Этот пост для тех, кто сталкивался с проблемой производительности, при расчете медианы в OLAP кубе.
Одним из главных достоинств OLAP технологии является скорость получения результатов при обращении к базе. Расчеты происходят "на лету". Однако с медианой, не все так просто.
Для справки: медиана - вид средней. Это величина, которая находиться в середине ряда значений отсортированного по возрастанию. Например, для ряда значений {1, 2, 5, 6, 9} медианой является 5.
Рассмотрим ситуацию на примере OLAP сервера от Microsoft - SSAS 2008 (SQL Server Analysis Services).
Для расчета медианы SSAS предлагает использовать MDX функцию Median. С ее помощью вы можете создать вычисляемую меру (Calculated Member) и использовать ее в расчетах.
Перед нами стояла задача проектирования OLAP куба для анализа данных о вакансиях на рынке труда полученных из различных источников. Общее число вакансий составляло около 10 миллионов. Мы реализовали медиану для определения среднего уровня заработной платы с помощью функции Median. Никакого расчета "на лету" при работе с кубом не получилось. При этом другие агрегации, например количество вакансий считались быстро.
Проблема в том, что такие агрегации как количество или сумма являются "преагрегированными" - при обновлении куба они рассчитываются заранее, а при запросе данных сервер отдает уже готовые результаты. В случае с медианой, сервер не рассчитывает ее значения заранее, а вычисляет ее при каждом обращении к кубу.
Рассмотрим пример отчета: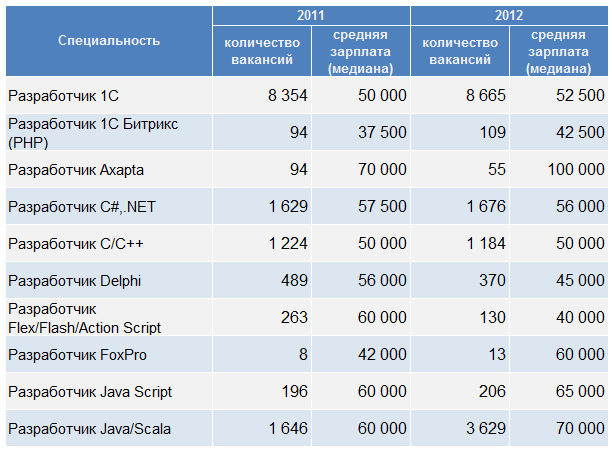
Для специальности "Разработчик 1С" в 2011 году было найдено 8 354 вакансии. Для расчета медианы зарплаты по этой специальности серверу необходимо произвести следующие операции: выборка всех значений относящихся к этой ячейке отчета, сортировка их по значению заработной платы, определение значения находящегося посередине ряда значений (кортежа). И так для каждой ячейки. Поэтому время выполнения отчета сильно возрастает. Основное время при этом уходит именно на сортировку.
Решение
Значения для расчета медианы выбираются из таблицы фактов хранилища данных, на основании которой создан OLAP куб. Что если предположить что таблица фактов будет заранее отсортирована по значению заработной платы. Тогда нам не нужно сортировать значения для каждой ячейки. Нужно просто определить для каждой ячейки число элементов и вычислить номер элемента, который находится посередине ряда. Значение этого элемента и будет медианой.
Код для создания Calculate Member:
//Количество значений в кортеже
CREATE MEMBER CURRENTCUBE.[measures].[AdvCount]
AS Count(NonEmpty([Advertisement].[ID].members,[Measures].[Salary]) as AdvSet),
VISIBLE = 0 ;
//Поиск значения находящегося посередине кортежа
CREATE MEMBER CURRENTCUBE.[Measures].[MedianReal] AS ([measures].[AdvCount]-1) * 50 / 100,
VISIBLE = 0;
CREATE MEMBER CURRENTCUBE.[Measures].[MedianInt] AS Int([Measures].[MedianReal]),
VISIBLE = 0;
CREATE MEMBER CURRENTCUBE.[Measures].[MedianFrac] AS [Measures].[MedianReal]- [Measures].[MedianInt],
VISIBLE = 0;
//Расчет медианы
CREATE MEMBER CURRENTCUBE.[Measures].[MedianLow]
AS (NonEmpty([Advertisement].[ID].members,[Measures].[Salary]).Item([Measures].[MedianInt]).Item(0),[Measures].[Salary]),
VISIBLE = 0;
CREATE MEMBER CURRENTCUBE.[Measures].[MedianHigh]
AS (NonEmpty([Advertisement].[ID].members,[Measures].[Salary]).Item([Measures].[MedianInt] + 1).Item(0),[Measures].[Salary]),
VISIBLE = 0;
CREATE MEMBER CURRENTCUBE.[Measures].[Salary Median]
AS ([Measures].[MedianLow] * [Measures].[MedianFrac])
+([Measures].[MedianHigh] * (1 - [Measures].[MedianFrac])),
FORMAT_STRING = "# ### ### ##0;-# ### ### ##0",
VISIBLE = 1 , ASSOCIATED_MEASURE_GROUP = 'Advertisement';
Данный код учитывает ситуацию, когда в кортеже содержится четное число элементов. В этом случае медиана вычисляется как среднеарифметическое двух значений находящихся посередине ряда. Если для вашей задачи не требуется абсолютная точность, то вы можете в этом случае считать медианой левое или правое значение. Для этого придется немного изменить вышеприведенный код, но это еще больше сократит время расчета.
Теперь о том, как заранее отсортировать таблицу фактов. Допустим, у вас есть исходная таблица фактов, данные в которую накапливаются по мере времени. Сделайте копию этой таблицы и вставьте туда данные из исходной таблицы отсортированные по необходимому значению.
Пример SQL запроса:
INSERT INTO CopyBasicTable
SELECT * FROM BasicTable ORDER BY ValueField
Данную операцию необходимо будет делать каждый раз перед обновлением OLAP куба. Конечно, в этом способе есть серьезный минус - при большом количестве данных время операции будет существенным. Однако для сравнительно небольших объемов этот способ вполне подходит. Аналогичным способом можно производить расчет процентилей и квартилей.