментам. В своей статистической консультационной практике я использую несколько инструментов, однако большая часть того, что я делаю, сделана на R. Следующие примеры объясняют, почему дело обстоит именно таким образом.
- R - это мощный скриптовый язык. Недавно меня попросили проанализировать результаты одного масштабного исследования. Исследователи просмотрели 1600 научных работ и закодировали их содержимое по нескольким критериям - количество критериев было действительно большим, особенно с учетом множественных вариаций и ветвлений. После переноса в электронную таблицу Microsoft® Excel® эти данные содержали более 8000 столбцов, большинство из которых были пустыми. Исследователи хотели подсчитывать общие количества по различным категориям и под разными заголовками. R является мощным скриптовым языком и поддерживает Perl-подобные регулярные выражения для обработки текста. Для обработки неупорядоченных данных требуются возможности языка программирования; продукты SAS и SPSS имеют скриптовые языки для задач, для решения которых недостаточно ниспадающего меню, однако R был создан именно как язык программирования и поэтому является более подходящим инструментом для этой цели.
- R - лидер направления. Многие новые разработки в области статистики сначала появляются как пакеты для платформы R ("R-пакеты") и только потом приходят на коммерческие платформы. Недавно я получила данные медицинского исследования по повторным обращениям пациентов. По каждому пациенту в этих данных имелось количество элементов лечения, предложенных врачом, и количество элементов, которые реально запомнил пациент. Естественной моделью для этой ситуации является т. н. бета-биномиальное распределение . Оно известно с 1950-х годов, однако процедуры оценки, связывающие модель с интересующими нас ковариациями, появились лишь недавно. Такие данные обычно обрабатываются с помощью т.н. GEE-методов (Generalized Estimating Equations), однако эти методы являются асимптотическими и исходят из предположения, что выборка имеет большие размеры. Мне требовалась обобщенная линейная модель с бета-биномиальным распределением. Один из недавно появившихся R-пакетов осуществляет оценку согласно этой модели: пакет betabinom , автором которого является Бен Болкер (Ben Bolker). Инструмент SPSS не имеет таких возможностей.
- Интеграция со средствами публикации документов. R органично интегрируется с системами публикации документов, что позволяет встраивать статистические результаты и графику из среды R в документы публикационного качества. Эта возможность не нужна абсолютно всем, однако если вы хотите написать книгу о своем анализе данных или просто не любите копировать свои результаты в документы текстового процессора, то самый короткий и самый элегантный маршрут состоит в использовании R и LaTeX.
- Бесплатность Я - владелец небольшой компании, поэтому мне нравится, что R распространяется свободно. Даже для более крупного предприятия весьма неплохо, когда в случае привлечения нужного специалиста на временной основе оно способно немедленно предоставить такому специалисту рабочую станцию с передовым аналитическим программным обеспечением. При этом нет никакой необходимости волноваться о бюджете.
Что такое R и для чего он предназначен
140-символьное объяснение
R - это реализация языка S с открытым исходным кодом, представляющая собой среду программирования для анализа данных и для работы с графикой.
В качестве языка программирования R подобен многим другим языкам. Любой человек, который когда-либо писал программный код, найдет в R множество знакомых моментов. Отличительные особенности R лежат в статистической философии, которую он исповедует.
Статистическая революция: S и разведочный анализ данных
Компьютеры всегда были эффективным инструментом для вычислений - но лишь после того, как кто-то написал и отладил программу для выполнения нужного алгоритма. Однако в 1960-1970-х годах компьютеры были еще очень слабы в области отображения информации, особенно графической. Эти технические ограничения, наряду с тенденциями в статистической теории, привели к тому, что практика статистики, как и подготовка статистиков, ориентировались на построение моделей и на проверку гипотез. В этом мире исследователи предлагали гипотезы, тщательно продумывали эксперименты, настраивали модели и проводили испытания. Подобный подход реализован в программных средствах, подобных SPSS, которые базируются на электронных таблицах и управляются с помощью меню. Фактически первые версии программных продуктов SPSS и SAS Analytics состояли из подпрограмм, которые можно было вызвать из основной программы (на Fortran или на другом языке) с целью подгонки и проверки модели из имеющегося набора моделей.
В эту формализованную и перегруженную теорией среду Джон Тьюки (John Tukey) вбросил, как булыжник в стеклянную витрину, концепцию т. н. разведочного анализа данных (Exploratory Data Analysis, EDA). Сегодня трудно представить время, когда к анализу набора данных можно было приступать без использования ящичной диаграммы (box plot) для проверки на асимметрию и на выбросы или без проверки невязок линейной модели на нормальность с помощью квантильной диаграммы. Автором всех этих идей был Дж. Тьюки, и сегодня ни один вводный курс по статистике не обходится без них. Однако дело не всегда обстояло подобным образом.
Цитата из книги: Graphical Methods for Data Analysis (Графические методы анализа данных)
"В любом серьезном приложении на данные следует посмотреть несколькими способами, а затем построить несколько графиков и выполнить несколько исследований. Это позволит по результатам каждого очередного шага выбирать следующий шаг. Чтобы анализ данных был эффективным, он должен быть итеративным". - Джон Чамберс (John Chambers), см. разделРесурсы).
EDA - это в большей степени подход, чем теория. Для успешного применения этого подхода необходимо соблюдать следующие эмпирические правила.
- По возможности используйте графики для рассмотрения интересующих вас функций.
- Всегда выполняйте анализ инкрементным образом. Испытайте одну модель; исходя из полученных результатов, настройте следующую модель.
- Проверяйте допущения модели с помощью графиков. Обращайте внимание на выбросы, если они есть.
- Используйте робастные методы с целью нейтрализации отклонений от допущений распределения.
Подход Дж. Тьюки породил волну новых графических методов и робастных оценок. Кроме того, этот подход инициировал разработку новой программной среды, ориентированной на разведочные методы.
Джон Чамберс вместе со своими коллегами из компании Bell Laboratories создал язык S в качестве платформы для статистического анализа, особенно той его разновидности, которую исповедовал Дж. Тьюки. Первая версия языка S, предназначенная для внутреннего использования в компании Bell, была разработана еще в 1976 г., однако лишь в 1988 году этот язык приобрел свою нынешнюю форму. К этому времени язык был доступен и пользователям за пределами Bell. В каждом своем аспекте язык S соответствует "новой модели" анализа данных.
- S - это интерпретируемый язык, действующий в среде программирования. Синтаксис S во многом походит на синтаксис языка C, но без его сложностей. К примеру, S берет на себя заботу об управлении памятью и об объявлении переменных, поэтому у пользователя нет необходимости описывать и отлаживать подобные вещи. Более низкие накладные расходы на программирование позволяют быстро проводить несколько исследований с одним и тем же набором данных.
- С самого начала язык S допускал создание высокоуровневых графических артефактов и позволял добавлять опции к любому открытому графическому окну. Этот язык позволяет с легкостью выделить интересные места, запросить их значения, добавить сглаживющие кривые к точечной диаграмме и т.д.
- В 1992 г. в языке S была дополнительно реализована объектная ориентированность. В языке программирования объекты осуществляют структурирование данных и функций в соответствии с интуитивными представлениями пользователя. Человеческое мышление всегда является объектно-ориентированным, а статистические умозаключения - в особенности. Статистик работает с частотными таблицами, с временными рядами, с матрицами, с электронными таблицами, содержащими данные разных типов, с моделями и т.д. В каждом случае необработанные числа наделяются атрибутами и сопровождаются теми или иными ожиданиями. Например, временной ряд состоит из наблюдений и соответствующих моментов времени. Для каждого типа данных ожидаются стандартные статистические показатели и графики. В случае временных рядов можно сформировать график временного ряда и коррелограмму; для эмпирически подобранной модели можно графически изобразить приближения и остатки. Язык S позволяет создавать объекты для всех этих концепций; по мере необходимости вы сможете создавать новые классы объектов. Объекты облегчают переход от концептуализации проблемы к ее реализации в программном коде.
Язык с характером: S, S-Plus и проверка гипотез
В своем первоначальном виде язык S относился к EDA-методам Дж. Тьюки весьма серьезно - до такой степени, что на языке S было неудобно делать что-либо иное, помимо EDA. Это был язык с характером. Например, S имел ряд полезных внутренних функций, однако у него отсутствовали некоторые вполне очевидные возможности, наличия которых можно было бы ожидать у статистического программного обеспечения. Так, отсутствовала функция для выполнения t-теста для двух выборок и не поддерживалось настоящее тестирование для гипотез любого вида. Однако, несмотря на аргументацию Дж. Тьюки, тестирование гипотез зачастую бывает весьма полезным.
В 1988 г. компания из Сиэтла под названием Statistical Science приобрела лицензию на S и портировала улучшенную версию этого языка под названием S-Plus на платформу DOS, а затем и в среду Windows®. Обладая реальным представлением о том, что требуется ее клиентам, компания Statistical Science добавила в язык S-Plus функциональность классической статистики. Были добавлены функции для дисперсионного анализа (ANOVA), t -тест и другие модели. В соответствии с объектной ориентированностью языка S результат любой подобранной модели сам является объектом языка S. Вызовы соответствующей функции предоставляют приближения, остатки и p -значение при тестировании гипотезы. Объект модели может даже содержать промежуточные вычислительные шаги анализа, такие как QR-разложение матрицы плана (где Q - ортогональная матрица, а R - верхнетреугольная матрица).
Для каждой задачи имеется пакет на языке R! Сообщество сторонников открытого кода
Примерно в то же самое время, когда был выпущен язык S-Plus, Росс Айхэка (Ross Ihaka) и Роберт Джентлмен (Robert Gentleman) из Оклендского университета в Новой Зеландии решили попробовать свои силы в написании интерпретатора. В качестве своей модели они выбрали язык S. Проект конкретизировался и получил поддержку. Они дали своему проекту название R.
R - это реализация языка S с дополнительными моделями, разработанными в языке S-Plus. В некоторых случаях моделями в обоих языках занимались одни и те же люди. R - это проект с открытым исходным кодом, который доступен в соответствии с лицензией GNU. На этом фундаменте R продолжает развиваться, в значительной степени посредством добавления пакетов. R- пакет представляет собой коллекцию наборов данных, функций языка R, документации и динамически загружаемых элементов на языке C или Fortran. R-пакет может быть установлен как группа, которая будет доступна в рамках сеанса R. R-пакеты добавляют новую функциональность к языку R; посредством этих пакетов исследователи могут с легкостью обмениваться вычислительными методами со своими коллегами. Некоторые пакеты имеют ограниченную область применения, другие представляют целые области статистики, а некоторые отражают новейшие разработки. И действительно, многие новые разработки в области статистики сначала появляются как R-пакеты, и только потом реализуются в коммерческих программных продуктах.
В тот момент, когда я писала этот текст, на веб-сайте CRAN, с которого осуществляется загрузка R, количество R-пакетов составляло 4701. Из них шесть пакетов было добавлено только в один этот день. Платформа R имеет пакет для решения любой задачи - по крайней мере именно такое впечатление складывается.
Что происходит при использовании R
Прмечание: Эта статья не является обучающим руководством по R. Следующий пример - это не более чем попытка показать, как выглядит сеанс R.
Имеются двоичные дистрибутивы R для Windows, для Mac OS X и для нескольких вариантов Linux®. Кроме того, для тех, кому нравится компилировать самостоятельно, доступны и исходные коды.
В среде Windows® установщик добавляет пункт R в Меню Start (Пуск). Чтобы запустить R в среде Linux, откройте окно терминала и при появлении подсказки введите с клавиатуры букву R. Вы должны увидеть нечто похожее на рис.1 .
Рисунок 1. Рабочее пространство R
Введите команду в строке приглашения, и R отреагирует соответствующим образом.
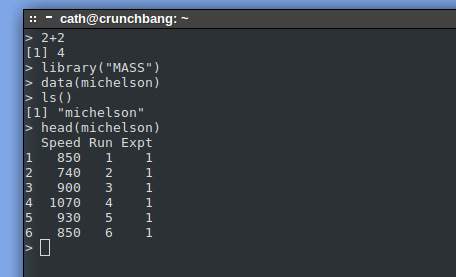
В реальной ситуации на этом этапе вы, вероятно, ввели бы данные в объект R из внешнего файла данных. R способен читать данные в различных форматах; однако в этом примере я использую набор данных michelson из пакета MASS. Этот пакет сопровождает этапную книгу Венаблса (Venables) и Рипли (Ripley) под названием Modern Applied Statistics with S-Plus (Современная прикладная статистика с использованием S-Plus) (см. раздел Ресурсы). Набор данных michelson содержит результаты известных экспериментов Майкельсона-Морли по измерению скорости света.
Команды, показанные в листинге 1, загружают пакет MASS, получают данные из michelson и позволяют рассмотреть их. На рис.2показаны эти команды с соответствующими ответами от R. Каждая строка содержит R-функцию с ее аргументами в квадратных скобках ([]).
Листинг 1. Старт сеанса R
Рисунок 2. Старт сеанса и ответы R
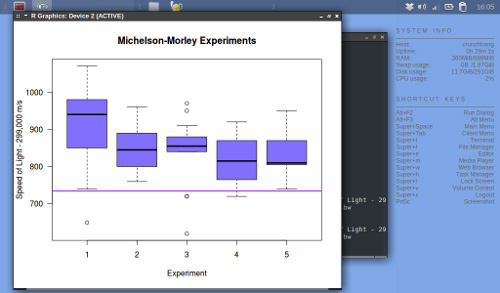
Теперь посмотрим на данные (листинг 2). Результаты показаны на рис.3.
Листинг 2. Ящичная диаграмма (box plot) на языке R
Складывается впечатление, что Майкельсон и Морли систематически завышали оценку скорости света. Кроме того, в результатах экспериментов наблюдается некоторая неоднородность.
Рисунок 3. Представление в виде ящичной диаграммы
Если меня удовлетворяют мои исследования, я могу сохранить все свои команды в виде одной функции языка R (листинг 3).
Листинг 3. Простая функция на языке R
Этот простой пример иллюстрирует несколько важных особенностей языка R.
Нуждается ли R в мощных аппаратных средствах?
Я выполняла этот пример на нетбуке Acer под управлением Crunchbang Linux. R не требует мощного компьютера для проведения анализа малого и среднего масштаба. На протяжении 20 лет про R говорили, что это медленный язык, поскольку он является интерпретируемым, и что объем данных, которые он способен проанализировать, ограничен памятью компьютера. Все это соответствует действительности, однако для современных компьютеров это, как правило, некритично, при условии, что приложение не является действительно огромным (т.е. не относится к категории Больших данных).
- Сохранение результатов- Функция
boxplot()помимо диаграммы возвращает несколько полезных статистических данных; их можно сохранить в объекте языка R посредством оператора присваивания (например,michelson.bp = ...), а затем извлечь в случае необходимости. Результат любого оператора присваивания доступен на протяжении всей сессии R и может стать предметом последующего анализа. Функцияboxplotвозвращает матрицу статистических данных, использованных для построения ящичной диаграммы (медианы, квантили и т.д.), число элементов в каждой коробке и значения выбросов (показаны на рис. 3 как незаштрихованные круги). См. рис. 4.Рисунок 4. Статистические данные из функции boxplot
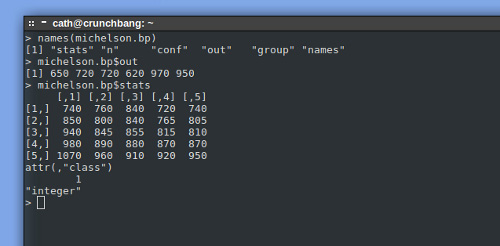
- Язык формул- R (и S) - это компактный язык для представления статистических моделей. Код
Speed ~ Exptв аргументе дает функции указание строить ящичную диаграмму значений Speed (скорость) для каждого уровня Expt (номер эксперимента). Если бы я хотела провести дисперсионный анализ для выявления существенных изменений значения Speed от эксперимента к эксперименту, я использовала бы ту же самую формулу:lm(Speed ~ Expt). Язык формул позволяет выражать широкое разнообразие статистических моделей, включая перекрестные и вложенные эффекты, а также постоянные и случайные факторы. - Определяемые пользователем функции R- Это язык программирования.
R остается актуальным и в 21 веке
Разведочный подход Дж. Тьюки к анализу данных стал нормой для учебного процесса. Он преподается в учебных заведениях и применяется специалистами по статистике. Язык R поддерживает этот подход, и это одно из объяснений того, почему он до сих пор сохраняет популярность. Объектная ориентация также помогает языку R оставаться актуальным, поскольку для анализа новых источников данных требуются новые структуры данных. В настоящее время платформа InfoSphere® Streams поддерживает анализ на языке R для данных, отличных от тех, на которые ориентировался Джон Чамберс.
Инструментарий R-project Toolkit на платформе InfoSphere Streams
InfoSphere Streams - это передовая вычислительная платформа, которая предоставляет возможность быстро принимать, анализировать и сопоставлять информацию в приложениях, разработанных пользователями, по мере поступления информации из тысяч источников в реальном времени. Это решение способно обрабатывать данные с очень высокой пропускной способностью: до нескольких миллионов событий или сообщений в секунду. В состав этой платформы входит инструментарий R-project Toolkit. Узнайте больше и загрузите ознакомительную версию.
Язык R и платформа InfoSphere Streams
InfoSphere Streams - это вычислительная платформа и интегрированная среда разработки для анализа данных, которые с высокой скоростью поступают из тысяч источников. Содержимое этих потоков данных обычно является неструктурированным или структурированным частично. Цель анализа состоит в выявлении изменяющихся закономерностей в данных и в принятии решений непосредственно на основе быстро меняющихся событий. Язык программирования для платформы InfoSphere Streams под названием SPL организует данные посредством парадигмы, которая отражает динамичную природу данных, а также необходимость быстрого анализа и реагирования.
Мы далеко ушли от электронных таблиц и обычных плоских файлов классического статистического анализа, однако язык R способен адаптироваться. В версии 3.1 приложения на SPL способны передавать данные в R и таким образом задействовать обширную библиотеку R-пакетов. InfoSphere Streams поддерживает аналитику на R посредством создания соответствующих R-объектов для получения информации, содержащейся в кортежах SPL (базовая структура данных в языке SPL). Это позволяет передавать данные InfoSphere Streams в среду R для последующего анализа, а полученные результаты возвращать обратно в SPL.
Для каких случаев R не годится
Справедливости ради следует отметить, что некоторые вещи R делает не очень хорошо или вообще не делает. Кроме того, R не в одинаковой степени подходит каждому пользователю.
- R не является хранилищем данных. Самый легкий способ ввода данные в R состоит в том, чтобы ввести нужные данные в каком-либо другом месте, а затем импортировать их в среду R. В свое время имели место попытки добавить к среде R интерфейсную часть в виде электронной таблицы, однако они не завоевали популярности. Отсутствие функциональности электронной таблицы не только затрудняет ввод данных, но и осложняет визуальное рассмотрение данных в R (в отличие от SPSS или Excel).
- R осложняет решение обычных задач. К примеру, при проведении медицинских исследований первый этап обработки данных состоит в вычислении сводной статистики по всем переменным и в составлении перечня отсутствующих ответов и пропущенных данных. В SPSS этот процесс реализуется буквально тремя щелчками мыши, однако R не имеет встроенной функции для вычисления этой вполне очевидной информации и ее последующего отображения в табличной форме. Нужный код достаточно легко написать самому, однако иногда хочется, чтобы такие вещи можно было делать щелчком мыши.
- Процесс обучения языку R является нетривиальным. Новичок может открыть управляемую с помощью меню статистическую платформу и получить результат за всего за несколько минут. Не каждый хочет становиться программистом для того, чтобы быть аналитиком, а, возможно, не каждому это и нужно.
- R имеет открытый исходный код. Сообщество R является многочисленным, зрелым и активным; вне всякого сомнения, R входит в число наиболее успешных проектов с открытым исходным кодом. Как я уже говорила, реализация языка R имеет возраст более 20 лет, а реализация языка S - еще больше. Это проверенная концепция и испытанный продукт. Однако, как и для любого другого продукта с открытым исходным кодом, надежность зависит от прозрачности. Мы верим в программный код, поскольку мы сами способны проверять его и поскольку другие люди способны проверять его и сообщать о выявляемых при этом ошибках. Иная ситуация имеет место в корпоративном проекте, который берет на себя обязанности по тестированию и валидации своего программного продукта. При этом в случае редко используемых R-пакетов у нас нет достаточных оснований предполагать, что эти пакеты действительно обеспечивают получение корректных результатов.
Заключение
Необходимо ли вам изучать язык R? Вполне возможно, что нет; необходимо - это слишком сильное утверждение. Но является ли R ценным инструментом для анализа данных? Несомненно. Этот язык специально разработан таким образом, чтобы отражать способы мышления и работы статистиков. R закрепляет хорошие привычки и улучшает анализ. По-моему, это хороший инструмент для такой работы.
Ресурсы
Научиться
- Оригинал статьи: Do I need to learn R?.
- The New S Language: A Programming Environment for Data Analysis and Graphics (R.A. Becker, John M. Chambers, A.R. Wilks; издательство Chapman & Hall, 1988). Эта основополагающая работа известна в кругах R и S как The Blue Book ("Синяя книга"). Книга содержит полное описание языка S и перечень всех его встроенных функций.
- Graphical Methods for Data Analysis (John M. Chambers, William S. Cleveland, Beat Kleiner, Paul A. Tukey; издательство Duxbury Press, 1983).
- Exploratory Data Analysis, (John Tukey) Обратите внимание, что Джон Тьюки (John Tukey) и Пол Тьюки (Paul Tukey) - это разные люди. В этой книге изложена концепция, которая была реализована в языке S.
- Modern Applied Statistics with S-Plus, (W.N. Venables, B.D. Ripley; издательство Springer-Verlag, 1997). Классическое введение в объектную ориентированность языка S-Plus (и языка R). Наборы данных и многие функции, использованные в этой книге, включены в пакет MASS языка R.
- R for Dummies (Joris Meys, Andrie de Vries; 2012). Доступное описание языка R для начинающих.
- R in a Nutshell (Joseph Adler; издательство O'Reilly, 2009). Фундаментальное введение в R для специалистов, осуществляющих стандартный статистический анализ наборов данных умеренного объема. Не охватывает большие данные.
- В издательстве Springer публикуется серия книг с оранжевыми обложками и заголовками типа Time Series Analysis in R и An Introduction to Applied Multivariate Analysis with R. These are a good introduction for the R user with a particular application Каждая из этих книг представляет собой хорошее введение для пользователей R, интересующихся определенной прикладной областью. В отличие от введений общего характера, книги этой серии в большей степени ориентированы на соответствующие пакеты для определенных предметных областей и в меньшей степени на базовые аспекты R.
- Многие "книги" по R в действительности являются работами по прикладной статистике с использованием R. Вероятно, самый сложный момент в использовании R - понимание статистических методов, реализованных в этом языке. В этой категории одной из моих любимых является книга Data Analysis and Graphics Using R - An Example-Based Approach (John Maindonald, John Braun; издательство Cambridge UP, 2010). Она охватывает множество полезных статистических методов и показывает, как использовать эти методы в R. Кроме того, к книге прилагается вспомогательный R-пакет с данными и функциями.
- The Art of R Programming, (Norman Matloff; издательство O'Reilly, 2011). Это не книга по статистике, а скорее одно из немногих учебных пособий, рассматривающих R именно как язык программирования. Она жизненно необходима вам, если вы планируете писать на R значительное количество программного кода, а не просто запускать пакеты.
- Если вы может позволить себе покупку лишь одной книги по R, то книга Data Mining with R, (Luis Torgo) не годится на эту роль. Однако если вы планируете иметь более одной книги, то эта книга послужит вам хорошим пособием промежуточного уровня. В этой книге, состоящей из трех различных примеров из области углубленного анализа данных, последовательно излагаются все этапы исследования, включая очистку данных и учет отсутствующих значений.
- Введение в InfoSphere Streams Превосходная вводная статья по платформе Streams.
- Overview of the R-project toolkit (Обзор инструментария R-project Toolkit) Описание Streams-инструментария для интеграции кода на языке R в приложения на языке SPL.
- Найдите ресурсы, которые помогут вам приступить к работе с InfoSphere Streams - высокопроизводительной вычислительной платформой IBM.
- Перечень продуктов по платформе InfoSphere Platform для проектов с интенсивным использованием информации.
- Новейшие видеоролики по большим данным для новичков и специалистов.
- Дополнительная техническая литература по этой и другим техническим темам.
- Смотрите демонстрации "по запросу" на веб-сайте developerWorks, охватывающие диапазон от демонстраций для новичков по установке и настройке продуктов до демонстраций по углубленным функциональным возможностям для опытных разработчиков.
- Дополнительная информация по большим данным на сайте developerWorks.. Техническая документация, руководства, учебные пособия, материалы для загрузки информация о продукции и многое другое.
- Найдите ресурсы, которые помогут вам приступить к работе с InfoSphere BigInsights - аналитической платформой, основанной на программном обеспечении с открытым кодом Hadoop и расширяющей его возможности благодаря таким функциям, как Big SQL, анализ текста и BigSheets.
- Руководства по IBM InfoSphere BigInsights(PDF) - учебные пособия для самостоятельного обучения по таким темам, как управление средой больших данных, импорт данных для анализа, анализ данных с помощью BigSheets, разработка первого приложения для работы с большими данными, разработка запросов Big SQL для анализа больших данных, создание экстрактора для извлечения осмысленной информации из текстовых документов с помощью InfoSphere BigInsights.
- Найдите ресурсы, которые помогут вам приступить к работе с InfoSphere Streams - высокопроизводительной вычислительной платформой, которая предоставляет возможность быстро принимать, анализировать и сопоставлять информацию в приложениях, разработанных пользователями, по мере поступления информации из тысяч источников в реальном времени.
- Следите за мероприятиями и трансляциями по техническим вопросам на Web-сайте developerWorks.
- Материалы developerWorks в Твиттере.
Получить продукты и технологии
- Опробуйте InfoSphere Streams: загрузите пробную версию со сроком действия 90 суток или попробуйте его в облаке.
- Многие продукты IBM SPSS можно опробовать бесплатно.
- IBM SPSS Decision Management- автоматизация и оптимизация принятия транзакционных решений перед развертыванием
- SPSS Modeler- инструмент для углубленного анализа данных, помогающий пользователю создавать прогнозирующие модели быстро и интуитивным образом, без программирования
- SPSS Text Analytics for Surveys- применение мощных технологий обработки естественных языков, специально спроектированных для исследования текста.
- SPSS Visualization Designer- простое создание и совместное использование впечатляющей визуализации для улучшения обмена аналитическими результатами
- Загрузите R и документацию на сайте CRAN.
- Загрузите продукт InfoSphere BigInsights Quick Start Edition, который доступен как нативный установочный пакет или как VMware-образ.
- Загрузите продукт InfoSphere Streams, который доступен как нативный установочный пакет или как VMware-образ.
- Оцените продукт InfoSphere Streams на платформе IBM SmartCloud Enterprise.
- Используйте в своем следующем проекте по разработке ознакомительное программное обеспечение IBM, которое можно загрузить непосредственно с сайта developerWorks.
Обсудить
- Присоединяйтесь к Streams Exchange- сообществу для разработчиков платформы InfoSphere Streams, чтобы делиться информацией, исходным кодом и сопутствующей информацией об исходном коде.
- Задавайте вопросы и получайте ответы на форуме по продукту InfoSphere BigInsights.
- Задавайте вопросы и получайте ответы на форуме по продукту InfoSphere Streams .
- Блоги developerWorks: присоединяйтесь к сообществу developerWorks.