Шмид Александр Викторович
Председатель правления ЗАО "ЕС-лизинг",
доктор технических наук, профессор.
Заметки о Big Data
"В ближайшие 5 лет все компании на рынке разделятся на
победителей и побежденных в зависимости от качества их аналитики."
Ginny Rometty - IBM CEO 2 марта 2012 года
Введение: от информационно-аналитических к информационно-решающим системам
В настоящее время мы являемся свидетелями эволюции коммерческих предложений в области инструментария создания аналитических систем предприятий: от частных решений, например, по визуализации аналитических результатов, к представлению интегрированных платформ с полной функциональностью для проведении аналитики по любым типам данных в ранее не доступных объемах. Например, платформы: IBM Big Data, либо IDOL 10 от HP. Эволюции от IT станков к IT заводам.
При этом конкурентные преимущества корпораций в конечном счете определяются качеством принимаемых их руководством РЕШЕНИЙ.
В этом смысле большинство рыночных предложений однобоко: предлагается только АНАЛИЗ, А СИНТЕЗ РЕШЕНИЯ по умолчанию остается за человеком.
В то же время никого уже не удивляет, что до 80 процентов операций на торгах проходит БЕЗ участия человека: решения о покупке-продаже принимаются IT роботами.
Суть действительно происходящей сейчас на наших глазах ЦИФРОВОЙ РЕВОЛЮЦИИ состоит не только в том, что для принятия конкурентных решений анализируются ранее невиданные объемы ранее не доступных для анализа типов данных, но также и в том, что во все большей степени качество решений машин начинает превосходить качество решений людей. Это надо осознать и к этому надо готовиться. Чтобы не оказаться в числе проигравших.
Совокупность технологий, стоящих за подготавливаемой всем ходом технического прогресса цифровой революции сейчас условно и называется: Big Data
1. Эволюция синтеза управляющих решений
1.1. Традиционная схема принятия решений
Человеку разумному свойственно принимать решения. В зависимости от статуса человека последствия принимаемых решений могут коснуться только его самого, а могут повлиять на судьбы партий, корпораций, армий, государств, повлиять на судьбы миллионов людей.
Человеку разумному свойственно желать успеха. Поэтому он стремится принимать решения, наилучшие из возможных.
Технологии выбора наилучших из возможных решений отработаны и не менялись на протяжении веков. Они подразумевали и подразумевают использование двух групп профессионально подготовленных людей:
- с одной стороны отвечающих за сбор информации, влияющей на принятие решения (разведки, аудиторы, бухгалтеры, следователи, диагносты, социологи),
- а с другой стороны, отвечающих за подготовку и принятие вариантов решения на основе собранной информации и исторического опыта принятия аналогичных решений (советники, аналитики, эксперты, оракулы, астрологи, провидцы).
Названные профессиональные группы по сути обеспечивали реализацию трех (в современной интерпретации) бизнес процессов:
П1. поиск и первичную фиксацию искомой информации (добычу информации).
П2. доставку информации до места ее использования.
П3. обработку информации и подготовку на ее основе вариантов принятия решения.
Само же решение принимается Руководителем - лицом или органом, с точки зрения нашего рассмотрения реализующего две основные функции:
- определение своей информационной потребности для принятия решения. То есть по сути выдачи задания остальным участникам процесса на предоставление необходимой для принятия решения информации;
- собственно принятия решения на основе полученной информации.
На рис 1. в самом общем виде представлена схема взаимодействия Руководителя с двумя названными профессиональным группами и выделены основные (бизнес) процессы, реализуемые ЛЮДЬМИ (а не компьютерами в составе АС).
То есть, по сути, в упрошенном виде представлены: макет оргструктуры взаимодействия трех участников процесса подготовки принятия решения, состоящего из двух бизнес процессов, обозначенных на рис. 1: детализации и реализации.
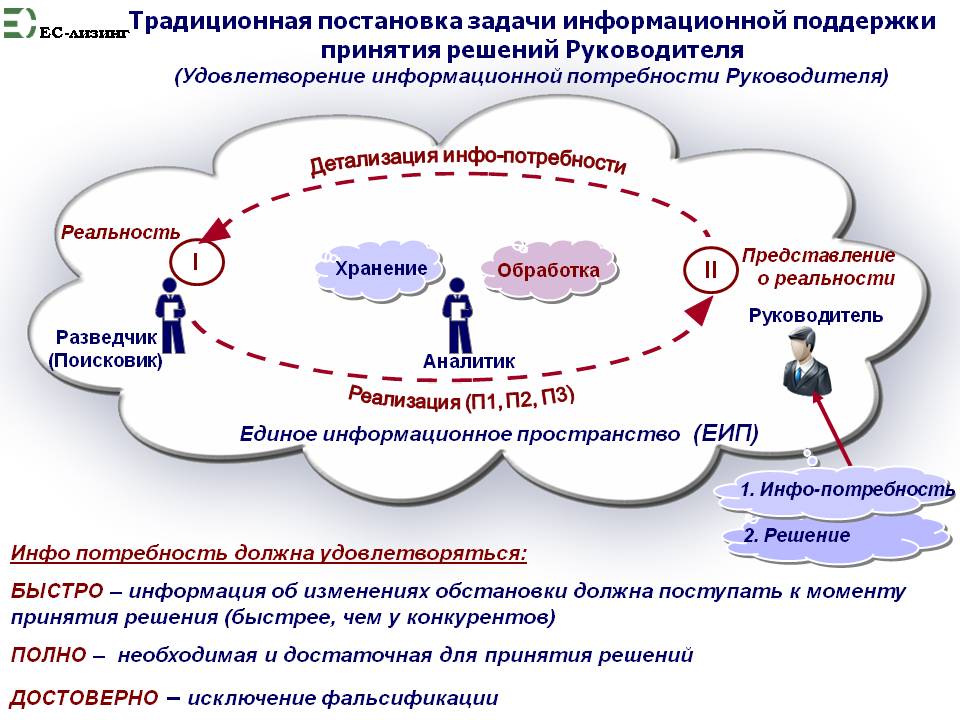
Рис. 1
Приведенной на рис. 1 оргструктуре соответствует ролевая модель в следующем виде:
1. Руководитель.
В процессе детализации: дает задание Аналитику на поиск и предоставление необходимой для принятия решения информации (определяет информационную потребность).
В процесс реализации: получает от Аналитика искомую информацию. На ее основании принимает решение.
2. Аналитик.
В процессе детализации: детализирует информационную потребность Руководителя, определяя состав и местонахождение источников первичной информации, а также состав подлежащей фиксации информации от каждого из источников. Дает задание на поиск и фиксацию искомой информации Разведчику (Поисковику).
В процессе реализации: получает первичную информацию от Разведчика. Анализирует, верифицирует и обобщает ее. Приводит информацию к виду, заданному информационной потребностью и передает Руководителю.
3. Разведчик (поисковик).
В процессе детализации: налаживает связь с источником (подключает источник).
В процессе реализации: фиксирует информацию источника и передает ее Аналитику.
Именно такая и ей подобные схемы подготовки и принятия решений существовали веками.
При реализации таких схем Руководители интуитивно стремились придерживаться еще не сформулированного до середины 19 века Чарльзом Дарвиным принципа: выживает не быстрейший, не сильнейший, а тот (вид), который быстрее приспосабливается к изменению окружающих обстоятельств.
Борьба за выживание ведется и поныне в мире Реальности, только в наше время Реальность стала цифровой. Стала Киберпространством или цифровым миром (digital universe в [1]).
И приведенные на рис. 1 вековые принципы создания традиционных схем принятия решений актуальны и поныне.
Именно на основе Традиционной схемы работали и в большинстве случаев в России продолжают работать Информационно аналитические системы (ИАС), для которых цифровая Реальность ограничена Структурированными данными.
Традиционная схема так подробно рассматривается здесь с единственной целью: установить, что же изменяется в традиционной схеме принятия решений в ходе цифровой революции.
1.2. Эволюция базовых технологий в традиционной схеме принятия решений: предпосылки цифровой революции
Появление с середины 20 века компьютеров (нового элемента в многовековой истории принятия решений), последующего появление сетей, обеспечивающих практически мгновенную доставку зафиксированной информации к месту обработки, а затем и цифровых средств первичной фиксации информации (видео камеры, радио метки, цифровые телефоны, мобильные устройства, персональные компьютеры), фиксирующих информацию в реальном времени - завершило формирование необходимых условий для комплексной цифровой автоматизации в совокупности всех трех бизнес процессов подготовки и принятия решений: П1, П2, П3.
На наших глазах происходят быстрые количественные изменения во всех трех бизнес- процессах традиционной схемы принятия решений:
П1 - возрастают объемы и множатся типы доступной для анализа информации. Это происходит как за счет расширения географического охвата и числа контролируемых процессов природы, общества, материального производства и потребления в связи с ростом числа и состава фиксирующих устройств, так и взрывного роста объема фиксируемой информации по каждому из контролируемых процессов;
П2 - возрастают возможности цифровых сетей по доставке зафиксированной информации к местам обработки, как по географическому охвату контролируемых процессов, так и по пропускной способности;
П3 - возрастают вычислительные возможности компьютеров по анализу доступной информации, а в последнее время во все возрастающей степени уже и по синтезу окончательных решений. Причем это возрастание в соответствии с правилом Мура происходит в геометрической прогрессии.
Названные количественные факторы в совокупности приводят к выводу о неизбежности грядущих качественных изменений взрывного порядка в области принятия решений - цифровой революции.
Цифровая революция подразумевает получение для компаний - участников технологического прорыва подавляющих конкурентных преимуществ за счет качественно новых технологий подготовки и принятия управленческих решений над компаниями, не применяющими подобных технологий.
Как отмечается в [1] цифровая революция, происходящая на наших глазах в нашем цифровом мире, несет в себе как огромные возможности, так и огромные угрозы.
Возможности для тех, кто впишется в этот новый, формирующийся на наших глазах цифровой мир.
Угрозы для тех, кто упустит такую возможность.
Сам этот мир огромен: согласно содержащейся в [1] оценке, ВСЯ информация, содержащаяся во всех средах хранения цифрового мира на 2011 год могла бы содержать более чем астрономическую цифру: около 1800 эксабайт!
То есть:
1800 эксабайт = 1800 * 1024 Петабайт = 1800 * 10242 Терабайт = 1800 * 10243 Гигабайт = 1800 * 10244 Мегабайт = 1800 * 10245 Килобайт = 1800 * 10246 байт
Остановимся на рассмотрении новых технологий, предопределяющих приход цифровой революции.
2. Новые технологии цифровой революции в области принятия управленческих решений (BIG DATA)
Big data сейчас, видимо, наиболее популярная и обсуждаемая тема в области IT.
Рынок завален огромным количеством рекламных, по своей сути, материалов, и их количество таково, что достаточно трудно рассмотреть за этим частоколом важных, но деталей, основные инновационные идеи, в совокупности и определяющие технологический прорыв.
Попытаемся провести выделение и классификацию инновационных технологических идей, лежащих в основе цифровой революции, в наиболее общей форме, без привязки к деталям: то есть с точки зрения здравого смысла.
В основу классификации положим оценку влияния технологических идей на качество управленческого решения, то есть на то, что и является искомым конкурентным преимуществом, достигаемым в итоге цифровой революции.
Именно качество принимаемых управленческих решений и разделит противоборствующие на рынке компании на победителей и побежденных.
Интуитивно ясно, что качество управленческого решения определяется двумя основными факторами:
- информированностью решающего центра (объемом доступной информации, ее своевременностью и достоверностью);
- интеллектуальностью решающего центра (умением адекватно воспользоваться Доступной информацией - IQ).
Попробуем провести выделение определяющих технологий BD раздельно по этим двум базовым факторам.
Как отмечается во всех доступных материалах, новые технологии не заменяют и не отменяют уже существующие технологии, а дополняют, развивают и интегрируют их, совместно обеспечивая выход на новый виток технического прогресса.
2.1. Технологии BD, влияющие на интеллектуальность решающего центра
2.1.1 Новые технологии принятия решений: кто будет принимать решения - человек или машина?
В октябре 2005 года делегация специалистов посетила лабораторию IBM в Цюрихе и была ознакомлена со стратегическим прогнозом развития IT на период 2005 - 2015 годы, написанным Нобелевскими лауреатами.
Суть прогноза состояла в том, что к 2015 году компьютеры будут принимать лучшие нежели люди решения во многих областях человеческой деятельности: банковской деятельности, медицине, экономике, биржевых и иных операциях.
Прогноз основывается на общеизвестной тенденции возрастания производительностей компьютеров в геометрической прогрессии (в два раза каждые 2 года - правило МУРА). С соответствующей тенденцией возрастания возможных объемов хранения.
А чем компьютер производительнее, тем более интеллектуальными оказываются принимаемые им решения.
В качестве исходной точки прогноза выбран 1998 год: в этом году компьютер IBM обыграл чемпиона мира Каспарова в шахматы.
С этого момента в шахматы играть с компьютером бесполезно - он будет выигрывать у человека всегда.
Аналогичная ситуация: превосходство машины над человеком в области принятия управленческих решений в большинстве областей человеческой деятельности, прогнозировалась на 2015 год и в ряде других областей.
Как же IBM выполняет свой собственный прогноз? И выполняет ли? Ведь 2015 теперь уже совсем близок.
2 марта 2012 на конференции основных бизнес партнеров IBM в Новом Орлеане (США) вновь назначенная CEO IBM (впервые за 105-летнюю историю IBM - женщина) сделала следующие заявления:
- первоочередной задачей IBM на ближайшие 5 лет является создание нового поколения аналитических систем;
- в ближайшие 5 лет все компании на мировом рынке разделятся на победителей и побежденных в зависимости от качества их аналитических систем;
- 12 апреля 2012 года IBM объявит о коммерческой доступности экспертно решающей системы WATSON.
Это объявление WATSON состоялось.
IBM так представляет историю развития Watson:
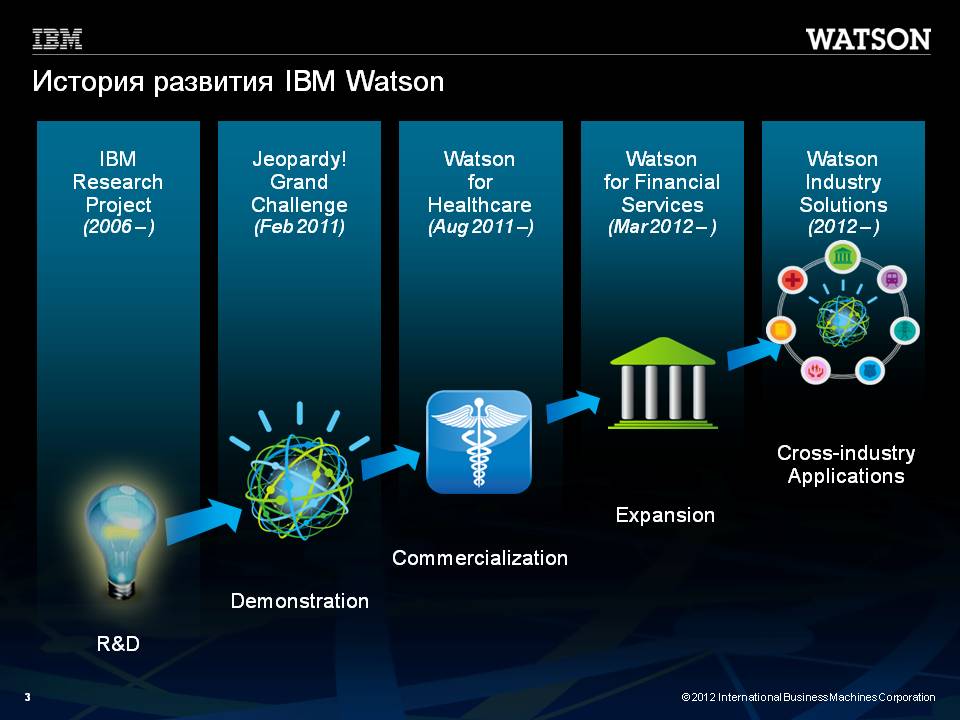
Рис. 2
Интересно, что старт исследовательскому проекту был дан через год после выхода стратегического прогноза по развитию ИТ.
В основу Watson положены три революционные технологии:
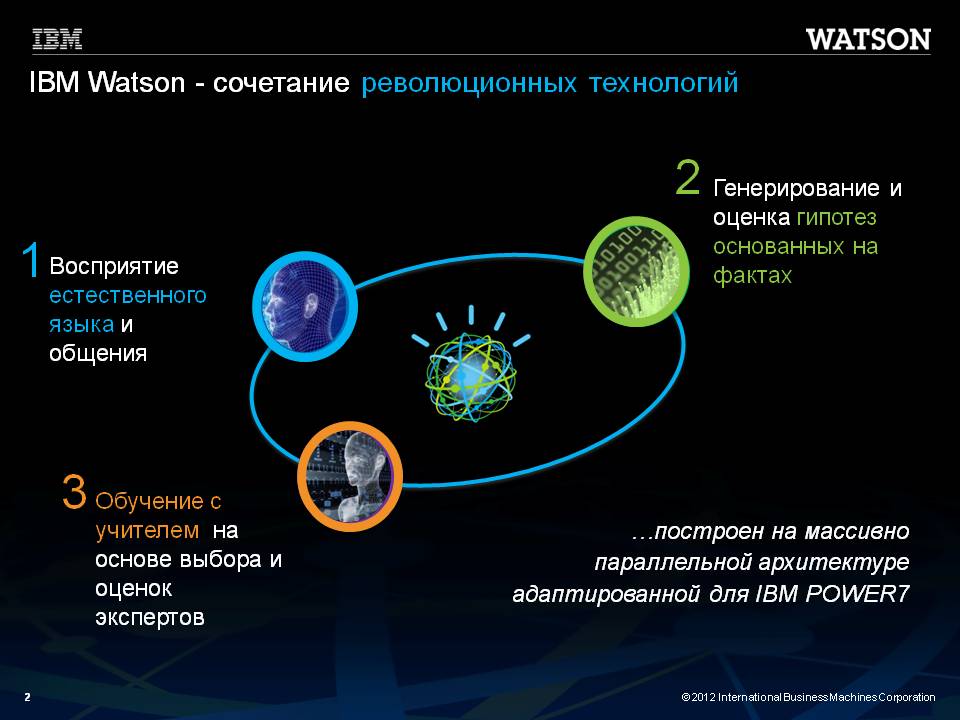
Рис. 3
Приведем краткую информацию по Watson, собранную по доступным нам источникам.
Watson названа в честь первого президента IBM Томаса Уотсона (Thomas J. Watson).
Watson построена по технологии DeepQA (Deep Question Answering), включающей генерацию гипотез, массовый сбор фактов, анализ и ранжирование гипотез на основе фактов (см. рис.)
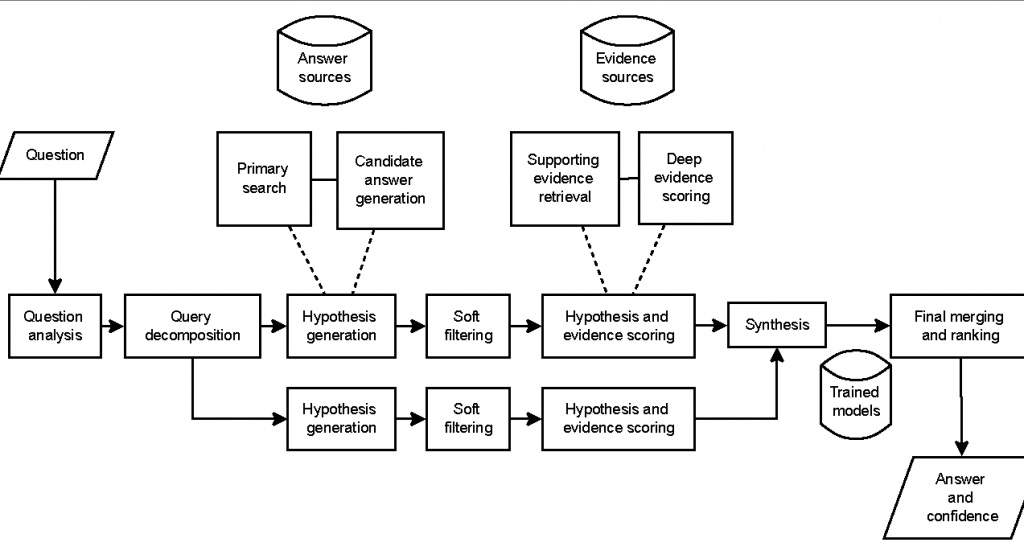
Инфраструктурно Watson реализован на 90 серверах IBM Power 750, каждый из которых содержит по 4 восьмиядерных процессора POWER7. Суммарная оперативная память Watson составляет 16 терабайт.
Команда IBM обеспечила и ЕЖЕДНЕВНО обеспечивает Watson миллионами документов, включая энциклопедии, словари, тезаурусы, новостные статьи, литературные работы. Watson также использует базы данных, таксономии и онтологии, особенно DBPedia, WordNet, и Yago. Watson может обрабатывать 500 Гигабайт в секунду, что эквивалентно миллиону книг.
Более 100 различных методов используются для анализа естественной речи, определения источников данных, генерации гипотез, поиска и ранжирования фактов, объединения и подтверждения гипотез.
В медицине Watson помогает анализировать специфические симптомы, историю болезни, историю наследственных заболевания, и выполнять синтез этих данных с доступной неструктурированной и структурированной медицинской информацией, включая медицинские книги и статьи. IBM поясняет, что Watson не пытается заменить врачей, но помогает им избегать ошибок и уточнять диагноз.
В итоге сегодня Watson первая и пока единственная система такого класса, реально претендующая на замещение человека при принятии Решений в цифровом мире. Наивысшее достижение в области IT.
В юбилейном выпуске журнала Популярная механика [2] приведены 10 интервью с ведущими учеными мира, обрисовывающими пределы нашего знания в биологии, физике, медицине, информационных технологиях.
Характерно, что в качестве наивысшего в мире достижения в области информационных технологий избрана экспертно-решающая система Watson.
В журнале приведено интервью с Дэвидом Ферруччи - руководителем разработки Watson, в котором он старается объяснить интервьюирующим его экспертам, что Watson пока не содержит искусственного интеллекта, по той простой причине, что ученым пока не понятно, что такое интеллект и как работает мозг. А всего лишь синтез новейших достижений в различных областях математики, лингвистики, ИТ.
Хотя внешне WATSON выглядит как система, обладающая искуственным интеллектом, да еще каким!
Основные возможности системы WATSON:
- Разговаривает с вами на естественном языке (английском), что само по себе не является каким - либо достижением.
- выиграла 3 года назад на американском телевидении в телевикторине Jeopardy (российский аналог - "Своя игра") в противоборстве с другими участниками: людьми.
- два года назад сдала на общих основаниях экзамены за 3-й курс медицинского университета и через два - три года планируется получение степени PhD в области медицины.
- осуществляет первичный прием пациентов в 30 госпиталях США, кроме опроса пациентов проводя анализ любых видов медицинских данных.
- является ведущим в США консультантом в области онкологии.
Известно также, что Watson проходит обучение в трех крупнейших американских банках и некоторых других областях.
Итак, цитата от Девида Ферручи [2]: "КОМПЬЮТЕР РЕШАЕТ ОТДЕЛЬНЫЕ ЗАДАЧИ ГОРАЗДО ЭФФЕКТИВНЕЕ ЧЕЛОВЕКА, но мыслить, как человек машина не может". Это про WATSON.
Гораздо важнее для практики выделенная большими буквами часть цитаты.
Истина в том, что круг задач, которые машина УЖЕ решает лучше чем человек, стремительно расширяется (от шахмат в 1998 году).
И если от качественных решений в медицине выигрывают все, то, например, в играх в экономику и финансы будут и проигравшие - те, для которых качество решений WATSON окажется недоступным.
Видимо, именно это имела в виду IBM CEO, когда предвещала, что в ближайшие пять лет все фирмы разделятся на победителей и побежденных в зависимости от качества их аналитики.
Исходя из изложенного, мы можем сделать вывод о том, что в традиционной схеме принятия решений рис. 1 появляется КАЧЕСТВЕННОЕ изменение: машина по все возрастающему кругу задач отбирает у человека роль Руководителя (в части функции: принятие решений).
В ходе цифровой революции борьба за повышение интеллектуальности решающего центра приводит и согласно прогнозам будет во все возрастающей степени приводить к замещению человека машиной при принятии решений. От аналитических к экспертно- решающим системам.
2.1.2 Специализированные ускорители обработки аналитических запросов к реляционным базам данных: скорая помощь аналитикам (людям и роботам).
Цифровая Реальность, в которой и ведется интеллектуальная борьба за выживание, быстро меняется во времени.
По Дарвину следует, что чем быстрее участники борьбы будут принимать адекватные изменению Реальности решения, тем выше их шансы на победу в конкурентной борьбе.
Если обратиться к Традиционной схеме принятия решений рис. 1, то очевидно, что ускорять следует исполнение всех трех бизнес процессов, предшествующих принятию Решения: П1, П2, П3.
Ускорители обработки запросов предназначены для ускорения процесса П3 - аналитической обработки накопленной информации с целью подготовки и оценки последствий различных вариантов решений.
Суть проблемы, на решение которой ориентированы ускорители, состоит в следующем.
Традиционные ИАС быстро обрабатывают запросы аналитиков к базе в том случае, если структура запросов и объекты поиска в базе заранее известны.
То есть, заранее определены: модель данных, логическая и физическая структуры реляционной базы.
Однако, аналитики высшего уровня заранее не могут определить для себя, какие именно запросы они будут задавать в базу. Более того известно, что последующие запросы будут наверняка изменяться в зависимости от ответов на предыдущие запросы.
В такой ситуации (нерегламентированные заранее запросы) ответы от базы будут поступать недопустимо медленно.
Известный выход: для ускорения получения ответов перепроектировать и переустановить базу - абсолютно неприемлем по времени. Тупик.
Специализированные ускорители обработки нерегламентных (непредвиденных при проектировании базы) запросов и предназначены для выхода из этого тупика в интересах аналитиков высшего уровня. Хотя являются скорой помошью для аналитиков любой квалификации: что людей, что роботов.
Доступными на рынке ускорителями являются, например: IBM Netezza, EMC ......
Идеи, на которых они базируются, в общем очевидны: массовый параллелизм и адаптивная динамическая перестройка структуры базы под запрос.
Общий вид и основная функциональность ускорителя IBM Netezza приведены на рисунке 4 из [3].
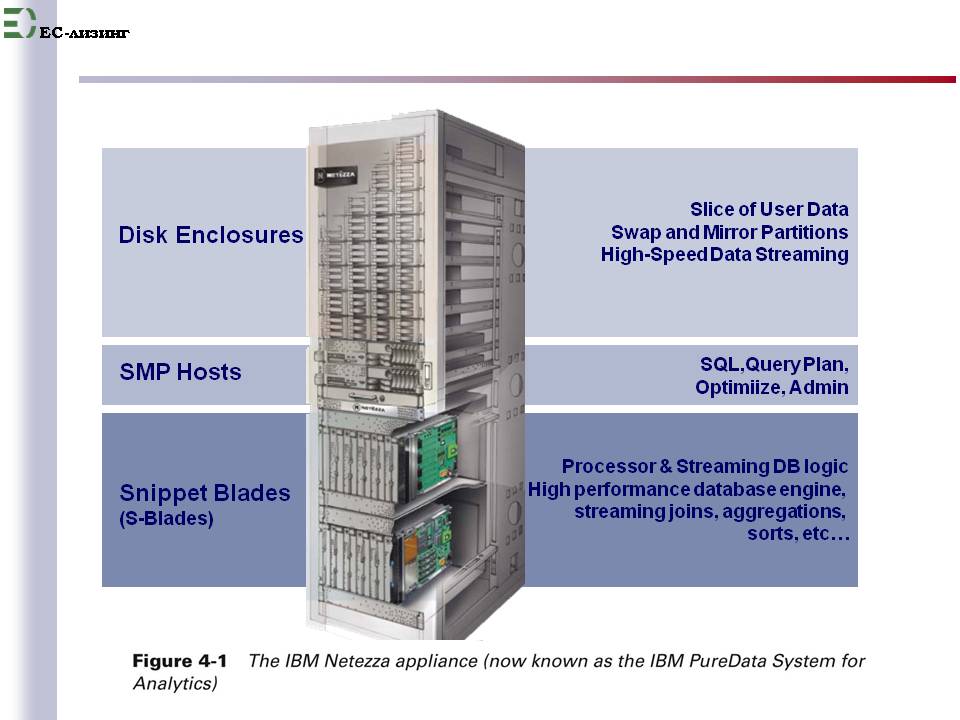
Рис. 4
Ускорение выполнения запросов в лучших примерах измеряется до 200 раз!!!
Для анализа данных с объемом до 1 петабайта в одном, представленном на рис. 4 , ящике.
А ящиков может быть и много. И это ведь без переделки приложения ВООБЩЕ! Просто ускоритель подключается как сервер базы приложения для SQL запросов любых видов.
1 - 2 дня на подключение и скорая помощь пришла.
2.1.3. Интеграция новых и старых технологий повышения интеллектульности решающего центра: "назад в будущее"
Примером интеграции абсолютно новых и традиционных технологий повышения качества решений может служить сконструированная IBM вокруг Netezza целая функционально полная платформа для аналитики и прогнозирования развития ситуаций, представленная на рис. 5 из [3].
Левая часть рисунка представляет состав технологий сбора данных, где наряду с давно применяемыми технологиями (Apache Hadoop для работы с неструктурированными данными всех видов и его усовершенствованного IBM варианта IBM infosphera BigInsight), показаны и новейшие технологии потоковой обработки, рассматриваемые в следующем разделе (IBM Infosphera Streams).
Центральная часть рисунка - ядро платформы, аналог корпоративного хранилища данных (КХД), но на основе Netezza (скорость, скорость!).
А правая часть рисунка представляет давно освоенный аналитиками состав продуктов анализа и прогнозирования: Cognos BI, IBM SPSS для построения статистических моделей и т. д,
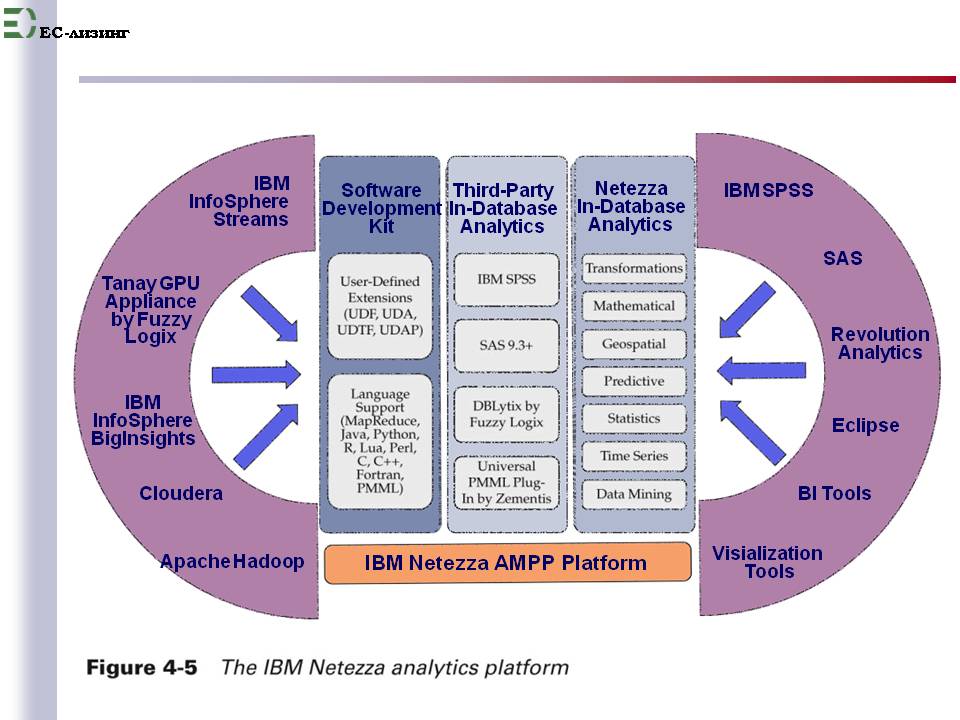
Рис. 5
Прагматичный синтез старого и нового, выводящий бизнес процесс принятия решений на основе СТРУКТУРИРОВАННЫХ данных на качественно новый уровень.
2.2. Технологии BD, влияющие на информированность решающего центра
А. Объем доступной информации цифрового мира и проблема проклятия размерности.
Любой решающий центр максимально информирован, если в своих решениях он так или иначе учитывает всю необходимую и достаточную для принятия решения информацию нашего цифрового мира (digital universe).
Как же велик объем этой ВСЕЙ информации нашего мира, другими словами как на самого деле велика эта big data (маленькими буквами)?
И каковы тенденции изменения этого объема во времени?
Интересующие нас оценки содержатся, например, в материале IDC, разработанном при спонсорской поддержке EMC [1].
На рис. 6 из этого материала приводится график ежегодного роста объема возникающей во всем мире информации по годам начиная с 2007 до 2011.
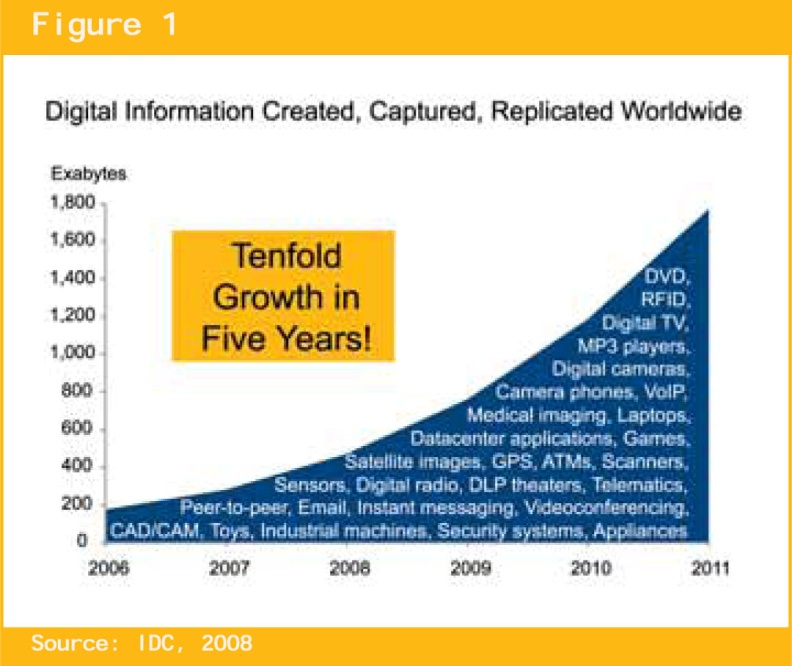
Рис. 6
Первое, что бросается в глаза это то, что этот объем действительно огромен: он измеряется в эксабайтах!
А второе - тенденция роста! При всей его огромности он еще (по мнению IDC) и возрастает в 10 раз каждые 5 лет.
Возникает закономерный общий вопрос: а какую часть из подобного объема постоянно возникающей информации мы можем в ПРИНЦИПЕ успеть запомнить с тем, чтобы на досуге разобраться, нет ли там чего-либо полезного для принятия наших Решений?
Ведь в случае невозможности сохранения эта информация как неотвратимо возникнет, так и безвозвратно пропадет!
Что может повлиять на информированность решающего центра.
Очевиден и ответ: сохранить можно объём возникающих данных, не превышающий имеющегося свободного объема всех сред хранения данных нашего мира текущего года!
Соотношения объемов ежегодно возникающих данных и объема данных, который можно в принципе ежегодно запоминать во всех средах хранения нашего мира представлены на рис. 7 из того же источника, где обозначено:
Синяя кривая - объем ежегодно возникающих данных в эксабайтах по годам,
Красная кривая - объем данных, который можно в принципе запомнить в текущем году из возникших.
Круговая диаграмма отражает процентные отношения запоминаемых объемов данных по средам хранения.
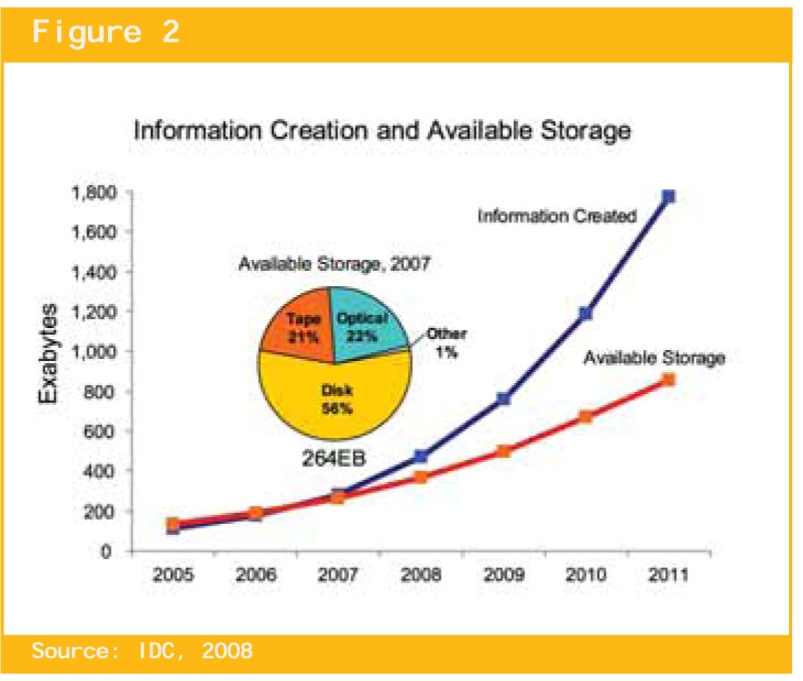
Рис. 7
Важнейшим выводом из рисунка 7 является тот факт, что начиная с 2007 объем возникающих ежегодно данных начинает во все возрастающей степени превышать объем данных, который мы могли бы в принципе запомнить!
И в 2011 более половины возникающих в цифровом мире данных уже пропадает навсегда бесследно! Безвозвратные потери мировых данных нарастают! Возникает проблема ПРОКЛЯТИЯ РАЗМЕРНОСТИ.
Мы во все возрастающей степени теряем представление о нашей РЕАЛЬНОСТИ в связи с ограниченными Возможностями хранения ее цифровых описаний.
Это явление можно назвать, например, амнезией (потерей памяти - а это название болезни) цифрового мира.
Можно долго рассуждать на тему о том, важная или не важная информация была утрачена, но поскольку мы ее не анализировали - то все эти рассуждения пустые. Потери МОГУТ повлиять на информированность решающего центра.
Как же лечить эту болезнь (амнезию цифрового мира), в принципе снижающую информированности решающего центра за счет безвозвратной утраты все возрастающей части мировых данных с сопутствующей утратой (возможно?) содержащегося в этих данных полезного для Решения контента?
В. Технологии BD, влияющие на информированность решающего центра
В.1: Идея BD номер 1 - ПОТОКОВАЯ ОБРАБОТКА (streaming): преодоление проклятия размерности при хранении данных.
Как нас учат психологи, давайте ответим на вечный вопрос: в чем ваша проблема, что вас беспокоит? Ну не можем мы запомнить всех мировых данных (памяти не хватает - а это непреодолимо), а поэтому возможно теряем контент.
Очевидно, что нам нужен именно контент. Если можно обойтись без запоминания первичных данных, то почему нет. Откуда же берется необходимость запоминания ВСЕЙ информации, порождаемой источником?
Да из исторически сложившихся и привычных способов анализа данных: мы сначала их копируем к себе и запоминаем, а потом начинаем в них копаться с целью выделения контента.
Так работают сейчас практически все значимые аналитические системы. При подобном подходе (запомнил - проанализировал) запоминается как сам контент, так и весь возможный шум, который мог бы быть выделен и уничтожен, но только в результате анализа данных, который при традиционном подходе СЛЕДУЕТ за запоминанием (extract - transform - load: ETL).
То есть нашей проблемой является наш же подход к анализу: запомнил - проанализировал.
Но ведь давным - давно в смежных областях (радиолокации, акустике, теории систем управления) существуют и принципиально иные по последовательности операторов подходы к анализу именно совершенно неструктурированных данных: например, алгоритмы фильтрации с целью выделения сигнала на фоне шума. Сначала выделение полезного сигнала на фоне шума, а затем анализ полезного сигнала и принятие решения.
Принципиальным при подобных подходах является тот факт, что НЕ требуется предварительного запоминания всего объема данных, порождаемого источником, а отделение полезного контента от шума производится ДО принятия решения и/или запоминания контента.
Streaming (ПОТОКОВАЯ обработка) - это одна из новых технологий BD, меняет порядок обработки данных от источника: вместо запомнил - обработал, появляется последовательность обработал - запомнил.
Описание подобной технологии, включенной, например, в состав платформы BIG DATA IBM содержится в [3,4].
Очевидно, чем выше доля устраняемого шума, тем меньше выделенного полезного контента придется запомнить для последующих принятий решений по историческим данным и тем ниже требования к объемам хранения.
Поскольку большинство источников работает в реальном времени, то и фильтрацию приходится производить в реальном времени - то есть быстро. В итоге streaming, снижая требование к памяти, повышает требования к производительности при фильтрации.
Фундаментальным пределом при потоковой обработке является не объем памяти, а производительность при фильтрации.
Ничего не дается даром.
Утешением является тот факт, что поскольку источники работают независимо, то при потоковой обработке возможен массовый параллелизм - то есть применение Больших ферм параллельно работающих компьютеров с возможностью их масштабирования.
Поток (stream) в этой технологии представляет из себя непрерывную последовательность элементов данных любых видов. Потоковое приложение может быть интерпретировано в виде графа, содержащего узлы, связанные направленными ветвями. В узлах графа располагаются операторы или адаптеры, обрабатывающие данные из потоков. Сами потоковые приложения могут разрабатываться как в графической, так и в текстовой форме.
На рис. 8 и 9 приведены фрагменты программы на языке потоковой обработки SPL (streams processing language от IBM) [4] в графической и структурной формах.
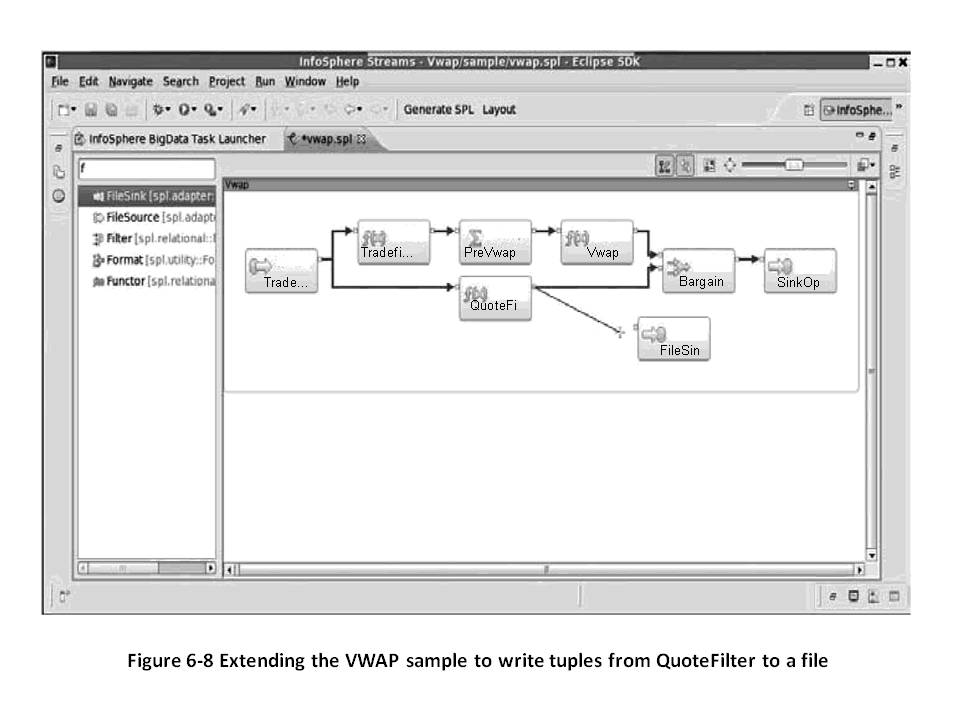
Рис. 8
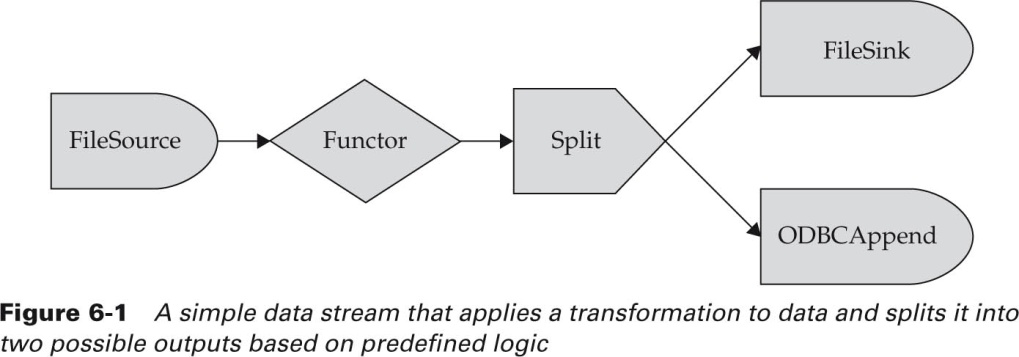
Рис. 9
Рекомендации по применению потоковой обработки связаны на бизнес уровне с двумя бизнес требованиями:
- Огромный (не помещающийся в память) объем данных для анализа, поступающий с предельной скоростью.
- Время реакции (анализа данных и синтеза решения) системы: миллисекунды.
- Любые типы источников.
Наличие любого из первых двух означенных факторов уже является рекомендацией для применения потоковой обработки. По сути, это рекомендации по работе с очень быстрыми источниками производящими очень большие объемы данных.
Для описания подобных реалий цифрового мира вводится и новый подход к классификации источников и данных [4].
Источники классифицируются по четырем измерениям вариативности (V4):
- скорости выдачи информации, объему выдаваемой информации, достоверности выдаваемой информации, способу выдачи информации.
И для некоторых типов источников применима ТОЛЬКО потоковая обработка: запоминать не успеете.
Данные же делятся на две категории:
- данные в покое (уже запомненные);
- данные в движении (поступающие от источника, но еще не запомненные).
Данным в покое ставится в соответствие море, а данным в движении Ниагарский водопад.
Очевидно, что ПОТОКОВАЯ обработка как метод анализа данных влияет как на философию, так и на технологию в Традиционной схеме принятия решений.
Например, в функции <Описание инфо потребности> рис 1 вместо традиционного: предоставьте среднюю зарплату по моей корпорации - появится что - то вроде: сформируйте мне психологический портрет инсайдера в моей корпорации и соберите по этому портрету все информацию по внутрикорпоративным и внешним источникам с целью его выявления.
В переводе на русский язык: пойди туда - не знаю куда, принеси то - не знаю что!
Эта фраза из сказки как нельзя лучше описывает изменения в философии принятия решений, вносимые потоковой обработкой:
- априорно состав, форма и географическое расположение источников в отличие от традиционной схемы рис. 1 неизвестны.
- если где-то и имеется полезный для решения контент, то он скорее всего сильно замусорен посторонней информацией - шумом.
Выручает тот факт, что проанализированы могут быть несравнимые с доступными традиционным технологиям объемы данных и любые типы источников. Поле поиска резко расширяется вплоть до всего киберпространства и нужны креативные идеи, сужающие его до условий задачи.
Возникающее принципиальное изменение подхода к работе с данными отражено на рис. 10 ИЗМЕНЕНИЕ ПАРАДИГМЫ.
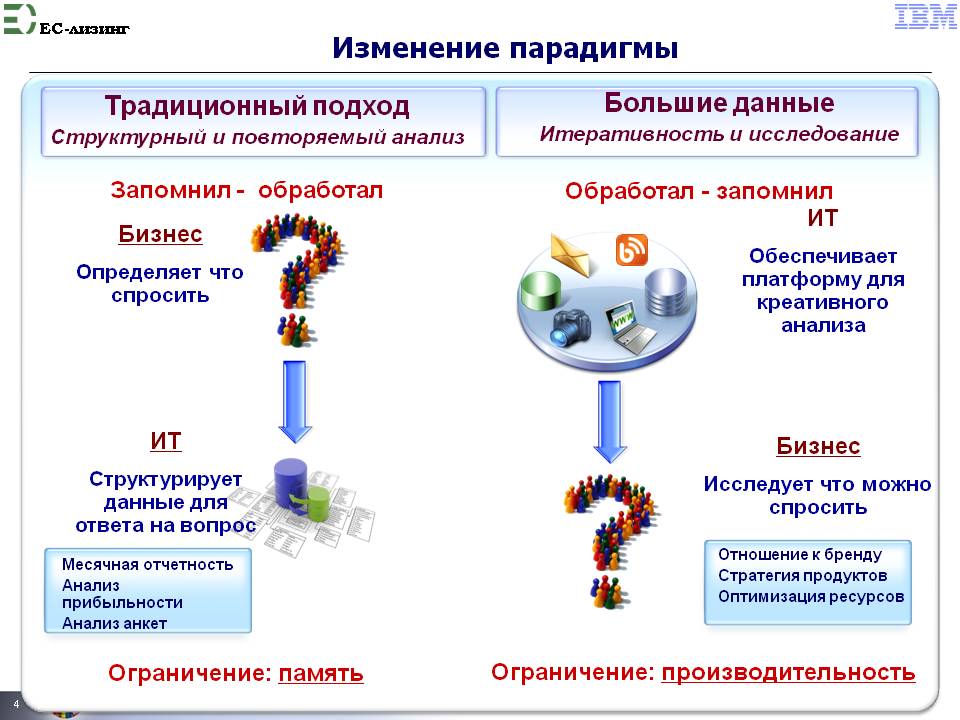
Рис. 10
Главное, что следует из рис. 10 - это изменение традиционных взаимоотношений и ролей бизнеса и ИТ: людей ИЗ БИЗНЕСА И ИТ надо переучивать на принципиально иные бизнес процессы и учить РАБОТАТЬ ВМЕСТЕ. Садиться вместе и думать, куда пойти (пойди туда - не знаю куда) из вариантов, представляемых платформой креативного анализа рис. 10.
. BIG DATA изменяет архитектуру бизнес процессов принятия решений, оргструктуру и роли персонала В ТРАДИЦИОННОЙ СХЕМЕ ПРИНЯТИЯ РЕШЕНИЙ.
На наш взгляд, именно в этом и состоит коренное отличие современной схемы принятия решений от традиционной рис. 1, порождаемое невиданными ранее технологическими возможностями по копанию в данных во всем киберпространстве.
С технологической точки зрения очевидно, что современная платформа для реализации ИАС должна обладать технологиями для работы как с данными в покое (структурированными и неструктурированными), так и с данными в движении (мощными потоками данных от любых типов источников).
Поэтому очевидно, что неотъемлемым свойством платформы должен быть инструмент интеграции всех видов данных для последующего комплексного анализа и принятия решения, в общем виде такой, как показано на рис. 11.
Рис. 11
B. 2. Идея BD номер 2: Обучающиеся Системы реального времени.
Целью обучения ИТ систем несомненно является улучшение их характеристик по двум базовым факторам, влияющим на качество решения:
информированности и интеллектуальности ИТ системы.
Любые идеи обучения людей или систем базируются на применении накопленных в прошлом знаний для принятия решений в настоящем либо прогнозировании будущего.
На идее обратной связи из прошлого в настоящее.
В популярной форме можно объяснить идею обучения ИТ систем на основе аналогии по сборке мозаики [3].
Действительно, гораздо легче найти место для очередного доставаемого из коробки элемента мозаики, если воссоздаваемый при сборке мозаики образ уже в значительной степени определился и уже проясняется, что же нам надо искать в коробке с неустановленными еще элементами мозаики.
То же самое можно сказать и по поводу очередного приходящего от источника элемента информации: уже накопленный контент оказывается полезным для отделения вновь пришедшего в составе новой порции данных контента от шума.
Здесь речь идет о системах с обратной связью с архитектурой, представленной на рис. 12 из [3].
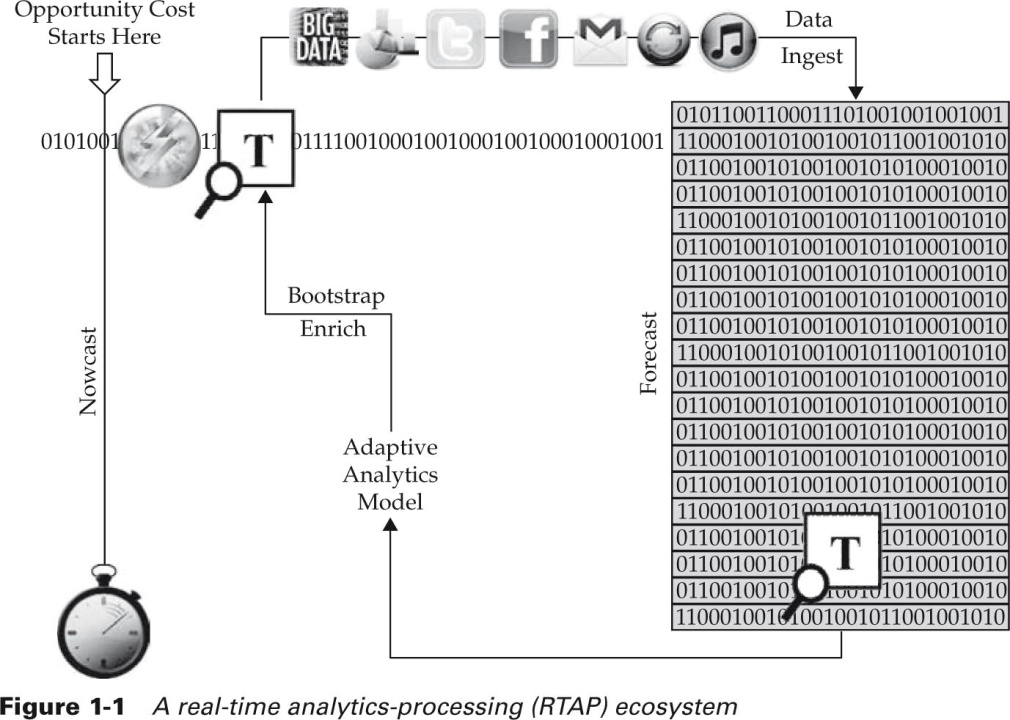
Рис. 12
Специально подчеркивается, что (как следует из торговых марок рис. 12) данная технология применима ко всем известным источникам.
Можно опять провести аналогию с мозаикой, а можно сказать, что по мере накопления исторического опыта принятия решения система с обратной связью как бы учится: становится все умнее и умнее и качество принимаемых ею решений повышается.
Например, обучение может состоять в накоплении метаданных: состава шаблонов для выделения полезного контента из входного потока.
Поскольку книга [3] написана ведущими сотрудниками IBM, а экспертно решающая система Watson также является изделием IBM, то можно предположить, что когда говорится о том, что Watson непрерывно учится, то речь идет именно об этом.
В целом можно сказать, что повышение эффективности выделения полезного сигнала на фоне шума при решении задач ИТ на основе адаптивных алгоритмов радикальным образом сказывается на показателях назначения системы в целом.
Снижаются требования к необходимому для принятия решения объему вычислений, к объемам памяти.
А в ряде случаев (по аналогии с адаптивными системами управления) принятие выигрышных решений вообще невозможно без применения адаптивных систем.
B.3. Идея BD номер 3: открыться цифровому миру.
В настоящее время большинство предприятий, во всяком случае в нашей стране, используют при принятии решений аналитические системы, базирующиеся на внутренней информации предприятия.
Поучительной для них может явиться информация, содержащаяся в приводимом рис. 13 из [1].
На рис. 13 классифицируется и оценивается ВСЯ информация цифрового мира (1,773 эксабайт в 2011 году) по трем категориям:
- Контент, генерируемый пользователями предприятий: 1, 234 эксабайта (желтый круг на рис.13).
- Контент, интересующий предприятия: 1,530 эксабайт (синий круг на рис. 13).
- Доля контента из генерируемого пользователями объема, интересная для предприятий (пересечение желтого и синего кругов на рис.13 - зеленая область на рис. 6: 1,000 эксабайт).
То есть, из ВСЕГО полезного контента, обеспечивавшего информированность решающего центра преприятий (1, 530 эксабайт), 1000 эксабайт находится ВНЕ предприятий и только 530 эксабайт внутри преприятий.
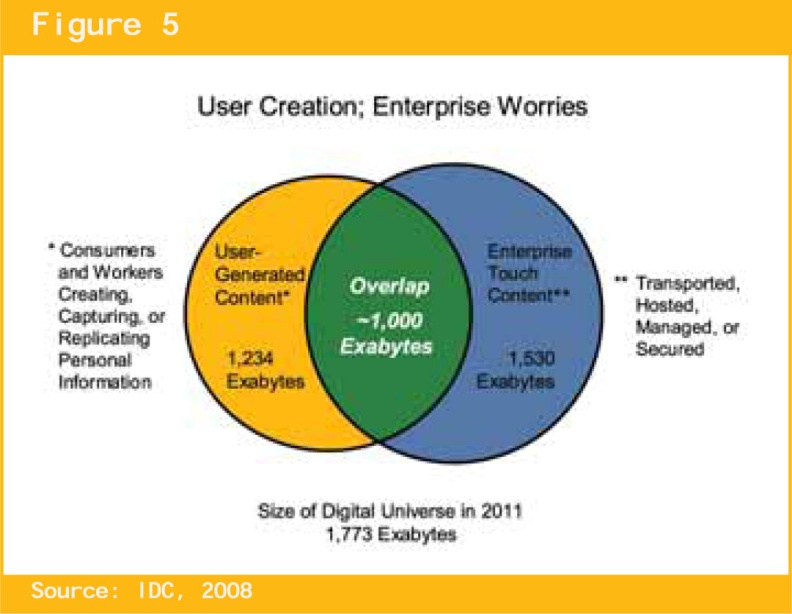
Рис. 13
Не забывая о внутреннем контенте предприятия, надо сконцентрироваться на изучении внешнего контента: открыться цифровому миру.
В.4. Идея BD номер 4: свободный адаптивный поиск и добыча информации: на войне как на войне.
В предыдущих разделах, мы остановились на ключевых технологических идеях BD по работе с информацией цифрового мира: как переварить огромные, ранее не доступные объемы информации в реальном времени, как отфильтровать контент от шума и куда следует обратиться за информацией.
Мы теперь понимаем, что большая часть нужной для выживания предприятия информации находится ВНЕ предприятия и знаем как ее обработать. Но как ее обнаружить и получить в интересах своего преприятия?
То есть как эффективно реализовать функцию П1 (добычу информации) Традиционной схемы принятия решений рис. 1, но уже в цифровом мире?
Ведь если добыча внешней для предприятия информации не организована, то и обрабатывать нечего. От качества оружия: поисковой платформы для обнаруженияи и рассмотрения всей необходимой информации как внутри преприятия, так и вне его зависит информированность решающего центра.
Способы добычи информации на протяжении веков делились на два класса: законные и незаконные.
Ничего не изменилось и сегодня и в цифровом мире.
Будем говорить, что законную добычу информации в киберпространстве осуществляют Поисковики, а незаконную (с точки зрения атакуемой стороны) осуществляют Разведчики (рис 1).
Реалиями киберпространства являются и те и другие.
Незаконные способы добычи информации реализуются через вирусы, черви и т. д.
Законные же способы добычи информации технологически реализуются через инструментарий поисковых платформ, предоставляющих для команд аналитиков (ИТ и бизнес) возможности свободного креативного поиска во всем киберпространстве в соответствии с парадигмой рис. 10.
На рис 14 приводится архитектура поисковой платформы Data Explorer - одной из поисковых платформ Big Data IBM для работы с ТЕКСТОВЫМИ данными в покое и движении от любых видов источников.
Этот инструмент позволяет вести во всем киберпространстве поиск, индексацию и визуализацию контента в интересах единой креативной команды предприятия [3].
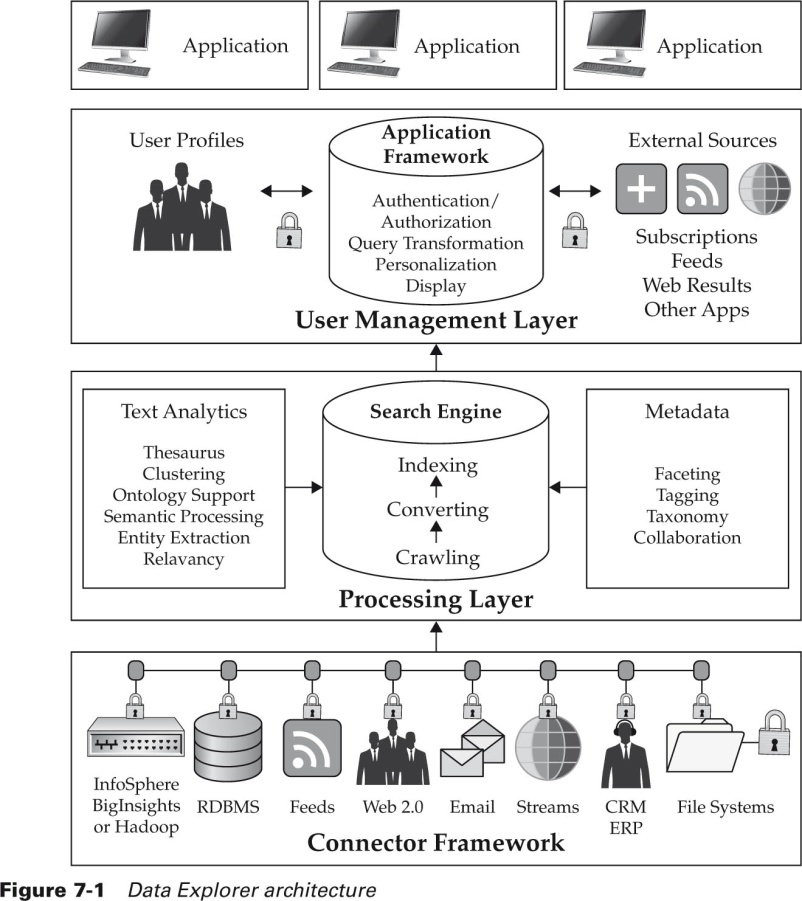
Рис. 14
IBM Data Explorer архитектурно разделен на четыре слоя:
- слой коннекторов предоставляет возможности стандартного доступа к множеству разнотипных внешних и внутренних для предприятия источников данных;
- процессинговый слой организует поиск источников в интересах и по заданиям креативной команды, нанесение найденных источников на карту поиска команды (навигацию), передачу информации для визуализации;
- пользовательский слой по сути организует ситуационный центр поиска и визуализации найденной информации для креативной команды;
- в слое приложений присутствует специфичная для данной креативной команды аналитика найденной информации, как раз и реализующая конкурентные преимущества.
В этом примере наглядно проявляются концептуальные отличия современной схемы принятия решений от Традиционной.
Data Explorer реализует концепцию свободного поиска по всему киберпространству под управлением и с обратной связью на креативную команду.
Платформа предоставляет команде заранее неизвестные ВОЗМОЖНОСТИ, которые в ходе поиска расширяются.
Что кардинально изменяет бизнес процесс доступа к искомой информации и вместе с ним оргструктуру и ролевую модель реализации бизнес процесса поиска и доступа к информации и последующего принятия решения.
Оба бизнес процесса (П1 и ПЗ) из статических и априорно предопределенных становятся динамическими и с обратными связями: уже полученная информация позволяет расширять или сужать круг поиска и повышать качество Решения по сравнению с Традиционной схемой.
В принципе, архитектурное решение и функциональный состав этого примера может служить прототипом для работы с любыми видами данных, а не только текстовыми.
Остановимся на незаконных способах добычи информации, но не с точки зрения атакующей стороны (война!), а с точки зрения атакуемой.
Как на архитектурном уровне просто и эффективно защитить информацию предприятия от незаконного сбора и /или уничтожения?
Обратимся к рис 15, на котором на качественном уровне отражена интегральная уязвимость вашей информации в зависимости от избранной Системотехнической платформы, где цветами обозначено: красный - высокая уязвимость, голубой - средняя, желтый - низкая, синий - нулевая.
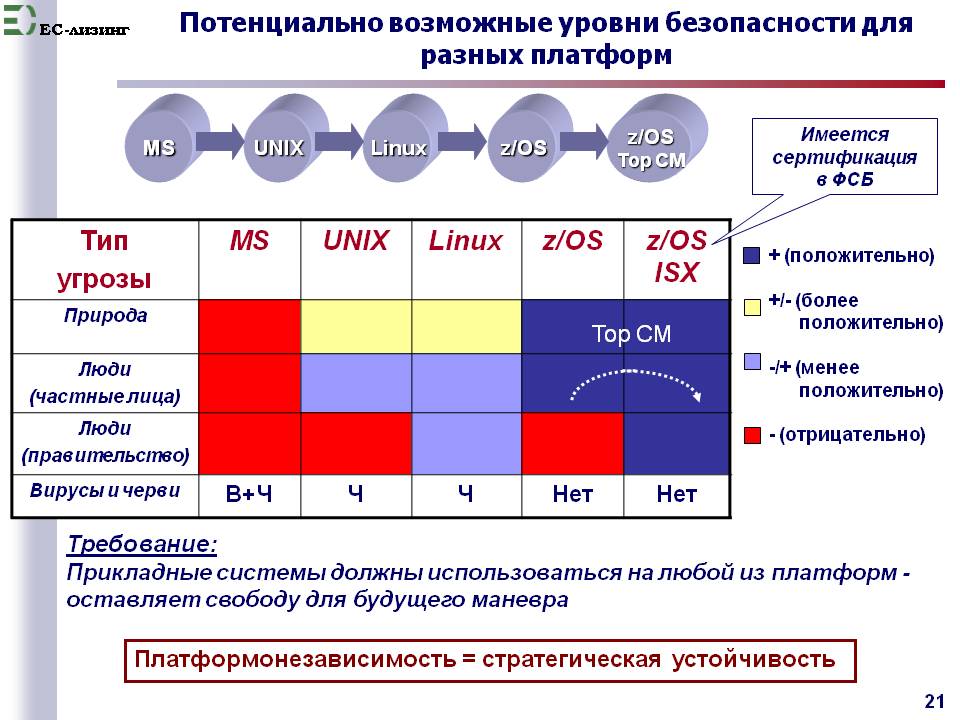
Рис. 15
Например, при выборе в качестве системотехнической платформы сервера базы IBM zOS вы изначально избавляетесь от всех внешних угроз (вирусов и червей для этой платформы НЕ СУЩЕСТВУЕТ, взломов не было никогда) и концентрируетесь на борьбе только с инсайдерами.
Наличие диспетчера доступа отечественного производства TOP CM обеспечивает целевой уровень защиты от внешних и внутрених угроз информации.
Вообщем, глядя на таблицу 15, можно прийти к выводу: ну зачем искать на свою "голову" приключения? Храните деньги (данные) в сберегательной кассе (сервере базы на z/OS)!
То есть думать надо не только на бизнес и технологическом уровнях, но и на системотехническом!
3. Реализация современных схем принятия решений на основе платформ BIG DATA в общем случае: сборка инструмента из конструктора платформы.
3.1. Общие соображения: философия сборки. Необходимые и достаточные условия получения конкурентных решений.
Любая платформа BIG DATA может быть уподоблена детскому конструктору: она содержит множество сопрягаемых между собой различных элементов, но оставляет ребенку возможности для творчества: сборки модели чего-либо.
В инструкции к конструктору на моей памяти содержались описания сборки моделей паровоза, самолета и т. д. Но можно было проявить фантазию и собрать что-то совершенно удивительное. Такое, чего нет ни у кого.
Целью сборки из конструктора платформы BIG DATA является получение на основе стандартных элементов современной схемы принятия решений, обеспечивающей компании конкурентные преимущества.
Но поскольку конструкторы (платформы) доступны всем, то все и могут начать собирать одинаковые паровозы по инструкции.
Откуда же взяться конкурентным преимуществам?
Где взять ТАКОЕ, чего нет ни у кого?
Если обратиться к рис. 10, то ответ напрашивается сам собой. Конструктор дает возможность собрать креативную платформу для принятия решений. Инструмент команды.
Но креативность платформы обеспечивается совокупным интеллектуальным потенциалом работающих с платформой людей: бизнес и ИТ вместе. Квалификацией команды.
Да взять хотя бы Watson c его очевидно подавляющими преимуществами как при принятии решений в телеиграх, так теперь и в медицине и далее везде.
IBM не скрывает, что конструктором из которого собирался Watson, является платформа IBM BIG DATA.
И платформа от Watson теперь стала коммерчески доступной. Но это совсем не означает, что даже получив в свои руки сконфигурированный под Watson инструмент кто угодно получит те же самые результаты.
Ведь с 2006 года на креативной платформе работал и работает огромный совместный коллектив медиков (и не только) и информатизаторов, обеспечивавший конкурентные преимущества.
Наличие качественного инструмента работы с цифровой Реальностью является только НЕОБХОДИМЫМ условием успеха, ДОСТАТОЧНЫМ условием является наличие креативной команды, в совершенстве владеющей инструментом.
3.2. Что мы будем собирать из конструтора? И какое изделие мы собираемся предъявлять на испытания?
Поскольку по документации (общедоступной во всяком случае для бизнес-партнеров IBM) конструктор IBM BIG DATA раскрывается более чем в 900 различных продуктов, шаблонов, готовых решений и т д., а уж число сочетаний этих элементов просто астрономическое, то при сборке должны быть сформулированы путеводные принципы сборки изделия (схемы принятия решения, оргструктуры, ролевой модели) под задачу.
Задачей же является построение и технологическое обеспечение из элементов конструктора Современной схемы принятия Решений, как минимум превосходящей уже существующую Традиционную схему принятия решений вашего предприятия.
А как максимум - обладающую конкурентными преимуществам в вашей отрасли бизнеса.
Мы теперь понимаем, что конкурентное преимущетсво схемы принятия решени определяется КРЕАТИВНОЙ КОМАНДОЙ, владеющей современной платформой для автоматизации подготовки и принятия решений.
Остановимся на определении технических требований к функциональности подобной современной платформы в общем виде.
Список функций, которые должны быть реализованы в составе платформы приведен в таблице на рис.16, где в левой части таблицы представлены искомые функции, а в правой части им посталены в соотвествие возможные варианты решений из состава продуктов IBM BIG DATA.

Рис 16. ТАБЛИЦА
В качестве упражнения можно поставить в соответствие набору базовых функций возможные варианты решениий из других платформ Big Data.
Все означенные в таблице элементы платформы в общем случае необходимы, однако эффективность работы КОМАНДЫ, определяется удобствами пользования ИНСТРУМЕНТОМ.
Поэтому наличие хорошего СИТУАЦИОННОГО ЦЕНТРА для управления всеми стадиями работы с данными при принятии решения (по аналогии с прототипом DATA EXPLORER рис. 14) обязательно.
. Очевидно, что все обратные связи между стратегиями: поиска и добычи данных, анализа данных, подготовки и передачи вариантов Решения Руководителю СУЩЕСТВУТ и ЗАМЫКАЮТСЯ через креативную команду, работающую на ситуационном центре.
Причем в отличие от Традиционной схемы, они (обратные связи) НЕ являются априорно статичными, а ОБЯЗАНЫ быстро изменяться во времени:
- по результатам уже произведенного поиска;
- по реакциям Реальности на уже принятые решения.
И конкурентные преимущества определяются качеством работы КРЕАТИВНОЙ команды: качеством работы ЛЮДЕЙ.
То есть со звездных высот надо опуститься на грешную землю и сказать: как и ранее мы имеем дело с человеко-машинной системой. Люди и средства автоматизации их деятельности. 34 ГОСТ. Автоматизированные системы (АС).
Система обеспечения жизненного цикла. Оргструктура. Ролевая модель. Процессы и процедуры.
Проза жизни.
Большие данные Большими данными, а внедрять-то придется АС по 34 ГОСТу, включающему покупные изделия: детали из конструктора и инфраструктурные компоненты.
Пример Watson не является исключением: решения принимает собственно экспертная система, а ее обучение, постановку отраслевых задач и сбор и анализ информации под задачу проводится Креативной командой Watson.
Инфраструктурно же "мозг" Watson реализован на идеях массово-параллельных вычислений, адаптированных под вычислительную платформу IBM power 7.
В настоящее время доступ к результатам деятельности Watson производится через облако IBM.
3.3 Немножко о составе конструктора на примере IBM BIG DATA.
Компонентная схема конструктора представлена на рис. 17 , где в квадрате Streams проводится классификация компонентов конструктора для направления streams.
По аналогичной схеме классификация проводится и по трем другим направлениям, обозначенным прямоугольниками разных цветов.
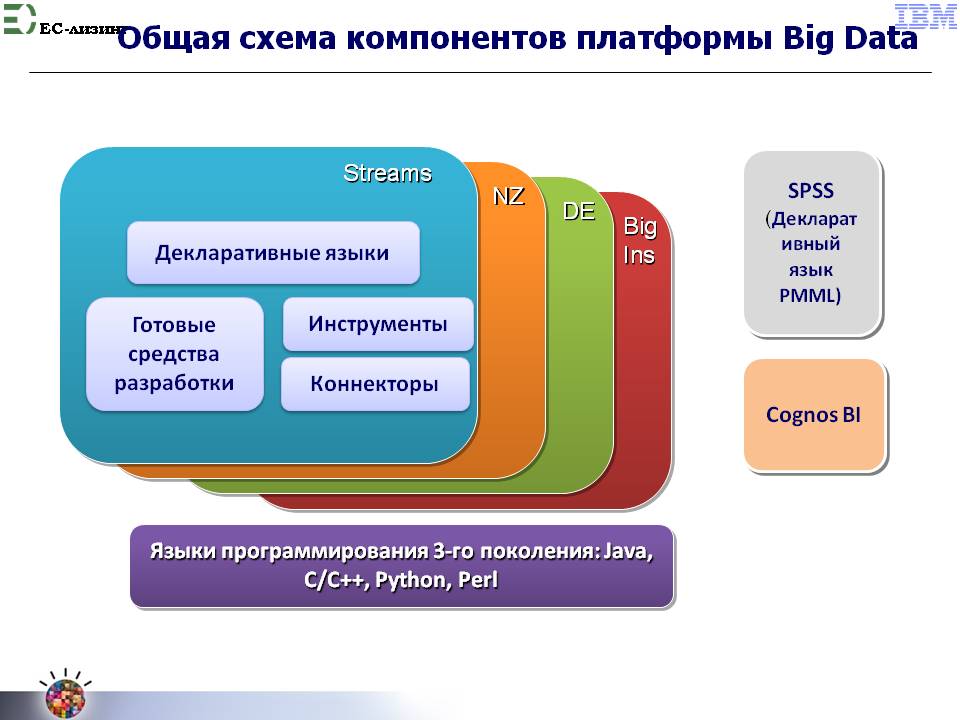
Рис. 17
NZ - решения для структурированных данных на основе Nettezza (например, рис. 5 ).
DE - ранее рассмотренная функционально завершенная платформа Data Explorer и средства ее интеграции с другими компонентами платформы Big Data IBM.
BigInsight (Hadoop) - средство работы со всеми типами данных в покое и его средства интеграции в платформу.
Отдельно представлены общезначимые средства, применимые ко всем направлениям работы с данными:
- платформонезависимые языки написания собственных приложений;
- инструмент статистического анализа и прогнозирования SPSS (куплен IBM 4 года назад);
- общеизвестный COGNOS (куплен IBM 7 лет назад).
Общезначимые средства предназначены для создания собственных приложений анализа данных и построения прогнозов для любых напралений работы с данными платформы.
Рассмотрим в качестве примера новейшую технологию IBM Streams, поскольку она самодостаточна и может работать как с данными в покое, так и с данными в движении любых типов.
С 2002 года эта технология разрабатывается IBM в интересах крупнейших госзаказчиков США. Для решения задачи мгновенного реагирования на любые изменения Реальности по любым видам источников. Она же является Основой механизмов взаимодействия Watson с внешней средой.
Обратимся к рис. 18, на макроуровне представляющем функциональные возможности технологии Streams.
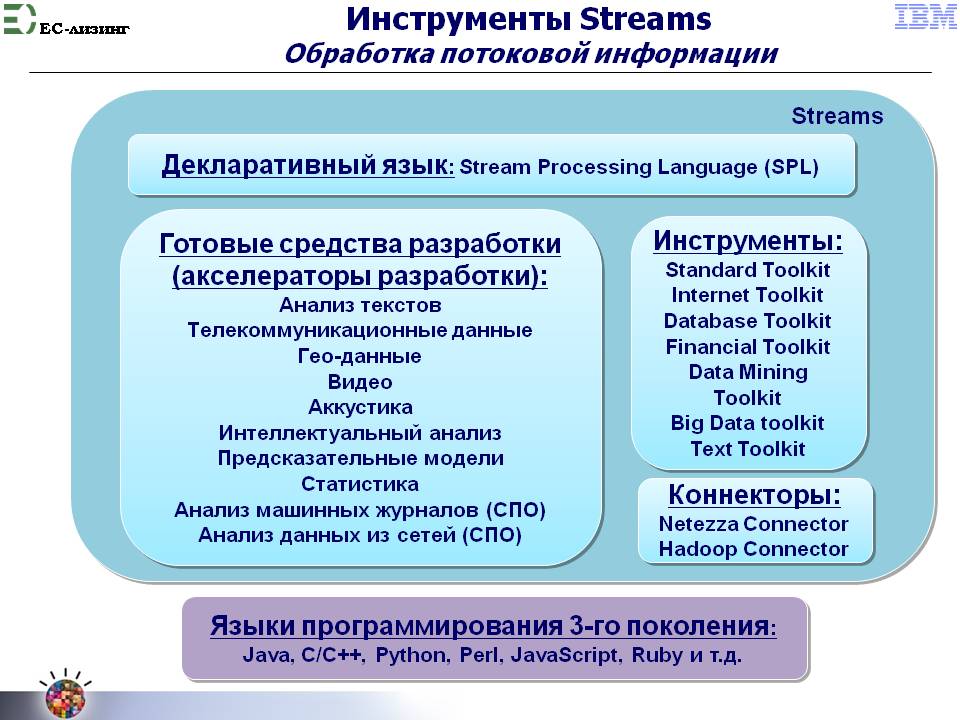
Рис. 18
Слой коннекторов (по аналогии Data explorer) в этой технологии создается на основе декларативного языка SPL (примеры - рис 8 и 9).
Предполагается, но не обязательно, применение готовых коннекторов из библиотеки к любым видам данных (см. Рис 18).
Спецификой Streams является тот факт, что если решение должно быть мгновенным, то времени на запоминание и последующее копание в данных уже нет и решение принимается сразу в потоке.
Запоминание как самого решения, так и полученных и отфильтрованных в потоке данных производится либо в среду Netezza (структурированные данные, реляционный подход), либо в среду Hadoop (файловая система, любые Виды данных).
Связь между блоком коннекторов Streams и блоком хранения добытой информации для процессингового слоя (опять по аналогии с Data Rxplorer - идем по схеме) в конструкторе предусмотрена в виде готовых коннекторов от Streams к Netezza и Hadoop (см рис. 18).
Необходимые для процессингового слоя Data Explorer поиск данных в покое и навигация (фиксация источников на карте поиска) реализуются механизмами Hadoop (см. Рис 17 и 19).
Там же присутствует и механизм реализации обратной связи для фильтрации входных данных (Master data Management server), функционально представленный рис. 12.
Можете поверить, что этот конструктор из более чем 900 элементов достаточно полон сам по себе, при этом включает встроенные средства функционального развития.
Раскроем для полноты картины основной инструмент работы с данными в покое: BigInsight - созданный IBM на основе Apache Hadoop. То есть распределенной файловой системы Open Source.
Поскольку сам по себе Hadoop в отличие от Streams известен уже много лет, то нет целесообразности говорить о нем подробно.

рис. 19
Два других направления: Netezza и Data explorer уже были рассмотрено ранее.
4. Заключение: что происходит с Традиционной схемой принятия решений рис. 1?
Пришло время выполнить данное в разделе 1 обещание и рассмотреть основные изменения в Традиционной схеме решений, порожденные как все возрастающей оцифровкой Реальности, так и появлением совокупности Технологий Big Data.
Рассмотреть на уровне оргструктуры и ролевой модели: действий людей.
4.1. Революция: решения принимают роботы, а не люди.
Человек покидает мировую сцену принятия решений и садится в партер в роли наблюдателя.
На наш взгляд, наиболее революционным из изменений в Традиционной схеме принятия решений является переход функции Руководителя (в части принятия решений) от человека к экспертно решающей сиситеме.
Функция Руководителя <задание инфо потребности> хотя и видоизменяется, но пока остается за человеком. Фирмами (пока еще) юридически командуют люди.
Уместно показать набор из трех сервисов, реализуемых экспертно-решающей системой Watson (рис. 20) при обсуждении решаемых проблем с людьми и последующего САМОСТОЯТЕЛЬНОГО принятия решения.
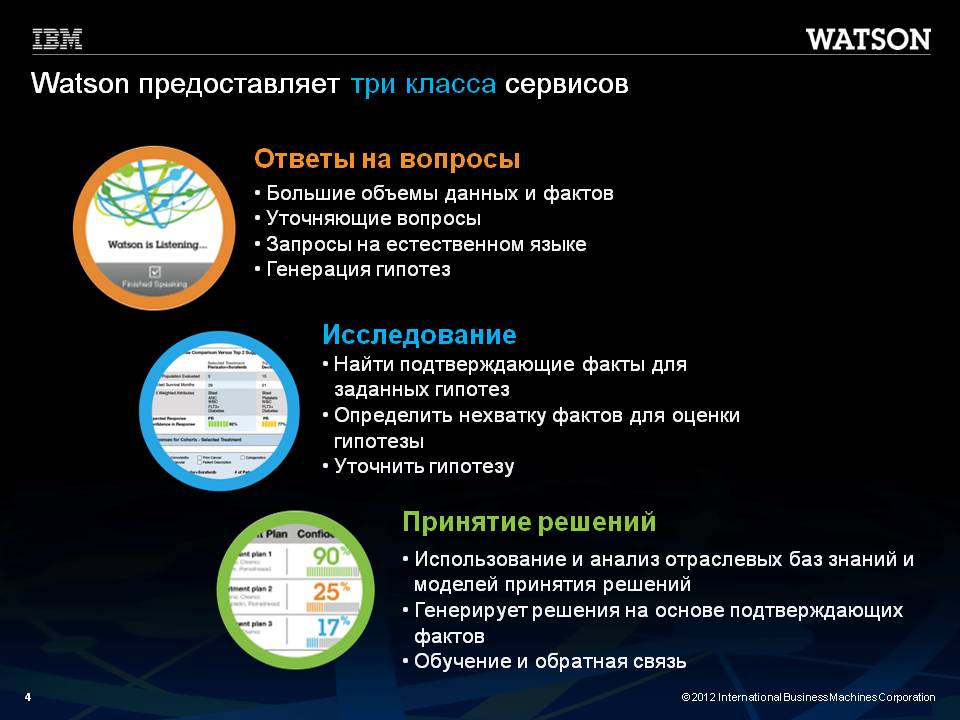
Рис. 20
Процесс принятия решения состоит из: выбора ГИПОТЕЗЫ, в наибольшей степени отвечающей имеющимся фактам. Запроса недостающих фактов, подтверждающих ГИПОТЕЗУ. Признания ГИПОТЕЗЫ РЕШЕНИЕМ.
А затем предоставления принятого решения на подтверждение CEO так, как это показано на рис. 21.
Состав возможностей Watson впечатляет.
С учетом этого состава возможностей приведем эскиз Современной схемы принятия решений с применением экспертно- решающей системы .
4.2. Эволюция: люди пока остаются, но их роли изменяются.
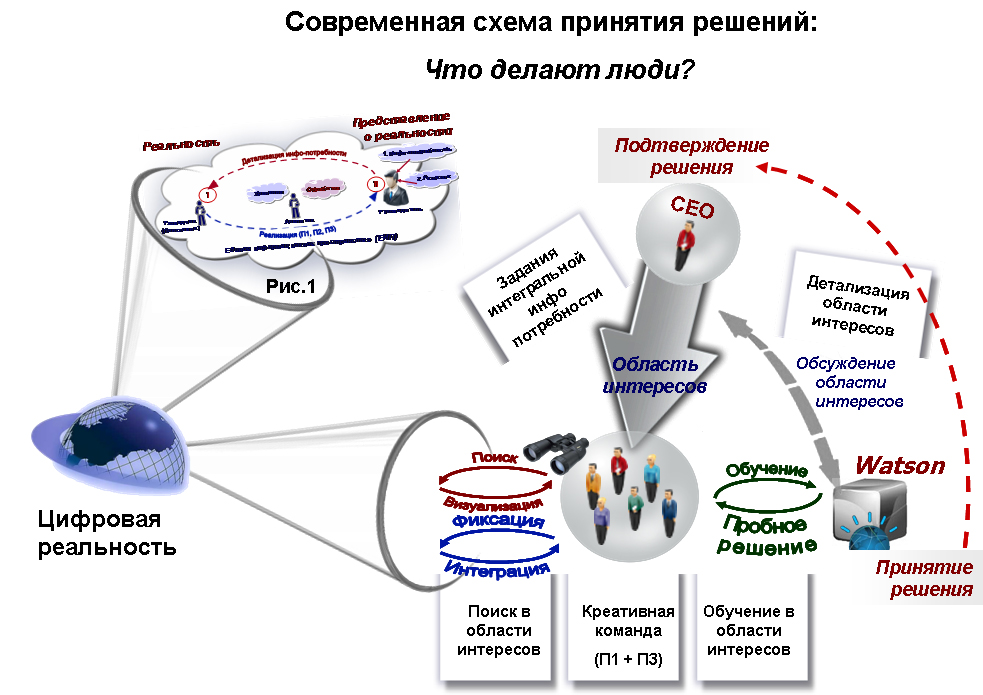
Рис. 21
Итак, различия в ролях людей в Традиционной Рис.1 и Современной Рис. 21 схемах принятия решений.
Чего уж ТОЧНО не было в роли пока еще РУКОВОДИТЕЛЯ (рис.1, а теперь CEO на рис. 21) - так это общения на естественном языке с роботом при обсуждении вариантов развития событий (обсуждения гипотез). Отрицания роботом предложений РУКОВОДИТЕЛЯ по решениям на основе ФАКТОВ (отрицания гипотез на основе фактов).
Чистый Голливуд!
Но таков ВЕКТОР РАЗВИТИЯ.
О чем НИКОГДА не думали АНАЛИТИКИ (от рис. 1 к рис. 21), что им придется обучать РОБОТА, который будет все более и более замещать их при общении с юридическим РУКОВОДИТЕЛЕМ.
О чем не имели представления ПОИСКОВИКИ И РАЗВЕДЧИКИ (рис.1), что роль ЛЮДЕЙ в количественном отношении по этим функциям сходит на нет и в законной коммерческой деятельности ее совсем не видно.
Роль переместилась в состав ролей Креативной команды ситуационного центра.
Для поиска и добычи информации не придется покидать помещение Ситуационного центра, тем более ездить в другие города и страны.
Что же остается?
1. Целеполагание (объявление области интересов - задание инфо потребности по старому) - пока остается за человеком: РУКОВОДИТЕЛЕМ.
На какую тему будем копаться в киберпространстве?
2. Разработка и реализация стратегии поиска и получения информации о Реальности (функции П1 и П3) рис.1 остаются за людьми, интегрируются в одном процессе и концентрируются в Креативной команде.
ПОИСК становится свободным (во всем киберпространстве) и итеративным (см. Рис. 21).
То есть, как и следовало ожидать, вековые функции РУКОВОДИТЕЛЯ, АНАЛИТИКА, РАЗВЕДЧИКА никуда не делись, просто во все большей степени доля работы средств автоматизации по отношению к доле работ людей возрастает.
А традиционная cхема принятия решений = современная схема принятия решений - минус компьютеры.
Частный случай, но все функции и роли Традиционной схемы сохранены, только перекомпанованы в оргструктуре: назад, в будущее.
4.3 Где то звено, за которое можно вытащить всю цепь?
Золотым фондом предприятия в эпоху цифровой революции является коллективный интеллектуальный потенциал Креативной команды, реализующей совокупность функций рис. 21.
Именно он в конечном счете определяет две базовые составляющие качества принимаемых решений: информированность и интеллектуальность Решающего центра (см. Раздел 1). И, в конечном счете, конкурентоспособность предприятия.
Ничего нового: качество команды управленцев - проблема жизни и смерти фирмы.
Проблема в том, что эта команда управленцев перемещается в Ситуационный центр и должна одинаково хорошо владеть как ИТ технологиями, так и бизнес технологиями.
Для CEO проблема: где брать таких разносторонних людей, а для CIO - чему и как их учить.
В прошлом лучшие аналитики вырастали из ИТ специалистов. А что будет в будущем - посмотрим.