Когда вышел Visual Studio 2005, обнаружилось, что в библиотеки Visual C++ внесены существенные усовершенствования - результат полного пересмотра функций, содержащихся в C Runtime Library (CRT), Standard C++ Library (SCL), Active Template Library (ATL) и Microsoft Foundation Classes (MFC), с точки зрения безопасности. Углубленный анализ показал, что имеет смысл внести изменения, которые повысят безопасность и надежность приложений.
К этим изменениям относится объявление устаревшими функций, не обеспечивающих достаточной безопасности, таких как strcpy. Их место призваны занять новые, более безопасные функции. Во многие функции добавили дополнительный код для обнаружения ошибок и проверки на допустимость. Кроме того, там, где это нужнее всего, реализована дополнительная под-держка отладки.
В этой статье рассказывается о библиотеках Safe C and C++ Libraries, доступных в Visual C++ 2005. Я рассмотрю архитектурные принципы, которыми руководствовались при создании этих библиотек, и приведу примеры различных методик написания с их помощью более безопасного кода. Я также кратко расскажу о том, как работают другие библиотеки, взаимодействующие с Safe Libraries. И наконец, дам рекомендации по переходу, которые помогут вам перенести в Visual C++ 2005 код, рассчитанный на предыдущие версии Visual C++.
Примеры кода, прилагаемые к статье, тестировались в предварительной версии Visual Studio 2005. Советую вам получить последнюю бета-версию и создавать свои приложения в ней. Наверное, это лучший способ ознакомиться с основными изменениями.
Принципы, на которых основаны Safe Libraries
При проектировании Safe Libraries мы (сотрудники группы разработки Visual C++) руководствовались несколькими принципами построения архитектуры. Знакомство с этими принципами поможет вам понять, почему мы сделали тот или иной выбор. Но имейте в виду, что никакие библиотеки или методики разработки, документирования или анализа не могут гарантировать полную безопасность кода. Применение наших библиотек позволит сделать существующий код безопаснее, внеся небольшие изменения, но ничто не может помешать вам выполнять какие-либо рискованные операции в своем коде или некорректно использовать наш код. В конечном итоге, даже если вы задействуете все возможности Safe Libraries, следует применять передовые методики, лежащие в основе разработки безопасного кода: моделирование угроз, анализ кода и тестирование на проникновение (penetration testing). Эти вопросы рассматриваются в книге Дэвида Лебланка (David LeBlanc) и Майкла Говарда (Michael Howard) «Writing Secure Code» (Microsoft Press 2002).
«Secure by default» - один из принципов Trustworthy Computing, помогающих решать эти проблемы. Мы знаем, что объявление функции strcpy устаревшей и генерация предупреждения при каждом ее использовании повысят издержки перехода. Но мы стремились к тому, чтобы только что установленная система автоматически обеспечивала наиболее безопасное поведение даже для проектов, переносимых из старых версий. Конечно, вы всегда можете отключить предупреждения, отложив исправление кода до момента, когда вы будете к нему готовы.
При проектировании библиотек мы старались сократить количество изменений парадигм. Сколько программистов, столько и мнений о том, как писать самый качественный и безопасный код. Я считаю, что наиболее безопасный подход к написанию кода, манипулирующего строками, - использовать строковые классы C++, такие как std::string, или CString из MFC/ATL. Но сотрудникам группы разработки Visual C++ известно, что существуют огромные объемы кода в стиле C, который приходится поддерживать или постепенно развивать, и что, возможно, нет смысла идти на риск и издержки и переводить этот код на C++ и строковые классы. Поэтому мы позаботились, чтобы Safe Libraries поддерживали код, используемый вами в настоящее время. Наши библиотеки применимы даже к старому, менее гибкому коду.
В библиотеках для Visual C++ 7.1 мы проделали кое-какую работу в области безопасности: полностью пересмотрели код и внесли массу изменений и исправлений. Однако наша основная цель состояла в том, чтобы не нарушить совместимость с существующим исходным кодом, поскольку эта версия была лишь усовершенствованием предыдущей. При работе над новой версией мы применили другой подход, чтобы выйти на новый уровень безопасности. Мы по-прежнему старались не нарушать совместимость, однако, когда мы обнаруживали проблемы, которые никак нельзя было решить без нарушения совместимости, мы шли на это. Так, в коде на C невозможно безопасно использовать strcpy, не передавая дополнительный параметр, задающий размер буфера-приемника. Все такие библиотечные функции помечены в документации как устаревшие, получить сведения о них не составляет труда. Мы не могли разработать максимально безопасные библиотеки, не вынудив вас внести некоторые изменения в свой код, поэтому при работе с новыми библиотеками вам придется модифицировать код. И поскольку современные угрозы сильно отличаются от угроз, существовавших во времена разработки C Standard Library, нужно было уделять внимание несколько другим вещам.
Несмотря на упомянутые выше причины, по которым вам понадобится изменять код, мы понимаем, что это дорогое удовольствие. Всякий раз, когда выход новой версии Visual Studio вынуждает вносить изменения, вам приходится тратить силы, сталкиваться с риском возникновения новых «багов» и выполнять тестирование, чтобы обеспечить прежнее качество. В большинстве случаев нам удалось повысить безопасность библиотек, не требуя от вас вообще никаких изменений, а там, где без изменений не обойтись, мы постарались упростить их внесение, сделав новые функции похожими на старые и используя единообразные шаблоны.
Мы считаем расширение продукта своей обязанностью перед сообществом разработчиков, поэтому я был очень рад, что мне представилась возможность сотрудничать с комитетом стандартов языка C при работе над проектом Safe Libraries. Мы получили от комитета множество предложений и отзывов, которые помогли нам усовершенствовать функции. Надеемся, что вскоре этот комитет выпустит наш технический отчет по данному вопросу. Текущий рабочий вариант технического отчета см. по ссылке www.open-std.org/jtc1/sc22/wg14.
Архитектура Safe Libraries
Моя группа занимается созданием Visual C++ Libraries, в которые входит как новейший код, созданный подразделением по разработке (например ATL Server), так и самый старый код продукта (например CRT). Проанализировав код, мы обнаружили, что за последние двадцать лет общепринятые стандарты кодирования существенно изменились. Мы увидели, что кое-какой старый код писали во времена, когда каждый байт был на вес золота, поэтому иногда параметры не полностью проверялись на допустимость.
Новый код изобилует всевозможными проверками, которые, как мы полагаем, действительно полезны при отладке. Мы уделили много внимания тому, чтобы окончательный код был так же надежен при неожиданных ситуациях, как и отлаживаемый. Эти проверки не только облегчают отладку - они делают код библиотеки более безопасным. При разработке Safe Libraries ключевая роль отводилась добавлению кода проверки на допустимость в большинство библиотечных функ-ций. Это повлияло и на отлаживаемый, и на окончательный код. Например, если вы передадите библиотечной функции некорректные флаги, она выявит это при проверке и сообщит вам об ошибке.
Изучив множество хакерских атак, мы извлекли следующий урок: злоумышленники часто используют то, что приложение не может выявить ошибку, или его «терпимость» к неожиданным ситуациям, например к ситуациям, когда стандартная функция возвращает значение, свидетельствующее об ошибке. Мы приняли это во внимание при разработке средства безопасной генерации кода (/GS) для Visual C++ 7.0. Когда код, скомпилированный с ключом /GS, обнаруживает переполнение буфера стека, библиотечный код немедленно прекращает выполнение этого кода, при этом в процессе выполняется минимальное количество дополнительного кода, что сокращает «область атаки» (attack surface). Мы еще больше сократили эту область в Visual C++ 2005 (см. статью Стефена Тауба (Stephen Toub) «C++: Write Faster Code with the Modern Language Features of Visual C++ 2005» в «MSDN Magazine» за май 2004 г. по ссылке msdn.microsoft.com/msdnmag/issues/04/05/VisualC2005). Дело в том, что любой код вашего процесса, который выполняется после того, как библиотечный код обнаружил сбой, может быть использован злоумышленником в своих целях, поэтому объем такого кода надо свести к минимуму.
Точно такая же логика действует в отношении кода проверки на допустимость. Если вы передадите биб-лиотечному коду некорректный параметр, тот сообщит об этом на этапе отладки, что поможет выявить ошибку. Если вы посмотрите стек вызовов при возникновении ошибочной ситуации, то сможете пройти по стеку вызовов от сообщения об ошибке до фрагмента вашего кода, который был причиной проблемы. В окончательной версии приложения библиотечный код запустит свой обработчик некорректного параметра, который вызовет средство Windows Error Reporting, при необходимости позволяющее получить аварийный дамп и вызвать JIT-отладчик.
В этом контексте некорректным является параметр, приводящий к очевидной ошибке, которую вы могли бы обнаружить при написании кода. Такое часто случается из-за отсутствия жестких рамок в стандарте языка C. Например, если ваш код с помощью функции sprintf записывает строку в буфер, задаваемый указателем NULL, библиотечный код сообщит о некорректном параметре. Но если вы с помощью функции malloc запросите, чтобы библиотечный код выделил 10 Мб памяти, а система располагает только 5 Мб свободной памяти, функция просто вернет NULL без сообщения об ошибке. Это ожидаемая ошибка периода выполнения, а не ошибка в программировании.
Одна из проблем, связанных с такими ошибками периода выполнения, - не все функции возвращают информацию об ошибке непосредственно вызвавшему коду. Одни C-функции присваивают значение переменной errno, а другие не делают даже этого. Добавляя новые функции, мы старались, чтобы они напрямую возвращали информацию об ошибках.
Один из самых безопасных вариантов обработки таких ситуаций - прерывание процесса, но нужно иметь возможность настроить обработку. Код на языке C может выбрать альтернативный обработчик, который, например, выполняет код, возвращающий стандартный номер ошибки языка C. Эта модель годится для переносимого кода обработки ошибок, который должен поддерживать несколько платформ. В коде на C++ можно было бы генерировать исключение из такого обработчика.
Многие разработчики постоянно имеют дело со строками. Поэтому переполнение буфера - распространенная причина проблем. Более того, один из крупнейших источников проблем в библиотечном коде Visual C++ - набор традиционных функций C Runtime Library, работающих со строками.
Бурные споры о том, какой вид строкового буфера лучше и безопаснее, будут идти вечно. Выбор между строками, оканчивающимися нулем, и строками, длина которых задана в префиксе, издавна был предметом войны между разработчиками низкоуровневых языков. Не желая вносить крупные изменения, мы должны были оставаться в рамках существующей практики применения C. Язык C и его библиотеки неразрывно связаны со строками, оканчивающимися нулем. Философия их архитектуры отражает приоритеты и ограничения тридцатилетней давности, когда в первую очередь беспокоились о производительности и размере кода. Однако, чтобы в наших библиотеках не возникали переполнения буфера, мы подошли к работе со строками более строго, чем в предыдущих библиотеках.
Простейшее правило, из-за которого разработчикам и проектировщикам библиотек приходится делать много дополнительной работы: никогда не записывайте данные в строковый буфер, не зная его размера. Архитектура strcpy - одно из самых крупных нарушений этого правила. Функция strcpy не может безопасно записывать данные в буфер-приемник, поскольку не «знает», сколько памяти выделил вызвавший код.
Чтобы соблюсти это простое правило, потребовалось добавить много новых функций, отличительная черта которых - дополнительный целый параметр после буфера-приемника: strcpy(dest, src) превращается в strcpy_s(dest, destsize, src).
Вас может заинтересовать, почему библиотеки не требуют, чтобы передавался и размер исходного буфера. Этот вопрос затрагивает ключевое архитектурное решение Safe Libraries. Я уже говорил, что мы должны были поддерживать строки, оканчивающиеся нулем. Запомните: длина строки с завершающим нулем, из которой считываются данные, уже известна. Передача еще одного значения длины привела бы к возникновению дополнительных ошибочных ситуаций, связанных с усечением строки. Кроме того, при анализе существующего кода мы увидели, что многие строки хранятся в буферах фиксированного размера, содержащих только саму строку. В этом случае добавление размера входного буфера не дает никакой новой информации. Наконец, мы решили, что передача размера входной строки приведет к запутыванию кода многих приложений. В итоге мы пришли к неизбежному выводу - функции должны доверять своим входным строкам.
В действительности это не так удивительно, как на первый взгляд. Не забывайте: библиотечный код принимает на веру и то, что размер строки-приемника соответствует размеру памяти, выделенному для нее. При использовании «родного» кода на C и C++ вы всегда можете передать библиотеке некорректные данные, «заложив мину» под приложение.
Мы применили в Safe C++ Libraries тот же принцип: библиотечный код доверяет вашему вводу, но требует, чтобы вы предоставили информацию о выводе. Если вы передаете пару входных итераторов, библиотека доверяет вам и рассчитывает, что вы не выйдете за границы контейнера. Но если вы передаете выходной итератор, то это должен быть итератор с проверкой (checked iterator), который «знает», сколько пространства доступно для вывода. Традиционные итераторы без проверки не годятся, поскольку они могут записать данные за конец буфера.
Очевидно, существует один важный случай, когда вы, разумеется, не хотели бы, чтобы библиотечный код предполагал, что входная строка допустима. Это ситуация, где такая строка получена из недоверяемого источника. Например, представьте, что вы анализируете пакет данных, поступивший от другого процесса или по сети. В этом случае злоумышленник может подготовить специальный пакет с пропущенным завершающим символом, рассчитывая на то, что в вашем коде возникнут какие-либо проблемы. Мы добавили специальную функцию (strnlen), чтобы определять длину не доверяемых строк. В отличие от других новых функций она не используется вместо strlen, а применяется в определенных случаях, когда приходится иметь дело с не доверяемыми данными.
Строки - самая большая и сложная проблема, с которой мы столкнулись, но наша группа решила и еще несколько проблем. В частности, все новые библиотечные функции для операций над файлами корректно работают со сверхдлинными путями Windows. Мы сделали так, чтобы во всех этих функциях по умолчанию использовался монопольный режим доступа к файлам, что уменьшает риск атаки на временные или промежуточные файлы. Кроме того, мы сделали все глобальные переменные основанными на функциях, поэтому библиотеки смогут сообщать о проблемах, если вы обратитесь к глобальной переменной при запуске - в момент, когда она еще не инициализирована. Наконец, мы изменили код всех низкоуровневых функций реализации так, чтобы они использовали минимальный объем памяти стека и по возможности работали не с ней, а с памятью из кучи. Благодаря этому функции будут надежнее работать в средах с ограниченным размером памяти.
Применение библиотека практике
Теперь рассмотрим код в разделе A на рис. 1 и посмотрим, как исправить его с помощью Safe Libraries. Это очень короткий фрагмент кода, манипулирующий строками с помощью библиотеки CRT, тем не менее в него можно внести различные изменения, демонстрирующие, какие решения предстоит принимать при модификации своего кода.

В разделе A показан классический код, подверженный риску переполнения буфера. Наверное, разработчик этого кода полагал, что строка никогда не будет длиннее 10 символов, поэтому размера в 20 байтов будет достаточно. При компиляции этого кода в Visual C++ 2005 будут выводиться предупреждения об использовании устаревших функций для строк, помеченных соответствующим комментарием.
В разделе B представлен самый простой вариант исправления этого кода. При этом исправлении просто вводится в действие предположение первоначального программиста. Если src и «…» действительно имеют достаточно малый размер и помещаются в dest, все будет прекрасно работать. Если нет, библиотека вызовет _invalid_parameter_handler и прекратит операцию, не допустив переполнения буфера. Для определения размера буфера в примере используется функция _countof. Это новая функция, добавленная в CRT: она получает количество элементов массива и использует шаблоны (только в C++-коде), чтобы ее нельзя было применять к указателям.
В разделе C дан альтернативный вариант исправления, когда разработчик просто усекает исходную строку. Важно понимать разницу между функцией wcscpy_s (которая предполагает, что вы выделили достаточно памяти, и, если памяти не хватает, вызывает ошибку) и функцией wcsncpy_s (которая усекает строку, если она не умещается в доступной для нее памяти).
В разделе D предполагается, что вашей программе известен максимальный размер любой строки, задаваемой переменной src (например путь не может быть длиннее MAX_PATH). В этом случае вы по-прежнему можете использовать статический буфер, содержащийся в стеке, и вернуться к использованию wcscpy_s. Как и в разделе B, если для строки не хватит места, операция не будет выполнена, но разработчик такого кода, по-видимому, полностью уверен, что никогда не столкнется со строкой длиннее MAX_SRC_SIZE.
В разделе E приведена версия функции, действительно способная справиться со сколь угодно длинными строками за счет использования памяти кучи. Если памяти не хватит, выполнение кода также прервется
на функции wcscpy_s, но это может произойти только при «баге» в логике программы. Заметьте: используется функция calloc, а не malloc, чтобы сделать невозможным переполнение при умножении целых чисел, когда вычисляется размер в байтах.
В разделе F показано, что вы написали бы, если бы у вас было время на то, чтобы по-настоящему вычистить свой код. Предполагается, что не в каждом приложении это удастся сделать, но в некоторых случаях такие изменения имеют смысл.
Safe C Library
Когда наша группа исследовала существующую библиотеку CRT, мы хотели внести некоторые незначительные изменения в ее функции. Большинство изменений - просто усовершенствования реализации: более строгая проверка параметров на допустимость, улучшенная обработка длинных имен файлов и ограниченное использование стека. Как правило, вам незачем изменять свой код из-за этих усовершенствований, хотя улучшенная проверка на допустимость может выявить проблемы в вашем коде.
Но имеется гораздо меньшая группа функций, в которые нам пришлось добавить параметры или поведение которых сильно изменилось (табл. 1). В этом списке более сотни функций, однако, как видите, многие из них, по сути, дублируются. Например, объявляя функцию strcpy устаревшей, мы объявляем устаревшими и функции wcscpy и _mbscpy.
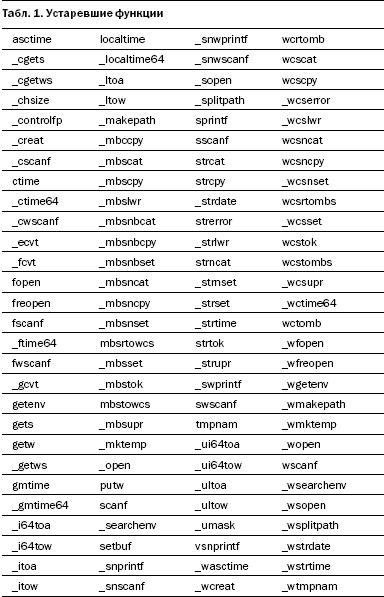
Каждая устаревшая функция заменена более безопасной, у которой к имени добавлено _s. Функции с префиксом - это расширения Microsoft или POSIX-расширения стандартных функций языка C. Функции без подчеркивания являются частью стандарта языка C. Мы сотрудничаем с комитетом по стандартам языка C, разрабатывая набор функций, которые займут их место.
Каждая из перечисленных в таблице функций помечена как устаревшая. Устаревшие функции - относительно новый механизм компилятора Visual C++, позволяющий библиотеке предупреждать вас, когда вы используете средства, не рекомендуемые ее разработчиками. В объявлении функции указывается __declspec(deprecated), и вы при каждом вызове такой функции получаете предупреждение.
Мы группировали устаревшие функции с помощью макросов. Все небезопасные функции содержат в заголовках строку _CRT_INSECURE_DEPRECATE. Чтобы эти функции не считались устаревшими, можно задать на этапе компиляции специальный макрос - _CRT_SECURE_NO_ DEPRECATE, и вы не будете получать предупреждения об устаревших функциях.
Мы добавляли новые функции для решения определенных проблем, которые нельзя решить, оставив функцию в существующем виде. В большинстве случаев проблемой было отсутствие параметра для задания размера буфера. Почти всем строковым функциям и многим другим функциям библиотек для языка C свойственна проблема задания размера буфера. Теперь библиотечные функции всегда принимают размер буфера в параметре, который идет сразу за выходным буфером.
Тот факт, что размер буфера не задается, особенно ярко проявляется при использовании функции scanf. Работая с функцией scanf_s и передавая параметры, описываемые строкой формата, вы должны указывать размер буфера после каждого параметра функции scanf, задающего буфер.
Еще одна типичная проблема - функции, некорректно завершающие строки. В Standard C Library эта проблема возникает при работе с функциями strncpy и snprintf. Все новые функции корректно завершают вывод и требуют, чтобы в буфере было место для завершающего символа строки.
При использовании библиотеки мы обнаружили, что нужно использовать две модели строковых функций. В большинстве случаев, если буфер для хранения строки переполняется, это означает, что в программе допущена ошибка, и библиотека прекращает операцию; так ведет себя strcpy_s. Реже встречаются ситуации, когда корректным поведением является усечение строки. Чтобы обеспечить их поддержку, мы добавили в функцию strncpy_s новый режим. Когда в последнем параметре передается _TRUNCATE, пользователь получает часть исходной строки, способную уместиться в выходном буфере (с учетом завершающего символа); если строка усечена, возвращается STRUNCATE.
В некоторых случаях мы не добавляли в функции дополнительные параметры, зато принципиально изменили поведение функций. Например, мы сделали, чтобы функция fopen_s по умолчанию открывала файлы в монопольном режиме, а не в режиме совместного доступа. Это гораздо более безопасный режим по умолчанию, тем не менее, мы изменили имя функции, чтобы вы выбирали новое поведение явно.
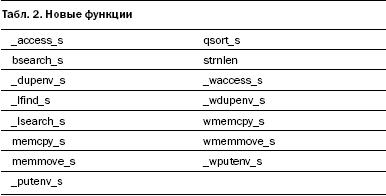
В табл. 2 показана небольшая группа функций, которые мы добавили, хотя их аналоги не устарели. В каждом из этих случаев мы добавляли функцию, поскольку она обеспечивала большую безопасность в определенных ситуациях, но не рассчитывали, что они вытеснят другие функции. Например, в qsort_s добавлена переменная контекста (context variable), которая может оказаться крайне полезной, когда вы сортируете данные и желаете передать дополнительную информацию о контексте, не хранящуюся в самих сортируемых объектах. Раньше разработчики часто использовали для этой цели статические переменные, что было чревато проблемами с реентерабельностью и многопоточным доступом. А функция memcpy_s принимает дополнительный параметр, задающий размер буфера-приемника. Чаще всего этот размер будет совпадать с размером исходного буфера, но некоторые разработчики полагают, что код удобнее читать, когда заданы оба размера.
Одно из главных преимуществ новых функций в том, что им всегда известен размер буфера, в который они записывают данные. Это позволило нам добавить в CRT новую отладочную функциональность. Всякий раз, когда вы вызываете функцию (например strcpy_s) в режиме _DEBUG, библиотечный код полностью заполняет выходной буфер. Благодаря этому, если вы неправильно зададите размер буфера, ошибку удастся обнаружить гораздо быстрее. Кроме того, это помогает выявить другие трудно уловимые ошибки, например использование переменных, которые уже уничтожены или вышли за область видимости.
Эти изменения относятся к библиотеке для языка C, но мы добавили и кое-какой код, специфичный для C++, чтобы еще больше сократить издержки из-за повышения безопасности кода. На рис. 2 показано, как это работает.

В разделе A показан еще один простой фрагмент кода на языке C. При использовании Safe Libraries для всех трех строк кода выводятся предупреждения, поскольку не заданы размеры буферов. Как видите, на самом деле эта функция может обойтись без временного буфера, но я буду использовать его для иллюстрации.
В разделе B представлено простое исправление, которое уже рассматривалось выше. В нем, чтобы задать размер выходного буфера, функции wcscpy_s передается результат вызова функции _countof.
Раздел C демонстрирует еще более простое исправление, но оно работает, только если вы компилируете этот код как C++-код. Данный код гораздо сильнее напоминает первоначальный. Вместо добавления параметров мы просто изменили имена первых двух функций. Мы применили шаблоны, чтобы при первых двух вызовах определялся размер буфера. Поскольку temp - локальный буфер фиксированного размера, механизм шаблонов может автоматически определить размер буфера и передать его функции wcscpy_s.
В разделе D мы возвращаемся к первоначальному коду, но используем #define _CRT_SECURE_CPP_OVERLOAD_STANDARD_NAMES. Этот режим не используется по умолчанию, поскольку может привести к проблемам при применении некоторых нестандартных шаблонов кода. Но его задание значительно сокращает затраты труда. После указания #define мы не получаем предупреждений при первых двух вызовах. Всякий раз, когда используется буфер-приемник фиксированного размера, вызов wcscpy с помощью шаблона преобразовывается в вызов wcscpy_s. Конечно, если буфер объявлен вне функции или под него выделена память из кучи, вам придется задавать его размер, поэтому для по-следней строки выводится предупреждение.
В разделе E показано, какие минимальные доработки нужны, чтобы исправить функцию при использовании _CRT_SECURE_CPP_OVERLOAD_ STANDARD_NAMES. Вам требуется лишь внести изменение для случая, когда используется динамический выходной буфер. Остальной код будет компилироваться без изменений. Мы применили такой подход, когда в конце прошлого года адаптировали к Safe Libraries кодовую базу целого подразделения по разработке, и это действительно позволило сократить затраты труда.
Safe C++ Library
Новая библиотека Standard C++ Library безопаснее и требует от программиста меньших усилий, поскольку ее разработали недавно и поскольку благодаря инкапсуляции, свойственной C++-классам, обеспечивается большая гибкость при внесении изменений. Основная проблема при использовании Standard C++ Library состоит в том, что ее создатели приложили огромные усилия, чтобы сделать ее такой же эффективной, как традиционные итерации в языке C, основанные на указателях. Это означает, что во многих случаях простому итератору известно о своем контексте не более, чем указателю, который ссылается на какой-либо элемент внутри массива.
К сожалению, это означает и то, что итератор не может сообщить о том, что он вышел за границы буфера. Итератор не знает, где находятся границы, и поэтому не может требовать их соблюдения.
Очевидно, что здесь приходится выбирать между эффективностью и контролем границ. В предыдущих версиях библиотечный код по умолчанию выполнял эффективные итерации, а в новой версии добавлен более безопасный режим, гарантирующий, что итератор работает корректно. На рис. 3 приведен пример использования этого режима.

В разделе A показана простая функция, выводящая известную всем строку. Этот код отлично работает, но при компиляции вы получите предупреждение о том, что _Copy_opt устарела. Предупреждение означает, что вы не задали размер буфера-приемника.
В разделе B дана исправленная версия этого кода, где используется новый итератор с проверкой. При объявлении такого итератора указываются обертываемый указатель и размер. При реализации Standard C++ Library нам посчастливилось сотрудничать с компанией Dinkumware. Мы добавляли в библиотеки более безопасные итераторы и переводили код Dinkumware на использование функций Safe C Runtime, а Dinkumware занималась реализацией новой отладочной функциональности итераторов. Эта функциональность доступна только в режиме _DEBUG, тем не менее, она позволяет выявить множество ошибок, например недопустимые итераторы или итераторы, для которых некорректно задан набор.
На рис. 4 приведен код, демонстрирующий эти два вида проверок в период выполнения. Как осуществляется проверка, зависит от режима компиляции приложения (отладочная версия или окончательная). Когда в окончательной версии кода происходит ошибка в период выполнения, C++ предоставляет два логичных варианта. Вы можете прервать процесс, как это делается в C, или сгенерировать исключение, что обычно делается в C++-коде. Доступны оба варианта. Если вы присвоите _SECURE_SCL_THROWS значение 1, то, когда вы выйдете за границы контейнера, вместо прерывания процесса возникнет исключение.

Другие усовершенствования Visual Studio 2005в области безопасности
В Safe Libraries появились и другие усовершенствования в области безопасности, заслуживающие внимания. Объем статьи не позволяет подробно рассмотреть каждое из них, но я вкратце расскажу об этих усовершенствованиях, чтобы вы знали, с чего начать ознакомление с ними.
Мы проделали огромную работу над MFC и ATL, но, поскольку эти библиотеки имеют высокоуровневую природу, нам не пришлось вносить в них существенные изменения, чтобы все их функции корректно работали со строковыми буферами. Мы перевели их на использование функций Safe C Library вместо старых функций. В некоторых случаях в MFC или ATL применялись функции, в которых не задавался размер выходного буфера, - мы объявляли такие функции устаревшими и добавляли новые перегруженные версии с дополнительными параметрами.
В новую версию также внесены существенные изменения в модель развертывания и обновления. Было важно обеспечить, чтобы разработчики ПО распространяли вместе со своими приложениями обновленные копии библиотек. Когда мы выпускаем сервисный пакет для Visual Studio, мы не обновляем автоматически DLL на компьютере каждого пользователя. Однако в Visual C++ 2005 мы поддерживаем DLL, существующие в нескольких версиях (side-by-side execution), при установке и использовании библиотек. Каждому исполняемому файлу, собранному в Visual C++, требуется манифест, указывающий, откуда берутся копии MSVCR80 и других библиотечных DLL. Поддержка DLL, существующих в нескольких версиях, позволяет устанавливать DLL в общий каталог (%systemroot%WinSxS) или в локальный каталог приложения.
Эта технология дает ряд преимуществ, в том числе избавляет от так называемой проблемы DLL Hell. Однако с точки зрения безопасности ключевым преимуществом является то, что в экстренных случаях мы можем напрямую обновить библиотеки на вашем компьютере с помощью Windows Update. Это централизованное обновление влияет на все приложения, в том числе и на те, у которых библиотеки установлены в локальный каталог приложения. Конечно, такое обновление - крайняя мера. Мы прилагаем огромные усилия, чтобы в наших библиотеках не было проблемного кода. Но, если в распространяемых компонентах обнаружится серьезная проблема, связанная с безопасностью, мы можем установить исправления прямо на компьютеры заказчиков.
Заключение
Благодаря работе в группе разработки Visual C++ мне представилась возможность сделать код лучше. Safe Libraries позволят вам и вашему коллективу существенно повысить надежность и безопасность своих приложений, приложив совсем немного усилий.