[От гл.редактора OM/RE А.Бачина: Публикация этой статьи имеет некую предысторию, которую я вкраце хочу поведать нашим читателям.
В журнале Oracle Magazine (весна 1995) Кери Миллсап (Cary Millsap), Грег Шаллхамер (Craig Shallahamer) и Миша Адлер (Micah Adler) опубликовали в статью "Predicting the Utility of the Nonunique Index." [Millsap и Al 1993] ("Когда использовать неуникальный индекс"). Эта статья была переведена на русский язык и опубликована в нашем журнале "Мир Oracle", который выходил еще в бумажном издании. Интернета в нашей стране еще не было (верится с трудом, но чистая правда!), поэтому статья сохранилась лишь в архивах и памяти многих наших читателей, как прекрасный источник правильного подхода к использованию индексов. Все последние годы мне хотелось заново перевести и переопубликовать эту статью, чтобы разработчики и АБД нового поколения познакомились с правильным подходом к этой проблеме. Но когда дело дошло до дела, оказалось, что ни у кого из доступных адресатов не сохранился английский вариант этой статьи. Даже у самого автора, Кери Миллсап. Когда я к нему обратился, он посоветовал перевести и опубликовать новый ее вариант, в котором грустно отметил [4] возможное невнимание к первоначальному тексту. Я постарался его в этом разуверить, послал ему scan-копию статьи и обложки журнала... Он был нам благодарен и разрешил переводить и публиковать статьи с сайта компании Hotsos Enterprises, чем мы, естестенно, с благодарностью еще не раз воспользуемся. Спасибо, Кери!]
===***===***===***===
[От редакции OM/RE: На сайте корпорации Oracle появилась Oracle ACE ( http://www.oracle.com/technology/community/oracle_ace/index.html) - "Аллея славы", то есть галерея наиболее прославленных Oracle-авторов,среди которых заслуженное место занимает автор данной статьи Cary Millsap. Из этой "Аллеи славы" взята публикуемая здесь фотография автора статьи.]

Резюме
Когда следует использовать индекс? Более десяти лет разработчики приложений Oracle использовали простое rule of thumb (правило большого пальца) - эмпирическое правило для приближенных расчётов, чтобы решить, использовать ли неуникальный индекс (non-unique index). Однако, в повседневной работе мы не редко сталкиваемся с проблемами производительности, вызванными использованием этого эмпирического правила. В этой статье я излагаю следующие результаты наших исследований:
- Правило большого пальца ненадежно, если можно получить процентный баланс селективности строк, чтобы определить, действительно ли нужно создавать индекс.
- Индекс может существенно улучшать эффективность запросов к таблице даже только с одной строкой (a one-row table).
- Доминирующим фактором вашего решения, следует ли создать индекс, должна быть селективность блоков, а не селективность строк.
- Вы можете определить селективность блоков, задавая фразу where, используя SQL-запрос, приведенный в этой статье.
- Значения столбцов обычно кластеризированы (сгруппированы) или естественным образом (naturally clustered), или унифицировано (naturally uniform), то есть единообразно. Вы можете использовать эти сведения, чтобы выработать более правильное решение, действительно ли надо создавать индекс.
- Много новых возможностей Oracle упрощают способность хранить данные в физическом порядке, что обеспечивает превосходную производительность.

Когда использовать индекс: Традиционный Совет
В одном или каком-либо другом виде, но стандартная рекомендация, надо ли использовать индекс, по крайней мере, начиная с версии Oracle 5, звучала следующим образом:
Используйте индекс, когда запрос возвращает менее чем x% строк таблицы.
Рисунок 1 иллюстрирует понятие, когда некий порог в x% действует как точка баланса производительности Oracle в сравнении диапазонного сканирования индекса и полного сканирования таблицы, осуществляемого по путям доступа. Этот график связывает время ответа R (обычно выражаемое в секундах) в пропорции к Pr строк таблицы, которые возвращаются за данную операцию запроса.
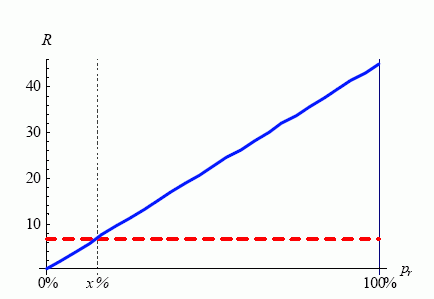
Рисунок 1. Время ответа R в секундах как процентная функция Pr возвращаемых строк таблицы. Пунктирная линия при R = 6.75 (красная линия, если вы видите это в цвете) является временем ответа при полном просмотре таблицы. Непрерывная (синяя) линия - время ответа диапазонного сканирования индекса, который возвращает Pr процентов строк данной таблицы.
Время ответа при плане выполнения, возвращающего r строк при полном просмотре таблицы, является примерно постоянным, независимо от того, r - это одна строка или общее количество строк в таблице. Однако, время ответа диапазонного сканирования индекса увеличивается по мере того, как нарастает объем результирующих исходных строк [1]. Процент pr = x - пороговое значение pr, когда время ответа полного просмотра таблицы и диапазонного сканирования индекса сравниваются. При значении pr < x диапазонное сканирование индекса имеет лучшую производительность. При значении pr > x лучшую производительность предоставляет полный просмотр таблицы.
Тем не менее, в этой линии рассуждения имеется большая проблема. Любое правило типа большого пальца в отношении индексов ненадежно, если существует балансовый процент типа x.

Почему правило большого пальца ненадежно
Правило большого пальца звучит примерно так: "Используйте индекс, когда запрос возвращает меньше чем x процентов от общего числа строк таблицы". Оно основано на следующих позициях:
- Если операция запроса, охватывающего весь источник строк, в результате выводит только одну строку, то диапазонное сканирование индекса более эффективно, чем полный просмотр таблицы.
- Если операция запроса, охватывающего весь источник строк, в результате выводит все строки таблицы, то полный просмотр таблицы более эффективен, чем диапазонное сканирование индекса.
- Поэтому должен существовать некий балансовый порог от полного числа строк в таблице, при котором стоимость получения исходных строк посредством диапазонного сканирования индекса эквивалентна получению исходных строк посредством полного просмотра таблицы. Для запроса, возвращающего меньшее количество строк, чем пороговое значение, диапазонное сканирование индекса более эффективно. Для запросов, возвращающих большее количество строк, чем пороговое значение, более эффективен полный просмотр таблицы.
Наши испытания и практический опыт показали, что позиция 1) является истинной даже для очень маленьких таблиц. Запрос, возвращающий одну строку, более эффективен, когда выполняется с использованием индекса, чем посредством полного просмотра таблицы, даже если таблица содержит только одну строку. Много людей, с которыми мы обсудили это, выразили удивление таким результатом. Этот результат также противоречит вполне конкретной рекомендации Oracle: "малые таблицы не требуют индексов" [Oracle 2001a]. Малые таблицы могут не требовать наличия индексов, но индексы на малых таблицах могут сделать вашу систему значительно более эффективной и, следовательно, значительно более масштабируемой [2].
Итак, мы принимаем позицию 1), но на позиции 2) начинаются большие проблемы. Иногда намного дешевле прочитать 100 % строк таблицы, используя индекс, чем при полном сканировании таблицы.
Пример: Представим таблицу с именем interface, которая занимает (high-water mark - высшая отметка использования пространства) 10,000 блоков. Хотя в своем историческом прошлом таблица interface содержала сотни тысяч строк, сегодня таблица включает только 100 строк. Эти строки произвольно рассеяны по 30 блокам таблицы. Предположим, что таблица имеет первичный ключ на столбце с названием id, на котором, конечно, построен индекс (с именем id_u1). И далее нам надо выполнить следующий запрос:
select id, date, status from interface i ;
Если этот запрос выполнять посредством полного просмотра таблицы, то потребуется 10,000 LIO-вызовов Oracle. Мы можем слегка переделать этот запрос, чтобы позволить Oracle выполнять его, используя индекс. Если id - числовой столбец и все значения id - неотрицательные целые числа, то следующий запрос выводит желательный набор строк посредством индекса:
select /*+ index(i id_u1) */ id, date, status from interface i where id> -1 ;
Этот запрос потребует менее 40 LIO-вызовов Oracle. Время ответа составит примерно 10,000/40, то есть в 250 раз лучше при использовании индекса, чем при выборке 100 % строк из таблицы посредством полного ее просмотра.
Существует много разных крючков и загогулин (all sorts of hooks and crooks), которые можно исследовать на этом примере. Например, если бы фраза select содержала только id или count(id) (что может быть получено из информации индекса даже без обращения к сегменту данных), то просмотр по индексу был бы еще быстрее.
Итак, чтобы быть применимым в случаях подобных этому, эмпирическое правило (большого пальца) для любого процента проиндексированных строк должно допускать возможность, что использование индекса может быть более эффективно, чем полный просмотр таблицы даже для тех запросов, которые возвращают все 100 % строк таблицы. На рисунке 2 показан этот феномен.
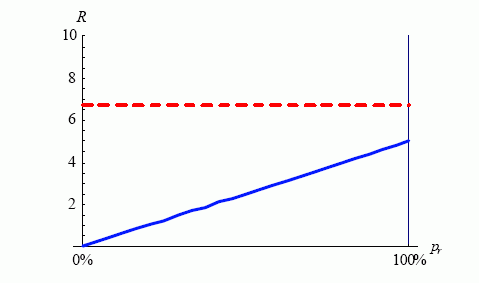
Рисунок 2. Эта схема отражает ситуацию, когда таблица содержит большое количество пустых блоков. Диапазонное сканирование индекса (синяя сплошная линия) быстрее, чем полный просмотр таблицы (красная пунктирная линия), даже для запроса, возвращающего 100% строк таблицы.
Существует много случаев, когда основанные на процентах эмпирические правила являются ненадежными. Имеется также большая проблема, связанная с высказанным ранее постулатом 3). Эта проблема еще покажет себя в ходе дальнейшего изложения.

Неравномерно эволюционирующий признак x
Упомянутая большая проблема эмпирического правила индексации состоит в том, что нет четкой ясности, какое значение x должно использовать. Если проследить историю рекомендаций для x в документации Oracle, то вы найдете следующее: [3]
|
Версия Oracle |
Рекомендуемое значение x по документации Oracle |
|
5 6 7 8 8i 9i |
10-15 10-15 2-4 2-4 15 15 |
Положение даже хуже, чем показано в таблице. Если память мне не изменяет, ранний выпуск производственной документации Oracle7 содержал рекомендацию для x как "1-15 процентов". Я был потрясен тем, насколько широк был диапазон. Если же углубиться в этот вопрос, некоторые из моих друзей из Oracle Applications development очень убедительно говорили, что в своих приложениях они часто наблюдали значение x более 40.
Многие люди полагают, что причина, по которой качается (wiggling) x, состоит в том, что Oracle продолжает совершенствовать работу оптимизатора (optimizer). Но это не всеобщая действительная причина. Причина же того, что значение x стал таким движущимся объектом (moving target), в том, что авторы рекомендаций не сумели выявить истинные параметры, которые дают сбалансированное значение.
Критический параметр - это число блоков Oracle ниже высшей точки заполнения (high-water mark) таблицы, которую можно игнорировать при использовании индекса [4]. Путь построения правила создания индекса, которое превзойдет эмпирическое правило большого пальца и которое сделает жизнь более легкой, должен включать вопрос: "Какой план выполнения потребует меньшее число блоков Oracle, которые должны быть просмотрены? "
Для любого источника строк, с более чем одной строкой, индекс во много раз позволяет Вам сократить PIO-вызовы. Число PIO-вызовов для блоков данных, которое игнорируется при задействовании индекса, зависит от следующего:
- Сколько блоков ниже high-water mark таблицы содержат по крайней мере по одной строке, которая удовлетворяла бы фразе where вашего запроса? Если "интересующие" вас строки распределены однородно по всей таблице, то можно выяснить, когда использование индекса неэффективно даже при невероятно "хороших" значениях селективности строк.
Пример: Мы желаем оптимизировать следующий запрос:
select id, date from shipment where flag="x"
- Загруженная таблица shipment содержит 1,000,000 строк, хранимых в 10,000 блоках Oracle. Только 10,000 строк соответствуют критерию flag="x". Поэтому селективность строк на столбце flag со значением x очень "хорошая" - 1 %. Однако, физическое распределение строк в shipment такова, что каждый отдельный блок в таблице содержит ровно одну строку, для который flag="x" . Следовательно, используем ли мы индекс на столбце flag или нет, чтобы удовлетворить этот запрос, мы должны просмотреть все блоки таблицы. Поэтому полный просмотр таблицы будет более эффективен, чем диапазонное сканирование индекса даже при том, что запрос возвращает только 1% строк из таблицы.
- Может ли Oracle выполнять требования фразы select запроса, используя исключительно данные, хранящиеся в индексе? Если да, то индекс может вообще устранить потребность обращения к таблице. Столбцы в индексе - это обычно небольшой поднабор столбцов индексированной таблицы. Следовательно, число листовых блоков в индексе обычно намного меньше, чем число блоков ниже high-water mark в соответствующей таблице. Поэтому сканирование даже всего индекса может быть дешевле, чем просмотр диапазона блоков в таблице.

Притча об индексаторах
Давайте раскроем важность концепции, называемой селективностью блоков с помощью истории. Речь пойдет о …
- Представим себе книгу с названием Brief History of Humanity (Краткая История Человечества), резюме на 1,000 страницах фактически обо всем, что наша порода сделала, с тех пор как мы обрели способность все это выражать словами. Представим, что из этой большой книги вы заинтересовались сведениями об Александре Великом. Как вы будете искать их? Конечно, через индекс книги.
- Индекс точно сообщит вам, на каких страницах находится информацию об Александре Великом. Вы, вероятно, отметите индекс, а затем пойдете поиском прямого доступа по номеру страницы с "Александр". Когда вы обработаете одну секцию, то вернетесь назад к отмеченной странице индекса, чтобы узнать, куда нужно далее обратиться, чтобы найти дальнейшие сведения. Наконец, вы сделаете еще один заход в индекс, чтобы удостовериться, что истощен список номеров страниц, которые содержат интересующую вас информацию.
- Теперь представьте себе, что в отличие от обычных книг, каждое отдельное слово этой книги находится в индексе. В индексе такой книги вы сможете найти местоположения даже таких слов, как "the" ("<определенный артикль>"). Теперь давайте скажем, что в Brief History of Humanity нас интересует полный список слов, которые следуют за словом "the". Запрашивая слова, которые следуют за словом "the", по индексу мы не сможем найти все, что ищем; для этого мы должны обратиться к фактическому тексту.
Экстраординарная частота слова "the", вероятно, сделает эту работу абсолютно невыполнимой даже при наличии индекса. "Давайте посмотрим, где есть "the"… Ах да, "the" есть на первой странице." Хорошо, что вы отметили первую "the" страницу в индексе. Тогда щелкнете по индексу для первой страницы. Вы расположите слово после первого "the". Потом вы возвращаетесь к индексу, чтобы найти следующую страницу, на которой появляется "the" - это также страница один. Вы будете ходить вперед и назад, пока вы не посетите каждую страницу всех множеств книжных времен. Вы будете щелкать по книге назад и вперед столько много раз, что ее переплет, вероятно, полностью износится.
Теперь представим, что существует Reader"s Digest Large Print for Easier Reading (Справочник Читателя для Большого Издания для более легкого чтения) этой Brief History of Humanity (Краткой Истории Человечества). Далее представим себе, что основная книга напечатана буквами по 72 пункта. Поэтому Brief History of Humanity содержит только по 20-30 слов на странице. И хотя слово "the" достаточно общее и фактически появляется на каждой странице обычной книги, оно уже не достаточно обычно, чтобы появляться на каждой странице справочника Large Print. В этих новых условиях индекс имеет очень большую полезность для нашего небольшого проекта "find the word after the "the"" ("найти слово после "the""), потому что теперь индекс позволяет нам пропускать большее количество страниц.

Это - 72-пунктовый шрифт. Справочник Large Print for Easier Reading для книги Brief History of Humanity содержит намного меньшее количество ссылок, чем к каждой странице стандартного размера.

Разгадка мифа
Параметры, которые влияют на полезность индекса при диапазонном сканировании, при котором требуется rowid-доступ к таблице, следующие:
- Размер блока данных Oracle. Чем больше размер блока данных, тем более "interesting" ("проверяемый") блок данных имеет тенденцию отвечать предикатам фразы where и тем поэтому менее он полезен при индексации. Применение больших блоков данных приводит к снижению значений x.
- Размер блока индекса Oracle. Больший размер блока индекс (который до Oracle9i, конечно, был такой же, как и размер блока данных) потребует меньшего количества LIO- и PIO- операций для действий с индексом, и поэтому более полезен при организации индекса. Применение больших блоков индекса приводит к увеличению значения x.
- Размер строк. В нашей притче полезность применения индекса повысилась, когда мы сделали слова большими по сравнению с размером страницы. Это аналогично наличию длинных строк в Oracle-блоках фиксированного размера. Применение длинных строк приводит к увеличению значения x.
- Распределение данных. Если бы текст Brief History of Humanity (Краткая История Человечества) был отсортирован в алфавитном по словам, наш индекс имел бы чрезвычайно высокую полезность, даже в издании с малыми буквами и даже для слова "the". Все "the" были бы собраны (clumped) вместе, составив две трети объема книги [5]. Но лучше, если физическая кластеризация данных таблицы приведет к большим значение x для вашего запроса.
Понимание параметров полезности индекса разрушает миф, почему люди не могут сделать хороший выбор значения x.
- Когда создатели документации Oracle писали руководство по настройке Oracle6 (Oracle version 6 tuning guide), они, вероятно, использовали таблицы типа dept в схеме scott/tiger в базе данных Oracle с блоками 2КБ. Когда создавалась документация по Oracle7, они, вероятно, протестировали те же самые запросы, что и прежде. Но, вероятно, использовался "new" ("новый") 4КБ размер блока Oracle, который вошел в моду с Oracle7. Так как большие блоки хранили большее число строк, чем прежде, наблюдаемое значение x было ниже. Индексы, очевидно, оказались менее полезными, чем они были в Oracle6. Выявленный порог снизился с 10-15 до 2-4 %.
- Документация по Oracle8i и Oracle9i намного лучше раскрывает тему полезности индексов. Теперь, как общее положение, Oracle использует x = 15, но упоминается, что значение "varies greatly" ("существенно варьирует"). Кластеризация (clustering) и скорость полного сканирования (full-scan) упоминаются как изменяющиеся параметры, но не упоминаются ни размер блока, ни размер строки как параметры кластеризации [Oracle 2001a].
- Вы не забыли наших хороших друзей из Oracle Applications development, которые объявляли хорошими результаты при x> 40? Почему они были убеждены в значении, так драматично отличном от всего, что говорила официальная документация Oracle? Не трудно понять их точку зрения, если вы подумаете о среде, в которой они находятся. Во-первых, их таблицы имеют огромные (huge) строки. Таблицы многих приложений включают более 200 столбцов в строке. Во-вторых, по разным причинам Oracle Applications являются "little slow" ("немного медленными") в плане восприятия новых технологий, предлагаемые ядром (kernel). С середины 1990-ых они почти исключительно использовали 2KB-блок базы данных. Разумеется, изменение размера блока в больших базах данных Oracle Applications - это огромная работа, не говоря уже о, по-видимому, непреодолимой работе по проверке правильности планов выполнения SQL-предложений. Коль уж так случалось, комбинация больших строк и маленьких блоков привела к наблюдаемому более высокому значению порога x, чем по наблюдениям многих других групп.

Что же теперь?
Мой вам совет:
Забудьте все о правилах индексации типа большого пальца, основанных на процентах.
На самом деле не имеется никакого диапазона процентов, который даст вам надежный результат. Имеются запросы, возвращающие 1 % или меньшее число строк таблицы, которые более эффективно выполняются полным просмотром таблицы, нежели с использованием индекса. И существуют запросы, возвращающие все 100 % строк таблицы, которые более эффективно выполняются посредством индекса. Но если вы настаиваете на выборе значения для x, я рекомендую найти такое значение, которое одновременно является меньше 1% и больше или равно 100%. Так как никакое такое число не существует, я рекомендую, чтобы вы полностью переключили свое внимание в другую сторону от правил индексации типа большого пальца, основанных на процентах.
Технология оптимизации Oracle проделала длинный путь, начиная с внедрения основанного на стоимости (cost-based) оптимизатора Oracle (это было весьма хорошо в Oracle8i). Все что требуется от Вас - это определить, какие создать индексы. Ядро Oracle только тогда будет использовать созданные вами индексы, когда это эффективно. Но создание индекса, который никогда не будет хорошо использоваться, - только трата и места, и времени [6]. Поэтому вы должны сами решать, создавать индекс или нет? Ответ в селективности блоков.
 Селективность блоков
Селективность блоков
Вы, вероятно, уже знакомы с концепцией селективности строк. Вы можете определить селективность строк данного предиката из фразы where, как число строк, возвращенных предикатом (r), разделенное на общее число строк в таблице (R):
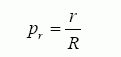 - определение селективности строк (row selectivity)
- определение селективности строк (row selectivity)
Селективность блоков можно определять, аналогично задавая в фразе where предикат отношения числа блоков данных, содержащих по крайней мере одну строку, отвечающую условию предиката (b), к общему количеством блоков данных ниже high-water mark (B):
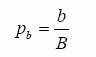 - определение селективности блоков (block selectivity)
- определение селективности блоков (block selectivity)
Различие между селективностью строк и селективностью блоков весьма существенно, потому что селективность блоков почти всегда хуже - часто много хуже - селективности строк. Ранее на примере таблицы shipment мы видели flag ='x'. Для этого предиката получается селективность строк 1 %, а селективность блоков 100 %.
Вы можете вычислить селективность строк и селективность блоков, используя SQL-скрипт из следующего примера, который мы назвали hds.sql [Holt 2002].
1 rem $Header: /usr/local/hotsos/RCS/hds.sql,v 1.8 2002/01/07 18:12:27 hotsos Exp $
2 rem Copyright (c) 2000-2002 by Hotsos Enterprises, Ltd. All rights reserved.
3 rem Author: jeff.holt@hotsos.com
4 rem Notes: Hotsos data selectivity using a full table scan for the row count.
5
6 define v_substr7 = 'substr(rowid,15,4)//substr(rowid,1,8)'
7 define v_substr8 = 'substr(rowid,7,9)'
8 define v_over = 'substr(''&_O_RELEASE'',1,1)'
9
10 col dummy new_value v_substr
11
12 set termout off heading on pause off
13
14 select decode(&v_over, '7', '&v_substr7', '&v_substr8') dummy
15 from dual;
16
17 set termout on verify off feedback off pages 10
18
19 accept p_town prompt 'TableOwner : '
20 accept p_tname prompt 'TableName : '
21 accept p_clst prompt 'ColumnList : '
22 accept p_where prompt 'WhereClause: '
23 accept p_pgs prompt 'PageSize : '
24
25 variable fblks number
26
27 declare
28 tblks number;
29 tbytes number;
30 ublks number;
31 ubytes number;
32 luefid number;
33 luebid number;
34 lublk number;
35 begin
36 sys.dbms_space.unused_space(
37 upper('&p_town'), upper('&p_tname'), 'TABLE',
38 tblks, tbytes, ublks, ubytes, luefid, luebid, lublk, null
39 );
40 :fblks := tblks - ublks;
41 end;
42 /
43
44 col blks form 9,999,999,999 heading 'Table blocks below hwm/(B)' just c
45 col nrows form 999,999,999,999 heading 'Table rows/(R)' just c new_value v_nrows
46
47 select :fblks blks, count(*) nrows
48 from &p_town..&p_tname;
49
50 col bs form a17 heading 'Block selectivity/(pb = b/B)' just c
51 col nblks form 9,999,999,999 heading 'Block count/(b)' just c
52 col rs form a17 heading 'Row selectivity/(pr = r/R)' just c
53 col nrows form 999,999,999,999 heading 'Row count/(r)' just c
54
55 set pause on pause 'More: ' pages &p_pgs
56
57 select &p_clst,
58 lpad(to_char(count(distinct &v_substr)/:fblks*100,'990.00')//'%',17) as bs,
59 count(distinct &v_substr) nblks,
60 lpad(to_char(count(*)/&v_nrows*100,'990.00')//'%',17) rs,
61 count(*) nrows
62 from &p_town..&p_tname &p_where
63 group by &p_clst
64 order by bs desc;
Использование скрипта hds.sql очевидно. Однако, получение полной информации о распределении данных в таблице может быть очень дорогим. В зависимости от ваших данных, этот запрос может выполняться и минуты, и часы. Это объясняет, почему стоимостной оптимизатор Oracle полагается на хранимую статистику вместо самостоятельного анализа данных, когда вычисляет или утверждает план выполнения. Следующий пример иллюстрирует, как мы используем данные hds.sql.
Пример: система имеет таблицу с именем po.cs_ec_po_items. Наша цель состоит в том, чтобы оптимизировать несколько подопераций запроса, которые во фразе where используют предикат ec_po_id =:vas . Что получится, если мы создадим индекс на столбце ec_po_id? Мы можем использовать скрипт hds.sql, чтобы получить истинную информацию о распределении данных по различным значениям ec_po_id:
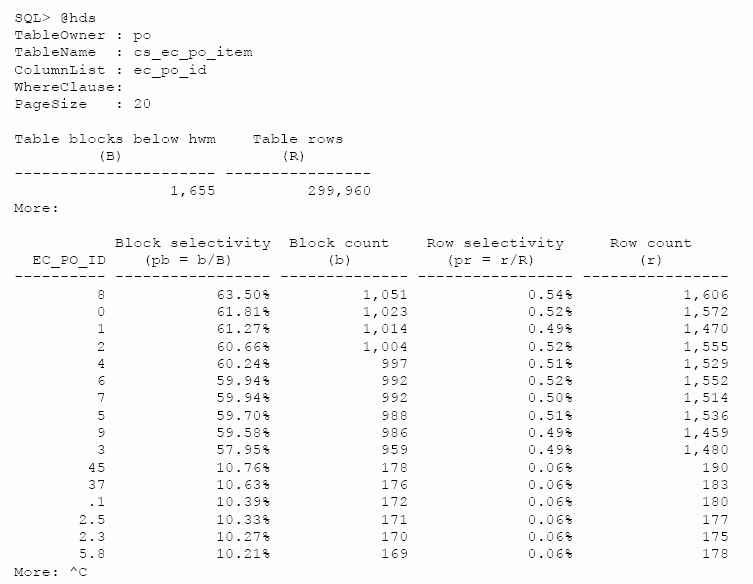
Выходные данные скрипта hds.sql отсортированы по убыванию селективности блоков. Листинг обычно содержит тысячи строк, но все самые плохие данные (worst-case data) - в данном случае представляющие наиболее интересную часть - находятся наверху. Поэтому мы обычно обрываем листинг hds.sql после выдачи одной-двух страниц.
Заметим, что для этой таблицы имеет место превосходная селективность строк для каждого значения ec_po_id. "Самое плохое" значение селективности строк - только 0.54 % [7]. Это означает, что только полпроцента строк таблицы имеет значение ec_po_id = '8'. Однако столбец селективности блоков представляет нам совсем другую историю. Селективность блоков ec_po_id = '8' составляет 63.50%. Это значит, что почти двух третях блоков таблицы содержится по крайней мере по одной строке, для который ec_po_id = '8'.
Должны ли мы создать индекс на ec_po_id? Можно потратить полдня или более, вычисляя "back of the envelope" ("быстро и легко определяемый") ответ, пытаясь вычислить по формулам затраты плана выполнения. Но оптимизатор Oracle может сделать эту работу за вас. Наиболее точный и, в конечном счете, наименее отнимающий время метод для определения ответа состоит в том, чтобы выполнить тестирование на фактической базе данных Oracle. Лучший способ определить относительные затраты двух планов выполнения состоит в том, чтобы выполнить их на некоих тестовых данных с установкой опции sql_trace=true. Если нужна большая детальность в части, скажем, использования других (не-CPU) механизмов, которых задействует Oracle в течение выполнения запроса, то протрассируйте выполнение с использованием Oracle-события 10046 на уровне 8 [Hotsos 2002]. Если нужно большее количество данных о том, почему оптимизатор выбрал такой план, который сам и сделал, то протрассируйте выполнение с Oracle-событием со случаем 10053 [Lewis 2001].
Из листинга hds.sql мы узнаем граничные условия, которые нужно проверить. Например, мы теперь знаем, что при тестировании следует ответить на следующие запросы:
- Выполнится ли запрос select foo from cs_ec_po_item where ec_po_id="8" быстрее с индексом на ec_po_id?
- Выполнится ли сколько-либо быстрее запрос с индексом для ec_po_id = '45'?
- Выполнится ли сколько-либо быстрее запрос для ec_po_id, которые имеют селективность блоков меньше чем 1 %? (Поскольку отчет сортируется в нисходящем порядке селективности блоков, значения с лучшей селективности блоков в нем не показываются.)
Ваше окончательное решение о построении индекса, конечно, зависит от того, превышает ли выгода от наличия индекса стоимость его наличия. Эти затраты могут включать:
- Случайная деградация планов выполнения других запросов. В приложениях, которые все еще используют синтаксический оптимизатор Oracle, это представляет очевидный риск. Создание индекса для оптимизации предложения А может случайно деградировать производительность некоторого другого предложения B. К счастью, в стоимостной оптимизации, особенно для гистогамм (histograms) это явление становится все более редким.
- Увеличение времени DML-ответа для конкретной таблицы. Однако я видел, как люди драматически переоценивают важность этого фактора. Не гадайте об этом; спрофилируйте трассовые данные ваших DML-операций, чтобы выяснить их истинную стоимость.
- Увеличение объема пространства для размещения индекса. Когда-то количество места, нужного для индекса, было материально важным фактором при определении, строить ли индекс. С сегодняшними ценами на диски это почти к делу не относится.
Когда используется инструмент подобно скрипту hds.sql, наблюдается один из трех вариантов:
- Селективность блоков каждого значения настолько хороша, что вы определенно хотите создать индекс для столбца.
- Селективность блоков каждого значения настолько низка, что вы определенно не хотите создать индекс для столбца.
- Селективность блоков низка для некоторых значений, но хороша для других. В этом случае, необходимо решить, достаточна ли полезность индекса в хороших случаях, чтобы компенсировать стоимость его наличия.
Решения в случаях 1 и 2 очевидны. А ситуация 3, вероятно, именно та, в которой вы пребываете наиболее часто. Пользователи стоимостного оптимизатора Oracle до релиза 7.3 стояли перед жестким выбором. Если индекс не создавался, то был велик риск низкой производительности при некоторых значениях во фразе where; если индекс создавался, то был риск низкой производительности для других значений. Новейшие версии стоимостного оптимизатора Oracle делают жизнь намного проще. Если в наши дни вы регулярно исполняете свои обязанности по сбору статистики [8], подобная ситуация намного менее вероятна, и ошибочное создание мало пригодного индекса причинит экстремальные издержки (torture - пытка) вашим пользователям.
Пример: Представим себе, что секционированная таблица содержит столбец id со следующим распределением данных:
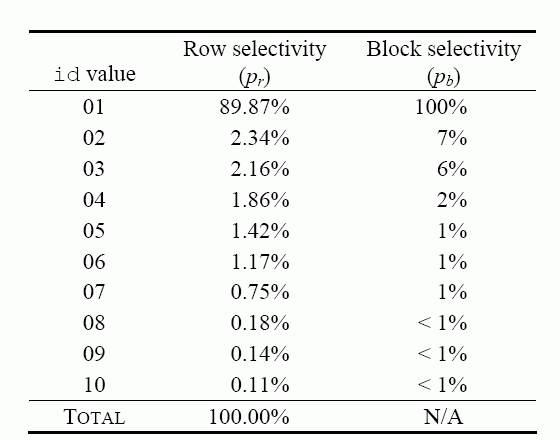
Показанное здесь распределение данных сильно перекошено (highly skewed). Теперь выдадим следующий запрос к этой таблице:
select name from division d where id=:a1
Без гистограмм стоимостной оптимизатор может предположить, что имеются десять различных значений id, каждый id отвечает за примерно 1/10 строк таблицы. Это предположение заставит его вспомнить хорошую идею использовать индекс на столбце id. И так было бы до тех пор, пока :a1 != '01'.
Сила гистограммной (histogram-based) оптимизации состоит в том, что должным образом реализованный [9] гистограммный оптимизатор заметит, когда :a1 = ' 01' и не будет пытаться использовать индекс на id. Без гистограммной оптимизации разработчик приложений должен или
- оптимизировать запрос так, чтобы было эффективно, если :a1 = ' 01 ', но крайне неэффективно иначе [10]; или
- вы должны написать процедурную логику, которая использует одно SQL-предложение для обычных значений и другое SQL-предложение для редких значений. Oracle General Ledger генерирует динамические SQL-предложения, используя метод 2 для функций Financial Statement Generator. Это умно, но одновременно и беспорядок (a mess).
Значения не часто распределяются произвольным образом
Недавняя документация по Oracle приводит предположение, что "строки в таблице упорядочены произвольно (randomly ordered) в отношении столбца, на котором базируется запрос" [Oracle 2001b]. Это предположение немного упрощает написание Oracle-документации, но это делает этот совет Oracle менее полезным, чем он мог бы быть.
В результате действий с hds.sql можно увидеть, что иногда значения столбца естественным образом группируются, и остаться сгруппированными навсегда.
Пример: таблица shipment имеет столбец состояния, называемый shipped, который принимает значение 'y', тогда и только тогда, когда пункт заказа был отгружен (shipped). Поскольку заказы имеют тенденцию отправляться, грубо говоря, в той же последовательность, что были введены, таблица shipment через какое-то время имеет хорошую естественную кластеризацию по значениям shipped="n", как это показано на рисунке 3. Кластеризация строк с shipped="n" улучшает полезность индекса при поиске строк с shipped="n" .
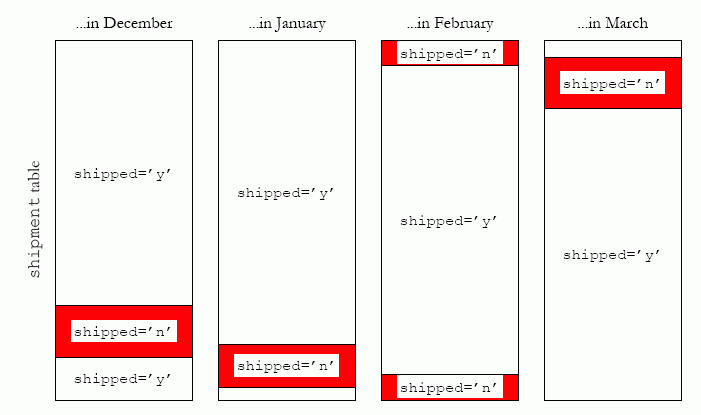
Рисунок 3. Значения столбца состояния имеют тенденцию к естественной кластеризации.
Противоположностью сгруппированного распределения является однородное распределение. Если значения столбца имеет истинное однородное распределение в пределах таблицы, то экземпляры данного значения физически равноудалены друг от друга.
Пример: таблица address имеет столбец с именем state, который содержит двух литерный код штата или провинции. В приложении, которое использует эту таблицу, нет никаких очевидных отношений между временем, когда была вставлена строка клиента, и значением state клиента. Следовательно, физическое распределение каждого значения state практически однородно. Хотя state ='TX' истинно, возможно, только для одной строки из 30, лишь немногие блоки таблицы не имеют ни одной строки с state ='TX'. Рисунок 4 показывает эту ситуацию.

[Блок содержит по крайней мере одну строка с state = 'TX'
Блок не содержит ни одной строки, для который state ='TX' ]
Рисунок 4. Индекс на state имеет низкую полезность для state ='TX '.
Использование здесь индекса по с state, вероятно, было бы неэффективно для поиска любого "известного" ("popular") кода штата. Но если, например, имеется один или более штатов с много меньшим количеством строк, чем наличествует блоков в таблице address, и если Вы часто ищете коды таких штатов и используете гистограммы, тогда создание индекса по state, вероятно, поможет вашему приложению.
Столбцы Status иногда могут самостоятельно группироваться естественным образом. Но при отсутствии любого искусственного внешнего влияния столбцы type в большинстве имеют тенденцию к однородному физическому распределению. Существует несколько типов воздействия на физическое хранение данных в таблице. Можно предписать определенную физическую упорядоченность данным, используя:
- Секционирование (partitioning) таблиц и индексов Oracle
- Индекс-организованные таблицы Oracle
- Периодические операционные процедуры обслуживания для удаления строк и затем повторной их вставки в предпочтительном физическом порядке
- Использование кластерных (cluster) сегментов Oracle, вместо табличных сегментов
Без нужды не предполагайте, что распределение ваших данных случайно (random). Выясните это с помощью hds.sql. Любые приемы, предписывающие физическую упорядоченность, принесут как выгоды, так и затраты вашему бизнесу. Если изменение физического распределения данных одновременно помогает максимизировать чистую прибыль вашей компании, поток наличности (cash flow) и возврат инвестиций, тогда делайте это [Goldratt 1992].

Заключение
Многие источники учат, что решения по индексации надо принимать на базе анализа предиката селективности строк во фразе where. Еще хуже, когда некоторые источники обсуждают применение индексации в терминах селективности строк для всего столбца, что полностью игнорирует возможность его асимметричности. Однако селективность строк - ненадежное основание для решения о создании индекса. Лучший способ смягчать риск состоит в том, чтобы проверить фактическую производительность SQL-предложения на проверенных тестовых данных. Инструмент, подобный скрипту hds.sql, который выдает информацию о селективности блоков, повышает надежность и эффективность вашего испытания, раскрывая критические значения столбца, на котором вы собираетесь проверить производительность.
Стоимостной (cost-based) оптимизатор Oracle делает более простым ответ на вопрос, надо ли строить индекс, поскольку он вырабатывает более продвинутые решения по использованию индексов, чем это может сделать синтаксический (rule-based) оптимизатор. Но для реализаций, которые все еще полагаются на синтаксический оптимизатор Oracle, понимание важности селективности блоков может быть жизненно важно для производительности приложений Oracle. Как только определятся характеристики селективности блоков, необходимо исключить пассивный подход к физической упорядоченности ваших данных. Много возможностей, привнесенных в СУБД Oracle, начиная с выпуска 7.3, упрощают ваши действия по хранению данных в физической упорядоченности, что обеспечивает превосходную производительность.
Примечания:
[1] Источник строк - это просто некоторое подмножество строк таблицы (возможно, строки всей таблицы, в случаях полного просмотра таблицы). Вывод результата запроса часто рассматривается как операция исчерпания источника строк (as the operation"s resulting row source). В сложном плане выполнения запроса Oracle, последующая (child) операция плана выполнения передаст свой закончившийся источник строк своему родителю (to its parent) для дальнейшей обработки (типа соединения или фильтрации).
[2] В Oracle8i мы нашли, что создание и использование индекса на таблице sys.dual существенно уменьшает число LIOS, требующихся, чтобы выбрать ее единственную строку. Мы наблюдали в отношении 10:1 соответствующее сокращение времени ответов на запросы к dual. Если ваше приложение выполняет, например, миллионы LIO-запросов в день к однострочным ссылочным таблицам, то по нашим данным, индексируя такие таблицы, вы сможете сэкономить эти миллионы LIOS в день и задействовать приблизительно на 90 % CPU меньше для тех же самых запросов.
[3] Пожалуйста, не путайте эту таблицу с диаграммами, которые соотносят изменения x с модификациям ядра Oracle. Например, [Niemiec 1999 (38, 318)] указывает, что доминирующий фактор в изменении значения x - номер версии Oracle. Моя же цель состоит в объяснении того, что реальный уровень (the actual break-even) существенно зависит от других параметров и фактически независим от номера версии Oracle.
[4] Craig Shallahamer, Micah Adler и я еще в 1993 [Millsap и др. 1993] написали статью в Oracle Magazine о нахождении истинных параметров, которые влияют на x. Craig, Micah и я может быть единственные люди в мире, которые читали эту статью. Недавно пересмотрев ее заново, я более четко понял, почему она не попала ни в одно из большего числа общедоступных изданий, с которыми я когда-либо работал. Скажем, в одной из строк этой статьи была приведена следующая формула:
![]()
… Конечно, нелегкое чтение. Не удивительно, что никто не когда-либо спросил меня, где заключительная круглая скобка, которая, как предполагалось, была. (Я вполне уверен, что по крайней мере наша первоначальная рукопись была синтаксически полна.) Эту статью уже фактически невозможно найти, что еще более затрудняет ее прочтение. Для получения дополнительных деталей см. секцию Ссылки.
[5] Без сомнения сортировка текста Brief History of Humanity (Краткая История Человечества) в алфавитном порядке по словам разрушила бы значение текста, как смысл нашего запроса типа "find the word that follows the word "the" " ("найти слово, которое следует за словом ' <определенный артикль>' ").
[6] …, пока этот индекс не потребуется, чтобы задействовать условие ограничения (constraint definition).
[7] Нельзя говорить, что 0.54 % - самая плохая селективность для строк таблицы, глядя только на приведенный здесь листинг. Выход скрипта hds.sql сортируется по уменьшению селективности блоков. Это не подразумевает уменьшающейся упорядоченности селективности строк. (Для доказательства заметим, что значения селективности строк в показанном здесь листинге, не появляются в строго убывающем порядке.) Чтобы определить самое плохое значение селективности по строкам в листинге в hds.sql, надо исследовать полный выходной поток этого скрипта.
[8] Это означает, что надо регулярно запускать fnd_stats, если вы - менеджер Oracle Applications, или пакет dbms_stats в других случаях.
[9] Это длинная история, гистограммная оптимизация Oracle пошла сквозь тяжелые компромиссные решения. До Oracle9i использование связанных переменных препятствовало гистограммной оптимизации. Это очень печально, поскольку в общем случае приложение, которое не использует связанные переменные, не может масштабироваться на увеличение пользовательских вычислений. В Oracle9i оптимизатор делает почти то, что мы хотим: он "peeks" ("смотрит") на контент, относящийся к связанной переменной, и вырабатывает решение, основанное на гистограмме. Однако, при последующих после первого исполнениях разделяемого (shared) SQL-предложения, каждый раз берется план первой оптимизации сессии. То есть, если первое выполнение запроса использует :a1 = '01', то второе (и каждое последующее) выполнение будет применять оптимальный план :a1 = '01', даже если ищется :a1 = '07'.
Хорошая весть в том, что не обязательно использовать связанные переменные для тех предикатов во фразе where, которые обладают небольшой областью значимости. Например, используя литеральные значения в sex="m", предикат хорош, потому что он порождает только два различных варианта разделяемого SQL-предложения в библиотечном кеше. Если же литеральные значения использовать в чем-то подобном order_id = '1289942' , эффект был бы катастрофическим, потому что это потенциально заставит задействовать тысячи почти идентичных, но тем не менее различных SQL-предложений, используя библиотечный кеш.
[10] Один из старомодных способов оптимизирования такого запроса состоит в том, чтобы переписать его подобно следующему:
select name from division d where nvl(id,id)=:a1
Эта техника предотвращает Oracle от использования любого индекса с id в качестве его префикса. Более современный способ сделать это состоит в том, чтобы определить указание (hint), например:
select /*+ full(d) */ name from division d where id=:a1
Начиная с Oracle8i, мы можем выполнить один шаг улучшения: мы можем оптимизировать запрос, манипулируя его stored outline (хранимый план выполнения). Эта замечательная новая особенность позволяет нам оптимизировать предложение без получения доступа к исходному его коду (without requiring access to the statement"s source code).

Ссылки
- GOLDRATT, E. M.; COX, J. 1992. The Goal: A Process of Ongoing Improvement. 2d ed. Great Barrington MA: North River Press.
- GORMAN, T. 2001. The Search for Intelligent Life in the Cost-Based Оптимизатор. Evergreen Database Technologies: http://www.evdbt.com/library.htm
- HOLT, J. 2000. Predicting Multi-Block Read Call Sizes. Hotsos: http://www.hotsos.com/catalog/catalog.html
- HOLT, J. 2002. Hotsos Clinic Tools Pack. Available to Hotsos Clinic students: http://www.hotsos.com/catalog/catalog.html
- HOTSOS. 2002. Sparky™ Data Collector. Hotsos: http://www.hotsos.com/products/sparky.html
- LEWIS, J. 2001. Practical Oracle8i: Building Efficient Databases. Upper Saddle River NJ: Addison-Wesley.
- MILLSAP, C; SHALLAHAMER, C.; ADLER, M. 1993. "Predicting the Utility of the Nonunique Index." Oracle Magazine Vol. VII, No. 2 (Spring 1993): 48-53. This article was also printed and distributed within Oracle Corporation from 1992 through 1995. Unfortunately, there is no electronic copy of this article available publicly anywhere. The only way the author knows to view this article is to locate a physical copy of the Spring 1993 issue of Oracle Magazine.
- NIEMIEC, R. 1999. Oracle Performance Tuning Tips & Techniques. Berkeley CA: Osborne/McGraw Hill.
- ORACLE. 2001a. Oracle9i Database Administrator"s Guide Release 1 (9.0.1). Oracle: http://downloadwest.oracle.com/otndoc/oracle9i/901_doc/server.901/a90117/indexes.htm#5640
- ORACLE. 2001b. Oracle9i Database Performance Guide and Reference Release 1 (9.0.1). Oracle: http://downloadwest.oracle.com/otndoc/oracle9i/901_doc/server.901/a87503/stats.htm
Благодарности
Прежде всего выражаю благодарность Джефу Холту (Jeff Holt), компания Hotsos, за большой вклад в эту работу, за его исследования, тестирование, корректуру, проверку фактов, а также действенную проверку использованных в этом материале принципов. Спустя девять лет после нашей дискуссии в Buckhorn Exchange в Денвере (Denver) я хотел бы снова поблагодарить Craig Shallahamer (Грег Шаллахамер) и Micah Adler (Миша Адлер) за хорошую беседу о принципах индексной селективности. Спасибо также Steve Adams (Стив Адамс), Jonathan Lewis (Джонатан Льюис), Bjorn Engsig (Бьорн Энгсиг), Dominic Delmolino (Доминик Делмолино), Mogens Norgaard (Могенс Норгаард) и Zach Friese (Зак Фрайз) за их конструктивную обратную связь в течение подготовки этого материала. Наконец, я благодарен студентам нашей Hotsos Clinic, которые помогли нам повысить качество сведений о селективности индексов.
Об авторе
Cary Millsap (Кэри Миллсап) - совладелец компании Hotsos Enterprises,Ltd., деятельность которой направлена на самостоятельное повышение квалификации администраторов баз данных Oracle во всем мире посредством формирования обучающей аудитории (classroom education) - www.hotsos.com, через которую предоставляются информация, программное обеспечение, сервисы и консультантские услуги. Cary Millsap - автор Optimal Flexible Architecture (Оптимальная Гибкая Архитектура), создатель оригинального инструментария APS, Hotsos проектировщика программного обеспечения и разработчика, редактор hotsos.com, создатель и основной преподаватель Hotsos Clinic по проблемам диагностики производительности систем Oracle (Oracle® System Performance Problem Diagnosis).
В течение десяти лет К. Миллсап в качестве ведущего эксперта по системной производительности работал в корпорации Oracle, где он основал System Performance Group (Группа системной производительности) и был ее вице-президентом. Он обучил тысячи Oracle-консультантов, аналитиков поддержки, разработчиков и клиентов оптимальному использованию технологий Oracle, благодаря их фиксированному описанию, обучению и публичных о них выступлениях. Еще работая в Oracle, К. Миллсап улучшил производительность более чем 100 клиентских системах, включая (по прямому указанию президента Oracle) несколько негативно развивающихся ситуаций. Он работал в глобальном консультационном комитете Oracle по регулированию (the Oracle Consulting global steering committee), где он отвечал за развертывание сервисного обслуживания во всем мире.