По мере распространения многоядерных процессоров разработчики ПО переключаются на написание многопоточных приложений, способных использовать преимущества дополнительных вычислительных ресурсов для большей производительности. Используя мощь параллельно выполняемых потоков, вы можете разбить общую работу на отдельные задачи и выполнять их параллельно.
Однако потокам зачастую нужно взаимодействовать друг с другом для выполнения задачи, а иногда они должны синхронизировать свое поведение, если того требует алгоритм или доступ к общим данным. Например, одновременный доступ на запись в общий ресурс следует разрешать потокам на основе взаимного исключения, чтобы избежать повреждения данных.
Синхронизация часто осуществляется за счет применения общих синхронизирующих объектов; в этом случае поток, захватывающий объект, получает либо разделяемый, либо монопольный доступ к чувствительному коду или данным. Когда ресурс больше не нужен, этот поток освобождает занятый им синхронизирующий объект, и другие потоки могут попытаться получить к нему доступ. В зависимости от типа синхронизации одновременные запросы на захват объекта могут привести к тому, что к общему ресурсу будет обращаться сразу несколько потоков или, напротив, некоторые из потоков будут блокированы до тех пор, пока объект не освободит предыдущий поток. Примеры синхронизирующих объектов включают критические секции в C/C++, использующие процедуры доступа EnterCriticalSection и LeaveCriticalSection, функцию WaitForSingleObject в C/C++, а также выражение lock и класс Monitor в C#.
Выбирать синхронизирующий механизм следует с осторожностью, так как неправильная синхронизация потоков может привести не к увеличению, а к падению производительности. Таким образом, средства выявления ситуаций, в которых потоки конкурируют за блокировку и не выполняют никакой работы, становятся все важнее.
Средства анализа производительности в Visual Studio 2010 поддерживают новый метод - профилирование конкуренции за ресурсы (resource contention profiling), который помогает обнаруживать конкуренцию параллельных потоков. Отличный обзор этой функциональности см. в статье Джона Роббинса (John Robbins) в блоге Wintellect wintellect.com/CS/blogs/jrobbins/archive/2009/10/19/vs-2010-beta-2-concurrency-resource-profiling-in-depth-first-look.aspx.
В этой статье я пошагово опишу, как выполнять профилирование конкуренции, и объясню смысл данных, которые можно собирать с помощью Visual Studio 2010 IDE и утилит командной строки. Я также покажу, как анализировать эти данные в Visual Studio 2010, и вы увидите, как переключаться из одного представления аналитической информации в другое в процессе изучения конкуренции. Затем я внесу правки в код примера, и мы сравним результаты профилирования модифицированной программы с результатами исходной, чтобы убедиться в том, что правки позволили уменьшить интенсивность конкуренции.
Начнем с проблемы
В качестве примера я возьму то же приложение для перемножения матриц, которым воспользовался Хасим Шафи (Hazim Shafi) в своей статье в блоге "Performance Pattern 1: Identifying Lock Contention" (blogs.msdn.com/hshafi/archive/2009/06/19/performance-pattern-1-identifying-lock-contention.aspx). Код примера написан на C++, но обсуждаемые мной концепции равно применимы к управляемому коду.
Это приложение-пример использует несколько потоков для перемножения двух матриц. Каждый поток получает свою порцию работы и выполняет следующий фрагмент кода:
for (i = myid*PerProcessorChunk;
i < (myid+1)*PerProcessorChunk;
i++) {
EnterCriticalSection(&mmlock);
for (j=0; j<SIZE; j++) {
for (k=0; k<SIZE; k++) {
C[i][j] += A[i][k]*B[k][j];
}
}
LeaveCriticalSection(&mmlock);
}Каждый поток имеет свой идентификатор (myid) и отвечает за вычисление ряда строк (одной или нескольких) в конечной матрице C, используя в качестве ввода матрицы A и B. Внимательное изучение кода показало, что в нем нет по-настоящему интенсивных попыток записи в общий ресурс и каждый поток пишет в другую строку C. Тем не менее разработчик решил защитить присваивание матрице критической секцией. И я должен поблагодарить его за это, потому что тем самым я получил возможность продемонстрировать новые инструменты анализа производительности в Visual Studio 2010 и показать, насколько легко теперь находить избыточную синхронизацию.
Профилирование набора данных
Предполагая, что у вас уже есть проект Visual Studio с показанным ранее кодом (хотя он не обязателен, поскольку вы можете подключить средство профилирования к любому выполняемому приложению), вы приступаете к профилированию конкуренции выбором Launch Performance Wizard из меню Analyze.
На первой странице этого мастера (рис. 1) выберите Concurrency и установите флажок Collect resource contention data. Заметьте, что профилирование конкуренции при параллельной обработке работает в любой версии Windows. Однако использование параметра, связанного с флажком Visualize the behavior of a multithreaded application, требует работы в Windows Vista или Windows 7.
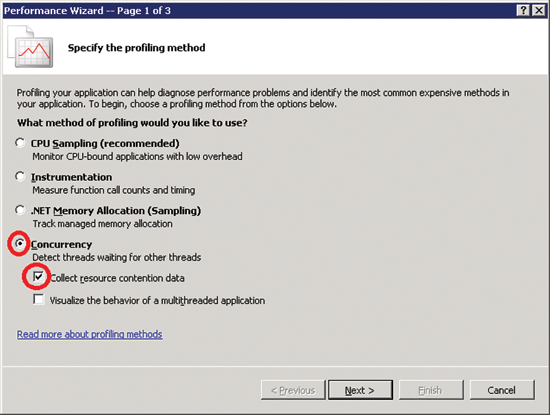
Рис. 1. Включение профилирования конкуренции при параллельной обработке
На второй странице мастера убедитесь, что в качестве целевого выбран текущий проект. На последней странице проверьте, чтобы был установлен флажок Launch profiling after the wizard finishes и щелкните кнопку Finish. Приложение запустится под управлением средства профилирования. По завершении файл данных профилирования появится в окне Performance Explorer (рис. 2).
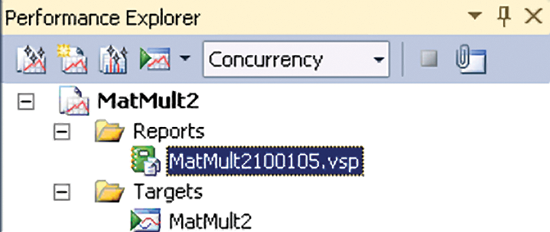
Рис. 2. Файл результатов профилирования показывается в окне Performance Explorer
Отчет о профилировании автоматически открывается в Visual Studio и в представлении Summary показываются результаты анализа работы программы (рис. 3).
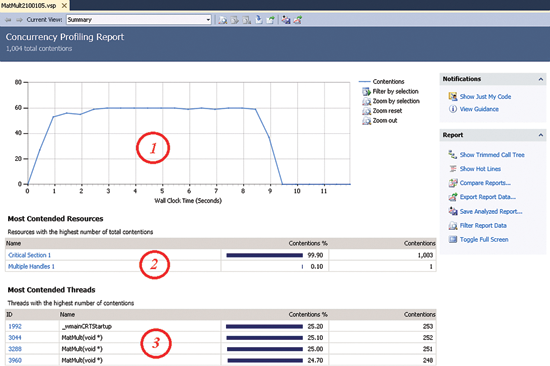
Рис. 3. Представление Summary отчета о профилировании
Анализ данных профилирования
Синхронизация не всегда вызывает конкуренцию потоков на блокировке. Если блокировка доступна, попытка ее захватить не блокирует выполнение потока и никакой конкуренции не возникает. В режиме Resource Contention Profiling средство профилирования собирает данные только по синхронизирующим событиям, которые вызывают конкуренцию, и не сообщает об успешных захватах (без блокировки). Если в вашем приложении вообще нет конкуренции, вы не получите никаких данных. Ну а если вы получили какие-то данные, значит, в вашем приложении есть конкуренция за блокировки.
В каждом случае конкуренции средство профилирования сообщает, как поток был блокирован, где наблюдалась конкуренция (ресурс и стек вызовов), когда это было (временная метка) и сколько времени провел поток, пытаясь захватить блокировку или войти в критическую секцию, сколько времени он ждал освобождения одного объекта и т. д.
Открыв файл, вы первым делом видите представление Summary (рис. 3) с тремя основными областями, которые можно использовать для экспресс-диагностики.
- Диаграмма конкуренции показывает интенсивность конкуренции в секунду, отложенную по оси времени выполнения вашего приложения. Вы можете визуально изучить пики конкуренции или выбрать временной интервал и либо увеличить его детализацию, либо включить фильтрацию результатов. При фильтрации осуществляется повторный анализ данных и удаляются все данные за пределами выбранного интервала.
- В таблице Most Contended Resources перечисляются ресурсы, вызвавшие наиболее интенсивную конкуренцию.
- В таблице Most Contended Threads перечисляются потоки с самыми высокими показателями конкуренции. Здесь в качестве критерия используется не длительность конкуренции, а ее частота. Следовательно, у вас может быть поток, длительно блокированный на каком-то ресурсе, но он не будет показан в представлении Summary. С другой стороны, поток, испытывающий частую, но кратковременную конкуренцию, при которой он блокируется на очень короткий промежуток, обязательно появится в этом представлении.
Если у вас есть ресурс, ответственный за большую часть конкуренции, присмотритесь к этому ресурсу. Если вы видите, что какой-то поток неожиданно для вас часто попадает в условия конкуренции, изучите данные по конкуренции, относящиеся к этому потоку.
Например, на рис. 3 видно, что Critical Section 1 ответственна почти за всю конкуренцию в приложении (99,90%). Давайте внимательно проанализируем этот ресурс.
Имена ресурсов и идентификаторы потоков в представлении Summary являются гиперссылками. Щелкнув Critical Section 1, вы переключитесь в представление Resource Details (рис. 4), где контекст установлен для конкретного ресурса - Critical Section 1.
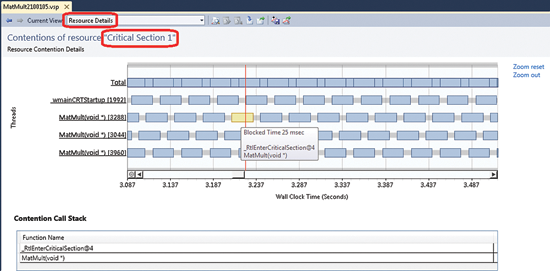
Рис. 4. Представление Resource Details
Resource Details
В верхней части представления Resource Details показана временная диаграмма, на которой каждая горизонтальная линия соответствует одному потоку. Линии обозначаются корневой функцией потока, если только вы не именуете управляемые потоки в своем коде (например, используя в C# свойство System.Threading.Thread.Name). Блоки на этой линии представляют конкуренцию потока за ресурс, а длина блока - длительность конкуренции. Блоки с разных линий могут перекрываться по времени, и это означает, что на ресурсе одновременно блокируется несколько потоков.
Линия Total имеет особый смысл. Она не относится к какому-либо потоку, а отражает всю конкуренцию всех потоков за данный ресурс (фактически на эту линию проецируются все блоки конкуренции). Как видите, Critical Section 1 весьма занятый ресурс - на его линии Total нет ни одного свободного промежутка.
Вы можете увеличить детализацию конкретной части диаграммы, выбрав временной диапазон левой кнопкой мыши (щелкните левой кнопкой мыши в точке диаграммы, откуда вы хотите начать, и перетащите указатель вправо). Вверху справа на диаграмме есть две ссылки: Zoom reset и Zoom out. Zoom reset сразу же восстанавливает исходный вид диаграммы. Zoom out делает то же самое, но пошагово, повторяя операции по увеличению детализации в обратном порядке.
Общая закономерность расположения блоков конкуренции может дать некоторые подсказки по поводу выполнения вашего приложения. Например, вы видите, что блоки конкуренции разных потоков сильно перекрываются по времени, а значит, распараллеливание далеко от оптимального. Каждый поток блокируется на синхронизирующем ресурсе намного дольше, чем выполняется, и это еще одно указание на неэффективность приложения.
Function Details
В нижней части представления Resource Details находится стек вызовов для конкретного блока конкуренции - данные в нем показываются только после того, как вы выберете какой-нибудь блок. Вы также можете просто задержать курсор мыши над блоком, не щелкая его, и появится всплывающее окно со стеком и длительностью конкуренции.
Как видно из стека вызовов, в нем присутствует MatMult - одна из функций приложения-примера, а значит, она была причиной конкуренции. Чтобы определить, какая строка в коде функции ответственна за конкуренцию, дважды щелкните имя функции в секции стека вызовов, и произойдет переключение в представление Function Details (рис. 5).
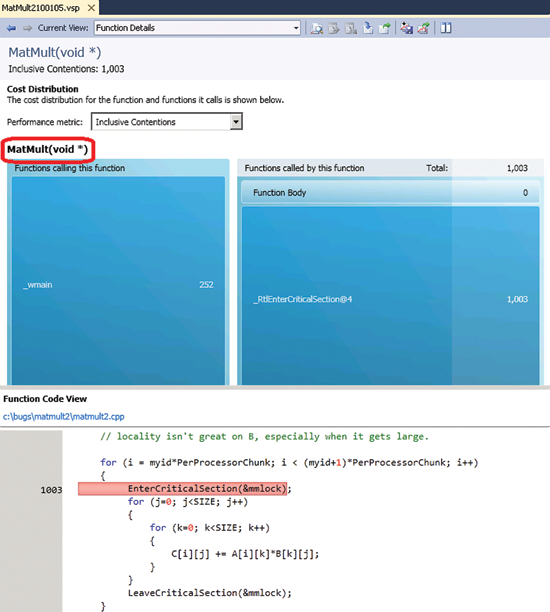
Рис. 5. Представление Function Details
В этом представлении вы видите графическое отражение функций, вызывавших MatMult, а также функций, вызывавшихся внутри нее. Нижняя часть представления отчетливо указывает, что за частую блокировку потоков ответственна EnterCriticalSection(&mmlock).
Зная строку кода, ответственную за конкуренцию, вы можете передумать реализовать синхронизацию в таком варианте. Наилучший ли это способ защиты вашего кода? Нужна ли она вообще?
В приложении-примере использование в этом коде данной критической секции излишне, так как потоки не осуществляют совместную запись в одни и те же строки конечной матрицы. Средства анализа производительности в Visual Studio подводят вас к точке, где вы можете закомментировать использование mmlock, что значительно ускорит работу приложения. Но если бы это всегда было так просто!
Более глубокое описание представления Function Details см. в блоге Visual Studio Profiler Team по ссылке blogs.msdn.com/profiler/archive/2010/01/19/vs2010-investigating-a-sample-profiling-report-function-details.aspx.
Thread Details
Как я уже упоминал, представление Summary дает хорошую отправную точку для ваших исследований. Изучая таблицы Most Contended Resources и Most Contended Threads, вы можете решить, как действовать дальше. Если вы обнаружите, что один из потоков ведет себя весьма подозрительно, так как вы не ожидали, что он окажется в списке потоков, испытывающих максимально интенсивную конкуренцию, то можете внимательнее посмотреть на этот поток.
Щелкните идентификатор потока в представлении Summary, чтобы перейти в представление Thread Details (рис. 6). Хотя это представление похоже на Resource Details, у него другой смысл - оно показывает конкуренцию в контексте выбранного потока. Каждая горизонтальная линия представляет ресурс, за который поток конкурировал в течение своего жизненного цикла. На этой диаграмме вы не увидите перекрытые по времени блоки конкуренции, так как иначе это означало бы, что поток одновременно блокируется более чем на одном синхронизирующем ресурсе.
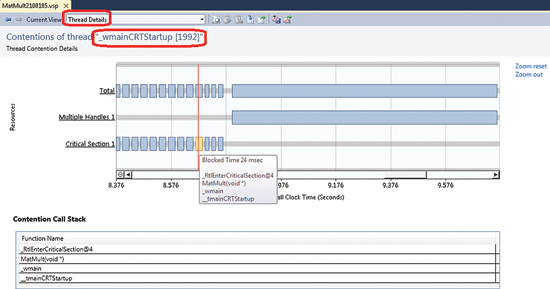
Рис. 6. Представление Thread Details с выбранным блоком конкуренции
Заметьте, что WaitForMultipleObjects (которую я здесь не показываю) обрабатывается отдельно и представляется и представлена единственной строкой диаграммы вместе с набором своих объектов. Это связано с тем, что средство профилирования интерпретирует все объекты-параметры функции WaitForMultipleObjects как единую сущность.
Любые манипуляции, которые можно выполнять в представлении Resource Details (увеличение детализации фрагментов диаграммы, выбор конкретных блоков конкуренции и просмотр их длины в миллисекундах, а также анализ стека вызовов), поддерживаются и в представлении Thread Details. Дважды щелкните имя функции в секции Contention Call Stack для перехода в представление Function Details этой функции.
В примере видно, что поток тратит больше времени в блокированном состоянии на начальном этапе выполнения, а затем надолго блокируется на наборе описателей объектов. Так как появление последнего блока вызвано ожиданием завершения других потоков, блоки конкуренции на ранних этапах указывают на не оптимальное использование потока, из-за чего он проводит в блокированном состоянии больше времени, чем в состоянии выполнения.
Локализация причин проблемы
Вероятно, вы заметили, что метки осей диаграммы являются гиперссылками. Это позволяет переключаться между детализированными представлениями ресурсов и потоков, каждый раз устанавливая требуемый контекст для представления; такое может пригодиться в итеративном процессе поиска и устранения проблемы. Например, вы обнаружили, что ресурс R1 блокирует многие потоки. Тогда вы переключаетесь из Resource Details в детализированное представление потока T1 и обнаруживаете, что он блокировался не только на R1, но иногда и на ресурсе R2. После этого вы можете посмотреть детальные сведения по R2 и проанализировать все потоки, которые блокировались ресурсом R2. Затем можно щелкнуть метку заинтересовавшего вас потока T2 и проверить все ресурсы, которые его блокировали, - и т. д.
Данные профилирования конкуренции не дадут вам явного ответа на вопрос, кто удерживает блокировку в любой выбранный момент времени. Но учитывая механизм "честного" использования синхронизирующих объектов между потоками и ваше знание поведения приложения, вы можете идентифицировать вероятного владельца блокировки (поток, который успешно захватил синхронизирующую блокировку), сравнивая данные в Resource Details с данными в Thread Details и наоборот.
Например, в представлении Thread Details вы видите поток T, блокируемый на ресурсе R в момент t. Вы можете переключиться в представление Resource Details для R, щелкнув метку R, и посмотреть все потоки, которые блокировались на R в течение жизненного цикла выполнения приложения. В момент t вы увидите некоторое количество потоков (в том числе T), блокировавшихся на R. Поток, который не блокировался на R в момент t, и есть вероятный успешный владелец блокировки.
Ранее я отметил, что линия Total диаграммы является проекцией всех блоков конкуренции. Метка Total также является гиперссылкой, но из представления Resource Details она переключает вас в представление Contention (рис. 7), которое представляет собой деревья вызовов при конкуренции индивидуально для каждого ресурса. "Горячий путь" (hot path) дерева вызовов соответствующего ресурса активизируется автоматически. Это представление отражает статистику по конкуренции и времени блокирования для каждого ресурса и для каждого узла (функции) в дереве вызовов для ресурса. В отличие от других представлений это агрегирует стеки конкуренции в дерево вызовов для ресурса (так же, как в других режимах профилирования) и дает вам статистику для всего прогона приложения.

Рис. 7. Представление Contention с "горячим путем", примененным к Critical Section 1
Из представления Contention вы можете вернуться в Resource Details любого ресурса с помощью контекстного меню. Укажите ресурс, щелкните его правой кнопкой мыши и выберите Show Contention Resource Details. В этом контекстном меню доступны и другие интересные операции. Так что рекомендую изучить контекстные меню в представлениях средства профилирования - они могут оказаться весьма полезными!
Щелкните метку Total в представлении Thread Details, чтобы отобразить представление Processes, где выбран поток (рис. 8). В этом представлении вы можете увидеть, когда поток был запущен относительно времени запуска приложения, когда он был завершен, сколько времени выполнялся, как часто он испытывал конкуренцию с другими потоками и сколько времени он блокировался за весь период конкуренции за ресурсы (в миллисекундах и в процентах от времени жизненного цикла потока).
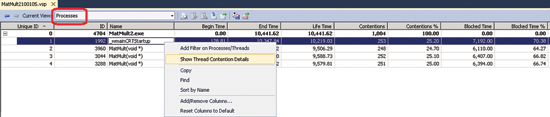
Рис. 8. Представление Processes
И вновь можно вернуться в представление Thread Details для любого потока через контекстное меню: укажите интересующий вас поток, щелкните его правой кнопкой мыши и выберите Show Thread Contention Details.
Другой возможный путь анализа - отображение представления Processes непосредственно при открытии файла, сортировка потоков щелчком заголовка одного из доступных столбцов (скажем, сортировка потоков по числу блоков конкуренции), выбор одного из потоков и переключение на диаграмму Contention Details для этого потока - опять же через контекстное меню.
Устранение проблемы и сравнение результатов
Найдя корневую причину конкуренции за блокировки в приложении, вы можете закомментировать критическую секцию mmlock, а затем повторно выполнить профилирование:
for (i = myid*PerProcessorChunk;
i < (myid+1)*PerProcessorChunk;
i++) {
// EnterCriticalSection(&mmlock);
for (j=0; j<SIZE; j++) {
for (k=0; k<SIZE; k++) {
C[i][j] += A[i][k]*B[k][j];
}
}
// LeaveCriticalSection(&mmlock);
}В этом случае можно ожидать уменьшения интенсивности конкуренции, и действительно профилирование модифицированного кода показывает конкуренцию только на одной блокировке (рис. 9).
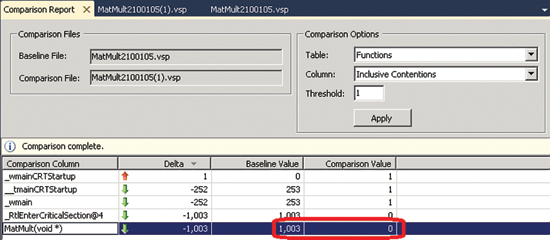
Рис. 9. Представление Summary для результатов профилирования исправленного кода
Мы также можем сравнить результаты анализа производительности новой и предыдущей версий в Visual Studio. Для этого укажите оба файла в Performance Explorer (выберите один файл, нажмите Shift или Ctrl, а затем выберите второй), потом щелкните их правой кнопкой мыши и выберите Compare Performance Reports.
Появится Comparison Report, как показано на рис. 10. В приложении-примере вы увидите, что количество Inclusive Contentions для функции MatMult упало с 1003 до 0.
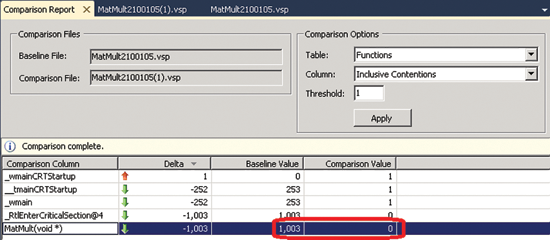
Рис. 10. Окно Comparison Report
Альтернативные методы сбора данных
Если вы создаете сеанс анализа производительности для профилирования в режиме Sampling (выборка) или Instrumentation (оснащение средствами мониторинга и протоколирования), вы всегда можете впоследствии перевести его в режим Concurrency. Один из способов быстро сделать это - использовать меню режимов профилирования в Performance Explorer. Просто выберите нужный режим, и все.
Вы также можете воспользоваться настройкой свойств своего сеанса. Укажите этот сеанс в Performance Explorer, щелкните правой кнопкой мыши, чтобы открыть контекстное меню, и выберите Properties. На вкладке General страниц свойств можно контролировать режим сеанса профилирования и другие параметры.
Как только режим профилирования задан Concurrency (или Sampling, если это имеет значение), вы можете либо запустить свое приложение (оно уже находится в списке Targets, если вы пользовались мастером Performance Wizard; кроме того, туда его можно добавить вручную), либо подключиться к приложению, которое уже запущено и выполняется. Performance Explorer позволяет управлять этими операциями, как показано на рис. 11.
Рис. 11. Средства Performance Explorer для управления профилированием
Visual Studio UI автоматизирует ряд операций, необходимых для сбора данных профилирования. Однако эти данные можно собирать средствами командной строки, что может быть полезно в автоматизированных прогонах и сценариях.
Чтобы запустить приложение в режиме профилирования конкуренции, откройте окно командной строки в Visual Studio (что помещает в ваш путь все двоичные файлы средства профилирования для платформы x86 или x64), а затем проделайте следующее.
- Введите VSPerfCmd.exe /start:CONCURRENCY,RESOURCEONLY /output:<Ваш выходной файл>.
- Введите VSPerfCmd.exe /launch:<ваше приложение> /args:"<аргументы вашего приложения>".
- Запустите сценарий.
- Введите VSPerfCmd.exe /detach.
- Эта операция не обязательна, если ваше приложение завершается, но и ничем не повредит, поэтому лучше добавьте ее в свои сценарии.
- Введите VSPerfCmd.exe /shutdown.
Теперь вы можете открыть Ваш_выходной_файл.VSP в Visual Studio для анализа.
Если приложение уже выполняется, можно подключить к нему средство профилирования, проделав следующее.
- Введите VSPerfCmd.exe /start:CONCURRENCY,RESOURCEONLY /output:<Ваш выходной файл>.
- Введите VSPerfCmd.exe /attach:<PID или имя процесса>.
- Запустите сценарий.
- Введите VSPerfCmd.exe /detach.
- Введите VSPerfCmd.exe /shutdown.
Более подробное объяснение доступных параметров командной строки см. в статье по ссылке msdn.microsoft.com/library/bb385768(VS.100).
Разнообразие представлений Visual Studio позволяет тщательно анализировать собранные данные под разными углами зрения. Некоторые представления дают картину жизненного цикла приложения в целом, а другие - более специфическую информацию, и вы можете использовать те, что считаете максимально полезными.
При анализе результатов профилирования вы можете переключаться между представлениями через гиперссылки, двойными щелчками или с помощью контекстных меню, а также переходя напрямую к нужному представлению в раскрывающемся меню. В табл. 1 кратко описывается каждое из этих представлений.
Рис. 12. Аналитические представления
| Представление | Описание |
| Summary | Предоставляет сводную информацию, которая служит отправной точкой в ваших исследованиях. Это первое представление, которое вы видите, и оно открывается автоматически по окончании сеанса профилирования и после готовности файла результатов |
| Call Tree | Дерево вызовов, агрегирующее все стеки вызовов, где наблюдается конкуренция. Здесь вы можете понять, какие стеки ответственны за конкуренцию |
| Modules | Список модулей, содержащих функции, каждая из которых приводит к конкуренции. Для каждого модуля создается список релевантных функций и сообщается число обнаруженных блоков конкуренции |
| Caller/Callee | Представление с тремя секциями, где отображаются функция F, все функции, вызывающие F, и функции, вызываемые F (показываются, конечно, только вызовы, приводящие к конкуренции) |
| Функции | Список всех функций, обнаруженных в любом стеке, где есть конкуренция, с сопоставленными данными |
| Lines | Строки функции в исходном коде |
| Resource Details | Подробные сведения о конкретном ресурсе (например, о блокировке), где показываются все потоки, блокировавшиеся на этом ресурсе в ходе жизненного цикла приложения |
| Thread Details | Подробные сведения о конкретном потоке с отображением всех ресурсов (таких как блокировок), на которых блокировался данный поток |
| Contention | Аналогично представлению Call Tree, но здесь деревья вызовов разделены по ресурсу, за который конкурируют потоки. Иначе говоря, оно представляет набор деревьев вызовов, каждое из которых содержит стеки, блокировавшиеся на конкретном ресурсе |
| Marks | Список автоматически и вручную записанных меток (marks), где каждая метка сопоставлена со своей временной меткой и значениями Windows-счетчиков |
| Processes | Список проверявшихся процессов, где каждый процесс имеет список своих потоков; при этом каждому потоку сопоставлены количество случаев конкуренции и суммарная длительность его блокирования |
| Function Details | Подробные сведения о конкретной функции, в том числе о вызываемых ею функциях, и собранные данные |
| IPs | Список указателей команд (IP), где происходила конкуренция (фактически это список функций вроде EnterCriticalSection, WaitForSingleObject и др., так как реально конкуренция наблюдается на таких функциях) |
Новые средства профилирования конкуренции за ресурсы в Visual Studio должны помочь вам обнаруживать причины проблем с производительностью при использовании синхронизации потоков и позволяют повысить скорость работы вашего приложения изменением, сокращением или исключением лишних синхронизирующих ресурсов.