Содержание
- Введение
- Описание проблемы
- Предлагаемое решение
- Заключение
Введение
Сегодня на многих предприятиях идет активное внедрение информационно-аналитических хранилищ данных. В результате обозначались и сформировались подходы и принципы, позволяющие оптимизировать построение систем подобного рода на платформе Oracle Database. Один из таких подходов и будет рассмотрен в статье.
Важной характеристикой хранилища данных является использование такого специализированного измерения как "Время". В абсолюном большинсве случаев значения показателей равномерно распределяются по этому измерению.
Учитывая вышеописанное свойство хранилища данных, в качестве метода для поддержки больших объмов данных информации, чаще всего применяют опцию Partitioning СУБД Oracle. При этом происходит разбиение (секционирование) больших таблиц на относительно небольшие разделы (секции). Каждая секция может храниться в отдельном табличном пространстве, что позволяет повысить управляемость, доступность и производительность системы.
Описание проблемы
К основным проблемным местам хранилища относят следующие:
- Постоянно растущий объем данных по мере эксплуатации системы, и как следствие, высокие требования к объему дискового пространства;
- Трудно прогнозируемое время выполнения запросов, и длительное время их выполнения, как следствие, большая нагрузка на дисковую подсистему.
Предлагаемое решение
Для "борьбы" со вышеперечисленными недостатками хранилищ данных предлагается разбивать факторные таблицы на секции и периодически сжимать архивные секции. Необходимо отметить, что в хранилищах данных основной объем информации приходится именно на факторные таблицы.
Далее будет рассмотрен законченный пример с помощью которого можно будет реально оценить эффективность предлагаемого подхода.
На схеме приведена структура факторной таблицы sample, которая содержит данные по продажам.

Рис.1 Структура факторной таблицы "Sample"
Данные по продажам формируются по четырем аналитикам: - "Время", "Продукт", "Клиент", "Отдел продаж". Минимальный уровень по измерению "Время" - год. Данные факторной таблицы можно разбить на логические диапазоны по годам. Т.е. в каждой секции таблицы sample будут содержаться данные за определенный год. Наибольшая производительность при работе с секционированными таблицами достигается при равномерном распределении данных по секциям. На схеме представлена таблица sample, секционированная по годам. Каждый раздел хранится в отдельном табличном пространстве. Секция year_current является загрузочной, то есть в текущий период времени (на рисунке - за 2007 год) данные из информационных источников поступают только в эту секцию; в остальных секциях хранятся архивные данные.
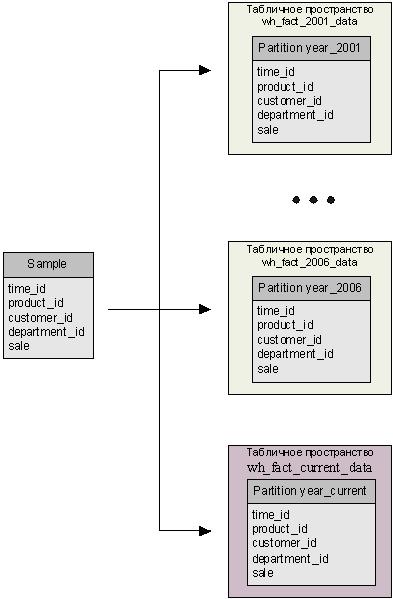
Рис.2 Секционирование факторной таблицы "Sample"
Перед созданием таблицы необходимо сформировать табличные пространства для ее секций.
Пример:
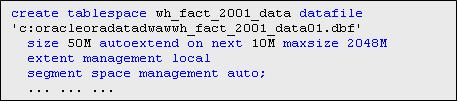
В прилагаемом файле приведен полный cкрипт по созданию табличных пространств.
Далее создаем факторную таблицу sample.
Пример:
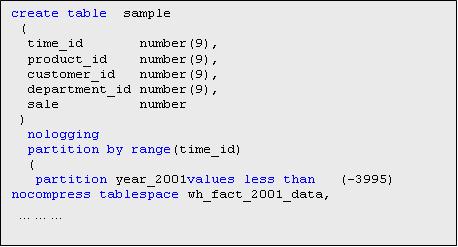
В целях эксперимента, индексы на столбцы таблицы отсутствуют.
Законченный скрипт создания факторной таблицы приведен в файле.
Следующим шагом заполняем факторную таблицу sample случайными значениями.
Приведенный ниже код служит лишь для заполнения данных в таблицу Sales; в реальной производственной системе загрузка данных будет происходить с помощью специализированных ETL-процедур.
Код для загрузки данных в факторную таблицу:

Законченный скрипт приведен в файле по следующей ссылке.
Далее проверяем: какое количество записей содержится в секции year_current.
Итак, сейчас в таблице samples содержится 20 миллионов записей.
После вставки записей собираем статистику для таблицы sample. Для этого необходимо вызвать процедуру GATHER_TABLE_STATS из пакета DBMS_STATS.
Код для сбора статистики:

Скрипт сбора статистики приведен в файле по следующей ссылке.
Повторно запускаем sql-запрос на подсчет количества записей в секции year_current и sql-запрос на поиск записи с кодом клиента для полного сканирования всей таблицы и анализируем время выполнения этих запросов.

Скрипты представлены в файле.
Время выполнения запроса А - 7,77 секунд (время сканирования секции year_current), время выполнения запроса B - 21,20 секунд (время полного сканирования таблицы).
Следующим шагом, с помощью оператора split partition секцию year_current разбиваем на две - на секцию year_2007, куда относятся значения показателя для 2007 года, и на секцию year_current, готовую для следующей порции загружаемых данных. Предварительно создаем табличное пространство для данных 2007 года.
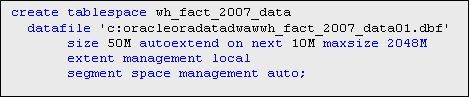
Скрипт по созданию табличного пространства приведен в файле.
Расщепляем партицию year_current на две, использую диапазон значений поля time_id, принадлежащих 2007 году.
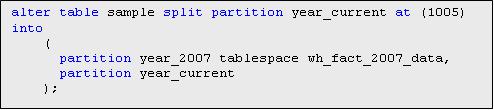
Скрипт приведен в файле.
Следующим шагом иследования будет сжатие (compress) вновь полуенной архивной секции (в нашем случае - year_2007) и выяснение: насколько это повысит быстродействие системы. Выясняем: сколько места на диске занимает секция year_2007, - для этого используем представление dba_segments.
Размер секции year_2007 составляет 464 Мб.
Далее, с помощью оператора, move partition производим сжатие секции year_2007.

Повторно выясняем размер секции year_2007. Теперь, после сжатия, размер секции year_2007 составляет 240 МБ. Таким образом, коэффициент сжатия равен 1,93.
После того, как поступит уведомление о том, что данные 2007 года больше модифицироваться не будут (т.е. этот период в учетных системах закрыт), для ускорения времени выполнения запросов на чтение, и контроля на изменение данных, переведем табличное пространство wh_fact_2007_data в режим "только для чтения" (read only).
Проверяем как изменилось время выполнения тестовых запросов (файл).
Время выполнения запроса А - 3,11 секунд, время выполнения запроса B - 9,06 секунд.
Время выполнения запросов существенно сократилось - примерно в 2,5 раза!
Далее выполняем команду на уменьшение файла данных вновь полученного табличного пространства с архивными данными.
Заключение
Были получены следующие положительные результаты:
- Достаточно большой коэффициент сжатия секции, что позволяетт уменьшить размер табличного пространства;
- Увеличение скорости выполнения запросов;
- Контроль на DML-операции после завершения формирования загрузки.
Законченные скрипты, использованные в статье, можно загрузить по следующей ссылке.
- Подробнее о продуктах компании Oracle
- Приобрести продукты Oracle в ITShop.ru
- Обратиться в "Интерфейс" за дополнительной информацией / по вопросу приобретения