Большинство компаний заинтересовано в поиске новых путей повышения трафика и получения дохода от инвестиций в онлайн-проекты. Однако увеличение объема информации и количества онлайн-сервисов затрудняет организацию быстрого и персонализированного доступа к этой информации. Одним из путей решения данной задачи является использование механизма рекомендаций, который может побудить посетителей Web-сайта рассмотреть дальнейшие предложения. Такие механизмы на основании различных шаблонов и анализа предпочтений пользователей выдают пользователям предложения, о которых в противном случае те могли бы и не узнать. В данной статье рассматривается интеграция механизма рекомендаций с открытыми исходными кодами Apache Mahout с IBM® WebSphere® Application Server V8.0 и IBM Rational® Application Developer for WebSphere Software V8.0.3.
Чтобы не отстать от быстро развивающейся глобальной индустрии, техническим специалистам необходимо следить за основными тенденциями в сфере ИТ и искать способы внедрения важнейших из них в своей компании. Одной из таких тенденций является использование механизмов рекомендаций, побуждающих пользователей исследовать предложения вашего Web-сайта или бизнеса. Эти механизмы, основываясь на разнообразных шаблонах, рекомендуют пользователям предложения, о которых в противном случае они могли бы и не узнать.
Некоторые наиболее популярные Web-сайты интенсивно используют механизмы рекомендаций. Например, посетители Amazon или Netflix часто видят персонализированные рекомендации, звучащие примерно так: "Если вы интересуетесь этим товаром, возможно, вас также заинтересует и этот…". Эти сайты используют рекомендации, чтобы направить пользователей (и доход) к другим предлагаемым ими товарам осмысленным и понятным способом, привязанным к конкретному пользователю и его предпочтениям.
Даже если вы не продаете книги или фильмы, у вас может быть множество причин для того, чтобы реализовать нечто подобное. Вы можете рекомендовать сопутствующие товары, особенно если предлагаете обширную номенклатуру товаров или услуг. Вы можете рекомендовать более абстрактные вещи, такие как связанные по смыслу страницы, которые могли бы посетить пользователи, список популярных сервисов, подходящие возможностей для обучения, специальные предложения или доступ к полезным техническим документам.
Вместо того чтобы строить догадки об интересах широкого круга пользователей, персонализация посредством рекомендаций позволяет ненавязчиво и точно идентифицировать предпочтения и антипатии отдельных пользователей и применить эту информацию для адаптации к потребностям каждого пользователя. Рекомендации новых вариантов на основе предыдущего поведения широко используются во многих приложениях и отраслях, и именно на этот пример мы будем ссылаться на протяжении всей статьи.
Проект Apache Mahout представляет собой небольшой, но достаточно мощный механизм рекомендаций с открытыми исходными кодами, хорошо реализующий эти концепции для небольших и средних компаний. В данной статье рассматривается интеграция Apache Mahout V0.5 с IBM WebSphere Application Server V8.0 и IBM Rational Application Developer for WebSphere Software V8.0.3. Статья начинается с обзора механизмов рекомендаций и общего описания Apache Mahout, после чего в ней объясняется, как можно интегрировать этот механизм с WebSphere Application Server и Rational Application Developer, а также предлагаются дальнейшие действия по поиску дополнительной информации по данной технологии.
Главное предназначение механизма рекомендаций - сделать выводы из имеющихся данных для отображения взаимоотношений между объектами. Объекты могут быть самые разные, в том числе пользователи, изделия, товары и т.д. Взаимоотношения предоставляют степень сходства или принадлежности объектов. Например, взаимоотношения могут представлять рейтинги продуктов (скалярная величина) или указывать, занес ли пользователь страницу в закладки (бинарная величина).
Чтобы выдать рекомендацию, механизм рекомендаций выполняет ряд действий по анализу данных. Все начинается с входных данных, представляющих объекты, а также их взаимоотношения. Входные данные состоят из идентификаторов объектов и взаимоотношений с другими объектами. На рисунке 1 приведена общая схема.
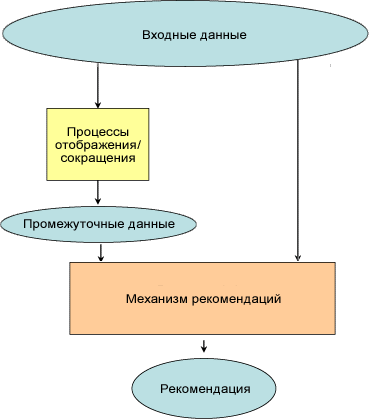
Рассмотрим рейтинги продуктов, которые присваивают им пользователи. Используя эти входные данные, механизм рекомендаций вычисляет показатель сходства между объектами. Это вычисление может потребовать много времени в зависимости от объема данных или конкретного алгоритма. Для распараллеливания вычисления показателей сходства можно использовать распределенные алгоритмы, такие как Apache Hadoop. Существуют разные алгоритмы вычисления показателей сходства. Наконец, используя информацию о сходстве, механизм может выдать рекомендацию на основе запрошенных параметров.
Возможно, вы знали о полезности механизмов рекомендаций, но избегали их, считая их слишком сложными. На самом деле механизмы рекомендаций весьма разнообразны и действительно могут быть очень сложными. К счастью, существуют инструменты, позволяющие продемонстрировать необходимые концепции в рамках одной статьи. Более того, изучив эти инструменты, можно применить их для реализации этих концепций на практике. Разработчики Apache Mahout сделали масштабируемость и доступность одной из главных целей проекта, поэтому вы можете расширять свое решение по мере возникновения новых потребностей.
Прежде чем приступать к персонализации приложения и использованию механизма рекомендаций, следует принять несколько важных решений:
- Какой алгоритм применять
Самое важное решение, которое нужно принять, - это выбор алгоритма работы с данными. Выбор зависит от того, что нужно идентифицировать и какой тип взаимоотношений определен в данных. Вот некоторые типичные подходы, используемые для рекомендаций:
- Совместная фильтрация (collaborative filtering). Этот подход основан на социальном взаимодействии между пользователями. Рекомендации базируются на предпочтениях других пользователей.
- Кластеризация (clustering). При данном подходе механизм пытается сформировать рекомендации на основе показателей сходства между пользователями или продуктами.
- Категоризация (categorization). При данном подходе продукты автоматически группируются в категории на основе общих атрибутов. Программа пытается классифицировать все продукты.
В данной статье основное внимание будет уделено совместной фильтрации, что поможет изучить социальные аспекты пользователей; полученные знания также станут хорошей отправной точкой для добавления рекомендаций в Web-приложения.
Совместная фильтрация - это простая и популярная методика. Ее простота состоит в том, что пользователи делают самую важную работу за вас, формируя интересующие вас критерии. При совместной фильтрации рекомендации вырабатываются на основе анализа рейтингов пользователей или продуктов. Есть два подхода к совместной фильтрации, главное отличие между которыми заключается в способности к масштабированию по мере роста количества пользователей в системе:
- Рекомендация, основанная на информации о пользователях
В этом подходе к выработке рекомендаций используются показатели сходства между пользователями, формируемые путем выявления общности продуктов, оцененных каждым пользователем. Например, если продуктами являются курсы, двух пользователей можно считать очень похожими, если оба выбрали одинаковые курсы. С другой стороны, их сходство будет минимальным, если они выберут абсолютно разные курсы. Алгоритмы выдачи рекомендаций основываются на оценках, выставленных похожими пользователями курсам, которые еще не прошел данный пользователь. Такой подход к рекомендациям очень прост, но у него есть существенное ограничение: чтобы сгенерировать показатели сходства, необходимо сравнить каждого пользователя со всеми остальными. Эти методика приемлема для приложений с небольшим числом пользователей, но по мере роста их числа время выполнения оценки растет экспоненциально.
- Рекомендация, основанная на информации о продуктах
Этот подход к выработке рекомендаций начинается с выявления продуктов, ассоциированных с пользователем. Для формирования списка рекомендаций алгоритм вычисляет сходство каждого продукта, ассоциированного с пользователем, с другими продуктами в наборе. Чтобы определить вероятность того, что пользователю понравится рекомендованный продукт, алгоритм просматривает оценки продукта пользователем и вычисляет взвешенную оценку каждого рекомендованного продукта. Главная проблема основанного на продуктах подхода к рекомендациям заключается в том, что необходимо создать индекс сходства для каждого доступного продукта. Однако изменения в продуктах происходят реже, чем изменения в пользователях, поэтому при таком подходе показатели сходства можно вычислить заранее в автономном режиме и периодически их обновлять.
- Масштабирование процесса для пользователей
Реальный процесс вычисления показателей сходства пользователей и продуктов является ресурсоемкой операцией. В зависимости от размера набора данных операция может продолжаться от нескольких миллисекунд до нескольких минут. При работе с Web-приложениями время реакции становится проблемой, если ожидание пользователем рекомендации затягивается.
Хотя показатели сходства пользователей и продуктов можно вычислять в режиме реального времени, при работе с большими базами данных необходимость такого вычисления надо тщательно оценить. При обоих подходах к выдаче рекомендаций рекомендуется выполнять вычисления в автономном режиме, если набор данных является большим (например, более 1 миллиона оценок). Автономные вычисления возможны в ситуациях, когда новые продукты добавляются редко или пользователи дают свои оценки лишь периодически, поскольку показатели сходства нужно вычислять только при добавлении нового продукта или указания новой оценки для него. При таком сценарии механизм рекомендаций может использовать согласованные показатели сходства.
Одним из способов предварительного вычисления показателей сходства в автономном режиме является использование возможностей распределенных вычислений продукта Apache Hadoop - реализации с открытыми исходными кодами методики MapReduce. Именно поэтому вы часто будете слышать об этих системах при обсуждении механизмов рекомендаций. Чтобы выработать рекомендации на основе большого объема разрозненных данных, вам необходимо сократить объем информации, что позволяют сделать эти системы.
К счастью, Apache Mahout умеет формировать задания, которые можно передать в Apache Hadoop для вычисления показателей сходства. После завершения вычислений можно загрузить результаты в источник данных, чтобы Web-приложение могло их использовать.
- Хранение данных
Наконец, необходимо определиться с хранением данных. Это могут быть необработанные входные данные или данные, содержащие вычисленные автономно (например, при помощи Apache Hadoop) показатели сходства. Если источником данных является огромный архив необработанных данных, возможно, придется выполнить их анализ, чтобы получить полезную информацию для механизма рекомендаций. Наборы данных можно хранить в файловой системе или в распределенном источнике данных. Если наборы данных невелики, можно программно считать их из файловой системы и записать в оперативную память. Однако если наборы данных велики, следует подумать о применении систем управления базами данных, таких как IBM DB2®, Apache Derby и т.д. В случае использования распределенных источников данных необходимо правильно настроить механизм оптимизации запросов (например, индексы).
Но ситуация не обязательно должна быть настолько сложной. Для простоты предположим, что у нас есть небольшой пул данных, который можно поместить в небольшую базу данных, например, в основанную на Java™ систему управления базами данных с открытыми исходными кодами Apache Derby, поставляемую с WebSphere Application Server V8. При выборе подхода необходимо на основании конкретных данных определить, какую систему хранения использовать: распределенную файловую систему или систему управления базами данных.
Как говорилось в статье developerWorks Введение в Apache Mahout (EN), целью проекта Apache Mahout является создание масштабируемых библиотек машинного самообучения. Apache Mahout реализован на базе Apache Hadoop, но не ограничен использованием только распределенных файловых систем.
Это подводит нас к цели статьи - алгоритмам машинного самообучения, предоставляемым Apache Mahout для преобразования данных в рекомендации. Мы сосредоточимся на реализованном в Apache Mahout алгоритме фильтрации, основанной на пользователях. В нашем примере используются социальные ссылки, поскольку есть множество способов получить такие данные и легко внести их в базу данных.
Предположим, нам нужно создать Web-приложение, предоставляющее пользователям рекомендации по продуктам, основанные на оценках других пользователей. У нас есть набор данных с такими оценками. Для простоты данные примера, включенные в статью, обезличены, поскольку мы будем работать только с идентификаторами пользователей и продуктов. В реальном приложении перед показом пользователю нужно заменить уникальный идентификатор рекомендованного продукта на его название.
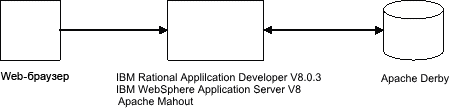
На рисунке 2 показано, что пользователи выполняют запрос к сервлету приложения. Приложение вызывает механизм рекомендаций для выдачи набора рекомендаций пользователю. Механизм рекомендаций извлекает данные из источника данных и вычисляет показатели сходства в режиме реального времени.
Для выполнения действий, рассматриваемых в данной статье, необходимо настроить среду разработки:
- Загрузите Apache Mahout
- Посетите Web-сайт Apache Mahout и загрузите свежую версию Apache Mahout. На момент написания данной статьи такой версией была 0.5 (mahout-distribution-0.5.zip).
- Извлеките содержимое архива. К этим файлам мы вернемся позже.
- Создайте проект Java EE-приложения
- Запустите Rational Application Developer for WebSphere Software V8.0.3.
- Перейдите в перспективу Java EE.
- Выберите File > New > Enterprise Application Project.
- В поле Project Name введите
RecommenderApp. - Убедитесь, что в качестве среды исполнения выбрана WebSphere Application Server v8.0, и нажмите кнопку Next.
- На следующей панели нажмите кнопку New module..., во всплывающем окне выберите Web module only и укажите его имя -
RecommenderWeb. - Нажмите кнопку OK, а затем Finish.
- Создайте базу данных и заполните ее данными примера
Apache Derby - это основанная на Java база данных, использующая для хранения файловую систему. Мы используем в этом примере Apache Derby, потому что она включена в поставку Rational Application Developer.
- Выберите Window > Show View > Data Source Explorer.
- Щелкните правой кнопкой мыши на Database Connections и выберите New ....
- В списке JDBC driver выберите Derby 10.5 - Embedded JDBC Driver Default.
- Поскольку Derby хранит базы данных в файловой системе, необходимо указать место размещения нашей базы данных. В поле Database location введите путь и имя базы данных. В данном примере используется имя
PREFERENCES. - Оставьте поля username и password незаполненными и нажмите кнопку Finish.
Далее мы определим модель данных, используя сценарий (листинг 1). Этот сценарий сначала создает схему PREFERENCES и таблицу taste_preferences. Эта таблица хранит все оценки пользователей для каждого продукта. Она содержит четыре столбца: user_id, item_id, preferences и timestamp. Каждая запись в таблице означает, что пользователь user_id оценил продукт item_id и выставил ему оценку preference.
Листинг 1. Схема источника данных
CREATE SCHEMA PREFERENCES; CREATE TABLE PREFERENCES.taste_preferences ( user_id BIGINT NOT NULL, item_id BIGINT NOT NULL, preference FLOAT NOT NULL, "timestamp" BIGINT, PRIMARY KEY (user_id, item_id) );
По причине большого числа обращений к базе данных очень важно также определить два индекса для ускорения поиска (см. листинг 2).
Листинг 2. SQL-запрос на создание индексов таблицы
CREATE INDEX PREFERENCES.user_id_idx ON PREFERENCES.taste_preferences ( user_id ); CREATE INDEX PREFERENCES.item_id_idx ON PREFERENCES.taste_preferences ( item_id );
Теперь создадим модель данных:
- Загрузите файл createtable.sql (включен в данную статью) и сохраните его в проекте RecommenderWeb.
- В перспективе Java EE щелкните правой кнопкой мыши на проекте RecommenderWeb и выберите Refresh. Должен появиться сценарий createtable.sql.
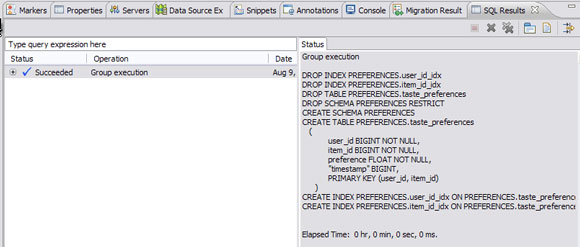
- Щелкните правой кнопкой мыши на сценарии createtable.sql и выберите Execute SQL Files.
- Убедитесь, что задан тип сервера Derby _10.x и правильно указаны имена профиля соединения и базы данных, а затем нажмите кнопку OK.
- Можно проверить успешность завершения сценария в представлении SQL Results (см. рисунок 3).
После создания таблицы можно заполнить ее данными:
- Загрузите файл u.data (включен в данную статью). Это разделенный запятыми список примерно 10 тысяч оценок пользователей из набора данных MovieLens. Аналогично SQL-сценарию сохраните этот файл в проект RecommderWeb.
- В перспективе Java EE щелкните правой кнопкой мыши на проекте RecommenderWeb и выберите Refresh. Должен отобразиться файл u.data.
- В представлении Data Source Explorer разверните Database Connections > PREFERENCES > PREFERENCES > Schemas > PREFERENCES > Tables.
- Щелкните правой кнопкой мыши на таблице TASTE_PREFERENCES и выберите Load....
- Чтобы заполнить поле Input File, нажмите кнопку Browse, найдите папку RecommenderWeb, выберите u.data и нажмите кнопку OK.
- В качестве Column delimiter выберите Tab. Отметьте флажок Replace existing data и нажмите кнопку Finish.
- Должен начаться процесс загрузки. Он может продолжаться до 60 секунд. Успешность завершения загрузки можно проверить в представлении SQL Results (см. рисунок 4).
- Проверьте загруженные данные, щелкнув правой кнопкой мыши на таблице TASTE_PREFERENCES и выбрав Data > Sample Contents.
- Отключитесь от базы данных, для чего перейдите в представление Data Source Explorer и откройте Database Connections.
- Щелкните правой кнопкой мыши на PREFERENCES и выберите Disconnect.
Мы завершили создание хранилища данных и заполнили его данными.
- Настройте библиотеки Apache Mahout
Для разработки исходного кода программы выдачи рекомендаций необходимо импортировать нужные библиотеки Apache Mahout в наше корпоративное приложение. (Если вы собираетесь использовать библиотеки Apache Mahout в нескольких корпоративных проектах, рекомендуется настроить библиотеку общего доступа.)
- Разверните EAR Projects, щелкните правой кнопкой мыши на RecommenderApp и выберите Import > Import ....
- Выберите General > File System и нажмите кнопку Next.
- В каталоге From найдите место, в которое извлекли файлы Apache Mahout, и нажмите кнопку OK.
- В диалоговом окне импорта выберите файлы, перечисленные в следующей таблице:
Имя библиотеки
Местоположение
mahout-core-0.5.jar mahout-distribution-0.5/ mahout-core-0.5-job.jar mahout-distribution-0.5/ slf4j-jcl-1.6.0.jar mahout-distribution-0.5/lib - Нажмите Finish.
- Теперь добавьте эти ссылки в Web-приложение, чтобы можно было определить class path для компиляции. Щелкните правой кнопкой мыши на проекте RecommenderWeb и выберите Properties.
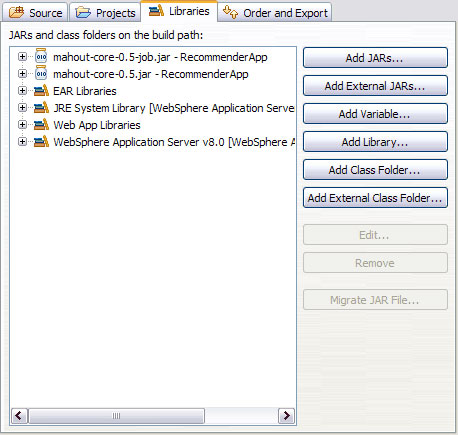
- Выберите Java Build Path и нажмите Add JARs ....
- В появившемся диалоговом окне разверните RecommenderApp, выберите mahout-core-0.5.jar и mahout-core-0.5-job.jar и нажмите кнопку OK (см. рисунок 5).
Рисунок 5. Редактор Java Build Path для проекта RecommenderWeb
- В проекте RecommenderWeb разверните WebContent > META-INF и дважды щелкните левой кнопкой мыши на MANIFEST.MF.
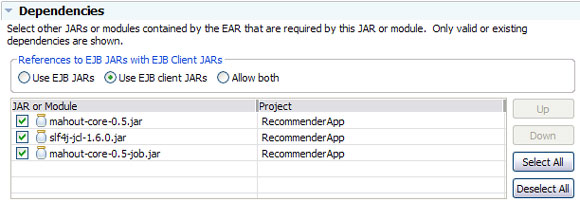
- В области Dependencies > Jar or Module отметьте все три библиотеки (рисунок 6).
- Сохраните изменения и закройте редактор.

К этому моменту мы завершили настройку среды разработки и готовы приступить к написанию кода программы выдачи рекомендаций.
Создание механизма рекомендаций
Мы создадим сервлет, который будет обрабатывать код механизма рекомендаций из Apache Mahout.
- Создайте класс сервлета
Начните с создания класса сервлета, который будет представлять наше Web-приложение.
- Щелкните правой кнопкой мыши на проекте RecommenderWeb и выберите New > Servlet.
- В поле Java Package введите
com.ibm.sample.recommender. - В поле Class Name введите
TestServlet.Рисунок 7. Create Servlet - панель Specify class file destination
- Нажмите Next.
- На следующей панели оставьте во всех полях значения по умолчанию и нажмите кнопку Next.
- На следующей панели снимите отметку с флажка doPost и нажмите кнопку Finish (рисунок 8).
Рисунок 8. Create Servlet - панель Specify method stubs to generate
Выполнив этот шаг, мы получим пустой класс сервлета, в который можно добавить код для работы с механизмом рекомендаций.
- Импортируйте исходный код
Пример исходного кода для класса сервлета включен в данную статью и содержится в файле snippet1.txt. Загрузите этот файл и используйте его для замещения содержимого исходного файла TestServlet.java.
Сейчас настал удобный момент проанализировать важные участки исходного кода, чтобы понять, что он делает.
- Создание модели данных
Ранее мы создали базу данных и загрузили в нее набор данных. На этом шаге мы определяем объект модели данных, обеспечивающий доступ к этому набору данных посредством JDBC-вызовов. Apache Mahout предоставляет классы реализации JDBC только для источников данных MySQL и PostgreSQL. Если вы захотите использовать другой источник данных, есть три варианта:
- Использовать класс GenericJDBCDataModel и предоставить все необходимые SQL-запросы в методе constructor.
- Расширить AbstractJDBCDataModel, добавив реализацию для вашего источника данных.
- Попробовать одну из существующих реализаций для проверки ее совместимости.
Для Derby подходит реализация PostgreSQL, поэтому мы будем использовать именно ее (листинг 3). Однако для ситуаций, требующих большей надежности, следует выбрать вариант с расширением AbstractJDBCDataModel.
Листинг 3. Определение модели данных
private @Resource (name="jdbc/taste") DataSource tasteDS; dataModel = new PostgreSQLJDBCDataModel(tasteDS, "PREFERENCES.TASTE_PREFERENCES", "USER_ID", "ITEM_ID", "PREFERENCE", "TIMESTAMP");
Класс интерфейса org.apache.mahout.cf.taste.model.DataModel представляет модель данных, к которой обращаются классы Similarity и Recommender. Существуют различные реализации этого интерфейса - File, JDBC и т.д. Для управления данными, используемыми после инициализации приложения, можно использовать методы, перечисленные в следующей таблице.
Имя метода
Описание
FastIDSet
getItemIDsFromUser(long userID)Возвращает идентификаторы всех продуктов, которые предпочитает пользователь. Float getPreferenceValue(long userID, long itemID)Возвращает значение предпочтения данного пользователя для данного продукта или null, если оно не существует. int getNumUsers()Возвращает общее число пользователей, известных модели. void setPreference(long userID, long itemID, float value)Устанавливает индивидуальное предпочтение (продукт плюс рейтинг) пользователя. void removePreference(long userID, long itemID)Удаляет индивидуальное предпочтение пользователя. - Генерирование показателя сходства для пользователя
После определения модели данных необходимо вычислить показатели сходства данных. Apache Mahout предоставляет несколько алгоритмов вычисления показателей сходства между пользователями. К ним относятся: City Block Similarity, Euclidean Distance Similarity, LogLikelihood Similarity, Pearson Correlation Similarity, SpearmanCorrelationSimilarity, TanimotoCoefficientSimilarity, UncenteredCosineSimilarity и другие. Дополнительная информация об этих алгоритмах приведена в документации javadoc, поставляемой с дистрибутивом Mahout.
Продолжительность процесса вычисления показателей сходства между пользователями увеличивается по мере роста числа продуктов и оценок. По этой причине для больших наборов данных вычисления следует выполнять в автономном режиме, создавая, например, задания для Apache Mahout. Результаты таких вычислений затем можно включить в модель данных.
Пример, рассматриваемый в данной статье, использует алгоритм PearsonCorrelationSimilarity, который выполняет вычисления в режиме реального времени без автономных вычислений.
Итак, давайте вычислим показатели сходства для нашей модели данных:
UserSimilarity similarity = new
PearsonCorrelationSimilarity(dataModel);Переменная similarity теперь содержит информацию о сходстве для всех пользователей, доступных в модели данных.
- Определение окружения пользователя
Алгоритм рекомендации, основанной на пользователе, использует понятие окружения пользователя (user neighborhood) для подбора пользователей, которых следует считать похожими на данного пользователя. В нашем примере используется реализация NearestNUserNeighborhood, позволяющая указать предельное число пользователей в окружении. В нашем примере окружение состоит из пяти наиболее похожих пользователей, т.е. окружение определяется следующим образом:
UserNeighborhood neighborhood = new NearestNUserNeighborhood(5, similarity, dataModel);Члены окружения считаются очень похожими на пользователя. Таким образом, при увеличении окружения количество рекомендованных продуктов тоже увеличивается, поскольку больше членов будут рекомендовать больше продуктов.
- Формирование рекомендаций
После вычисления показателей сходства между пользователями и определения окружения пользователя можно сформировать рекомендации. Для доступа к рекомендациям Mahout предоставляет интерфейс Recommender:
Recommender recommender = new GenericUserBasedRecommender(dataModel, neighborhood, similarity);После определения Recommender можно сформировать рекомендации, вызывая метод recommend(long, int) и передавая идентификатор пользователя и максимальное количество рекомендуемых продуктов. Затем каждую рекомендацию обрабатывает итератор Iterator.
В листинге 4 показано, как извлечь рекомендации для пользователя.
Листинг 4. Итерирование по рекомендациям
java.util.List<RecommendedItem> list = recommender.recommend(USER_ID, 10); Iterator<RecommendedItem>iter = list.iterator(); while ( iter.hasNext()) { RecommendedItem item = iter.next(); out.println("<tr><td>" + item.getItemID() + "</td><td>" + item.getValue() + "</td></tr>"); }Итак, для рекомендации, основанной на пользователях, сначала вычисляются показатели сходства между пользователями в базе данных, а затем определяется окружение для выбора пользователей, которые считаются похожими на данного пользователя. После этого алгоритм программы выдачи рекомендаций может сформировать рекомендации на основе информации о том, какие продукты оценили похожие пользователи, и на основании этой информации определить, насколько данному пользователю могут понравиться эти продукты.
- Тестирование механизма в Web-приложении
Перед тестированием приложения в WebSphere Application Server V8 необходимо настроить источник данных на сервере и определить для него JNDI-ссылку, чтобы сервлет смог к нему обратиться.
Для настройки источника данных:
- В представлении Servers щелкните правой кнопкой мыши на WebSphere Application Server at localhost и выберите Start.
- После запуска сервера щелкните правой кнопкой мыши на сервере и выберите Administration > Run Administrative Console.
- Если аутентификация разрешена, введите в консоли ваш идентификатор пользователя и пароль. Нажмите кнопку Login.
- Разверните Resources > JDBC > JDBC Providers.
- В поле scope выберите Server.
- Нажмите кнопку New ....
- Введите значения, показанные на рисунке 9.
- Нажмите Next.
- Проверьте конфигурацию и нажмите кнопку Finish.
- Вернитесь в список JDBC Providers и выберите Derby JDBC Provider.
- В поле Additional Properties выберите Data sources.
- Нажмите кнопку New ....
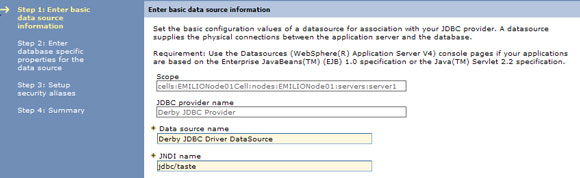
- В поле JNDI name введите
jdbc/taste(см. рисунок 10). - Нажмите Next.
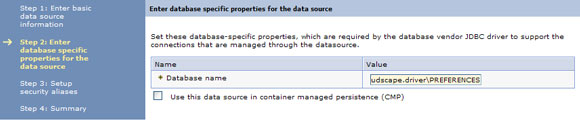
- В поле Database name введите путь местоположения источника данных Derby, созданного для загрузки модели данных. Снимите отметку с флажка Use this data source in contained managed persistence (CMP) (см. рисунок 11).
- Нажмите Next.
- На шаге Step 3 оставьте поле security configuration пустым и нажмите кнопку Next.
- На шаге Step 4 проверьте настройки и нажмите кнопку Finish.
- Сохраните конфигурацию, нажав кнопку Save.
Это все изменения, которые нужно сделать на сервере WebSphere Application Server V8. Информация связывания источника данных уже определена в коде сервлета с использованием аннотаций Servlet 2.5 (см. snippet1.txt), поэтому нет необходимости настраивать ее в дескрипторе развертывания Web-модуля. Последний шаг - установка приложения на сервер:
- В представлении Servers щелкните правой кнопкой мыши на тестовом сервере WebSphere Application Server V8 и выберите Add or Remove ....
- Выберите RecommenderApp и нажмите кнопку Add.
- Нажмите Finish.
Вот и все. Приложение установлено и готово к тестированию.
Для тестирования приложения:
- Запустите тестовый сервер WebSphere Application Server V8 из представления Servers, если он еще не запущен.
- Разверните Dynamic Web Projects > RecommenderWeb > RecommenderWeb > Servlets (см. рисунок 12).
- Щелкните правой кнопкой мыши на TestServlet и выберите Run As > Run on Server.
- Выберите WebSphere Application Server V8 at localhost и нажмите кнопку Finish.
- Внутренний браузер не должен запуститься: отобразятся результаты рекомендации (рисунок 13).
- Создание модели данных
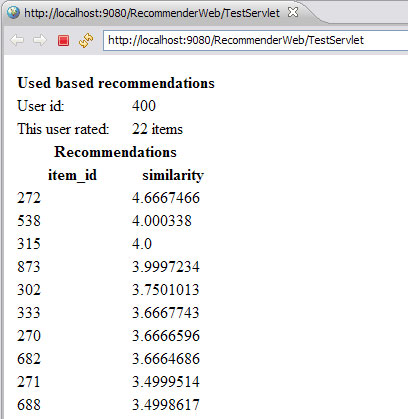
Как вы видите, в нашем примере мы хотим получить рекомендации для пользователя 400. Этот пользователь уже оценил 22 продукта. На основании модели данных и алгоритма рекомендаций Apache Mahout смог рекомендовать ряд продуктов и определить предположительные оценки, которые данный пользователь мог бы дать рекомендованным продуктам.
Итак, вы познакомились с механизмами рекомендаций. Что делать дальше?
Начинающие могут найти дополнительную информацию, предоставляемую продуктами, уже содержащими механизм рекомендаций. Например, IBM WebSphere Portal и IBM WebSphere Commerce Suite предлагают механизм рекомендаций как часть основной функциональности. С помощью подобных продуктов IBM усовершенствовала поддержку в этих областях в плане конфиденциальности, производительности и интеграции. (Вспомните о встроенных функциональных возможностях этих продуктов, когда будете выбирать между самостоятельным построением системы и покупкой готового решения.)
В данной статье не рассматривались проблемы обработки больших объемов данных с использованием MapReduce-заданий. Эта проблема уже решена IBM. Инициатива IBM Big Data поможет справиться с большими объемами данных, необходимыми для некоторых приложений. Как уже упоминалось, представленный здесь пример решения не масштабируется сверх определенного уровня из-за ограничений ресурсов при увеличении количества пользователей. Проблемы обработки больших объемов данных становятся все более типичными и не должны тормозить прогресс. При наличии проектов Big Data нет причины отказываться от реализации обработки любого масштаба.
Для использования Apache Mahout не нужен большой центр обработки данных. Более того, при использовании облачных вычислений центр обработки данных не нужен для любого решения. Облачные вычисления не связаны напрямую с механизмами рекомендаций, но стоит отметить, что облачные проекты IBM могут предоставить ресурсы для опробования подходов, которые в других ситуациях были бы нереализуемы.
Механизмы рекомендаций могут добавить в ваши Web-приложения новые мощные функции, направляя пользователей к другим продуктам или предложениям исходя из их индивидуальных характеристик и поведения. В данной статье было представлено краткое введение в технологии, используемые механизмами рекомендаций, а также информация о том, что необходимо для их масштабирования. Также вы узнали, как программа Apache Mahout использует возможности этих технологий и помогает интегрировать их в Web-приложения. Интегрировав эти концепции в сервер IBM WebSphere Application Server, вы узнали, как усовершенствовать существующие Web-приложения и добавить в них эффективные функции персонализации.
|
Описание |
Имя |
Размер |
Метод загрузки |
|---|---|---|---|
| Пример кода | 1109_recsample.zip | 9.4 МБ | HTTP |
Научиться
- Оригинал статьи: Using a recommendation engine to personalize your web application (EN).
- Программируем коллективный разум, Тоби Сегаран (Toby Segaran), O'Reilly Media, Inc., 2007 год (EN).
- Что такое Apache Mahout.
- Введение в Apache Mahout.
- Apache Hadoop.
- Что такое "большие данные".
- IBM Portal LikeMinds Recommendations.
- IBM WebSphere Portal 6.1.5 Information Center.
- Облачные вычисления IBM.
- Сервис рекомендаций "New York Times" Quietly Rolls Out.
Получить продукты и технологии