Эта работа открывает цикл из трех статей, посвященных архитектурам хранилищ данных (ХД) и их предшественников. Обилие различных подходов, методов и рекомендаций приводят к некоторой путанице понятий, достоинств, недостатков и границ применимости тех или иных архитектурных решений. В первой статье рассмотрены эволюция понимания места OLAP, компоненты архитектуры ХД, виртуальные ХД и независимые витрины данных. В двух следующих публикациях будут рассмотрены централизованное ХД с системой извлечения, преобразования и загрузки данных (ETL), хранилище данных с системой извлечения, загрузки и преобразования данных (ELT), ЦХД с оперативным складом данных (ОCД), расширенная модель с витринами данных (ВД), хранилище с накоплением данных в ВД, централизованная ETL с параллельными ХД и ВД, а также рекомендованная архитектура хранилища данных
Любая транзакционная система, как правило, содержит два типа таблиц. Один из них отвечает за быстрые транзакции. Например, при продаже билетов необходимо обеспечить работу большого числа кассиров, которые обмениваются с системой короткими сообщениями. Действительно, вводимая и распечатываемая информация, касающаяся фамилии пассажира, даты вылета, рейса, места, пункта назначения, может быть оценена в 1000 байт. Таким образом, для обслуживания пассажиров необходима быстрая обработка коротких записей. Другой тип таблиц содержит итоговые данные о продажах за указанный срок, по направлениям, по категориям пассажиров. Эти таблицы используются аналитиками и финансовыми специалистами раз в месяц, или в конце года, когда необходимо подвести итоги деятельности компании. И если количество аналитиков в десятки раз меньше числа кассиров, то объемы данных, необходимых для анализа, превышают размер средней транзакции на несколько порядков величины. Естественно, что во время выполнения аналитических работ время отклика системы на запрос о наличии билета увеличивается. Создание систем с резервом вычислительной мощности может сгладить негативное воздействие аналитической нагрузки на транзакционную активность, но приводит к значительному удорожанию комплекса, при том, что избыточная мощность большую часть времени остается невостребованной. Вторым фактором, приведшим к разделению аналитических и транзакционных систем, являются разные требования, которые предъявляют аналитические и транзакционные системы к вычислительным комплексам.
История OLAP начинается в 1993, когда была опубликована статья 1 "Обеспечение OLAP (оперативной аналитической обработки) для пользователей - аналитиков". Первоначально казалось, что разделения транзакционных и аналитических систем (OLTP - OLAP) вполне достаточно.
Однако вскоре выяснилось, что OLAP - системы очень плохо справляются с ролью посредника между различными транзакционными системами - источниками данных и клиентскими приложениями.
Стало ясно, что необходима среда хранения аналитических данных. И поначалу на эту роль претендовали единые базы данных, в которые предлагалось копировать исходную информацию из источников данных. Эта идея оказалась не вполне жизнеспособной, поскольку транзакционные системы разрабатывались, как правило, без единого плана, и содержали противоречивую и несогласованную информацию.
Рис. 1. Эволюция понимания места OLAP в архитектуре
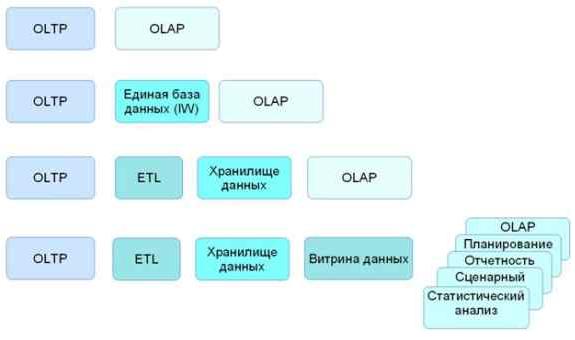
Так появились хранилища данных, предназначенные для надежного хранения информации, и системы извлечения, очистки и загрузки данных. OLAP-системы работали поверх хранилищ данных.
Вскоре выяснилось, что хранилища данных накапливают настолько важную для организации информацию, что всякий несанкционированный доступ в хранилище чреват серьезными финансовыми потерями. Кроме того, ориентированные на надежное хранение форматы данных плохо сочетаются с требованиями быстрого информационного обслуживания. Территориальная распределенность и организационная структура предприятия также требуют специфического подхода к информационного обслуживания каждого подразделения. Решением является витрины данных, которые содержат необходимое подмножество информации из хранилища. Наполнение витрин из хранилища может происходить в часы спада активности пользователей. В случае сбоя информация может быть легко восстановлена из хранилища с минимальными потерями.
Витрины данных могут обслуживать задачи отчетности, статистического анализа, планирования, сценарных расчетов, и, в том числе, многомерного анализа (OLAP). Таким образом, системы OLAP, первоначально претендовавшие на роль чуть ли не половины вычислительного мира (отдавая вторую половину OLTP системам), в настоящее время занимают место аналитических средств уровня рабочих групп.
Шесть уровней архитектур хранилища данных
Архитектура хранилищ данных иногда напоминает детскую игру в кубики. Как их ни сложи, все равно получается нечто, что можно встретить в реальной жизни. Иной раз в организации можно обнаружить наличие нескольких корпоративных хранилищ данных, каждое из которых позиционируется как единый и единственный источник непротиворечивой информации.
Еще забавнее многослойные витрины данных при наличии единого хранилища. Почему нельзя построить новую витрину поверх хранилища? Видите ли, пользователям захотелось объединить некоторые данные из двух витрин в третью. Это, может быть, имело бы смысл, если бы в витринах содержалась информация, которой нет в хранилище, например, если бы пользователи обогащали витрину своими расчетами и данными. Даже если так, то какова ценность этих обогащенных данных по сравнению с теми, что прошли через сито очистки в соответствии с корпоративными правилами? Кто отвечает за качество этих данных? Как они появились в системе? Никто не знает, но всем хочется получить доступ к информации, которой нет в хранилище.
Хранилища данных чем-то похожи на системы очистки воды. Вода собирается из разных источников с различным химическим составом. Поэтому в каждом конкретном случае применяются свои методы очистки и обеззараживания воды. Вода, отвечающая строгим стандартам качества, поступает к потребителям. И как бы мы ни жаловались на качество воды, именно такой подход предотвращает распространение эпидемий в большом городе. И никому не приходит в голову (я очень на это надеюсь) очищенную воду обогащать водой из ближайшей лужи. Но в ИТ свои законы.
В дальнейшем будут рассмотрены различные архитектуры хранилищ данных, кроме совсем экзотичных вариантов.
Мы будем рассматривать архитектуры корпоративного хранилища данных на шести уровнях, так как, несмотря на то, что сами компоненты могут отсутствовать, уровни в том или ином виде сохраняются.
Рис. 2. Шесть уровней архитектуры хранилища данных
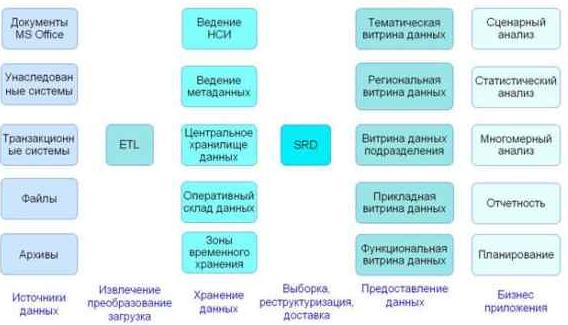
Первый уровень представлен источниками данных, в качестве которых выступают транзакционные и унаследованные системы, архивы, разрозненные файлы известных форматов, документы MS Office, а также любые иные источники структурированных данных.
На втором уровне размещается система извлечения, преобразования и загрузки данных (ETL - Extract, Transformation and Load). Основная задача ETL - извлечь данные из разных систем, привести их к согласованному виду и загрузить в хранилище. Программно-аппаратный комплекс, на котором реализована система ETL, должен обладать значительной пропускной способностью. Но еще важнее для него - это высокая вычислительная производительность. Поэтому лучшие из систем ETL способны обеспечивать высокую степень параллелизма вычислений, и даже работать с кластерами и вычислительными гридами.
Роль следующего уровня - надежное, защищенное от несанкционированного доступа, хранение данных. В соответствии с предлагаемой тройной стратегией 2 , мы полагаем, что на этом уровне должны размещаться также системы ведения метаданных и нормативно-справочной информации (НСИ). Оперативный склад данных (Operational Data Store) необходим тогда, когда требуется как можно более оперативный доступ к пусть неполным, не до конца согласованным данным, доступным с наименьшей возможной задержкой. Зоны временного хранения (Staging area) нужны для реализации специфического бизнес - процесса, например, когда перед загрузкой данных контролер данных должен просмотреть их и дать разрешение на их загрузку в хранилище.
Иногда зонами временного хранения называют буферные базы данных, необходимые для выполнения внутренних технологических операций, например, ETL выбирает данные из источника, записывает их во внутреннюю БД, обрабатывает и предает в хранилище. В данной работе под зонами временного хранения понимаются области хранения данных, предназначенные для выполнения операций внешними пользователями или системами в соответствии с бизнес требованиями обработки данных. Выделение зон временного хранения в отдельный компонент ХД необходим, так как для этих зон требуется создание дополнительных средств администрирования, мониторинга, обеспечения безопасности и аудита.
Информационные системы на уровне распределения данных все еще не имеют общепринятого названия. Они могут называться просто ETL, так же, как и система извлечения, преобразования и загрузки данных на втором уровне. Или, чтобы подчеркнуть отличия от ETL, их иногда называют ETL-2. При этом системы уровня распределения данных выполняют задачи, значительно отличающиеся от задач ETL, а именно, выборку реструктуризацию и доставку данных (SRD - Sample, Restructure, Deliver) ETL извлекает данные из множества внешних систем. SRD выполняет выборку из единого хранилища данных. ETL получает несогласованные данные, которые надо преобразовать к единому формату. SRD имеет дело с очищенными данными, структуры которых должны быть приведены в соответствие с требованиями различных приложений. ETL загружает данные в центральное хранилище. SRD должно доставить данные в различные витрины в соответствии с правами доступа, графиком доставки и требованиями к составу информации.
Уровень предоставления данных предназначен для разделения функций хранения и функций обслуживания различных задач. Витрины данных должны имеет структуры данных, максимально отвечающие потребностям обслуживаемых задач. Поскольку не существует универсальных структур данных, оптимальных для любой задачи, витрины данных следует группировать по территориальным, тематическим, организационным, прикладным, функциональным и иным признакам.
Уровень бизнес-приложений представлен сценарными расчетами и статистическим анализом, многомерным анализом, средствами планирования и подготовки отчетности. Естественно, что список бизнес-приложений этим не исчерпывается.
Виртуальные хранилища данных остались в той романтической эпохе, когда казалось, что можно реализовать все, что ни измыслит мозг человеческий. О них уже никто не помнит, и потому вновь и вновь изобретают их, правда, на новом уровне. Поэтому просто необходимо начать с того, чего уже давно нет, но пытается возродиться в новом обличье. Идея создания виртуальных хранилищ основывалась на нескольких возвышенно- прекрасных идеях.
Первая идея - это сокращение расходов. Нет необходимости тратить средства на дорогостоящее оборудование для центрального хранилища данных. Не надо содержать высококвалифицированный персонал, обслуживающий это хранилище. Не нужны серверные помещения с дорогостоящим оборудованием систем охлаждения, пожаротушения и мониторинга.
Вторая идея - надо работать с самыми свежими данными. Аналитические системы должны напрямую работать с источниками данных, минуя всех посредников. Посредники - это зло, это все знают. У наших экспертов нет доверия к программам-посредникам. Эксперты всегда работали напрямую с данными исходных систем.
Третья идея - мы сами все напишем. Все, что нужно - это рабочая станция и доступ к источникам данных. И еще компилятор. Наши программисты все равно сидят без дела. Они разработают программу, которая по запросу пользователя будет сама обращаться ко всем источникам, сама будет доставлять данные на пользовательский компьютер, сама будет преобразовывать несовпадающие форматы, сама будет выполнять анализ данных, и сама же покажет все на экране.
Рис. 3. Виртуальные хранилища данных
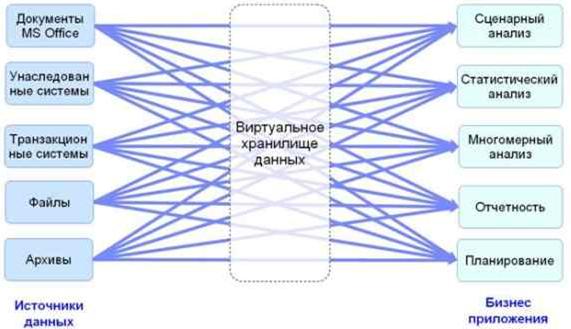
В компании много разных пользователей с разными нуждами? Ничего страшного, мы модифицируем нашу универсальную программу под столько вариантов, сколько требуется.
Появился новый источник данных? Все замечательно. Мы перепишем все наши программы с учетом особенностей этого источника.
Изменился формат данных? Прекрасно. Мы перепишем все наши программы с учетом нового формата.
Все хорошо, все при деле, надо расширять отдел программирования.
Да, еще пользователи систем-источников данных жалуются, что с некоторых пор их системы очень медленно работают по той причине, что при каждом, даже повторном запросе наше универсальное клиентское приложение снова и снова обращается к источнику данных. Поэтому надо приобрести новые, более мощные серверы. Где сокращение расходов? Его нет. Наоборот, расходы только растут. Нужно больше разработчиков, больше серверов, больше электричества, больше площадей под серверные помещения.
Может, все же есть выгода от такой архитектуры?
Мы получили жесткую связь между источниками данных и аналитическими приложениями. Любое изменение в источнике данных должно согласовываться с разработчиками универсального клиента с тем, чтобы избежать передачи искаженных и неверно интерпретируемых данных в аналитические программы. На каждом рабочем месте необходимо поддерживать набор интерфейсов доступа к различным системам - источникам.
Иногда говорят, что все это очевидно и не стоит тратить время на разъяснение того, что и так всем понятно. Но почему эти же разработчики на запрос пользователя "Мне нужны данные из витрин А, Б и В" пишут клиентское приложение, которое обращается к сразу к нескольким витринам, вновь и вновь воспроизводя умершую архитектуру виртуального хранилища данных?
Независимые витрины данных появились как физическая реализация понимания того, что транзакционная и аналитическая обработка данных плохо уживаются на одной ЭВМ. Причины несовместимости заключаются в следующем:
- Для транзакционной обработки характерно большое количество чтений и записей в базу данных. Аналитическая обработка может потребовать всего несколько обращений к БД.
- Длина записей в OLTP обычно не превышает 1000 символов. Аналитический запрос может потребовать мегабайты данных за одно обращение для анализа.
- Количество пользователей транзакционной системы может достигать несколько тысяч человек. Число аналитиков обычно в пределах нескольких десятков.
- Характерными требованиями для транзакционных систем является круглосуточная бесперебойная работа 365 дней в году (24 х 365). Аналитическая обработка не выдвигает столь четко сформулированных требований к готовности аналитических комплексов, но не подготовленная в срок отчетность может привести к серьезным неприятностям, как для аналитиков, так и для предприятия.
- Нагрузка на транзакционные системы распределяется более или менее равномерно во времени. Нагрузка на аналитические системы, как правило, максимальна в конце отчетных периодов (месяца, квартала, года).
- Транзакционная обработка осуществляется, в основном над текущими данными. Аналитические вычисления производятся над историческими данными.
- Данные в транзакционных системах могут обновляться, тогда, как в аналитических системах данные должны только добавляться, и попытка внесения изменений задним числом должна вызывать, по меньшей мере, настороженность.
Таким образом, транзакционные и аналитические системы выдвигают разные требования к программно-аппаратному комплексу в части производительности, пропускной способности, доступности комплекса, моделям данных, организации хранения данных, способов доступа к данным, пиковым нагрузкам, объемам обрабатываемы данных и методам обработки.
Создание независимых витрин было первой реакцией на необходимость разделения аналитической и транзакционных систем. В те времена это был большой шаг вперед, упростивший проектирование и эксплуатацию программно-аппаратных комплексов, так как не надо было пытаться удовлетворить взаимоисключающим требованиям аналитических и транзакционных систем.
Преимуществом создания независимых витрин является легкость и простота их организации, так как каждая из них оперирует с данными одной задачи, и поэтому не возникает проблем с метаданными и НСИ. Нет никакой необходимости в сложных системах извлечения, преобразования и загрузки данных (ETL). Данные просто копируются на регулярной основе из транзакционной системы в витрину данных. Одно приложение - одна витрина. Поэтому независимые витрины данных часто называют прикладными витринами данных. Но что делать, если пользователям нужно использовать информацию из нескольких витрин одновременно? Разработка сложных клиентских приложений, способных обращаться ко многим витринам и на лету преобразовывать данные, уже была скомпрометирована виртуальными хранилищами данных.
Рис. 4. Независимые витрины данных
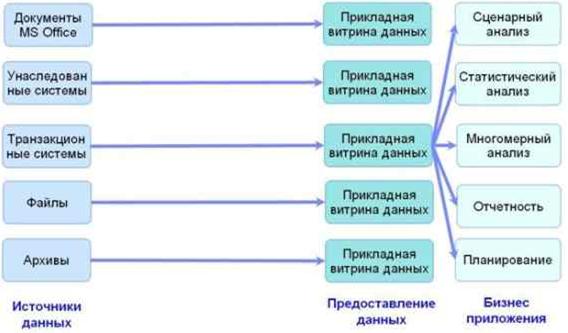
Значит, нужен единый репозиторий - хранилище данных. Но информация в витринах не согласована. Каждая витрина унаследовала от транзакционной системы свою терминологию, свою модель данных, свою нормативно-справочную информацию, в том числе, кодировку данных. Например, в одной системе дата выполнения операции может быть закодирована в российском формате ДД.ММ.ГГГГ (день, месяц, год), а в другой в американском формате ММ.ДД. ГГГГ (месяц, день, год). Значит, при слиянии данных необходимо понимать, что означает дата 06.05.2009 - это 5 июня, или 6 мая. Итак, нам нужна система извлечения, преобразования и загрузки данных.
Таким образом, все преимущества независимых витрин данных исчезают при первом же требовании пользователей работать с данными из нескольких витрин
В статье рассмотрены эволюция понимания места OLAP, компоненты архитектуры ХД, виртуальные ХД и независимые витрины данных. В двух следующих публикациях будут обсуждены достоинства и ограничения следующих архитектур: централизованное ХД с системой извлечения, преобразования и загрузки данных (ETL), хранилище данных с системой извлечения, загрузки и преобразования данных (ELT), ЦХД с оперативным складом данных (ОCД), расширенная модель с витринами данных (ВД), хранилище с накоплением данных в ВД, централизованная ETL с параллельными ХД И ВД и рекомендованная архитектура хранилища данных.