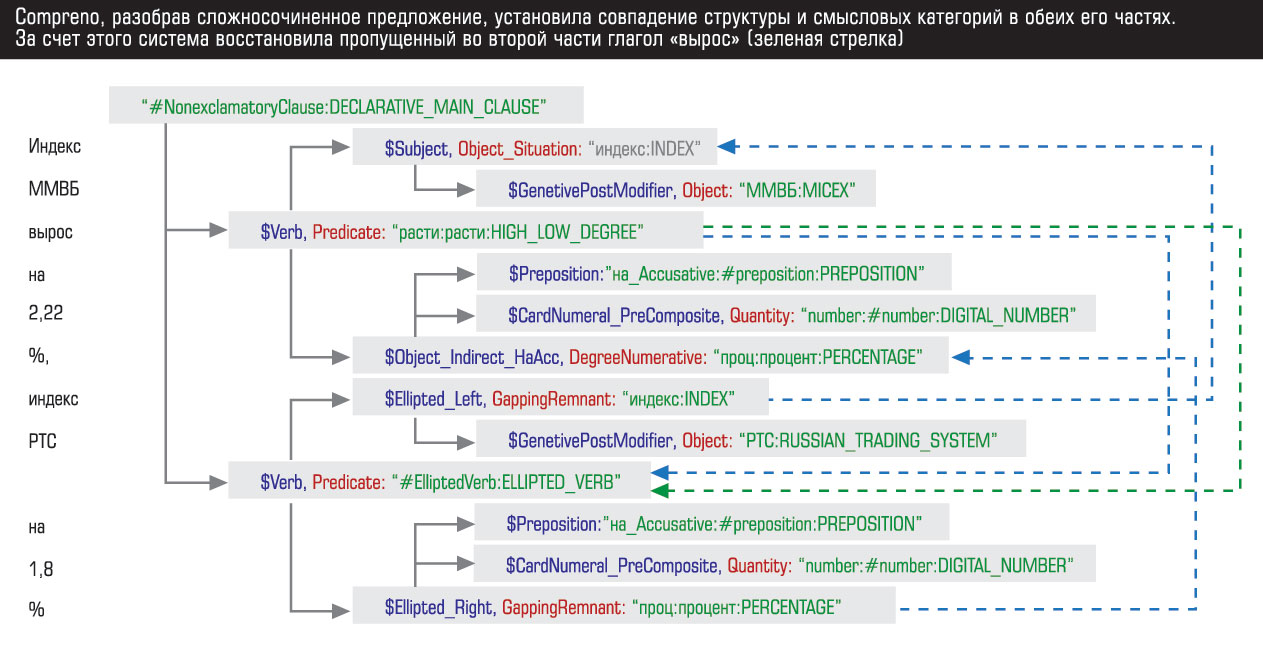
9 апреля компания ABBYY представила первые решения на основе революционной технологии Compreno, разработка которой заняла невероятный для ИТ срок - 19 лет. Однако благодаря ей могут произойти серьезные изменения не только в сфере работы с информацией, но и в нашей повседневной жизни
Два первых решения, представленные ABBYY, ориентированы на корпоративный поиск. Intelligent Search - интеллектуальный поиск, который учитывает не только все формы слов, но и их значения, смысловые связи между словами и контекст употребления. Intelligent Tagger автоматически извлекает из документов объекты, а также события и связи между ними для оптимизации бизнес-процессов и мониторинга различных информационных источников. Эти приложения - лишь первые попытки коммерциализации системы семантического анализа Compreno - универсальной иерархии понятий и модели отношений между ними. Фактически ABBYY попыталась описать чуть ли не все основные понятия, которыми мы пользуемся, и то, как они взаимодействуют между собой в тексте.
Чтобы была понятна смелость замысла, необходимо объяснить его предысторию. С момента появления компьютеров человечество мечтало научить машины общаться с людьми и облегчить общение людей между собой, используя компьютерный перевод. Эти задачи представлялись взаимосвязанными, ведь казалось, что для перевода текста сперва нужно понять его смысл.
Лингвисты vs математики
Первую попытку сделали лингвисты, взявшись за создание модели языка. На возникшую в 1950-1960-х годах компьютерную лингвистику возлагались большие надежды. Казалось, достаточно чуть детальнее, чем в школьном учебнике, описать правила языка, перевести их на язык алгоритмов - и компьютер начнет понимать наши тексты. Но человеческий язык оказался невероятно сложен. То, что в речи нам кажется элементарным и само собой разумеющимся, при попытке формализовать и алгоритмизировать превращается в огромный свод правил и исключений, делающих задачу моделирования языка предельно сложной. Применение нескольких правил приводило к взаимоисключающим результатам.
Кроме того, наш язык омонимичен и неоднозначен. Но и снятие омонимии не избавляет от многообразия оттенков значений, зависимости смысла от синтаксиса и контекста. Даже носители языка не всегда могут однозначно интерпретировать смысл речи. Например, трактовка фразы "мужу нельзя изменять" зависит от пола и гендерных стереотипов. Научить же компьютер выбирать из множества значений нужное оказалось невыполнимой задачей. В итоге лингвисты в рамках первой попытки отчасти справились с описанием морфологии и синтаксиса (на этом построены существующие сейчас системы проверки правописания в текстовых редакторах), но не смогли осилить семантику (понимание смысла) и тем более прагматику (понимание контекста употребления и картины мира автора текста). Поэтому вскоре энтузиазм по отношению к моделированию языка сошел на нет.
На смену лингвистам пришли математики с кардинально иной идеей: "Не нужно ничего понимать, достаточно быстро считать". Рост мощностей компьютеров и взрывное увеличение объема текстов в электронном виде позволили использовать статистические методы для перевода. Сопоставление одного и того же текста на нескольких языках дает возможность вычленять эквиваленты слов и на их основе формировать новые переводы. Казалось, растущие вычислительные мощности решат те задачи, которые не по силам лингвистам. Расхожей фразой стало высказывание, приписываемое руководителю одной из ИТ-компаний: "Каждый раз, когда я увольняю лингвиста, производительность системы возрастает".
Однако качество статистического перевода вполне соответствует его дешевизне. Оценить его можно на примере популярных систем "Яндекс. Перевод" и Google Translate, результаты работы которых хотя и помогают в целом уловить, о чем примерно идет речь, но весьма далеки от желаемого. Проблемы статистического подхода - все то же непонимание смысла текста, а также неумение полноценно анализировать морфологию и синтаксис.
Так, эллипсис - намеренный пропуск слов, несущественных для смысла, и замена существительных местоимениями - становится неразрешимой задачей для статистического перевода. Кроме того, неискоренимы статистические перекосы - например, Google переведет на русский текст о любом премьер-министре в мужском роде, какого бы пола ни была персона, потому что большинство премьер-министров мужчины, и следовательно, в текстах о них эта должность будет вести себя как существительное мужского рода. По этой же причине перевод женских романов может стать предметом нескончаемого веселья. Намного обиднее, когда происходят фактологические замены. Одной из самых известных хохм несколько лет назад стал перевод Google фразы "Путин едет на желтой "Калине"" как "Putin goes to a yellow Mazda". Если с подобными подменами будет переведено с незнакомого вам языка важное письмо, последствия могут оказаться совсем не смешными.
Будущее систем анализа текста в гибридных подходах: можно либо в статистические системы добавлять алгоритмы анализа морфологии и синтаксиса, либо усложнять и детализировать модель языка, в том числе методами статистического анализа.
В поисках смысла
Компания ABBYY началась в 1989 году с создания электронного словаря, следующей освоенной технологией стало распознавание - перевод печатного или рукописного текста в электронный. Напрашивался следующий шаг - создание системы машинного перевода.
ABBYY попыталась реализовать полный синтаксический и семантический разбор текста, решив те проблемы, на которые у компьютерных лингвистов сорок лет назад не хватило сил и вычислительных мощностей. В результате появилась Compreno - система понимания, анализа и перевода текстов на естественных языках. Она включает в себя описание глубинной структуры языка - соотношение используемых в нем смыслов и взаимосвязи между ними. Глубинная структура универсальна для всех языков, поскольку во всех культурах люди используют примерно одни и те же предметы и совершают одни и те же действия. Ее можно представить в виде дерева, толстые ветви которого - общие понятия, а тонкие - понятия более специфические. Например, понятие "стол" относится к родительской категории "мебель", оно может сочетаться с понятиями "собрать", "сидеть за", "быть зачатым на", "дубовый", "дешевый" и т. д. Фактически ABBYY создала универсальный синтетический язык, на который можно перевести текст с любого естественного, а также решить обратную задачу, что необходимо для перевода текстов с одного естественного языка на другой.
На универсальную семантическую модель языка накладываются уникальные для каждого языка морфология и синтаксис. Система анализирует текст и выстраивает дерево связей, с его помощью понимая смысл каждого слова с учетом контекста. Например, наличие в тексте "стола" придает "стулу" совсем другое значение, отсылающее к той же родительской категории, чем контекст медицинских терминов. А отличия в смысле выражений "знать всех местных" и "вся местная знать" невозможно понять без анализа морфологии.
Полнота описания семантики, морфологии и синтаксиса проверяется на внутренней системе статистического анализа. ABBYY собрала гигантский объем корпусов - специальным образом размеченных текстов, на которых осуществляются проверка и обучение системы.
Сейчас в Compreno включено уже 110 тыс. универсальных понятий. По словам Татьяны Даниэлян, заместителя директора по разработке технологий, отвечающей в ABBYY за создание Compreno, такой подход к системам уникален - ей не известно о попытках разработки подобных полноценных систем семантического анализа конкурентами. Пока платформа работает только с английским и русским языками; планируется в будущем добавить немецкий, испанский, французский и китайский.
Задача оказалась куда сложнее, чем виделось изначально. К нынешнему моменту общие трудозатраты составили уже около 2000 человеко-лет. Создание Compreno потребовало от ABBYY 19 лет, 80 млн долларов собственных средств и 14 млн долларов гранта Сколково. Сейчас над проектом трудятся около 350 человек.
"Когда мы начинали проект Compreno в 1995-м, то планировали, что три года уйдет на исследования, а затем за четыре года за счет привлечения дополнительных лингвистов мы заполним систему понятиями и выпустим коммерческий продукт, - рассказывает Татьяна Даниэлян. - Но задача оказалась сложнее, чем представлялось изначально. Кроме того, появившиеся в 2000-х годах онлайновые переводчики, пусть не очень качественные, но бесплатные, заставили нас изменить стратегию коммерциализации". Google Translate занял нишу быстрого понимания: люди, которым время от времени нужно понять примерный смысл иноязычного текста, не готовы платить за это, и бесплатный статистический перевод является сильным конкурентом. Из наиболее понятных для коммерциализации остались ниши профессионального перевода и интеллектуального поиска. Технологически поиск проще перевода, а его рынок достаточно емкий и растущий. Именно поэтому поиск был выбран первым проектом для реализации.
По оценкам компании IDC, объем мирового рынка корпоративного поиска в 2014 году составит 2 млрд долларов, а появление более эффективных инструментов может значительно увеличить его размер. Кроме того, вывод новой технологии на уже сформировавшийся и понятный рынок дает время на то, чтобы доработать технологию, прежде чем предлагать пользователям более непривычные для них решения.
Сейчас рынок корпоративного поиска поделен между тремя основными игроками: Google, HP и Microsoft, которые в сумме занимают долю около 80%. "Наши первые тесты говорят, что мы показываем преимущество по точности и полноте результатов поиска", - уверяет Антон Тюрин, директор департамента продуктов Compreno. В менее официальных комментариях сотрудники говорят, что "рвут конкурентов".
Татьяна тут же на примере показывает работу поиска. Специально для нас она проиндексировала 15 тыс. новостных заметок на русском языке. На первой странице Intelligent Search автоматически выскакивают фасеты - наиболее важные и часто встречающиеся категории: упомянутые персоны, географические объекты и даты. На запрос "отделение" система уточняет, какое из множества значений "отделения" имелось в виду, и легко различает в выдаче: "отделение" в смысле организации (отделения банков) или "отделение" - как выделение части из целого. Любая система неидеальна - я быстро нахожу, что Intelligent Search воспринимает "и. о." и "исполняющий обязанности" как разные понятия. Татьяна тут же заходит в сервис рекламаций и отправляет лингвистам заявку на дополнение словаря. Поиск от ABBYY легко уточняется и масштабируется на новые предметные области, так как смысл многих понятий в словаре общей лексики и, например, медицинском весьма разнится. Дерево понятий поражает дотошностью. Так, класс Beautiful person включает в себя в русском варианте "богиню", "королеву", "кралю", "красаву", "няшку", "пупсика" и еще множество слов, не сразу приходящих на ум при описании кого-либо прекрасного.
Intelligent Tagger позволяет автоматически вычленять факты и связи между объектами. По запросу "Сноуден" система рисует легкочитаемую инфографику, отображающую ключевые факты: родился, учился, работал; разбивку событий по годам, ключевых лиц, с которыми он был связан, причем их система вычленяет из новостной базы не только по именам, но и по социальным ролям, например girlfriend.
Количество возможных применений Compreno ограничено лишь фантазией заказчика. Например, можно настроить анализ корпоративной переписки на поиск любых эвфемизмов для "откат" и "вознаграждение" или негативных отзывов о руководителе, причем система поймает не только прямые упоминания "Иван Иваныч" или "генеральный", но и "дражайший", "сам" и "наш козел".
Интеллектуальный поиск может работать не только с корпоративными документами. Запустив робота на индексацию интернета, можно отыскать все упоминания о каких-либо событиях, фактах или персонах в определенных контекстах и взаимосвязях. Например, можно использовать систему для поиска взаимосвязей между сотрудниками вашего отдела снабжения и руководителями поставщиков, и вполне возможно, что кто-то из них родственники или учился в одном классе. Сейчас министерство внутренней безопасности США публикует длинный перечень ключевых слов, по которым осуществляется мониторинг интернета: от "Аль-Каиды" и "теракта" до "исламистов" и "свинины". Использование поисковых решений на основе Compreno позволит более изощренно и эффективно подходить к контролю интернета, чем уже заинтересовались компетентные службы.
Как признался нам генеральный директор ABBYY Сергей Андреев, компания мечтала бы сосредоточиться на лицензировании технологий сторонним разработчикам. Но как стало очевидно на примере нынешней "дойной коровы" ABBYY - решений в области распознавания текстов и потокового ввода данных, только непосредственная работа с конечным потребителем дает понимание его нужд и возможность совершенствовать под них технологию.
Цены на Intelligent Search и Intelligent Tagger не называются, поскольку формируются в зависимости от объема задач в каждом конкретном случае и числа используемых процессоров. Но, по словам Антона Тюрина, средняя цена установки корпоративного поиска на рынке - 62,5 тыс. долларов, и решения ABBYY будут вполне конкурентоспособны по цене. Ключевой рынок, на который нацелена ABBYY, - Соединенные Штаты.
Плоды понимания
Однако поисковые решения - лишь первый шаг. Compreno - базовая технология, которая может быть использована в десятках различных приложений, предназначенных для работы с текстом. Уже на этапе финальной доработки находится eDiscovery - поиск информации в документах в рамках юридических разбирательств, аудита и расследований в США, Великобритании и других государствах. В них требуется обработка огромных массивов корпоративной информации для дальнейшего поиска и выявления фактов и доказательств.
В числе следующих решений - анализ тональности высказываний (отношения автора к предмету обсуждения) в текстах, обрабатываемых, например, в процессе мониторинга СМИ и социальных сетей. Охрана "информационного периметра" организации с выявлением фактов передачи несанкционированной информации и система прогнозирования и оповещения о наступлении событий. Настоящим переворотом может стать планируемый выход программы семантического перевода - ориентированного на передачу смысла с учетом контекста.
Пока ABBYY в своих решениях нацелена на корпоративный рынок, ввиду его готовности платить. Однако издержки, которые несет человечество из-за языковых барьеров, несопоставимо обширнее корпоративного спроса. Появление системы осмысленного перевода (коим не всегда могут похвастать даже переводчики из плоти и крови), особенно в сочетании с технологиями распознавания речи, может перевернуть нашу повседневную жизнь. Небольшой гаджет или приложение на мобильном позволят нам понимать все основные языки мира и общаться на них в режиме реального времени.
Но еще большие перемены сулит семантический анализ в применении к проблеме "больших данных". Сейчас маркетологи, госорганы, врачи, юристы, соцсети, спецслужбы и многие другие копят гигантские данные, количество которых в мире удваивается каждые 12-18 месяцев. Но проку от них пока немного: 80% накапливаемых данных являются неструктурированными, поэтому их поиск, анализ и обработка крайне затруднены. Использование семантического анализа радикально изменит ситуацию, сделав наш мир электронных данных тотально прозрачным и контролируемым.
Compreno ориентирована на понимание и передачу смысла текста. Художественных изысков она порой не понимает и уж точно не ориентирована на то, чтоб их синтезировать. Можно предположить, что массовое распространение семантического анализа повлияет и на наш язык, сделает его проще и строже. Иначе тех, кто выражается излишне затейливо, не поймет даже их собственный холодильник.
Впрочем, чуждость Compreno языковой эстетике имеет свой плюс. Любой художественный текст система интерпретирует и переводит лишь как набор информации, поэтому плоды ее работы вряд ли будут радовать утонченностью стиля. А значит, какие-то задачи для переводчиков и журналистов еще останутся. Осталась бы для них аудитория.