Екатерина Муса-Оглы,
Oracle PL/SQL Developer Certified Associate,
Кубанский Государственный Университет,
Николай Бессарабов,
к. т. н., доцент,
Кубанский Государственный Университет
 |
 |
Введение
Существует до десятка реализаций специфической модели данных, которую принято называть универсальной (УМД). Такая модель состоит из иерархически связанного набора таблиц, представляющих и метаданные, и данные приложения. Универсальная схема хранит любое число виртуальных схем, заполненных данными. Типичная схема УМД включает таблицы:
В ряде реализаций данные хранятся в нескольких таблицах, каждая из которых содержит данные одного типа, например, все числовые данные. Обычно вместо запроса в виртуальной схеме создается вручную сложный эквивалентный запрос к схеме УМД с соединениями всех или почти всех реальных таблиц УМД. В предлагавшихся версиях считалось, что УМД может послужить основой для реализации любых баз данных. Такое предположение вряд ли оправдано. Однако существует как минимум четыре класса задач, для которых реализация базы в УМД имеет существенные преимущества, в частности:
Хранение полуструктурированных данных.
Реализация базы знаний в базе данных, предполагающая, в частности, возможность ввода информации, структура которой не предусмотрена заранее. Одна из причин эффективности УМД в таких решениях заключается в том, что замена команд определения данных в виртуальной схеме на команды манипулирования данными в УМД может существенно повысить быстродействие при изменении схемы "на ходу". Поскольку выполнение действий определения данных для виртуальной схемы не завершает транзакцию, в УМД возможны откаты и определений и изменений данных.
По непонятным для нас причинам в существующих реализациях УМД игнорируются малая скорость работы, отсутствие реализации ограничений целостности, триггеров и пользовательского доступа к данным. Все эти проблемы можно успешно решить в последних версиях Oracle (10.2, 11). На рисунке 1 представлена предлагаемая нами универсальная схема. Ее отличие в том, что добавлены таблицы, хранящие сведения о представлениях, триггерах и ограничениях целостности.
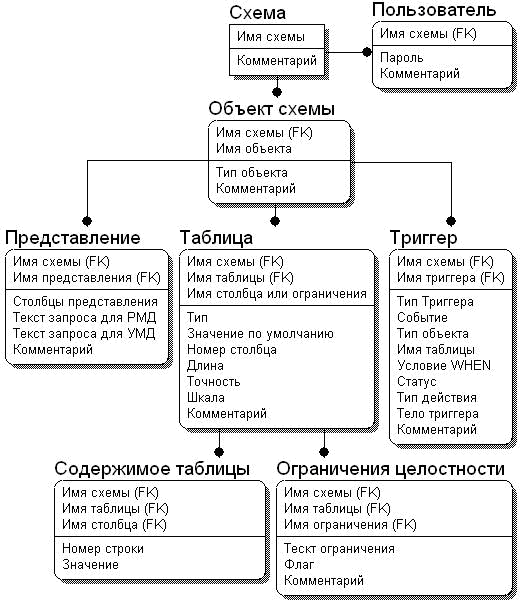
Рисунок 1 - Предлагаемая универсальная схема
Еще один недостаток УМД - очень сложные инструкции, требующие большого числа соединений. В нашей реализации пользователь пишет только инструкции для виртуальной схемы. Транслятор преобразует их в инструкции для УМД. В результате существенно снижается нагрузка на пользователя, который делает ровно то, что в обычной базе. В одном из вариантов пользователь создает запрос QBE, который записывается в XML-файл определенной структуры. Далее на сервере происходит разбор файла с запросом. Схема работы приложения представлена на рисунке 2.
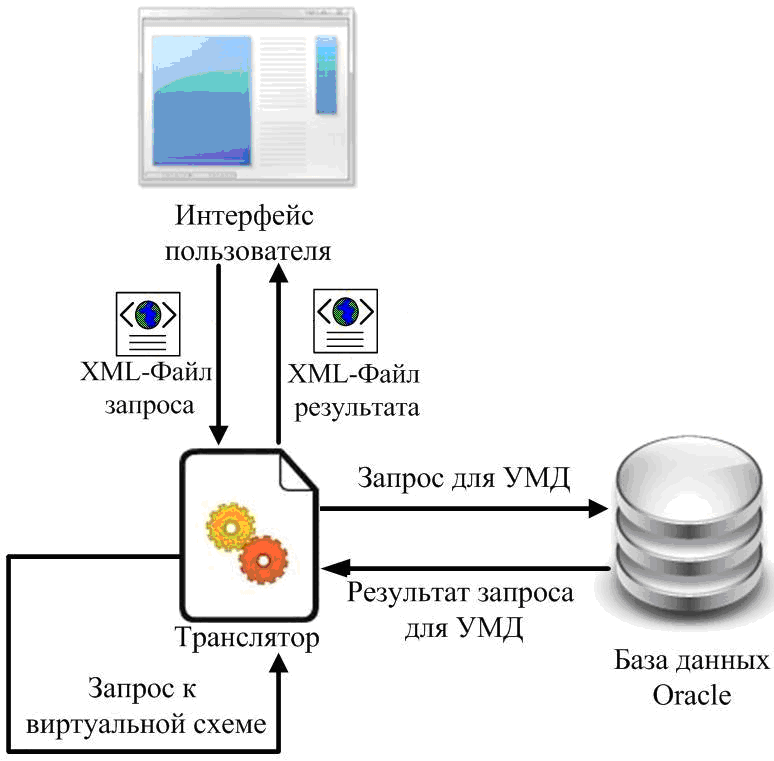
Рисунок 2 - Схема работы приложения
Предлагаются два варианта работы транслятора, реализующего разбор файла.
В первом варианте на выходе получаем SQL-запрос к виртуальным таблицам, который можно показать пользователю. Далее этот запрос разбирается и транслируется в SQL-запрос к реальным таблицам УМД, содержащим данные.
Второй вариант не предполагает промежуточного SQL-запроса к виртуальным таблицам. В нем по информации, полученной при разборе XML, сразу строится запрос к реальным таблицам УМД. Существует возможность трансформации реляционной базы данных в универсальную, и наоборот. Это позволяет работать в УМД на стадии создания базы и при необходимости перейти к обычной базе, не теряя данных.
И декларативные, и процедурные ограничения целостности реализуются через триггеры.
В таблице Триггер содержатся полные описания виртуальных триггеров. Поскольку в реальной схеме эти триггеры не существуют, их действия имитируются запуском процедуры, которая исполняет тело виртуального триггера. Так как запуск этой процедуры обязательно производится при исполнении любой команды, то эта команда является событием, запускающим виртуальный триггер. Событиями могут быть SELECT, CREATE TABLE. Таким образом, триггерных событий существенно больше, чем у стандартных триггеров Oracle. Опции BEFORE и AFTER реализуются изменением порядка выполнения запроса и триггера.
При трансформации базы из РМД в УМД тело триггера должно быть транслировано. При этом необходимо выделить SQL-выражения и только их транслировать в соответствующие SQL-выражения для УМД. Фразы PL/SQL транслировать нет необходимости, так как они не имеют дело с таблицами, а только со значениями, получаемыми из этих таблиц с помощью SQL-выражений.
Существует еще один способ реализации виртуальных триггеров. Для таблицы данных создаются все 12 триггеров по одному на каждый тип. При этом добавляется условие WHEN, в которое входит имя виртуальной таблицы. В данном случае тело триггера выполняет процедуру, которая в динамическом SQL запускает тело виртуального триггера, хранимое в таблице описания триггеров.
Создание пользователя виртуальной базы - это запись его в таблицу Пользователь. Для разграничения прав пользователей виртуальных моделей используется контроль доступа на уровне строк, реализованный с помощью пакета DBMS_RLS. Фильтрующий предикат, определяющий политику RLS, использует сравнение имен виртуальных схем, размещенных в таблице данных УМД. Для каждого пользователя виртуальной модели существует политика, позволяющая ему видеть только "свои" строки данных, соответствующие таблицам своей схемы. Таблица данных в нашем случае хранит и данные и метаданные. Таким образом, формирование запросов в логике второго порядка не составляет сложности. Такие запросы транслируются в единственный SQL-запрос к таблице данных.
- Методы построения запросов к УМД
В разработанном прототипе инструментального средства таблица Данные содержит столбцы с именами виртуальной схемы, таблицы, столбцов. Поэтому при формировании запроса мы пользуемся только одной таблицей Данные. Остальные таблицы УМД содержат более подробную информацию об объектах виртуальной схемы. Главный недостаток УМД - большое число соединений даже для выполнения тривиальных запросов к виртуальной базе. Пример такого запроса представлен на рисунке 3. Запросы выполнены в схеме HR.
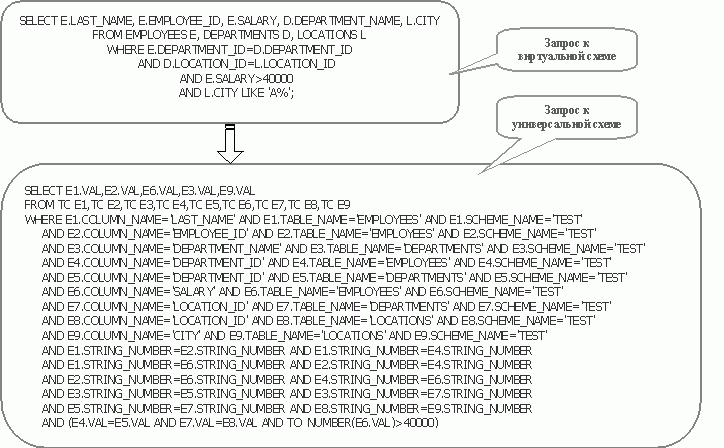
Рисунок 3 - Запрос к виртуальной схеме и соответствующий ему запрос к универсальной схеме по методу соединения таблицы данных с собой.
При анализе содержимого таблиц Таблица, Содержимое таблицы и Ограничение целостности нетрудно заметить ту же особенность, что и при заполнении таблиц, представляющих гиперкубы, а именно: некоторые столбцы содержат сравнительно небольшое число часто повторяющихся значений. Для перехода от запроса к виртуальной базе в запрос к УБД можно воспользуемся техникой, основанной на применении функции decode с добавлением одной из функций max, min [1]. В результате приведенный выше запрос транслируется в запрос, представленный на рисунке 4.
SELECT E.ENAME,E.EMPNO,E.SAL,D.DNAME,L.CITY
FROM (
SELECT STRING_NUMBER,
MIN(DECODE(COLUMN_NAME,'LAST_NAME',VAL)) ENAME,
MIN(DECODE(COLUMN_NAME,'SALARY',VAL)) SAL,
MIN(DECODE(COLUMN_NAME,'EMPLOYEE_ID',VAL)) EMPNO,
MIN(DECODE(COLUMN_NAME,'DEPARTMENT_ID',VAL)) DEPTNO
FROM TC
WHERE TABLE_NAME='EMPLOYEES'
AND SCHEME_NAME='TEST'
GROUP BY STRING_NUMBER
) E,
(
SELECT STRING_NUMBER,
MIN(DECODE(COLUMN_NAME,'DEPARTMENT_ID',VAL)) DEPTNO,
MIN(DECODE(COLUMN_NAME,'LOCATION_ID',VAL)) LOC_ID,
MIN(DECODE(COLUMN_NAME,'DEPARTMENT_NAME',VAL)) DNAME
FROM TC
WHERE TABLE_NAME='DEPARTMENTS'
AND SCHEME_NAME='TEST'
GROUP BY STRING_NUMBER
) D,
(
SELECT STRING_NUMBER,
MIN(DECODE(COLUMN_NAME,'LOCATION_ID',VAL)) LOC_ID,
MIN(DECODE(COLUMN_NAME,'CITY',VAL)) CITY
FROM TC
WHERE TABLE_NAME='LOCATIONS'
AND SCHEME_NAME='TEST'
GROUP BY STRING_NUMBER
) L
WHERE E.DEPTNO=D.DEPTNO
AND D.LOC_ID=L.LOC_ID
AND E.SAL>40000
Рисунок 4 - Запрос к универсальной схеме по методу Т. Кайта
Может показаться удивительным, но запросы подобного типа выполняются в Oracle намного быстрее соединений. Далее приведены результаты проверки быстродействия различных методов.
- Быстродействие
Изначально применены следующие настройки системы, основываясь на [2]:
select event, TOTAL_WAITS from v$system_event where event like 'db%'; /* optimizer_index_cost_adj=db_file_scattered_read/db_file_sequential_read *100 */ alter system set optimizer_index_caching=90; alter system set optimizer_index_cost_adj=15;
Рисунок 5 - Настройки системы
2.1. Метод Т. Кайта
Проводились измерения скорости одного запроса на одном и том же наборе данных таблицы ТС, но с различными индексами. Для проведения измерений в УМД выполнялся запрос, представленный на рисунке 6, в РМД - представленный на рисунке 7.
select e.ename,e.empno,e.sal,d.dname,l.city
from (
select string_number,
min(decode(column_name,'LAST_NAME',val)) ename,
min(decode(column_name,'SALARY',val)) SAL,
min(decode(column_name,'EMPLOYEE_ID',val)) EMPNO,
min(decode(column_name,'DEPARTMENT_ID',val)) deptno
from tc
where table_name='EMPLOYEES'
and scheme_name='TEST'
group by string_number
) e,
(
select string_number,
min(decode(column_name,'DEPARTMENT_ID',val)) deptno,
min(decode(column_name,'LOCATION_ID',val)) LOC_ID,
min(decode(column_name,'DEPARTMENT_NAME',val)) dname
from tc
where table_name='DEPARTMENTS'
and scheme_name='TEST'
group by string_number
) d,
(
select string_number,
min(decode(column_name,'LOCATION_ID',val)) LOC_ID,
min(decode(column_name,'CITY',val)) CITY
from tc
where table_name='LOCATIONS'
and scheme_name='TEST'
group by string_number
) l
where e.deptno=d.deptno
and d.loc_id=l.loc_id
and e.sal>40000
and city like 'A%';
Рисунок 6 - Пример запроса к УМД
select e.last_name, e.employee_id, e.salary,
d.department_name, l.city
from employees e, departments d, locations l
where e.department_id=d.department_id
and d.location_id=l.location_id
and e.salary>40000
and l.city like 'A%';
Рисунок 7 - Пример запроса к виртуальной схеме
Количество записей в таблицах схемы приведено в таблице 1.
Таблица 1

Результаты выполнения указанного выше запроса для УМД с различными индексами для таблицы данных представлены в таблице 2 и на рисунке 8.
Таблица 2
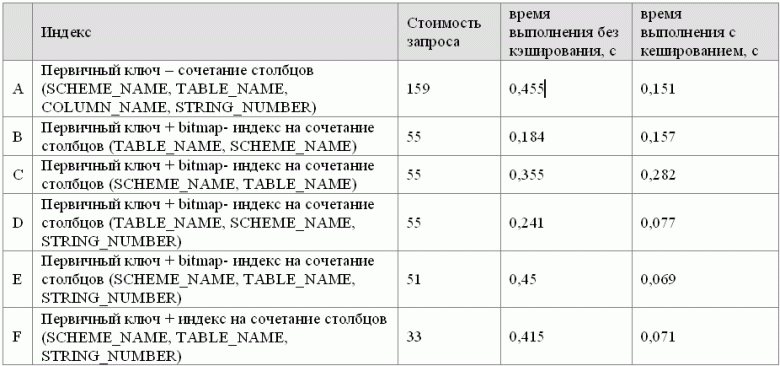

Рисунок 8 - Результаты выполнения запроса на различных объемах данных
По графику, представленному на рисунке 8, видно, что различия по времени несущественные, но в тоже время наименьшая стоимость у плана выполнения с использованием неуникального индекса на столбцы SCHEME_NAME, TABLE_NAME, STRING_NUMBER. Поэтому для дальнейших измерений по методу Т. Кайта выбран этот индекс.
2.2. Соединение таблицы данных УМД с собой.
При соединении таблицы с собой при выполнении запроса используется только индекс, созданный для первичного ключа. Остальные индексы не используются. Время выполнения представлено в таблице 3.
Таблица 3

Было проведено сравнение времени выполнения запросов для реляционной модели данных, для универсальной модели с трансляцией запросов по методу Т. Кайта и для универсальной модели с трансляцией запросов, в которых таблица данных соединяется сама с собой. Результаты представлены на рисунке 9. Разница во времени выполнения запроса в РМД и по методу Кайта, а также запроса в РМД и по методу соединения таблицы с собой представлена на рисунке 10.
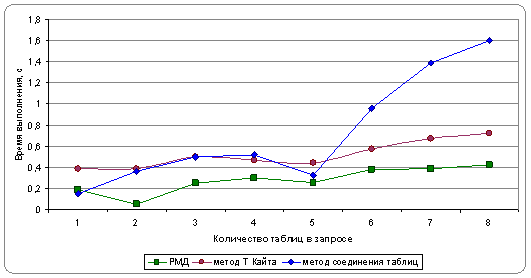
Рисунок 9 - время выполнения запроса в виртуальной схеме, в универсальной схеме по методу соединения таблицы данных с собой и методу Т. Кайта
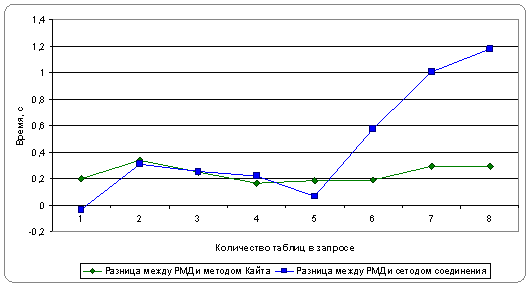
Рисунок 10 - Разница во времени выполнения запроса в РМД и по методу Т. Кайта, а также запроса в РМД и по методу соединения таблицы с собой
По графику "Разница во времени", изображенному на рисунке 10, видно, что разница между РМД и методом Кайта представляет собой относительно постоянную величину. Возможно, это связано с тем, что время уходит на группировку данных, чего нет при запросе к РМД. Если же сравнить время выполнения запроса к РМД и к УМД методом соединения таблицы с собой, то видно, что с увеличением числа таблиц разница увеличивается.
Заключение
Реализованная универсальная модель обладает следующими достоинствами:
- повышенное быстродействие;
- затраты времени на написание запросов для УМД не увеличиваются;
- расширенные возможности реализации декларативных и процедурных ограничений целостности. В частности, совершенно естественным образом создаются триггеры на SELECT, которые могут быть полезны для реализации в базе продукционных систем;
- возможностью задания пользователей виртуальных моделей.
В настоящее время разработан транслятор для версии SQL2.