Автор: Alex Поветкин, Королевство Delphi
Вступление
На написание этого опуса меня спровоцировала статья Юрия Кислякова "Реализация простейшего алгоритма распознавания графических образов", который, по моему скромному мнению очень удачно начал мысль о том, что распознавание образов не есть что-то сверхсуперсложное, не поддающееся разуму простых смертных. Давным-давно уже во многих областях техники используются различные автоматы и устройства, более или менее удачно решающие задачу распознавания (это и автомат для сортировки почтовых конвертов по индексу, и зенитная ракета, захватывающая горячее сопло самолетного двигателя, но игнорирующая солнце, и различные системы анализа спутниковых снимков, и голосовой вызов вашего мобильника, и многое-многое другое), тем не менее, людей, уверенных в непреодолимой сложности алгоритмов, очень много. В статье Юрия, однако, есть одно сильное, на мой взгляд, упущение: его программу невозможно обучать, т.к. у него сравнение происходит только с одним набором эталонов. Предложу вашему вниманию алгоритм, который можно обучать. Особую пикантность алгоритму придает тот факт, что его математическое обоснование было предложено советскими математиками в начале 60х годов (т.е. в то время, когда компьютер не всегда помещался в среднестатистической квартире), а еще лет через 15 была доказана его весьма глубокая аналогия с очень популярным в настоящее время нейросетевым методом. Итак,
Немного математики
Разумеется, для простоты мы будем рассматривать только черно-белые изображения. Пусть у нас рисунок состоит всего из двух пикселей. Тогда множество всех объектов, которое можно будет изобразить (универсальное множество), состоит из четырех объектов: (0,0), (0,1), (1,0), (1,1), где 1 - черный пиксель, 0 - белый.
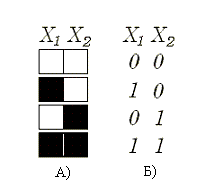
Рисунок 1
Все объекты универсального множества можно разместить в вершинах единичного квадрата, таким образом, множеству фигур, изображенных на двухпиксельном поле, может быть сопоставлено множество точек в двумерном пространстве. Ребру этого квадрата будет соответствовать переход от одного изображения к другому. Для перехода от (1,1) к (0,0) нужно будет пройти два ребра, для перехода от (0,1) к (0,0) - одно. Отметим, что число ребер в нашем переходе - это количество несовпадающих пикселей двух изображений. Вывод интересный: расстояние от одного рисунка до другого равно числу несовпадающих пикселей в них. Это расстояние называется расстоянием по Хэммингу .
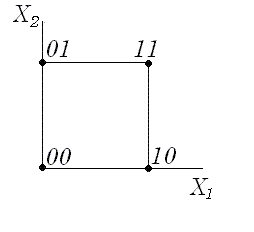
Рисунок 2
Теперь представим себе, что у нас рисунок состоит из трех пикселей. Коды изображений тогда будут состоять из трех значений, универсальное множество - из восьми элементов, которые мы разместим в вершинах единичного куба. Но принципиально ничего не изменится, и расстояние по Хэммингу вычисляется так же. В приложенной тестовой программе используется рисунок 50х70 = 3500 пикселей. Легко сообразить, что в этом случае код любого изображения состоит из 3500 значений, универсальное множество - из 23500 = 4,027 * 101053 элементов, которые мы будем размещать в вершинах единичного 3500-мерного куба. Представить себе такой 3500-мерный куб нелегко, но смысл от этого не меняется абсолютно. Основная идея заключается в том, что в этом многомерном кубе изображения, соответствующие какому-то определенному образу, лежат недалеко друг от друга. Эта идея получила название "Гипотеза о компактности образов".
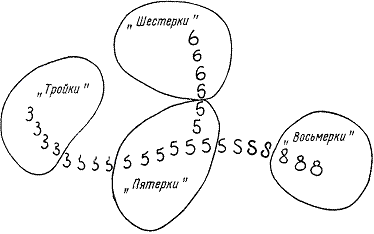
Рисунок 3
Теперь можно сформулировать задачу: нужно универсальное множество разбить на "куски", компактные множества, каждому из которых соответствует образ.
Реализация
А собственно реализация проста до безобразия, если вы разобрались в математической части. Программе в процессе обучения сообщаются изображения (точки многомерного куба) и указания, к какому образу каждое изображение относится. При распознавании программа просто смотрит, в какую из известных компактных областей попало входное изображение. Скорее всего, все указанные машине изображения лягут более-менее компактно, поэтому универсальное множество будет можно разделить. Собственно разделять универсальное множество мы не будем, а будем пользоваться некоторой характеристикой, которая показывает удаленность одного рисунка (точки в вершине многомерного куба) до группы таких же изображений. В качестве меры удаленности рисунка от группы рисунков используется потенциал.
Известно, что электрический заряд создает вокруг себя поле, одной из характеристик которого является потенциал. В любой точке он может быть вычислен по формуле
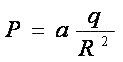
Рисунок 4
где a - некоторый постоянный коэффициент, q - величина заряда, R - расстояние от данной точки до заряда. Если электрическое поле образовано двумя или более зарядами, то потенциал в данной точке равен сумме потенциалов каждого заряда. Аналогия очевидна - каждый рисунок, на котором программа обучалась, создает в пространстве универсального множества потенциал. После обучения программе дают распознать какой-либо рисунок (точку в вершине многомерного куба), программа вычисляет потенциал, создаваемый в этой точке всеми объектами образа "а", образа "б"… на которых программу учили и распознаваемый рисунок относится к образу, который создал наибольший потенциал.
|
30 рублей за $1 на продукты Embarcadero Technologies До 27 марта в компании "Интерфейс" действует льготный курс - 30 рублей за $1- на все электронные лицензии программных продуктов Embarcadero Technologies. |
Программа
Итак, при запуске программы в массив Data: array of array [0..9] of TBitmap; записываются цифры от 0 до 9, написанные следующими шрифтами: Arial, Century Gothic, Courier New Cyr, Goudy Old Style и Times New Roman - всего пять комплектов (можно легко увеличить). Все эти изображения были сохранены мною и заботливо выложены в папку \fonts (более опытный программист, нежели я, наверняка сделал бы отрисовку, чтобы не мучаться с файлами).
|
После загрузки эталонных изображений пользователь рисует на поле размером 50х70 пикселей цифру, которую программа будет распознавать. При нажатии кнопки "распознать" высчитываются расстояния от распознаваемого рисунка до каждого из эталонных (расстояние по Хэммингу).
|
Зная это расстояние R, легко вычислить потенциал, создаваемый каждым эталонным рисунком в точке, соответствующей нарисованному пользователем изображению. Я немного изменил формулу расчета потенциала, чтобы избежать деления на 0 в случае R=0 и для лучшего восприятия домножил на 1 000 000:
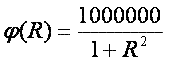
Рисунок 5
Потенциалы, создаваемые нулями всех начертаний, суммируются в p[0], единицами - в р[1] и так далее.
|
Бесплатный семинар: "Borland ALM. Средства обеспечения жизненного цикла разработки ПО" 29 мая компания "Интерфейс" проводит бесплатный семинар: "Borland ALM. Средства обеспечения жизненного цикла разработки ПО" |
|
После всего этого остается найти, какому образу соответствует наибольший потенциал.
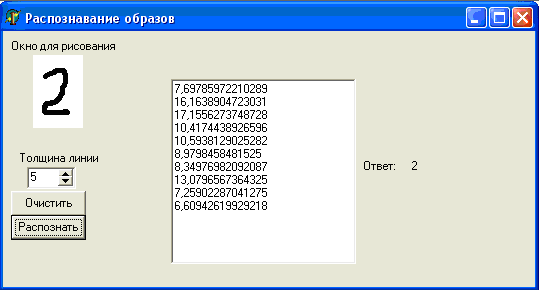
Рисунок 6
Заключение
Предложенный метод дает весьма неплохие результаты как на машинописных, так и на рукописных цифрах. Алгоритм легко может быть переобучен для различения других символов (латинских/русских букв, знаков препинания и т.п.). Для повышения надежности распознавания можно предусмотреть сильно различающиеся между собой эталоны (для того, чтобы как можно сильнее разбросать эталонные точки в пределах компактного множества). Для распознавания цифр я еще использовал такой прием: исходный рисунок разбивался на 7 участков по вертикали и 5 по горизонтали, участок целиком заливался белым либо черным в зависимости от того, каких пикселей участок содержал больше, после чего работа с каждым участком происходила как с пикселем. Очевидно, что после такого фокуса 99.9% восьмерок, написанных и от руки, и машинописных, будут иметь вид

Рисунок 7
после чего работать с таким изображением легко и приятно.
Буду очень рад, если моя статья кому-то будет полезна.