Антон Шмаков,
старший консультант отдела бизнес-анализа и хранилищ данных
Консалтинговая группа "Борлас" (Москва)
Источник: Oracle Magazine - Русское издание
Введение
Oracle Real Time Decisions (ORTD) - специальный инструмент от компании Oracle, предназначенный для автоматизации принятия решений в режиме реального времени (ранее об этом продукте была опубликована статья "Глубинный анализ данных в режиме реального времени: Oracle Real Time Decisions"). Он позволяет строить сложные прогностические модели, опираясь на анализ исторических и оперативных данных. Кроме мощного аналитического движка, ORTD предоставляет бизнес-пользователям и разработчикам полную инфраструктуру как для построения моделей, так и для их повседневного исполнения.
В статье "Решения "растут" на деревьях" (Decisions Grow on Trees, by Ron Hardman) описывается конкретный тип классификации данных, называемый деревья решений. Этот метод был не так давно реализован в продукте Oracle Data Miner (ODM). Результаты его работы легко воспринимаются визуально и могут быть легко объяснены в бизнес-терминах.
В этой статье мы хотели бы познакомить читателей с ORTD на практическом уровне. В ней описывается весь путь от установки и настройки ORTD и до создания проекта и получения практических результатов. В качестве бизнес задачи предлагается взять пример из уже упоминавшейся статьи "Решения "растут" на деревьях". Следует отметить, что в Real Time Decisions реализованы Байесовский классификатор и регрессионная модель, деревья решений в нем не реализованы. Мы построим небольшой тестовый проект в ORTD, целью которого будет продемонстрировать работу в ORTD и сравнить результаты работы Байесовского классификатора в Real Time Decisions, с деревьями решений в ODM.
Постановка задачи
Рассмотрим бизнес ситуацию. Производитель предлагает два продукта, А и B. Относительно них имеется очень скудная информация, а именно тип продукта (PRODUCT), версия продукта (VERSION), время его последней модификации (LAST_UPGRADE_YEAR) и отзыв покупателей (FEEDBACK). Производитель хочет, во-первых, узнать как связаны отзывы покупателей с характеристиками продукта и, во-вторых, построить модель для прогнозирования будущих отзывов. В упоминаемой статье автор строит модель классификации на основе деревьев решений в Oracle Data Miner. Мы же попробуем построить Байесовскую модель в Oracle Real Time Decisions, c помощью которой мы сможем проанализировать входные данные.
Как начать работать в ORTD
I. Установка Oracle Real Time Decisions
- Скачать дистрибутив Oracle Real Time Decisions с сайта Oracle
- Разархивировать (Unzip) его, найти файл rtd_2.2_OC4J_win.zip и разархивировать его в папку, которая будет RTD_HOME (например: С:\Oracle\RTD)
- Подключиться к SQL*Plus под SYSDBA и выполнить следующие команды.
SQL>create user rtd identified by rtd; SQL>grant resource,connect to rtd;
- Установить схему с метаданными в rtd. Перейти в папку RTD_HOME/scripts и запустить SDDBTool.cmd
- Ввести информацию и нажать кнопку Next
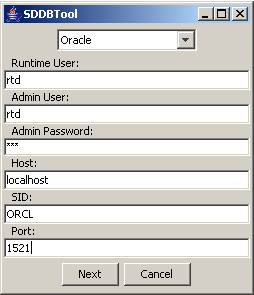
- Выбрать Initialize.
- Далее для установки необходимо, чтобы у вас был установлен OC4J. Его можно установить либо отдельно, либо он входит в состав Oracle Business Intelligence EE Basic Installation (BI_EE_HOME/oc4j_bi). Далее OC4J_HOME - папка, куда установлен OC4J.
Поскольку администрирование ORTD осуществляется в JConsole через JMX протокол, надо настроить его поддержку в OC4J.
- Найти файл OC4J_HOME/bin/oc4j.cmd открыть его на редактирование, найти строку начинающуюся с :oc4j и добавить после нее следующий код:
set JVMARGS=%JVMARGS% -Dcom.sun.management.jmxremote=true set JVMARGS=%JVMARGS% -Dcom.sun.management.jmxremote.port=12345 set JVMARGS=%JVMARGS% -Dcom.sun.management.jmxremote.authenticate=true set JVMARGS=%JVMARGS% -Dcom.sun.management.jmxremote.ssl=false
Для удобства настроим ORTD на отдельный порт 8080.
- Найти файл OC4J_HOME/j2ee/home/config/default-web-site.xml, скопировать в его в ту же директорию с новыми именем rtd-web-site.xml. Затем в файле rtd-web-site.xml сделать следующие изменения и сохранить:
- Заменить внутри тега <web-site> значение атрибута port на 8080
- Заменить внутри тега <web-site> значение атрибута display-name на OC4J 10g RTD Web Site
- Удалить все теги <web-app>
- Заменить внутри тега <access-log> значение атрибута path на ../log/rtd-web-access.log

Скриншот 2
- Найти файл OC4J_HOME/j2ee/home/config/server.xml открыть его на редактирование, добавить после строки
<web-site default="true" path="./default-web-site.xml" />
строку
<web-site default="true" path="./rtd-web-site.xml"
/>. - Найти (JAVA_HOME - папка с JDK, которая используется для запуска OC4J) JAVA_HOME/jre/lib/management/jmxremote.password (если такого файла нет, создать его скопировав из jmxremote.password.template) и раскомментировать строчки:
monitorRole QED controlRole R&D
- Зайти в свойства файла, далее Безопасность->Дополнительно->Разрешения. Убрать галку с "Наследовать от родительского объекта…". Удалить все разрешения кроме разрешения для владельца файла, которого можно найти на закладке Владелец.
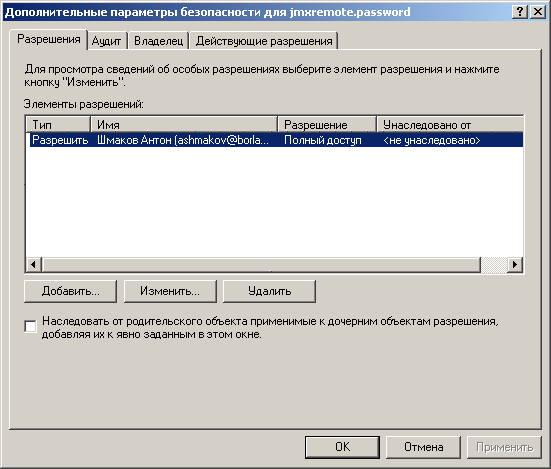
Скриншот 3
- Запустить OC4J сервер командой
OC4J_HOME/bin/oc4j.cmd -start - Зайти в консоль управление OC4J по адресу http://oc4j_host:port/em (Для отдельного OC4J порт будет 8888, для Oracle BI EE порт будет 9704.) администратором.
Для корректной работы ORTD надо настроить JDBC источники в OC4J для схемы с метаданными.
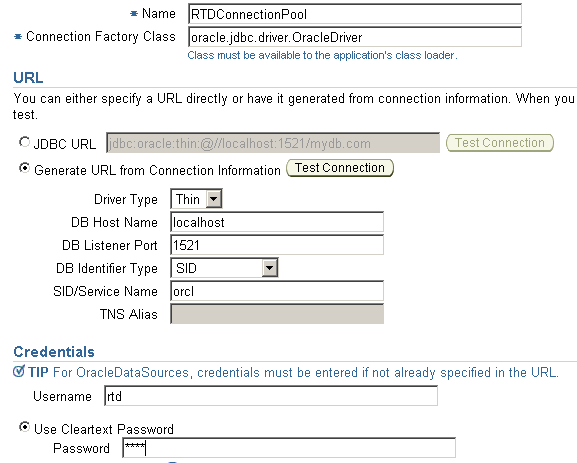
- Перейти на закладку Administration и затем в JDBC Resources. В разделе Connection Pools нажать на Create.
- Ввести следующие значения, остальные оставить без изменения и нажать кнопку Apply
-
Свойство Значение Application Default Connection Pool Type New Connection Pool Name RTDConnectionPool Connection Factory Class Oracle.jdbc.driver.OracleDriver URL Ваша строка соединения к базе данных Username rtd Password (Use Cleartext Password) rtd -

-
Скриншот 4
-
-
Скриншот 5
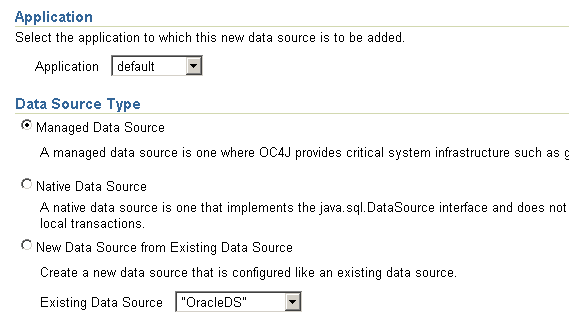
- Нажать на копку Create в разделе Data Sources
- Ввести следующие значение, остальные оставить без изменения и нажать кнопку Finish
-
Свойство Значение Application Default Data Source Type Managed Data Source Name RTD_DS JNDI Location jdbc/SDDS (жестко прошито в ORTD) Connection Pool RTDConnectionPool -
Скриншот 6

-
Скриншот 7
- Проверить, что созданные соединения, нажав на Test Connection.
- Перейти по адресу http://oc4j_host:port/em и затем на закладку Applications.
Теперь можно "задеплоить" приложение ORTD на сервер.
- Нажать на копку Deploy
- Выбрать архив из RTD_HOME/package/RTD.ear и нажать Next.

Скриншот 8
- Выбрать значения и нажать Next
-
Свойство Значение Application Name OracleRTD Parent Application default Bind Web Module to Site rtd-web-site -
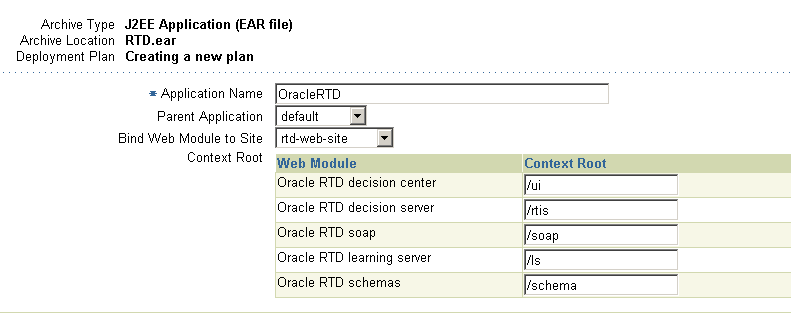
Скриншот 9
-
- Нажать Deploy
- Oracle Real Time Decisions доступен по адресу http://oc4_host:8080/ui
Создадим и настроим схему SURVEYS из статьи "Решения "растут" на деревьях" (Decisions Grow on Trees, by Ron Hardman). Кроме того, зарегистрируем ее в JDBC источниках в OC4J, чтобы мы могли работать с ней в Real Time Decisions.
II. Настройка схемы SURVEYS
- Скачать файл sample data file.
- Разархивировать его и перейти к папке, содержащей скрипт create_user.sql
- Подключиться к SQL*Plus под SYSDBA и выполнить скрипт create_user.sql
- Зайти в консоль управление OC4J по адресу http://oc4j_host:port/em администратором.
Настроим дополнительный JDBC источник для схемы Survyes.
- Перейти на закладку Administration и затем в JDBC Resources. В разделе Connection Pools нажать на Create.
- Ввести следующие значения, остальные оставить без изменения и нажать кнопку Apply
-
Свойство Значение Application Default Connection Pool Type New Connection Pool Name SurveysConnectionPool Connection Factory Class oracle.jdbc.driver.OracleDriver URL Ваша строка соединения к базе данных Username surveys Password (Use Cleartext Password) surveys
-
- Нажать на копку Create в разделе Data Sources
- Ввести следующие значение, остальные оставить без изменения и нажать кнопку Finish
-
Свойство Значение Application Default Data Source Type Managed Data Source Name SURVYES_DS JNDI Location jdbc/SURVEYSDS Connection Pool SurveysConnectionPool
-
- Проверить, что созданные соединения, нажав на Test Connection.
- Перейти в папку OC4J_HOME/j2ee/home/applications/OracleRTD
- Найти файл ./rtis/WEB-INF/web.xml и вставить в конец перед тегом </web-app> следующий текст
<resource-ref id="SURVEYSDS_RTIS">
<res-ref-name>SURVEYSDS</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
<res-sharing-scope>Unshareable</res-sharing-scope>
</resource-ref>
- Аналогичным образом найти и изменить файл ./soap/WEB-INF/web.xml. Только в качестве id теперь будет SURVEYSDS_Axis
- Перейти в папку OC4J_HOME/j2ee/home/application-deployments/OracleRTD
- Найти файл ./rtis/WEB-INF/orion-web.xml и добавить после строки
<resource-ref-mapping name="SDDS" location="jdbc/SDDS" />
строку
<resource-ref-mapping name="SURVEYSDS" location="jdbc/SURVEYSDS" />
- Аналогичным образом найти и изменить файл ./soap/WEB-INF/orion-web.xml.
- Перезапустить OC4J.
Итак, теперь, у нас есть полностью настроенный Oracle Real Time Decisions и мы можем приступить к созданию проекта.
Настройка Oracle Real Time Decisions осуществляется через стандартный инструмент Java JConsole, работающий через JMX протокол.
III. Настройка доступа в Oracle Real Time Decisions.
- Открыть JAVA_HOME/bin/jconsole.exe
- Если у вас запущен OC4J, то jconsole найдет его, и он будет в списке доступных соединений.
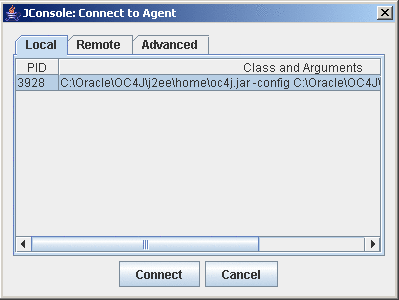
- Нажать Connect
Из всех закладок самая важная для нас - это MBeans, поскольку MBeans и протокол JMX позволяют читать и устанавливать атрибуты, вызывать операции (методы) MBean, подписываться и получать нотификации.
- Перейти на закладку MBeans и раскрыть в дереве OracleRTD.
- Открыть SDClusterPropertyManager->SecurityManager
Включим поддержку аутентификации средствами самого Oracle Real Time Decisions.
- Справа откроются свойста, поставить true в строке AuthenticationEnabled, проверить, что в строке AuthenticationProviderClass стоит com.sigmadynamics.server.security.DBAuthenticator
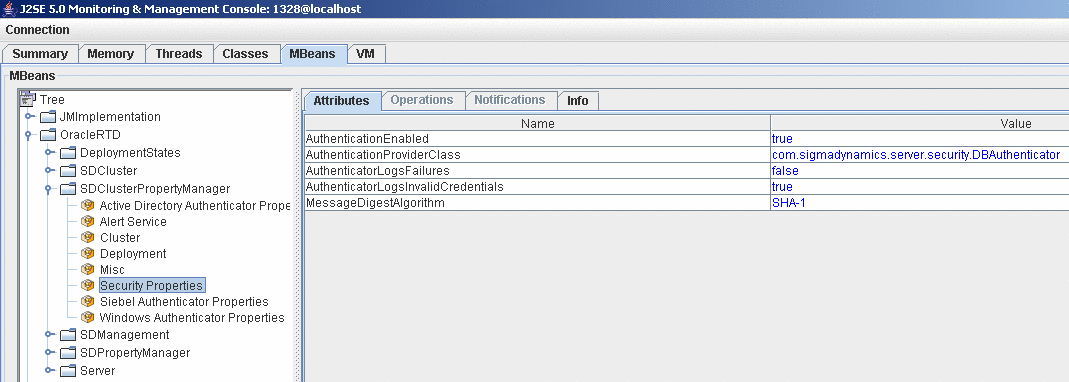
Скриншот 11
Создадим администратора
- Выбрать в дереве, SDManagement->SecurityManager и затем справа закладку Operations.
- В строке с кнопкой createUser вписать значения username - admin, description - admin, password - admin и нажать кнопку .

Скриншот 12
- В строке с кнопкой assignPermission вписать userOrGroup - admin, permCode - 0 и нажать кнопку.

Скриншот 13
Вся разработка для Real Time Decisions ведется в Decision Studio, специальном инструменте, построенном на основе движка Eclipse.
IV. Создание проекта в Oracle Real Time Decisions
- Открыть Decision Studio из RTD_HOME\eclipse\eclipse.exe. Начать новый проект,для этого выбрать в меню File > New > Inline Service Project.
- Ввести название для проекта Surveys и выбираем Basic Template в качестве шаблона. (По умолчанию файлы с проектом располагаются в директории C:\Documents and Settings\WIN_USER\Oracle RTD Studio\Surveys)
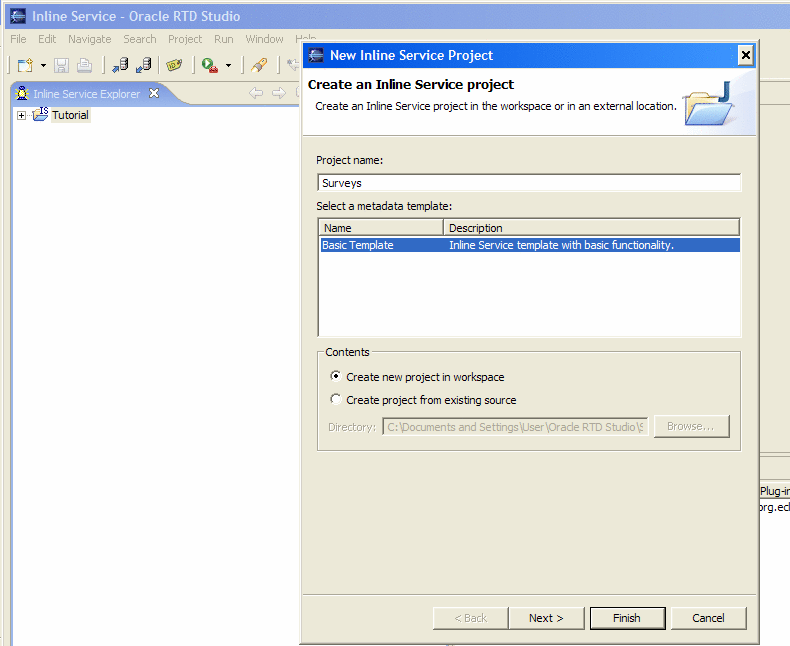
Скриншот 14
Интерфейс Decision Studio устроен следующим образом.

Скриншот 15
- Справа в Проводнике проекта появляется созданный нами проект Surveys. Открыть элемент Surveys > Service Metadata > Application. Это основной объект, в котором содержится вся информация о проекте. Ввести описание для проекта и перейти на закладку Permissions.
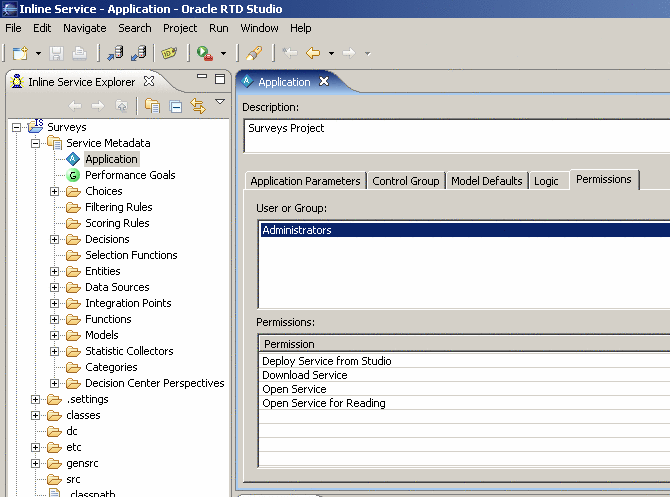
Скриншот 16
-
Для того, чтобы можно было заходить в проект из Decision Studion (Web-приложение для конечного пользователя, необходимо дать доступ пользователя к проекту.
- В разделе User or Groups нажимаем Add и далее Select Server. В появившемся окне вводим имя хоста и номер порта, где установлен RTD, а также имя пользователя "admin" и пароль "admin". Нажимаем Connect и возвращаемся обратно в окно добавления пользователей.
- Нажать галочку Show Users и затем кнопку Get Names. В таблице появится созданный нами ранее пользователь admin. Выбрать его нажать OK.
- Выбрать пользователя admin и нажать в столбец Granted напротив строк Deploy Service from Studio и Download Service. После этого все 4 строчки должны быть помечены.
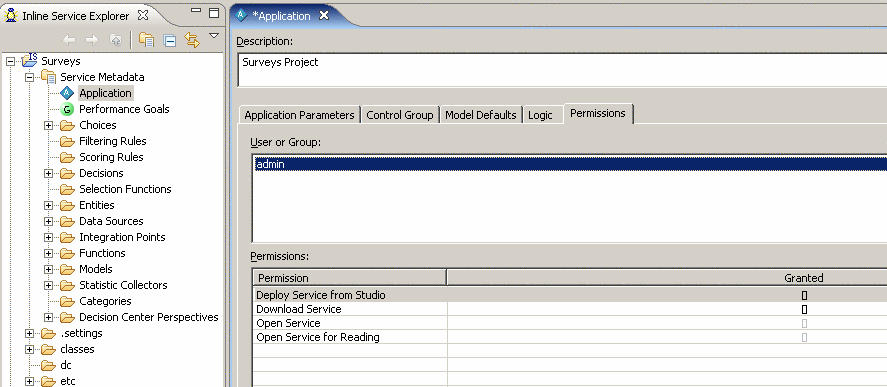
Скриншот 17
-
На предыдущих шагах, мы настроили в OC4J и ORTD поддержку нашего источника данных Surveys Data Source.
- Настроим источник информации для проекта. Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Data Sources и выбрать New SQL Data Source
- Ввести название Surveys Data Source
- Справа откроется окно со свойствами, нажать кнопку Import.
- Свойства сервера должны совпадать с настроенными нами ранее при импорте пользователя admin, нажать Next
- Выбрать SURVEYSDS в качестве JDBC Data Source и таблицу CUSTOMER_SATISFACTION и нажать Finish.
- Все колонки таблицы появятся в Output.
- Перенести колонку Input Customer_Satisfaction_Id направо в input
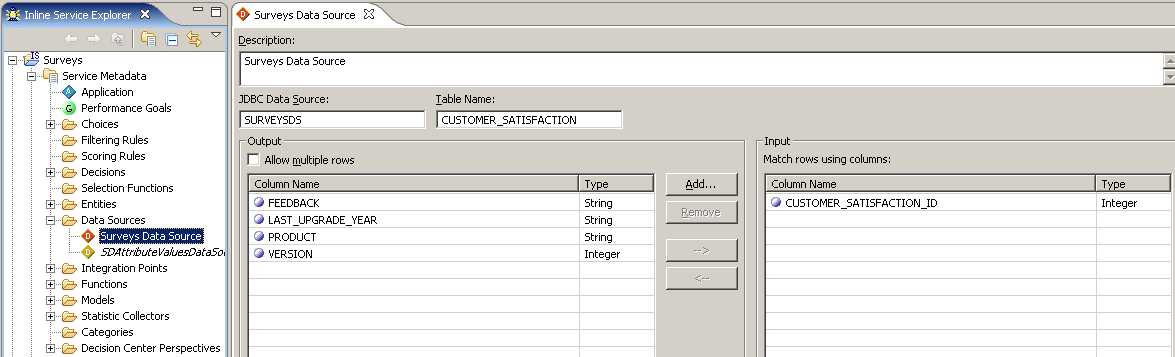
Скриншот 18
-
К этому моменту мы создали новый проект, настроили доступ пользователя admin к нему, настроили источник данных из схемы Surveys. Теперь настроим основную логику работы.
Создадим сущность, описывающую событие, что конкретный продукт получил или положительную или отрицательную оценку.
- Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Entities и выбрать New Entity
- Ввести название Satisfaction
- Нажать на кнопку Import и выбрать в качестве источника Surveys Data Source
- В таблице появится список полей из таблицы
- Нажать кнопку Add Key, ввести Display Label - Id, Data Type - Integer. Созданный ключ появится в таблице с полями.
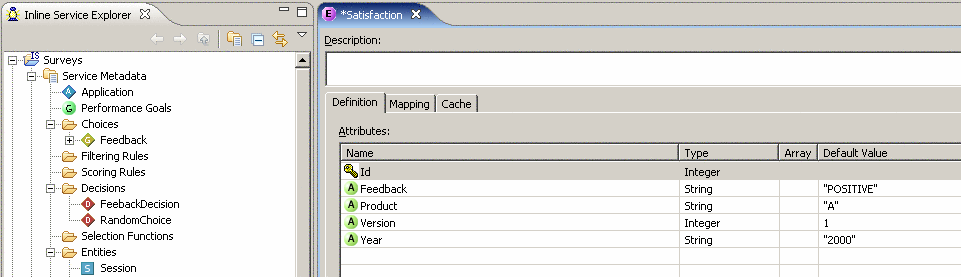
Скриншот 19
- Перейти на закладку Mapping.
В таблице поля, которые были импортированы, автоматически настроены на источник Surveys Data Source. Созданное нами поле Id не имеет привязки к источнику. Нам надо привязать созданный нами атрибут на входные атрибуты.
- В таблице Data Source Input Values нажать на поле в Input Value на поле CUSTOMER_SATISFACTION_ID.
- Выбрать Attribute or variables и сущность Satisfaction, поле Id.
- Выбрать File > Save All
Во всех проекта Real Time Decisions есть специальная сущность Session, которая создается при открытии новой сессии к серверу. Нам надо связать сущность Session с только что созданной сущностью Satisfaction
- Открыть Surveys > Service Metadata > Entities > Session
- Нажать Add Attribute, ввести название Satisfaction, выбрать Data Type - Other, затем Entity Types и Satisfaction
- Нажать Select в около Session Keys from Dependent Entities и выбрать Session > Satisfaction > Id
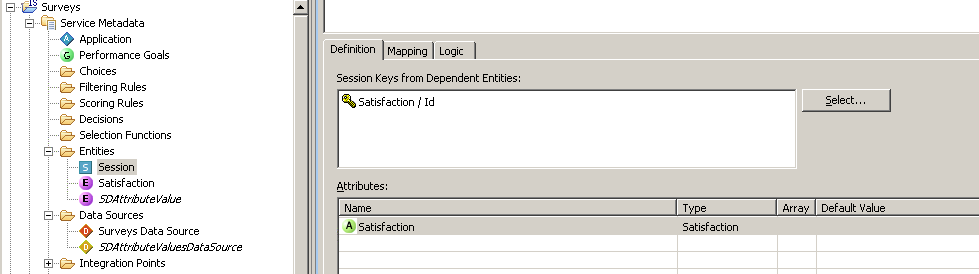
Скриншот 20
-
Для построения анализа зависимостей оценки типа продукта, его версии и год обновления , надо создать группу возможных оценок продукта.
- Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Choices и выбрать New Choice Group, ввести название Feedback.
- На закладке Choices Attributes нажать Add, ввести название code, Data Type - String
C помощью атрибута code, будем определять оценку, которую получает той или иной продукт. Создадим сами оценки.
- Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Choices > Feedback и выбрать New Choice
- Ввести имя NEGATIVE, на закладке Attributes Values ввести значение в поле Attribute Value для атрибута code - NEGATIVE

Скриншот 21
- Аналогичным образом, нажать правую кнопку мыши на элементе Surveys > Service Metadata > Choices > Feedback и выбрать New Choice
- Ввести имя POSITIVE, на закладке Attributes Values ввести значение в поле Attribute Value для атрибута code - POSITIVE
Перейдем к созданию модели для поиска зависимостей между оценками продукта и его характеристиками.
- Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Models > Feedback и выбрать New Choice Model
- Ввести название FeedbackAnalysis, на закладке Choice выбрать Choice Group - Feedback
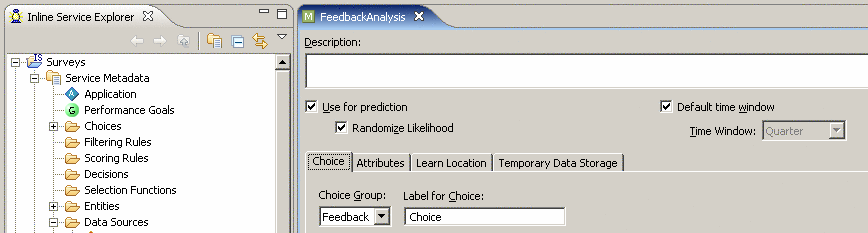
Скриншот 22
-
Необходимо исключить саму оценку из анализа зависимостей.
- На закладке Attributes в разделе Excluded Attributes нажать Select и выбрать Session > Satisfaction > Feedback
Теперь создадим простейший информатор, который будет добавлять новые прецеденты к модели анализа FeedbackAnalysis
- Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Integration Points > Informants и выбрать New Informant, ввести название Process
Для работы информатора надо выбрать Session Key и ввести логику его работы.
- Нажать Select в Session Keys, выбрать Satisfaction / Id
- Ввести 0 в поле Order, убрать галку с Force Session Close и перейти на закладку Logic
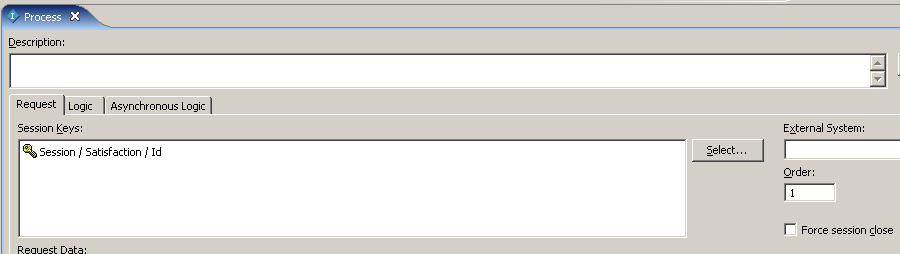
Скриншот 23
На закладке Logic вводится вся логика работы информатора. Логика пишется на языке Java. Список всех методов можно посмотреть в документации. Для обращения к созданным сущностям и объектам, используется стандартная нотация. Поскольку в Real Time Decisions есть сущность по умолчанию Session, то мы можем обратиться к ней всегда. Кроме того, на предыдущих шагах, мы связали Сущность Session c сущностью Satisfaction.
- Ввести следующий код

Скриншот 24
-
Теперь создадим еще одного информатора, который будет закрывать сессию.
- Нажать правую кнопку мыши на элементе Surveys > Service Metadata > Integration Points > Informants и выбрать New Informant, ввести название End
- Аналогичным образом выбрать Session Key - Satisfaction / Id
- Поставить Order - 1 и галку Force Session Close, которая означает после отработки этого информатора сессия будет закрываться.
- На закладке Logic ввести logInfo("Close");
Остается последний шаг, указать модели анализа выбора FeedbackAnalysis, где осуществляется добавление нового прецедента.
- Открыть Surveys > Service Metadata > Models > FeedbackAnalysis
- Перейти на закладку Learn Location, выбрать On Integration Point, нажать Select и выбрать Process.
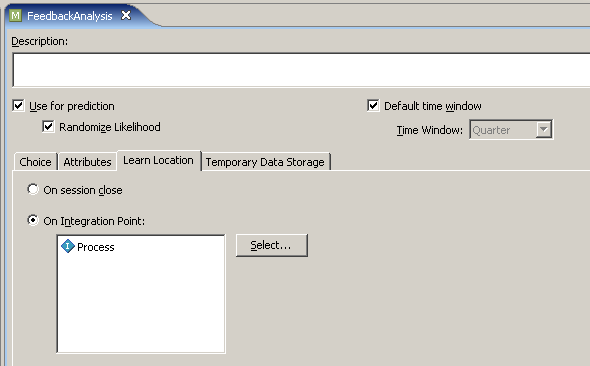
Скриншот 25
- Выбрать File > Save All
После того, как мы создали все необходимые структуры, для того чтобы их протестировать , необходимо "задеплоить" проект на сервер, для этого надо выбрать в меню Project > Deploy. Затем выбрать проект Survyes, ввести название Inline Service - Surveys, Deploymeny State - Development, отметить Terminate active sessions и нажать Deploy.

Если все было сделано правильно, то проект удачно "отдеплоится" на сервер и может приступать к тестированию. Если возникнут ошибки, то их список можно посмотреть, выбрав в меню Windows > Show View > Problems.
Для тестирования необходимо выбрать Windows > Show View > Test.
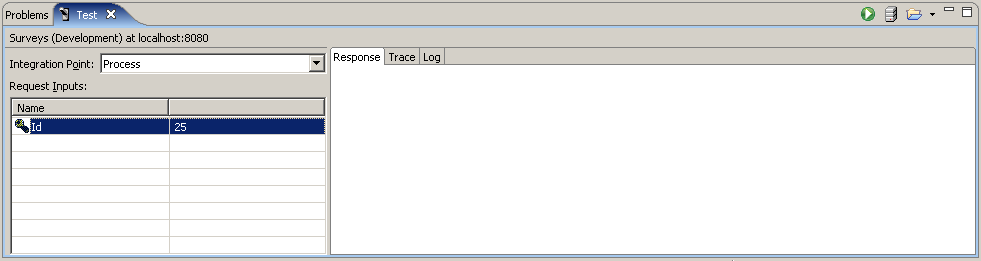
-
Скриншот 27
-
В Integration Point надо выбрать Process, тогда в таблице Request Inputs появится одно поле Id. Введем значение 25 и нажмем справа вверху на кнопку Execute Request. Сервер выполнит наш запрос и запишет результаты в лог. Откроем закладку Log.

Скриншот 28
-
Сервер сделает запрос к таблице CUSTOMER_SATISFACTION по указанному Id, возьмем все характеристики по продукту, и запишет в модель анализа FeedbackAnalysis положительный или отрицательный отзыв.
Для того, чтобы не перебирать руками все записи в таблице CUSTOMER_SATISFACTION, для построения модели анализа. В состав Oracle Real Time Decisions входит специальный инструмент для моделирования работы системы. Называется он Oracle RTD Load Generator и находится RTD_HOME/scripts/loadgen.cmd. Запустим его.
V. Моделирование работы системы
- Нажать Create new Load Generator Script
- Перейти на закладку General и ввести следующую информацию
-
Свойство Значение Client Configuration File RTD_HOME/client/clientHttpEndPoints.properties Graphs Refresh Interval in Seconds 1 Inline Service Surveys (мы указывали название, когда деплоили проект на сервер) Random Number Generator Seed -1 Think Time Fixed Global Think Time Constant 0 Number of Concurrent Scripts to Run 1 Maximum Number of Scripts to Run 4920 Enable Logging Убрать галку
-
- Перейти на закладку Variables, выбрать Script, нажать правую кнопку мыши и выбрать Add Variable
- Ввести название var_Id, Contents - Integer Range, Minimum - 1, Maximum - 4920, Access Type - Sequential
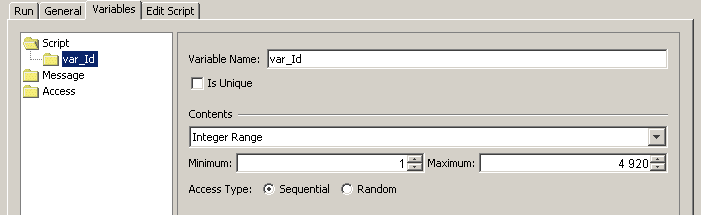
Скриншот 29
- Перейти на закладку Edit Script
- Нажать правую кнопку мыши на белом фоне и выбрать Add Action
- Ввести следующую информацию
-
Свойство Значение Type Message Integration Point Process (Точное название, как он называется в проекте) Inline Service Surveys (мы указывали название, когда деплоили проект на сервер) Is Asynchronous Не отмечен
-
- В таблице Input Fields добавить новое поле, поставить галку на Session Key, Name - id, выбрать Variable - var_Id.
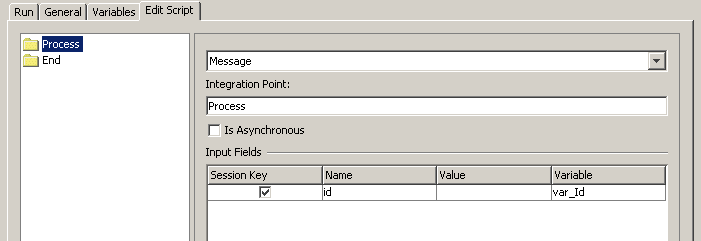
Скриншот 30
- Аналогично добавить еще один шаг в скрипт, нажать правую кнопку мыши на белом фоне и выбрать Add Action
- Ввести следующую информацию
-
Свойство Значение Type Message Integration Point End (Точное название, как он называется в проекте) Inline Service Surveys (мы указывали название, когда деплоили проект на сервер) Is Asynchronous Не отмечен
-
- В таблице Input Fields добавить новое поле, поставить галку на Session Key, Name - id, выбрать Variable - var_Id
- Можно сохранить настроенную конфигурацию в файл.
Построенная нам скрипт будет генерит последовательно id с 1 по 4920 и вызывать шаги Process и End, моделируя работу оператора, который вводит информацию об отзывах о продуктах.
Запустим выполнение построенного нами скрипта.

-
Скриншот 31
-
Если все было сделано правильно, то в поле Total Finished Scripts будет стоять 4920, а в поле Total Errors - 0. Это означает, что все запросы были успешно обработаны сервером Real Time Decisions.
VI. Просмотр результатов
- Зайти по адресу http://oc4j_host:8080/ui, и ввести имя пользователя и пароль admin/admin
- Выбрать Open Inline Service и далее Surveys
После этого открывается интерфейс Decision Center, слева отображается дерево объектов системы, которые можно анализировать.
- Выбрать Surveys (Development) в дереве, затем справа выбрать Interactive Integration Map.
На Integration Map отображается вся информация о логике работы системы, в ней присутствуют все объекты взаимодействия: информаторы (Informants) и советчики (Advisors). В ней можно интерактивно выполнять тот или иной объект, указывая его входные параметры. В нашем тестовом проекте мы ввели только два информаторы Process, которые записывает очередную реакцию на продукт в модель FeedbackAnalysis и End, который закрывает сессию.
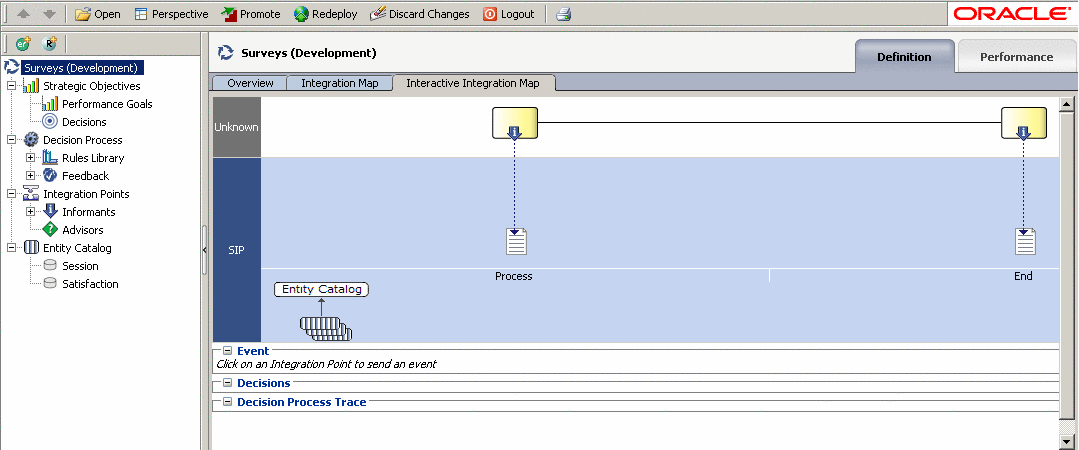
-
Скриншот 32
- Выбрать Surveys > Decision Process > Feedback
Ветка Decision Process является для нас наиболее важной, потому что именно там, находится вся информация о построенной модели для анализа отзывов покупателей.
- Выбрать закладку Performance

-
Скриншот 33
-
Мы увидим общую информацию по группе выборов Feedback, сколько было положительных и отрицательных отзывов.
- Перейти на закладку Analysis

-
Скриншот 34
На этой закладке выводится общая информация по прогнозированию значений атрибутов. Мы видим, что наилучшие прогноз получается на негативных отзывах (NEGATIVE), причем наибольшую влияние на отзыв оказывает атрибуты LAST_UPGRADE_YEAR, VERSION, PRODUCT.
- Перейти в дереве слева в NEGATIVE или POSITIVE и затем на закладку Analysis
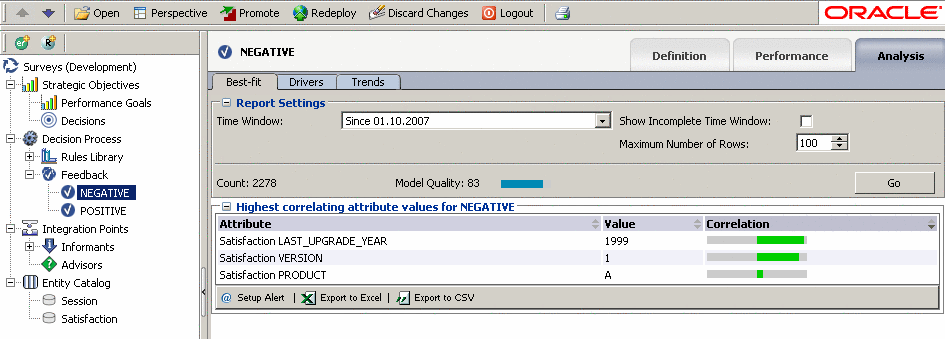
- На закладке Best-fit указаны атрибуты и их значения, которые наиболее сильно влияют на отзыв покупателя или наибольшим образом коррелированны с отзывом.
-
Скриншот 35
Для NEGATIVE мы видим, что наибольшая корреляция наблюдается с LAST_UPGRADE_YEAR = 1991, VERSION = 1 и PRODUCT = A (в порядке степени корреляции)
-
Скриншот 36
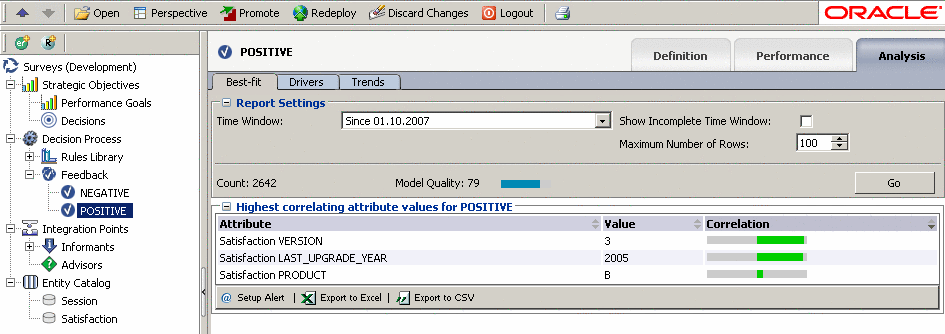
В то время как для POSITIVE наиболее характерно VERSION = 3, LAST_UPGRADE_YEAR = 2006 и PRODUCT = B (в порядке степени корреляции).
- Перейти на закладку Drivers
-
Скриншот 37
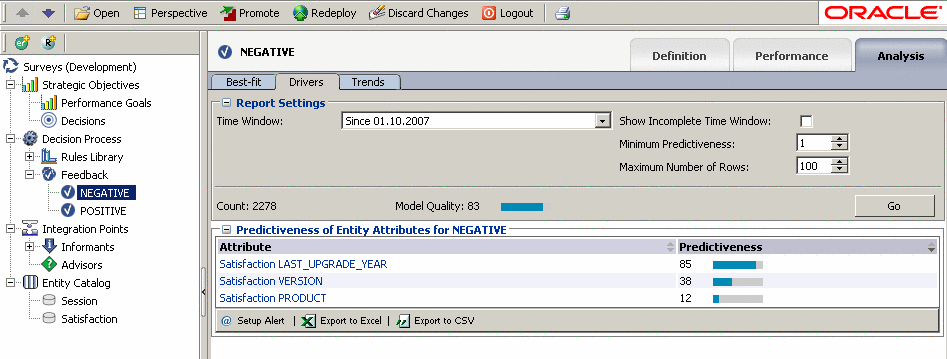
Для NEGATIVE указано, качество предсказания 83%, причем по LAST_UPGRADE_YEAR качество, даже выше, чем вся модель - 85%.
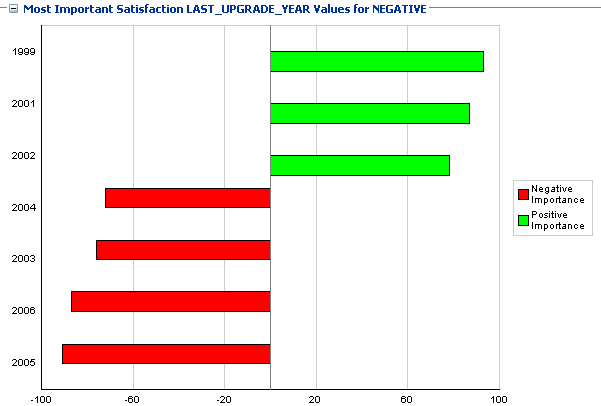
- Нажать на ссылку Satisfaction LAST_UPGRADE_YEAR
-
Скриншот 38
Получим, что негативные отзывы наиболее сильно коррелированны со следующими значениями атрибута LAST_UPGRADE_YEAR: 1999, 2001, 2002 (в порядке степени влияния).
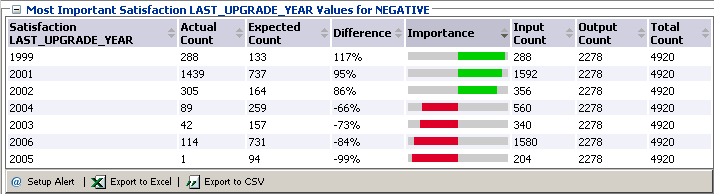
-
Скриншот 39
Для позитивных отзывов получим следующее распределение по атрибуту LAST_UPGRADE_YEAR
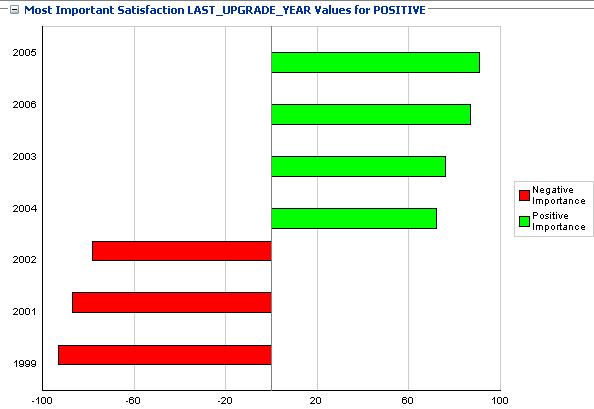
-
Скриншот 40
Наиболее сильно коррелированные годы для POSITIVE: 2005,2006,2003,2004 (в порядке степени влияния).
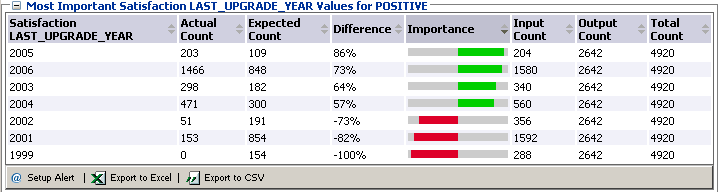
-
Скриншот 41
Аналогичным образом, мы посмотреть результаты по атрибутам VERSION и PRODUCT.
В результате получаются следующие наиболее устойчивые кластеры
NEGATIVE: LAST_UPGRADE_YEAR: 1999, 2001, 2002 VERSION: 1,2 PRODUCT: A POSITIVE: LAST_UPGRADE_YEAR: 2005, 2006, 2003, 2004 VERSION: 3 PRODUCT: B
Таким образом, мы получили следующие результаты: основное расщепление или ветвление осуществляет по атрибуту LAST_UPGRADE_YEAR, если он меньше 2003 года, то отзыв отрицательный, иначе он положительный. При этом если учитывать атрибуты VERSION и PRODUCT в анализе, то получается, что отрицательный отзыв получают продукт A с версиями 1 и 2, а положительный B с версиями 3.
Чтобы посмотреть результаты, надо зайти в Decision Center - приложение для среды J2EE, которое обеспечивает доступ к проекту через Web и позволяет бизнес пользователям просматривать и администрировать проекты, следить за работой всей системы, собирать статистику. На сегодняшний момент корректно Decision Center работает только с Internet Explorer.
Заключение
Если посмотреть на результаты, которые были получены в статье "Решения "растут" на деревьях" (Decisions Grow on Trees, by Ron Hardman) с полученными нами, то видно, что они совпадают. Отличия лишь в максимальной достоверности классификации и представлении самих результатов. В Data Mining Option была получена точность предсказания на уровне 90%. В Real Time Decisions максимальная точность была 83%. Связано это с тем, что в Real Time Decisions использовался Байесовский классификатор, а в Oracle Data Mining деревья решений, которые в данном случае оказались лучше. С точки зрения графической интерпретации результатов, в Oracle Data Miner они были представлены в виде иерархической группировки признаков и их значений (дерева решений). В Real Time Decisions они же были представлены в виде упорядоченных списков коррелированных признаков и их значений. Каждый вариант представления информации имеет свои достоинства и недостатки.
На данном примере очевидными становятся различия в применении Oracle Data Mining и Real Time Decisions. В Data Mining можно легко и быстро осуществить сложный и глубокий анализ на уровне базы данных, причем достоверность классификации будет выше. С другой стороны Real Time Decisions позволяет сроить менее глубокий анализ, но в режиме реального времени. В нашем случае в качестве он-лайн системы, которая генерила события выступал специальный инструмент LoadGen, но с тем же успехом можно подключить и любое бизнес приложение. Real Time Decisions в реальном времени будет пересчитывать модель и строить закономерности между признаками.
- Обратиться в "Интерфейс" за дополнительной информацией/по вопросу приобретения продуктов
- Подробнее о продуктах Oracle
- Приобрести продукты Oracle в ITShop.ru