Последние несколько лет я собирал приёмы программирования, разрушающие в программном коде его утончённую красоту:

-
Объявление всех переменных в начале программы;
-
Возврат результата функции через её параметр;
-
Отсутствие локальных функций;
-
Отсутствие
else if; -
Использование параллельных массивов;
-
Обязательное хранение размера массива в отдельной переменной;
-
Доступ к свойствам объекта через
obj.getProperty()иobj.setProperty(value); -
Использование рекурсии для вычисления факториалов и Чисел Фибоначчи;
-
Отсутствие именованных параметров функции;
Объявление всех переменных в начале программы
В двух словах:
Переменные должны объявляться в начале логического блока, в котором они используются, а НЕ в начале функции или программы.
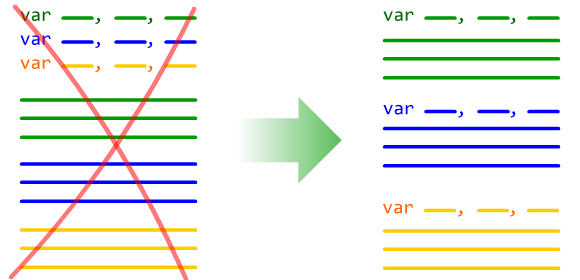
Все программные системы иерархичны. Программы делятся на пакеты, пакеты - на классы, классы разбиваются на отдельные функции.
Данные, относящиеся к тому или иному модулю программы, принято объявлять в начале этого модуля. Локальные переменные объявляются в начале функции; свойства, относящиеся ко всему классу, объявляются в начале определения класса и т.д.
Однако функции не являются последним уровнем в иерархии программы. Любая нетривиальная функция состоит из блоков, реализующих отдельны шаги выполнения алгоритма. Тех самых блоков, которые никак не обособляются в коде, разве что отделяются друг от друга парочкой пустых строк.
Однако эти блоки - полноценные элементы в иерархии программы. И они тоже имеют право на собственные "локальные" переменные! Которые объявляются в начале этого блока и используются только в его пределах.
Пример:
Предположим, нам надо написать функцию сортировки массива методом слияния.
Алгоритм сортировки слиянием состоит из следующих шагов:
- Если длина массива = 2, то:
-
просто меняем местами эти два элемента в случае неправильного их расположения.
-
- Если длина массива > 2, то:
-
разбиваем массив на две половины: левый и правый подмассивы;
-
отдельно сортируем каждый подмассив (рекурсивно);
-
сливаем эти два отсортированных подмассива в один отсортированный результирующий массив.
-
Блоки кода, реализующие шаги этого алгоритма, являются неотъемлемыми частями функции, и не имеют отдельного самостоятельного смысла (может быть, за исключением, блока слияния, который, в принципе, можно преобразовать в отдельную функцию).
Однако, они являются полноправными элементами иерархии программы, и решают свои собственные маленькие подзадачи.
Поэтому:
В начале функции объявляются переменные, относящиеся ко всей функции, например: intLeftIndex, intRightIndex, intLength.
А переменные, относящиеся к отдельным её блокам, объявляются в начале соответствующего блока, например: elTemp объявляется в начале блока сортировки массива из 2-х элментов; intCenterIndex - в начале блока разбиения; arSortedSubarray и intLeftElIndex - в начале блока слияния.
/*
Эта функция реализует сортировку слиянием
*/
function mergeSort (arArryay, intLeftIndex, intRightIndex)
{
/*
Здесь объявляются переменные, относящиеся ко ВСЕЙ ФУНКЦИИ.
Переменные, относящиеся к отдельным её блокам,
объявляются в начале соответствующего блока.
*/
intLeftIndex = intLeftIndex // 0;
intRightIndex = intRightIndex // arArryay.length-1;
var intLength = intRightIndex - intLeftIndex + 1;
if (intLength == 2)
{
/*
БЛОК КОДА: сортировка массива из 2-х элементов
*/
if (arArryay [intRightIndex] < arArryay [intLeftIndex])
{
var elTemp = arArryay [intRightIndex];
arArryay [intRightIndex] = arArryay [intLeftIndex];
arArryay [intLeftIndex] = elTemp;
}
}
else if (intLength > 2)
{
/*
БЛОК КОДА: разбиение массива на два подмассива
*/
var intCenterIndex = intLeftIndex + Math.ceil (intLength / 2) - 1;
var intLeftSubarrayLength = intCenterIndex - intLeftIndex + 1;
var intRightSubarrayLength = intRightIndex - intCenterIndex;
/*
БЛОК КОДА: рекурсивная сортировка каждого подмассива
*/
mergeSort (arArryay, intLeftIndex, intCenterIndex);
mergeSort (arArryay, intCenterIndex+1, intRightIndex);
/*
БЛОК КОДА: слияние
*/
var arSortedSubarray = [];
var intLeftElIndex = intLeftIndex;
var intRihtElIndex = intCenterIndex+1;
while (intLeftElIndex <= intCenterIndex // intRihtElIndex <= intRightIndex)
{
if (intRihtElIndex <= intRightIndex && (arArryay [intRihtElIndex] <= arArryay [intLeftElIndex] // intLeftElIndex > intCenterIndex))
{
arSortedSubarray [arSortedSubarray.length] = arArryay [intRihtElIndex];
intRihtElIndex++;
}
if (intLeftElIndex <= intCenterIndex && (arArryay [intLeftElIndex] <= arArryay [intRihtElIndex] // intRihtElIndex > intRightIndex))
{
arSortedSubarray [arSortedSubarray.length] = arArryay [intLeftElIndex];
intLeftElIndex++;
}
}
for (var i = 0; i < intLength; i++)
{
arArryay [intLeftIndex + i] = arSortedSubarray [i];
}
}
}И поэтому:
Объявление всех переменных в начале функции - страшное зло[1].
Это приводит к смешению переменных, относящихся ко всей функции, с переменными, относящимися только к её отдельному блоку.
Это разрывает блок на две части: объявления данных (в начале функции) и использования этих данных (в самом блоке).
Это усложняет комментирование блока: в одном месте мы комментируем переменные, но не знаем, как их использовать; в другом месте мы комментируем алгоритм, но не знаем, с какими данными он работает.
Пример:
В случае объявления всех переменных в начале функции, переменные, относящиеся ко всей функции, перемешаются с переменными, имеющими смысл только внутри отдельных её блоков.
function mergeSort (arArryay, intLeftIndex, intRightIndex)
{
/*
Угадайте: какие из этих переменных относятся ко всей функции,
а какие - к отдельным её блокам?
*/
var intLength,
elTemp,
intCenterIndex,
intLeftSubarrayLength,
intRightSubarrayLength,
arSortedSubarray,
intLeftElIndex,
intRihtElIndex,
i;
intLeftIndex = intLeftIndex // 0;
intRightIndex = intRightIndex // arArryay.length-1;
intLength = intRightIndex - intLeftIndex + 1;
if (intLength == 2)
{
if (arArryay [intRightIndex] < arArryay [intLeftIndex])
{
elTemp = arArryay [intRightIndex];
arArryay [intRightIndex] = arArryay [intLeftIndex];
arArryay [intLeftIndex] = elTemp;
}
}
else if (intLength > 2)
{
intCenterIndex = intLeftIndex + Math.ceil (intLength / 2) - 1;
intLeftSubarrayLength = intCenterIndex - intLeftIndex + 1;
intRightSubarrayLength = intRightIndex - intCenterIndex;
mergeSort (arArryay, intLeftIndex, intCenterIndex);
mergeSort (arArryay, intCenterIndex+1, intRightIndex);
arSortedSubarray = [];
intLeftElIndex = intLeftIndex;
intRihtElIndex = intCenterIndex+1;
//...код сокращён...
}
}Пример:
Вы только представьте: У нас есть функция в 300 строк кода [2]. Где-нибудь на 200-й строке нам надо поменять две переменные местами. Для этого мы лезем на 200 сток выше в начало функции, объявляем переменную temp, которая не имеет никакого отношения ко всей функции, а используется только один раз в одном месте, потом опять возвращаемся к 200-й строке и меняем переменные местами… По-моему, это просто кошмар.
Хуже всего, что существуют языки, которые считают себя умнее разработчика и заставляют объявлять все переменные в начале функции. Например, такой уважаемый язык как Pascal/Delphi. Чего я ему простить не могу…
Возврат результата функции через её параметр
В двух словах:
Функция должна возвращать результат, зависящий от её параметров, а НЕпринимать результат в качестве аргумента.

Понятие функции (как в математике, так и в программировании) имеет чёткий смысл: вычисление результата, зависящего от аргументов.
В нормальном программном коде ясно видно, что является результатом, а что аргументами: результат = функция (аргумент1, аргумент2).
Однако часто встречается приём, при котором возвращаемое значение передаётся в качестве аргумента функции:функция (аргумент1, аргумент2, &результат).
Этот приём ужасен. При его использовании не видно, от чего функция зависит, а что возвращает.
Чаще всего, в применении этого приёма виноваты не сами разработчики, а языки программирования.
Существуют две основные причины, по которым языки заставляют нас прибегать к этому приёму.
Первая причина состоит в том, что в некоторых языках функции не могут создавать и возвращать сложные объекты.
Пример:
Предположим, что мы хотим на C++ написать функцию, перемножающую две матрицы и возвращающую получившуюся матрицу в качестве результата. Матрицы мы решили представлять в виде двумерного массива.
Но мы не можем объявить в функции результирующий двумерный массив, а затем вернуть его:
int mtxResult [10][10] = mult (mtxA, mtxB);
Поэтому нам придётся сначала вне функции объявить результирующий массив, а затем вызвать функцию перемножения, передав результат в качестве аргумента:
mult (mtxA, mtxB, mtxResult);
В данном случае от использования этого приёма можно избавиться, храня результат в том виде, который функция может возвратить.
Пример:
Можно хранить матрицу не в виде двумерного массива, а в виде структуры или объекта:
Matrix mtxResult = mult (mtxA, mtxB);
Код станет менее лаконичным (из-за объявления дополнительных структур), но, зато, гораздо более красивым.
Вторая причина состоит в том, что в большинстве языков программирования функция не может возвращать несколько значений.
Пример:
Предположим, что мы хотим на C++ написать функцию, решающую квадратное уравнение. Функция принимает в качестве аргумента коэффициенты a, b, c и возвращает три результата: число корней, x1и x2.
Однако вернуть сразу три значения в C++ невозможно:
intRootsCount, numX1, numX2 = quadraticEquation (numA, numb, numC)
Поэтому нам придётся часть результатов выполнения функции передать через указатель в качестве аргументов:
intRootsCount = quadraticEquation (numA, numB, numC, &numX1, &numX2);
Здесь, опять же, от этого приёма можно избавиться, возвращая объект или структуру, хранящую результаты выполнения функции в виде полей.
Пример:
Можно возвращать результаты решения квадратного уравнения в виде структуры с тремя свойствами [3]:
QuadrEqResult qerResult = quadraticEquation (numA, numB, numC); intRootsCount = qerResult.count; numX1 = qerResult.x1; numX2 = qerResult.x2;
Однако и в первом, и во втором случае, при использовании структур или объектов, мы можем столкнуться с ещё одной проблемой: необходимостью отдельно описывать эти структуры или классы.
Причём во многих языках, например на C++, мы не можем описать структуру или класс внутри самой функции (см. следующий раздел). Нам придётся описывать их отдельно от функции, делая их неподчиненными функции сущностями, что уродует иерархию программы.
Слава богу, в других языках классы можно описывать прямо внутри функции, а, например в JavaScript можно просто возвратить объект, нигде отдельно не описывая его структуру.
Пример:
function quadraticEquation (numA, numb, numC)
{
//...
return ({
count: intRootsCount,
x1: intX1,
x2: intX2
});
}
var objResult = quadraticEquation (numA, numB, numC);
intRootsCount = objResult.count;
numX1 = objResult.x1;
numX2 = objResult.x2; Вот это настоящая красота!
Отсутствие локальных функций
В двух словах:
Локальная функция должна объявляться внутри функции, которой она логически подчиняется, а НЕ в глобальном контексте.
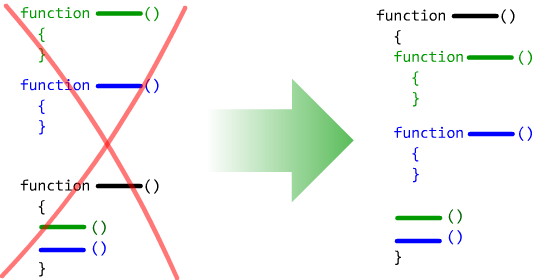
Как уже говорилось, программные системы (как объектно-ориентированные, так и процедурные) иерархичны и делятся на вложенные друг в друга модули(впрочем, это очевидно).
Каждый из модулей располагает своими локальными ресурсами, используемыми только в рамках этого модуля.
Например, локальные переменные являются ресурсами модуля функции.
Однако ресурсами функции являются не только переменные! Подфункции, классы, структуры и т.д. также являются полноправными ресурсами функции, подчинёнными ей, и используемыми только в её рамках.
Пример:
Предположим, нам надо написать функцию printDossier, печатающую досье.
Сверху и снизу досье должен находиться его номер, выровненный по центру и обрамлённый декоративными свасти звёздочками:
****************** 666 ****************** Имя: Макс Отто фон Штирлиц Звание: штандартенфюрер Национальность: истинный ариец Характер: нордический, выдержанный ****************** 666 ******************
Чтобы не дублировать код, печатающий верхний, и печатающий нижний номер, мы решили вынести его в отдельную функциюprintNumber.
Функция, печатающая номер досье, является подчинённой по отношению к функции, печатающей всё досье, используется только в её рамках и не имеет самостоятельного смысла. Поэтому, функцияprintNumber должна быть локальной по отношению к printDossier, и объявляться в её теле.
#
#Эта функция печатает досье:
#
def printDossier (people):
#
#Эта локальная функция печатает номер досье:
#
def printNumber ():
#Вычисляем количество звёздочек слева и справа, так, чтобы номер оказался по центру
stringLength = 32
numberLength = len (people.number)
starsCount = (stringLength - numberLength) / 2
#Печатаем звёздочки слева, номер досье, и звёздочки справа
print ('*' * starsCount) + people.number + ('*' * starsCount)
#
#Печатаем досье
#
#Печатаем номер сверху
printNumber ()
#Печатаем: имя, звание, национальность и характер
print 'Имя: '+ people.name
print 'Звание: '+ people.rank
print 'Национальность: '+ people.race
print 'Характер: '+ people.character
#Печатаем номер снизу
printNumber ()Поэтому:
Это уродует иерархию программы, делая подчинённую функцию независимой, и иерархически неподчиненной родительской функции сущностью.
Это нарушает принцип сокрытия информации, вынося наружу детали внутренней реализации родительской функции - подчинённую функцию.
Это затрудняет понимание кода, засоряя глобальный контекст лишними сущностями.
Это приводит к возникновению ошибок, делая возможным случайный вызов подчинённой функции не в родительском, а в глобальном контексте.
Но многие языки программирования, например C++, не поддерживают локальные функции, классы, структуры и т.д.
Пример:
Поскольку C++ не поддерживает локальные функции, функцию, печатающую номер досье, нам придётся сделать глобальной, независимой и иерархически неподчинающейся функции, печатающей всё досье:
/*
Эта функция печатает номер досье.
Мы вынуждены сделать её глобальной,
хотя она является деталью внутренней реализации функции printDossier
и не имеет самостоятельного смысла.
*/
void printNumber ()
{
//Вычисляем количество звёздочек слева и справа, так, чтобы номер оказался по центру
int stringLength = 32;
int numberLength = strlen (people.number);
int starsCount = (stringLength - numberLength) / 2;
//Печатаем звёздочки слева, номер досье, и звёздочки справа
for (int i = 0; i < starsCount; i++) cout<<"*";
cout<<people.number;
for (int i = 0; i < starsCount; i++) cout<<"*";
}
/*
Эта функция печатает досье
*/
void printDossier (People people)
{
/*
Печатаем досье
*/
//Печатаем номер сверху
printNumber ();
//Печатаем: имя, звание, национальность и характер
cout<< "Имя: " << people.name;
cout<< "Звание: " << people.rank;
cout<< "Национальность: " << people.race;
cout<< "Характер: " << people.character;
//Печатаем номер снизу
printNumber ();
}Язык Pascal/Delphi поддерживает локальные функции, но, заставляет их объявлять только в начале функции. Это не так страшно, как объявлять только в начале все переменные, но тоже, иногда, бывает достаточно некрасиво.
Пример:
Предположим, у нас есть функция из нескольких блоков кода, каждый из которых выполняет отдельный шаг всего алгоритма.
Мы решили переписать один их блоков в рекурсивной форме.
Для этого мы переделали его в рекурсивную локальную функцию… после чего вынуждены перетащить этот блок кода (ставший теперь локальной функцией) с того места, где он используется, в начало основной функции.
program main ();
function block3 (param: integer): integer; // (4)──┐
begin // ↑ ↓
Рекурсивный блок кода #3 // ↑ ↓
end; // ↑ ↓
{} // ↑ ↓
procedure block5 (param: integer); // ↑ ↓ (7)──┐
begin // ↑ ↓ ↑ ↓
Рекурсивный блок кода #5 // ↑ ↓ ↑ ↓
end; // ↑ ↓ ↑ ↓
{} // ↑ ↓ ↑ ↓
begin // ↑ ↓ ↑ ↓
блок кода #1 // (1) ↑ ↓ ↑ ↓
{} // ↓ ↑ ↓ ↑ ↓
блок кода #2 // (2) ↑ ↓ ↑ ↓
{} // ↓ ↑ ↓ ↑ ↓
{Прокручиваем на самый верх // ↓ ↑ ↓ ↑ ↓
и находим код рекурсивной функции block3} // ↓ ↑ ↓ ↑ ↓
block3 (param); // (3)──┘ ↓ ↑ ↓
{} // ↓ ↑ ↓
блок кода #4 // (5) ↑ ↓
{} // ↓ ↑ ↓
{Прокручиваем на самый верх // ↓ ↑ ↓
и находим код рекурсивной функции block5} // ↓ ↑ ↓
block5 (param); // (6)──┘ ↓
{} // ↓
блок кода #6 // (8)
end.
Как теперь прикажите читать эту функцию? Первый блок кода, второй, третий, пока, всё нормально и понятно. Вдруг, хлоп, вызов рекурсивной подфункции, для чтения которой прокручиваем код к самому началу. Затем опять возвращаемся, назад и продолжаем читать обычные блоки. Не намного лучше, чем читать спагетти-код с goto.
К счастью, поддержка локальных функций есть почти во всех "новых" языках, как динамических (JavaScript, Python), так и классических (Java). И надо только воспользоваться этой возможностью.
Отсутствие else if
В двух словах:
Уровень вложенности блока должен соответствовать его иерархическому положению в программе.
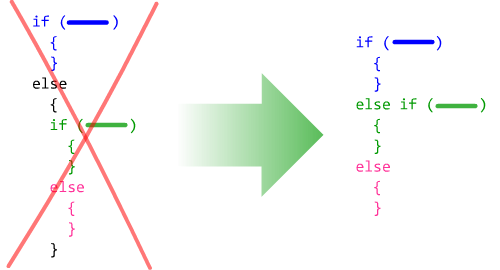
Блоки кода, имеющие одинаковый уровень вложенности, относятся к одному уровню иерархии программы. Соответственно, блоки кода с б о льшим уровнем вложенности являются подчинёнными по отношению к блокам с меньшей вложенностью.
Вроде бы, это очевидный факт.
Тем не менее, иногда, особенно в учебной литературе, я встречаю нарушение этого правила:
Когда блоки, логически находящиеся на одном уровне иерархии в программе, тем не менее, имеют разный уровень вложенности. Или наоборот, имеют разный уровень иерархии, но одинаковый уровень вложенности.
Пример 1:
Предположим, что нам надо приветствовать пользователя, в зависимости от времени суток. Приветствия "Спокойной ночи","Доброе утро", "Добрый день", и "Добрый вечер" совершенно равноправны и относятся к одному уровню иерархии программы.
Поэтому этот код, где приветствия имеют разный уровень вложенности, страшно уродлив:
if (numHour >= 0 && numHour < 6)
{
print ("Спокойной ночи!");
}
else
{
if (numHour >= 6 && numHour < 12)
{
print ("Доброе утро!");
}
else
{
if (numHour >= 12 && numHour < 18)
{
print ("Добрый день!");
}
else
{
print ("Добрый вечер!");
}
}
}
Его надо переписать так, чтобы равноправные блоки имели равный уровень вложенности:
if (numHour >= 0 && numHour < 6)
{
print ("Спокойной ночи ");
}
else if (numHour >= 6 && numHour < 12)
{
print ("Доброе утро!");
}
else if (numHour >= 12 && numHour < 18)
{
print ("Добрый день!");
}
else
{
print ("Добрый вечер!");
}Пример 2:
Предположим теперь, что мы должны проверить, зарегистрирован ли пользователь в системе, и, если зарегистрирован, то поприветствовать, а если нет - послать вон.
В данном случае, блоки кода приветствия имеют подчинённый уровень по отношению к блоку "зарегистрирован", а блок "пошёл вон" - подчинённое к блоку "не зарегистрирован". Поэтому уродлив код, в котором все блоки имеют одинаковый уровень вложенности:
if (!isRegistred ())
{
print ("Вы не зарегистрированы в системе. Идите вон!");
}
else if (numHour >= 0 && numHour < 6)
{
print ("Спокойной ночи ");
}
else if (numHour >= 6 && numHour < 12)
{
print ("Доброе утро!");
}
else if (numHour >= 12 && numHour < 18)
{
print ("Добрый день!");
}
else
{
print ("Добрый вечер!");
}
Его надо переписать так, чтобы уровень вложенности блоков соответствовал их иерархическому положению:
if (!isRegistred ())
{
/*
Не зарегистрирован
*/
print ("Вы не зарегистрированы в системе. Идите вон!");
}
else
{
/*
Зарегистрирован
*/
if (numHour >= 0 && numHour < 6)
{
print ("Спокойной ночи!");
}
else if (numHour >= 6 && numHour < 12)
{
print ("Доброе утро!");
}
else if (numHour >= 12 && numHour < 18)
{
print ("Добрый день!");
}
else
{
print ("Добрый вечер!");
}
}В некоторых старых языках программирования (по-моему, в каких-то древних версиях Паскаля или что-то в этом роде) были операторы if и else, но отсутствовал оператор else if. Они навязывали приём, при котором каждый последующий блок в цепочке сравнений имел всё б о льший уровень вложенности(как в примере №1).
Но сейчас эти языки вымерли как динозавры, и все нормальные языки поддерживают else if.
Поэтому надо писать код, в котором уровень вложенности соответствует уровню иерархии блока, а также не поддаваться на провокации всяких вредных учебников.
Использование параллельных массивов
В двух словах:
При работе с вложенными данными следует соблюдать правила иерархии:свойства должны храниться внутри объекта, а НЕ объект - внутри свойства.
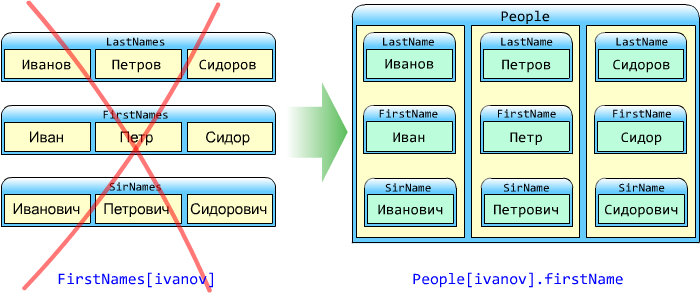
При работе с вложенными данными следует соблюдать правила иерархии.
Во-первых, связанные данные должны иметь общий контейнер.
Благодаря этому объект выглядит именно как объект, и не распадается на множество независимых свойств.
Также, мы можем работать с объектом как с единым целым, например, передавать его в качестве параметра функции и т.д.
Пример:
В данном примере видно, что lastName, firstName, surName относятся к одному объекту: objPeople1.
objPeople1.lastName = "Пупкин"; objPeople1.firstName = "Василий"; objPeople1.surName = "Иванович";
Мы можем работать с этим объектом не как с набором свойств, а как с единым целым:
doSomething (objPeople1);
Во-вторых, при обращении к вложенным данным следует соблюдать иерархический порядок: сначала обращаться к корневому элементу, затем к вложенному в него элементу, затем к элементу с ещё большей вложенностью и т.д.
Пример:
За время написания статьи Путин успел переехать:
World.Russia.Moscow./*Kremlin*/WhiteHouse.Putin
Пример:
А в данном примере только с помощью иерархического порядка можно определить, что
синий пакет находится в красном:
redBag.blueBag.myThing
…или же красный - в синем:
blueBag.redBag.myThingВ программах на объектно-ориентированных языках это правила иерархии почти всегда соблюдается.
Однако соблюдать правила иерархии при обращении к данным надо не только в объектно-ориентированных языках! Тем не менее, в программах на процедурных языках это правило нередко нарушается.
Одним их вопиющих примеров уродского обращения к данным является использование так называемых параллельных массивов.
Пример:
Предположим нам надо сохранить данные о советских лидерах, содержащие следующие свойства: фамилию, имя и отчество.
Каждое из этих свойств хранится в отдельном массиве:
char *lastNames [3] = {"Ленин", "Сталин", "Хрущёв"};
char *firstNames [3] = {"Владимир", "Иосиф", "Никита"};
char *surNames [3] = {"Ильич", "Виссарионович", "Сергеевич"};
const lenin = 0, stalin = 1, khrushchev = 2;
И обращение к данным происходит следующим образом:
//Печатаем: "Никита Хрущёв" cout<<firstNames[khrushchev]<<" "<<lastNames[khrushchev];
При использовании параллельных массивов нарушаются все возможные правила работы с иерархичными данными.
Во-первых, записи распадаются на множество несвязанных полей. Мы не можем работать с записью как с единым объектом.
Пример:
Вместо работы с объектом как с единым целым, нам приходится работать со множеством полей:
doSomething(lastNames [lenin], lastNames [lenin], surNames [lenin]);
Во-вторых, обращение к вложенным данным происходит "задом-наперёд".
Пример:
Запись
firstNames[khrushchev]
означает не Хрущёва, хранящего свойство firstName, а, наоборот, свойство, хранящее внутри себя Хрущёва!
Мне не раз приходилось встречаться с ещё одним приёмом, очень похожим на параллельные массивы: хранение данных в многомерном массиве, где первый индекс отвечает за номер свойства, а второй - за номер записи.
Пример:
char *leaders [3][3] =
{
{"Ленин", "Сталин", "Хрущёв"},
{"Владимир", "Иосиф", "Никита"},
{"Ильич", "Виссарионович", "Сергеевич"}
}
const lenin = 0, stalin = 1, khrushchev = 2;
const lastName = 0, firstName = 1, surName = 2;
Обращение к данным происходит следующим образом:
leaders [propertyNumber][peopleNumber]
Например:
//Печатаем: "Владимир Ленин" cout<< leaders [firstName][lenin]<<" "<< leaders [lastName][lenin]; //Печатаем: "Никита Хрущёв" cout<< leaders [firstName][khrushchev]<<" "<< leaders [lastName][khrushchev]; //Печатаем: "Иосиф Сталин" cout<< leaders [firstName][stalin]<<" "<< leaders [lastName][stalin];
Этот приём имеет только одно преимущество по сравнению с параллельными массивами - список всех записей объединён в единый объект. Однако все остальные недостатки параллельных массивов никуда не деваются:
Во-первых, записи, по прежнему, распадаются на множество несвязанных полей.
Пример:
Вместо работы с объектом как с единым целым, нам опять приходится работать со множеством полей:
doSomething(leaders [lastName][lenin], leaders [firstName][lenin], leaders [surName][lenin]);
Во-вторых, обращение к вложенным данным происходит "задом-наперёд".
Пример:
Запись
leaders [propertyNumber][peopleNumber]
означает не человека peopleNumber хранящего свойствоpropertyNumber, а, наоборот, свойство, propertyNumber хранящее внутри себя человека!
Использовать красивые приёмы работы с данными не так сложно.
Вместо параллельных массивов можно даже воспользоваться предыдущим приёмом с многомерными массивами, просто переставив индексы местами, так чтобы: сначала шёл номер записи, а затем - номер свойства.
Пример:
char *leaders [7][3] =
{
{"Ленин", "Владимир", "Ильич"},
{"Сталин", "Иосиф", "Виссарионович"},
{"Хрущёв", "Никита", "Сергеевич"},
{"Брежнев", "Леонид", "Ильич"},
{"Андропов", "Юрий", "Владимирович"},
{"Черненко", "Константин", "Устинович"},
{"Горбачёв", "Михаил", "Сергеевич"},
};
const lenin = 0, stalin = 1, brezhnev = 2, gorbachev = 6;
const lastName = 0, firstName = 1, surName = 2;
//Печатаем: "Владимир Ленин"
cout<<leaders [lenin][firstName]<<" "<< leaders [lenin][lastName];
//Печатаем: "Леонид Брежнев"
cout<<leaders [brezhnev][firstName]<<" "<< leaders [brezhnev][lastName];
//Печатаем: "Михаил Горбачёв"
cout<<leaders [gorbachev][firstName]<<" "<<leaders[gorbachev][lastName];Этот способ уже имеет ряд преимуществ перед параллельными массивами.
Во-первых, "свойства" "объекта" объединены в единый контейнер. Мы можем работать с "объектом", как с единым целым.
Пример:
Делаем что-то с Хрущёвым:
doSomething (leaders [khrushchev]);
Во-вторых, обращение к данным идёт в иерархическом порядке.
Пример:
Все советские лидеры: leaders
Лидер - Хрущёв: leaders [khrushchev]
Имя Хрущёва: leaders [khrushchev] [firstName]
Однако, использование многомерных массивов имеет и ряд серьёзных недостатков.
Во-первых, обращение к "свойствам" происходит не через осмысленное имя:leaders[2].firstName, а через номер свойства: leaders[2][1]. Для нормального обращения через осмысленные имена приходится объявлять лишние константы, что тоже достаточно уродливо.
Во-вторых, "объект" не может иметь "свойства" разных типов. Пожалуй, это самый серьёзный недостаток многомерных массивов.
Разумеется, самым правильным и красивым решением является создание массива объектов или структур.
Пример:
People *leaders [7] =
{
new People ("Ленин", "Владимир", "Ильич"),
new People ("Сталин", "Иосиф", "Виссарионович"),
new People ("Хрущёв", "Никита", "Сергеевич"),
new People ("Брежнев", "Леонид", "Ильич"),
new People ("Андропов", "Юрий", "Владимирович"),
new People ("Черненко", "Константин", "Устинович"),
new People ("Горбачёв", "Михаил", "Сергеевич")
};
//Эти константы - только для удобства чтения примера. В реальном коде их не будет
const lenin = 0, stalin = 1, brezhnev = 2, gorbachev = 6;
//Печатаем: "Владимир Ленин"
cout<<leaders [lenin].firstName<<" "<< leaders [lenin].lastName;
//Печатаем: "Леонид Брежнев"
cout<<leaders [brezhnev].firstName<<" "<< leaders [brezhnev].lastName;
//Печатаем: "Михаил Горбачёв"
cout<<leaders [gorbachev].firstName<<" "<< leaders [gorbachev].lastName;Обязательное хранение размера массива в отдельной переменной
В двух словах:
Размер массива должен быть доступен через его свойство, а НЕ только изотдельной переменной.
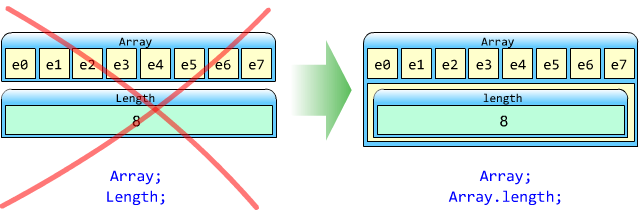
Итак, при работе с вложенными данными следует соблюдать правила иерархии: связанные данные должны иметь общий контейнер; и при обращении к ним следует соблюдать иерархический порядок.
В процедурных языках эти правила нередко нарушаются, причём не только при использовании параллельных массивов.
Ещё одним примером некрасивой работы с данными является обязательное хранение размера массива в отдельной переменной.
Пример:
Предположим, нам надо считать в массив фамилии из текстового файла.
Поскольку число фамилий нам заранее неизвестно, мы объявляем массив names с заведомо большим количеством элементов (например,1000), а число реально используемых элементов храним в отдельной переменной length.
var
//names - массив фамилий с заведомо большим количеством элементов
names : array [0..1000] of string;
//length - число реально использованных элементов
length: integer;
begin
assign (input, 'input.txt'); reset (input);
{/*
Считываем данные из файла в массив
*/}
length := 0;
while not SeekEof (input) do
begin
length := length + 1;
read (names [length]);
end;
end.При этом, так же, нарушаются все возможные правила работы с иерархичными данными:
Во-первых, массив перестаёт быть единым объектом и распадается на две независимые сущности: собственно данные и размер массива.
Пример:
Вместо работы с массивом как с единым целым, нам приходится передавать его по частям: собственно данные - names и размер -length.
doSomething (names, length);
Во-вторых, нарушается иерархический порядок работы с данными.
Размер массива должен быть доступен через его свойствоlength (или, в крайнем случае, через функцию len (array), как в Python, например).
Благодаря этому:
Во-первых, мы можем работать с массивом как с единым объектом.
Пример:
Делаем что-то с массивом:
doSomething (names);
Во-вторых, обращение к свойству массива идёт в иерархическом порядке.
Пример:
Весь массив: array;
Длина массива: array.length;
Разумеется, нет ничего плохого в том, чтобы временно закешировать размер массива в отдельной переменной (например, в целях производительности).
Главное, чтобы размер массива при этом всегда был доступен через свойство и без всяких внешних переменных.
Пример:
Предположим, нам надо написать на JavaScript функцию, суммирующую в цикле элементы массива.
Чтобы в каждой итерации цикла не выполнять достаточно ресурсоёмкое для динамического интерпретируемого языка обращение к свойствуlength, мы можем сохранить размер массива во временной переменнойintLength.
function summ (arNumbers)
{
var intSumm = 0;
//intLength - размер массива, закешированный во временной переменной
var intLength = arNumbers.length;
for (var i = 0; i < intLength; i++)
{
intSumm += arNumbers [i];
}
return (intSumm);
}
Однако, при этом, размер массива нам всегда остаётся доступен через свойство length.
И мы всегда можем обойтись без внешней переменной:
//Передаём массив как единое целое, без отдельной передачи его размера var intSumm = summ (arNumbers);
Доступ к свойствам объекта черезobject.getProperty () и object.setProperty (value)

У полей и методов объектов есть своё чёткое предназначение:
Поля - хранят данные;
Методы - реализуют поведение объекта.
В нормальном коде ясно видно, где идёт работа с данными, а где реализуется логика поведения объекта:
Работа с данными: objObject.property1 = "value1";
Поведение объекта: objObject.doSomething (param1, param2);
Использование методов в качестве акцессора и мутатора поля - уродство.
Во-первых, смешиваются два различных понятия: данные объекта и его поведение.
Нарушается естественная конструкция для доступа к данным через оператор присваивания. Оператор присваивания самой своей сутью подразумевает присваивание.
objObject.property1 = "value1"; strValue = objObject.property1;
Вызов метода, само использование круглых скобок, подразумевает реализацию поведения объекта.
Во-вторых, чтение и запись свойства реализуется по-разному, что противоречит сути поля.
Пример 1:
При использовании свойств, для доступа к полю, как для чтения, так и для записи мы используем одну конструкцию: objObject.property1
intA = objObject.property1; //Чтение objObject.property1 = intB; //Запись
При использовании методов, для чтения и для записи поля используются разные конструкции: objObject.getProperty1 () иobjObject.setProperty1 ():
intA = objObject.getProperty1 (); //Чтение objObject.setProperty1 (intB); //Запись
К полю не будет возможности применять стандартные операторы работы с данными, такие как ++, += и др.
Пример 2:
Мы хотим увеличить значение свойства на 1.
При использовании свойств мы можем воспользоваться естественным для этого действия оператором инкрементации:
objObject.property1++;
При использовании методов, для выполнения элементарного действия приходится писать такую кашу:
objObject.setProperty1 (objObject.getProperty1 () + 1);
Для обращения к защищённым полям объекта как к данным, используются свойства. (Внимание: не "открытые поля", а именно - "свойства", см сноску [4]).
Свойство - это интерфейс для красивого и безопасного доступа к данным объекта [5].
При его использовании вызываются методы доступа к данным (например, для выполнения проверки на правильность записываемых в свойство данных).
Однако, вызов этих методов происходит "прозрачно" для разработчика, что позволяет красиво обращаться к данным: value = object.property иobject.property = value.
Пример 3:
Класс Person хранит поле _money, доступ к которому осуществляется через свойство money:
class Person
{
private long _money;
public long money
{
get
{
/*
Метод, который "прозрачно" вызывается при чтении свойства
*/
return (_money);
}
set
{
/*
Метод, который "прозрачно" вызывается при изменении свойства.
Например, здесь может быть проверка на валидность данных.
*/
_money = value;
}
}
}
Теперь мы можем нормально работать с данными:
Person psnBillGates = new Person (); lngOldRiches = psnBillGates.money; //Чтение psnBillGates.money = lngNewRiches; //Запись psnBillGates.money += 1000000000; //Инкрементация
Свойства поддерживает большое количество современных языков: Delphi, C#, Python, Ruby и др.
Однако немало языков свойства не поддерживают: C++, Java и даже гибкий и красивый JavaScript [6]…
Знаете, есть две вещи, которые обязательно надо добавить в JavaScript. Но это не классы и строготипизированные переменные, как думают многие. Отсутствие классов и строгих типов - это не баг, а фича, дающая JavaScript такую гибкость.
Две возможности, которых действительно не хватает в JavaScript - это перегрузка операторов и поддержка свойств [7].
Использование рекурсиидля вычисления факториалов и Чисел Фибоначчи
В двух словах:
Рекурсию следует использовать только в тех случаях, когда решение задачи на каждом шаге разбивается на несколько подобных подзадач более низкого ранга
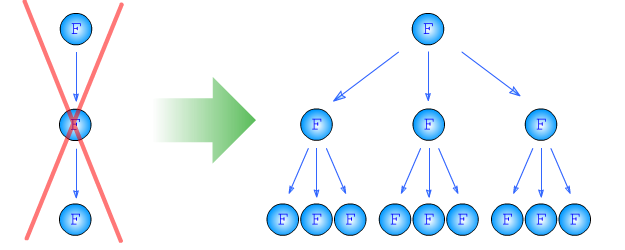
Здесь, в отличие от предыдущих разделов, я не буду столь категоричен.
Ибо рекурсия, или даже философия рекурсии, штука не такая простая.
И вопрос, когда следует (вернее, когда красиво) применять рекурсию, а когда нет, не столь однозначен.
Ну, в функциональных языках (таких как Lisp или Haskell) всё понятно: рекурсия применяется всегда, когда надо выполнить любые повторяющиеся действия. Там даже сумма элементов массива (там он называется списком) вполне может определяться рекурсивно как сумма первого элемента + сумма оставшейся части. В этих языках такой подход гармонирует с философией языка и, потому, красив.
Пример:
Программа вычисления факториала на функциональном языке Haskell красива,
как в интерационной форме:
factorial n = product [1..n]
…так и в рекурсивной с использованием приёма "Сопоставление с образцом":
factorial :: Integer -> Integer factorial 0 = 1 factorial n / n > 0 = n * factorial (n - 1)
В императивных же языках всё сложнее.
Мне кажется, что в этих языках смысл рекурсии состоит в разбиении задачи на несколько подобных подзадач более низкого ранга. А тех в свою очередь - на насколько под-подзадач, и так, в геометрической прогрессии, пока мы не дойдём до тривиального случая.
Пример 1:
При рекурсивном обходе дерева, мы разбиваем дерево на несколько поддеревьев (ветвей), каждое из поддеревьев на под-поддеревья, и так, пока не дойдём до листов.
Пример 2:
При вычислении определителя матрицы, мы находим определители нескольких подматриц меньшего порядка (миноры), для нахождения же миноров, мы разбиваем каждую из подматриц на под-подматрицы и т.д. пока не дойдём до матриц 2×2.
Пример 3:
При сортировке массива слиянием мы сортируем несколько (обычно два) подмассивов этого массива. Для сортировки каждого подмассива мы сортируем их под-подмассивы, пока не дойдём до подпод…подмассивов длины 2.
Поскольку задача разбивается именно на несколько подобных подзадач, то количество данных (локальных переменных) на каждом шаге рекурсии увеличивается. Из-за этого заранее красиво объявить все эти локальные переменные в итеративном алгоритме не получится. Можно, конечно, вручную организовать стек, хранящий состояния каждой "итерации", но это уже будет замаскированная рекурсия, пусть и в обычном цикле без вызова функций. Что нелаконично, малопонятно и не очень красиво. И, соответственно лаконично и красиво использовать рекурсию.
Когда же задача не требует разбиения на несколько подобных, смысл рекурсии вырождается. И применять её в таких случаях - некрасиво.
Самым вопиющим примером уродского применения рекурсии является её использование при вычислении факториала и чисел Фибоначчи.
Я даже не говорю, что это страшно не эффективно. Я говорю, что вычисление факториала и чисел Фибоначчи - чисто итерационная задача, и рекурсивное её решение - это извращение самого смысла, самой сути рекурсии в императивных языках [8].
Как ни странно, эти задачи часто приводят в учебной литературе, причём в самом начале обучения рекурсии, в качестве первого примера. Быть может, рекурсия считается столь сложным для обучения приёмом, именно из-за того, что её объяснение ведётся на совершенно противоестественных её сути примерах…
Отсутствие именованных параметров функции
В двух словах:
Параметры любой нетривиальной функции должны задаваться по осмысленному имени, а НЕ положению в списке аргументов.
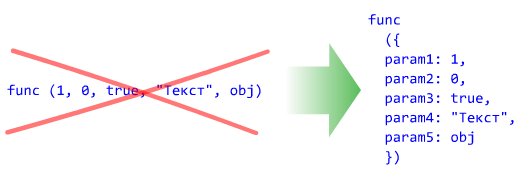
Никто не будет спорить с тем, что имена должны отражать суть переменённых. И что использование имён переменных вроде a0, a1, a2 - не самый понятный и красивый приём.
Точнее, не иметь осмысленного имени могут переменные, не являющиеся уникальными, входящие в состав коллекции, обрабатываемые не каждая отдельно, а вместе, в цикле.
Осмысленные имена должны быть у уникальных переменных, обрабатываемых отдельно.
Пример:
Программа, выводящая имя продукта, его кодовое имя и список глюков:
println ("Имя продукта: "+ objWinVista.name); //Windows Vista
println ("Кодовое имя: "+ objWinVista.codename); //Longhorn
println ("Число глюков: "+ objWinVista.bugsCount); //1 000 000 000 :-)
println ("Список глюков:");
for (long numBugNumber = 0; numBugNumber < objWinVista.bugsCount; numBugNumber++)
{
println (objWinVista.bugs [numBugNumber]);
}
В данном примере name, codename и bugsCount являются уникальными данными и обрабатываются отдельно, поэтому имеют осмысленные имена.
Каждый же из глюков bugs [i] уникальным не является, поэтому имеет не осмысленное имя, а просто номер.
Параметры функции являются такими же полноценными переменными. Однако при вызове функции мы задаём параметр не по его осмысленному имени, а по положению в списке параметров, т.е. по номеру. Это ещё хуже, чем переменные a0, a1, a2.
Пример:
Вот примеры из официальной документации к Java 2D:
GradientPaint gp = new GradientPaint (50.0f, 50.0f, Color.blue, 50.0f, 250.0f, Color.green);
или
RotationInterpolator rotator = new RotationInterpolator ( new Alpha (-1, Alpha.DECREASING_ENABLE, 0, 0, 8000, 0, 0, 0, 0, 0), xformGroup, axis, 0.0f, (float)Math.PI*2.0f);
Что означают эти параметры: -1, Alpha.DECREASING_ENABLE, 0, 0, 8000,0, 0, 0, 0, 0?
Есть только два случая, когда можно использовать неименованные параметры функции.
Первый случай, это когда параметров немного (не больше 3), и их предназначение очевидно.
Пример:
Math.pow (2, 5) вряд ли можно интерпретировать иначе как 25. Ну, разве что, как 52 :-)
Второй случай, это когда каждый из параметров не является уникальным, и не имеет собственного предназначения.
Пример:
Функция, суммирующая числа: Math.summ (3, 7, 18, -2, 11, 2.3)
Во всех остальных случаях параметры надо задавать по осмысленным именам.
К сожалению, лишь немногие языки поддерживают именованные параметры функций (я могу вспомнить только динамические Perl, Python и Ruby, может быть есть ещё).
Пример (perl):
Функция перевода текста.
$strResult = translate text => "Hello, world!", from => $lngEnglish, to => $lngRussian, vocabulary => $vcblrGeneral, quality => 10;
Что же делать в остальных языках?
В процедурных языках (вроде C или Pascal) проблема вызова функций с большим количеством малопонятных параметров стоит особенно остро.
Для её решения вместо передачи большого числа параметров, можно создать структуру, в которой поля будут соответствовать параметрам функции; затем, обращаясь через поля с осмысленными именами записать в структуру нужные данные; и вызвать функцию, передав ей структуру в качестве параметра.
Пример:
//rectangle1 - структура для хранения параметров функции Rectangle rectangle1; //Задаём параметры функции rectangle1.x = 80; //x rectangle1.y = 25; //y rectangle1.width = 50; //ширина rectangle1.height = 75; //высота rectangle1.rotation = 30; //угол наклона rectangle1.borderWeight = 2; //толщина контура rectangle1.borderColor = "red"; //цвет контура rectangle1.backgroundColor = "blue"; //цвет заливки rectangle1.alpha = 20; //процент прозрачности //Вызываем функцию, передавая ей структуру с параметрами drawRectangle (rectangle1);
Гораздо больше кода, но зато более понятно и красиво. Хотя, объявление лишних структур для каждой функции, тоже не очень красивое решение.
К счастью, сейчас процедурные языки используются достаточно редко, и главным образом в тех случаях, когда больше важна не красота и понятность, а скорость выполнения программы (например, C).
В классических объектно-ориентированных языках вместо сложной функции, лучше всего реализовать шаблон проектирования "Command": создать объект; затем, обращаясь через свойства с осмысленными именами, записать в него данные; и вызвать метод apply ();
Пример:
Rectangle rectangle1 = new Rectangle (); rectangle1.x = 80; rectangle1.y = 25; rectangle1.width = 50; rectangle1.height = 75; rectangle1.rotation = 30; rectangle1.borderWeight = 2; rectangle1.borderColor = "red"; rectangle1.backgroundColor = "blue"; rectangle1.alpha = 20; rectangle1.draw ();
Опять же, гораздо больше кода, но зато понятно, и достаточно красиво.
И, наконец, в динамических языках, не поддерживающих именованные параметры (например JavaScript), в качестве параметра функции можно передать созданный на лету объект с осмысленными свойствами.
Пример:
Функция анимации из библиотеки Dojo Toolkit. В качестве аргумента функции передаём объект со свойствами-аргументами функции:
var slideLeft = dojo.fx.slideTo
({
node: divAnim,
duration: 1000,
left: 0,
top: 80
});Пример:
Функция поиска файлов. Объект с аргументами имеет сложную структуру:
var arSerchResult = searchFiles
({
text: "Пушкин",
extensions: ["txt", "rtf", "doc", "pdf", "odt"],
hidden: true,
modified:
{
from: new Date (01, 02, 2008),
to: new Date (15, 03, 2008)
},
size:
{
min: 10000,
max: 1000000
}
});Лаконично, понятно и красиво!
Заключение
Пока всё на этом.
Наверняка, в некоторых местах вы будете со мной несогласны - ведь чувство красоты у всех разное.
Ну и не стоит забывать, что отсутствие в коде приведённых "уродских приёмов" - лишь идеальная ситуация, к которой надо стремиться, но приходится жертвовать в определённых ситуациях (например, в целях производительности). Ведь умение приносить жертвы при решении практических задач - один из элементов профессионального программирования.
Примечания
-
↑ Стив Макконнелл ещё более категоричен, чем я. В книге "Совершенный код" он пишет:
В идеальном случае сразу объявляйте и определяйте каждую переменную непосредственно перед первым обращением к ней
-
↑ Вообще, надо стараться избегать длинных функций и методов. Одно из правил рефакторинга: "если текст метода не умещается на экране без прокрутки - это уже повод разбить его на несколько более коротких методов".
Однако, это далеко не всегда удаётся, например при генерации отчётов или при реализации сложных вычислений.
-
↑ Есть и противоположенная точка зрения. Например, Ховик Меликян в статье "Клиника плохого кода" пишет, что возврат корней квадратного уравнения через параметр функции:
num_roots = qe_solve(10, 20, 2, &x1, &x2);- гораздо красивее, чем использование объектов. -
↑ Не надо путать методы, открытые поля и свойства (как, например, в этомсамоуверенном комментарии).
Открытое поле - это просто переменная внутри объекта, доступ к которой извне ничем не ограничен.
При использовании открытых полей нет никакой возможности отследить обращение к ним, или провести проверку корректности записываемых в поле данных.
Поэтому, использование открытых полей - нежелательно.
Для контроля обращения к данным можно использовать методы
object.getProperty()иobject.setProperty(value).Методы позволяют отслеживать обращение к данным, выполнять при этом сопутствующие действия и проверять правильность введённых данных.
Однако, использование методов - очень некрасиво, о чём я и пишу в статье.
Тем не менее, в языках, не поддерживающих свойства, при выборе между использованием открытых полей и методов - лучше использовать методы. Хоть это и очень некрасиво, но, зато, гибко и безопасно.
Вместо открытых полей и методов, при наличие такой возможности, следует использовать свойства.
Свойства - это интерфейс для доступа к данным, совмещающий гибкость и безопасность методов с красотой открытых полей.
При обращении к свойствам вызываются всё те же методы, однако вызов их происходит "прозрачно" для разработчика.
Это позволяет красиво обращаться к данным:
value = object.propertyиobject.property = value. Как в этом примере с классомPersonи свойствомmoney. -
↑ Разумеется, свойствами, как и любой другой возможностью, не стоит злоупотреблять, применяя их где только можно.
Свойства следует использовать для реализации доступа к данным объекта. Ведь использование свойств, само использование оператора присваивания подразумевает доступ к данным.
Если же, при обращении к данным происходят сильные побочные действия - использовать свойства нежелательно.
В этом случае, красиво и правильно, как раз, использовать методы. Ведь вызов метода, само наличие круглых скобок предполагает реализацию поведения объекта. О чём я и писал в самом начале этой главы.
-
↑ Формально поддержка свойств появилась ещё в JavaScript 1.5:
object.__defineGetter__ ("property", function () {/*Код аксессора*/}) object.__defineSetter__ ("property", function (value) {/*Код мутатора*/})Однако она только относительно недавно стала работать в "нормальных браузерах" и, несмотря на все обещания, до сих пор не работает в Internet Explorer.
-
↑ Перегрузка операторов появится только в JavaScript 2.0.
-
↑ Для вычисления чисел Фибоначчи использование рекурсии имеет какой-то смысл: всё-таки основное определение этой функции является рекурсивным:
Fib (n) = Fib (n−1) + Fib (n−2); Fib (0) = 0; Fib (1) = 1Однако, наличие же у факториала рекурсивной формы записи:
n! = n × (n−1)!нисколько не приближает нас ни к пониманию смысла рекурсии, ни к пониманию смысла факториала как произведения чисел от
1доn.