Вы задумываетесь о том, сколько полезной информации можно было бы извлечь путем анализа данных, поступающих из социальных сетей, но не предпринимаете никаких действий лишь потому, что не располагаете достаточным временем или ресурсами для того, чтобы создать необходимое приложение? В настоящем руководстве показано, насколько легко работать с редактором потоков операций Node-RED в IBM Bluemix™ для получения ленты сообщений, содержащей данные из социальной сети (лента Twitter), и последующего создания файла Распределенной файловой системы Hadoop (Hadoop Distributed File System, HDFS) на основе этих данных. Кроме того, мы продемонстрируем вам способы анализа данных и построения итоговых диаграмм с помощью службы IBM Analytics for Hadoop. Вы будете удивлены тому, насколько это просто - превратить набор неизвестных данных в полезную информацию для дальнейшей работы.
Что потребуется для создания приложения
Шаг 1: Настройка служб Bluemix
Для реализации потока операций по извлечению, преобразованию и загрузке (ETL) необходимы функции Bluemix Node-RED. Для того чтобы разработать поток операций, вначале необходимо создать приложение Node-RED и добавить в него службу IBM Analytics for Hadoop.
- Выполните вход в учетную запись Bluemix (или зарегистрируйтесь, чтобы получить ИД для пробного пользования).
- Выберите Каталог.
- Найдите и выберите Node-RED Starter.

- В правой части введите имя приложения в поле Имя (которое также отображается в поле Хост ), а затем выберите действие CREATE (СОЗДАТЬ).
Дождитесь запуска приложения Node-RED. Прежде чем работать с приложением, необходимо подключить к нему службу IBM Analytics for Hadoop.
- В левой части выберите действие Вернуться к панели управления и щелкните на созданном вами приложении Node-RED.
- Выберите Добавить службу или API.
- В левой части, в разделе Категория отметьте Большие данные. Затем справа выберите IBM Analytics for Hadoop.
- В правой части выберите App (Приложение), а затем - свое приложение Node-RED.
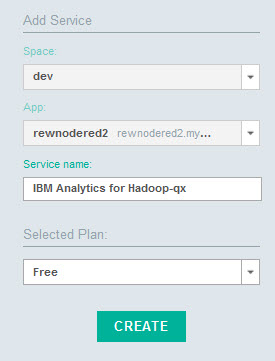
- Выберите CREATE (СОЗДАТЬ) и, если появится соответствующее приглашение, нажмите кнопку ОБНОВИТЬ (RESTAGE). Дождитесь обновления и повторного запуска приложения.
- В верхней части, рядом с разделом Маршруты (Routes), щелкните на имени приложения Node-RED, например, sampleName .mybluemix.net (где sampleName - это имя, присвоенное вами приложению), чтобы открыть приложение Node-RED в новом окне браузера.

- Нажмите большую кнопку Go to your Node-RED flow editor (Перейти к редактору потока Node-RED).
Шаг 2. Создание потока операций ETL в Node-RED
Далее с помощью редактора потоков операций Node-RED необходимо создать поток ETL. Этот поток получает "твиты" из социальной сети Twitter и в динамичном режиме создает файл Распределенной файловой системы Hadoop (Hadoop Distributed File System, HDFS). Этот файл потребуется вам на следующем этапе - для анализа "твитов". Весь поток операций в редакторе потоков Node-RED выглядит следующим образом:
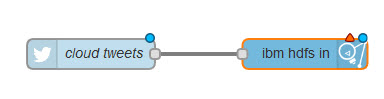
- С помощью функции прокрутки найдите на палитре раздел социальные сети и перетащите узел Twitter на холст.

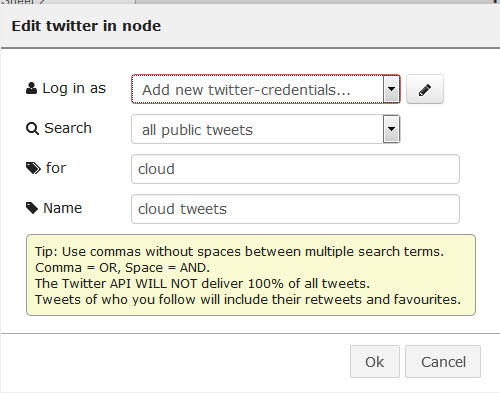
- Дважды щелкните на узле Twitter, чтобы настроить его:
- В выпадающем списке Войти от имени выберите Добавить новые идентификационные данные twitter и щелкните на значке в виде карандаша. Нажмите кнопку для идентификации в Twitter. Введите имя пользователя и пароль Twitter и нажмите кнопку Авторизация приложения, после чего закройте окно.
- Проверьте, отображается ли ваш ИД для Twitter и нажмите кнопку Добавить.
- В текстовом поле для введите значение
cloud. - В поле Имя введите значение
cloud tweetsи нажмите кнопку Ok.
- С помощью функции прокрутки найдите на палитре раздел память, выберите второй узел ibm hdfs (запись) и перетащите его на холст.
- С помощью мыши соедините узел Twitter с узлом hdfs.
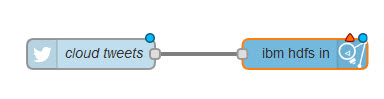
- Дважды щелкните на узле ibm hdfs , чтобы настроить его:
- В окне Имя файла введите имя файла, создаваемого приложением в динамичном режиме (например,
sampleTwitterData/stream). Этот файл содержит "твиты", удовлетворяющие вашим критериям. - Выберите Ok.
- В окне Имя файла введите имя файла, создаваемого приложением в динамичном режиме (например,
- В верхнем правом углу редактора потоков Node-RED выберите действие Deploy (Развернуть).
- Закройте окно браузера.
Теперь ваша служба запущена. Выполняется сбор данных из Twitter и запись их в файл. Этот файл располагается в HDFS службы Hadoop (BigInsights) и может увеличиваться в размерах до 20 ГБ (ограничение объема памяти в HDFS для бесплатной службы BigInsights).
Поскольку HDFS поддерживает линейное масштабирование, размер данного файла ограничен лишь вашими финансовыми возможностями. Для того чтобы получить дополнительное пространство для хранения данных, можно выбрать соответствующий план. Самая большая из известных HDFS, размером 455 петабайт, принадлежит компании Yahoo, так что вы можете себе представить реальные масштабы Hadoop. Усовершенствованные кластеры Hadoop в Bluemix работают на основе физического аппаратного обеспечения в SoftLayer. Минимальный объем памяти - 18 ТБ, но при необходимости его можно увеличить до нескольких петабайт.
Шаг 3. Использование IBM Analytics for Hadoop для анализа "твитов"
Завершив создание потока операций ETL и настройку сбора данных, вы можете приступить к анализу данных с помощью консоли IBM Analytics for Hadoop в Bluemix.
- Вернитесь в Bluemix. В окне Services (Службы) приложения выберите IBM Analytics for Hadoop .
- На странице служб нажмите кнопку LAUNCH (ЗАПУСТИТЬ) , чтобы открыть консоль BigInsights.
- В IBM InfoSphere BigInsights щелкните на вкладке Файлы , а затем найдите в проводнике созданный вами файл:
/user/biblumixsampleTwitterData/stream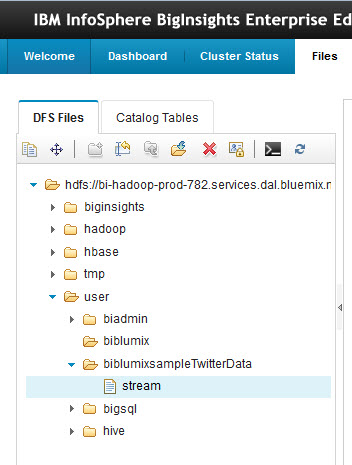
- Выберите пункт Лист (Sheet) над файлом и выберите файл.
Кнопка Лист (Sheet) активирует средство импорта BigSheets. BigSheets - это веб-приложение, использующее электронные таблицы и поддерживающее функции анализа данных в объеме до нескольких петабайт. Этому приложению удается управлять такими огромными объемами данных следующим образом: вначале выполняется определение реального потока операций по обработке данных на примере небольшого фрагмента данных, а затем поток операций для обработки данных передается в кластер Hadoop в виде процесса MapReduce.
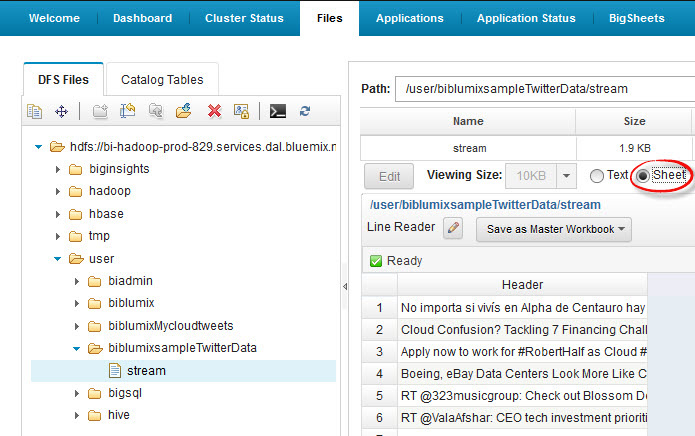
- Выберите Сохранить как главную рабочую книгу (Save as Master Workbook).
- В поле Имя введите значение
tweets - Выберите Save (Сохранить), в результате чего выполняется автоматический переход на вкладку BigSheets.
- В поле Имя введите значение
- Выберите Создать новую рабочую книгу (Build new workbook). Это обязательное действие, поскольку, по умолчанию, изменять данные в оригинале рабочей книги в BigSheets нельзя, так как исходный файл, лежащий в основе рабочей книги, редактированию не подлежит. После создания новой рабочей книги базовые данные можно изменять (как показано в описании следующих двух шагов).
- Выберите пункт Добавить листы (Add sheets) в выпадающем списке, а затем выберите Функция (Function).
- В окне Создать лист: Функция выберите Categories (Категории) и нажмите кнопку Объекты (Entities).
- С помощью функции прокрутки выберите в списке пункт Организация (Organization). При выборе раздела Организация, с помощью встроенной функции BigInsights (на основе Watson/NLP) выполняется извлечение из данных названий компаний для последующего анализа.
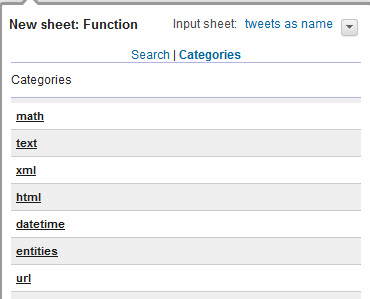
- Из выпадающего списка Ввод параметра (Fill in parameter) выберите Заголовок (Header) и щелкните на отметке зеленого цвета.
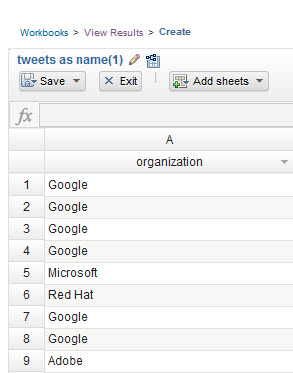
Первый столбец таблицы (под стандартным названием Header (Заголовок)) используется в качестве входных данных для функции, основанной на технологии IBM Watson и позволяющей извлекать названия компаний из "твитов".
- Список различных компаний, упомянутых в сочетании с термином "cloud" в ваших "твитах", будет отображен в разделе Организация (Organization). Этот список представляет собой подмножество данных, с помощью которых вы сможете разработать и протестировать анализ. Выберите Save (Сохранить) > Сохранить и выйти (Save & Exit) и нажмите кнопку Save (Сохранить).
- В центре окна нажмите кнопку Run (Запустить). Теперь задание MapReduce применяет аналитику ко всем полученным "твитам" в файле HDFS. Дождитесь, пока в строке состояния выполнения задачи, расположенной в верхней правой части окна, будет отображено значение 100%.
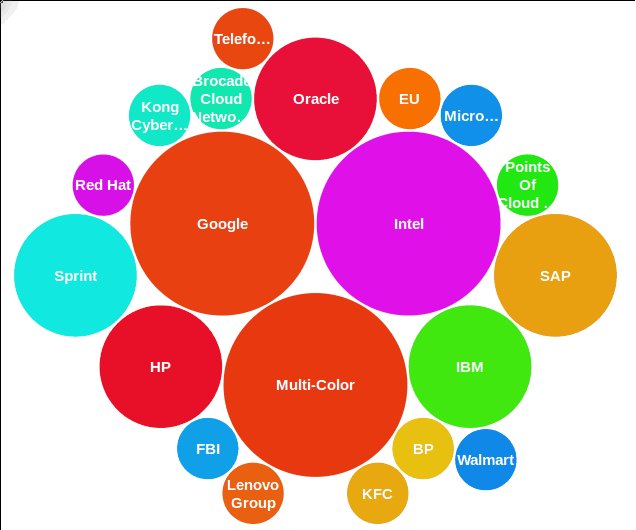
- Выберите Добавить диаграмму (Add chart) > cloud > Пузырьковая облачная (Bubble Cloud) и щелкните на отметке зеленого цвета.
Вначале диаграмма будет изображена, исходя из образцов данных.
- Нажмите кнопку Run (Запустить) еще раз, чтобы провести совокупные вычисления по всем данным в HDFS. Дождитесь, пока в строке состояния выполнения задачи, расположенной в верхней правой части окна, будет отображено значение 100%.
Итоговый результат отражает распределение значений, с применением анализа по организациям, во всех "твитах" за последние 10 минут, в которых встречался термин cloud .
Ниже приводится пример диаграммы, полученной в результате запуска приложения; ваша диаграмма будет отличаться, так как ваш поток данных из Twitter будет принадлежать к другому промежутку времени, к тому же социальные тенденции отличаются высокой динамичностью, отчего качественная аналитика приобретает еще более важное значение. При проведении анализа в различных временных промежутках можно получить совершенно разные результаты.
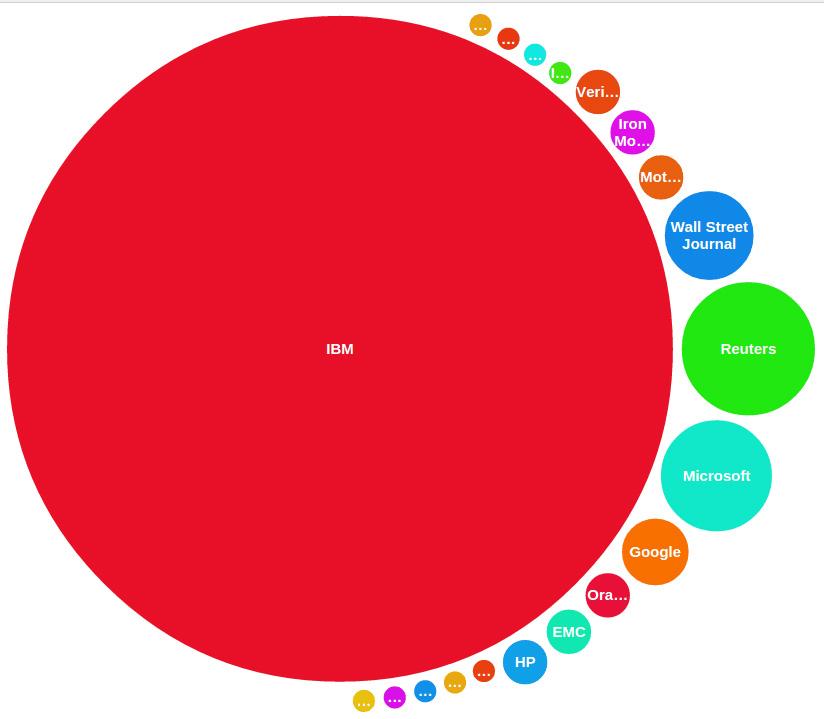
Например, на следующем рисунке изображена диаграмма, полученная после проведения конференции IBM Interconnect в Лас-Вегасе:
Теперь можно закрыть и приложение IBM InfoSphere BigInsights, и IBM Bluemix.
Заключение
В настоящем руководстве показано, как быстро создать поток операций ETL с помощью Node-RED и проанализировать полученные данные путем использования IBM Analytics for Hadoop. Во всем проекте используются службы IBM Bluemix, поэтому нет абсолютно никакой необходимости в написании кода. Вы можете создавать другие потоки операций с помощью Node-RED и анализировать любые собранные данные, используя функциональные возможности аналитики Hadoop.