Автор: Артур Юртайкин, королевство Delphi
1. Предпосылки
Занимаясь прикладным программированием, мне часто приходилось разрабатывать структуру баз данных (определять так называемые методанные - МД). Многолетний опыт показал, что львиная доля усилий идет не столько на разработку, сколько на развитие и модернизацию МД.
База данных, среднего по сложности проекта, уже через год эксплуатации содержит в себе десятки, а то и сотни таблиц и процедур. И это не предел, со временем структура БД пухнет как на дрожжах. В итоге мы имеем огромное количество таблиц со сложной схемой взаимных связей. Управлять такой махиной становится сложно, особенно когда приходится постоянно вносить изменения.
Из всего перечисленного напрашивается очевидный вывод - требуется унификация структуры данных, а также некий механизм управления МД.
2. Свойства и время
Прежде чем двигаться дальше поговорим о времени. Если понаблюдать за объектами реального мира, то станет очевидно, что их свойства претерпевают изменения с течением времени. Как говорят философы: "Все течет, Все изменяется". Если сегодня фамилия Вашей знакомой Сидорова, то не факт что завтра она не станет Ивонова. В наше время даже пол человека может измениться. Меняется все. У каждого события есть отметка на шкале времени, а у каждого процесса временной интервал. С течением времени меняется законодательство и как следствие бизнес-логика приложения.
Считаю, что при разработке информационных систем необходимо учитывать, что объекты и логика могут меняться во времени. По всей видимости, необходимо, уже на этапе разработки приложения, предусмотреть возможность внесения изменений, как в свойства, так и в логику. Должен быть некий механизм синхронизации значении свойств объектов и логики приложения. Хорошим примером считаю продукцию фирмы 1С, где предусмотрена работа с "периодическими" реквизитам.
В проекте Вектор все свойства изначально периодические. Это означает, что их значения позиционируется на шкале времени, а вся история изменений хранится в БД.
При работе с данными мы имеем их состояние на определенный момент времени. В принципе даже саму логику можно хранить в БД, при этом будет сохраняться её история. Но это отдельная тема.
3. Авторизация
В проекте Вектор предусмотрено автоматическое подписывание данных. Это означает, что все изменения данных подписываются Вашим логическим именем. Сделано это затем, чтобы снять вопрос ответственности. Кто изменял данные, вот тот пусть и отвечает.
Кроме того, отпадает необходимость в поддержке громоздких логов. В любой момент можно определить, кто и когда вносил изменения.
Администраторы баз данных, безусловно, поймут и оценят такую возможность.
4. Задача
На самом деле решение уже существует. Крупнейшие разработчики СУБД, такие как: Cache', GemStone, ITASCA, Objectivity /DB, ObjectStore Versant, стали встраивать в свои продукты поддержку объектной ориентации. Но все это довольно дорогостоящее ПО
За неимением финансов, попытаемся решить эту задачу исходя из наших возможностей. А имеем мы SQL сервер и некую среду разработки, Ваш покорный слуга предпочитает всему Delphi 7.
И так приступим. Это должна быть некая оболочка над SQL, абстрагирующая разработчика от реляционной модели, и берущая на себя всю нагрузку по созданию и поддержке МД.
Формулируем требования к оболочке:
- унификация МД
- автоматическая генерация и поддержка всех необходимых структур для работы с БД
- встроенный механизм поддержки периодических свойств
- авторизация изменений
- абстрагирование от реляционной модели, на базе объектно-ориентированного подхода
5. Решение
Для решения задачи я избрал, популярный в среде MS, механизм OLE - Автоматизации. Саму оболочку, в виде сервера автоматизации, я называл Вектор.
Чтобы отобразить объектно-ориентированную концепцию на МД, необходимо предусмотреть такие структурные элементы, которые могли бы поддерживать понятия объектов, типов, свойств и методов.
Реализация методов выходит за границы данной статьи, поэтому оставим рассмотрение этой темы на будущее.
Что касается типов объектов, то я взял на себя смелость упростить это понятие до примитива, при котором тип рассматривается как свойство объекта!!! Согласен, что это слишком смело, но в дальнейшем вы увидите, что данное допущение вполне приемлемо и даже полезно для работы с МД.
И так посмотрим, как нам хранить объекты и их свойства.
Представляется очевидным, что в БД должна быть таблица, хранящая массив ссылок на экземпляры объектов. Под ссылкой мы будем понимать уникальный идентификатор объекта - id. Для реализации лучше всего подходит автоинкрементное поле. Ко всему прочему хотелось бы знать, кто и когда создал объект, добавляем в таблицу еще два поля: Creator и Time. В итоге получаем таблицу Objs, представленную на рис. 1.
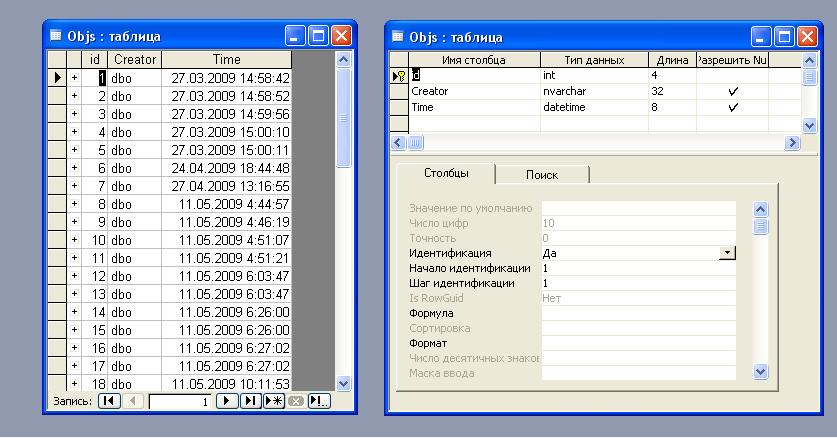
Рис. 1
Теперь рассмотрим свойства объектов. В общем случае свойство может иметь любой тип.
Что касается базовых типов то очевидно, что хранится они должны отдельно - каждый тип в своей таблице. Чтобы обеспечить стандартный механизм доступа создадим сводную таблицу описания свойств Props. Для уникальной идентификации свойства послужит поле автоинкрементного типа id. Название свойства будем хранить в поле Name. Для описания типа свойства создадим поле Type, в котором будем хранить имя типизированной таблицы. В итоге получилась таблица представленная на рис. 2.
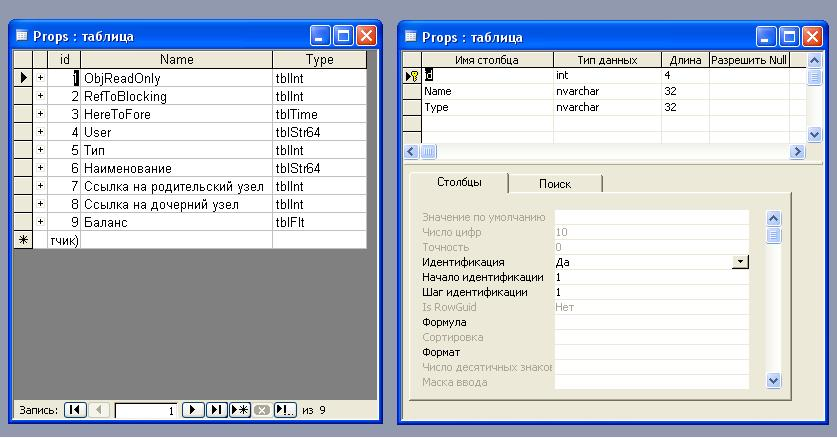
Рис. 2
Сами значения свойств будем хранить в отдельных таблицах. Таблицы эти создаются автоматически по мере надобности. При описании нового свойства, Вектор будет размещать его в подходящей по типу таблице, если же таковой не окажется, то будет создана новая. Для примера рассмотрим таблицу для свойств типа int (длинное целое). Идентификатор объекта - поле idObj, идентификатор свойства - idProp, позиция на шкале времени - Time, само значение - Value, пользователь создавший это значение - Creator. Структура представлена на рис. 3. Чтобы быстро извлекать значения создаем составной индекс: idObj, idProp, Time.
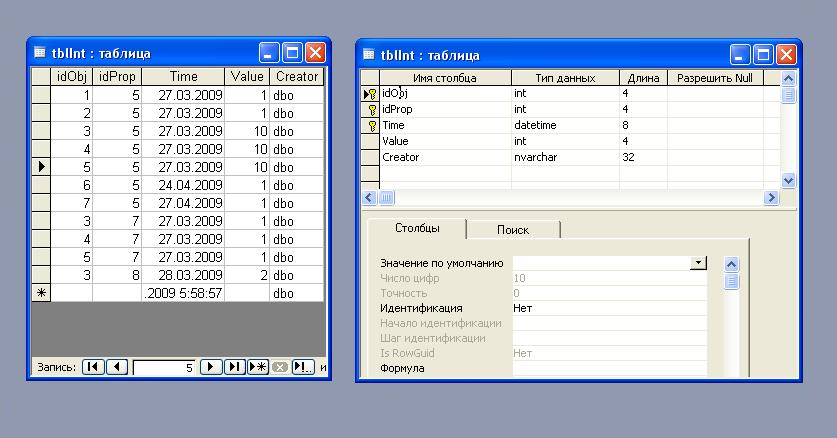
Рис. 3
Аналогичным образом устроены таблицы для других типов свойств, меняется только тип поля Value. В настоящее время Вектор поддерживает четыре типа свойств:
- Cтрока SQL формат - nvarchar, (максимальная длинна 4000 символов);
- Целое SQL формат - int, (диапазон значений -2,147,483,648 ... 2,147,483,647);
- Число с плавающей точкой SQL формат - float, (диапазон значений - 1.79E + 308 ... 1.79E + 308)
- Дата время SQL формат - datetime, (диапазон значений 1753-01-01 00:00:00.000 ...9999-31-12 23:59:59.999)
Итак, структура данных унифицирована, осталось реализовать механизмы: создания объектов, создания свойств, работу со значениями свойств.
Теперь поговорим об оболочке. По сути, оболочка это программный слой переводящий нас на новый уровень абстракции. Все механизмы генерации и поддержки структур инкапсулированы в сервер автоматизации - Вектор.
Интерфейс поддерживает такие методы как создание объекта, создание свойства, присвоение и извлечение значений свойств. Это необходимый минимум. Также я предусмотрел свойство для работы с точкой актуальности.
На SQL уровне извлечение свойств происходит с помощью, так называемых, скалярных функций. На самом деле это обычная сохраненная процедура. Отличием является лишь то, что скалярная функция возвращает единственное значение. Параметрами являются: idObj, idProp, и Time. Для конкретного объекта возвращается значение определенного свойства, актуальное на заданный момент времени.
Посмотреть описание интерфейса можно здесь.
Больше об оболочке говорить нечего.
В заключение пара замечаний:
- интерфейс сделан как можно проще;
- извлечение множественных данных из базы целесообразно производить с помощью пользовательских процедур. Любопытно, что использование типизированных скалярных функций позволяет значительно упростить построение требуемого запроса.
Например:
Требуется извлечь для всех объектов их идентификаторы и значения для свойства наименование.
Вариант в стандартном формате
|
А теперь посмотрите как просто и изящно с использованием скалярных функций
|
- - во всех процедурах выражение FROM вырождается в форму - FROM dbo.Objs. Теперь не надо задумываться какие таблицы, как, и в каком порядке необходимо связывать.
- - значительно упрощается выражение WHERE - параметр @ta передается непосредственно в скалярные функции: fGetVal_Str64 и fGetVal_Int, туда же передаем в качестве параметров id - идентификатор объекта и идентификатор свойства 6 - для свойства Наименование, 5 - для свойства Тип. Вообще в качестве параметра скалярной функции можно подставлять саму скалярную функцию. :)))
- Обратиться в "Интерфейс" за дополнительной информацией/по вопросу приобретения продуктов
- Подробнее о продуктах Embarcadero / CodeGear
- Курсы обучения по продуктам компании Embarcadero/CodeGear
- Купить продукты компании Embarcadero Technologies в интернет-магазине itshop.ru
- Скачать демоверсии продуктов компании Embarcadero / CodeGear