В информационный век успех компаний и отдельных людей все чаще зависит от того, как быстро и эффективно они превращают огромные объемы данных в полезную информацию. Потребность в инструментах, способных организовывать и обогатить данные, будь то обработка сотен или тысяч личных почтовых сообщений в день или определение намерений пользователей по петабайтам содержания блогов, велика как никогда. Здесь-то и кроются предпосылки и обещания машинного обучения и проекта, с которым знакомит эта статья: Apache Mahout.
Машинное обучение ― это подраздел искусственного интеллекта, который занимается методами, позволяющими компьютерам улучшать результаты своей работы, основываясь на предыдущем опыте. Оно тесно связано с интеллектуальным анализом данных и часто использует методы, заимствованные из статистики, теории вероятностей, распознавания образов и целого ряда других областей знаний. Машинное обучение ― не новая, но, несомненно, развивающаяся область. Алгоритмы машинного обучения внедрили в свои приложения многие крупные компании, включая IBM®, Google, Amazon, Yahoo! и Facebook. Гораздо больше компаний выиграют от использования в своих приложениях машинного обучения для того, чтобы учиться у пользователей и на прошлых ситуациях.
После краткого обзора понятий машинного обучения я познакомлю читателей с особенностями, историей и целями проекта Apache Mahout. Затем покажу, как использовать Mahout для решения некоторых интересных задач машинного обучения с использованием свободно доступного набора данных Википедии.
Область применения машинного обучения простирается от игр до изобличения мошенничества и анализа фондового рынка. Оно используется для построения таких систем, как Netflix и Amazon, которые рекомендуют пользователям товары на основе прошлых покупок или находят все новостные стати на одну и ту же тему за день. Оно может использоваться и для автоматической классификации Web-страниц по жанрам (спорт, экономика, война и т. д.) или для того чтобы помечать сообщения электронной почты как спам. Областей применения машинного обучения столько, что я не смогу охватить их все в этой статье.
Для решения практических задач используется несколько подходов к машинному обучению. Я сосредоточусь на двух наиболее известных - контролируемом и неконтролируемом обучении - потому, что это основные подходы, поддерживаемые Mahout.
Контролируемое обучение связано с обучением функции по специально размеченным учебным данным с целью предсказания значений любых допустимых входных данных. Типичными примерами контролируемого обучения является классификация сообщений электронной почты для выявления спама, маркировка Web-страниц в соответствии с их жанром и распознавание рукописного текста. Существует множество алгоритмов контролируемого обучения, наиболее распространенными из которых являются нейронные сети, метод опорных векторов и наивный байесовский классификатор.
Неконтролируемое обучение, как легко догадаться, пытается извлекать пользу из данных без каких-либо примеров правильного или неправильного поведения. Чаще всего оно используется для распределения подобных исходных данных по логическим группам. Также может использоваться и для уменьшения размерности набора данных, чтобы сосредоточиться на наиболее полезных атрибутах, или для выявления тенденций. Типичными подходами к неконтролируемому обучению являются метод k-средних, иерархическая кластеризация и самоорганизующиеся карты.
В этой статье я сосредоточусь на трех конкретных задачах машинного обучения, которые в настоящее время реализованы в Mahout. Это также три области, которые довольно широко применяются в реальных приложениях:
- коллаборативная фильтрация,
- кластеризация,
- категоризация.
Прежде чем перейти к реализации каждой из этих задач в Mahout, я подробнее рассмотрю их на концептуальном уровне.
Коллаборативная фильтрация (CF) ― это метод, популяризированный Amazon и другими, при котором информация от пользователей, такая как рейтинги, "клики" и покупки, применяется для предоставления рекомендаций другим пользователям сайта. С помощью CF часто рекомендуют потребительские товары, такие как книги, музыка и фильмы, но применяют и в других приложениях, где множество субъектов сотрудничает для сужения круга рассматриваемых данных. CF в действии можно увидеть на сайте Amazon (см. рисунок 1).
Рисунок 1. Пример коллаборативного фильтра на Amazon
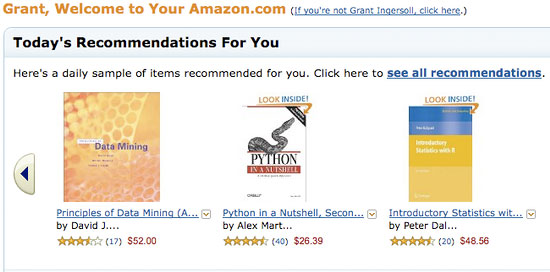
CF-приложения дают рекомендации текущему пользователю системы с учетом совокупности пользователей и товаров. Обычно используются четыре способа получения рекомендаций:
- на основе пользователей: предметы рекомендуются путем поиска аналогичных пользователей. Этот способ часто бывает трудно масштабировать ввиду динамической природы пользователей;
- на основе предметов: для выдачи рекомендаций ищутся аналогии между предметами. Предметы обычно меняются не так часто, и расчеты можно производить в автономном режиме;
- slope-One: очень быстрый и простой подход к получению рекомендаций на основе предметов, применимый, когда пользователи присваивают рейтинги (а не просто предпочтения "да-нет");
- на основе модели: вырабатывает рекомендации, основанные на разработке модели пользователей и их рейтингов.
В конечном итоге при всех подходах CF рассчитывается степень сходства между пользователями и оцениваемыми ими предметами. Существует много способов вычисления сходства, и большинство CF-систем позволяет подключать различные меры, чтобы можно было определить, какая из них лучше всего подходит для тех или иных данных.
При больших наборах данных, текстовых или числовых, часто бывает полезно автоматически объединять их в группы ― или кластеры ― подобных элементов. Например, имея все новости за день из всех газет в США, можно попробовать автоматически сгруппировать все статьи на одну и ту же тему; тогда читатель может сосредоточиться на определенных кластерах и статьях без необходимости прочитывать множество статей на другие темы. Еще один пример: имея показания датчиков машины с течением времени, можно сгруппировать результаты таким образом, чтобы отличать нормальную работу от аномальной.
Как и в случае CF, при кластеризации вычисляются аналогии между элементами коллекции, но задача состоит лишь в том, чтобы сгруппировать похожие элементы. Во многих реализациях кластеризации элементы коллекции представлены векторами в n-мерном пространстве. Имея векторы, можно рассчитать расстояние между двумя элементами с применением таких мер, как манхэттенское расстояние, евклидово расстояние или мера Охаи. Затем можно рассчитывать фактические кластеры, группируя элементы, расположенные близко друг к другу.
Существует много подходов к расчету кластеров, каждый со своими преимуществами и недостатками. Некоторые подходы работают снизу вверх, создавая большие кластеры из меньших, тогда как другие разбивают большой кластер на все более мелкие. Оба подхода имеют критерии выхода из процесса в определенный момент, прежде чем распасться на тривиальные кластеры (все элементы в одном кластере или каждый элемент в своем собственном кластере). В число популярных подходов входят k-средние и иерархическая кластеризация. Mahout, как я покажу позже, предлагает несколько различных способов кластеризации.
Цель категоризации (часто ее также называют классификацией) - помечать незнакомые документы, таким образом объединяя их в группы. При многих подходах к классификации в машинном обучении рассчитывают разнообразные статистические параметры, связывая особенности документов с определенной меткой, чтобы создать модель, которую позднее можно будет использовать для классификации незнакомых документов. Например, простой подход к классификации может заключаться в том, чтобы хранить информацию о словах, ассоциирующихся с меткой, и о встречаемости этих слов для данной метки. Тогда при классифицировании нового документа слова, встречающиеся в документе, проверяются по модели, вычисляются вероятности, и выводится лучший результат, обычно вместе с оценкой степени доверия к этому результату.
Для классификации могут использоваться слова, весовые коэффициенты этих слов (например, частотные), части речи и т.п. Конечно, на самом деле можно учитывать все, что помогает связать документ с меткой и может быть включено в алгоритм.
Область машинного обучения велика и сложна. Вместо того чтобы вдаваться в теорию, что сделать здесь надлежащим образом все равно не удастся, я перейду к Mahout и его использованию.
Apache Mahout ― это новый открытый проект Apache Software Foundation (ASF), основной целью которого является создание масштабируемых алгоритмов машинного обучения, которые предлагаются для бесплатного использования по лицензии Apache. Проекту второй год, и на его счету один публичный выпуск. Mahout содержит реализации кластеризации, категоризации, CF и эволюционного программирования. Более того, там где это разумно, он использует библиотеку Apache Hadoop, что позволяет Mahout эффективно масштабироваться в облаке.
- строить и поддерживать сообщество пользователей и участников, так чтобы код жил дольше участия любого конкретного участника или финансирования любой конкретной компании или университета;
- сосредоточиться на реальных, практических применениях, а не передовых исследованиях или непроверенных технологиях;
- обеспечить качественную документацию и примеры.
Относительно молодой для проектов с открытым исходным кодом, Mahout, тем не менее, уже обладает широкими функциональными возможностями, особенно в части кластеризации и CF. Основные функциональные возможности Mahout:
- Taste CF. Taste - это открытый проект CF, основанный Шоном Оуэном на SourceForge и подаренный Mahout в 2008 году;
- несколько реализаций кластеризации с поддержкой Map-Reduce, k-Means, fuzzy k-Means, Canopy, Dirichlet и Mean-Shift;
- распределенные реализации алгоритмов наивной байесовской классификации и комплементарной наивной байесовской классификации;
- возможности распределенной функции приспособленности для эволюционного программирования;
- библиотеки для матричных и векторных вычислений;
- примеры всех вышеупомянутых алгоритмов.
Получить Mahout и начать работать относительно легко. Необходимо установить следующие компоненты:
- JDK 1.6 или более позднюю версию;
- Ant 1.7 или более позднюю версию;
- если вы хотите писать исходный код Mahout, то Maven версии 2.0.9 или 2.0.10.
Необходим также пример кода для этой статьи (см. раздел Загрузка), в который входит копия Mahout и его зависимости. Чтобы установить пример кода, выполните следующие действия.
unzip sample.zipcd apache-mahout-examplesant install
На шаге 3 загружаются необходимые файлы Википедии и компилируется код. Используемый файл Википедии содержит примерно 2,5 гигабайт данных, так что время загрузки будет зависеть от пропускной способности соединения.
Создание механизма рекомендаций
В настоящее время Mahout предоставляет средства для построения механизма рекомендаций с помощью библиотеки Taste - быстрого и гибкого механизма CF. Taste поддерживает рекомендации на основе пользователей и на основе предметов и содержит множество способов выработки рекомендаций, а также интерфейсов для определения своих собственных. Taste состоит из пяти основных компонентов, которые работают с пользователями (User), предметами (Item) и предпочтениями (Preference):
- DataModel: хранилище данных для пользователей, предметов и предпочтений;
- UserSimilarity: интерфейс, определяющий сходство между двумя пользователями;
- ItemSimilarity: интерфейс, определяющий сходство между двумя предметами;
- Recommender: интерфейс для предоставления рекомендаций;
- UserNeighborhood: интерфейс для вычисления соседства подобных пользователей, которое затем можно применять для рекомендующих.
Эти компоненты и их реализации позволяют строить сложные системы рекомендаций для работы в режиме реального времени или в автономном режиме. Рекомендации реального времени часто способны работать только с несколькими тысячами пользователей, тогда как системы автономного режима допускают гораздо более высокое масштабирование. В состав Taste даже входит инструмент, использующий Hadoop для выработки рекомендаций в автономном режиме. Во многих случаях это разумный подход, который позволяет удовлетворить требования большой системы с большим количеством пользователей, предметов и предпочтений.
Для демонстрации процесса создания простой системы рекомендаций нам понадобятся пользователи, предметы и рейтинги. Для этой цели я сгенерировал большой случайный набор пользователей и предпочтений для документов Википедии (предметов в терминологии Taste) с помощью кода из cf.wikipedia.GenerateRatings (входит в пример исходного кода), а затем дополнил его ручными рейтингами на конкретную тему (Авраам Линкольн) для создания окончательного файла recommendations.txt, включенного в пример. Идея этого подхода заключается в том, чтобы показать, как CF может направлять тех, кто интересуется конкретной темой, к другим документам, представляющим интерес в рамках этой темы. В этом примере 990 случайных пользователей (с метками от 0 до 989), которые случайным образом присвоили рейтинги всем статьям коллекции, и 10 пользователей (от 990 до 999), которые дали оценку одной или более из 17 статей коллекции, содержащих словосочетание Авраам Линкольн.
Листинг 1. Создание модели и определение сходства пользователей
//создание модели данных FileDataModel dataModel = new FileDataModel(new File(recsFile)); UserSimilarity userSimilarity = new PearsonCorrelationSimilarity(dataModel); // Вариант: userSimilarity.setPreferenceInferrer(new AveragingPreferenceInferrer(dataModel)); |
В листинге 1 я использую меру PearsonCorrelationSimilarity, которая измеряет корреляцию между двумя переменными, но имеются и другие меры UserSimilarity. Выбор меры сходства зависит от типа данных и вашего опыта. По моему опыту, для этих данных такая комбинация работает лучше всего и при этом демонстрирует возникающие проблемы. Более подробную информацию о выборе меры сходства можно найти на Web-сайте Mahout.
Чтобы выполнить пример, создадим область UserNeighborhood и рекомендующего Recommender. UserNeighborhood определяет пользователей, похожих на моего, и передает их Recommender, который затем составляет список рекомендованных предметов. В листинге 2 эти идеи выражены в коде.
Листинг 2. Выработка рекомендаций
//Получение области пользователей
UserNeighborhood neighborhood =
new NearestNUserNeighborhood(neighborhoodSize, userSimilarity, dataModel);
//Создание рекомендующего
Recommender recommender =
new GenericUserBasedRecommender(dataModel, neighborhood, userSimilarity);
User user = dataModel.getUser(userId);
System.out.println("-----");
System.out.println("User: " + user);
//Распечатка собственных предпочтений пользователей
TasteUtils.printPreferences(user, handler.map);
//Составление списка из пяти лучших рекомендаций
List<RecommendedItem> recommendations =
recommender.recommend(userId, 5);
TasteUtils.printRecs(recommendations, handler.map);
|
Весь пример можно выполнить из командной строки командой ant user-demo, запущенной в каталоге, содержащем пример. Эта команда распечатает предпочтения и рекомендации для мифического пользователя 995, который как раз оказался фанатом Линкольна. В листинге 3 приведен результат выполнения команды ant user-demo.
Листинг 3. Рекомендации для пользователя
[echo] Getting similar items for user: 995 with a neighborhood of 5
[java] 09/08/20 08:13:51 INFO file.FileDataModel: Creating FileDataModel
for file src/main/resources/recommendations.txt
[java] 09/08/20 08:13:51 INFO file.FileDataModel: Reading file info...
[java] 09/08/20 08:13:51 INFO file.FileDataModel: Processed 100000 lines
[java] 09/08/20 08:13:51 INFO file.FileDataModel: Read lines: 111901
[java] Data Model: Users: 1000 Items: 2284
[java] -----
[java] User: 995
[java] Title: August 21 Rating: 3.930000066757202
[java] Title: April Rating: 2.203000068664551
[java] Title: April 11 Rating: 4.230000019073486
[java] Title: Battle of Gettysburg Rating: 5.0
[java] Title: Abraham Lincoln Rating: 4.739999771118164
[java] Title: History of The Church of Jesus Christ of Latter-day Saints
Rating: 3.430000066757202
[java] Title: Boston Corbett Rating: 2.009999990463257
[java] Title: Atlanta, Georgia Rating: 4.429999828338623
[java] Recommendations:
[java] Doc Id: 50575 Title: April 10 Score: 4.98
[java] Doc Id: 134101348 Title: April 26 Score: 4.860541
[java] Doc Id: 133445748 Title: Folklore of the United States Score: 4.4308662
[java] Doc Id: 1193764 Title: Brigham Young Score: 4.404066
[java] Doc Id: 2417937 Title: Andrew Johnson Score: 4.24178
|
Результаты, приведенные в листинге 3, показывают, что система порекомендовала несколько статей с разным уровнем доверия. В самом деле, каждый из этих предметов был оценен другими фанатами Линкольна, но не пользователем 995. Чтобы увидеть результаты для других пользователей, достаточно передать в командной строке параметр -Duser.id=USER-ID, где USER-ID - это число между 0 и 999. Можно также изменить размер области, передав параметр -Dneighbor.size=X, где X - целое больше нуля. На самом деле при изменении размера области на 10 получаются совершенно другие результаты ― ввиду того, что в этой области оказался один из случайных пользователей. Чтобы увидеть область пользователей и предметы одновременно, добавьте в командную строку параметр -Dcommon=true.
Теперь можно заметить, что если ввести число, не входящее в круг пользователей, пример выдаст NoSuchUserException. Действительно, приложение должно будет решить, что делать, когда в систему входит новый пользователь. Например, можно просто показать 10 самых популярных статей, случайный набор статей или набор "разнородных" статей - или, если на то пошло, вообще ничего.
Как я уже упоминал, подход на основе пользователей часто не масштабируется. В данном случае лучше применить подход на основе подобия предметов. К счастью, Taste с той же легкостью использует и этот подход. Как видно из листинга 4, основной код для работы с подобием предметов отличается не сильно.
Листинг 4. Пример подобия предмет-предмет (из cf.wikipedia.WikipediaTasteItemItemDemo)
//создание модели данных FileDataModel dataModel = new FileDataModel(new File(recsFile)); //создание ItemSimilarity ItemSimilarity itemSimilarity = new LogLikelihoodSimilarity(dataModel); //создание рекомендующего на основе предметов ItemBasedRecommender recommender = new GenericItemBasedRecommender(dataModel, itemSimilarity); //получение рекомендаций List<RecommendedItem> recommendations = recommender.recommend(userId, 5); TasteUtils.printRecs(recommendations, handler.map); |
Как и в листинге 1, создаем DataModel из файла рекомендаций, но на этот раз, вместо экземпляра UserSimilarity, создаем ItemSimilarity с помощью LogLikelihoodSimilarity, который помогает обрабатывать редкие события. Затем передаем ItemSimilarity в ItemBasedRecommender и просим рекомендаций. Вот и все! Этот пример кода можно запустить командой ant item-demo. Конечно, систему можно настроить на выполнение этих расчетов в автономном режиме, а также исследовать другие меры ItemSimilarity. Обратите внимание, что ввиду случайного происхождения данных в этом примере рекомендации могут быть неожиданными. На самом деле важно оценивать результаты в ходе тестирования и попробовать различные меры подобия, так как многие из общепринятых мер имеют определенные граничные случаи, которые могут проявиться, если доступных данных недостаточно для выдачи нормальных рекомендаций.
Возвращаясь к примеру с новым пользователем: когда пользователь выбрал предмет, решить проблему действий в отсутствие предпочтений пользователя значительно легче. В этом случае можно воспользоваться преимуществом вычислений предмет-предмет и попросить ItemBasedRecommender выдать предметы, наиболее похожие на текущий. Соответствующий код показан в листинге 5.
Листинг 5. Демонстрация аналогичных предметов (из cf.wikipedia.WikipediaTasteItemRecDemo).
//создание модели данных FileDataModel dataModel = new FileDataModel(new File(recsFile)); //создание ItemSimilarity ItemSimilarity itemSimilarity = new LogLikelihoodSimilarity(dataModel); //создание рекомендующего на основе предметов ItemBasedRecommender recommender = new GenericItemBasedRecommender(dataModel, itemSimilarity); //получение рекомендаций для Item List<RecommendedItem> simItems = recommender.mostSimilarItems(itemId, numRecs); TasteUtils.printRecs(simItems, handler.map); |
Листинг 5 можно запустить из командной строки, выполнив ant sim-item-demo. Единственное ощутимое отличие от листинга 4 состоит в том, что в листинге 5 мы обращаемся не за рекомендациями, а за предметом, максимально близким к входному.
Теперь у вас достаточно знаний, чтобы углубиться в Taste. За дополнительной информацией обращайтесь к документации Taste и списку рассылки mahout-user@lucene.apache.org. Дальше мы рассмотрим, как находить подобные статьи, используя некоторые возможности Mahout в области кластеризации.
Кластеризация с помощью Mahout
Mahout поддерживает несколько воплощений алгоритма кластеризации, написанных в форме Map-Reduce, каждый со своим собственным набором целей и критериев:
- Canopy: быстрый алгоритм кластеризации, который часто используется в качестве отправной точки для создания других алгоритмов кластеризации;
- k-Means (и fuzzy k-Means): группирует элементы в k-кластеры, основываясь на расстоянии от этих элементов до центроида, или центра тяжести предыдущей итерации;
- Mean-Shift: алгоритм, не требующий никаких предварительных знаний о количестве кластеров и способный выдавать кластеры произвольной формы;
- Dirichlet: кластеры, основанные на смешивании многих вероятностных моделей, что исключает необходимость придерживаться кластеров заранее определенного вида.
С практической точки зрения имена и реализации не так важны, как результаты, которые они производят. С учетом этого я покажу, как работает k-Means, а другие подходы оставлю вам для самостоятельного исследования. Имейте в виду, что для эффективной работы каждому алгоритму нужно что-то свое.
В общих чертах (подробности ниже) кластеризация данных с использованием Mahout состоит из следующих этапов.
- Подготовка входных данных. При кластеризации текста его нужно преобразовать в числовое представление.
- Запуск выбранного алгоритма кластеризации с помощью одного из множества поддерживающих Hadoop программ-драйверов, имеющихся в Mahout.
- Оценка результатов.
- Повторение по мере необходимости.
Прежде всего, алгоритмам кластеризации требуются данные в формате, пригодном для обработки. В машинном обучении данные часто представляются в виде векторов, иногда называемых характеристическими векторами. В кластеризации вектор представляет собой массив весовых коэффициентов, представляющих данные. Я продемонстрирую кластеризацию на векторах, полученных из документов Википедии, но векторы могут поступать и из других источников, таких как информация датчиков или профили пользователей. Mahout содержит два представления Vector: DenseVector и SparseVector. Для получения хорошей производительности нужно выбрать соответствующую реализацию в зависимости от ваших данных. Вообще говоря, задачи на основе текста обычно имеют дело с разреженными данными, что делает правильным выбором для них SparseVector. С другой стороны, если большинство значений для большинства векторов ненулевые, то может подойти и DenseVector. Если вы не уверены, попробуйте и посмотрите, какой из них работает быстрее на подмножестве ваших данных.
Чтобы получить векторы из содержимого Википедии (что я проделал для вас), выполните следующие шаги.
- Проиндексируйте содержимое в Lucene, сохраняя векторы терминов для той области, векторы для которой нужно сгенерировать. Я не вдаюсь в подробности - это выходит за рамки статьи, - но приведу здесь некоторые краткие советы вместе с указаниями по Lucene. В Lucene есть класс EnWikiDocMaker (в пакете Lucene contrib/benchmark), который может прочесть дамп файла Википедии и подготовить документы для индексации в Lucene.
- Создайте векторы из индекса Lucene с помощью класса org.apache.mahout.utils.vectors.lucene.Driver, расположенного в модуле Mahout utils. Этот драйвер снабжен большим количеством параметров для создания векторов. Дополнительную информацию можно почерпнуть на вики-странице Mahout "Создание векторов из текста".
Результатом выполнения этих двух шагов будет файл, похожий на файл n2.tar.gz, который вы загрузили в разделе Начало работы с Mahout. Для полноты картины файл n2.tar.gz состоит из векторов, созданных из индекса всех документов файла chunks Википедии, который автоматически загрузился ранее методом ant install. Векторы нормализованы с использованием евклидовой нормы (или нормы L2). При использовании Mahout можно попробовать создать векторы разными способами, чтобы посмотреть, какой дает наилучшие результаты.
После успешного запуска в автономном режиме можно приступить к работе с Hadoop в распределенном режиме. Для этого понадобится JAR-файл Mahout Job, расположенный в каталоге hadoop кода примера. JAR-файл Job содержит весь код и все зависимости для упрощения загрузки в Hadoop. Кроме того, загрузите Hadoop 0.20 и следуйте инструкциям руководства по Hadoop, чтобы сначала запустить его в псевдораспределенном режиме (то есть в кластере из одного элемента), а затем в полностью распределенном режиме. За дополнительной информацией обращайтесь на Web-сайт Hadoop и к соответствующей литературе, а также к ресурсам IBM по облачным вычислениям.
Классификация информации с помощью Mahout
В настоящее время Mahout поддерживает два смежных подхода к категоризации/классификации информации на основе байесовской статистики. Первый подход - это просто наивный байесовский классификатор с поддержкой Map-Reduce. Наивные байесовские классификаторы быстры и достаточно точны, несмотря на очень простые (и часто ошибочные) предположения о полной независимости данных. Они обычно отказывают, когда размер обучающих примеров для каждого класса не сбалансирован или когда данные не являются достаточно независимыми. Второй подход, называемый комплементарным наивным байесовым классификатором, пытается решить некоторые проблемы, характерные для байесова классификатора, при сохранении его простоты и быстродействия. Однако в этой статье я покажу только первый подход, потому что он демонстрирует общую задачу и знакомит с Mahout.
В общих чертах, наивный байесовский классификатор представляет собой двухкомпонентный процесс, который находит признаки (слова), связанные с определенным документом и категорией, а затем использует эту информацию для прогнозирования категории новых, еще не встречавшихся данных. Первый шаг, называемый обучением, приводит к созданию модели, основанной на примерах уже классифицированного контента, и определению вероятностей того, что каждое слово связано с определенным содержанием. На втором шаге, называемом классификацией, для прогнозирования категории входящего документа используется созданная в процессе обучения модель и содержание нового, незнакомого документа наряду с теоремой Байеса. Таким образом, чтобы запустить классификатор Mahout, нужно сначала обучить модель, а затем использовать эту модель для классификации нового контента. В следующем разделе будет показано, как это сделать, с применением набора данных из Википедии.
Запуск наивного байесовского классификатора
Прежде чем запустить тренера и классификатор, нужно проделать некоторую подготовительную работу по созданию наборов документов для обучения и для тестирования. Можно подготовить файлы из Википедии (загруженные методом Ant install), запустив ant prepare-docs. Входные файлы Википедии будут разделены с помощью класса WikipediaDatasetCreatorDriver, включенного в примеры для Mahout. Документы разделяются в зависимости от того, относится ли данный документ к категории, совпадающей с одной из выбранных. Выбранные категории могут быть любыми допустимыми категориями Википедии (или даже любой подстрокой категории Википедии). В этот пример я включил две категории: естественные науки и историю. Таким образом, любая категория Википедии, в которую входит слово science или history (полного совпадения не требуется) будет включена в одну пачку с другими документами данной категории. Кроме того, каждый документ помечен и нормализован с целью удаления знаков препинания, разметки Википедии и других признаков, не нужных для решения этой задачи. Окончательные результаты хранятся в файле с именем категории, содержащем по одному документу в строке ― это формат ввода для Mahout. Аналогично, при выполнении команды ant prepare-test-docs та же работа проделывается для тестовых документов. Важно, чтобы тестовые и учебные документы не перекрывались, что может исказить результаты. Теоретически использование для тестирования документов, на которых производилось обучение, должно привести к идеальным результатам, но на практике даже этого может не случиться.
После подготовки учебного и тестового наборов можно запускать класс TrainClassifier методом ant train. Это должно привести к большому количеству событий как Mahout, так и Hadoop. По завершении ant test берет образцы тестовых документов и пытается классифицировать их с помощью модели, построенной во время обучения. Результатом такого теста в Mahout будет структура данных, называемая матрицей неточностей. Матрица неточностей для каждой из категорий указывает, сколько результатов классифицировано правильно и сколько неправильно.
Итак, для получения результатов классификации нужно выполнить следующие команды.
ant prepare-docsant prepare-test-docsant trainant test
В результате (Ant classifier-example собирает их все в один вызов) получается резюме и матрица неточностей, как показано в листинге 6.
Листинг 6. Результаты работы байесовского классификатора для категорий истории и естественных наук
[java] 09/07/22 18:10:45 INFO bayes.TestClassifier: history
95.458984375 3910/4096.0
[java] 09/07/22 18:10:46 INFO bayes.TestClassifier: science
15.554072096128172 233/1498.0
[java] 09/07/22 18:10:46 INFO bayes.TestClassifier: =================
[java] Summary
[java] -------------------------------------------------------
[java] Correctly Classified Instances : 4143
74.0615%
[java] Incorrectly Classified Instances : 1451
25.9385%
[java] Total Classified Instances : 5594
[java]
[java] =======================================================
[java] Confusion Matrix
[java] -------------------------------------------------------
[java] a b <--Classified as
[java] 3910 186 / 4096 a = history
[java] 1265 233 / 1498 b = science
[java] Default Category: unknown: 2
|
Результаты промежуточных процессов сохраняются в подкаталоге wikipedia базового каталога.
При виде набора результатов напрашивается вопрос: "Как же это получилось?" Резюме гласит, что я получил примерно 75% правильных и 25% неправильных результатов. На первый взгляд это кажется довольно разумным, потому что означает, что я добился лучшего, чем при методе "тыка". Однако более тщательный анализ показывает, что прогнозы в отношении истории оказались точными (около 95% правильных результатов), а в отношении естественных наук из рук вон плохими (примерно 15%). Беглый взгляд на входные файлы для обучения приводит к выводу, что примеров по истории гораздо больше, чем по естественным наукам (размер файла почти вдвое больше), что, вероятно, было одной из возможных проблем.
Для проверки можно добавить к ant test параметр -Dverbose=true, который выдаст информацию о каждом тестовом элементе и покажет, правильно ли он помечен. Углубившись в эти результаты, можно просмотреть документ, чтобы понять, почему он мог быть неправильно классифицирован. Можно также попробовать переобучать модель с разными входными параметрами и дополнительными данными по естественным наукам и посмотреть, не улучшатся ли результаты.
Важно также подумать о выборе признаков для обучения модели. В этих примерах для маркировки оригинальных документов я использовал WikipediaTokenizer из Apache Lucene, но не прикладывал много усилий к тому, чтобы удалить общие или нежелательные термины, которые могут быть неправильно помечены. Если бы я искал классификатор для производственных целей, я бы гораздо глубже изучил входные данные и другие параметры настройки, чтобы выжать из программы максимум возможностей.
Чтобы посмотреть, не были ли результаты по естественным наукам случайностью, я попробовал другой набор категорий: республиканцы и демократы. В этом случае нужно определить, посвящен ли новый документ республиканцам или демократам. Чтобы вы могли попробовать сами, я создал файл repubs-dems.txt в каталоге src/test/resources. Затем я выполнил этапы классификации:
ant classifier-example -Dcategories.file=./src/test/resources/repubs-dems.txt -Dcat.dir=rd |
Два значения -D просто указывают файл категории и имя подкаталога для промежуточных результатов в каталоге wikipedia. Резюме и матрица неточностей для этого прогона выглядят как в листинге 7.
Листинг 7. Результаты работы байесовского классификатора для республиканцев и демократов
[java] 09/07/23 17:06:38 INFO bayes.TestClassifier: --------------
[java] 09/07/23 17:06:38 INFO bayes.TestClassifier: Testing:
wikipedia/rd/prepared-test/democrats.txt
[java] 09/07/23 17:06:38 INFO bayes.TestClassifier: democrats 70.0
21/30.0
[java] 09/07/23 17:06:38 INFO bayes.TestClassifier: --------------
[java] 09/07/23 17:06:38 INFO bayes.TestClassifier: Testing:
wikipedia/rd/prepared-test/republicans.txt
[java] 09/07/23 17:06:38 INFO bayes.TestClassifier: republicans 81.3953488372093
35/43.0
[java] 09/07/23 17:06:38 INFO bayes.TestClassifier:
[java] Summary
[java] -------------------------------------------------------
[java] Correctly Classified Instances : 56 76.7123%
[java] Incorrectly Classified Instances : 17 23.2877%
[java] Total Classified Instances : 73
[java]
[java] =======================================================
[java] Confusion Matrix
[java] -------------------------------------------------------
[java] a b <--Classified as
[java] 21 9 / 30 a = democrats
[java] 8 35 / 43 b = republicans
[java] Default Category: unknown: 2
|
Хотя с точки зрения правильности конечный результат выглядит примерно так же, можно убедиться, что выбор между двумя категориями теперь выполнен лучше. Беглый анализ каталога wikipedia/rd/prepared, содержащего входные документы, показывает, что два учебных файла гораздо лучше сбалансированы с точки зрения обучающих примеров. Проверка показывает также, что в общей сложности примеров было гораздо меньше, чем в случае истории/естественных наук, потому что размер каждого файла гораздо меньше, чем в обучающем наборе по истории или естественным наукам. В целом результаты кажутся, по крайней мере, гораздо более сбалансированными. Более крупные учебные наборы, вероятно, выровняют разницу между республиканцами и демократами ― в противном случае можно предположить, что одна партия лучше представлена в Википедии, чем другая - но этот вопрос я оставлю политологам.
Итак, я показал, как выполнить классификацию в автономном режиме, и теперь нужно перенести код в облако и выполнить его в кластере Hadoop. Как и в случае кода кластеризации, нам понадобится JAR-айл Mahout Job. Помимо этого, все алгоритмы, которые я приводил, поддерживают Map-Reduce и должны просто работать при запуске под управлением процесса Job submission, описанного в руководстве по Hadoop.
Всего за год с небольшим проект Apache Mahout пришел большой путь и обладает значительным потенциалом в области кластеризации, классификации и CF, но и для дальнейшего роста еще много места. На ближайшем горизонте реализации лесов со случайным принятием решений Map-Reduce для классификации, правила ассоциаций, скрытые распределения Дирихле для определения темы документов и больше вариантов классификации с использованием HBase и других вспомогательных систем хранения данных. Помимо этих новых реализаций, ждите новых демонстраций, расширения документации и исправления ошибок.
Наконец, как реальный погонщик слонов использует силу и возможности слона, так и Apache Mahout может помочь использовать силу и возможности желтого слона, символизирующего Apache Hadoop. В следующий раз, когда у вас возникнет потребность в кластеризации, классификации или рекомендовании информации, особенно в крупных масштабах, приглядитесь к Apache Mahout.
| Описание | Имя | Размер | Метод загрузки |
|---|---|---|---|
| Пример кода | j-mahout.zip | 90 МБ | HTTP |