1. Введение. Проблема перехода в архитектуру клиент-сервер.
В 80-х и начале 90-х годов в нашей стране было создано множество программных продуктов, предназначенных для автоматизации деятельности предприятий и организаций. Как правило, такие приложения были реализованы в архитектуре файл-сервер и для их создания применялись весьма популярные тогда средства разработки приложений Clipper, FoxPro или Paradox. В современных условиях перед предприятиями встают задачи, которые файл-серверные приложения решить не могут или решают недостаточно эффективно, а именно:
- Обеспечение высокой производительности при оперативной работе большого количества пользователей.
- Обеспечение высокой производительности при анализе информации (выполнении аналитических отчетов).
- Обеспечение информационной безопасности предприятия.
Перевод информационной инфраструктуры предприятия на современные архитектуры и технологии может оказаться непростой задачей. Между тем, довольно часто приходится встречаться с упрощеныым подходом к решению проблемы. Переход от архитектуры файл-сервер к архитектуре клиент-сервер при таком подходе заключается в следующем:
- Проводится обратное проектирование структуры данных файл-серверного приложения. Заметим, что для обратного и прямого проектирования может быть использован CA Erwin).
- Модель данных конвертируется 1:1 в структуру реляционного сервера и проводится прямое проектирование системного каталога реляционной СУБД.
- С помощью какого-либо инструмента (купленной или созданной самостоятельно утилиты) данные переносятся из файлов Paradox или dbf в реляционную СУБД.
- Проводятся минимальные изменения клиентской части (например, переписывается модуль, ответственный за доступ к данным).
Затраты на работы по переводу на клиент-серверную платформу при таком подходе минимальны. Но, как правило, полученный результат не удовлетворяет заказчика. Не решается ни одна из перечисленных выше задач. Более того, тестирование полученного клиент-серверного приложения в однопользовательском режиме часто показывает более низкую производительность по сравнению с исходным файл-серверным. Причиной этому является низкая эффективность использования реляционной СУБД. Современные СУБД имеют развитые средства как для обеспечения высокой производительности так и обеспечения безопасности данных и способны обеспечить высокоэффективную обработку данных на стороне сервера. Все эти возможности при упрощенном подходе не используются. В полученном клиент-серверном приложении сервер работает вхолостую.
Для обеспечения требований производительности и безопасности требуется другой подход, который хотя и требует больших ресурсов, приводит к созданию действительно эффективной информационной системы. Для создания высокопроизводительного клиент-серверного приложения должны быть реализованы следующие этапы.
- Обратное проектирование структуры данных
- Построение логической модели. Целью этого этапа является исключение избыточности при хранении данных и ликвидация аномалий при операциях вставки, удаления и редактирования.
- Создание диаграммы сущность связь на основе модели данных файл-серверного приложения.
- Определение ключей (дополнение до уровня модели данных, основанной на ключах).
- Построение полной атрибутивной модели (нормализация)
- Проверка логической модели данных.
- Построение физической модели на основе созданной логической модели. Основной целью создания физической модели является повышение производительности информационной системы.
- Денормализация.
- Настройка индексов и создание объектов физической памяти.
- Перенос функциональности на сервер, в том числе создание процедур и триггеров.
- Обеспечение информационной безопасности средствами СУБД, в том числе за счет предоставления и лишения привилегий, создания временных таблиц, процедур и триггеров
- Создание хранилищ данных. Целью этого этапа является обеспечение высокой производительности при анализе информации.
- Прямое проектирование системного каталога реляционной СУБД.
- Перенос данных из файлов Paradox или dbf в реляционную СУБД.
- Изменения клиентской части.
Ниже будет подробно рассмотрена реализация этапов 1-7 с помощью CASE-средств фирмы Computer Associated.
2. Обратное проектирование структуры данных из файлов Paradox или dbf.
Создание модели данных существующих файлов Paradox или dbf (обратное проектирование) может быть осуществлено автоматически с помощью Erwin - CASE-средства нижнего уровня фирмы Computer Associated. Erwin поддерживает работу более чем с 20-ю СУБД различных производителей, в том числе с файлами Paradox или dbf.
Для выполнения обратного проектирования в главном меню Erwin следует выбрать пункт Tasks / Reverse Engineer…
Рис. 1 Диалог ERwin Template Selection.
При этом возникает диалог ERwin Template Selection (рис. 1), в котором нужно выбрать шаблон диаграммы, затем диалог выбора СУБД, в котором необходимо выбрать тип базы данных (рис 2):
Access;
Clipper;
DBase III;
DBase IV;
FoxPro;
Paradox;
Рис. 2. Диалог Reverse Engineer - Select Target Server/
и, наконец, диалог задания опций обратного проектирования Reverse Engineer - Set Options (рис. 3).

Рис. 3. Диалог Reverse Engineer - Set Options.
В диалоге Reverse Engineer - Set Options можно задать следующие опции:
Группа Reverse Engineer From позволяет задать источник обратного проектирования - базу данных или SQL (DDL) -скрипт. При помощи кнопки Browse можно выбрать текстовый файл, содержащий SQL -скрипт.
Группа Items to Reverse Engineer позволяет задать объекты БД, на основе которых будет создана модель. При помощи списка выбора Option Set, а также кнопок New, Update и Delete можно создавать и редактировать именованные конфигурации объектов БД, которые могут быть использованы многократно при других сеансах обратного проектирования.
Группа Reverse Engineer (доступна только при обратном проектировании из БД) позволяет включить в модель системные обьекты (окно выбора System Objects) и установить фильтр на извлекаемые таблицы по их владельцу.
Установка опции Primary Keys в группе Infer означает, что ERwin будет генерировать первичные ключи на основе анализа индексов. Если включена опция Relations, ERwin будет устанавливать связи на основе имен колонок первичного ключа или индексов. Эти опции имеют смысл, только если связи не прописаны явно.
Группа Case Conversion позволяет задать опции конвертации регистра при создании логических и физических имен модели.
После установки необходимых опций можно щелкнуть по кнопке Next, после чего появляется диалог связи с БД, устанавливается сеанс связи с сервером (для настольных БД должен быть установлен и настроен ODBC - драйвер и начинается процесс обратного проектирования, во время которого показывается статус процесса в диалоге Reverse Engineer -Status. В результате процесса создается новая модель данных.
3. Построение логической модели данных.
Основные компоненты диаграммы Erwin - это сущности, атрибуты и связи. Каждая сущность является множеством подобных индивидуальных объектов, называемых экземплярами. Каждый экземпляр индивидуален и должен отличаться от всех остальных экземпляров. Атрибут выражает определенное свойство объекта. С точки зрения БД (физическая модель) сущности соответствует таблица, экземпляру сущности - строка в таблице, а атрибуту - колонка таблицы.
Построение модели данных предполагает определение сущностей и атрибутов, то есть необходимо определить, какая информация будет храниться в конкретной сущности или атрибуте. Erwin имеет набор инструментов для создания логической модели -палитра и панель инструментов, диалоги редактирования связей, сущностей и атрибутов, инструмент создания независимых атрибутов, различные уровни представления модели, инструменты работы с большими моделями. Поддерживаются нотации IDEF1X и IE.
Различают три уровня логической модели, отличающихся по глубине представления информации о данных:
- диаграмма сущности - связь (Entity Relationship Diagram, ERD);
- модель данных, основанная на ключах (Key Based model, KB);
- полная атрибутивная модель (Fully Attributed model, FA).
Диаграмма сущность-связь представляет собой модель данных верхнего уровня. Она включает сущности и взаимосвязи, отражающие основные бизнес-правила предметной области. Такая диаграмма не слишком детализирована, в нее включаются основные сущности и связи между ними, которые удовлетворяют основным требованиям, предъявляемым к информационной системе. Диаграмма сущность-связь может включать связи многие-ко-многим и не включать описание ключей. Как правило, ERD используется для презентаций и обсуждения структуры данных с экспертами предметной области. Для создания ERD на основе полученной в результате обратного проектирования модели данных файлов Paradox или dbf следует описать основные первичные ключи и установить связи между сущностями (рис. 4).

Рис. 4. Фрагмент диаграммы сущность-связь.
Модель данных, основанная на ключах - более подробное представление данных. Она включает описание всех сущностей и первичных ключей и предназначена для представления структуры данных и ключей, которые соответствуют предметной области. Erwin поддерживает проектирование следующих типов ключей:
Первичный ключ. Атрибуты первичного ключа показываются в верхней части списка атрибутов сущности.
Внешний ключ. Создается автоматически при создании связи и помечаются символами (FK).
Альтернативный ключ - это ключ, который идентифизирует экземпляр сущности, но не выбран в качестве первичного. ERwin позволяет выделить атрибуты альтернативных ключей и по умолчанию в дальнейшем при генерации схемы БД по этим атрибутам будет генерироваться уникальный индекс.
При работе информационной системы часто бывает необходимо обеспечить доступ к нескольким экземплярам сущности, объединенным каким-либо одним признаком. Для повышения производительности в этом случае используются неуникальные индексы. ERwin позволяет на уровне логической модели назначить атрибуты, которые будут участвовать в неуникальных индексах.
Атрибуты, участвующие в неуникальных индексах, называются Inversion Entries (инверсионные входы). Inversion Entry - это атрибут или группа атрибутов, которые не определяют экземпляр сущности уникальным образом, но часто используются для обращения к экземплярам сущности. ER win генерирует неуникальный индекс для каждого Inversion Entry. Для редактирования альтернативных ключей и инверсионных входов используется закладка Key Group диалога Attribute Editor (рис.5).
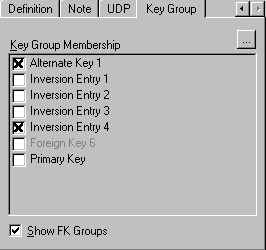
Рис.5. Закладка Key Group диалога Attribute Editor.
Полная атрибутивная модель - наиболее детальное представление структуры данных - представляет данные в третьей нормальной форме и включает все сущности, атрибуты и связи. Для построения полной атрибутивной модели необходима нормализация.
Нормализация - это процесс проверки и реорганизации сущностей и атрибутов с целью удовлетворения требований к реляционной модели данных. Нормализация позволяет быть уверенным, что каждый атрибут определен для своей сущности, значительно сократить объем памяти для хранения информации и устранить аномалии в организации хранения данных. В результате проведения нормализации должна быть создана структура данных, при которой информация о каждом факте хранится только в одном месте. Процесс нормализации сводится к последовательному приведению структуры данных к нормальным формам - формализованным требованиям к организации данных. Необходимо приведение структуры данных к трем нормальным формам - первой второй и третьей.
Первая нормальная форма (1NF). Сущность находится в первой нормальной форме тогда и только тогда, когда все атрибуты содержат атомарные значения. Среди атрибутов не должно встречаться повторяющихся групп, то есть несколько значений для каждого экземпляра.
Вторая нормальная форма (2NF). Сущность находится во второй нормальной форме, если она находится в первой нормальной форме и каждый неключевой атрибут полностью зависит от первичного ключа (не должно быть зависимости от части ключа). Вторая нормальная форма имеет смысл только для сущностей, имеющих сложный первичный ключ.
Для приведения сущности ко второй нормальной форме следует
- выделить атрибуты, которые зависят только от части первичного ключа,
- создать новую сущность,
- поместить атрибуты, зависящие от части ключа в их собственную (новую) сущность,
- установить идентифицирующую связь от прежней сущности к новой.
Третья нормальная форма (3NF). Сущность находится в третьей нормальной форме, если она находится во второй нормальной форме и никакой неключевой атрибут не зависит от другого неключевого атрибута. (Не должно быть взаимозависимости между неключевыми атрибутами).
Для приведения сущности ко второй нормальной форме следует
- создать новую сущность и перенести в нее атрибуты с одной и той же зависимостью от неключевого атрибута,
- использовать атрибут(ы), определяющий эту зависимость, в качестве первичного ключа новой сущности,
- установить неидентифицирующую связь от новой к старой сущности.
ERwin не содержит полный алгоритм нормализации и не может проводить нормализацию автоматически, однако его возможности облегчают создание нормализованной модели данных. Запрет на присвоение неуникальных имен атрибутов в рамках модели (при соответствующей установке опции Unique Name) облегчает соблюдение правила "один факт - в одном месте". Имена ролей атрибутов внешних ключей и унификация атрибутов также облегчает построение нормализованной модели.
После построения полной атрибутивной модели необходимо проверить качество полученной модели. До недавнего времени эта задача решалась вручную и требовала значительных ресурсов. В октябре 2000 года компания Computer Associates выпустила новый программный продукт серии ER win - ER win Examiner. Этот основанный на базе знаний инструмент позволяет анализировать структуру баз данных с целью выявления недочетов и ошибок проектирования. ER win Examiner дополняет функциональность Erwin ERX, автоматизируя трудоемкую задачу поиска и исправления ошибок, и одновременно повышая квалификацию модельщиков данных благодаря встроенной системе обучения. Принципиальная схема работы ER win Examiner показана на рис.6.

Рис.6. Принципиальная схема работы ERwin Examiner.
ER win Examiner поддерживает работу со следующими СУБД:
- ORACLE 7 и 8 (SQL*NET или NET 8);
- DB2 версии DB2 for OS390 версий 4 и 5 (DB2 Connect);
- DB2 Universal Database версии 4, 5 и 6;
- Microsoft SQL Server версий 6 и 7 (32 разрядный ODBC драйвер);
- Sybase версий 10 и 11 (32 разрядный ODBC драйвер).
Ошибки, определяемые и исправляемые с помощью ER win Examiner, объединены в четыре категории. В первую категорию (Columns) входят ошибки проектирования колонок. Ниже приведен фрагмент списка ошибок этой категории:
- Inconsistent Definition. Название колонки встречается в различных таблицах, но при этом колонки (или их синонимы) имеют разные определения. Это может привести к сохранению неверных данных.
- Groups with Inconsistent Definition. Группа колонок, нарушающих первую нормальную форму имеет противоречивое взаимное определение.
- Duplicate Table. Имя таблицы неуникально в модели.
- Table with No Columns. Таблица не имеет колонок.
- Data Names Conflict with SQL Keywords. Имя является резервированным словом.
Вторая категория объединяет ошибки проектирования индексов и ограничений(Indexes and Constraints). В эту группу входят следующие ошибки:
- Incorrectly Defined Foreign Keys. Некорректное определение внешнего ключа, не обеспечивающее правила ссылочной целостности.
- Candidate Keys with All Nullable Columns. Уникальные индексы или/и первичные ключи содержат колонки null, что может привести к дублированию строк.
- Improperly Defined Indexes. По меньшей мере один индекс имеет аномалии.
- Undefined Alternate Keys. Таблица имеет суррогатный первичный ключ и не имеет альтернативного ключа.
- Different CHECK Constraints. Несколько колонок определены в разных таблицах, но имеют разные ограничения CHECK.
- Tables without a Candidate Key. Таблица не имеет ограничений, гарантирующих уникальность записи (PK, Unique Constraint или Unique Index).
- Disabled Constraints. Неверное ограничение.
- Tables with No Clustered Index. Таблица должна иметь кластеризованный индекс.
- Primary Key with Columns Allowing Decimals. Колонка первичного ключа содержит числовую колонку с десятичными знаками, например, типа REAL.
- Unnecessary CHECK Constraints. Ненужные ограничения, например, ограничения на внешнем ключе дочерней таблицы вместо ограничения на первичном ключе родительской.
- Unnecessary Indexes. Ненужные индексы.
- Unnecessary Foreign Keys. Ненужные внешние ключи, например, если целостность уже поддерживается другими внешними ключами.
- Missing Indexes. Отсутствие индексов, например на внешнем ключе.
- Tables with Too Many Indexes. Таблица содержит слишком много индексов.
- Indexes with Too Many Columns. Индекс содержит слишком много колонок.
- Primary Keys with Too Many Columns. Первичный ключ содержит слишком много колонок.
- Indexes with Variable Length Columns. Индекс содержит колонки переменной длины VARCHAR (только для DB2).
- Conflicting Indexes. Конфликтующие индексы.
- Tables with No Relationships. Таблица не имеет связей.
- Delete Cascade/Restrict Conflicts. Ограничение ссылочной целостности для внешнего ключа определено как ON DELETE CASCADE, а дочерняя таблица имеет по крайней мере один внешний ключ без этой опции, поэтому автоматическая ссылочная целостность не может поддерживаться для "внучатой" таблицы.
Третья категория объединяет ошибки нормализации (Normalization). Находятся некорректно определенные функциональные зависимости и ошибки первой, второй и третьей нормальной формы.
В четвертую категорию входят ошибки связей (Relationships):
- Incorrect Recursive Relationships. Некорректно определенная рекурсивная связь. Внешний ключ рекурсивной связи должен включать по крайней мере одну колонку NULL, в противном случае возникает коллизия при вставке.
- Disabled Relationships. Недоступная связь - ссылочный ключ связи недоступен.
- Non-Enforceable Relationships. Связи, не имеющие определения внешнего ключа.
- Mismatched Foreign Keys. Имеются аномалии во внешних ключах.
- Infinite Loops. Бесконечные циклы. Существует цикл между таблицами и внешние ключи не имеют свойства NULL. При этом вставка данных невозможна.
- Tables with Too Many Relationships. Таблица имеет слишком много связей, это может привести к потере производительности.
- Cross Linked Relationships. Между таблицами существует цикл и внешние ключи не имеют свойства NULL. Вставка данных невозможна.
- Incompatible Relationships. Связь, основанная на колонке с разными типами или определениями.
Результатом диагностики ошибок может стать отчет генерация SQL- скрипта, корректирующего ошибки моделирования.
Ключевой возможностью ER win Examiner является возможность обучения модельщиков данных. При вызове описания ошибки (кнопка "i" слева от имени ошибки в закладке Diagnostics) появляется диалог с описанием ошибки, содержащий кнопку Teach Me. Щелчок по этой кнопке вызывает справку по данной проблеме, включая примеры и описание путей решения проблемы. Следовательно, модельщики данных обучаются в первую очередь тем темам, которые они плохо знают.
Помимо выявления ошибок, ER win Examiner позволяет также сравнивать модели данных и сливать модели. Для работы с большими моделями предусмотрена удобная навигация по модели и работа с подмоделями, причем диагностика может быть проведена в рамках отдельной подмодели.
4. Построение физической модели данных.
Физическая модель содержит всю информацию, необходимую для реализации конкретной БД. Физический уровень представления модели зависит от выбранного сервера. ERwin поддерживает практически все распространенные СУБД, всего более 20 реляционных и нереляционных баз данных, при этом он позволяет учесть особенности реализации конкретной СУБД.
Основными объектами физической модели являются таблицы и колонки. ERwin автоматически создает имена таблиц и колонок на основе имен соответствующих сущностей и атрибутов, учитывая максимальную длину имени и другие синтаксические ограничения, накладываемые СУБД. При генерации имени таблицы или колонки по умолчанию все пробелы автоматически преобразуются в символы подчеркивания, а длина имени обрезается до максимальной длины, допустимой для выбранной СУБД. Для модификации таблиц и колонок в Erwin используются редакторы Table Editor и Column Editor.
Денормализация. В результате нормализации все взаимосвязи данных становятся правильно определены, исключаются аномалии при оперировании с данными, модель данных становится легче поддерживать. Однако, часто нормализация данных не ведет к повышению производительности информационной системы в целом. В результате нормализации вместо одной таблицы может появится несколько. Хотя общее количество строк в этих таблицах может быть меньше, чем в исходной (до нормализации), теперь для получения полной информации о серверу БД необходимо обращаться одновременно к нескольким таблицам (объединение таблиц, join). Время выполнения запроса с объединением может во много раз превосходить время выполнения запроса к одной таблице, общая производительность информационной системы в результате нормализации скорее всего упадет. В целях повышения производительности при переходе на физический уровень приходится сознательно отходить от нормальных форм для того, чтобы использовать возможности конкретного сервера или информационной системы в целом.
В отличие от процесса нормализации денормализация не может быть представлена в виде четко сформулированных правил. К сожалению, в каждом конкретном случае приходится искать конкретные решения, которые используют специфику информационной системы и предметной области и не могут быть тиражированы. Примером денормализации могут служить производные атрибуты, которые являются нарушением первой нормальной формы.
Денормализация проводится на уровне физической модели. ERwin позволяет сохранить на уровне логической модели нормализованную структуру, при этом построить на уровне физической модели структуру (возможно денормализованную), которая обеспечивает лучшую производительность, используя особенности конкретной СУБД и бизнес-правил предметной области. ERwin имеет следующую функциональность для поддержки денормализации:
- Сущности, атрибуты, ключи и домены можно создавать только на уровне логической модели, включив в соответствующих редакторах опцию Logical. Такие объекты не будут отображаться на уровне физической модели и не будут создаваться при генерации БД.
- Таблицы, колонки, домены и индексы можно создавать только на уровне физической модели
- При автоматическом разрешении связи многие-ко-многим в физической модели создается новая таблица и структура данных может быть дополнена только на уровне физической модели.
Настройка индексов и создание объектов физической памяти. ERwin позволяет создавать объекты физической памяти и настраивать индексы с учетом конкретной реализации СУБД. Эта особенность Erwin обеспечивает создание высокопроизводительных приложений для любой из выбранных СУБД. На рис.7 показана закладка ORACLE диалога Index Editor. Видно, что при проектировании индекса можно учесть специфические свойства СУБД Oracle.

Рис.7. Закладка ORACLE диалога Index Editor.
Перенос функциональности на сервер. Создание процедур и триггеров.
В информационных системах, созданных в архитектуре файл-сервер функциональность, поддерживающая бизнес-правила реализуется на стороне клиента. В результате для любой обработки данных их необходимо передать на рабочую станцию. Современные реляционные сервера позволяют значительную часть обработки данных проводить на стороне сервера, тем самым понижая трафик сети и повышая общую производительность системы.
В частности, целостность данных может поддерживаться сервером автоматически на основе правил ссылочной целостности. Правила ссылочной целостности (referential integrity, RI) - логические конструкции, которые выражают бизнес-правила использования данных и представляют собой правила вставки, замены и удаления. При генерации схемы БД на основе связей, создаваемых в логической модели, Erwin генерирует правила декларативной ссылочной целостности, которые должны быть предписаны для каждой связи, и триггеры, обеспечивающие ссылочную целостность.
Триггеры и хранимые процедуры - это именованные блоки кода SQL, которые заранее откомпилированы и хранятся на сервере для того, чтобы быстро производить выполнение запросов, валидацию данных и выполнять другие, часто вызываемые функции.
Хранение и выполнение кода на сервере позволяет создавать код только один раз, а не в каждом приложении, работающем с базой данных, что экономит время при написании и сопровождении программ. При этом гарантируется, что целостность данных и бизнес - правила поддерживаются независимо от того, какое именно клиентское приложение обращается к данным. Триггеры и хранимые процедуры не требуется пересылать по сети из клиентского приложения, что значительно снижает сетевой трафик.
Хранимой процедурой называется именованный набор предварительно откомпилированных команд SQL, который может вызываться из клиентского приложения или из другой хранимой процедуры.
Триггером называется процедура, которая выполняется автоматически, как реакция на событие. Таким событием может быть вставка, изменение или удаление строки в существующей таблице. Триггер сообщает СУБД, какие действия нужно выполнить при выполнении команд SQL INSERT, UPDATE или DELETE для обеспечения дополнительной функциональности, выполняемой на сервере.
Триггер ссылочной целостности - особый вид триггера, используемый для поддержания целостности между двумя таблицами, которые связаны между собой. Если строка в одной таблице вставляется, изменяется или удаляется, то триггер ссылочной целостности (RI-триггер) сообщает СУБД, что нужно делать с теми строками в других таблицах, у которых значение внешнего ключа совпадает со значением первичного ключа вставленной (измененной, удаленной) строки. По умолчанию ERwin генерирует триггеры, дублирующие декларативную ссылочную целостность. Например, если удаляется клиент из таблицы CUSTOMER, рис. 8, то в зависимости от установленных правил ссылочной целостности могут быть сгенерированы RI-триггеры, которые будут воздействовать на соответствующие удаляемому клиенту заказы из таблицы ORDER. Команда DELETE может быть обработана следующими способами:
- Проверяется наличие заказов у удаляемого клиента и если заказы есть, то запрещается удаление клиента из таблицы CUSTOMER . Правило ссылочной целостности, запрещающее вставку, изменение или удаление строки, называется RESTRICT.
- Клиент удаляется из таблицы CUSTOMER и все соответствующие ему строки в таблице ORDER также автоматически удаляются. Правило ссылочной целостности, передающее изменение от одной таблицы к другой, называется CASCADE . При этом все заказы удаленного клиента теряются. Если эту информацию необходимо сохранить, можно переопределить триггер ссылочной целостности так, чтобы записать, например, эту информацию в архивную таблицу.
- Клиент удаляется, но номеру клиента в таблице заказов, автоматически присваивается нулевое значение. Правило ссылочной целостности, изменяющее текущее значение данных на нулевое, называется SET NULL.

Рис.8
Для генерации триггеров ERwin использует механизм шаблонов - специальных скриптов, использующих макрокоманды. При генерации кода триггера вместо макрокоманд подставляются имена таблиц, колонок, переменные и другие фрагменты кода, соответствующие синтаксису выбранной СУБД. Шаблоны триггеров ссылочной целостности, генерируемые ERwin по умолчанию можно изменять, кроме того, можно переопределить как триггера для конкретной связи, так и шаблоны во всей модели в целом.
Шаблоны триггеров ссылочной целостности связываются с сущностями в зависимости от типа связи и роли сущности в этой связи. Тип связи и роль сущности определяют, какое правило ссылочной целостности будет по умолчанию дополнено шаблоном триггера. Связи могут быть: идентифицирующими, неидентифицирующими (nulls allowed), неидентифицирующими (no nulls), связями подтипа.
Роль сущности в связи может быть - родительская (Parent) или дочерняя (Child) сущность. Если сущность является родительской в данной связи, то ER win присваивает ей шаблон триггера для родительской сущности. Если сущность является дочерней в данной связи, то ER win присваивает ей шаблон триггера для дочерней сущности. Код триггера, который генерируется шаблоном триггера для родительской сущности, указывает СУБД, что нужно делать при вставке, изменении или удалении строки в родительской таблице связи. Код триггера, который генерируется шаблоном триггера для дочерней сущности, указывает СУБД, что нужно делать при вставке, изменении или удалении строки в дочерней таблице связи.
Ниже приведен текст шаблона триггера, соответствующего правилу ссылочной целостности ON PARENT DELETE RESTRICT.
/* ERwin Builtin %Datetime */
/* %Parent %VerbPhrase %Child ON PARENT DELETE RESTRICT */
select count(*) into numrows
from %Child
where
/* %%JoinFKPK(%Child,:%%Old," = "," and") */
%JoinFKPK(%Child,:%Old," = "," and");
if (numrows > 0)
then
raise_application_error(
-20001,
'Cannot DELETE %Parent because %Child exists.'
);
end if;
При генерации схемы СУБД для Oracle 7.2 будет сгенерирован триггер:
create trigger tD_CUSTOMER after DELETE on CUSTOMER for each row
-- ERwin Builtin Tue Jan 26 21:55:13 1999
-- DELETE trigger on CUSTOMER
declare numrows INTEGER;
begin
/* ERwin Builtin Tue Jan 26 21:55:13 1999 */
/* CUSTOMER размещает ORDER ON PARENT DELETE RESTRICT */
select count(*) into numrows
from ORDER
where
/* %JoinFKPK(ORDER,:%Old," = "," and") */
ORDER.CustomerID = :old.CustomerID;
if (numrows > 0)
then
raise_application_error(
-20001,
'Cannot DELETE CUSTOMER because ORDER exists.'
);
end if;
ER win по умолчанию использует для генерации кода триггера на языке SQL встроенные шаблоны триггеров ссылочной целостности, которые автоматически присваиваются каждой связи. Если встроенные шаблоны не удовлетворяют бизнес-правилам, можно изменить коды триггера, генерируемые на основе встроенных шаблонов. ER win позволяет изменить шаблон и указать, что при генерации модифицированная версия должна заменить встроенный шаблон.
5. Обеспечение информационной безопасности средствами СУБД
Современные реляционные сервера имеют мощные инструменты, предназначенные для обеспечения информационной безопасности. Основная нагрузка по организации безопасности лежит на администраторе базы данных. Комплекс мероприятий по обеспечению безопасности включает как административные меры, так и технические. Целью настоящей статьи не является обзор всех мероприятий, ограничимся лишь описанием некоторых технических средств, которые имеются на каждом сервере.
Любой современный реляционный сервер позволяет создавать пользователей и предоставлять или отбирать привилегии для каждого пользователя. Команды предоставления и лишения привилегий описаны стандартом языка SQL (подмножество DCL, Data Control Language):
Команды DCL позволяют задавать или лишать стандартных привилегий для объектов:
- SELECT - выборка данных
- INSERT - вставка данных
- UPDATE - обновление данных
- REFERENCES - изменение правил ссылочной целостности.
Команда GRANT позволяет предоставлять права пользователю на объект, например
GRANT INSERT ON Salespeople TO Scott
предоставляет привилегию вставлять данные (INSERT) в таблицу Salespeople пользователю Scott. Параметр PUBLIC позволяет предоставлять права всем пользователям, зарегистрированным в системе, параметр ALL - предоставлять права на все объекты, например
GRANT ALL PRIVILEGES ON Salespeople TO Scott
предоставляет все стандартные привилегии пользователю Scott;
GRANT INSERT, SELECT ON Salespeople TO PUBLIC
предоставляет привилегии INSERT, SELECT на таблицу Salespeople всем пользователям.
Для лишения привилегий используется команда REVOKE, которая также может использоваться с параметрами PUBLIC и ALL, например
REVOKE INSERT, SELECT ON Salespeople FROM Scott
лишает привилегий INSERT, SELECT на таблицу Salespeople пользователю Scott.
Особенно эффективно применение механизма предоставление и лишения привилегий совместно с использованием представлений (view).
Представления, или как их иногда называют временные или производные таблицы, представляют собой объекты базы данных, данные в которых не хранятся постоянно, как в таблице, а формируются динамически при обращении к представлению. Представление не может существовать само по себе, а определяется только в терминах одной или нескольких таблиц. Применение представлений позволяет разработчику баз данных обеспечить каждому пользователю или группе пользователей свой взгляд на данные, что решает проблемы простоты использования и безопасности данных. ERwin имеет специальные инструменты для создания и редактирования представлений. Палитра инструментов ERwin на физическом уровне содержит кнопки внесения представлений и установления связей между таблицами и представлениями. Для внесения представления нужно щелкнуть по кнопке ![]() в палитре инструментов, затем по свободному месту диаграммы. По умолчанию представление получает номер V_n, где n- уникальный порядковый номер представления. Для установления связи нужно щелкнуть по кнопке
в палитре инструментов, затем по свободному месту диаграммы. По умолчанию представление получает номер V_n, где n- уникальный порядковый номер представления. Для установления связи нужно щелкнуть по кнопке ![]() , затем по родительской таблице и, наконец, по представлению (рис. 9). Связи с представлениями и прямоугольники представлений показываются на диаграмме пунктирными линиями.
, затем по родительской таблице и, наконец, по представлению (рис. 9). Связи с представлениями и прямоугольники представлений показываются на диаграмме пунктирными линиями.
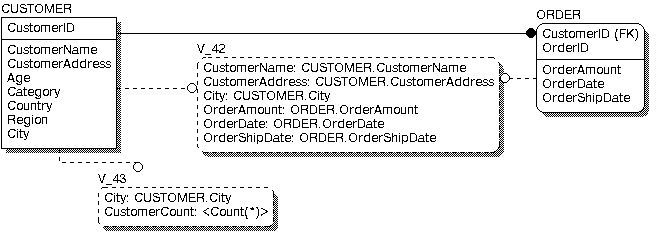
Рис. 9. Создание представления.
Для редактирования представления служит диалог View Editor (рис.10). Для его вызова следует щелкнуть правой кнопкой мыши по представлению и выбрать в меню пункт View Editor.
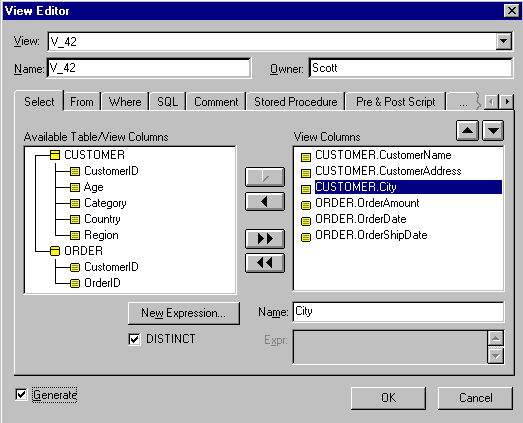
Рис.10. Диалог View Editor.
При генерации схемы базы данных Erwin генерирует команду SQL для создания представления на основе информации, внесенной в закладках Select, From и Where. Текст команды можно просмотреть или переопределить в закладке SQL.
Представление может включать только часть колонок таблицы (или нескольких таблиц). Администратор базы данных может создать такое представление, и командой GRANT дать привилегии на операции всем пользователям, при этом лишить пользователей прав на исходные таблицы. Кроме того, в закладке Where может быть включено условие фильтрации, которое позволит включить в представление только часть строк. В итоге, используя механизм представлений, можно предоставить пользователям доступ к подмножеству строк и колонок исходных таблиц, скрыв от них прочую информацию.
Другим мощным инструментом обеспечения безопасности являются процедуры и триггера. Как правило, реляционный сервер обеспечивает механизм предоставления и лишения прав на использование процедуры. Администратор может предоставить права пользователю на использование процедуры, лишив прав на операции с исходной таблицей.
Триггеры выполняются автоматически и скрыты для пользователя. Это дает возможность контроля и аудита критической информации.
Рассмотрим простейший пример. Предположим, бизнес-правила требуют, чтобы при любом изменении имени клиента (колонка CustomerName таблицы CUSTOMER , рис.11) в таблице SECURITY создавалась строка, в которой бы фиксировалось прежнее значение имени, новое значение, дата изменения и имя пользователя, произведшего изменение.

Рис. 11. Таблицы CUSTOMER и SECURITY.
Ниже приведен код триггера (на языке выбранного сервера, в примере - Oracle 7.2), автоматически генерируемого Erwin по шаблону, который поддерживает эти бизнес-правила:
create trigger SecurWrite
BEFORE UPDATE OF
CustomerName
on CUSTOMER
REFERENCING OLD AS old1 NEW AS new1
for each row
/* ERwin Builtin Tue Jan 26 21:24:37 1999 */
/* default body for SecurWrite */
begin
Insert into Security (OldName,NewName, UserUpdate, UpdateDate)
values (:old1.CustomerName,:new1.CustomerName, User, Sysdate);
end;
/
6. Создание хранилищ данных
Одна из основных задач, решаемых в корпоративных информационных системах, является предоставление аналитической информации необходимой для менеджеров, принимающих решения. Для поддержки принятия решения необходим не один заранее подготовленный отчет, а серия разнообразных отчетов, причем менеджер не всегда представляет, какой именно отчет понадобится ему в следующие полчаса. Например, при анализе продаж по компании оказывается, что в феврале текущего года произошел спад. Чтобы выяснить причины спада, необходимо просмотреть отчет о продажах в регионах. Отчет о продажах в регионах показывает, что спад произошел, видимо, по причине неудовлетворительной работы одного из филиалов, следовательно, необходим отчет о работе данного филиала и т.д. и т.п. Организовать выполнение таких отчетов в случае использования обычной базы данных крайне сложно. Во-первых, вследствие сложной структуры данных, СУБД не сможет обеспечить выполнение отчетов в реальном масштабе времени (что необходимо для поддержки принятия решения - менеджер не может ждать час - данные нужны ему немедленно), а во-вторых, выполнение таких отчетов может замедлить текущую работу серверов баз данных.
Решением проблемы может быть размещение всех данных в единой специализированной базе данных, называемой хранилищем данных (Data Warehouse).
Хранилища данных представляют собой специализированные базы данных, предназначенные для хранения данных, которые редко меняются, но на основе которых часто требуется выполнение сложных запросов. Хранилища данных позволяют разгрузить промышленные базы данных, и тем самым, позволяют пользователям более эффективно и быстро извлекать необходимую информацию. Они могут быть включены в общую корпоративную сеть (рис.2), по которой в хранилище по заранее определенному расписанию, как правило, в период наименьшей загрузки сети и серверов сбрасывается накопленная за день или за неделю информация. Поскольку данные меняются редко, то к хранилищу данных не предъявляются жестких требований, которые обычно предъявляются к обычным базам данных - отсутствие аномалий при выполнении операций обновления или удаления и избыточности хранения информации. Зато предъявляются требования, необходимые для эффективного выполнения аналитических запросов.
- Менеджеру, принимающему решения необходимы самые разнообразные отчеты, причем всякий раз новые. Не всегда возможно выделить специалиста, который бы непрерывно готовил все новые и новые отчеты. Лучший выход - научить создавать отчеты самого менеджера. Существуют разнообразные инструменты (например, упомянутый выше Crystal Reports), интерфейс которых достаточно прост для того, чтобы непрофессионалы в области информационных технологий могли создать отчеты. Однако, в этом случае конечный пользователь непосредственно обращается к структуре данных. Следовательно, структура данных хранилища должна быть понятна пользователям.
- Поскольку данные в хранилище не должны устаревать, они должны регулярно пополняться. Должны быть выделены данные, которые регулярно модифицируются: (ежедневно, еженедельно, ежеквартально и т.п.) и созданы спецификации алгоритмов такого пополнения.
- Поскольку отчет будет создавать конечный пользователь, должны быть упрощены требования к запросам с целью исключения запросов, которые могли бы требовать множественных утверждений SQL в традиционных реляционных СУБД.
- Обработка запросов к хранилищу должна быть проведена с высокой производительностью, желательно в реальном масштабе времени, поэтому должна быть обеспечена поддержка сложных запросов SQL, которые требуют последовательной обработки тысяч или миллионов записей.
Все это предъявляет к их проектированию и реализации хранилищ повышенные требования. ERwin является незаменимым инструментом для проектирования хранилищ данных по нескольким причинам:
- Хотя реализовать хранилище данных можно на любом сервере БД, существуют специализированные сервера, специально предназначенные для поддержки хранилищ данных. Erwin поддерживает генерацию схемы БД для двух таких серверов - Teradata и Red Brick.
- Как было указано выше, при проектировании хранилища необходимо создавать подробные спецификации для всех, в том числе самых разных типов источников данных. Erwin поддерживает на физическом уровне прямое и обратное проектирование объектов более чем для 20 типа БД, поэтому является идеальным CASE-средством для работы с гетерогенными информационными системами.
- Для эффективного проектирования хранилищ данных ERwin использует размерную (Dimensional) модель. Dimensional - методология проектирования специально предназначенная для разработки хранилищ данных.
Рассмотрим основные особенности техники моделирования хранилищ данных с помощью Erwin. Нормализация данных в реляционных СУБД приводит к созданию множества связанных между собой таблиц. В результате, выполнение сложных запросов неизбежно приводит к объединению многих таблиц, что существенно увеличивает время отклика. Проектирование хранилища данных подразумевает создание денормализованной структуры данных (допускается избыточность данных и возможность возникновения аномалий при манипулировании данными), ориентированной в первую очередь на высокую производительность при выполнении аналитических запросов. Нормализация делает модель хранилища слишком сложной, затрудняет ее понимание и ухудшает эффективность выполнения запроса.
ERwin поддерживает методологию моделирования хранилищ благодаря использованию специальной нотации для физической модели - Dimensional. Наиболее простой способ перейти к нотации Dimensional в ERwin - при создании новой модели (меню File / New) в диалоге ERwin Teamplate Selection выбрать из списка предлагаемых шаблонов DIMENSION. В шаблоне DIMENSION сделаны все необходимые для поддержки нотации размерного моделирования настройки, которые, впрочем, можно установить вручную.
Моделирование Dimensional сходно с моделированием связей и сущностей для реляционной модели, но отличаются, целями. Реляционная модель акцентируется на целостности и эффективности ввода данных. Размерная (Dimensional) модель ориентирована в первую очередь на выполнение сложных запросов к БД.
В размерном моделировании принят стандарт модели, называемый схемой звезда (star schema), которая обеспечивает высокую скорость выполнения запроса, посредством денормализации и разделения данных. Невозможно создать универсальную денормализованную структуру данных, обеспечивающую высокую производительность при выполнении любого аналитического запроса. Поэтому схема звезда строится так, чтобы обеспечить наивысшую производительность при выполнении одного самого важного запроса, либо для группы похожих запросов.
Схема звезда обычно содержит одну большую таблицу, называемую таблицей факта ( fact table) , помещенную в центр, и окружающие ее меньшие таблицы, называемые таблицами размерности ( dimensional table) , соединенными c таблицей факта в виде звезды радиальными связями. В этих связях таблицы размерности являются родительскими, таблица факта - дочерней. Схема звезда может иметь также консольные таблицы (outrigger table) , присоединенные к таблице размерности. Консольные таблицы являются родительскими, таблицы размерности - дочерними.
В размерной модели, ERwin обозначает иконкой роль таблицы в схеме звезда (рис.12)
![]() Таблица факта ( fact table)
Таблица факта ( fact table)
![]() Таблица размерности ( dimensional table) ,
Таблица размерности ( dimensional table) ,
![]() Консольная таблица (outrigger table) .
Консольная таблица (outrigger table) .
Рис. 12. Обозначения таблиц в схеме "звезда".
Прежде чем создать базу данных со схемой типа звезда, необходимо проанализировать бизнес-правила предметной области с целью выяснения центрального вопроса, ответ на который наиболее важен. Все прочие вопросы должны быть объединены вокруг этого основного вопроса и моделирование должно начинаться с этого основного вопроса. Данные, необходимые для ответа на этот вопрос, должны быть помещены в центральную таблицу модели - таблицу факта. Например, если необходимо создавать отчеты об общей сумме дохода от продаж за период или по типу товара или по продавцам, следует разрабатывать модель так, чтобы каждая запись в таблице факта представляла общую сумму продаж, для каждого клиента за определенный период времени для каждого продавца. В примере (рис.13), таблица факта содержит суммарные данные о продажах ("SALE"), а таблицы размерности содержат данные о заказчике и заказах ("CUSTOMER"), продуктах ("PRODUCT"), продавцах ("SALESPEOPLE") и периодах времени ("TIME").

Рис.13. Схема звезда.
Таблица факта является центральной таблицей в схеме звезда (рис. 13). Она может состоять из миллионов строк и содержать суммирующие или фактические данные, которые могут помочь ответить на требуемые вопросы. Она соединяет данные, которые хранились бы во многих таблицах традиционных реляционных базах данных. Таблица факта и таблицы размерности связаны идентифицирующими связями, при этом первичные ключи таблицы размерности мигрируют в таблицу факта в качестве внешних ключей. В размерной модели направления связей явно не показываются - они определяются типом таблиц. Первичный ключ таблицы факта целиком состоит из первичных ключей всех таблиц размерности. В примере (таблица факта "SALE") первичный ключ составлен из четырех внешних ключей: CustomerID, SalespeopleID, TimeID и ProductID.
Таблицы размерности имеют меньшее количество строк, чем таблицы факта и содержат описательную информацию. Эти таблицы позволяют пользователю быстро переходить от таблицы факта к дополнительной информации.
В примере таблица "SALE" - таблица факта; "CUSTOMER", "TIME", "SALESPEOPLE" и "PRODUCT" - таблицы размерности, которые позволяют быстро извлекать информацию о том, кто и когда сделал покупку, какой продавец и на какую сумму продал, и какие именно товары были проданы.
При проектировании хранилища данных важно определить источник данных (для каждой колонки), метод, которым исходные данные извлекаются, преобразовываются, и фильтруются прежде, чем они импортируются в хранилище данных. Хранилище данных может объединять информацию из текстовых файлов и многих баз данных, как реляционных (в том числе других БД на платформе Informix), так и нереляционных, в единую систему поддержки принятия решений. Чтобы поддерживать регулярные обновления и проверки качества данных, необходимо знать источник для каждой колонки в хранилище данных. Для документирования информации об источниках данных используется редактор Data Warehouse Source Editor (рис.14.) .
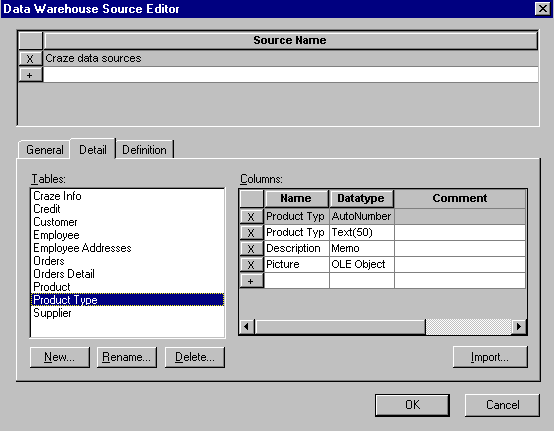
Рис.14. Диалог Data Warehouse Source Editor.
Имена таблиц и колонок источников данных могут быть импортированы как из баз данных (обратное проектирование), так и из других моделей ERwin. Каждому источнику может быть задано имя и определение.
В редакторе Column Editor необходимо внести информацию об использовании источников данных для каждой колонки таблиц хранилища данных, а так же дополнительную информацию о способах, режимах и периодичности переноса данных из источника в хранилище данных.
7. Прямое проектирование системного каталога реляционной СУБД.
После завершения работы над физической моделью можно сгенерировать системный каталог СУБД. Этот процесс называется прямым проектированием (Forward Engineering). При генерации физической схемы ER win включает триггеры ссылочной целостности, хранимые процедуры, индексы, ограничения и другие возможности, доступные при определении таблиц в выбранной СУБД.
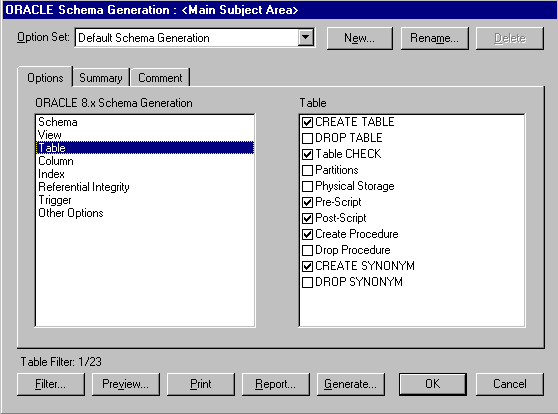
Рис. 15. Диалог Schema Generation.
Для генерации системного каталога БД следует выбрать пункт меню Tasks / Forward Engineer/Schema Generation или нажать кнопку ![]() на панели инструментов. Появляется диалог Schema Generation (рис. 15). В диалоге Schema Generation следует указать параметры генерации схемы и щелкнуть по кнопке Generate. Появляется диалог связи с сервером (клиентская часть сервера должна быть предварительно установлена на той же машине, что и Erwin). После установления сеанса связи выполняется SQl- скрипт, создающий объекты базы данных.
на панели инструментов. Появляется диалог Schema Generation (рис. 15). В диалоге Schema Generation следует указать параметры генерации схемы и щелкнуть по кнопке Generate. Появляется диалог связи с сервером (клиентская часть сервера должна быть предварительно установлена на той же машине, что и Erwin). После установления сеанса связи выполняется SQl- скрипт, создающий объекты базы данных.
Несмотря на то, что переход к технологии клиент-сервер является сложной задачей, CASE-средства Computer Associated позволяют автоматизировать выполнение почти всех ее этапов.