Введение
Со времени появления хиромантии искусство предсказания будущего прошло долгий путь. Теперь для этого используется большое количество исторических данных, которые анализируются и обрабатываются, а затем вводятся в систему прогнозирования для ее обучения. Прогностическая модель предполагает соединение данных и математических методов для решения конкретной задачи. Когда имеется четко сформулированная задача и построена модель для ее решения, нужно тщательно измерить и оценить ошибки прогнозирования. Такая оценка модели используется для определения ее точности. Затем на основе результатов оценки выбирается лучшая модель и устанавливаются точные пороги дискриминации. Прогностические модели в сочетании с бизнес-правилами могут существенно влиять на финансовые результаты предприятия. Поэтому прогностическое решение в сочетании с данными, математическими методами и бизнес-правилами обеспечивают повышенное качество деловых решений.
Прогностический анализ позволяет компаниям и частным лицам строить решения, способные использовать исторические данные для предсказания будущего. Но чаще всего даже превосходные прогностические модели остаются без применения, так как задача, которую они пытаются решить, недостаточно четко определена.
Принято считать, что построение прогностического решения начинается с анализа данных и первичной обработки, за которыми следует построение модели и т.д. На самом деле оно начинается еще раньше. Прогностическое решение предполагает соединение данных и математических методов для решения конкретной задачи. Чтобы решение было успешным, эта задача должна быть четко сформулирована. Если задача определена плохо, будет трудно измерить результаты, полученные при оценке решения, и, следовательно, его не удастся внедрить в производство. С другой стороны, четко поставленная задача позволяет четко оценить, насколько хорошо предлагаемое решение. Это облегчает понимание результатов и укрепляет доверие к ним всех участников.
При наличии конкретной, четко поставленной задачи, аналитики могут проанализировать исторические данные, чтобы убедиться, что они позволяют построить решение. Даже если они не совершенны, имеющиеся данные, могут послужить основой для построения успешного прогностического решения. Когда анализ данных выполнен, наступает очередь предварительной обработки. За этим этапом следует построение модели, которое ведет к созданию собственно прогностической модели. После оценки работоспособности модели она помещается в бизнес-контекст и, наконец, внедряется в практику. В этой статье рассматриваются все этапы процесса создания прогностического решения, от предварительной обработки данных до внедрения. Для иллюстрации многих из этих этапов я буду использовать систему IBM SPSS Statistics.
Предварительная обработка данных: от "сырых" данных к параметрам
Можно ли построить прогностическую модель непосредственно по необработанным данным? Или нужно ли предварительно обрабатывать данные перед построением модели? Как обычно все зависит от обстоятельств. Хотя некоторые поля данных можно использовать "как есть", для подавляющего большинства требуется определенная предварительная обработка.
Исторические данные поступают в самых разнообразных формах и форматах. Например, данные могут содержать структурированную и неструктурированную информацию о конкретном покупателе. В этом случае структурированные данные состоят из таких полей, как возраст, пол и количество покупок за прошлый месяц. Эта информация извлекается из учетной записи покупателя и его прошлых транзакций. Неструктурированные данные могут содержать отзывы того же покупателя о товарах или услугах. В первой и второй статьях этого цикла я использовал аналогичные поля данных для иллюстрации одного из приложений прогностического анализа: прогнозирования оттока покупателей ввиду истощения спроса. Тем, кто читает статьи по порядку, эта задача должна быть уже знакома.
Для построения прогностической модели с целью определения риска оттока клиентов может потребоваться группирование значений некоторых входных полей. Например, всех покупателей в возрасте до 21 года можно отнести к категории студентов. Аналогично, всех покупателей старше 55 лет можно отнести к категории пенсионеров. А каждого покупателя в возрасте от 21 до 55 лет ― к категории работающих. Очевидно, что это упрощение исходного поля возраста, но оно может увеличить его прогностическую силу на этапе обучения прогностического метода. На самом деле увеличение прогностической силы полей входных данных и является конечной целью предварительной обработки данных. Извлекая признаки из необработанных данных, мы фактически выделяем то, что имеет значение. Таким образом, мы упрощаем технику прогнозирования, чтобы выявить важные модели, скрытые в данных.
Еще одна цель предварительной обработки ― изменение данных таким образом, чтобы они подходили для обучения. Например, в зависимости от используемого метода построения модели может потребоваться разделение на три возрастных категории, перечисленных выше. В этом случае, если покупателю A 25 лет, то его возраст будет представлен тремя различными полями - студент, работник и пенсионер, ― которые будут иметь значения соответственно 0, 1 и 0. По той же причине может потребоваться нормализация любых полей с непрерывными значениями. В нашем случае количество покупок в прошлом месяце будет преобразовано в число со значениями от 0 до 1. Обратите внимание, что само по себе исходное поле уже является результатом первичной обработки, так как представляет собой комбинацию: общее количество покупок по всем транзакциям, имевшим место за определенный период времени.
Кроме того, можно принять решение об использовании интеллектуального анализа текста для выявления признаков истощения спроса в комментариях и создать меру истощения спроса, которая также может быть представлена значениями от 0 до 1. Затем можно представить каждого покупателя набором его параметров и объединить их в запись. Если выбрано 100 параметров и существуют 100K покупателей, мы придем к набору данных, содержащих 100K строк, или записей, и 100 столбцов.
Для упрощения обработки данных, помимо предоставления пользователям возможности управлять своими данными, как описано выше, ряд статистических пакетов позволяет им выбрать вариант автоматической предварительной обработки данных. Например, IBM SPSS Statistics позволяет создавать параметры автоматически. Для этого выберите Transform menu > Prepare Data for Modeling и нажмите кнопку Automatic. Вам будет предложено указать свою цель. Можно выбрать один из четырех вариантов: 1) сбалансированные быстродействие и точность; 2) оптимизация по быстродействию; 3) оптимизация по точности и 4) настраиваемый анализ. Этот последний вариант рекомендуется только опытным пользователям. IBM SPSS Statistics позволяет также применять к данным множество преобразований. Они легко доступны через меню Transform.
Когда данные надлежащим образом обработаны, наступает время обучения модели.
Обучение модели: извлечение модели из данных
В процессе обучения все записи данных обрабатываются методом прогнозирования, который отвечает за извлечение модели из данных. В случае задачи об оттоке клиентов это будут модели, которые отличают "челночных" клиентов от лояльных. Обратите внимание, что цель здесь заключается в создании функции сопоставления между входными данными (возраст, пол, количество покупок за последний месяц и т. д.) и целевой, или зависимой переменной (челночный - лояльный). Методы прогнозирования бывают разные. Некоторые, такие как нейронные сети (NN) и метод опорных векторов, ― очень мощные и отличаются способностью обучаться сложным задачам. Эти методы также являются универсальными и могут применяться для решения самых разных задач. Другие, такие как деревья решений и оценочные таблицы, способны объяснить логику своих предсказаний. Учитывая, что методы прогнозирования рассматривались во второй статье этого цикла, я остановлюсь здесь на NN. Имейте в виду, что те же принципы построения модели применимы ко всем другим методам. С этого момента я предполагаю также, что читатель ― это аналитик, ответственный за задачу моделирования.
Чтобы построить NN в IBM SPSS Statistics, выберите Analyze menu > Neural Networks и нажмите кнопку Multilayer Perceptron. Появится окно с вкладками, позволяющее настроить все параметры, необходимые для построения прогностической модели.
На вкладке Variables выберите целевую, или зависимую переменную и все входные переменные, которые нужно предоставить сети для обучения. В IBM SPSS Statistics входные данные нужно разделить на факторы и ковариаты. Факторы представляют собой категорийные поля ввода, такие как возраст, которые мы преобразовали ранее, наполнив значениями: студенты, работающие и пенсионеры. IBM SPSS Statistics автоматически дискретизирует их до начала обучения. Ковариаты представляют собой непрерывные переменные. Они автоматически масштабируются для повышения качества обучения сети. Учитывая, что дискретизация категорийных и масштабирование непрерывных переменных применяется по умолчанию, нет необходимости делать это до начала обучения модели.
Набор данных, содержащий предварительно обработанные данные, обычно делится на две части: одна резервируется для обучения модели, а другая ― для ее тестирования. Первый набор данных, как правило, содержит 70% от общего объема данных. Второй набор, содержащий оставшиеся данные, используется для проверки достоверности модели (см. ниже). IBM SPSS Statistics выполняет такое разделение по умолчанию. Это можно изменить, выбрав вкладку Partitions.
Как и любой прогностический метод, NN имеет параметры, которые можно настраивать в зависимости от данных и задачи, которую вы пытаетесь решить. На вкладке Architecture можно выбрать автоматическое определение архитектуры или, в зависимости от вашего уровня знаний, ручную настройку сети с выбором определенного количества уровней и узлов в уровне. Более подробная информация об архитектуре NN и ее значении для обучения содержится во второй статье этого цикла. На вкладке Training находятся другие параметры, включая скорость обучения (как быстро сеть должна обучиться?) и алгоритм оптимизации. Имейте в виду, что неправильный выбор параметров может помешать обучению. Также отметим, что, как и в случае с любыми лекарствами (отпускаемыми по рецепту или нет), выбор того или иного параметра для прогностического метода всегда сопровождается побочными эффектами. Например, если выбрать слишком низкую скорость обучения NN, она "завязнет". А при слишком высокой скорости не будет сходиться. Хорошим началом всегда служат значения параметров по умолчанию, устанавливаемые IBM SPSS Statistics.
IBM SPSS Statistics содержит и другие вкладки настройки конфигурации, которые будут обсуждаться в следующем разделе. Когда все вкладки настроены должным образом, пора приступать к построению модели. Для этого достаточно нажать кнопку OK в нижней части окна с вкладками настройки конфигурации.
Проверка модели: оценка точности
Для проверки модели обычно оставляют до 30% данных. Использование образца данных, которые не участвовали в обучении модели, позволяет беспристрастно оценить ее точность.
Во вкладке Output выберите Classification results для вывода результатов классификации. По завершении обучения в таблице Classification будет находиться мгновенный снимок состояния модели. Он позволяет быстро узнать, удалось ли модели обучиться задаче, или нет. Точность не обязательно должна быть 100%-й. На самом деле бывает, что прогностические модели делают неверные предсказания. Мы хотим гарантировать лишь то, что они будут делать как можно меньше ошибок, давая много правильных прогнозов. В переводе на жаргон прогностического анализа, модель должна иметь низкий уровень ложноположительных (false-positives - FP) и ложноотрицательных (false-negatives ― FN) результатов, что предполагает высокий уровень истинных положительных (true-positives ― TP) и истинных отрицательных (true-negatives ― TN) результатов. Для задачи об оттоке клиентов, если модель точно присваивает высокий риск ухода тому, кто уже почти потерян, то это означает TP. Если она присваивает низкий риск ухода тому, кто действительно остается лояльным клиентом, это означает TN. Однако каждый раз, когда модель присваивает высокий риск ухода удовлетворенному клиенту, это FP. Аналогично, если она ошибочно присваивается низкий риск ухода тому, кто на самом деле готов уйти, это FN.
На рисунке 1 приведен график данных испытаний после их оценки. График предполагает, что модель выдает значения оценки риска от 0 до 1000 и что чем выше оценка, тем выше риск. Так как проверочные данные помечены, их можно разделить на две отдельных кривых: челночные клиенты, представленные красной кривой, и лояльные, представленные голубой кривой. Зеленая линия указывает порог дискриминации, который мы выбрали на уровне 500. Таким образом, если оценка для клиента ниже этого порога, он считается лояльным. А если оценка выше 500, клиент считается челночным. Однако как видно из рисунка 1, порог, равный 500 создает ряд ошибок типа FP и FN. Выбрав более высокий порог, скажем 600, мы сведем к минимуму ошибки типа FP, но ошибки FN останутся. Выбрав более низкий порог, скажем 400, мы существенно минимизируем ошибки типа FN, но останется больше ошибок FP. Здесь напрашивается вопрос: какой из всех потенциальных вариантов пороговых значений будет идеальным? Ответ зависит от бизнес-целей и расходов, связанных с ошибками разного типа.
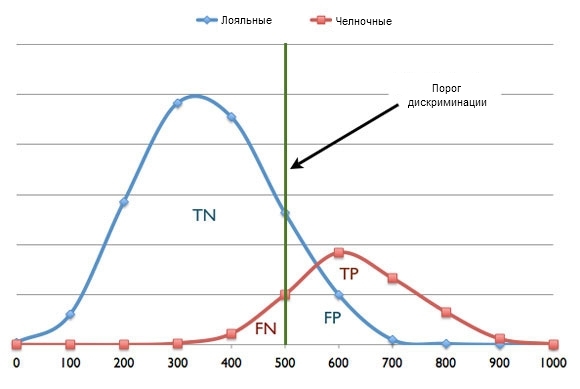
Расходы, связанные с ошибками типа FN, обычно существенно отличаются от расходов, связанных с ошибками типа FP. Для примера с оттоком клиентов, если модель ошибочно признает клиента почти безнадежным (FN), компания потеряет все будущие доходы, которые могла бы получить от этого клиента. А предлагая пакеты льгот и скидок удовлетворенным клиентам (FP), она выбрасывает деньги на ветер. Поэтому в зависимости от расходов, связанных с ошибками каждого типа, можно решить, какая прогностическая модель выдает меньше ошибок FN, чем FP, и наоборот. Это решение и будет определять идеальный порог дискриминации.
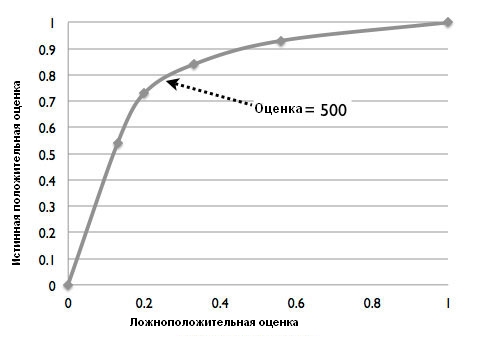
Отличный способ оценки точности модели, обученной классифицировать входные данные на два класса, опирается на изучение ее ROC-кривой (Receiver Operating Characteristic ― рабочая характеристика приемника), которую также можно использовать для выбора идеального порога дискриминации. Эту кривую можно получить в IBM SPSS Statistics, выбрав вкладку Output и нажав кнопку ROC Curve. ROC-кривая обеспечивает графическое представление уровня истинных положительных (чувствительность) и ложноположительных (единица минус определенность) результатов для двоичного классификатора при изменении порога дискриминации. На рисунке 2 показана ROC-кривая для модели риска оттока клиентов, в которой уровень истинных положительных результатов получен при разных порогах дискриминации путем деления числа TP на общее количество челночных клиентов (представленное на рисунке 1 красной кривой). Аналогично, уровень ложноположительных результатов получается при других порогах дискриминации путем деления количества FP на общее число лояльных клиентов (представленное на рисунке 1 голубой кривой). Как видно из рисунка 2, оценка 500 соответствует переломной точке кривой, в которой мы получаем относительно низкий уровень ложноположительных и высокий уровень истинных положительных результатов.
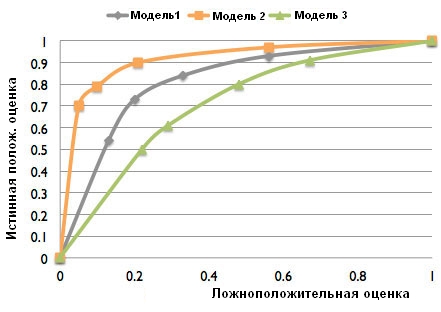
Кроме того, для сравнения различных моделей (при построении нескольких моделей с различными параметрами) можно использовать площадь под ROC-кривой (значение которой IBM SPSS Statistics выводит вместе с ROC-кривой). Чем больше площадь, тем точнее считается модель. На рисунке 3 показана ROC-кривая для трех различных моделей: 1, 2 и 3. Очевидно, что модель 2 точнее моделей 1 и 3.
Заключительная обработка данных: от оценки до деловых решений
Необработанные выходные данные прогностической модели обычно имеют значения в интервале от 0 до 1 или от -1 до 1. Чтобы сделать их более наглядными, эти данные часто переводят в интервал от 0 до 1000. Выходные данные модели можно также масштабировать по заданной функции, чтобы определенное значение указывало на желаемое количество TP и FP.
Заключительная обработка также подразумевает внедрение оценки в рабочий процесс. В этом случае оценки должны переводиться в деловые решения. Например, для задачи прогнозирования оттока клиентов компания может предложить клиентам с высоким уровнем риска оттока более существенный пакет удержания. На самом деле для поиска разных деловых решений можно использовать разные значения порога дискриминации в зависимости от результата, а также от количества TP и FP и их стоимости.
Системы управления принятием решений, которые традиционно включали только бизнес-правила, теперь содержат и прогностические модели. Для этого модели "завертываются" в правила. Сочетание бизнес-правил и прогностического анализа позволяет компаниям извлекать пользу из знаний двух типов: экспертных и основанных на анализе данных. В этом случае решения, полученные при различных пороговых значениях, можно сразу реализовывать и даже расширять, добавляя другие важные факторы. Например, чтобы определить реальную ценность клиента, полученный для него риск оттока можно сопоставить с потраченной в прошлом суммой денег. Если расходы высоки, но и риск оттока высок, тем важнее убедить этого клиента остаться.
Объединение экспертных знаний со знаниями, извлеченными из данных, делает системы управления принятием решений рациональнее, так как они приобретают дополнительные возможности по принятию решений.
Создание прогностического решения начинается с четкой постановки задачи, которую оно должно решать. Когда цель четко определена, аналитики могут взяться за создание прогностической модели, которая будет точной и преимущества которой будут понятны всем заинтересованным сторонам.
Когда задача, которую нужно решить, поставлена, проводится анализ и предварительная обработка исторических данных в рамках подготовки модели к обучению. Результатом этого процесса становится набор функций, которые повышают прогностическое значение исходных данных. Предварительная обработка данных необходима, чтобы сделать исходные данные пригодными для обучения модели. Учитывая, что существует множество методов прогнозирования, прогностическое решение может извлекать выгоду из конкретного метода, такого как NN, или от группы методов, которые работают над решением данной проблемы вместе.
После построения прогностической модели ее нужно проверить. Так как ошибки ― неотъемлемая часть прогностического анализа, можно использовать различные пороги дискриминации, не только сводя к минимуму количество ошибок, но и сокращая связанные с ними расходы. Используя различные пороговые значения в сочетании с бизнес-правилами, можно построить многоуровневую систему, оптимизирующую использование оценок, производимых прогностической моделью. Наконец, в результате объединения бизнес-правил и прогностического анализа рождается истинно прогностическое решение.
В четвертой, последней статье этого цикла мы остановимся на внедрении прогностических решений и их эксплуатации.