Предыдущая часть
© Наталия Елманова
Статья была опубликована в КомпьютерПресс 10'2003
- Средства Data Mining корпорации Microsoft
- Что такое кластеризация
- Постановка задачи
- Создание кластеров
- Результаты кластеризации
В предыдущей части данной статьи мы выяснили, что представляют собой современные технологии поиска закономерностей в данных (Data Mining), а также кратко рассмотрели основные алгоритмы осуществления подобного поиска.
Теперь мы продолжим рассказ об этой технологии и представим вам некоторые практические аспекты ее применения на примере средств Data Mining корпорации Microsoft - одного из претендентов на лидерство на рынке средств разработки решений Business Intelligence. Средства Data Mining входят в состав аналитических служб Microsoft SQL Server 2000, которые, в свою очередь, включены в комплект поставки СУБД Microsoft SQL Server 2000, что делает Data Mining одним из наименее затратных способов решения задач подобного класса.
Средства Data Mining корпорации Microsoft
Средства Data Mining, входящие в комплект поставки Microsoft SQL Server 2000, содержат реализацию двух популярных алгоритмов:
- Microsoft Decision Trees - алгоритм построения так называемых деревьев решений, основанных на создании иерархической структуры, которая базируется на ответе "Да" или "Нет" на набор вопросов;
- Microsoft Clustering - алгоритм, основанный на объединении сходных событий в группы на базе сходных значений нескольких полей в наборе данных.
Кроме того, средства Data Mining компании Microsoft позволяют подключать библиотеки независимых производителей, реализующие другие алгоритмы поиска закономерностей. Согласно сведениям, полученным от менеджеров Microsoft, ответственных за данную линейку продуктов, следующая версия Microsoft SQL Server под кодовым названием Yukon будет содержать еще более внушительный набор алгоритмов.
В настоящей статье мы рассмотрим применение кластеризации и алгоритма Microsoft Clustering. Однако прежде выясним, что представляет собой кластеризация.
Что такое кластеризация
Людям свойственно классифицировать и группировать все объекты и явления, с которыми они сталкиваются, и на основе отнесения объекта к той или иной группе пытаться предсказывать его поведение. Например, мы оцениваем опасность, исходящую от пробегающей мимо собаки, по ее размеру, принадлежности к той или иной породе, наличию у нее ошейника и присутствию рядом хозяина, бессознательно относя ее к определенной группе собак, типичное поведение которых считается более или менее известным.
В качестве еще одного примера групп (или кластеров) можно привести возрастной состав участников демонстрации против введения повременной оплаты за телефонные разговоры, состоявшейся в одном из крупных российских городов несколько лет назад. Эта демонстрация состояла в основном из молодых людей преимущественно мужского пола (пользователей Интернета) и очень пожилых людей преимущественно женского пола (одиноких пенсионерок, для которых телефон - практически единственное средство общения с друзьями). При этом в демонстрации практически не участвовали ни люди среднего возраста, ни дети. Схематически состав этих групп можно изобразить так, как это представлено на рис. 1.
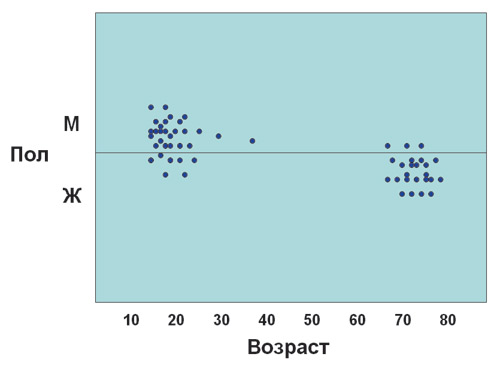
рис. 1
Иными словами, можно сказать, что типичный участник данной демонстрации принадлежит с высокой долей вероятности к одной из двух указанных групп и что вероятность участия в ней человека среднего возраста невелика. Впрочем, данный пример крайне прост (наблюдаемых параметров в нем всего два - возраст и пол), равно как и логическое объяснение полученных данных. В более сложных случаях закономерности, по которым группируются объекты или события, не столь очевидны, особенно если число параметров велико.
Обычно алгоритмы кластеризации используются в тех случаях, когда нет абсолютно никаких предположений о характере взаимосвязи между данными, а результаты их применения нередко являются исходными данными для других алгоритмов, например для построения деревьев решений.
Как же работают подобные алгоритмы? Обычно они осуществляют итеративный поиск групп данных на основании заранее заданного числа кластеров. Изначально центры будущих кластеров представляют собой случайным образом выбранные точки в n-мерном пространстве возможных значений (где n - число параметров). Затем все исходные данные перебираются и в зависимости от значений параметров помещаются в тот или иной кластер, при этом постоянно происходит поиск точек, сумма расстояний которых до остальных точек в данном кластере является минимальной. Эти точки становятся центрами новых кластеров, и процедура повторяется до тех пор, пока центры и границы новых кластеров не перестанут перемещаться.
Отметим, что данный алгоритм далеко не всегда приводит к результату, поддающемуся логическому объяснению, - он просто позволяет определить различные группы объектов или событий. Кроме того, не всегда можно с первого раза точно угадать число кластеров, отражающее реально существующее число групп.
Выяснив, что такое кластеризация, рассмотрим пример ее реализации. Для выполнения примера нам потребуется Microsoft SQL Server 2000 (Enterprise Edition, Standard Edition или Personal Edition) с установленными аналитическими службами, причем можно использовать и ознакомительную версию.
Постановка задачи
В качестве примера применения кластеризации рассмотрим принцип действия антиспамового фильтра, назначение которого - принять решение о том, является ли данное письмо несанкционированно рассылаемой рекламной информацией. Действие подобного фильтра может базироваться на разных алгоритмах, но, как правило, состоит из двух процессов: настройки фильтра (которая выполняется либо однократно, либо периодически, но не часто) и принятия решения о том, относится ли спама конкретное письмо к категории (что происходит намного чаще, чем настройка фильтра).
Один из возможных алгоритмов настройки антиспамового фильтра выглядит следующим образом. Берется большое количество писем, о которых точно известно, принадлежат ли они к несанкционированно рассылаемой рекламе. Далее для каждого письма вычисляется частотность встречающихся в нем определенных, заранее заданных слов, словосочетаний или символов. Сведения об этом наборе служат исходными данными для процесса создания кластеров согласно описанному выше алгоритму (этот процесс в некоторых источниках называется model training - тренировка модели). Принятие решения о принадлежности конкретного письма к категории спама осуществляется на основании того, в какой кластер попадет данное письмо. Заметим, что алгоритм действия коммерческих антиспамовых фильтров может быть сложнее - данная статья отнюдь не претендует на детальный разбор принципов их работы.
В качестве примера исходных данных воспользуемся набором сведений о более чем 4 тыс. писем, изученных сотрудниками компании Hewlett-Packard в 1999 году. Этот набор данных, доступный в виде файла в формате CSV по адресу www.ics.uci.edu/~mlearn/MLRepository.html (на указанном сайте находится довольно много интересных баз данных, которые разрешено свободно применять в научных целях), содержит одну таблицу, в которой имеется колонка IsSpam с целочисленными значениями (1 - письмо является спамом, 0 - письмо не является таковым), а также большое количество колонок с частотностью различных английских слов. Для упрощения работы с этим набором данных импортируем его в какую-нибудь СУБД, например в Access или Microsoft SQL Server. Имеет также смысл создать автоматически заполняемое целочисленное ключевое поле, которое потребуется при создании модели Data Mining на основе этих данных (рис. 2).
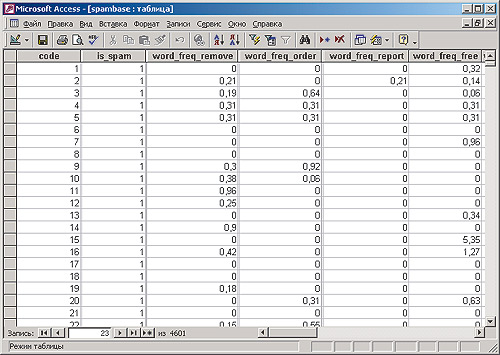
рис. 2
Итак, можно приступить к созданию кластеров.
Создание кластеров
ля создания кластеров следует запустить инструмент администрирования аналитических служб Microsoft SQL Server Analysis Manager (мы не будем останавливаться на подробностях применения данного инструмента; интересующиеся этим вопросом могут обратиться к циклу статей "Введение в OLAP", опубликованному в нашем журнале в 2001 году, - найти его можно на компакт-диске, прилагаемом к этому номеру журнала). С помощью Analysis Manager следует создать новую многомерную базу данных (назовем ее MyMiningData) и описать в ней доступ к источнику исходных данных (в нашем случае - к базе данных Access; рис. 3).
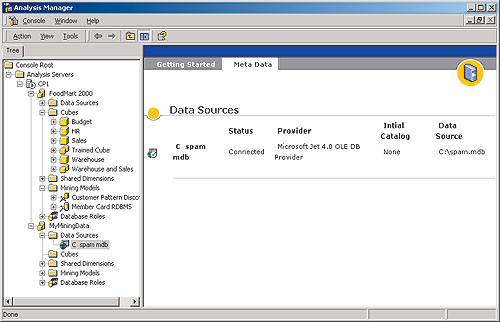
рис. 3
Далее следует выбрать соответствующую дочернюю ветвь Mining Models, а из ее контекстного меню - пункт New Mining Model. Затем нужно ответить на вопросы мастера построения моделей Data Mining. В частности, необходимо указать следующее: для построения модели используются реляционные данные, применяется алгоритм Microsoft Clustering, данные для анализа расположены в одной таблице (при этом следует выбрать ее имя). Затем в этой таблице нужно выбрать поле, являющееся уникальным идентификатором каждого письма в наборе (case key), а также поля, которые будут использоваться в качестве параметров для построения кластеров. В нашем примере из имеющихся в таблице нескольких десятков полей, соответствующих частоте употребления в письмах разных слов и символов, мы выбрали десять (рис. 4).
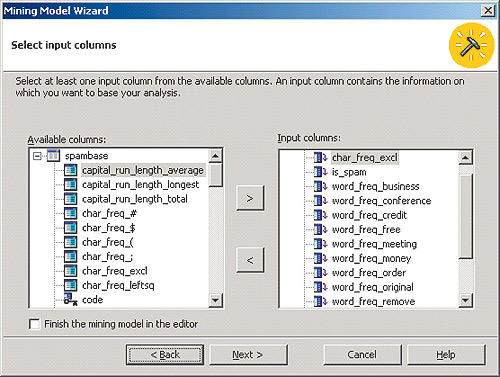
рис. 4
Завершить создание модели можно в редакторе Relational Mining Model Editor, указав в свойствах модели число кластеров (пусть оно будет равно пяти). Создание самих кластеров осуществляется с помощью выбора пункта меню Tools ® Process Mining Model (рис. 5).
рис. 5
Ниже мы рассмотрим, что представляют собой полученные кластеры.
Результаты кластеризации
тобы увидеть результаты кластеризации, нужно выбрать пункт View ® Content в меню редактора Relational Mining Model Editor. Здесь можно изучить свойства полученных пяти кластеров, выбирая их последовательно в разделе Content Detail. В нашем примере наибольший интерес представляют первые два из них - самые большие по объему: 1806 и 1114 из 4681. В одном значении поля IsSpam для всех членов кластера оказалось равным нулю (что означает, что письмо, параметры которого соответствуют этому кластеру, с высокой вероятностью не является спамом), в другом - единице (это означает, что письмо, параметры которого соответствуют данному кластеру, с очень высокой вероятностью является спамом; данный кластер показан на рис. 6).
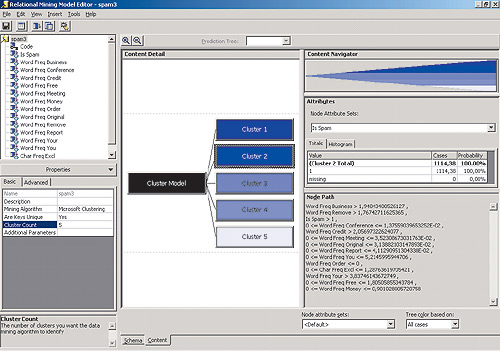
рис. 6
Третий кластер (653 письма) также практически не содержит данных, относящихся к категории спама, а в оставшихся двух кластерах имеются данные обеих категорий (то есть письма с подобными характеристиками могут оказаться как спамом, так и обычными деловыми или личными посланиями).
Таким образом, мы создали модель настройки антиспамового фильтра. Применение его вполне очевидно - принятие решения о том, относится ли письмо к категории спама, зависит от того, в какой из полученных кластеров оно попадет.
Может возникнуть вопрос: почему при построении данной модели было выбрано именно пять кластеров? На практике выбор числа кластеров во многом является итеративным процессом. В данном случае это было минимальное число, при котором появились кластеры, данные в которых характеризовались одним и тем же значением параметра IsSpam, поскольку именно это позволяет принять решение, которое с большой долей вероятности окажется правильным (если 1114 писем из 4681 с параметрами, характерными для данного кластера, были спамом, то, скорее всего, 1115-е также окажется спамом).
Отметим, что методы анализа, основанные на кластеризации, нередко применяются для решения многих других задач, например при оценке кредитных и страховых рисков.
В следующей части статьи мы продолжим рассказ о моделях и алгоритмах Data Mining.
Литература
- Seidman C. Data Mining with Microsoft SQL Server 2000. Technical Reference. - Microsoft Press, 2001.
- Ville B.de. Microsoft Data Mining. - Digital Press, 2001.