 Высоконагруженные сайты, доступность "5 nines". На заднем фоне (backend) куча обрабатываемой информации в базе данных. А что, если железо забарахлит, если вылетит какая-то давно не проявлявшаяся ошибка в ОС, упадет сетевой интерфейс? Что будет с доступностью информации? Из чистого любопытства я решил рассмотреть, какие решения вышеперечисленным проблемам предлагает Oracle. Последние версии, в отличие от Oracle 9i, называются Oracle 10g (или 11g), где g - означает "grid", распределенные вычисления. В основе распределенных вычислений "как ни крути" лежат кластера, и дополнительные технологии репликации данных (DataGuard, Streams). В этой статье в общих чертах описано, как устроен кластер на базе Oracle 10g. Называется он Real Application Cluster (RAC).
Высоконагруженные сайты, доступность "5 nines". На заднем фоне (backend) куча обрабатываемой информации в базе данных. А что, если железо забарахлит, если вылетит какая-то давно не проявлявшаяся ошибка в ОС, упадет сетевой интерфейс? Что будет с доступностью информации? Из чистого любопытства я решил рассмотреть, какие решения вышеперечисленным проблемам предлагает Oracle. Последние версии, в отличие от Oracle 9i, называются Oracle 10g (или 11g), где g - означает "grid", распределенные вычисления. В основе распределенных вычислений "как ни крути" лежат кластера, и дополнительные технологии репликации данных (DataGuard, Streams). В этой статье в общих чертах описано, как устроен кластер на базе Oracle 10g. Называется он Real Application Cluster (RAC).
Статья не претендует на полноту и всеобъемлемость, также в ней исключены настройки (дабы не увеличивать в объеме). Смысл - просто дать представление о технологии RAC.
Статью хотелось написать как можно доступнее, чтобы прочесть ее было интересно даже человеку, мало знакомому с СУБД Oracle. Поэтому рискну начать описание с аспектов наиболее часто встречаемой конфигурации БД - single-instance, когда на одном физическом сервере располагается одна база данных (RDBMS) Oracle. Это не имеет непосредственного отношения к кластеру, но основные требования и принципы работы будут одинаковы.
Введение. Single-instance.
Наиболее распространенная база данных, установленная на одном физическом сервере, называется single-instance. Я раньше не предавал особого значения разнице понятий между: экземпляр (instance) базы данных и самой базы данных (в целом). Теперь же хочу особенно отметить, что под экземпляром подразумевается ПО (процессы, потоки, сервисы) которое располагается в оперативной памяти и обрабатывает данные (сортировка, буферизация, обслуживание) полученные непосредственно с диска. Таким образом, под базой данных подразумевается совокупность:
- область хранения данных, т.е. физические файлы на диске (datastorage) (сама БД)
- экземпляр БД (получающая и обрабатывающая эти данные в оперативной памяти) (СУБД)
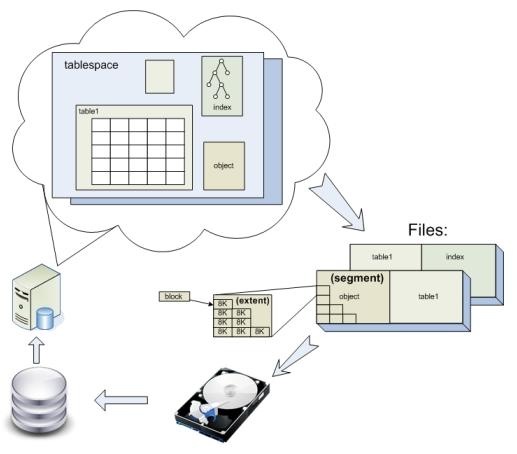
Во всех современных реляционных БД данные хранятся в таблицах. Таблицы, индексы и другие объекты в Oracle хранятся в логических контейнерах - табличных пространствах (tablespace). Физически же tablespace располагаются в одном или нескольких файлах на диске. Хранятся они следующим образом:
Каждый объект БД (таблицы, индексы, сегменты отката и.т.п.) хранится в отдельном сегменте - области диска, которая может занимать пространство в одном или нескольких файлах. Сегменты в свою очередь, состоят из одного или нескольких экстентов. Экстент - это непрерывный фрагмента пространства в файле. Экстенты состоят из блоков. Блок - наименьшая единица выделения пространства в Oracle, по умолчанию равная 8K. В блоках хранятся строки данных, индексов или промежуточные результаты блокировок. Именно блоками сервер Oracle обычно выполняет чтение и запись на диск. Блоки имеют адрес, так называемый DBA (Database Block Address).
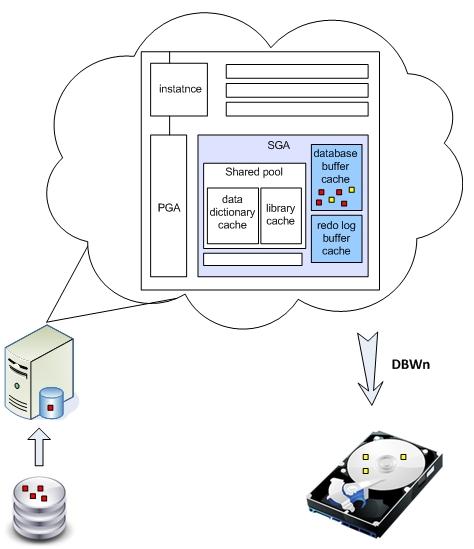
При любом обращении DML (Data Manipulation Language) к базе данных, Oracle подгружает соответствующие блоки с диска в оперативную память, а именно в буферный кэш. Хотя возможно, что они уже там присутствуют, и тогда к диску обращаться не нужно. Если запрос изменял данные (update, insert, delete), то изменения блоков происходят непосредственно в буферном кэше, и они помечаются как dirty (грязные). Но блоки не сразу сбрасываются на диск. Ведь диск - самое узкое место любой базы данных, поэтому Oracle старается как можно меньше к нему обращаться. Грязные блоки будут сброшены на диск автоматически фоновым процессом DBWn при прохождении контрольной точки (checkpoint) или при переключении журнала.
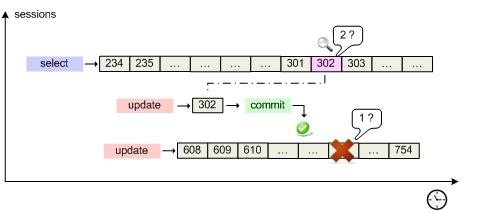
Предположим, что была запущена одна длительная транзакция, считывающая данные, и где-то в процессе ее выполнения запустилась другая транзакция с намерением изменить один из считываемых блоков. Как сервер скоординирует работу этих запросов? На самом деле, вопрос разделяется на два:
- Что будет, если Oracle упадет где-то на середине длинной транзакции (если бы она вносила изменения)?
- Какие же данные прочтет первая транзакция, когда в кэше у нее "под носом" другая транзакция изменила блок?
Для ответа на эти вопросы рассмотрим механизм обеспечения согласованного чтения CR (consistency read). Все дело в волшебных пузырьках журналах транзакций, которые в Oracle представлены двумя типами:
- журнал повтора (redo log)
- сегмент отмены (undo)
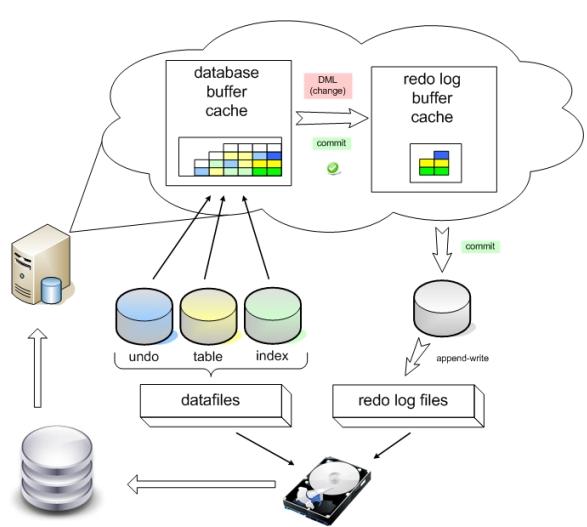
Когда в базу данных поступает запрос на изменение, то Oracle применяет его в буферном кэше, параллельно внося информацию, достаточную для повторения этого действия, в буфер повторного изменения (redo log buffer), находящийся в оперативной памяти. Как только транзакция завершается, происходит ее подтверждение (commit), и сервер сбрасывает содержимое redo buffer log на диск в redo log в режиме append-write и фиксирует транзакцию. Такой подход гораздо менее затратен, чем запись на диск непосредственно измененного блока. При сбое сервера кэш и все изменения в нем потеряются, но файлы redo log останутся. При включении Oracle начнет с того, что заглянет в них и повторно выполнит изменения таблиц (транзакции), которые не были отражены в datafiles. Это называется "накатить" изменения из redo, roll-forward. Online redo log сбрасывается на диск (LGWR) при подтверждении транзакции, при прохождении checkpoint или каждые 3 секунды (default).
С undo немного посложнее. С каждой таблицей в соседнем сегменте хранится ассоциированный с ней сегмент отмены. При запросе DML вместе с блоками таблицы обязательно подгружаются данные из сегмента отката и хранятся также в буферном кэше. Когда данные в таблице изменяются в кэше, в кэше так же происходит изменение данных undo, туда вносятся "противодействия". То есть, если в таблицу был внесен insert, то в сегмент отката вносится delete, delete - insert, update - вносится предыдущее значение строки. Блоки (и соответствующие данные undo) помечаются как грязные и переходят в redo log buffer. Да-да, в redo журнал записываются не только инструкции, какие изменения стоит внести (redo), но и какие у них противодействия (undo). Так как LGWR сбрасывает redo log buffer каждые 3 секунды, то при неудачном выполнении длительной транзакции (на пару минут), когда после минуты сервер упал, в redo будут записи не завершенные commit. Oracle, как проснется, накатит их (roll-forward), и по восстановленным (из redo log) в памяти сегментам отката данных отменит (roll-back) все незафиксированные транзакции. Справедливость восстановлена.
Кратко стоит упомянуть еще одно неоспоримое преимущество undo сегмента. По второму сценарию (из схемы) когда select дойдет до чтения блока (DBA) 500, он вдруг обнаружит что этот блок в кэше уже был изменен (пометка грязный), и поэтому обратится к сегменту отката, для того чтобы получить соответствующее предыдущее состояние блока. Если такого предыдущего состояния (flashback) в кэше не присутствовало, он прочитает его с диска, и продолжит выполнение select. Таким образом, даже при длительном "select count(money) from bookkeeping" дебет с кредитом сойдется. Согласованно по чтению (CR).
Отвлеклись. Пора искать подступы к кластерной конфигурации. =)
Уровень доступа к данным. ASM.
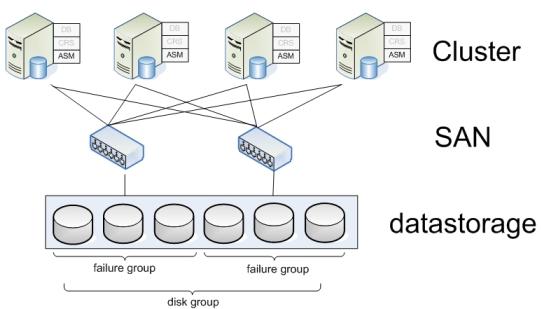
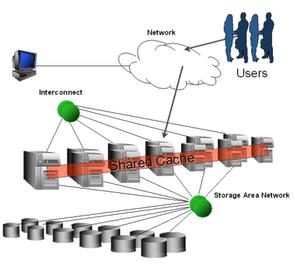
Хранилищем (datastorage) в больших БД почти всегда выступает SAN (Storage Area Network), который предоставляет прозрачный интерфейс серверам к дисковым массивам.
Сторонние производители (Hitachi, HP, Sun, Veritas) предлагают комплексные решения по организации таких SAN на базе ряда протоколов (самым распространенным является Fibre Channel), с дополнительными функциональными возможностями: зеркалирование, распределение нагрузки, подключение дисков на лету, распределение пространства между разделами и.т.п.
Позиция корпорации Oracle в вопросе построения базы данных любого масштаба сводится к тому, что Вам нужно только соответствующее ПО от Oracle (с соответствующими лицензиями), а выбранное оборудование - по возможности (если средства останутся после покупки Oracle :). Таким образом, для построения высоконагруженной БД можно обойтись без дорогостоящих SPARC серверов и фаршированных SAN, используя сервера на бесплатном Linux и дешевые RAID-массивы.
На уровне доступа к данным и дискам Oracle предлагает свое решение - ASM (Automatic Storage Management). Это отдельно устанавливаемый на каждый узел кластера мини-экземпляр Oracle (INSTANCE_TYPE = ASM), предоставляющий сервисы работы с дисками.
Oracle старается избегать обращений к диску, т.к. это является, пожалуй, основным bottleneck любой БД. Oracle выполняет функции кэширования данных, но ведь и файловые системы так же буферизуют запись на диск. А зачем дважды буферизировать данные? Причем, если Oracle подтвердил транзакцию и получил уведомления том, что изменения в файлы внесены, желательно, чтобы они уже находились там, а не в кэше, на случай "падения" БД. Поэтому рекомендуется использовать RAW devices (диски без файловой системы), что делает ASM.
ASM работает поверх RAW device, его преимуществами являются:
- отсутствие необходимости в отдельном ПО для управления разделами дисков
- нет необходимости в файловой системе
Disk group - объединение нескольких дисков. При записи файлов на диски данные записываются экстентами размерами по 1 МБ, распределяя их по всем дискам в группе. Это делается для того, чтобы обеспечить высокую доступность, ведь части одной таблицы (из tablespace) разбросаны по разным физическим дискам.
Способности ASM:
- Зеркалирование данных:
как правило, 2-х или 3-х ступенчатое, т.е. данные одновременно записываются на 2 или 3 диска. Для зеркалирования диску указываются не более 8 дисков-партнеров, на которые будут распределяться копии данных. - Автоматическая балансировка нагрузки на диски (обеспечение высокой доступности):
если данные tablespace разместить на 10 дисках и, в некоторый момент времени, чтение данных из определенных дисков будет "зашкаливать", ASM сам обратится к таким же экстентам, но находящимся на зеркалированных дисках. - Автоматическая ребалансировка:
При удалении диска, ASM на лету продублирует экстенты, которые он содержал, на другие оставшиеся в группе диски. При добавлении в группу диска, переместит экстенты в группе так, что на каждом диске окажется приблизительно равное число экстентов.
Предположим, что несколько дисков подключены к определенному контроллеру- и, таким образом, представляют собой, SPF - single point of failure (При выходе из строя контроллера теряем весь дисковый массив). У ASM есть технология определения Failure Groups внутри Disk Group. При этом механизме зеркалирование будет раскидывать копии экстентов по дискам, находящимся в различных failure groups, чтобы избежать SPF (Single Point of Failure), например, при смерти SAN или RAID контроллера.
Таким образом, кластер теперь может хранить и читать данные с общего файлового хранилища.
Пора на уровень повыше.
Clusterware. CRS.
На данном уровне необходимо обеспечить координацию и совместную работу узлов кластера, т.е. clusterware слой: где-то между самим экземпляром базы данных и дисковым хранилищем:
CRS (Cluster-Ready Services) - набор сервисов, обеспечивающий совместную работу узлов, отказоустойчивость, высокую доступность системы, восстановление системы после сбоя. CRS выглядит как "мини-экземпляр" БД (ПО) устанавливаемый на каждый узел кластера. Устанавливать CRS - в обязательном порядке для построения Oracle RAC. Кроме того, CRS можно интегрировать с решениями clusterware от сторонних производителей, таких как HP или Sun.
Опять немного "терминологии"…
CRS состоит из 3-х основных компонент:
- CSSD - Cluster Synchronization Service Daemon
- CRSD - Cluster Ready Services Daemon
- EVMD - Event Monitor Daemon
| x | Назначение (вкратце) | С какими правами работает | При смерти процесса, перезагружается: |
| CSSD | Механизм синхронизации для взаимодействия узлов в кластерной среде. | user | процесс |
| CRSD | Основной "движок" для поддержки доступности ресурсов | root | хост |
| EVMD | Процесс оповещения о событиях, происходящих в кластере | user | процесс |
Как уже стало ясно из таблички, самым главным процессом, "самым могущественным демоном", является CRSD (Cluster Ready Services Daemon). В его обязанности входит: запуск, остановка узла, генерация failure logs, реконфигурация кластера в случае падения узла, он также отвечает за восстановление после сбоев и поддержку файла профилей OCR. Если демон падает, то узел целиком перезагружается. CRS управляет ресурсами OCR: Global Service Daemon (GSD), ONS Daemon, Virtual Internet Protocol (VIP), listeners, databases, instances, and services.
В обязанности сервиса CSSD (Cluster Synchronization Service Daemon) входит координация взаимодействия узлов кластера, синхронизация узлов и ресурсов между ними, определение их доступности через следующие функции:
- Node Membership (NM).Каждую секунду проверяет heartbeat между узлами. NM также показывает остальным узлам, что он имеет доступ к так называемому voting disk (если их несколько, то хотя бы к большинству), делая регулярно туда записи. Если узел не отвечает на heartbeat или не оставляет запись на voting disk в течение нескольких секунд (10 для Linux, 12 для Solaris), то master узел исключает его из кластера.
- Group Membership (GM). Функция отвечает за своевременное оповещение при добавлении / удалении / выпадении узла из кластера, для последующей реконфигурации кластера.
CSSD предоставляет динамическую информацию о узлах и экземплярах, которые являются частью его на текущий момент, и отвечает за блокировки ресурсов в кластере.
Информатором в кластере выступает EVMD (Event Manager Daemon), который оповещает узлы о событиях: о том, что узел запущен, потерял связь, восстанавливается. Он выступает связующим звеном между CRSD и CSSD. Оповещения также направляются в ONS (Oracle Notification Services), универсальный шлюз Oracle, через который оповещения можно рассылать, например, в виде SMS или e-mail.
Стартует кластер примерно по следующей схеме: CSSD читает из общего хранилища OCR, откуда считывает кластерную конфигурацию, чтобы опознать, где расположен voting disk, читает voting disk, чтобы узнать сколько узлов (поднялось) в кластере и их имена, устанавливает соединения с соседними узлами по протоколу IPC. Обмениваясь heartbeat, проверяет, все ли соседние узлы поднялись, и выясняет, кто в текущей конфигурации определился как master. Ведущим (master) узлом становится первый запустившийся узел. После старта, все запущенные узлы регистрируются у master, и впоследствии будут предоставлять ему информацию о своих ресурсах.
Уровнем выше CRS на узлах установлены экземпляры базы данных.
Друг с другом узлы общаются по private сети - Cluster Interconnect, по протоколу IPC (Interprocess Communication). К ней предъявляются требования: высокая ширина пропускной способности и малые задержки. Она может строиться на основе высокоскоростных версий Ethernet, решений сторонних поставщиков (HP, Veritas, Sun), или же набирающего популярность InfiniBand. Последний кроме высокой пропускной способности пишет и читает непосредственно из буфера приложения, без необходимости в осуществлении вызовов уровня ядра. Поверх IP Oracle рекомендует использовать UDP для Linux, и TCP для среды Windows. Также при передаче пакетов по interconnect Oracle рекомендует укладываться в рамки 6-15 ms для задержек.