Введение
В течение нескольких последних лет мы наблюдаем эволюцию языков моделирования программных систем, одним из результатов которой стало появление и развитие Унифицированного Языка Моделирования - UML (Unified Modeling Language), объединившего под своим названием фактически несколько методологий. Он стал основой для целого спектра различных средств поддержки разработки программного обеспечения - CASE-средств (Computer-Aided Software Engineering).
Оставим за скобками рассуждений средства проектирования информационных структур (CA ERwin Process Modeler (BPwin) , Oracle Designer, и т.д.): просто речь у нас пойдет о конкретном классе инструментов - средствах моделирования ПО, из которых будем рассматривать только язык UML. Во-первых, это хорошо известный инструмент, и его вполне достаточно для обсуждения рассматриваемой темы, а во-вторых, другие средства подобного класса, хотя и в разной степени, имеют особенности, аналогичные рассматриваемым.
Однако, несмотря на интенсивное развитие средств моделирования, абсолютное большинство программистов либо вообще не пользуются ими, либо применяют их только тогда, когда все средства решения задачи исчерпаны (в [2] приведен хороший пример такой ситуации). И нельзя сказать, чтобы это объяснялось простой ленью: мне известно множество попыток (причем довольно грамотных специалистов) подступиться к CASE-средствам, однако почти все они заканчивались возвратом к традиционным методам.
Здесь мы будем вести речь о разработке программных средств средней и меньшей сложности, которые далее для простоты будем называть "средними". Говоря о программистах, будем иметь в виду разработчиков программных средств только указанной категории.
В чем же причина столь редкого использования CASE-средств? Виноваты ли "упрямые ретрограды" программисты, или, может быть, средства эти создают больше проблем, чем решают?
Рассмотрим в связи с этим два аспекта применения средств моделирования:
- Могут ли они использоваться так же широко, как сегодня применяются обычные визуальные системы программирования?
- Насколько они применимы в разработке "средних" программных средств?
Очевидно, что эти аспекты в значительной степени пересекаются, поэтому в дальнейшем выделять какой-либо из них нет необходимости.
Обсуждение проведем в следующей последовательности:
Вначале обсудим моменты, определяющие применимость средств моделирования в указанной области. Затем рассмотрим свойства типичного средства на примере диаграмм UML, обсудим особенности языка. Наконец, определим требования к средству моделирования для указанных областей, и предложим соответствующее им решение.
Применимость CASE-средств
В [3] утверждается, что сфера применения современных CASE-средств - "большие и сложные системы". В самом деле, сложность и стоимость CASE-средств оправдывается только в больших проектах. Следовательно, не стоит даже пытаться применять их в разработке "средних" программ. С этим утверждением можно полностью согласиться, но применительно только (!) к существующим на сегодняшний день на рынке средствам. По собственному опыту знаю: почти в каждой разработке попадается какая-нибудь "закавыка", справиться с которой "в рукопашную" (то есть, без моделирования) в принципе возможно, но только при крайнем напряжении интеллекта. Да и при разработке обычных объектов чрезвычайно полезны схемы, диаграммы, алгоритмы, и т.д., которые в основном рисуются на бумаге от руки. По сути, это - те же модели, только выполненные вручную. Поэтому, возможно, более справедливым будет утверждение, что современные CASE-системы не удовлетворяют некоторым критериям качества, существенным для сферы "средних" программных средств, в силу чего их применение здесь невозможно.
Но что же тогда остается разработчикам "средних" программных средств? Ручка и бумага? Как ни прискорбно будет заметить, но огромнейший класс специалистов оказался, что называется, "за бортом" автоматизации. Это явление представляется ненормальным, что собственно, и стало основным мотивом проделанной работы.
Возможны ли CASE-средства массового применения? Считаю, возможны на сто процентов. Более того, меня удивляет их отсутствие. В разделе реализации это мнение получит подтверждение, а сейчас в связи с этим рассмотрим следующий вопрос: почему в свое время языки высокого уровня получили широкое распространение, и, в конце концов, вытеснили низкоуровневые языки типа ассемблеров? Очевидно, потому, что имели ощутимые преимущества:
- Были основаны на сравнительно простых элементах: достаточно было изучить небольшой набор довольно простых конструкций (операторные скобки, функции, присваивание, ветвление, и т.д.), чтобы начать уверенно программировать.
- Более качественно отображали алгоритмы, структуру программы, и т.п.
- Обеспечивали существенно более высокий уровень автоматизации программирования, т.е. множество ранее ручных операций выполнялось теперь компилятором.
- Со временем перекрыли функциональные возможности языков предыдущего поколения, то есть практически не оставили для них сферы применения.
В ассемблерных языках за кажущейся простотой команд (всего-то несколько символов!) кроется неоднородная структура из кода операции (которых в ассемблере как минимум несколько десятков), набора операндов, специфичных для каждой команды, идентификация которых к тому же осложнена разнообразием методов адресации. Это является пожалуй, наиболее существенной причиной сложности программирования на ассемблере. По сравнению с языками ассемблера, элементы языков высокого уровня были намного проще в понимании и применении.
Обеспечение первых двух качеств дает право на существование и практически неограниченное распространение. Два следующих качества обеспечили вытеснение компиляторов предыдущего поколения. Однако обеспечение первого качества - простоты - стало решающим в распространении не только языков и компиляторов высокого уровня, но и самого программирования на более широкий круг специалистов, превращении его из колдовства, дела избранных, в инженерную науку. Этот фактор - фактор простоты - является фундаментальным условием успеха и в других областях массового применения: чтобы получить массовое распространение, инструментальные средства должны быть простыми для пользователя. Применительно к программированию это означает - должны базироваться на простых элементах.
Зависимость распространенности инструмента от его простоты характерна не только для программирования: пожалуй, во всех областях деятельности человека количество специалистов, владеющих инструментом, всегда примерно обратно пропорционально его сложности.
Значимость фактора простоты в программировании особенно критична в силу итеративности процесса разработки программного обеспечения, то есть необходимости неоднократных повторений, возвратов к предыдущим этапам, присущей в равной степени и большим, и малым проектам. На сегодняшний день необходимость итераций никем не отрицается, более того, настоятельно рекомендуется именно такая схема процесса разработки. Но это означает, что необходимо многократное повторное осмысление ранее разработанных конструкций. Вследствие чего, усложнение элементов представления вызывает экспоненциальный прирост трудоемкости.
Обратное утверждение собственно и составляет основную мысль данной статьи:
Упрощение инструментального средства в программировании дает экспоненциальное упрощение его использования, и придает этому средству соответственный потенциал распространения.
Рассмотрим с этой точки зрения UML как пример CASE-средства, конкретно - диаграммы состояний.
UML-диаграммы состояний
Рассмотрим наиболее характерный элемент диаграммы - состояние (Рисунок 1).
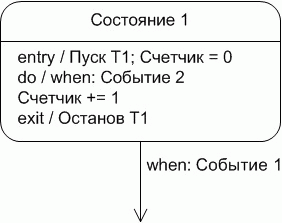
Очевидно, основной смысл элемента - нахождение объекта в этом состоянии какое-то время, и выход из него при возникновении какого-то условия (события). Фактически же, представленный на рисунке объект в этом состоянии выполняет еще что-то, по каким-то правилам. Понять это можно, только прочитав его содержимое, и зная при этом определение его внутренней структуры. Фактически имеем довольно-таки сложный элемент, нагруженный, кроме базового определения, дополнительными понятиями:
- Входное действие.
- Выходное действие.
- Действие внутреннее (деятельность).
Кроме того, в соответствии со стандартом UML, состояние может содержать:
- Вложенные состояния.
- Входные и выходные порты.
В итоге сложность понятия "состояние" получается настолько высокой, что становится сопоставимой со сложностью соответствующего ему кода.
Результаты аналогичного рассмотрения других элементов диаграммы состояний сведены в Таблицу 1.
| Элемент диаграммы состояния | Базовое понятие | Нагружен понятиями | |||
|---|---|---|---|---|---|
| Состояние | Действие | Решение | Событие | ||
| Состояние | Состояние | * | *** | ||
| Переход | Действие | * | * | * | |
| Решение | Решение | ||||
| Событие | Событие | Не имеет специального обозначения | |||
Таблица 1.
Как нетрудно заметить, основные элементы (кроме элемента "Решение") нагружены несколькими дополнительными понятиями. Между тем, все элементы и их "нагрузки", фактически являются производными от небольшого числа элементарных (базовых) понятий: Состояние, Действие, Решение, Событие.
В итоге, уже на этапе моделирования сложность создания представления посредством этих элементов сопоставима с прямым программированием. Но мы же еще только моделируем объект, а не программируем его! Получается, мы должны на разработку объекта затратить близкое к двойному количество труда. И ради чего? Ради получения более выразительного представления, которого к тому же зачастую бывает недостаточно для программирования объекта.
С другой стороны, такой существенный элемент модели, как событие (без которого модель состояний бессмысленна), не имеет самостоятельного графического обозначения. Событие распознается только по тексту, сопровождающему другой элемент (переход), что на наш взгляд, является существенным недостатком языка, создающим дополнительную сложность при моделировании диаграмм состояний.
Подобные качества элементов в разной степени присутствуют и в других диаграммах UML.
Резюмируем изложенное: элементы диаграмм UML обладают избыточной сложностью, имеются неявные элементы, и все это существенно затрудняет их изучение, восприятие, использование, а, соответственно, вносит избыточную трудоемкость в разработку программного обеспечения.
Представления UML
Еще одна особенность UML - заложенное в нем многообразие представлений. Наличие нескольких представлений в модели, конечно же, дает более разностороннее, и в итоге более качественное понимание проектируемого объекта. Однако такое суждение справедливо только в первом приближении. Рассмотрим эту особенность более внимательно с точки зрения рассматриваемой области применения.
Для начала введем некоторые термины, необходимые для понимания последующего изложения.
Разработка программных систем представляет собой некоторое количество отображений, то есть создание ряда представлений проектируемой системы на основании разработанных ранее других представлений. Например, разработка программного кода - это отображение сформулированных ранее требований к системе, либо созданных ранее диаграмм, моделей, в упорядоченное множество операторов языка программирования. При прямом программировании выполняется отображение требований к системе в программный код (Рисунок 2). В случае использования CASE-средства выполняется несколько отображений. Например, в UML выполняются такие отображения: требования - диаграммы взаимодействия, требования - диаграммы состояний, требования - структурные диаграммы, и т.д. (Рисунок 3).
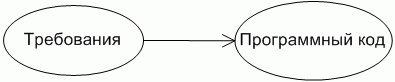
Рисунок 2.
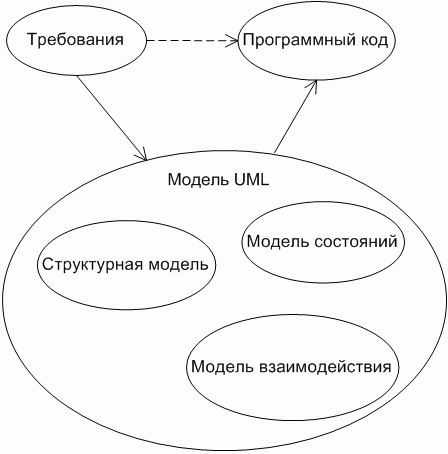
Рисунок 3.
Однако, как говорится, отображение отображению рознь: качественно они могут сильно отличаться друг от друга. Для лучшего понимания этого введем простейшую классификацию отображений:
- Трансляция - когда элементы исходного представления, в т.ч. их совокупности (или их существенная часть), имеют соответствующие аналоги в виде элементов или их совокупностей в целевом представлении.
- Преобразование - когда элементы исходного представления или их совокупности не могут быть сопоставлены с элементами или их совокупностями в целевом представлении.
При некоторой схожести этих терминов (в том смысле, что оба они означают перевод из одной системы понятий в другую), трансляция - особенно в программистской среде - хорошо ассоциируется с формализованным процессом, что и требуется в данном случае. Преобразование же ассоциируется с чем-то гораздо менее определенным. Условимся считать эти два понятия своеобразными "полюсами", противоположными сторонами спектра возможных отображений
Если в первом случае можно определить некоторые стандартные процедуры отображения, вплоть до полной формализации процесса, то во втором - таких процедур либо не существует в принципе, либо возможное их количество незначительно. Отсюда вытекает оценка трудоемкости: если преобразование требует существенных трудозатрат, причем квалифицированного персонала, то с трансляцией может справиться практически любой специалист, знающий правила этой трансляции . Выполнение преобразования является в основном искусством, в то время как трансляция - довольно рутинный набор операций, легко поддающийся автоматизации.
В реальном мире, конечно же, имеется спектр возможных характеристик, то есть отображение может быть различным по качеству - от преобразования до трансляции . Практическая полезность данной классификации состоит в том, что конкретное отображение, его трудоемкость, требуемую квалификацию персонала, мы можем качественно оценивать путем определения степени приближения его к одному из краев этого спектра.
Отсюда вытекает возможность сопоставления представлений, связываемых отображением.
Введем еще одно понятие. Будем оценивать соотношение представлений, участвующих в отображении, степенью приближения этого отображения к преобразованию, и назовем эту характеристику "ортогональность". Она может принимать значения от нуля до максимума, то есть, от стопроцентной трансляции (нулевая ортогональность) до стопроцентного преобразования (максимальная ортогональность).
Термин "ортогональность" довольно успешно применяется в литературе для обозначения степени несоответствия различных представлений (см. например, [4]). Уточнение термина и сопоставление предыдущими понятиями введено исключительно с целью более однозначного понимания дальнейших рассуждений.
Исходное и целевое представления в преобразовании можно назвать ортогональными в том смысле, что они не имеют точек сопоставления. Это означает, что конкретная реализация (диаграмма, модель), выполненная в исходном представлении, может быть отображена в несколько практически эквивалентных по качеству реализаций в целевом представлении. Причем, количество возможных эквивалентов может быть и неограниченным, поскольку зависит только от разнообразия мышления выполняющих это преобразование специалистов. Степень ортогональности двух представлений соответствует степени приближения их отображения к преобразованию .
Примером трансляции может быть компиляция программного кода в язык ассемблера: элементы исходного представления - языка программирования - имеют соответствующие аналоги (элементы, или их совокупности) в целевом представлении - языке ассемблера. Пример преобразования - разработка структуры классов, когда исходным представлением являются функциональные требования к проектируемой системе: на сегодняшний день не существует однозначного соответствия между элементами требований и элементами структуры классов.
Теперь можно сформулировать еще одну характеристику качества CASE-инструмента применительно к рассматриваемой области: в процессе разработки программных средств количество отображений типа преобразование должно быть минимальным, в идеале - отсутствовать, в то время как количество отображений типа трансляция ограничивается только практическими соображениями.
Возвращаясь к UML и с учетом вышесказанного, отметим, что многообразие представлений, кроме положительного эффекта в виде более полного представления, создает и дополнительные проблемы. С одной стороны, требуется формирование, воплощение этих представлений в модели. То есть трудоемкость моделирования умножается на их (представлений) количество. С другой стороны, создание кода по спецификациям сразу нескольких различных представлений - гораздо более трудоемкая задача, нежели прямое программирование. К тому же некоторые из этих работ требуют преобразования , что по определению является искусством, то есть, задачей значительной трудоемкости. Если еще учесть итеративность разработки, которая представляет собой множитель для всех работ по моделированию, то мы получим весьма впечатляющие значения дополнительной трудоемкости. Эти суждения вполне согласуются с оценками сложности внедрения CASE-средств, приведенными в многочисленной литературе (см. например, [3], [4]). Только причиной здесь, как мы видим, является не столько сложность проектируемой системы, сколько сложность инструмента, умноженная на специфику проектирования программных средств.
Еще одна особенность UML - то, что в нем сложно моделировать просто алгоритмы, обычные последовательности действий. Специального вида диаграмм не существует, а похожие виды (например, диаграмма активностей) обладают избыточной сложностью, и не имеют некоторых аналогов элементов алгоритмических схем. Между тем, алгоритмические схемы широко используются в разработке "средних" программных средств, поскольку обладают высокой степенью адекватности программному коду. В результате, как отмечено в [5], в анализе реально выполненных проектов, "В рассмотренных моделях операции практически не обладали семантикой состояний, поэтому 99% операций описывались автоматами без состояний, вырождаясь в императивную последовательность действий", то есть автоматы фактически использовались для отображения алгоритмов. Что свидетельствует о наличии серьезной потребности в таких средствах, степень адекватности которых алгоритмическому представлению, программному коду, была бы достаточно высокой.
Резюмируем изложенное: существенными особенностями UML, усложняющими проектирование, являются необходимость разработки нескольких представлений проектируемой системы, иногда ортогональных исходному либо целевому представлению, избыточное многообразие этих представлений, а также неполная адекватность инструмента фактическим потребностям разработчиков.
Все вышесказанное в той же мере относится и к основанным на UML CASE-средствам, поскольку они автоматически воспроизводят избыточную сложность языка.
Инструмент разработчика ПО: требования
На основании изложенного выше сформулируем требования, предъявляемые к средству моделирования "средних" программных средств:
- Количество представлений должно быть минимальным (в идеале - одно).
- В инструменте не должно быть ортогональных представлений.
- Представления должны как можно больше соответствовать программному коду.
- Элементы представлений должны быть простыми.
- В представлениях не должно быть неявных элементов.
Важно заметить, что от инструмента не следует требовать отражения всего многообразия особенностей программных систем, поскольку многие из них применительно к "средним" программным средствам являются достаточно экзотичными. Иначе опять придем к некоему подобию UML. Нас должны интересовать в основном такие свойства, которые используются программистами практически в каждом разрабатываемом модуле.
Инструмент разработчика ПО: реализация
Начнем с нескольких предварительных замечаний. Считаем, что разработка ведется в объектно-ориентированной среде. Следовательно, будем моделировать объекты, но больше обращать внимание на их алгоритмическую и поведенческую часть. Однако разработчикам, не использующим ООП, не следует переживать: инструмент может использоваться и в классическом процедурном программировании. Этот инструмент - метод "Автоматно-алгоритмических схем".
Определение состава элементов уже в значительной степени выполнено выше: колонка "Базовое понятие" Таблицы 1 содержит все необходимое: Состояние, Событие, Действие, и Решение. Именно такой состав элементов, с небольшой коррекцией, содержится и в нашем методе. Рассмотрим их подробнее.
Состояние . В излагаемом методе состояние - элемент конечно-автоматного происхождения. Оно означает, что моделируемый объект в нем "находится". Находясь в некотором состоянии, объект не выполняет никаких действий. Состояние обозначается подобно UML, в виде вытянутого по горизонтали прямоугольника с закругленными углами, выполненного жирной линией (Рисунок 4). Содержимое состояния - только его название. Ширина фигуры должна быть достаточной для размещения названия элемента. Высота - как правило, достаточная для размещения одной строки текста.
![]()
Рисунок 4.
Находясь в некотором состоянии, объект может реагировать на события посредством принадлежащих этому состоянию реакций. По сути, реакция также конечно-автоматного происхождения, но в нашем методе ее смысл несколько отличается от автоматных понятий: она является следствием наступления конкретного события. В схеме может быть несколько реакций на одно и то же событие, но одному состоянию может принадлежать только одна реакция на это событие. Имя реакции совпадает с именем инициирующего ее события, поскольку в нашем представлении они тождественны. Реакция всегда принадлежит конкретному состоянию, и является единственным возможным путем выхода объекта из него.. Она изображается квадратом со скошенными углами, выполненным жирной линией, и примыкающим непосредственно к нижней грани состояния-владельца (Рисунок 5).
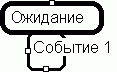
Рисунок 5.
Реакция является также отправной точкой некоторой последовательности действий - алгоритма. Все элементы алгоритма соединяются между собой направленными дугами - линиями обычной толщины со стрелками на конце. Дуги, в отличие от переходов в диаграммах состояний, не несут никакой смысловой нагрузки, кроме указания направления передачи (перемещения) действия объекта (Рисунок 6), что существенно упрощает восприятие схем. Алгоритм может ветвиться практически неограниченно, но конечными точками всех его ветвей должны быть те или иные состояния.
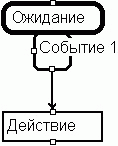
Рисунок 6.
Рассмотрим далее элемент "Действие" (Рисунок 6). Под ним понимается любой оператор действия какого-либо языка, или некоторая неразрывная последовательность действий. Это чисто алгоритмический символ, аналог символа "Процесс" по стандарту [6]. Он изображается прямоугольником с линиями обычной толщины, и с размерами, достаточными для размещения внутри него однозначного описания сути выполняемых действий. Например, описание может быть оператором присвоения, вызовом кого-либо метода, и т.д., а также может быть группой из нескольких подобных операций (Рисунок 7).

Рисунок 7.
Наконец, последний элемент нашего представления - Решение. По смыслу он аналогичен алгоритмическому символу "Решение" по [6]. Фактически это аналог операторов if - else, switch (case) в языках программирования. Он выполняется в виде ромба, усеченного сверху и снизу (Рисунок 8). Подобный вариант изображения предлагается стандартом [8], считаю его весьма удобным.
![]()
Рисунок 8.
Он имеет две формы. Первая - простое решение - аналог операторов if - else (Рисунок 9).

Рисунок 9.
Здесь дуга, выходящая из бокового угла фигуры, всегда соответствует невыполнению условия (else). Дуга, выходящая снизу, соответствует выполнению условия (if). Такое жесткое сопоставление смысла выходных дуг с пространственным расположением их выходных точек существенно упрощает чтение схем: разработчику не надо вчитываться в текст дуги, чтобы понять, куда идет алгоритм при каких-либо условиях. Кроме того, обозначения дуг становятся ненужными, а схема освобождается от избыточной информации.
Вторая форма элемента "решение" - аналог операторов switch (case) (Рисунок 10). В отличие от первой, она дополняется колонкой выбора - узким вертикальным прямоугольником из линий обычной толщины, примыкающим к середине нижней грани основной фигуры. Колонка выбора служит для размещения на ней отправных точек специальных дуг - ветвей выбора, обозначающих варианты ветвления аналогично вхождениям case оператора switch (метки ветвления оператора case).
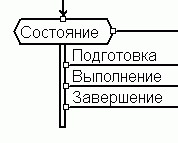
Рисунок 10.
Над первым отрезком ветви выбора указывается конкретное значение проверяемого в операторе выражения.
Такое расположение точек ветвления во многом соответствует стандарту [7]. Считаю его удобным, поскольку это напоминает структуру оператора многозначного выбора, и удобно для обозначения перечислимых типов, которые часто используются в подобных операторах.
Дуга, выходящая из бокового угла основной фигуры, всегда соответствует предложению default (otherwise, else) оператора switch (case). То есть переход по ней происходит, если не выполняется ни одно из условий ветвей выбора. Поэтому она также не нуждается в обозначении.
Несколько слов о правилах соединения элементов дугами. Основное направление развития действия - сверху вниз. Но не запрещены и другие направления, в том числе и возвраты, что позволяет отображать даже весьма сложные варианты алгоритмов. Сами дуги изображаются в виде ломаной линии с прямыми углами. При этом изгибы дуг изображаются закругленными, или виде скоса, что позволяет легко проследить каждую дугу от источника до целевого элемента (Рисунок 11). Дуги, идущие к одному элементу, могут частично совмещаться (сливаться) в одну линию, что освобождает схему от лишних линий, упрощая тем самым ее восприятие.
У каждого элемента, кроме реакции, имеется единственная входная точка в середине верхней грани фигуры. К ней подключаются все входные дуги элемента.
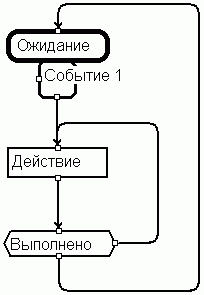
Рисунок 11.
Вот собственно, и все, что касается нотации автоматно-алгоритмических схем. Как видно, все элементы схем являются концептуально простыми, количество их минимально, правил - минимум. И при этом метод обладает весьма приличными возможностями в моделировании программных средств. Как уже было отмечено, программные блоки здесь начинаются с реакции, и заканчиваются на каком-либо состоянии. Это практически полная аналогия метода объекта в ООП, или функции в классическом программировании. В реальной модели такие блоки могут быть весьма сложными, разветвленными, причем каждая ветвь может заканчиваться на отдельном состоянии.
Вернемся к Рисунку 1, и рассмотрим его в терминах изложенного метода. Фактически, содержимое блока Состояние 1 представляет собой некоторый алгоритм, управляемый событиями. В нашей системе обозначений изображенное на Рисунке 1 состояние будет выглядеть следующим образом:
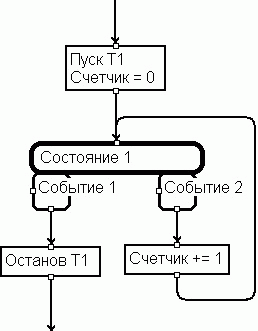
Рисунок 12.
Читатель может возразить: вместо одного элемента - шесть: где же здесь упрощение? Ответ такой:
- В схеме всего 4 типа элементов, и каждый элемент отражает однозначное, односложное, и единственное понятие. Очень легко запомнить, легко читать, анализировать схемы. Для оценки содержимого схемы нет необходимости знать внутреннюю сложность элементов, вчитываться в текст внутри них.
- Достоинством схем является органичное совмещение двух представлений: автоматного и алгоритмического (отсюда и название метода), что дает уменьшение количества отображений, являющегося мультипликативным коэффициентом в отношении трудоемкости.
- Схема является фактически моделью поведения объекта, и в этом отношении она самодостаточна. То есть для представления поведения объекта не требуется никаких дополнительных средств.
Все это существенно упрощает, делает более предсказуемым и однозначным процесс создания программного обеспечения.
В качестве примера применения схем на Рисунке 13 представлена простейшая модель буфера сообщений (очереди) между двумя объектами. Он реагирует на три события: Готовность к записи (Готов), Запись в буфер (Запись), и Передача из буфера (Передача). Первые два события генерируются источником данных, последнее - приемником данных. Реакция "Запись" содержит параметр "Вход" - входное сообщение буфера. Реакция на событие "Готов" имеет возвращаемое источнику данных значение логического типа "Возврат", которое означает возможность записи в буфер. Реакция на событие "Запись" также имеет возвращаемое значение, которое означает, что запись в буфер выполнена. Для простоты операция перемещения указателей в пределах кольцевого буфера показана в виде инкремента "++". Буфер может находиться в одном из трех состояний: Свободен, Занят, и Переполнен.
Автоматно-алгоритмические схемы в силу своей простоты могут применяться программистами даже невысокой квалификации, при разработке программных средств и систем средней и малой сложности. Особенно они эффективны при разработке объектов, модулей с нетривиальным поведением, или со сложными алгоритмами, так как в этих случаях наиболее полно "работает" эффект наглядности поведения объекта. Метод полностью соответствует сформулированным выше требованиям, и вполне может служить основой для CASE-средств если не массового, то, как минимум, достаточно широкого применения.
Заключение
Как видно из изложенного, в общем-то, здесь выполнены достаточно простые действия: по принципу скульптора - "Убрать все лишнее" - сформирован минимальный комплект простых графических элементов. В результате получен простой и эффективный инструмент для моделирования программного обеспечения. Повторюсь уже с учетом изложенного: отсутствие простых средств моделирования вызывает удивление, поскольку на данном примере очевидна относительно невысокая сложность их создания, и в то же время, существенная полезность.
Автоматно-алгоритмические схемы являются частью метода проектирования программных средств, которым я и мои коллеги пользуемся на протяжении вот уже более двух лет. За это время с его помощью разработано более десятка программных средств и приложений, в том числе - для собственных нужд - графический редактор схем для поддержки метода. В течение этого времени метод также дорабатывался, совершенствовался, и к настоящему моменту достиг уровня приличного практического инструмента. Даже в столь минимальном составе - метод + графический редактор - применение схем дает ощутимую экономию времени и усилий.
Заинтересовавшиеся могут попробовать графический редактор в действии - для этого достаточно связаться с автором по e-mail.
Все вопросы, замечания, предложения, будут с благодарностью приняты, и надлежащим образом рассмотрены.