Среда R не претендует на звание языка программирования как такового, являясь скорее интерактивным инструментом анализа наборов данных. Вы можете сохранять для последующего использования созданные графики и последовательности команд, выполненных во время сеанса работы, что особенно полезно тем, что позволяет воссоздать рабочую среду проекта после закрытия сессии. По умолчанию команды R сохраняются в истории команд, но есть также возможность экспортировать особо важные последовательности инструкций в файлы с расширением .R, выполнив команду source() во время сеанса.
Разработчики описывают цели создания R в статье "An Introduction to R":
Рекомендуется использовать для различных проектов в R отдельные рабочие каталоги. Достаточно часто во время работы создаются объекты с именами типа x или y. Такие имена имеют смысл в контексте определенного проекта, однако будет сложно определить, что имелось в виду, когда [...] файлы нескольких проектов сохранялись в одном каталоге.
В каждом каталоге создаются скрытые файлы, содержащие в бинарном виде описание рабочих объектов сеанса. Это позволяет перезапустить сеанс со всеми действовавшими ранее переменными.
Распространяемый по лицензии GPL язык программирования R имеет двух родителей: коммерческий язык программирования S/S-PLUS, из которого была позаимствована большая часть синтаксиса, и язык программирования Scheme, предоставивший многие (наиболее изящные) семантические структуры. Ранние реализации S датируются 1984 годом; более поздние версии (включая S-PLUS) добавили много новых возможностей. Scheme (как и Lisp), конечно, появился еще раньше. R возник как свободная реализация расширенной версии S/S-frPLUS в 1997 году и сразу стал пользоваться успехом у пользователей и разработчиков.
Среда R доступна в бинарном виде для многих компьютерных платформ: Linux, Windows, Mac OS X и Mac OS Classic. Естественно, предоставляется также исходный код для компиляции на других платформах (например, соавтор этой статьи Брэд без труда скомпилировал R на FreeBSD). Работа R не всегда корректна на некоторых платформах: например, окна графиков, использующих Quartz, на компьютере Дэвида под Mac OS X зависают; более того, на компьютере Брэда (FreeBSD/AMD Athlon) выход из R может спровоцировать перезагрузку (возможно, это происходит из-за некорректных опций ядра SSE, но такое поведение все равно неприятно). Несмотря на это, R в целом стабилен, быстр и обладает совершенно удивительным набором статистических и математических функций. Вдобавок к огромному набору стандартных пакетов и функций существуют дополнительные пакеты.
Модель данных R
Базовым объектом данных в R является вектор. Различные виды векторов добавляют такие возможности, как работа с (многомерными) массивами, структурами данных, (разнородными) списками и матрицами. Так же как и в NumPy/NumArray или Matlab, операции над векторами и однородными элементами производятся поэлементно. Несколько простых примеров работы в R дадут возможность понять его синтаксис (в примеры включены команды и ответы системы):
Листинг 1. Векторы и элементарные операции
> a <- c(3.1, 4.2, 2.7, 4.1) # Присваивание "стрелкой" предпочтительнее, чем "="
> c(3.3, 3.4, 3.8) -> b # Можно также присваивать направо
> assign("c", c(a, 4.0, b)) # или явно назначать имя переменной
> c # Конкатенация "уплощает" аргументы
[1] 3.1 4.2 2.7 4.1 4.0 3.3 3.4 3.8
> 1/c # Операция над каждым элементом вектора
[1] 0.3225806 0.2380952 0.3703704 0.2439024 0.2500000 0.3030303 0.2941176
[8] 0.2631579
> a * b # Цикл по более короткому вектору "b" (с предупреждением)
[1] 10.23 14.28 10.26 13.53
Warning message:
longer object length
is not a multiple of shorter object length in: a * b
> a+1 # "1" обрабатывается как вектор длины 1
[1] 4.1 5.2 3.7 5.1
|
Ниже приведены другие примеры индексации, разделения, именованных и необязательных аргументов и других элементов синтаксиса R. Командная оболочка R, особенно если у вас установлен GNU readline, -- это замечательный интерфейс для обучения. Заведите привычку пользоваться командой help(function), чтобы учиться в процессе работы (также можно использовать команду ?function). Пользователи оболочки Python найдут в оболочке R много знакомого и полезного.
Набор данных о температуре
Брэд почти в течение года собирал данные о температуре с четырех термометров внутри и вокруг своего дома и с помощью GnuPlot автоматически преобразовывал изменения температуры в скользящие по времени графики, доступные через Web. Хотя такая любительская коллекция данных не имеет реальной научной ценности, она имеет ряд замечательных особенностей, которые делают ее похожей на настоящие научные данные.
Данные фиксировались с интервалом в три минуты, благодаря чему в течение всего года было создано множество точек данных (около 750 000 на четыре пункта измерения). Некоторые данные были утеряны вследствие поломок термометров, ошибок в каналах передачи или записывающем компьютере. Иногда, как известно, однопроводной передающий канал переставляет местами результаты нескольких одновременных операций чтения вследствие ошибок синхронизации. Другими словами, температурные данные Брэда похожи на хорошие научные данные, хотя и имеющие дефекты и недоработки.
Чтение данных
Результаты измерения температуры сохранены в четырех файлах данных, именуемых по пунктам сбора. Каждый файл имеет следующий формат:
Листинг 2. Формат файла исходных данных о температуре
2003 07 25 16 04 27.500000 2003 07 25 16 07 27.300000 2003 07 25 16 10 27.300000 |
Изначально данные могут быть прочитаны, например, следующим образом:
Листинг 3. Первоначальное чтение данных о температуре
> lab <- read.fwf('therm/lab', width=c(17,9)) # Формат фиксированной ширины
> basement <- read.fwf('therm/basement', width=c(17,9))
> livingroom <- read.fwf('therm/livingroom', width=c(17,9))
> outside <- read.fwf('therm/outside', width=c(17,9))
> l_range <- range(lab[,2]) # Вектор блока данных: весь второй столбец
> b_range <- range(basement[,2]) # range() дает min/max
> v_range <- range(livingroom[,2])
> o_range <- range(outside[,2])
> global <- range(b_range, l_range, v_range, o_range)
> global # Интервалы температур по всем точкам
[1] -19.8 32.2
|
Очистка данных
Исходный формат данных имеет некоторые проблемы. Например, не указываются потерянные данные - вместо этого стоят простые метки отсутствия строчек и отметки времени. Кроме того, даты хранятся в нестандартном формате (отличном от ISO8601/W3C). Менее существенный недостаток - избыточное повторение временных меток в каждом из четырех файлов. Конечно, мы можем очистить данные в самом R, но вместо этого воспользуемся рекомендациями авторов R, представленными в документе "R Data Import/Export" ("Импорт/Экспорт данных в R"). Обработку текстовых данных обычно лучше производить на языке, предназначенном для этого: в доказательство мы написали скрипт на языке Python, создающий единый файл данных, который будет напрямую загружаться в R. Для примера приведем несколько первых строк нового файла данных glarp.temps:
Листинг 4. Формат объединенных данных о температуре
Время Подвал Лаборатория Гостиная Улица 2003-07-25T16:04 24.000000 NA 29.800000 27.500000 2003-07-25T16:07 24.000000 NA 29.800000 27.300000 2003-07-25T16:10 24.000000 NA 29.800000 27.300000 |
Теперь будем работать с обновленными данными:
Листинг 5. Работа с объединенными температурными данными
> glarp <- read.table('glarp.temps', header=TRUE, as.is=TRUE)
> timestamps <- strptime(glarp[,1], format="%Y-%m-%dT%H:%M")
> names(glarp) # Каковы имена колонок?
[1] "timestamp" "basement" "lab" "livingroom" "outside"
> class(glarp[,'basement']) # Какой вид данных в колонке "подвал"?
[1] "numeric"
> basement <- glarp[,2] # присваивание по позиции
> lab <- glarp[,'lab'] # присваивание по имени
> outside <- glarp$outside # соответствует предыдущему присваиванию
> livingroom <- glarp$living # уникальное исходное имя
> summary(glarp)
# Удобное встроенное средство описания большинства объектов в R
timestamp basement lab livingroom
Length:171349 Min. : 6.40 Min. : -6.40 Min. : 7.20
Class :character 1st Qu.: 17.00 1st Qu.: 16.60 1st Qu.: 18.10
Mode :character Median : 19.10 Median : 17.90 Median : 20.30
Mean : 18.88 Mean : 18.12 Mean : 20.17
3rd Qu.: 20.50 3rd Qu.: 19.50 3rd Qu.: 22.00
Max. : 27.50 Max. : 25.50 Max. : 31.30
NA's :1854.00 NA's :2406.00 NA's :1855.00
outside
Min. : -19.800
1st Qu.: 2.100
Median : 9.800
Mean : 9.585
3rd Qu.: 17.000
Max. : 32.200
NA's :1858.000
|
Базовый статистический анализ
Взгляните на функцию range(): min() и max() находят отдельные экстремумы интервала данных. summary(), очевидно, показывает ту же информацию, но в виде, недоступном для прямого использования в других вычислениях. Начнем с нахождения нескольких базовых статистических свойств этих данных:
Листинг 6. Базовые статистические расчеты
> mean(basement) # Среднее значение не будет вычислено, если включить
[1] NA
> mean(basement, na.rm=TRUE)
[1] 18.87542
> sd(basement, na.rm=TRUE)
# При вычислении среднего отклонения также нужно исключить отсутствующие данные
[1] 2.472855
> cor(basement, livingroom, use="all.obs") # Все наблюдения: не проходит
Error in cor(basement, livingroom, use = "all.obs") :
missing observations in cov/cor
> cor(basement, livingroom, use="complete.obs")
[1] 0.9513366
> cor(outside, livingroom, use="complete.obs")
[1] 0.6446673
|
Можно догадаться, что два столбца температур внутренних помещений более взаимосвязаны, чем оба столбца наружных температур. Однако это легко проверить.
Распределение температур
Мы посчитали среднее значение и среднее отклонение температур; интуитивно можно полагать, что температуры будут распределены по нормальному закону. Давайте проверим:
Листинг 7. Создание гистограммы одной короткой строкой
> hist(outside) |
Многие команды R приводят к появлению всплывающих окон с графиками, чертежами или диаграммами данных. Детали создания всплывающих окон зависят от платформы и настроек. Графики можно также перенаправить для сохранения во внешних файлах для дальнейшего использования. Команда hist() приводит к следующему результату:
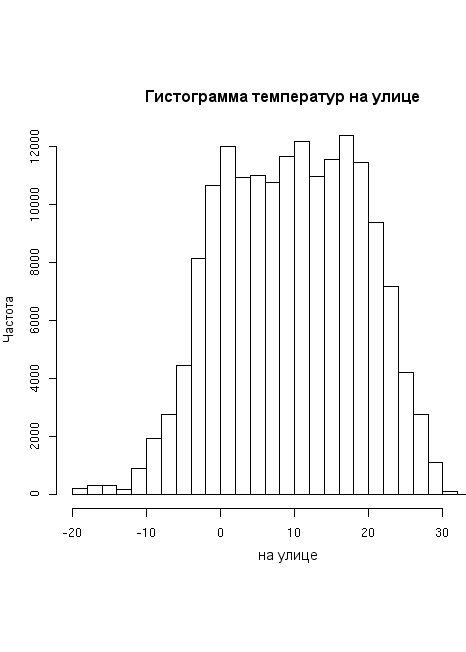
Неплохо для первой попытки. С помощью нескольких параметров можно сузить интервал усреднения:
Листинг 8. Сужение диапазона суммирования гистограммы
hist(outside, breaks=1000, border="blue") |
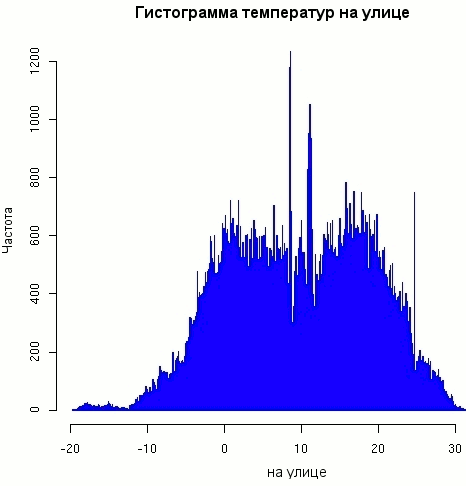
Отметим наличие неровностей в гистограмме плотности в районе 7-12 градусов: наряду с несколькими очень высокими частотами видны неожиданно низкие частоты в других измерениях. Вероятнее всего эти сильные расхождения -- следствие отклонений, возможно, в результате инструментальных погрешностей. С другой стороны, большая, но узкая черта в районе 24 градусов -- близкой для контролируемой кондиционером внутренней температуры -- больше похожа на следствие перестановок результатов измерения, отмеченных выше при обсуждении канала передачи данных. В любом случае графики дают интересный материал для исследований и анализа.
Еще пара небольших изменений и распределение внутренней температуры:
Листинг 9. Гистограммы распределения температур в гостиной
> hist(livingroom, breaks=40, col="blue", border="red") > hist(livingroom, breaks=400, border="red") |
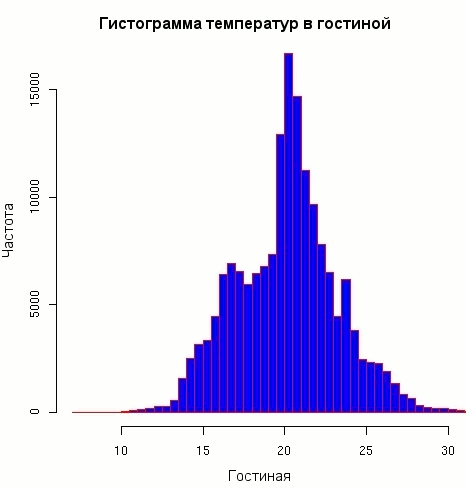
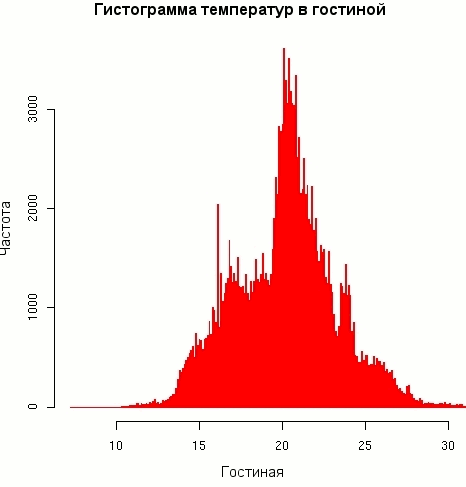
График распределения температур в гостиной представляется более разумным. Сильные неравномерности, проявляющиеся при высоком разрешении, похоже, являются следствием небольших инструментальных погрешностей. Но основное трехпиковое распределение -- это результат работы управляемого таймером термостата Брэда (большой пик в районе 21, меньшие -- в районе 16 и 24 градусов).
Подробнее о визуализации данных
Каждому пункту измерений соответствует линейный вектор значений температур. Можно ожидать наличия в данных двух основных циклов: суточного и годичного (ночи и зимы холоднее).
Первая проблема состоит в преобразовании одномерного вектора данных в двумерную матрицу точек данных. Затем необходимо визуализировать полученное двумерное множество:
Листинг 10. Преобразование вектора и создание графика температуры
> oarray <- outside[1:170880] # Необходимо отбросить несколько точек данных, относящихся к последнему дню > dim(oarray) <- c(480,356) # Преобразование вектора в двумерный массив > plot(oarray[1,], col="blue", type="l", main="4 p.m. outside temp", + xlab="Day of year (starting July 25, 2003)", + ylab="Temperature (Celsius)") |
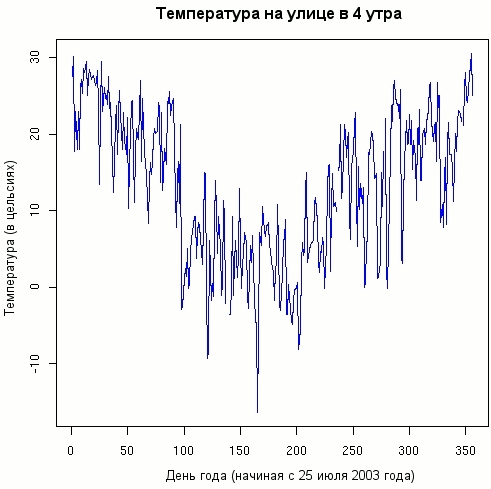
Когда мы преобразовали данные в матрицу "время-день" (двумерный массив), естественный шаг -- взять значения температуры для каждого дня и построить график годичного поведения. Можно сделать иначе -- извлечь каждую 480-ую точку из вектора, но способ R более элегантен.
Трехмерный массив данных
Как насчет представления результатов измерения температуры за весь год? Один из подходов - цветокодированный график температур:
Листинг 11. Создание графика температур
> x <- 1:480 # Создание индексов оси X > y <- 1:356 # Создание индексов оси Y > z <- oarray[x,y] # Определяем ось z (в действительности совпадающую с oarray) > mycolors <- c(heat.colors(33),topo.colors(21))[54:1] > image(x,y,z, col=mycolors, + main="Outside temperatures near Glarp", # Brad's name for his house + xlab="Minutes past 4 p.m", + ylab="Days past July 25, 2003" ) > dev2bitmap(file="outside-topo.pdf", type="pdfwrite") |
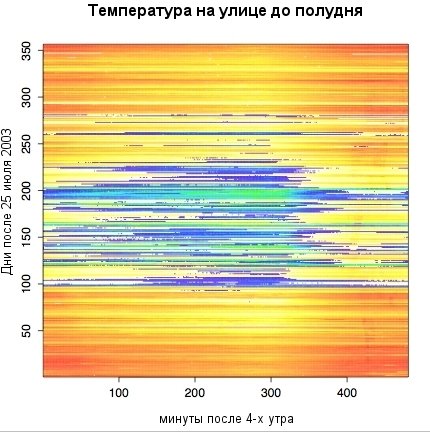
Несколько комментариев о том, что было сделано. Определение осей и точек очевидно, если вы узнали нотацию создания списка чисел, подобную используемой в языке Python. Индексирование по x и y при создании z приводит к появлению массива с длиной и шириной индексов. В данном случае z тривиальна -- совпадает с oarray; однако достаточно легко систематично изменять значения или смещения, используемые для их получения. Цветовая карта mycolor подбирается путем проб и ошибок: мы полагаем, что необходимо использовать красные и желтые цвета для "горячих" температур (другими словами -- выше нуля градусов Цельсия) и неправильно использовать их для "холодных" температур. Поэтому мы добавляем в цветовой вектор несколько голубых/зеленых цветов. Мы также хотим использовать обратный порядок цветов вместо предлагаемого стандартными функциями цветовых карт -- это достаточно просто при использовании индексирования.
Вы можете заметить, что карта температур нарисована немного более контрастно, чем прежние графики. Команда image() создает на экране похожую, но менее впечатляющую картинку. Экспорт "текущего изображения" во внешний файл часто дает лучший результат, что и показано здесь.
Пока мы занимались плоскими картами температур, однако многие читатели предпочли бы, чтобы изображение имело псевдоперспективу для отображения трехмерных данных. Приложив лишь небольшие усилия, в R можно создавать весьма впечатляющие топологические карты трехмерных данных. Например:
Листинг 12. Создание графика топографической поверхности
> persp(x,y,z, theta=10, phi=60, ltheta=40, lphi=30, shade=.1, border=NA, + col=mycolors[round(z+20)], d=.5, + main="Outside temperatures near Glarp", + xlab="Minutes past 4 p.m", + ylab="Days past July 25, 2003", + zlab="Temperature", ) |
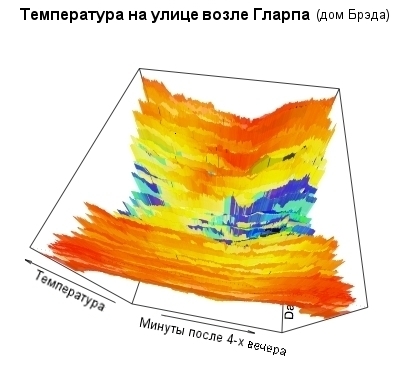
Заключение
В этой статье, представляющей лишь малую часть статистических возможностей R, мы выполнили несколько простых статистических анализов и создали несколько графиков. Фактически для всех областей науки и для всех хорошо известных (или не очень известных) статистических методик в R имеются поддерживающие их функции и пакеты расширений.
Мы надеемся, что эта статья дала читателю представление о работе в R. Однако R предлагает значительно больше возможностей, чем мы показали здесь. Во второй части в этой серии из трех частей мы представим более продвинутые методы работы в R, начав с линейных и нелинейных регрессий.