В наше время многоядерные процессоры широко распространены, и производительность однопоточных программ на новых процессорах скорее всего останется примерно на том же уровне, что и на старых. А это фактор, усиливающий давление на разработчиков ПО, чтобы они лучше использовали параллелизм.
Параллельное программирование - штука сложная по многим причинам, но в этой статье я хотел бы сосредоточиться на вопросах производительности параллельных приложений. Многопоточные приложения не только подвержены тем же проблемам, что и последовательные реализации, например низкой производительности из-за неэффективных алгоритмов, неправильного использования кеша и слишком интенсивного ввода-вывода, но и страдают от ошибок распараллеливания. Производительность и масштабируемость параллельных программ могут быть ограничены неправильным распределением нагрузки, чрезмерными издержками на синхронизацию и др.
Понимание таких узких мест для производительности требовало раньше основательного оснащения средствами мониторинга и протоколирования, а также анализа разработчиками-экспертами. Но даже для такой элиты разработчиков оптимизация производительности была утомительным и длительным процессом.
Вскоре произойдут перемены к лучшему. Visual Studio 2010 включает новое средство профилирования - Concurrency Visualizer, который значительно облегчит бремя анализа производительности параллельных программ. Более того, Concurrency Visualizer поможет разработчикам анализировать последовательные приложения на предмет возможности их распараллеливания. В этой статье я дам обзор функций Concurrency Visualizer в Visual Studio 2010, а также некоторые полезные советы по его использованию.
Представление CPU Utilization
Concurrency Visualizer включает несколько инструментов для визуализации и создания отчетов. Поддерживается три основных представления (режима просмотра): CPU Utilization (степень использования процессора), Threads (потоки) и Cores (ядра).
Представление CPU Utilization (рис. 1) задумано как отправная точка в Concurrency Visualizer. По оси x показывается время, истекшее с начала трассировки и до конца работы приложения (или до окончания трассировки - в зависимости от того, что закончится раньше). По оси y показывается число логических ядер процессора в системе
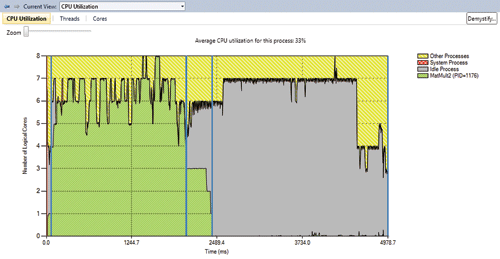
Рис. Представление CPU Utilization
Прежде чем описывать предназначение каждого представления, важно, чтобы вы поняли, что такое логическое ядро. Один процессор в наше время может содержать несколько микропроцессоров, которые называют физическими ядрами. Каждое физическое ядро может выполнять несколько потоков сразу. В таком случае говорят об одновременной многопоточности (simultaneous multithreading, SMT); Intel называет это технологией Hyper-Threading. Каждый аппаратно поддерживаемый поток в одном физическом ядре с поддержкой SMT представляется операционной системе как логическое ядро.
Если вы осуществляете трассировку в четырехъядерной системе без поддержки SMT, по оси y будут показаны четыре логических ядра. Но если каждое ядро в вашей четырехъядерной системе способно выполнять два SMT-потока, тогда по оси y будут показываться восемь логических ядер. Суть в том, что число логических ядер отражает количество потоков, которые могут одновременно работать в вашей системе, а не число физических ядер.
Теперь вернемся к представлению. На графике отображаются четыре области, обозначенные в легенде. Зеленая область отражает среднее количество логических ядер, которое анализируемое приложение использует в любой момент во время цикла профилирования. Остальные логические ядра либо простаивают (закрашиваются серым цветом), либо задействованы процессом System (красный цвет), либо используются другими процессами в системе (желтый).
Вертикальные синие полоски в этом представлении соответствуют дополнительному механизму, который позволяет оснащать программистам свой код так, чтобы визуализации коррелировали с конструкциями приложениями. Я поясню, как это делается, позже.
Ползунок Zoom вверху слева дает возможность увеличивать какой-либо участок представления для получения деталей, а элемент управления "график" (graph control) поддерживает горизонтальную полосу прокрутки в случае увеличенного изображения. То же самое можно делать, щелкнув левой кнопкой мыши и перемещая курсор на самом графике.
Это представление служит трем основным целям. Во-первых, если вас интересует распараллеливание приложения, ищите области выполнения, которые обнаруживают значительные объемы последовательной работы с процессором (они показываются как длинные зеленые области на уровне одного ядра по оси y), или области, где процессор используется довольно слабо (области зеленого цвета нет или высота этой области существенно меньше единицы в среднем). Оба этих обстоятельства обычно указывают на возможность распараллеливания. Работа, требующая интенсивного использования процессора, может быть ускорена распараллеливанием, а области, где наблюдается неожиданно малое использование процессора, как правило, связаны с блокированием (возможно, из-за ввода-вывода), и здесь параллельная обработка поможет за счет перекрытия выполнять другую полезную работу.
Во-вторых, если вы пытаетесь оптимизировать свое параллельное приложение, это представление позволяет увидеть реальную степень его параллелизма при выполнении. Простое изучение этого графика обычно делает явными многие распространенные ошибки, связанные с параллельной работой. Например, вы можете наблюдать неправильное распределение нагрузки в виде ступенчатых областей на графике или конкуренцию за синхронизирующие объекты, которая проявляется как последовательное выполнение вместо параллельного.
В-третьих, поскольку ваше приложение "живет" в системе, которая скорее всего выполняет массу других программ, конкурирующих за ее ресурсы, важно знать, влияют ли другие приложения на производительность вашего. Если влияние других программ не ожидалось, неплохо для начала отключить посторонние приложения и сервисы, чтобы повысить точность данных; оптимизация производительности требует итеративного подхода. Иногда влияние оказывается другими процессами, с которыми взаимодействует ваше приложение. В любом случае с помощью этого представления вы увидите, есть ли такое влияние, а затем, используя представление Threads, определите, какие именно процессы влияют на ваше приложение (об этом представлении я расскажу позже).
Еще один вариант, способный помочь в уменьшении влияния других программ, - применение средств профилирования командной строки для сбора трассировочных данных вне интегрированной среды разработки (IDE) Visual Studio.
Обращайте внимание на некоторые окна выполнения, которые вызывают ваш интерес, увеличивайте их, а потом переключайтесь в представление Threads для дальнейшего анализа. Вы всегда можете вернуться в исходное представление, чтобы выбрать другую область и повторить весь процесс.
Представление Threads
Представление Threads (рис. 2) содержит множество средств детального анализа и отчетов в Concurrency Visualizer. Именно здесь вы находите информацию, проясняющую поведение, которые вы выявляете в представлениях CPU Utilization или Cores. Кроме того, здесь есть данные, позволяющие по возможности связывать поведение приложения с его исходным кодом. В этом представлении есть три основных компонента: временная шкала (timeline), активная легенда (active legend) и элемент управления "вкладка" для получения отчета/детальных сведений.
Как и в CPU Utilization, в представлении Threads по оси x показывается время. (При переключении между представлениями в Concurrency Visualizer диапазон времени, показываемый по оси x, сохраняется.) Однако в представлении Threads по оси y размещаются два типа горизонтальных каналов.
Верхние каналы обычно отводятся под физические диски в вашей системе, если они активны в профиле вашего приложения. На каждый диск создается два канала: один для операций чтения, а другой для операций записи. Эти каналы отображают обращения к диску из потоков вашего приложения или процесса System. (Обращения из System показываются потому, что они иногда отражают работу, выполняемую от имени вашего процесса, например подкачку страниц памяти.) Каждая операция чтения или записи рисуется как прямоугольник. Длина прямоугольника обозначает задержку доступа, связанную в том числе с помещением в очередь; из-за этого прямоугольники могут перекрываться.
Чтобы определить, к каким файлам был доступ в определенный момент, выберите прямоугольник, щелкнув его левой кнопкой мыши. После этого окно отчетов ниже переключится на вкладку Current Stack. В ней перечисляются имена файлов, которые считывались или записывались (в зависимости от выбранного канала диска). К анализу ввода-вывода я еще вернусь.
Следует понимать, что не все файловые операции чтения и записи, выполняемые приложением, могут быть видны именно тогда, когда они ожидаются. Дело в том, что файловая система использует буферизацию, что позволяет выполнять некоторые операции дискового ввода-вывода без обращения к физическому диску.
Остальные каналы на временном графике перечисляют все потоки, существовавшие в приложении за период профилирования. Для каждого потока, если инструмент обнаруживает любую активность в ходе профилирования, показывается его состояние вплоть до завершения.
Если поток выполняется в данный момент, что отмечается зеленым сегментом Execution, то Concurrency Visualizer отображает, что этот поток делал. Получить эти данные можно двумя способами. Первый - щелкнуть зеленый сегмент, и тогда вы увидите ближайший стек вызовов (в пределах +/- 1 мс) во вкладке Current Stack.
Вы также можете создать отчет с выборками в профиле для видимого диапазона времени, чтобы выяснить, где выполняется наибольшая часть работы. Если щелкнуть метку Execution в активной легенде, в отчете появится вкладка Profile Report. На ней есть два средства, помогающие уменьшить сложность. Одно из них - подавление шума, которое по умолчанию удаляет стеки вызовов, ответственные за 2% и менее выборок в профиле. Этот порог можно менять. Другое средство под названием Just My Code позволяет сократить количество фреймов стека, удаляя из отчета те, которые относятся к системным DLL. Об отчетах поговорим подробнее позже.
Прежде чем продолжить, хотел бы обратить ваше внимание еще на несколько функций, с помощью которых можно регулировать детализацию отчетов и представлений. Вы будете часто сталкиваться с ситуациями, где показывается много потоков, но некоторые из них ничего полезного при данном прогоне средства профилирования не делают. Кроме фильтрации отчетов на основе временного диапазона, Concurrency Visualizer также позволяет выполнять фильтрацию по активным потокам. Если вас интересуют потоки, делающие какую-то работу, вы можете выбрать в Sort By сортировку потоков по времени, в течение которого они находятся в состоянии Execution. Затем вы можете выбрать группу потоков, не делающих ничего особо полезного, и скрыть их, либо щелкнув правой кнопкой мыши и выбрав из контекстного меню команду Hide, либо щелкнув кнопку Hide на панели инструментов в верхней части представления. Сортировать можно по всем категориям состояний потоков, а затем скрывать/отображать то, что вам нужно.
Эффект от сокрытия потоков состоит в том, что они удаляются из всех отчетов в добавок к сокрытию их каналов из временной шкалы. Актуальность всей статистики и отчетов средства поддерживается динамически в ходе фильтрации по потокам и временному диапозону.
Категории блокировки
Потоки могут блокироваться по многим причинам. Представление Threads пытается идентифицировать причину, по которой блокирован поток, сопоставляя каждый экземпляр с набором категорий блокировки. Я сказал "пытается", потому что эта категоризация иногда оказывается неточной (почему - чуть позже), а значит, относиться к ней следует как к примерной оценке. Как уже говорилось, представление Threads отображает все задержки потоков и точно показывает периоды их выполнения. Вы должны уделять основное внимание категориям, ответственным за значительные задержки, исходя из понимания поведения своего приложения.
Кроме того, представление Threads отображает стек вызовов, при котором выполнение потока остановилось, на вкладке Current Stack - для этого щелкните событие блокировки. Щелкнув фрейм стека в окне Current Stack, вы перейдете в файл исходного кода (если он доступен) на строку с тем номером, где вызвана следующая функция. Это важная функция продуктивности средства.
Давайте рассмотрим различные категории блокировки.
Synchronization (синхронизация) Почти все блокирующие операции можно сопоставить с нижележащими синхронизирующими механизмами в Windows. Concurrency Visualizer пытается сопоставить события блокировки с этой категорией по таким синхронизирующим API, как EnterCriticalSection и WaitForSingleObject, но иногда к этой категории могут быть отнесены другие операции, которые вызывают внутреннюю синхронизацию. Следовательно, зачастую это очень важная категория блокировки при анализе на предмет оптимизации производительности - не только из-за значимости издержек синхронизации, но и из-за того, что она может отражать другие важные причины задержек в выполнении.
Preemption (вытеснение) В эту категорию входит вытеснение из-за истечения кванта времени, когда заканчивается доля времени, выделенного потоку на выполняющем его ядре. Сюда же включается вытеснение в соответствии с правилами планирования в операционной системе, например из-за появления готового к выполнению потока другого процесса с более высоким приоритетом. Concurrency Visualizer также включает сюда другие причины вытеснения, в частности прерывания и LPC, которые могут прервать выполнение потока. При каждом таком событии вы можете получить имя/идентификатор процесса и идентификатор его потока, который вытеснил ваш поток, просто задержав курсор мыши над областью вытеснения и дождавшись появления подсказки (или щелкнув желтую область и просмотрев содержимое вкладки Current Stack). Это может очень пригодиться для понимания корневых причин появления желтых участков в представлении CPU Utilization.
Sleep (засыпание) Эта категория используется для отчетов о событиях блокировки потоков в результате явного запроса потока на засыпание или добровольного освобождения своего ядра.
Paging/Memory Management (управление памятью/подкачкой) Эта категория охватывает события блокировки, связанные с управлением памятью, в том числе любые блокирующие операции, запущенные системным диспетчером памяти в ответ на какое-либо действие приложения. Здесь отражаются ошибки страниц, конкуренция за выделение определенных областей памяти или блокирование на определенных ресурсах. Особенно важны ошибки страниц, так как они влекут за собой операции ввода-вывода. Видя событие блокировки из-за ошибки страницы, вы должны изучить стек вызовов и найти соответствующее событие ввода-вывода в дисковом канале, если эта ошибка страницы потребовала ввода-вывода. Вы можете выяснить причину ошибки страницы (из-за загрузки DLL или подкачки), щелкнув соответствующий сегмент ввода-вывода и узнав имя причастного к ошибке файла.
I/O (ввод-вывод) В эту категорию включаются такие события, как блокировка на операциях чтения и записи файлов, некоторых сетевых операциях на сокете и обращениях к реестру. Ряд операций, которые некоторыми считаются сетевыми, могут появляться не здесь, а в категории синхронизации. Дело в том, что многие операции ввода-вывода используют синхронизирующие механизмы для блокировки. Как и в случае категории управления памятью/подкачкой, когда вы видите событие блокировки из-за ввода-вывода, вы должны проверить, есть ли соответствующее обращение к диску в дисковых каналах. Чтобы это было делать проще, используйте кнопки-стрелки на панели инструментов для смещения своих потоков поближе к дисковому каналу. Для этого выберите канал потока, щелкнув его метку слева, а затем щелкните соответствующую кнопку на панели инструментов.
UI Processing (обработка UI) Это единственная форма блокировки, которая обычно желательна. Она отражает состояние потока, который находится в цикле приема (прокачки) сообщений. Если ваш UI-поток проводит большую часть времени именно в этом состоянии, значит, ваше приложение быстро отвечает на действия пользователя. С другой стороны, если UI-поток выполняет лишнюю работу или блокируется по другим причинам, то с точки зрения пользователя UI будет казаться зависшим. Эта категория открывает широкие возможности в изучении "отзывчивости" вашего приложения и его оптимизации.
Зависимости между потоками
Одна из самых ценных функций представления Threads - возможность определять зависимости синхронизации между потоками. На рис. 2 я выбрал сегмент задержки из-за синхронизации. Этот сегмент увеличен, и он выделен другим цветом (красным). На вкладке Current Stack показывается стек вызовов потока в этот момент. Изучая стек вызовов, вы можете найти API, вызов которого привел к блокировке потока.
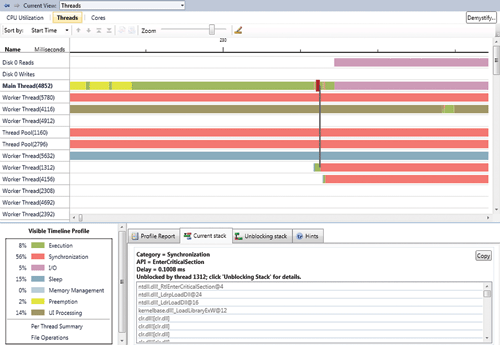
Рис. Представление Threads
Другое средство визуализации - линия, соединяющая сегмент блокировки с сегментом выполнения в другом потоке. Если такая линия видна, она указывает поток, который прекратил блокировку вашего потока. Кроме того, в этом случае можно открыть вкладку Unblocking Stack, чтобы узнать, что делал неблокированный поток, когда освободил ваш поток.
Например, если блокированный поток ждал на критической секции Win32, вы увидели бы сигнатуру EnterCriticalSection в стеке вызовов блокированного потока. А когда он разблокируется, вы заметили бы сигнатуру LeaveCriticalSection в стеке вызовов неблокированного потока. Это средство очень полезно при анализе поведения сложного приложения.
Отчеты
Отчеты профилей позволяют легко находить наиболее значимые факторы, влияющие на производительность приложения. В представлении Threads предлагаются четыре типа отчетов:
профили выборки выполнения (execution sampling profiles), профили блокировки (blocking profiles), отчеты по файловым операциям и сводки по каждому потоку. Все отчеты доступны через легенду. Например, чтобы получить отчет профиля выполнения, щелкните в легенде метку Execution. На вкладке Profile Report будет создан соответствующий отчет. Этот отчет выглядит примерно так, как показано на рис. 3.
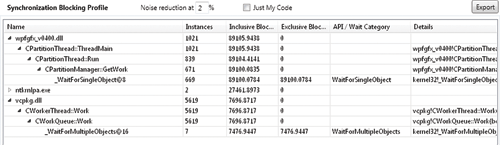
Рис. 3 Типичный отчет профилирования
В отчете профиля выполнения Concurrency Visualizer анализирует все стеки вызовов, полученные при выборках данных в процессе выполнения вашего приложения (зеленые сегменты), и сравнивает их по общим фреймам стека, чтобы помочь вам понять структуру процесса выполнения приложения. Данный инструмент также вычисляет все издержки (включающие и исключающие) для каждого фрейма. Inclusive samples указывает на все примеров на данном пути выполнения, включая все пути, находящиеся под ним. Exclusive samples соответствует числу примеров, оставленных графом вызовов фрейма стека.
Чтобы получить профиль блокирования, щелкните нужную категорию блокировки в легенде. Этот отчет генерируется по аналогии с отчетом профиля выполнения, но включающие и исключающие столбцы теперь соответствуют времени блокировки, сопоставленному со стеками вызовов или фреймами в отчете. Еще один столбец показывает число экземпляров блокировок, сопоставленных с данным фреймом стека в дереве вызовов.
Эти отчеты - удобное средство, позволяющее расставить приоритеты в оптимизации производительности и выявить части приложения, ответственные за наиболее значимые задержки. Отчет по вытеснению носит чисто информационный характер и обычно не предоставляет никаких данных для дальнейших действий из-за самой природы этой категории. Все отчеты позволяют переключаться в соответствующие места исходного кода. Это можно сделать, щелкнув правой кнопкой мыши нужный фрейм стека. Появляющееся после этого контекстного меню позволяет перейти либо к определению функции (команда View Source) или к участку в приложении, где эта функция была вызвана (команда View Call Sites). Если вызовы исходили от нескольких блоков кода, вам будет предложено несколько команд. Это обеспечивает бесшовную интеграцию диагностических данных в процесс разработки, помогающую настраивать поведение приложения. Отчеты также можно экспортировать для сравнений между профилями.
Отчет File Operations (рис. 4) включает сводку по всем операциям файлового чтения и записи, видимым в текущем временном диапазоне. Для каждого файла Concurrency Visualizer перечисляет поток приложения, который обращается к нему, число операций чтения и записи, общее количество считанных или записанных байтов, а также общую задержку чтения или записи. Кроме отображения файловых операций, прямо связанных с приложением, Concurrency Visualizer показывает и те, которые выполняются процессом System. Это сделано из-за того, что они могут выполняться от имени вашего приложения. Экспорт отчета позволяет проводить сравнение между профилями.
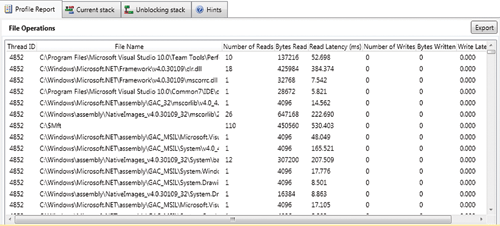
Рис. Отчет File Operations
Отчет Per Thread Summary (рис. 5) представляет собой столбчатый график для каждого потока. Столбик делится между различными состояниями потока. Это может пригодиться для отслеживания вашего прогресса в оптимизации. Экспортируя эти данные на каждой итерации оптимизации, вы сможете документировать процесс оптимизации. На графике показываются не все потоки приложения, если оно создает слишком большое их количество, не умещающееся в окно представления.
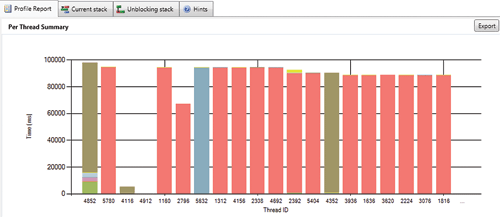
Рис.
Представление Cores
Избыточное переключение контекстов может отрицательно сказаться на производительности приложения, особенно когда потоки мигрируют между ядрами или процессорами при возобновлении своего выполнения. Дело в том, что запускаемый поток загружает необходимые команды и данные (часто называемые рабочим набором) в иерархию кешей. Возобновляя выполнение, особенно на другом ядре, поток может пострадать от значительной задержки из-за повторной загрузки своего рабочего набора из памяти или других кешей в системе.
Уменьшить эти издержки можно двумя наиболее распространенными способами. Разработчик может либо сократить частоту переключений контекстов, устранив нижележащие причины этого, либо использовать привязку (affinity) к определенному процессору или ядру. Первый вариант всегда предпочтительнее, так как привязка потоков к определенным процессорам или ядрам может стать источником других проблем с производительностью и ее можно применять только в особых обстоятельствах. Представление Cores - это инструмент, помогающий выявлять слишком частое переключение контекстов или ошибки, связанные с привязкой потоков.
Как и в других представлениях, в представлении Cores показывается временная шкала, где время откладывается по оси x. Количество логических ядер в системе показывается по оси y. Каждый поток приложения открашивается своим цветом, а сегменты выполнения потоков рисуются на каналах ядер. Легенда и статистика переключений контекстов отображаются в нижней секции (рис. 6).
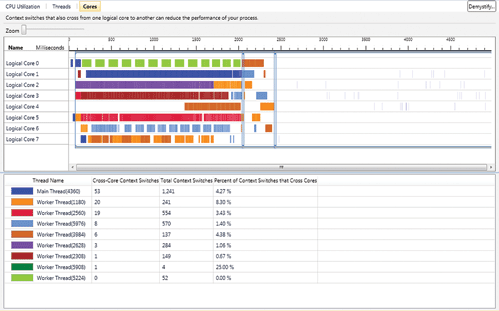
Рис. Представление Cores
Статистика помогает определять потоки со слишком частым переключением контекста и миграцией между ядрами. Затем это представление можно использовать для поиска областей выполнения, где анализируемые потоки прерываются или часто переключаются между ядрами (цветовые выделения помогают в поиске). Найдя нужную область, вы увеличиваете ее и переключаетесь в представление Threads, чтобы понять, что вызывает переключения контекста, и по возможности устранить причины (например, уменьшив конкуренцию за критическую секцию). Ошибки привязки потоков также проявляют себя в некоторых случаях, когда два или более потоков конкурируют за одно ядро, в то время как остальные ядра фактически простаивают.
Поддержка PPL, TPL и PLINQ
Concurrency Visualizer поддерживает модели параллельного программирования, предоставляемые Visual Studio 2010, а также существующие модели программирования с использованием управляемого и неуправляемого кода. Некоторые из новых параллельных конструкций - parallel_for в Parallel Pattern Library (PPL), Parallel.For в Task Parallel Library (TPL) и PLINQ-запросы - включают визуальные подсказки в этом средстве профилирования, которые позволяют обратить внимание на соответствующие области выполнения.
Для поддержки такой функциональности PPL требует включения трассировки, как показано в примере:
Concurrency::EnableTracing();
parallel_for (0, SIZE, 1, [&] (int i2) {
for (int j2=0; j2<SIZE; j2++) {
A[i2+j2*SIZE] = 1.0;
B[i2+j2*SIZE] = 1.0;
C[i2+j2*SIZE] = 0.0;
}
});
Concurrency::DisableTracing();При включенной трассировке в представлениях Threads и Cores начало и конец области выполнения parallel_for отмечаются вертикальными маркерами. Вертикальные полоски соединяются с горизонтальными полосками вверху и внизу представления. Задержав курсор мыши над горизонтальной полоской, вы получите подсказку с именем конструкции (рис. 7).
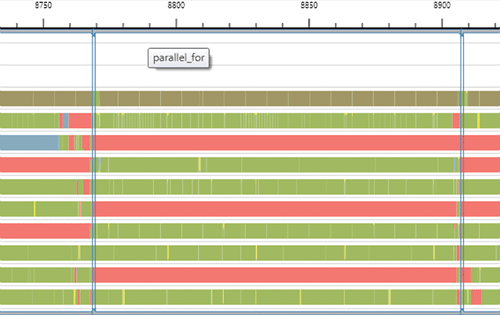
Рис. Пример визуального маркера parallel_for в представлении Threads
TPL и PLINQ не требуют ручного включения трассировки для поддержки эквивалентной поддержки в Concurrency Visualizer.
Сбор профиля
Concurrency Visualizer поддерживает методы как запуска приложения, так и подключения к нему для сбора профиля. Это поведение точно соответствует привычному Visual Studio Profiler. Новый сеанс профилирования можно инициировать через меню Analyze, либо запустив Performance Wizard (рис. 8), либо выбрав команду Profiler / New Performance Session. В обоих случаях Concurrency Visualizer активируется выбором метода профилирования Concurrency и последующего указания параметра Visualize the behavior of a multithreaded application (визуализировать поведение многопоточного приложения).
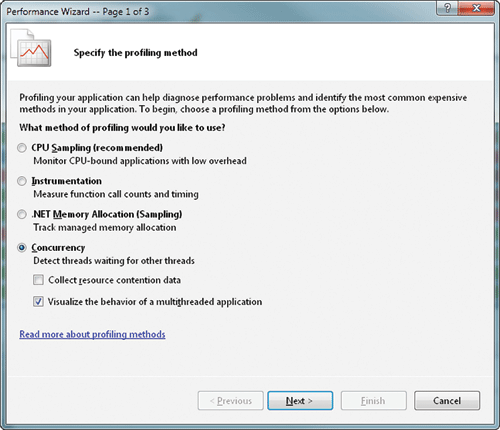
Рис. Диалог для выбора метода профилирования в Performance Wizard
Утилиты командной строки в Visual Studio Profiler позволяют собирать трассировку Concurrency Visualizer, а затем анализировать ее в IDE. Это дает возможность тем, кто заинтересован в серверных сценариях, где установка IDE недопустима, собирать трассировку с минимальным вмешательством.
Вы заметите, что в Concurrency Visualizer не интегрирована поддержка профилирования ASP.NET-приложений. Тем не менее его можно подключать к хост-процессу (обычно w3wp.exe), в котором выполняется ваше ASP.NET-приложение.
Так как Concurrency Visualizer использует Event Tracing for Windows (ETW), он требует административных привилегий для сбора данных. Так что запускайте IDE как администратор, иначе появится предложение сделать это. В последнем случае IDE будет перезапущена с правами администратора.
Связывание визуализаций с фазами работы приложения
Еще одно средство в Concurrency Visualizer - дополнительная библиотека оснащения (instrumentation library), позволяющая разработчикам настраивать представления, отмечая маркерами интересующие их фазы работы приложения. Это крайне ценно для упрощения корреляции между визуализациями и поведением приложения. Библиотека оснащения называется Scenario, и ее можно скачать с сайта MSDN Code Gallery по ссылке code.msdn.microsoft.com/scenario. Вот пример, где используется приложение на C:
#include "Scenario.h"
int _tmain(int argc, _TCHAR* argv[]) {
myScenario = new Scenario(0, L"Scenario Example", (LONG) 0);
myScenario->Begin(0, TEXT("Initialization"));
// Initialization code goes here
myScenario->End(0, TEXT("Initialization"));
myScenario->Begin(0, TEXT("Work Phase"));
// Main work phase goes here
myScenario->End(0, TEXT("Work Phase"));
exit(0);
}Использовать эту библиотеку несложно; вы включаете заголовочный файл Scenario и связываете свою программу с библиотекой. Затем вы создаете один или более объектов Scenario и помечаете начало и конец каждой фазы вызовами методов Begin и End соответственно. Кроме того, вы можете указать этим методам имя каждой фазы. Визуализация идентична показанной на рис. 7 с тем исключением, что подсказка будет показывать имя фазы, заданное вами в коде. Маркеры сценария также видны в представлении CPU Utilization, в котором другие маркеры не отображаются. Библиотека поставляется с эквивалентной управляемой реализацией.
Здесь хотел бы предостеречь вас. Не следует слишком интенсивно использовать Scenario-маркеры, так как иначе визуализации будут полностью скрыты ими. Чтобы избежать этой проблемы, инструмент значительно сократит количество отображаемых маркеров, если обнаружит их избыточное использование. Чтобы избежать этой проблемы, инструмент значительно сократит количество отображаемых маркеров, если обнаружит их избыточное использование. Более того, при вложении Scenario-маркеров будет отображаться только самый внутренний маркер.
Ресурсы и ошибки
В Concurrency Visualizer много средств, помогающих понять отображаемые им представления и отчеты. Самое интересное из таких средство - кнопка Demystify в правом верхнем углу всех представлений. Щелкнув Demystify, вы увидите, что курсор мыши приобрел особую форму, и теперь можете щелкать им любой элемент в представлении, по которому вы хотели бы получить подсказку. Это наш вариант контекстно-зависимой справки.
Кроме того, есть вкладка Tips, содержащая более подробную справочную информацию, в том числе ссылку на галерею сигнатур визуализации для наиболее распространенных проблем производительности.
Как уже упоминалось, инструмент использует ETW. Некоторые события, необходимые Concurrency Analyzer, отсутствуют в Windows XP или Windows Server 2003, поэтому инструмент поддерживает только Windows Vista, Windows Server 2008, Windows 7 и Windows Server 2008 R2, в том числе их 32- и 64-разрядные версии.
Инструмент также поддерживает как неуправляемые программы на C/C++, так и .NET-приложения (исключая .NET 1.1 и более ранние версии). Если вы используете неподдерживаемую платформу, то изучите другой полезный инструмент для анализа параллельных программ в Visual Studio 2010, который включается при выборе параметра Collect resource contention data (собирать данные о конкуренции за ресурсы).
В определенных случаях, когда в сценарии профилирования наблюдается высокая активность или когда возникает конкуренция за ресурсы ввода-вывода со стороны других приложений, важные трассировочные события могут быть потеряны. А это приводит к ошибкам при анализе трассировки. Есть два способа решить эту проблему. Во-первых, вы могли бы попытаться повторить профилирование, но с меньшим числом активных приложений, - это хорошая методология, позволяющая минимизировать стороннее влияние в процессе оптимизации приложения. В этом случае можно использовать и утилиты командной строки.
Во-вторых, вы можете увеличить количество или размер буферов памяти для ETW. Мы предоставляем документацию по ссылке в окне вывода, из которой можно узнать, как это делается. Если вы выберете второй вариант, пожалуйста, задайте общий объем буферов минимально необходимым для сбора корректной трассировки, так как эти буферы используют важные ресурсы ядра.
Любой диагностический инструмент хорош только тогда, когда предоставляет пользователю нужные данные. Concurrency Visualizer поможет точно определить корневые причины проблем с производительностью со ссылками на исходный код, но для этого ему нужен доступ к файлам символов. Вы можете добавить серверы символов и пути к ним в IDE, используя диалог Tools / Options / Debugging / Symbols. Символы для вашего текущего решения будут включены неявно, но вы должны сами указать общедоступный сервер символов Microsoft, а также любые другие пути поиска важных файлов символов, специфичных для анализируемого приложения. Также хорошей идеей будет включение кеша символов, так как это существенно уменьшит время анализа профиля.
Хотя ETW предоставляет механизм трассировки с малыми издержками, объем трассировочных данных, собираемых Concurrency Visualizer, может быть очень большим. Анализ больших объемов трассировочных данных может оказаться очень длительным и привести к задержкам в визуализации. Как правило, профили следует собирать в течение одной-двух минут, чтобы свести к минимуму вероятность появления упомянутых проблем. В большинстве случаев одной-двух минут вполне достаточно для идентификации проблемы в приложении. Возможность подключения инструмента к выполняемому процессу тоже помогает избегать сбора данных до достижения вашим приложением определенной фазы в своей работе.
Источников информации по Concurrency Visualizer много. Ответы сообщества и группы разработчиков можно найти на форуме по Visual Studio Profiler (social.msdn.microsoft.com/forums/en-us/vstsprofiler/threads). Дополнительная информация расположена в блоге группы разработчиков по адресу blogs.msdn.com/visualizeparallel, а также в моем личном блоге по адресу blogs.msdn.com/hshafi. Если у вас есть какие-либо вопросы, касающиеся этого инструмента, пожалуйста, не стесняйтесь и связывайтесь со мной или моей группой. Мы рады пообщаться с людьми, использующими наш Concurrency Visualizer, и ваши отзывы помогают нам улучшать его.
Хазим Шафи (Hazim Shafi) - архитектор инструментов для проверки корректности и оптимизации производительности параллельных программ в группе Microsoft Parallel Computing Platform. Имеет 15-летний опыт работы во многих областях параллельных и распределенных вычислений, а также в анализе производительности. Бакалавр в области проектирования электронных систем (Университет Санта-Клары), а также магистр наук и доктор естественных наук (Университет Райса).