Краткое описание: В этом уроке мы создадим программу на delphi, которая демонстрирует результаты работы алгоритма сортировки подсчетом, я объясню вам принцип алгоритма и его ограничения на использование.
Давайте приступим. Создаем новый проект, кидаем на форму кнопку (Button) и Memo. При нажатии на кнопку мы будем заполнять массив случайными значениями и сортировать его, результаты сортировки будут отображены в Memo. Вначале совсем чуть-чуть теории. В ней я расскажу про то, в каких случаях следует применять этот алгоритм. Сортировка подсчетом применяется тогда, когда массив заполнен неотрицательными значениями и кода эти значения не слишком большие, т.к. при работе алгоритма создается временный массив, длина которого зависит от максимального значения элемента сортируемого массива. Зачем тогда ее вообще использовать? Затем, что если максимальное значение элемента не слишком высоко, то эта сортировка работает очень быстро. Если кому-то важно, то эта сортировка работает за время О(k) (ограничено сверху), где k - верхняя планка диапазона значений. Т.е. если k = n (n - длина массива), то сортировка будет происходить за время О(n), что очень быстро. Но все равно, эта сортировка очень редко где применяется, обычно используют быструю сортировку. теперь давайте от теории отойдем и приступим к практике, к нашему любимому кодингу!! Вначале надо создать событие OnClick для Button. Здесь мы и будем писать наш код. Я вначале покажу вам код, а затем его откомментирую. Итак, встречайте! Его Величество, Код! =)
Ну что ж, поехали. Начнем с переменных. i - переменная для счетчика for. В k хранится диапазон значений, точнее максимальное значение диапазона. tmp - строка, которая будет хранить в себе все значения массива и выводить их в Memo. A, B - массивы. В А хранится неотсортированная последовательность чисел, в B мы будем записывать отсортированные. C - темповый динамический массив [0..k]. Идем дальше. С randomize я думаю, что вы знакомы. Затем мы инициализируем k. т.е. наш диапазон чисел будет от 1 до 50. Затем мы выделяем память для массива C. Инициализируем tmp. В первом цикле for мы инициализируем массив A случайными значениями в пределах нашего диапазона, записываем эти значения в строку, разделяя пробелом и увеличиваем значение элемента, равного значению массива A, на единицу, тем самым мы узнаем, сколько одинаковых значений есть в массиве A. т.е. C[i] равно количеству элементов, равных i. Если в массиве A все значения уникальны, т.е. нет одинаковых элементов, то можно в C[i] записывать единицу. В следующем цикле for мы запоминаем в массиве C, сколько элементов меньше, чем текущий, т.е. C[i] равно количеству элементов, не превосходящих i. Чтобы это узнать, мы прибавляем к текущему элементу значение предыдущего, а т.к. у нас в массиве С хранится количество элементов, то мы как раз и узнаем то, что нам надо. И в следующем цикле небольшая мозговая атака - Мы каждый из элементов массива A помещаем на нужное место в массиве B. Помогает нам в этом массив C. И затем мы убавляем значение элемента в массиве C на единицу. Опять же, если массив A содержит уникальные значения, то этого делать не надо. Вот и все. Для наглядности и лучшего понимания приведу то, что хранится в массивах A и C.
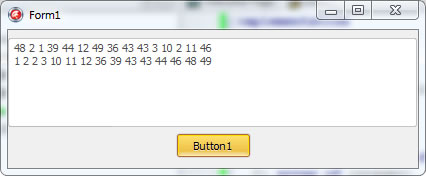
В C* отображено то, что содержится в массиве C после первого цикла. Давайте теперь разберем на таблице. Разбираем C*. В массиве A нолей нет, поэтому и в C* ноль. единица одна, поэтому и там один. двоек в массиве A две, поэтому и в C* двойка и так далее... С массивом C разбираться нечего. Каждый столбец - сумма всех предыдущих. Думаю, после этого все встало на места и с разбором этого алгоритма можно закончить. Вот вам скриншот работы программы.
procedure TForm1.Button1Click(Sender: TObject); var i, k: integer; tmp: string; A, B: array [1..15] of integer; C: array of integer; begin randomize; //Диапазон значений от 1 до 50 k := 50; // C := [0..k], а не [0..k - 1] setlength(C,k + 1); tmp := ''; for i := 1 to length(A) do begin // Только положительные числа A[i] := random(k) + 1; inc(C[A[i]]); tmp := tmp + IntToStr(A[i]) + ' '; end; Memo1.Lines.Add(tmp); tmp := ''; for i := 2 to k do inc(C[i], C[i-1]); for i := length(A) downto 1 do begin B[C[A[i]]] := A[i]; dec(C[A[i]]); end; for i := 1 to length(B) do tmp := tmp + IntToStr(B[i]) + ' '; Memo1.Lines.Add(tmp); end;
A
5
4
3
10
3
9
8
7
7
2
C*
0
1
2
1
1
0
2
1
1
1
C
0
1
3
4
5
5
7
8
9
10