Данной статьей хотелось бы показать шаги и предложить некоторые рекомендации в процессе создания BI-решения с использованием практически всего стека BI компании Microsoft. В создании BI-решения будут использованы SQL Server, SQL Service Integration Services, SQL Server Analysis Services.
Для примера мы выбрали разработку нашей компании RetailIQ - BI-систему глубокого анализа чеков розничных продаж, поставок и складских запасов для сети аптек. Для общего понимания контекста темы: все данные выгружаются из учетных систем (1С, М-Аптека и т.д.), верифицируются, складываются в специальную базу данных с последующим построением многомерных OLAP-кубов. Из источников (учетных систем) с помощью ETL мы перекачиваем данные в хранилище, на основе которого строим куб, о котором дальше пойдет речь.
Построение витрины данных
Построение витрины данных наиболее важный шаг, так как от витрины данных зависит корректность отображаемых данных и время процессинга куба SSAS.
На данном шаге решается, какие данные нужно отобразить (остатки, продажи и т.д.) и в каких разрезах (например, продукт, дата, сотрудник, филиал).
Определяются источники данных, из которых можно получить данные (файлы, web-сервисы, другие БД). Какие преобразования необходимо сделать в получаемых данных для поддержания целостности.
Также готовится витрина данных - реляционная база данных, в которую будут сливаться данные из разрозненных источников. Для построения витрины данных можно использовать две схемы хранения данных: схема звезда и снежинка. В этой статье есть описание обеих схем. Какую схему применять в том или ином случае во многом зависит от данных. Однако обычно мы используем схему снежинки, так как, на наш взгляд, это позволяет упростить манипуляции с данными.
Совет #1 Источниками для куба должны быть представления (View)
Источники для OLAP-куба, на наш взгляд, лучше всего делать в виде представлений, а не привязывать непосредственно к таблице. Это позволит делать любые изменения в источнике, не меняя сам OLAP-куб. Также, на наш взгляд, лучше всего не делать запрос в самом Data Source View, так как изменения в DSV проекта SSAS делать проблематично.
Создаем ETL
ETL - это процесс передачи и трансформации данных согласно определенным бизнес-правилам. Для данного шага у нас есть некоторое количество рекомендаций.
Совет #2 Строки NA
В таблицы измерений добавляются элементы "Нет данных" (NA). Они будут служить привязкой к тем данным, у которых отсутствует привязка в таблицах фактах в источниках. Например, если у нас есть продажи по продукту, который нельзя определить, будем складывать с его ключом NA. Если у измерения есть привязка к другим таблицам, то в тех таблицах также нужно определить NA элементы и задать в NA элементе измерения привязку к этим записям.
Например, пусть у нас есть таблица Car, у которой есть привязки к таблицам CarType и CarMark. Делаем примерно так:
INSERT INTO CarType (ID, Name) VALUES (0, "NA") INSERT INTO CarMark (ID, Name) VALUES (0, "NA") INSERT INTO Car (ID, Name, CarTypeID, CarMarkID) VALUES(0, "NA", 0, 0)
Совет #3 Суррогатные ключи
Мы рекомендуем генерировать суррогатный ключ, даже если есть первичный ключ в источнике. Первичный ключ источника лучше записывать в отдельную ячейку таблицы измерения с именем "Native Key". Что мы получим:
- сможем определить NA элемент
- первичные ключи из разных источников могут совпадать
- у нас есть свобода выбора формата первичного ключа в нашей БД (например, можем использовать Guid, даже если в источниках используется INT).
Совет #4 Установка NA значений в ETL пакете
Если в источнике фактов значения ячеек CarID и EmployeeID содержат NULL, либо те данные, которые отсутствуют в наших измерениях, то используем следующее преобразование:

В обоих Lookup-ах поле "Specify how to handle rows with no matching entries" устанавливаем значение "Ignore failure". Таким образом, неизвестные ключи будут иметь значение NULL. В элементе "Set NA To Dimension" NULL заменяем на значение NA для каждого измерения.
Совет #5 Документирование ETL
По завершению работы над пакетом создаем следующий XLS-файл, который будет служить документацией нашего ETL-пакета.
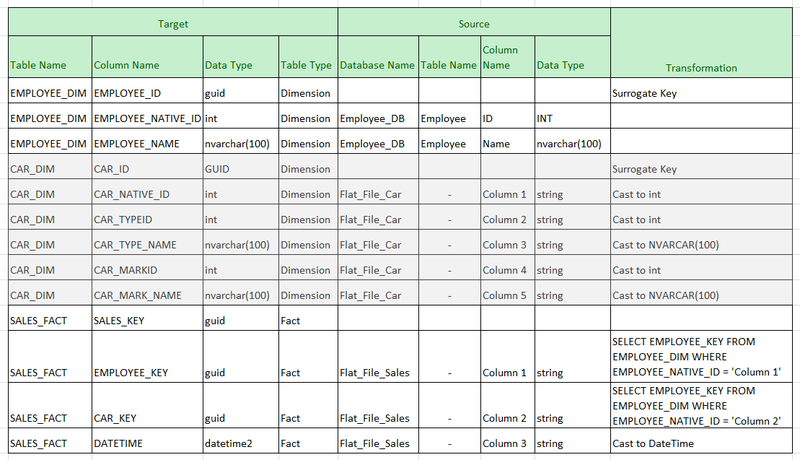
По данной таблице можно легко определить, откуда и куда данные "перетекают".
Создаем куб
Куб является конечной точкой нашей работы. Для его создания у нас также припасено несколько советов.
Дату и время необходимо разносить в разные измерения
Обычно OLAP-кубы созданные с помощью SSAS не очень хорошо работают с измерениями, которые содержат большое количество записей. По нашему мнению лучше всего избегать случаев, когда дата и время находятся в одном измерении. Предположим, мы хотим создать измерение Дата-Время, в которой будет точность до секунды. Записей в данном измерении за 10 лет будет: 10 лет * 365 дней * 24 часа * 60мин * 60 сек = 315 360 000 ≈ 315 млн записей.
Точность до секунды в аналитических базах обычно не требуется, так как задачи у куба другие по сравнению с операционными базами, но если же все же нужно добавить время в куб, то сделать это лучше в отдельном измерении.
Совет #6 Создание иерархий с одинаковыми элементами
Предположим у нас есть задача построения иерархии: Тип автомобиля->Марка автомобиля->Название автомобиля из таблицы вида:
| CarID | Name | CarTypeID | CarType | CarMarkID | CarMark |
| 1 | Mercedes-Benz F 800 Style | 1 | Sport | 1 | Mercedes |
| 2 | Smart | 2 | Microcar | 1 | Mercedes |
CarID в данном случае будет ключом к измерению, а CarTypeID и CarMarkID атрибуты измерения. Предполагаем, что после процессинга куба получим следующее:

Но, к сожалению, так просто не получится, группа Mercedes будет принадлежать либо Sport, либо Microcar (зависит, какая строка будет обработана в первую очередь). Данное ограничение можно обойти с помощью составного ключа для атрибута. Сделаем ключ для атрибута CarMark вида CarTypeID + "_" + CarMarkID. В итоге на входе в куб получим примерно такую таблицу:
| CarID | Name | CarTypeID | CarType | CarMarkID | CarMark |
| 1 | Mercedes-Benz F 800 Style | 1 | Sport | 1_1 | Mercedes |
| 2 | Mercedes-Benz F 800 Style | 2 | Microcar | 1_2 | Mercedes |
В результате получим необходимую для нас иерархию.
Также мы бы рекомендовали для каждого атрибута измерения по мере возможности определять наименование и ключ из отдельных источников.
Мы привели лишь самые простые рекомендации при построении OLAP-куба, которые могут добавить гибкости и расширяемости вашим BI-решениям. Надеемся, советы окажутся вам полезными и сделают труд создания аналитических решений более легким!
Источники
Основные информацию о кубах можно прочитать в статье habrahabr.ru/post/66356/.
Expert Cube Development with Microsoft SQL Server 2008 Analysis Services
www.sql.ru/ - :)
