В первой части статьи был дан обзор принципов оценки производительности среды IBM Rational ClearCase. Там описан подход, хорошо зарекомендовавший себя при диагностике проблем производительности. Этот подход основан на методичном анализе стека производительности - начиная с уровня операционной системы / аппаратуры, затем проверяя и настраивая параметры Rational ClearCase, а в конце - анализируя и оптимизируя прикладной уровень. Теперь же, во второй части этой серии, будет рассказано, как использовать определенные инструменты и практики для каждого слоя стека производительности, что необходимо для оценки функционирования и повышения эффективности работы IBM Rational ClearCase как на платформе Windows, так и под UNIX.
Аппаратный / операционный уровень стека производительности
Как уже было описано в первой части, я приступаю к анализу проблем производительности, начиная с нижнего уровня стека - аппаратного / операционного уровня (см. Рисунок 1).

Рис. 1. Стек производительности IBM Rational ClearCase
На этом уровне проверяется:
- Наличие ситуаций возникновения нехватки памяти.
- Проблемы с дисковым вводом/выводом.
- Пропускную способность сети и проблемы с задержками.
Далее эти вопросы обсуждаются подробно.
Проверка на ситуации возникновения нехватки памяти
Для повышения производительности IBM Rational ClearCase использует ряд кэшей. Оперативная память используется для кэширования данных на view-серверах и VOB-серверах. Кроме того, имеются кэши MVFS, а также кэш для каждого представления для процесса view-сервера. Для эффективной работы все эти кэши нуждаются в наличии соответствующего объема памяти, и именно в этом кроется причина чрезвычайной важности памяти для производительности Rational ClearCase.
Память также влияет на производительность процессора и операций дискового ввода/вывода. Система, испытывающая недостаток оперативной памяти, может также иметь высокий уровень использования процессора, так как процессор вынужден чаще обмениваться с диском страницами виртуальной памяти.
В системах под UNIX для проверки утилизации памяти и загрузки процессора я использую такие UNIX-утилиты, как vmstat, sar и glance. Тем не менее, эти утилиты присутствуют не во всех версиях UNIX. В системы Linux и Solaris, скорее всего, включен vmstat, а в HP-UX присутствует glance.
На рисунке 2 показана информация, выводимая vmstat в системе со значительной утечкой памяти; каждая строка, выводимая vmstat, является мгновенным снимком состояния системы в определенный интервал времени.
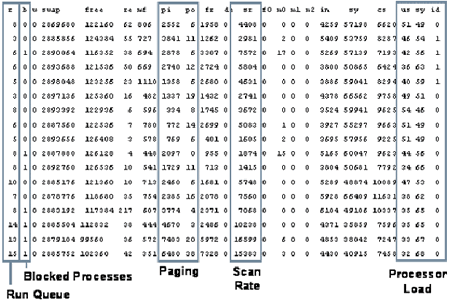
Рис. 2. Информация, выводимая утилитой vmstat, показывает статистику по виртуальной памяти
Основным индикатором нехватки памяти является частота сканирования. Когда система обнаруживает необходимость в оперативной памяти, начинается сканирование страниц виртуальной памяти, которые были сброшены на диск. Частота сканирования указывает, как много страниц памяти система ищет в секунду. До появления восьмой версии операционной системы Solaris, непрерывная частота сканирования более 200 страниц в секунду указывала на нехватку памяти. Начиная с восьмой версии Solaris и выше, любое ненулевое значение частоты сканирования означает, что системе не хватает памяти.
Также стоит обратить внимание на столбец "run queue" (очередь выполнения) - это важно, так как показывает количество процессов в очереди, ждущих выполнения процессором. Очередь выполнения не должна быть больше числа имеющихся в системе процессоров минус 1, но, как правило, я обращаю внимание на любое ненулевое значение.
Метрики на рисунке 2 указывают на нехватку памяти, которая, скорее всего, вызвана недостаточно мощным процессором. Время ожидания центрального процессора, указанное в последнем столбце, является нулевым. Очередь на выполнение также состоит из 15 процессов, перечисленных в последнем столбце. Если вы посмотрите только на эти два последних столбца, у вас может возникнуть мысль, что более мощный процессор сможет решить эту проблему; но фактически процессор оказывается занят исключительно подкачкой страниц памяти, что перекрывает выполнение системных задач, а на выполнение других процессов практически не остается времени.
Следует учесть, что величина частоты обмена страниц не всегда так важна, как частота сканирования. В некоторых операционных системах, ввод / вывод производится через отображение на страницы памяти, поэтому высокая частота обмена страниц может быть вызвана интенсивными операциями ввода/вывода. Подобная ситуация особенно характерна для компьютеров, работающих в качестве серверов NFS.
Если в вашей системе не доступна утилита vmstat, большинство подобной информации можно получить от sar, хотя в этом случае информация менее наглядна. На рисунке За показан вывод sar в системе, имеющей достаточное количество памяти, а на рисунке 3b - выводимая информация для системы с малым объемом памяти.
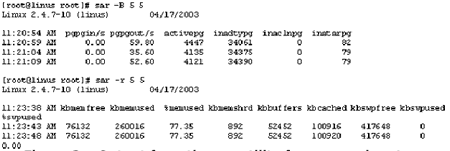
Рис. 3а. Выводимая утилитой sar информация для системы с достаточным количеством оперативной памяти

Рис. 3b. Выводимая утилитой sar информация для системы с нехваткой оперативной памяти
Видно, что объем используемой памяти, составляет лишь 77 процентов в нормальной системе, и 94 процента в системе с нехваткой памяти; в нормальной системе частота обмена страниц равна нулю, а в системе с нехваткой памяти составляет сотни страниц в секунду. Для последней системы - и для систем, показанных на рисунке 2, - добавление большего количества памяти является хорошим первоначальным шагом к повышению производительности.
Альтернативно можно просмотреть выполняющиеся в системе процессы с помощью утилит ps или top, с целью анализа, не могут ли некоторые интенсивно использующие память задачи выполняться на других компьютерах.
На платформе Windows есть еще более простой способ проверки памяти и загрузки процессора - с помощью менеджера задач Windows (taskmgr.exe). Монитор производительности (Performance Monitor_ (perfmon.exe) является еще одним хорошим инструментом анализа систем Windows. Кроме того, можно найти свободно доступные, распространяемые в исходных кодах, Windows-версии vmstat, sar и других утилит UNIX для проверки системных ресурсов.
Проверка наличия проблем с дисковым вводом/выводом
Так же, как и утилита vmstat выводит статистику по виртуальной памяти, UNIX-утилита iostat выводит статистику по операциям ввода/вывода. На рисунке 4 показан образец статистики, выводимой iostat, что можно использовать для идентификации узких мест с дисковой производительностью и проблем с балансировкой загрузки.
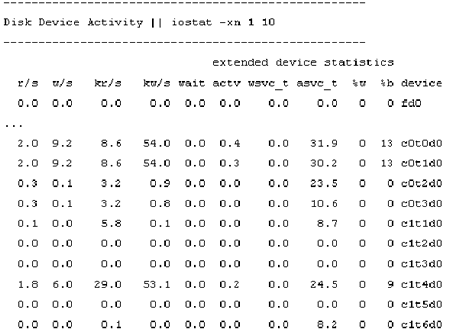
Рис. 4. Утилита iostat показывает дисковую активность
При анализе вывода iostat, я смотрю, прежде всего, на столбец %w, в котором указывается процент времени существования транзакций, ждущих выполнения. Другими словами, это процент времени, для которого очередь устройства не является пустой. Приведенное в этом столбце число должно быть нулем. Устранить ненулевые значения в столбце %w можно с помощью перераспределения дисков, чтобы интенсивно используемые диски были распределены среди нескольких дисковых контроллеров. Альтернативно, вы можете перераспределить данные таким образом, чтобы часто используемые данные размещались на дисках, работающих с различными контроллерами, или установить более быстрые дисковые контроллеры.
Обратим внимание на столбец %b, в котором приводится процент времени нахождения устройства в занятом состоянии. Этот столбец поможет идентифицировать проблемы с балансировкой загрузки. Например, вы можете отметить, что практически все ваши устройства имеют низкие значения %b - скажем менее 5% - и что один диск занят на 30%. В этом случае перед вами действительно проблемный диск, и возможно стоит распределить данные по остальным дискам.
Для работы в среде Windows была написана небольшую утилиту на Visual Basic (см. рисунок 5 и Приложение A), которая поможет идентифицировать как узкие места с дисковой производительностью, так и ситуации нехватки памяти1.
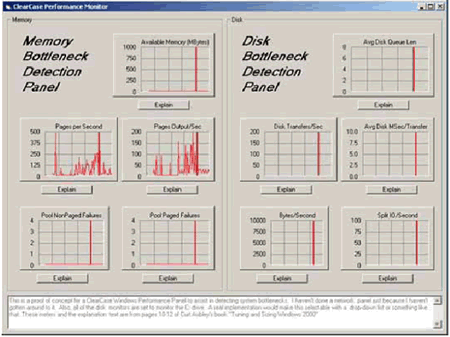
Рис. 5. Приложение на Visual Basic для мониторинга дисков и отслеживания использования памяти
Проверка на пропускную способность сети и наличие задержек
Если не обнаружено какой-либо нехватки ресурсов после проверки памяти, дисков и уровня загрузки процессора на VOB-хосте IBM Rational ClearCase, view-хосте, и соответствующих клиентских машинах Rational ClearCase, то следующим шагом будет поиск ситуаций сетевых задержек. Находясь на клиентской машине, надо использовать утилиту ping, имеющуюся как в UNIX, так и в Windows, и измерить время прохождения сетевых пакетов между VOB- и view-хостами. В качестве главного правила можно использовать следующее: если наблюдаемые времена прохождения пакетов превышают 10 мс, то пропускная способность сети может влиять на производительность IBM Rational ClearCase. Факты утери пакетов также должны привлечь внимание, так как в таком случае пакеты передаются повторно, что фактически удваивает время передачи.
Если результаты, выдаваемые утилитой ping, указывают на существование проблемы, я запускаю утилиту traceroute (на платформе Windows, это tracert.exe) для того, чтобы получить более подробную информацию о пути, который проходят пакеты по дороге к серверу. В идеальном случае мне хотелось бы видеть, что путь к серверу занимает лишь один сетевой сегмент (или вообще без сегментов, но в большинстве сетей такая ситуация маловероятна). Каждый сегмент характеризуется своей задержкой, так как пакет маршрутизируется сетевым оборудованием - поэтому чем меньше сегментов, тем лучше. По информации, выводимой утилитой traceroute, также можно точно определить, какой сетевой сегмент вызывает наибольшую задержку прохождения пакетов. Сетевые администраторы могут использовать эту информацию для улучшения пропускной способности сети, и в свою очередь, для сокращения времени отклика IBM Rational ClearCase.
Двумя другими утилитами, которые могут полезны для идентификации сетевых проблем, являются strace и truss2. В частности, эти утилиты можно применять при отслеживании воспроизводимых проблем, связанных с командами, так как они идентифицируют каждый системный вызов, выполняемый программой. Например, если обновление snapshot-представления занимает значительное количество времени, то можно запустить strace во время проведения одного из обновлений. При анализе выводимой информации видны длительные паузы между производимыми системными вызовами. Если обнаруживается длительная задержка вызова, относящегося к сетевым операциям - например, определение имени хоста или открытия файла на сетевом сервере, то можно использовать эту информацию для изоляции и выяснения причины возникновения торможения.
Если возникает подозрение, что в низкой производительности виновата сеть, но при этом не возможно определить, в чем именно заключается проблема, используется анализатор пакетов, такой как snoop или ethereal3. Обычно используются эти утилиты лишь, в крайнем случае, для того, чтобы точно определить, что происходит на уровне пакетов. Необходимо помнить, что важные данные часто проходят по сети в незашифрованной форме, и ПО для анализа сетевых пакетов может сделать эти данные видимыми для пользователя. По этой причине многие компании отрицательно относятся к проведению неавторизованного анализа пакетов в их внутренних сетях, поэтому в таком случае рекомендуется привлекать сетевого администратора, если подобный сбор данных действительно необходим.
Иногда обнаруживается, что бывает очень полезно поработать с подобными утилитами. Например, не так давно я был удивлен тем, что может случиться, если перестает работать мой сервер регистрации. Я сконфигурировал свою сеть, запустил ethereal, а затем отсоединил сетевой кабель от компьютера, на котором выполнялся сервер регистрации. Затем, чтобы посмотреть на VOB, я попробовал использовать cieartooi, запускаемую из командной строки утилиту IBM Rational ClearCase. Я увидел ушедший пакет с запросом на поиск сервера регистрации, а затем зависание, вызванное ожиданием отклика. В командной строке cieartooi была также заблокирована и находилась в состоянии ожидания. После того, как я снова подключил кабель, пакеты снова начали проходить по сети, и cieartooi продолжила свою работу.
Когда я отслеживаю проблемы производительности, и наблюдаю блокировку выполнения определенной команды IBM Rational ClearCase, я могу использовать утилиту ethereal для просмотра того, что именно происходит с пакетами, когда команда наконец начинает свою работу. Подобные приемы часто помогают мне идентифицировать ситуацию, когда сетевой ресурс оказывается либо недоступен, либо отклик от него слишком замедлен.
Уровни стека производительности IBM Rational ClearCase
После устранения любых проблем, обнаруженных на нижнем уровне стека производительности, я двигаюсь вверх и приступаю к изучению настраиваемых параметров Rational ClearCase. На этом уровне я смотрю на три принципиально важные области улучшения производительности, причем все они включают динамические представления:
- Кэши MVFS. В IBM Rational ClearCase файловая система MVFS (файловая система с поддержкой множественных версий) поддерживает динамические представления. Динамические представления используют MVFS для отображения выбранных комбинаций локальных и удаленных файлов в таком виде, как если бы они хранились в собственной файловой системе. Особенно важным является то, что MVFS позволяет пользователям просматривать VOB как наборы файлов и каталогов. Для повышения производительности MVFS поддерживает несколько кэшей.
- Индивидуальные view-кэши. В дополнение к кэшам MVFS, каждое индивидуальное представление имеет свой собственный кэш. Динамические представления требуют частых проверок на обновления, что делает их довольно "болтливыми" в смысле выполняемого ими количества RPC (удаленных вызовов процедур). View-сервер поддерживает несколько кэшей, состоящих главным образом из данных VOB, и необходимых для обеспечения быстрого отклика на запрошенные клиентом RPC.
- Экспресс-сборки. В моей практике, лишь небольшое количество людей осведомлены о существовании экспресс-сборок. С технической точки зрения они не являются настраиваемыми параметрами, но могут быть использованы для значительного увеличения производительности при использовании динамических представлений.
Давайте внимательнее посмотрим на каждую из этих областей.
Кэши MVFS.
Я использую два инструмента IBM Rational ClearCase для доступа к кэшу производительности MVFS: cleartool и mfvsstat.
Используя команду cleartool getcache - mvf s, я могу видеть, насколько полны различные кэши MFVS.
Как показано на рисунке 6, команда cleartool getcache -mvfs также предоставляет рекомендации по настройке параметров кэша MVFS. В Руководстве администратора IBM Rational ClearCase4 предоставлена более подробная информация по операциям, выполняемым каждым кэшем.

Рис. 6. Информация, выводимая командой cleartool getcache - mfvs
Если кэш почти заполнен, то это еще не говорит о проблеме. Фактически такая ситуация часто наблюдается в хорошо работающей системе. Тем не менее, если вы наблюдаете, что кэш заполнен, а частота успешных обращений низка, то вероятно кэш имеет слишком маленький размер. Частота успешных обращений указывает, насколько часто IBM Rational ClearCase находит информацию, за которой обращается в кэш.
Для определения частоты успешных обращений для кэшей MVFS я использую команду mvf sstat -ci, как показано на Рисунке 7:

Рис. 7. Информация, выводимая утилитой IBM Rational ClearCase mvfsstat
Я смотрю на общий вид полных кэшей, а также на частоту успешных обращений, и пытаюсь определить кэш, работу которого можно улучшить путем увеличения его размера. В общем случае мне хотелось бы видеть частоту успешных обращений выше 90 процентов. Если я отмечаю частоту успешных обращений ниже 80 процентов, и при этом кэш является почти заполненным, тогда я увеличиваю размер кэша. И одно дополнительное замечание: кэш enoent or name not found является очень важным, так как запросы на получение отсутствующей в таком кэше информации приводят к значительным затратам времени. Если вы обнаруживаете, что кэш заполнен, а частота успешных обращений низка, то увеличение размера кэша должно значительно увеличить производительность. На многопроцессорных компьютерах вам следует быть осторожным, чтобы не сделать размер кэша слишком большим. Слишком большой размер кэша фактически может вызвать некоторое снижение производительности для систем, имеющих несколько процессоров, так как процессы IBM Rational ClearCase управляют блокировками памяти кэшей, и, кроме того, на поиск в кэшах большего размера требуется дополнительное время.
Вы также можете измерить эффективность работы кэшей MVFS с помощью одиночной команды, такой как mvfstime -ci <command>, где <command> должна быть ciearmake или другой утилитой IBM Rational ClearCase. Это может пригодиться для доступа к информации о производительности кэшей во время выполнения определенных операций, таких как сборка (build). После того, как команда закончит работу, mvfstime выведет информацию о частоте успешных обращений во время выполнения команды.
Корректировка размера кэшей MVFS довольно проста. На платформе Windows можно использовать апплет из панели управления IBM Rational ClearCase (см. рисунок 8). Во многих случаях предпочтительным методом является использование коэффициента масштабирования, с помощью которого увеличивается размер всех кэшей. Альтернативно вы можете установить размеры индивидуальных кэшей, щелкнув по флаговой кнопке "override" ("переопределить"). Тем не менее, изменение индивидуальных размеров кэшей может отрицательно повлиять на производительность. Обычно я просто увеличиваю фактор масштабирования на некоторую величину, и затем повторно проверяю производительность кэша, причем повторяю это до тех пор, пока частота успешных обращений к кэшу не поднимется до приемлемого уровня.
На платформе UNIX, я использую команду cleartool setcache -mvfs -persistent -scalefactor для корректировки размеров кэшей. Опция -persistent нужна для того, чтобы изменения вступили в силу после рестарта системы MVFS. Без указания этой опции, размеры кэшей будут возвращены к их исходной величине после того, как MVFS будет еще раз запущена. Подробное обсуждение деталей находится за пределами этой статьи, но в Руководстве администратора IBM Rational ClearCase, в разделе Проверка и корректировка размера кэша MVFS даны исчерпывающие указания.
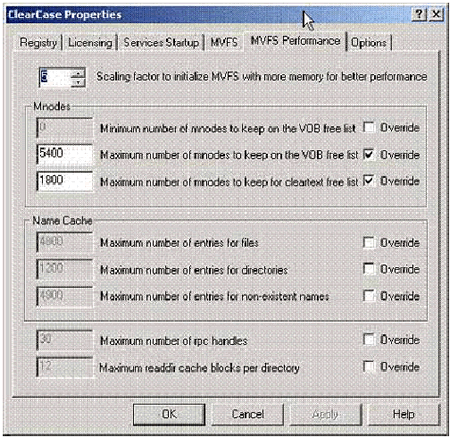
Рис. 8. Корректировка размеров кэшей MVFS с помощью апплета IBM Rational ClearCase
Индивидуальные view-кэши
Шаги, необходимые для выполнения анализа и корректировки индивидуальных view-кэшей, сходны с шагами при анализе кэшей MVFS. Для проверки эффективности кэша, используйте команду cleartool getcache -view viewname в Windows и в системах UNIX.
Как и в случае с кэшами MVFS, я обращаю внимание на заполненные кэши с низкой частотой успешных обращений. Например, на рисунке 9 показан кэш просмотра, который заполнен только на шесть процентов, с частотой успешных обращений 59 процентов. Если заполнение кэша просмотра близко к 100 процентам, я мог бы сделать корректировку, но в данном случае не о чем беспокоиться. Также важным является то, что статистику кэша следует проверить несколько раз и убедиться в том, что вы наблюдаете реальные результаты, а не переходные значения, вызванные недавним рестартом сервера.
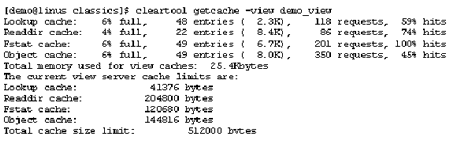
Рис. 9. Проверка эффективности индивидуальных view-кэшей
На рисунке 10 показано, как настраивать индивидуальные размеры view-кэшей с использованием утилиты cieartooi setcache -view. В этом примере, опция -cview указывает, что я установил текущее представление. Опция -cachesize IM указывает общее количество памяти, доступной для использования всеми кэшами. Значениями по умолчанию для общего размера кэшей являются 512 КБайт на 32-разрядных платформах и 1 МБайт на 64-разрядных. Корректировка общего размера кэшей не изменяет отношения, выделенного для дополнительных кэшей; если я увеличиваю общий размер кэшей, то и дополнительные кэши станут соответственно больше. Я могу также установить значение по умолчанию размеров кэшей для всей локальной сети, используя команду cieartooi setsite.
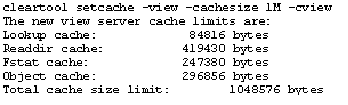
Рис. 10. Установка размеров индивидуальных view-кэшей
Экспресс-сбороки
Вы можете также рассмотреть использование экспресс-сборок для повышения производительности сборки. Если вы незнакомы с концепцией экспресс-сборок, то ниже будет приведено краткое описание.
Во время обычной контролируемой сборки IBM Rational ClearCase, тот факт, что был создан производный объект (например, foo.o), наряду с другой информацией, такой как версия исходных файлов и команды, использованные для генерации производного объекта, - все это регистрируется в VOB. Все это делается для обеспечения работы принятого в IBM Rational ClearCase механизма исключения сборок (или совместного использования двоичных файлов). Рассмотрим проект, над которым совместно работают несколько разработчиков, и некоторые разработчики снова и снова собирают один и тот же программный продукт. Когда один разработчик собирает foo.o с использованием ciearmake в динамическом представлении, ciearmake "идет в магазин" - то есть, запрашивает VOB, не собрал ли кто-нибудь foo.o с использованием той же самой версии foo.c и всех других исходных файлов, и используя тот же самый набор параметров сборки. Если кто-нибудь это уже сделал, тогда нет необходимости в повторной сборке foo.o, поэтому ciearmake просто начинает использовать оригинальный foo.o, который перемещается в специальный пул внутри VOB, называемый пулом производных объектов. Когда какие-либо сборки используют одни и те же параметры, то они будут использовать foo.o из пула производных объектов. Эта операция известна как "winkin", и как правило происходит быстрее, чем непосредственная компиляция foo.c.
С точки зрения производительности это означает то, что всякий раз, когда я использую ciearmake или omake для сборки версии проекта в динамическом представлении, эти утилиты говорят VOB, что именно я собираю. Это генерирует значительное число удаленных вызовов процедур и транзакций записи в VOB, которые снижают производительность.
Тем не менее, во время экспресс-сборки эти утилиты не говорят VOB о том, что нечто было собрано. Я все еще могу получить доступ к VOB, пулу производных объектов и совместно использовать существующие объекты, но я не могу сказать VOB что именно я делаю - поэтому я не смогу предоставить результаты своей сборки для общего использования.
Это выглядит довольно эгоистично, но при этом может ускорить процесс сборки двумя способами. Во-первых, во время экспресс-сборки производные объекты "регистрируются" в VOB. Это означает, что база данных VOB не блокируется при доступе на запись; поэтому другие пользователи могут получить более быстрый доступ к VOB во время проведения сборок, и на имеющемся оборудовании хост VOB сможет работать с большим количеством пользователей. Во-вторых, мой процесс сборки выполняется быстрее, так как устраняются требующие много времени транзакции записи в VOB. Я обнаружил, что в зависимости от проекта индивидуальные экспресс-сборки могут выполняться быстрее вплоть до 20 процентов.
На рисунке 11 вы можете увидеть, что время отклика увеличивается при увеличении количества фоновых пользователей, выполняющих сборки в стандартном режиме. Для экспресс-сборок, эта кривая становится значительно более пологой. Таким образом, используя то же самое аппаратное обеспечение, вы можете поддерживать значительно большее число пользователей, так как экспресс-сборки снижают объем входящего трафика в VOB, а вместе с тем и объем работы, которую VOB-сервер должен будет выполнить.
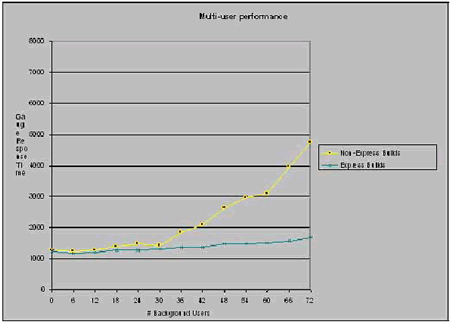
Рис. 11. Экспресс-сборки ухудшают время отклика системы при увеличении количества пользователей
Адаптация экспресс-сборок в качестве практики коллективной работы обычно требует изменений в способах взаимодействия разработчиков друг с другом. Если я использую экспресс-сборки, то тогда я должен явно сделать общими результаты своей сборки или же функция исключения сборки не будет работать для остальных разработчиков. Я могу это сделать вручную с использованием команды winkin. Кроме того, я могу использовать команду cieartooi is -long для определения того, является ли объект совместно используемым, или нет. Например,
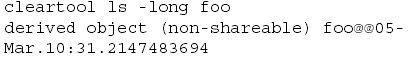
указывает, что объект foo не является совместно используемым для остальных сотрудников группы разработки. Важно помнить, что совместно используемый производный объект не может иметь закрытых для совместного использования частей. Если я собираю целое приложение, то я, например, не могу разрешить совместное использование только самого приложения; я должен разрешить использовать все объекты, которые в него входят.
Обычно, когда группа разработки принимает эту модель, то в качестве общего значения по умолчанию будет установлено создание представлений, использующих экспресс-сборки. При этом будет также установлено одно стандартное представление (normal view), которое не является представлением экспресс-сборки. Вместо предоставления всем сотрудникам группы разработки возможности явного совместного использования производных объектов, они используют это стандартное представление для выполнения еженощных сборок - и даже ежечасных сборок, если в этом имеется необходимость. Целью является заполнение VOB производными объектами, с помощью которых любой разработчик может провести экспресс-сборку (winkin). Таким образом, разработчик все еще может использовать преимущества совместного использования двоичных файлов, но без замедления, связанного с записью в VOB каждый раз при проведении сборки.
Для создания нового представления, использующего экспресс-представления, можно просто использовать опцию -nsnareabie_dos в cieartooi. Например, вы можете использовать следующую команду: cieartooi mkview -nshareable_dos <остальная командная строка>. Для преобразования существующего представления в представление с экспресс-сборками, используйте ту же опцию с cnview. Например, используйте следующий формат команды: cieartooi cnview - nshareable_dos <остальная командная строка>. После этого, просто используйте clearmake ИЛИ omake для обычной сборки.
В проектах, использующих Unified Change Management (унифицированное управление изменениями), или UCM5, представления с экспресс-сборкой создаются по умолчанию. В не-UCM проектах они не создаются. Тем не менее, вы можете использовать команду cieartooi setsite для установки во всей локальной сети значения по умолчанию для создания представлений, использующих экспресс-сборки. Для дополнительной информации по экспресс-сборкам, см. Building Software with Rational ClearCase6 (Сборка программного обеспечения с помощью Rational ClearCase).
Не зависимо от того, решите вы использовать экспресс-сборки или нет, но если вы захотите использовать такие преимущества IBM Rational ClearCase, как исключение сборки и возможности совместного использования двоичных файлов, то администраторы Rational ClearCase могут увеличить производительность сборки путем удаления устаревших представлений, когда они уже более не нужны. Процесс "приобретения" соответствующих производных объектов для экспресс-сборки ("winkin") может негативно влиять на производительность, когда Rational ClearCase будет вынуждена для поиска возможного соответствия проверять несколько конфигурационных записей7. Поэтому группам, практикующим экспресс-сборку, следует вычищать VOB от устаревших производных объектов. Под этим, в свою очередь, подразумевается удаление более не используемых представлений. Утилита scrubber, чья работа заключается в удалении производных объектов, не будет удалять производный объект до тех пор, пока одиночное представление сохраняет на него ссылку. Со временем количество ссылок уменьшается до тех пор, пока не остаются только представления, их создавшие, и поэтому содержащие на них ссылку, что достаточно для удержания в VOB производного объекта. Удаляя неиспользуемые представления, администратор позволяет утилите scrubber удалять из пула старые производные объекты, что ускоряет процесс "приобретения" для сборок с динамическими представлениями.
Прикладной уровень стека производительности
Прикладной уровень является самым верхним уровнем стека производительности. Он состоит из скриптов и триггеров процессов, выполняющих операции, относящиеся к функциям IBM Rational ClearCase. Он также содержит вызовы ciearmake - для сборки приложений - и make-файлы, содержащие зависимости для ciearmake. Как я уже говорил в Части I этой серии, с прикладным уровнем иногда труднее работать, так как зачастую он более сложен, и, кроме того, владельцы или создатели скриптов, триггеров или make-файлов защищают его от возможных изменений. Тем не менее, потенциал роста производительности в этой области достаточно велик.
Скрипты и триггеры процессов
Многие организации для выполнения специальной обработки используют скрипты, написанные на интерпретируемых языках, таких как Perl или язык командного процессора. Например, вместо использования простого взятия на редактирование cieartooi, они будут создавать скрипт, который сначала регистрирует операцию взятия на редактирование, а затем генерирует одну или несколько команд cieartooi. Другие организации создают скрипты, сходные с создаваемыми наследуемыми системами управления версиями. В любом случае, эти скрипты генерируют несколько выполняемых друг за другом команд cieartooi.
Триггеры, которые конфигурируются для автоматического запуска при выполнении определенной операции IBM Rational ClearCase, могут также вызвать cieartooi из интерпретируемого языка. В отличие от скриптов, триггеры часто являются невидимыми для пользователей, которые могут не знать, что какая-либо дополнительная обработка выполняется как часть их операций, например, взятия на редактирование.
Если вы используете Perl для написания скриптов или триггеров, то существуют несколько шагов, которые вы можете выполнить для улучшения производительности. Фактически, даже если вы не используете Perl, то вы возможно захотите переписать ваши скрипты прикладного уровня на Perl, для того, чтобы воспользоваться преимуществами некоторых из этих техник.
Как я уже писал в своей более ранней статье в Rational Edge , "Using Perl with Rational ClearCase Automation Library (CAL)," (Использование Perl c библиотекой автоматизации Rational ClearCase), когда программа вызывает cieartooi, то операционная система должна создать новый процесс, причем запуск нового процесса обходится достаточно дорого - сначала для него нужно выделить память, затем создать новую запись в таблице процессов и т.д. Эти операции могут занимать значительное количество времени, и если скрипт вызывает cieartooi несколько раз, то задержки накапливаются и могут становится весьма ощутимыми. Вы можете избежать задержек, связанных с выполнением нескольких команд cieartooi, воспользовавшись пакетом Perl ClearCase8 или библиотекой автоматизации ClearCase, которая предоставляет возможность обращения непосредственно к IBM Rational ClearCase. В моей предыдущей статье по CAL, я описал простой эксперимент, который я провел с целью выявления основных характеристик производительности. Я замерил время работы задачи, выполненной с помощью cieartooi, и затем замерил время работы той же задачи, но выполненной с помощью CAL. При выполнении этой определенной операции реализация на CAL была примерно на 30 процентов быстрее.
Другой техникой, которая может улучшить производительность, является предварительная компиляция ваших Perl-скриптов в самостоятельные приложения, что может быть сделано, например, с использованием PerlApp из Perl Development Kit9 от ActiveState. В первой части этой серии статей было дано исследование прецедента для организации, реализовавшей иной подход. При повторной оценке функциональности, реализованной с использованием скриптов и триггеров, обнаружилось, что Unified Change Management с успехом может справляться с большинством этих задач. Поэтому было принято решение по внедрению UCM. В качестве вторичного эффекта от подобного изменения, большинство выполняемых операций прикладного уровня было преобразовано во встроенные операции Rational ClearCase, которые выполняются значительно быстрее.
До того, как стало доступным использованием UCM, в ряде организаций были созданы программы-упаковщики (wrappers) для выполнения операций взятия на редактирование и снятия с редактирования, что было необходимо для реализации наборов изменений, связанных с определенными действиями разработчиков. Работа подобных скриптов заключается в том, что при запуске у пользователя запрашивается, какого рода операции он хочет провести, а затем производится регистрация этих операций с использованием базы данных или каким-либо другим способом. Теперь же все эти операции являются встроенными операциями UCM Rational ClearCase. Используя при выполнении этих задач UCM, а не написанные самими разработчиками скрипты, вы сможете достичь значительного увеличения производительности.
Упрощение структуры make-файлов и ускорение сборок
Во многих организациях, с которыми мне довелось работать, я часто обнаруживал make-файлы, структура которых была загадочна и чрезвычайно запутана.
Организации, которые использовали make или ciearmake для работы с большими проектами, опасались изменять что-либо в своих make-файлах из страха, что внесенные изменения сделают невозможным процесс дальнейшей сборки. Результатом был неконтролируемый рост размера этих файлов. Я люблю сравнивать подобный эффект с тем, что наблюдается в доме привидений в Винчестере, что близ Сан-Франциско в Калифорнии, где имеются лестницы и коридоры, ведущие в никуда, и двери, за которыми стены или которые открываются в пустоту10.
Подобно этому дому, многие make-файлы создавались годами без наличия какой-либо определенной руководящей схемы. Поэтому люди опасаются добавлять к ним что-либо, за исключением абсолютно необходимого для сборок новой версии. Обычно эти make-файлы не оптимизированы и никто не знает, как именно они работают. Тем не менее, разработчики при сборке своих систем все еще полагаются на эти файлы.
Я всегда настоятельно рекомендую своим клиентам периодически проверять и переписывать make-файлы проектов во избежание проявления «синдрома дома привидений в Винчестере». Кроме того, всегда весьма полезно заручиться поддержкой сотрудника, который хорошо знаком с процессом сборки программного обеспечения. Если вы точно не знаете, что именно делает ваш make-файл, но при этом вам нужно собрать программный проект, тогда можно использовать конфигурационную запись IBM Rational ClearCase для создания базиса для нового make-файла. Просто собирайте ваше ПО с помощью контролируемой сборки, используя ciearmake. Когда сборка будет завершена, запустите команду run cleartool cater -makefile myapplication. При этом конфигурационная запись будет выведена в формате make-файла. Этот make-файл может не быть оптимизированным, но его структура будет более прозрачной, что облегчит последующее проведение оптимизации.
Безусловно, использование экспресс-сборок может также ускорить процесс сборки. Кроме того, вы можете рассмотреть возможность выполнения параллельных распределенных сборок в среде UNIX или параллельных сборок в многопроцессорной среде Windows. За более подробной информацией по параллельной сборке обратитесь к руководству по IBM Rational ClearCase, разделу Building Software with Rational ClearCase (Сборка программного обеспечения с помощью Rational ClearCase).
Последнее замечание по эффективности сборки при работе с кэшами MVFS: будьте осторожны при использовании многих директив -i для указания путей поиска файлов компилятором. Директива компилятора -i <d±r> используется для указания каталога <dir> в качестве одного из каталогов, в котором следует искать файлы заголовков, используемые при компиляции. Для каждого включенного в исходный файл заголовка, компилятор будет производить поиск в каждом каталоге, и если не будет обнаружено соответствие, продолжать поиск в следующем каталоге. MVFS кэширует файловую информацию в кэшах dirent и enoent, а в последнем кэшируются имена путей, по которым каждый искомый файл не был найден. Эти кэши обеспечивают более быстрое выполнение просмотра, как для поиска корректных, так и отбрасывания неправильных имен путей. Если вы используете много директив -i для многих каталогов, и в каждом из этих каталогов имеется много различных файлов, из которых лишь некоторые фактически нужны для компиляции, то эффектом будет заполнение кэша enoent каждым элементом каталога, который не соответствует каждому не найденному файлу. При значительном количестве файловых записей кэш enoent становится заполненным, а поиск в нем - менее эффективным. Если вы считаете, что это может отрицательно влиять на производительность процесса сборки, то подумайте о том, чтобы сгруппировать все заголовки и другие включаемые файлы в одном каталоге, и указать этот единственный каталог в директиве -i.
Совместно используемые сетевые ресурсы и IBM Rational ClearCase Doctor
Общие сетевые ресурсы - такие, как контроллеры доменов, серверы доменных имен, и так далее - также отрицательно влияют на производительность IBM Rational ClearCase. На платформах Windows, проведение анализа в этой области не так сложно; все, что нужно сделать - это предоставить возможность IBM Rational ClearCase Doctor выполнить свою работу.
На рисунке 12 приведены результаты стандартного статического анализа, выполняемого при запуске Rational ClearCase Doctor. Эта утилита тестирует разрешение имени хоста и сообщает о том, сколько времени заняло ожидание ответа от контроллера домена, запрос лицензии и ожидание ответа от сервера регистрации.
Рис. 12. Rational ClearCase Doctor показывает время отклика от общих сетевых ресурсов
Большинство заказчиков, с которыми я говорил, знают об этих отчетах, но лишь некоторые знают о том, что IBM Rational ClearCase Doctor также может выполнять и динамический анализ. Из меню Analysis , вы можете выбрать Server Accessibility Analysis... ("анализ доступности сервера...") для получения доступа к различным возможностям динамического анализа, как показано на рис. 13a.
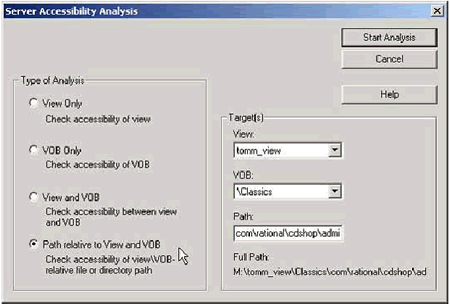
Рис. 13a. IBM Rational ClearCase Doctor предоставляет возможности анализа доступности сервера
На рисунке 13a, я выбрал селективную кнопку для проверки определенного пути, связанного с представлением и с VOB. После того, как я щелкну по "Start Analysis" ("запуск анализа"), я увижу результаты, приведенные на рисунке 13b.
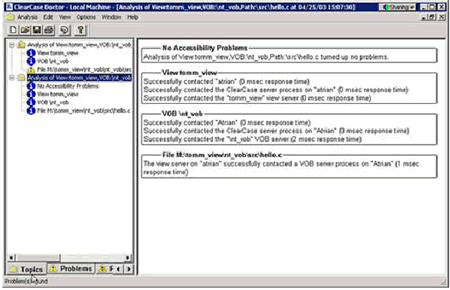
Рис.13b. Результаты анализа доступности сервера
Результаты показывают время отклика для доступа к указанному мной файлу в данном представлении и VOB. В этом случае отклик является очень быстрым, так как все объекты, к которым происходят обращения, находятся на моем компьютере. Тем не менее, если я отмечаю, что взятие/снятие с редактирования определенного файла требует слишком много времени, я могу использовать этот динамический анализ в Rational ClearCase Doctor для получения более полной картины происходящего.
Другие факторы производительности
Существует несколько других путей для предотвращения замедлений работы IBM Rational ClearCase.
В качестве общей рекомендации, не храните тысячи файлов в корневом каталоге VOB, который не кэшируется вместе с остальными каталогами; вместо этого, разместите файлы в подкаталогах. Фактически я следую этому правилу для каждой используемой мной операционной системы.
Кроме того, если вы используете версию UCM от 2002 г. или более раннюю, старайтесь снизить количество модифицируемых компонентов вашего проекта до десяти или меньше и старайтесь избегать продолжительных потоков работ с большим количеством базовых версий. В противном случае подобные операции могут отрицательно влиять на производительность. Улучшения в UCM для IBM Rational ClearCase версии 2003 сняли эти ограничения.
Делайте это шаг за шагом
Анализ и улучшение производительности IBM Rational ClearCase может быть достаточно сложной задачей. Но как и при работе над любой сложной проблемой, она становится более простой, если ее решение разбить на ряд последовательных операций. Согласно моему опыту, работа со стеком производительности предоставляет прекрасную основу для разбиения задачи на составляющие. По мере того, как я перемещаюсь по стеку производительности - от аппаратного уровня / уровня ОС к параметрам IBM Rational ClearCase и далее к прикладному уровню, я постоянно помню о том, что даже небольшое увеличение производительности в долгосрочной перспективе может оказать значительное влияние на продуктивность и эффективность работы организации. Поэтому, затратив немного времени на улучшение производительности, можно достичь значительной экономии времени при работе над проектом.
Ссылки
Curt Aubley, Tuning & Sizing NT Server. Prentice Hall, 1998.
Curt Aubley, Tuning and Sizing Windows 2000 for Maximum Performance. Prentice Hall, 2000.
Adrian Cockroft and Richard Pettit, Sun Performance and Tuning: Java and the Internet.
Prentice Hall, 1998.
Gian-Paolo D. Musumeci and Mike Loukides, System Performance Tuning, 2nd Edition. O'Reilly & Associates, 2002.
Richard Pettit, SE Toolkit, http://www.setoolkit.com.
Joseph D. Sloan, Network Troubleshooting Tools. O'Reilly & Associates, 2001.
Hal Stern, Mike Eisler, and Ricardo Labiaga, Managing NFS and NIS, 2nd Edition. O'Reilly & Associates, 2001.
Ed Wilson and James Naramore, Network Monitoring and Analysis. Prentice Hall, 2000.
Brian L. Wong, Configuration and Capacity Planning for Solaris Servers. Prentice Hall, 1997.
" HP-UX Memory Management." Hewlett Packard Company White Paper, 2000. http://docs.hp.com/hpux/onlinedocs/os/lli/mem mqt.html.
Примечания
1 Мое предложение основано на двух книгах Курта Убли (Curt Aubley): Tuning & Sizing NT Server (Настройка и масштабирование NT сервера) и Tuning and Sizing Windows 2000 for Maximum Performance (Настройка и масштабирование Windows 2000 для получения максимальной производительности), обе книги опубликованы издательством Prentice Hall. В этих книгах приведена более подробная информация по использованию встроенных утилит Windows, таких как Task Manager (диспетчер задач) и Performance Monitor (монитор производительности), для выявления узких мест производительности системы Windows. Дополнительная информация доступна в он-лайновом режиме по адресу http://www.tuningandsizingnt.com.
2 truss является утилитой, специфичной для Solaris (AIX теперь эмулирует ее в версии 5.x, но эта версия не так усложнена, как Solaris 5.7 и выше). MKS предоставляет версию для Windows, truss.exe. Существуют, по меньшей мере, два типа strace для Windows, причем лучшей из них является та, которая устанавливается вместе с Cygwin.
strace от Cygwin предоставляет информацию по промежуткам времени, в то время как доступный для загрузки стандартный вариант этой утилиты такой информации не дает. Cygwin особо указывается, что strace была разработана главным образом для отладки dll-библиотек Cygwin. Аналогичная утилита в HP 11.x называется tusc, и она предоставляет выводимую информацию и функциональность, сравнимую с truss для старших версий Solaris. В AIX имеется несколько более сложная в использовании утилита 'trace', которая предоставляет подробный анализ отслеживания системных вызовов.
3 snoop является утилитой Solaris. Netmon от Microsoft доступен на платформе Windows; утилита ethereal доступна для ряда операционных систем. Кроме того, tcpdump предоставляет сходную функциональность для версий UNIX, отличных от Solaris (включая Linux).
4 Это руководство поставляется вместе с продуктом IBM Rational ClearCase
5 Unified Change Management представляет собой созданную IBM Rational систему "наилучших практик" для управления изменениями, начиная от требований и заканчивая релизом. Интегрируемая с IBM Rational ClearCase и IBM Rational ClearQuest, UCM определяет последовательный, основанный на выполнении отдельных задач процесс управления изменениями, который непосредственно может применяться группами для работы над проектами разработки ПО.
6 Это руководство поставляется вместе с продуктом IBM Rational ClearCase.
7 IBM Rational ClearCase использует технологию кэширования для быстрого удаления наиболее производных объектов (most derived objects), но в крупных проектах разработки ПО могут находиться несколько потенциальных кандидатов, которые должны быть более тщательно проанализированы.
8 Пакет Perl ClearCase доступен от CPAN по адресу http://www.cpan.org. Пакет ciearcase::ctcmd, поставляемый IBM Rational, является компилируемым интерфейсом к таблице процессов подкоманд cleartool. При этом устраняется расходование ресурсов на запуск каждой сессии cleartool, что делается за счет непосредственной привязки к библиотекам IBM Rational ClearCase и использованию компилированных точек обращения к совместно используемым объектам Rational ClearCase. Это может существенно увеличить производительность Perl-скриптов для Rational ClearCase.
9 См. мою статью в Rational Edge: "Using Perl with Rational ClearCase Automation Library (CAL)" (Использование Perl c библиотекой автоматизации Rational ClearCase), где приведена дополнительная информация и некоторые ньюансы использования CAL.
10 Сара Винчестер (Sarah Winchester), наследница состояния Винчестерской ружейной компании, непрерывно работала над этим домом в течение 38 лет. См. http://www.winchestermvsteryhouse.com/