Бытует мнение, что программирование на низком уровне - чрезвычайно сложное занятие. Доля правды здесь есть, однако не стоит этого опасаться - всему можно научиться, стоит только начать. Для тех, кто изучает Delphi, но хочет приобщиться и к "низкоуровневым изысканиям" и предназначена эта статья.
Могучая процедура Move
Move - любопытная стандартная процедура, доставшаяся нам в наследство ещё от старого, доброго Turbo Pascal'я. Она, наверное, по какой-то ошибке попала в язык программирования высокого уровня, однако изрядно добавила мощности и упростила жизнь (а мы только и рады ![]() ). Вроде бы ничего особенного: procedure Move(const Source; var Dest; Count: Integer); Перемещает из Source в Dest участок памяти, равный Count байтам. Причем, как вы заметили (если заметили), Source/Dest - не указатели, а непосредственно переменные, и за точку отсчета Move берет первый байт, занимаемый переменной. Посмотрите на примеры:
). Вроде бы ничего особенного: procedure Move(const Source; var Dest; Count: Integer); Перемещает из Source в Dest участок памяти, равный Count байтам. Причем, как вы заметили (если заметили), Source/Dest - не указатели, а непосредственно переменные, и за точку отсчета Move берет первый байт, занимаемый переменной. Посмотрите на примеры:
var
b : array[0..80] of byte;
c : array[4..67] of char;
w : array[8..670] of word;
procedure SomeProc;
begin
MessageBox(0, 'hello!', nil, 0);
end;
begin
{1}move(b, c[4], 20); //копирует 20 байт из начала массива b в массив с, начиная с 4-ой позиции.
{2}move(b, w, SizeOf(b)); //копирует весь массив b в начало массива w (обратите внимание на несоответствие размеров типов!)
{3}move(w[4], w[50], SizeOf(word)*100); //"отодвигает" 100 значений с 4-ой на 50-ю позицию внутри одного массива(обратите внимание - участки памяти Source и Dest перекрываются!)
{4}move(SomeProc, b, SizeOf(b)); //копирует код процедуры SomeProc в массив b
...
Теоретически, просто побайтно копируются куски памяти, невзирая на типы данных и их размеры. Замечательно также то, что процедура корректно работает в случае, когда данные на новом месте "задевают" исходные. В примерах мы определяем размер массива с помощью функции SizeOf. Она возвращает размер в байтах либо структуры данных, либо типа данных. Замечу, что в реализации Move не предусмотрено никакой проверки на выход за границы переменных, что является поводом как для большей осторожности при её использовании, так и для всевозможных низкоуровневых трюков. Четвертый пример как раз из таких. Он сегодня для нас является ключевым, итак...
Четвертый пример
Логически, загруженная в память и работающая программа состоит из кода - инструкций для процессора ("глаголов"), и данных, которые этими инструкциями обрабатываются ("существительных"). Хранятся в памяти компьютера и те, и другие одним способом - как последовательности байтов. И поэтому код иногда можно рассматривать как данные. Будь я профессором, сказал бы, что в таком случае жизнь проводится "принцип фон-Неймана". В различных специфических программах (компиляторах, паковщиках исполняемых файлов, всевозможных защитах и т.д.) без него не обойтись. Подобные методы справедливо считаются прерогативой языков низкого уровня (в первую очередь, ассемблера), однако и с Delphi можно провести некоторые любопытные эксперименты такого сорта.
Теперь, ближе к нашему примеру. Массив b заполнится представлением процедуры SomeProc в памяти компьютера. Причем, нам не известно, сколько байт она занимает - скорее всего, исходя из её миниатюрности, в конце массива будет мусор - кусок либо другой процедуры, либо данных. Но будь процедура побольше, то могла бы и не поместиться в отведенные 80 байт. Как видите: сплошная неизвестность, но мы попробуем пролить на ситуацию немного света. Первое, что приходит в голову - посмотреть, что же таки записалось в наш массив. Вполне резонно! Вы, наверное, уже написали что-то вроде
for i:=Low(b) to High(b) do
Memo1.Lines.Add(IntToStr(i) + ' - ' + IntToStr(b[i]));
...и смотрите непонимающим взором на колонки чисел.
Те, кто не написал, поскорей набирайте, а я же не упущу возможности кое-что пояснить. Паскаль дает возможность задавать любые границы индексации массивов (что есть признак "высокоуровневости" языка - например, в языке Си все массивы индексируются с нуля). В Delphi пошли дальше и ввели функции Low и High, которые определяют нижний и верхний индексы массива, соответственно. Это действительно удобно, так что рекомендую повсеместно в ваших программах использовать их, избавляясь от малозначащих констант.
Итак, колонка чисел. Ничего, вроде, интересного. Но я предлагаю выводить не только код, но еще и символьное представление байта. В итоге, пишем следующее:
for i:=Low(b) to High(b) do
Memo1.Lines.Add(IntToStr(i)+' - '+IntToHex(b[i], 2) + ' ' + chr(b[i]));
Обратите внимание - теперь используется функция IntToHex вместо IntToStr. Она переводит число в его строковое представление в шестнадцатеричной системе счисления. Первым аргументом подается само число, вторым - нужное нам количество знаков в искомом представлении. Профессиональные программисты очень любят использовать шестнадцатеричную систему счисления. Во-первых, в ней для описания значения одного байта достаточно только 2-х символов. А во-вторых, байты имеют обыкновение группироваться в слова (2 байта), и двойные слова (4 байта), для возможности представления чисел, больших 255. И теперь, перед нами стоит задача: определить, какое число определяет машинное слово, состоящее из 2-x байтов {28, 86} (порядок имеет значение!). Нужно вычислять: 28*256 + 86 = 7254. А вот если использовать 16- чную (не хочу уже повторять этот "длиннючее" слово ![]() ) систему, то искомое число получится простым "склеиванием". Т.е. в данном случае {1С, 56} = 1C56! Еще явственней её преимущества проявляются, когда число надо наоборот, "расчленить" на байты.
) систему, то искомое число получится простым "склеиванием". Т.е. в данном случае {1С, 56} = 1C56! Еще явственней её преимущества проявляются, когда число надо наоборот, "расчленить" на байты.
Итак, опять возвращаемся к нашим бананам. Запустите программку и внимательно изучите полученный результат. В байтах с 14-го по 19-ый (изъясняюсь в 16-чной, извините-с ![]() ) расположилась наша строчка 'hello!'. Уже теплее. Причем, обратите внимание, она завершается байтом с кодом нуль, так называемым "нуль-терминатором". Так устроены строки в Си-программах. Компилятор увидел, что вызывается функция (MessageBox), аргументом которой является строка в стиле Си (в терминологии Delphi ей соответствует тип PChar). И, поэтому, вместо достаточно сложной во внутреннем представлении "паскалевской", сформировал нужную "сишную".
) расположилась наша строчка 'hello!'. Уже теплее. Причем, обратите внимание, она завершается байтом с кодом нуль, так называемым "нуль-терминатором". Так устроены строки в Си-программах. Компилятор увидел, что вызывается функция (MessageBox), аргументом которой является строка в стиле Си (в терминологии Delphi ей соответствует тип PChar). И, поэтому, вместо достаточно сложной во внутреннем представлении "паскалевской", сформировал нужную "сишную".
Идем дальше, копаем глубже. Как же все-таки определить, сколько байт занимает наша SomeProc? Для этого её нужно немного изменить:
procedure SomeProc;
begin
asm
nop
nop
end;
MessageBox(0, 'hello!', nil, 0);
asm
nop
nop
end;
end;
В Delphi есть удобная возможность вставлять в код нашей программы куски, целиком написанные на ассемблере. Инструкции записываются между ключевыми словами asm и end и вставляются компилятором в нужное место объектного кода без изменений. Нам понадобилась всего одна ассемблерная инструкция - nop (аббревиатура от "No OPeration"), главная задача которой - ничего не делать, а преспокойно занимать собой один байт памяти (скажу вам по секрету, с кодом 90...). Кое-кто уже, наверное, догадался, что к чему. Мы поставили эту инструкцию дважды в начало и в конец нашей процедурки. Теперь, мы точно сможем сказать, что все, что расположено между двумя парами байт с кодом 90 и есть наша SomeProc! По две же инструкции - для надежности, чтоб отделить свои nop'ы от чужих. Конечно, компилятору нет нужды просто так вставлять в код ничего не делающую инструкцию, однако еще более нет нужды вставлять её дважды ![]() .
.
Итак, барабанная дробь, запускаем нашу программу. Так-так... Два раза по девяносто в самом начале - значит, мы попали, куда надо. Уже хорошо... Идем дальше. Под номером, или как говорят программисты, по смещению 1B видим вторую пару, итак, найдено, наша процедура занимает 19 байтов! Только, что за чертовщина? Строки 'hello!' в этих границах нет! Но ведь строка-то находится внутри процедуры, почему же в итоге она оказалась снаружи? Вот она, как и полагается, сдвинулась на четыре байта относительно предыдущей позиции (мы же добавили в общей сложности 4 nop'a), но она снаружи! Отсюда стоит сделать важный вывод: несмотря на то, что в исходном коде программы данные и инструкции находятся рядом, в выполняемой программе они разнесены, каждый в свое место (мухи отдельно, котлеты, сами понимаете...).
Теперь, давайте проведем эксперимент: не позволим компилятору самовольно выделять место под строку, а сделаем это сами и посмотрим, что произойдет. SomeProc станет такой:
Procedure SomeProc;
const
s: array[0..7]of char = 'hello!'#0;
begin
asm
nop
nop
end;
MessageBox(0, s, nil, 0);
asm
nop
nop
end;
end;
Запускаем программу, и что мы видим? Строка исчезла с насиженного места в неизвестном направлении! Делаем ещё один вывод: Данные хранятся в разных местах, и места эти зависят от того, кто поместил туда их - компилятор, или сам программист. Разговоры разговорами, а целая строка куда-то делась средь бела дня. Её непременно надо найти!
В поисках Немо
Память компьютера состоит из ячеек (байтов), пронумерованных целыми числами, начиная с нуля. Номер первого байта любой структуры данных называется адресом этой структуры. Таким образом, у всех "жителей" памяти есть адреса. И у нашей потерявшейся строки - тоже. Адрес (или, как еще говорят, указатель) занимает 4 байта. Как нетрудно подсчитать, таким способом можно адресовать FFFFFFFF - целых четыре гигабайта! Что называется, "с запасом".
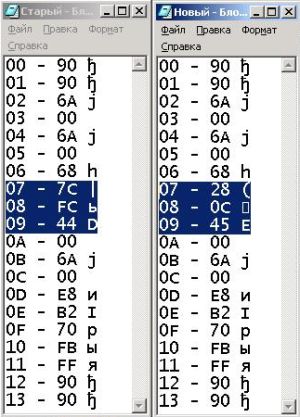
А теперь рассмотрим, как происходит вызов функции MessageBox и передача ей параметра-строки. Мы в программе вызываем функцию по её имени, но как вы могли убедиться, никакого имени непосредственно в код функции не записано. Функция вызывается по адресу, и параметром служит не сама строка, а её адрес - указатель на первый символ. Сплошные адреса! Вот почему в коде SomeProc не оказалось нашей строки, её отправили на хранение в укромное место, а вместо - подставили её адрес. Задача уже кажется разрешимой! Изменилось местоположение строки - значит, изменился её адрес. Дело за малым - определить, где находится тот самый указатель.
Итак, что же делать? Предлагаю вернуться к предыдущей версии SomeProc и скопировать её представление в текстовый файл - пригодится! Теперь, переходим к новой версии, и копируем её представление в другой файл. Осталось только найти отличия! Ведь, кроме адреса строки, ничего не изменилось. Даже невооруженным взглядом можно найти различия трёх подряд идущих байтов. Но, почему трёх? Ведь указатель занимает четыре. Значит, нам не повезло. Один из байтов не изменился. Теперь, вопрос состоит в том, верхний (68), или нижний (00) относиться к адресу. Как видите, круг подозреваемых сузился. Строка почти найдена. Итак, возможные её адреса - либо 00450C28, либо 450C2868 (обратите внимание, байты в программе записаны в обратном порядке).
Теперь вопрос можно решить, просто посмотрев, что находится в памяти по этим адресам у работающей программы. Как это сделать? Есть несколько способов, предлагаю использовать для этого шестнадцатеричный редактор с функцией редактирования памяти. Рекомендую WinHex, как мощный, и в то же время весьма удобный редактор (доступен на сайте www.winhex.com). Запускаем его, заходим в меню Tools -> RAM Editor. Выбираем в списке работающих программ нашу, раскрываем дерево, выбираем "Entire memory" ("Вся память"). Жмем ОК.

Появилась таблица из трех колонок, чем-то напоминающая наши с вами недавно изучаемые. Данные представлены в средней и в правой - как шестнадцатеричные коды, и как символы, соответственно. А в левой колонке показаны смещения.
Нажимаем Alt+G, чтобы перейти к нужному смещению. Итак, вводим первое - 00450C28, и сразу же - удача! Строка найдена. Кстати, оказалось что смещение 450C2868 вообще не принадлежит нашей программе (проверьте). Отлично, коллега, вот мы и распутали это дело.
Эпилог
Вот, пожалуй, и закончено наше занимательное (надеюсь ![]() ), повествование, которое (опять же, надеюсь) помогло вам посмотреть на программирование в другом ракурсе и возбудило желание продолжить "низкоуровневые изыскания". Что ж, если так, то пишите мне о том, что вас интересует, и, я надеюсь, вскоре у него появится продолжение. Будьте здоровы!
), повествование, которое (опять же, надеюсь) помогло вам посмотреть на программирование в другом ракурсе и возбудило желание продолжить "низкоуровневые изыскания". Что ж, если так, то пишите мне о том, что вас интересует, и, я надеюсь, вскоре у него появится продолжение. Будьте здоровы!
- Обратиться в "Интерфейс" за дополнительной информацией/по вопросу приобретения продуктов
- Подробнее о продуктах Embarcadero / CodeGear
- Курсы обучения по продуктам компании Embarcadero/CodeGear
- Купить продукты компании Embarcadero Technologies в интернет-магазине itshop.ru
- Скачать демоверсии продуктов компании Embarcadero / CodeGear