Источник: msdn.microsoft.com/
Загрузка кода возможна по следующей ссылке: SQLHierarchyID2008_09a.exe (155 KB)
Обзор кода в интерактивном режиме
Обзор кода в интерактивном режиме
Эта статья основана на предварительной версии сервера SQL Server 2008 RC0. Любые содержащиеся в ней сведения могут быть изменены.
В этой статье рассматриваются следующие вопросы/
|
В данной статье используются следующие технологии. SQL Server 2008 |
 Cодержание
Cодержание
Иерархические данные
Проблема ведомости материалов
Использование сущностей для понимания проблемы
Система ведомостей материалов в SQL Server 2005
Создание таблиц
Запросы для проверки проекта
Эксплуатация HierarchyID
Тестирование применения HierarchyID
Заключение
Система производства автомобилей; разделение страны на штаты, округа, города и почтовые индексы; описание домашней мультимедийной системы - что у них общего? Простой ответ состоит в том, что все они описывают иерархии.
SQL Server 2008 поддерживает новый тип данных, HierarchyID, помогающий решать некоторые из проблем при моделировании и запросах иерархической информации. Я представлю вам этот тип данных, рассказывая о шаблоне, часто используемом в производстве и известном как ведомость материалов (bill of materials - BOM) или ведомости. Начав с краткого рассказа о ведомостях, я проиллюстрирую моделирование такого рода данных. Я также представлю реализацию этой модели в SQL Server 2005. Затем я покажу, как тип данных HierarchyID можно использовать для ее реализации в SQL Server 2008.
Иерархические данные
Автомобили являются сочетанием множества компонентов, таких как двигатели, трансмиссии, электроника и рулевые механизмы. В Соединенных Штатах наша географическая территория разделена на штаты, а затем на административные единицы, именуемые округами. Округа делятся на более мелкие единицы - различные для различных правительственных учреждений. Например, Бюро переписей Соединенных Штатов делит их на переписные районы. Почтовая служба США маршрутизирует доставку почты по кодам плана почтовых зон (Zone Improvement Plan - ZIP) или почтовым индексам. Геоинформационные системы (GIS) могут сводить переписные районы и коды ZIP вместе, чтобы дать пользователям знакомый ориентир в пространстве для области.
Во время недавнего похода в местный магазин электроники для оценки новой домашней системе мультимедиа показал похожую иерархическую систему во всей красе - ото всех комбинаций возможных компонентов и параметров у меня закружилась голова! Я задумался, как можно моделировать и реализовать подобные системы в системе базы данных.
Отношения между автомобилем и его двигателем представляют из себя иерархию: автомобиль содержит двигатель. Те же отношения существуют для трансмиссии, электроники и рулевого механизма. Отношение заключается в том, что один объект содержит другой. Подобную иерархию можно наблюдать в отношениях между различными группами географических или переписных данных.
Иерархии существуют повсюду, но их реализация в контексте реляционной базы данных часто оказывается проблемой. Типичным подходом является представление иерархии путем использования родительских или дочерних отношений при помощи одной или нескольких таблиц. Хотя этот подход определенно работает во многих случаях, у него есть несколько недостатков. В таком решении необходимо тщательно обдумать способ поддержания целостности данных. И хотя запросы по всей глубине и ширине таких таблиц были существенно упрощены в SQL Server 2005, с появлением рекурсивных обобщенных табличных выражений написание запросов для таблиц такого типа может оставаться проблематичным, когда требуются объединения данных из многих таблиц.
Проблема ведомости материалов
Несколько лет назад я работал над системой, разрабатывавшейся производственной компанией для помощи ее дилерам в указании компонентов, необходимых для создания дождевальных машин с поливом в движении по кругу. Программа предоставляла список компонентов, необходимых для индивидуализированной сборки нужной дождевальной машины. Требуемые компоненты определялись на основе географии, типа почвы и того, что предполагалось выращивать в охватываемой области, а также гидрологических и конструкционных соображений самого устройства.
Основой решения должна была быть база данных SQL Server. Целью базы данных было хранение информации о доступных компонентах для создания дождевальной машины. Однако при создании спецификации для производства нам требовалось указать эти компоненты как ведомости материалов.
За некоторыми ведомостями скрывались коллекции физических деталей, из которых состоял один из компонентов системы. Например, каждой дождевальной машине требовался насос для перекачки воды из колодца в систему. Насос мог работать на электричестве, а это значило, что ему требуется также трансформатор и коробка предохранителей. Как вариант, он мог работать на топливе, а это значило что ему нужен бак, топливный насос и шланги для подключения насоса к баку. В обеих случаях требуемые части для насоса перечислялись в ведомости насоса.
В ведомость на насос в целом могло входить собрание других ведомостей. Например, стандартизированная дождевальная машина могла состоять из дерева ведомостей для насоса, другого дерева для труб, используемых для перекачки воды, и ведомостей для прочего оборудования, необходимого для ее создания.
Использование сущностей для ознакомления с проблемой
Первый вопрос, который следует задать себе: каковы сущности, о которых следует думать при представлении иерархической системы, и какие атрибуты они могут иметь? Фокус в том, чтобы не втягиваться в семантику отдельных элементов нижележащей системы, которую вы пытаетесь моделировать.
Например, рассмотрим случай основанного на ПК домашнего кинотеатра, показанного на рис. 1. Сказать, что каждый показанный там элемент представляет сущность, просто. Хотя это и так, должным образом представить все возможные системы домашних кинотеатров, продаваемых компанией, становится сложно. Что если некоторые системы используют цифровой видеомагнитофон (digital video recorder - DVR) вместо ПК? Как насчет потребителей, которым не нужен радиоприемник?

Рис. 1. Компоненты системы домашнего кинотеатра(щелкните изображение, чтобы увеличить его)
Вариации вроде этих и являются причиной, почему система ведомостей материалов эффективна как шаблон для проблем моделирования иерархических данных. Она позволяет законченной системе состоять из множества различных подведомостей и под-подведомостей, идущих вниз по структуре данных типа дерева вплоть до ее отдельных частей. В корне дерева находится законченная система, представленная одной ведомостью. Первый уровень веток также, как правило, состоит из ведомостей. Список подведомостей продолжается вниз по иерархии, пока ведомость не состоит только из списка физических деталей системы, и эти части становятся оконечными узлами дерева.
Так какие же сущности у нас имеются в системе? У нас имеются ведомости, содержащие только детали (списки деталей), и ведомости, содержащие другие ведомости.
Деталь снабжена описанием и ценой. (Само собой, она может иметь много других атрибутов, но, ради наглядности, не будем усложнять вещи.) Атрибуты списка деталей могут включать деталь и требуемое количество этих деталей. Важно отличать необходимое количество определенных деталей от информации о самой детали. Если этого не сделать, то можно получить много дубликатов одной и той же детали, разница между которыми заключается только в используемом количестве. Правила нормализации предполагают, что в большинстве случаев это недопустимо.
Ведомость будет иметь описание, способ связать ее с родительской ведомостью и связанный с нею список деталей. На рис. 2 представлен набор сущностей и их отношений.
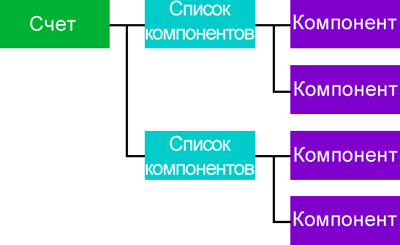
Рис. 2. Отношения сущностей (щелкните изображение, чтобы увеличить его)
Хотя реляционные базы данных отлично представляют большинство отношений, они плохо подходят для работы с моделями сущностей "многие к многим". Не то чтобы физические таблицы не могли обработать данные; проблема в том, что сложно создать соответствующие ограничения для обеспечения целостности данных между таблицами. Такие отношения могут также привести к сложным запросам. Но эту проблему несложно исправить, если сперва коснуться логической структуры таблиц. Необходимо вставить таблицу между таблицей списка деталей и таблицей ведомостей. Эта таблица будет просто содержать ссылку на ведомость и ссылку на список деталей. Нарис. 3 показана диаграмма отношений сущностей, в том числе эта дополнительная таблица.
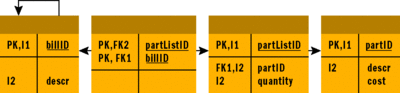
Рис. 3. Диаграмма отношений сущностей для упрощенной системы ведомости материалов(щелкните изображение, чтобы увеличить его)
Система ведомостей материалов в SQL Server 2005
Теперь, когда теория, лежащая в основе системы ведомостей, показана, пора перейти к практике. Процедура выполняется просто.
- Создайте базу данных
- Создайте таблицы, показанные на диаграмме отношений сущностей
- Добавьте требуемые ограничения на соответствующих таблицах
- Настройте необходимые разрешения на доступ для таблиц
- Заполните таблицы тестовыми данными
- Напишите и выполните запросы к таблицам, чтобы проверить архитектуру
Вот код T-SQL для создания примера базы данных. Для использования его на своих системах читателям, вероятно, потребуется изменить пути имен файлов:
create database [dbBom] on primary ( name = n'dbBom', filename = n'c:\msdnmag\dbBom.mdf', size = 50mb , maxsize = unlimited, filegrowth = 2mb ) log on ( name = n'dbBom_log', filename = n'c:\msdnmag\dbBom_log.ldf', size = 10mb , maxsize = 2048gb , filegrowth = 10%);
После успешного исполнения этого оператора не забудьте изменить область базы данных на dbBOM, например с помощью оператора USE dbBOM.
Создание таблиц
Ниже приведен исполняемый код T-SQL для создания четырех требуемых таблиц:
create table dbo.part( partID smallint not null, descr varchar(50) not null, cost money not null); create table dbo.partList( partListID int not null, partID smallint not null, quantity smallint not null); create table
dbo.billPartList( billID int not null, partListID int not null); create table dbo.bill( billID int not null, parentBillID int null, descr varchar(50) not null);
Отметьте, что единственный столбец в этих значениях, для которого допустимо иметь нулевое значение - это parentBillID в dbo.bill. Нулевое значение позволяет нам отличить ведомость, представляющую завершенную систему, от прочих ведомостей.
Ключом к обеспечению верности ссылок в этой реализации является правильная установка ограничений на таблицах. Таблицы имеют различные функции в решении, так что их ограничения будут различны. Однако каждая таблица SQL Server должна иметь связанный с нею первичный ключ в следующем духе:
alter table dbo.part add constraint pkPart primary key clustered(partID); alter table dbo.bill add constraint pkBill primary key clustered(billID); alter table dbo.partList add constraint pkPartList primary key clustered(partListID); alter table dbo.billPartList add constraint pkBillPartList primary key clustered(billID,partListID);
Некоторые из этих столбцов должны всегда иметь уникальное значение, подобно описанию (descr) части ведомости. Можно также предотвратить создание пользователями того, что сводится к дубликатам записей в списке деталей, требуя сочетания partID и требуемого количества детали:
alter table dbo.part add constraint uqDescr unique(descr); alter table dbo.bill add constraint uqBill unique(descr); alter table dbo.partList add constraint uqPartList unique(partID,quantity);
Наконец, добавьте ограничения внешнего ключа между таблицами. Первое ограничение - между dbo.part и dbo.partList. Оно потребует, чтобы деталь, добавляемая к списку деталей, сперва была определена в таблице dbo.part. Если деталь удалена из dbo.part, желательно отразить это изменение в списке деталей. Это несложно сделать, добавив условие "on delete cascade" к ограничению.
Поскольку поле partID помечено как идентификатор, оно не может быть изменено и, таким образом, каскадных действий производиться не должно:
alter table dbo.partList add constraint fkPartList_Part foreign key(partID) references dbo.part(partID) on delete cascade on update no action;
Следующее ограничение требует, чтобы если ведомости выделяется идентификатор parentBillID, ведомость, на которую ссылается billID, должна уже существовать в dbo.bill. Каскадные ограничения различны. Здесь запрещено иметь каскадные ограничения, поскольку SQL Server не может гарантировать, что при удалении или обновлении родительской ведомости произойдет бесконечная рекурсия действий. Поскольку значения по умолчанию не определены, "set default" ("установить значение по умолчанию") - тоже не вариант.
alter table dbo.bill add constraint fkBill_Bill foreign key(parentBillID) references dbo.bill(BillID) on delete no action on update no action;
Таблица billPartList требует нескольких ограничений внешнего ключа. Во-первых, необходимо потребовать, чтобы список деталей, связанный с ведомостью, существовал в таблице PartList. Кроме того, ведомость, на которую дается ссылка, должна находиться внутри таблицы dbo.bill. Поскольку ни billID из dbo.bill, ни partListID из dbo.partList нельзя обновлять, каскадные действия для ограничений невозможны. Однако если часть ведомости удалена, эти ограничения могут повлиять на таблицу:
alter table dbo.billPartList add constraint fkBillPartList_PartList foreign key(partListID) references dbo.partList(partListID) on delete cascade on update no action; alter table dbo.billPartList add constraint fkBillPartList_Bill foreign key(billID) references dbo.bill(billID) on delete cascade on update no action;
Теперь в таблицы можно вставить какие-нибудь данные для тестирования. Учитывая требуемый объем данных, я не буду показывать здесь код для этого. Если загрузить образец кода для этой статьи, то можно просто открыть и выполнить сценарий, именуемый named 01_data.sql, для создания данных к этому примеру.
Запросы для проверки проекта
Написав и исполнив несколько простых запросов, можно протестировать проект и проверить, работает ли он, как ожидается. В первом запросе используется новый синтаксис обобщенных табличных выражений для создания иерархического списка ведомостей:
with c as ( select billID,parentBillID,descr,0 as [level] from dbo.bill b where b.parentBillID is null union all select b.billID,b.parentBillID, b.descr,[level] + 1 from dbo.bill b join c on b.parentBillID = c.billID) select descr,[level],billID,parentBillID as bill from c
В возвращенных данных, показанных на рис. 4, имеется единственный корневой узел (где значение parentBillID - null). При наличии более чем одной такой ведомости потребуется изменить запрос для выбора этой родительской ведомости по ее идентификатору. (Для получения дополнительных сведений об обобщенных табличных выражениях ознакомьтесь с выпуском рубрики "Точки данных" за октябрь 2007 по адресу msdn.microsoft.com/magazine/cc163346.)

Рис. 4. Запрос иерархии ведомостей(щелкните изображение, чтобы увеличить его)
Следующий запрос базируется на первом, перечисляя все детали, использованные для ведомости системы, возвращенной первым запросом. Этот запрос приводит в действие все отношения между таблицами:
with c as ( select billID,parentBillID,descr,0 as [level] from dbo.bill b where b.parentBillID is null union all select b.billID,b.parentBillID,b.descr,[level] + 1 from dbo.bill b join c on b.parentBillID = c.billID) select p.partID,p.descr from c join dbo.billPartList bpl on c.billID = bpl.billID left join dbo.partList pl on bpl.partListID = pl.partListID join dbo.part p on pl.partID = p.partID group by p.partID,p.descr;
Затем следующий запрос вычисляет рекомендованную розничную цену производителя для системы (manufacturer's suggested retail price - MSRP), суммируя стоимость требуемых деталей системы и умножая на 2:
with c as ( select billID,parentBillID,descr,0 as lvl from dbo.bill b where b.parentBillID is null union all select b.billID,b.parentBillID,b.descr,lvl + 1 from dbo.bill b join c on b.parentBillID = c.billID) select SUM(p.cost*pl.quantity) * 2.0 from c join dbo.billPartList bpl on c.billID = bpl.billID left join dbo.partList pl on bpl.partListID= pl.partListID join dbo.part p on pl.partID = p.partID
Следующий запрос -это предыдущие запросы наизнанку. Можно видеть, что вместо того, чтобы двигаться по данным "сверху вниз" от верхней родительской ведомости, он начинается с детали, запрашивает ведомость, к которой она принадлежала, и затем идет вверх по иерархии, чтобы найти все ведомости, в которых используется эта деталь:
with c as ( select b.descr,b.billID,b.parentBillID,0 as lvl from dbo.partList pl left join dbo.billPartList bpl on pl.partListID = bpl.partListID left join dbo.bill b on bpl.billID = b.billID where pl.partID = 19 union all select b.descr,b.billID,b.parentBillID,lvl+1 from dbo.bill b join c on c.parentBillID = b.billID) select * from c;
Визуализация взаимных отношений ведомостей с помощью построчного перечисления может оказаться сложной. В подобных случаях имеет смысл организовать ведомости в пути, как показано ниже. Это позволяет легко визуализировать вложение ведомостей:
with c as ( select '/'+cast(billID as varchar(49)) as path,BillID from dbo.bill b where b.parentBillID is null union all select cast(c.path+'/'+CAST(b.billID as varchar(4)) as varchar(50)), b.billID from dbo.bill b join c on b.parentBillID = c.billID) select c.path+'/',b.descr from c join dbo.bill b on c.billID = b.billID order by 1;
Результат вложения показан на рис. 5.
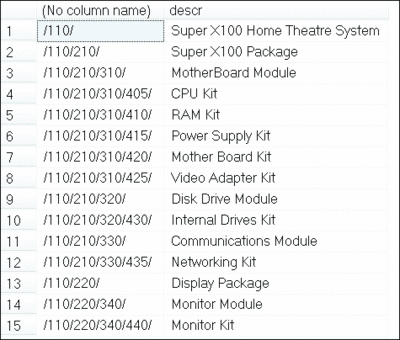
Рис. 5. Перечисление вложенных ведомостей материалов (щелкните изображение, чтобы увеличить его)
В оставшихся запросах показано добавление новой ведомости к системе - в данном случае предположим, что компания включает 4-гигабайтный флэш-накопитель в свое "Дополнительное летнее предложение". Код на рис. 6 вставляет в иерархию новую часть и представляющую ее ведомость.
 Рис. 6. Добавление новой части и ведомости
Рис. 6. Добавление новой части и ведомостиbegin transaction declare @mp int; declare @mpl int; declare @mb int; select @mp = MAX(partID)+10 from dbo.part; insert into dbo.part(partID,descr,cost) output inserted.* values (@mp,'4GB USB 2.0 Memory Stick',20.0); select @mpl = MAX(partListID)+10 from dbo.partList; insert into dbo.partList(partListID,partID,quantity) output inserted.* values (@mpl,@mp,1); select @mb = MAX(billID)+10 from dbo.bill; insert into dbo.bill(billID,parentBillID,descr) output inserted.* values (@mb,110,'Summer Bonus Package') insert into dbo.billPartList(billID,partListID) output inserted.* values (@mb,@mpl); commit; go select * from dbo.bill where parentBillID = 110; select * from dbo.part; go
Теперь предположим, что кто-то указал, что ведомость "Дополнительного летнего пакета" должна находиться не прямо под общей ведомостью системы, а под модулем дисковода. В реляционной базе данных внести такое изменение несложно:
update dbo.bill set parentBillID = 320 where billID = 507 go select * from dbo.bill where parentBillID = 320; go
Также просто и удалить эту новую ведомость в конце периода летнего предложения:
begin transaction delete from dbo.billPartList where billID=507; delete from dbo.bill where billID=507; delete from dbo.part where partID=45; commit; go select * from dbo.billPartList; select * from dbo.bill;
Использование преимуществ HierarchyID
Тип данных HierarchyID - это основанное на CLR двоичное представление, разработанное для хранения компактного, двоичного представления упорядоченного пути. Поскольку это встроенный тип данных, для его использования нет нужды специально активировать функции SQL/CLR. HierarchyID полезен всякий раз, когда необходимо представить вложенное отношение между значениями, где это отношение можно выразить в синтаксисе упорядоченного пути.
Упорядоченный путь немного напоминает путь к файлу, но вместо каталога и имен файлов в нем используются цифровые значения. Подобно любому отношению предка/потомка, все упорядоченные пути должны быть привязаны к корневому узлу. В SQL Server 2008 для текстового представления корневого узла используется единственный символ (/). Элементы с упорядоченным путем обычно представляются целыми числами, но возможно и использование десятичных значений. Упорядоченный путь должен прерываться другим единственным символом (/).
Однако упорядоченные пути не хранятся в базе данных в текстовой форме. Вместо этого они математически хэшируются в двоичные значения, и эти двоичные значения сохраняются на страницах данных.
Как же тогда нам нужно изменить нашу существующую базу данных, чтобы использовать HierarchyID? На рис. 7 показаны некоторые из упорядоченных путей, используемых в примере ведомости. Поскольку взаимоотношения предка/потомка в моем примере данных можно найти в таблице ведомости, логично начать с нее. Вместо изменения этой таблицы я добавлю новую таблицу, именуемую bill2.

Рис. 7. Пути, использованные в примере ведомости материалов (щелкните изображение, чтобы увеличить его)
Я добавлю столбец с именем billPath и типом HierarchyID. Я храню отношения предка/потомка между ведомостями в этом столбце (используя формат упорядоченного пути). И хотя на этом этапе я могу удалить столбец для перехода к родительской строке, наличие такой способности останется полезным для многих запросов. Но вместо сохранения родительского идентификатора как статического поля данных я покажу, как для этого типа переходов можно использовать сохраняемый, вычисляемый столбец на основе идентификатора иерархии. Обновленный код создания таблицы выглядит следующим образом:
create table dbo.bill2( billPath HierarchyID not null, billID smallint not null, parentBillPath as billPath.GetAncestor(1) persisted, descr varchar(50) not null);
Для тех, кто не работал ранее с типами данных, основанных на Microsoft .NET Framework, может показаться необычным вызов метода в определении parentBillPath. Возможность вызвать метод, определенный по типу, при желании передавая ему один или несколько параметров, намного упрощает код.
Здесь можно увидеть метод GetAncestor типа HierarchyID. HierarchyID сохраняет путь в компактной двоичной форме. Сослаться на какой-нибудь сегмент этого двоичного значения и обращаться с ним как с billID просто невозможно, равно как и напрямую извлечь какие-либо подсегменты упорядоченного пути для ведомости. Для этого можно воспользоваться методом GetAncestor. Значение параметра здесь означает "возвратить упорядоченный путь, заканчивающийся родительским узлом этого узла". Значение параметра контролирует, насколько высоко по упорядоченному пути происходит усечение. Так что здесь у нас имеется упорядоченный путь к родителю текущего узла. На рис. 8 дана сводка методов, доступных на типе данных HierarchyID, и некоторые типичные случаи использования для каждого метода.
 Рис. 8. Методы HierarchyID
Рис. 8. Методы HierarchyID| Метод | Возвращает | Значения параметров. | Назначение |
|---|---|---|---|
| GetAncestor | HierarchyID, представляющий упорядоченный путь для родителя или элемента верхнего уровня. | Целое число, указывающее число уровней, на которое надо подняться над текущим уровнем в текущем упорядоченном пути. | Находит родительский элемент или элемент еще более высокого уровня в упорядоченном пути для этого экземпляра. |
| GetDescendent | HierarchyID, представляющий путь дочерних элементов текущего узла и их "потомков". | Два экземпляра HierarchyID (значение одного или обеих может быть нулевым), ограничивающие потенциально возвращаемый дочерний элемент. | Получает путь для вставки нового элемента на некоторую глубину в текущий упорядоченный путь. |
| GetLevel | 16-битное целочисленное значение, представляющее общую глубину упорядоченного пути. | Нет | Определяет, одинакова ли глубина двух упорядоченных путей. |
| GetRoot | HierarchyID для упорядоченного пути без элементов. | Нет | Находит абсолютный корень для любого упорядоченного пути. |
| IsDescendantOf | 1, если упорядоченный путь, переданный как параметр, является дочерним элементом вызывающего экземпляра. | Экземпляр HierarchyID. | Определяет, является ли данный HierarchyID дочерним для другого экземпляра. |
| Parse | Экземпляр HierarchyID. | Текстовое представление упорядоченного пути. | Создает экземпляр HierarchyID из данного пути. Неявно вызывается всякий раз, когда экземпляр HierarchyID устанавливается на строку. |
| GetReparentedValue | HierarchyID, представляющий законченный упорядоченный путь при перемещении текущего элемента с одного пути на другой. | Текущий упорядоченный путь в виде HierarchyID и целевой упорядоченный путь также в виде HierarchyID. | Перемещает одно или несколько значений строк с одного родительского упорядоченного пути на другой. |
| ToString | Текстовое представление упорядоченного пути HierarchyID. | Нет | Анализирует упорядоченный путь HierarchyID. |
Далее необходимо создать первичный ключ на новой таблице, а также ее ограничение внешнего ключа:
alter table dbo.bill2 add constraint pkBill2 primary key(billPath); alter table dbo.bill2 add constraint fkBill2Parent foreign key (parentBillPath) references dbo.bill2(billPath);
В данном случае я использую значения HierarchyID и как первичный и как внешний ключ. Помните, что HierarchyID представляет упорядоченный путь преимущественно в глубину. В силу этого, значения будут наиболее различаться между одноранговыми элементами и в меньшей степени между родительскими/дочерними. При использовании значения HierarchyID для кластеризованного индекса на таблице узлы вдоль одного пути будут храниться ближе, чем узлы на других путях. Во многих случаях это хорошая мысль благодаря необходимости запрашивать все дочерние элементы у отдельно взятых путей. Однако, если чаще запрашиваются конкретные узлы, может быть желательно создать кластеризованный индекс на столбце, произведенном от GetLevel.
Эта конкретная реализация создает тонкую проблему. Поскольку я основываю ограничение внешнего ключа на пути, а не на значении, мне нужно существующее значение в таблице для привязки. Все цепи ведомостей требуют точки привязки, и, к счастью, все они могут использовать одну и ту же точку. Метод GetRoot в HierarchyID является, на самом деле, идеальным способом решения этой проблемы. Рассмотрим следующий оператор:
insert into dbo.bill2(billPath,billID,descr) values (hierarchyID::GetRoot(),0,'All Bills');
Здесь я создаю ведомость, представляющую наивысший возможный корень в любой иерархии, вызывая метод GetRoot как статический член типа. Теперь, когда я вставляю узлы первого уровня, они всё ещё будут ссылаться на родительский элемент внутри текущей таблицы.
Так как же можно перенести существующие ведомости из dbo.bill в dbo.bill2? Достаточно лишь изменить ранее показанный запрос, который выбирает путь иерархии, чтобы он привел этот путь к формату HierarchyID и затем вставил данные в dbo.bill2. Ниже приведен код T-SQL:
with c(billID,[path],[descr]) as ( select b.billID,'/'+CAST(b.billID as varchar(max)),descr from dbo.bill b where parentBillID is null union all select b.billID,c.path+'/'+CAST(b.billID as varchar(max)),b.descr from dbo.bill b join c on b.parentBillID = c.billID) insert into dbo.bill2(billpath,billID,descr) select path+'/' as [path],billID,descr from c order by c.path;
На рис. 9 показано содержимое dbo.Bill2.
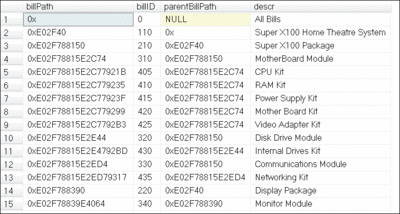
Рис. 9. Первые 15 строк dbo.bill2 (щелкните изображение, чтобы увеличить его)
Теперь также необходимо обновить отношения внешнего ключа с dbo.BillPartList следующим образом:
alter table dbo.billPartList drop constraint fkBillPartList_Bill go alter table dbo.billPartList add constraint fkBillPartList_Bill2 foreign key(billPath) references dbo.bill2(billPath) on delete cascade on update no action;
Тестирование применения HierarchyID
Создав и заполнив таблицы и разместив ограничения, я могу переписать запросы из предыдущего теста, чтобы в них использовался новый тип HierarchyID. Первый запрос создавал иерархическое перечисление ведомостей сверху (ведомость 110) вниз при помощи рекурсивного обобщенного табличного выражения. Когда я использую тип данных HierarchyID, полная "родословная" любой конкретной ведомости уже представлена в этом значении. Например, одной из самых нижних ведомостей является ведомость 405, представляющая набор ЦП. Как мне узнать, из каких ведомостей состоит ее "родословная"? Ответ даст приведенный ниже код:
select billPath.ToString() from dbo.bill2 where billID=405;
Результатом данного запроса является строка со значением "/110/210/310/405". Тогда вопрос становится таким: как именно я могу получить ведомости, представленные этой строкой? Это немного более хитрая задача, поскольку тип HierarchyID не предлагает метода для преобразования списка значений в вектор. Однако можно написать свой собственный метод, используя T-SQL либо SQL/CLR. Ниже приведен код для этого, использующий функцию T-SQL, возвращающую табличное значение:
create function dbo.Vectorize(@i hierarchyID) returns @t table (position int identity(1,1) not null,nodeValue int not null) as begin declare @list varchar(max) = @i.ToString(); declare @delimit int; set @list = substring(@list,2,len(@list)-1); while len(@list) > 1 begin set @delimit = charindex('/',@list); insert into @t values (cast(substring(@list,1,@delimit-1) as int)); set @list = substring(@list,@delimit+1,len(@list)); end; return; end;
Теперь у нас есть простой способ узнать "родословную" любой ведомости в системе с помощью одного нерекурсивного запроса:
declare @anyBill int = 405; select b1.billPath,b2.billID,b2.descr from dbo.bill2 b1 cross apply dbo.vectorize(b1.billPath) p join dbo.bill2 b2 on b2.billID = p.nodeValue where b1.billID = @anyBill;
А как насчет обнаружения деталей, используемых определенной ведомостью? В отличие от предыдущего случая, где необходимо рекурсивно запросить список ведомостей, этот запрос может использовать способность HierarchyID определить, происходит ли один упорядоченный путь от другого, используя IsDescendantOf:
declare @anyBill int = 110; declare @sourceBillPath hierarchyID; select @sourceBillPath = billPath from dbo.bill2 where billID = @anyBill; select p.partID as 'partID', p.descr 'partName' from dbo.bill2 b2 left join dbo.billPartList bpl on b2.billID = bpl.billID left join dbo.partList pl on bpl.partListID = pl.partListID left join dbo.part p on pl.partID =p.partID where b2.billPath.IsDescendantOf(@sourceBillPath)=1 and p.partID is not null order by p.partid;
Вычислить рекомендованную розничную цену производителя для всей системы или любой из подведомостей можно с помощью нескольких изменений в ранее показанном приеме:
declare @anyBill int = 110; declare @sourceBillPath hierarchyID; select @sourceBillPath = billPath from dbo.bill2 where billID = @anyBill; select SUM(p.cost * pl.quantity)*2.0 from dbo.bill2 b2 left join dbo.billPartList bpl on b2.billID = bpl.billID left join dbo.partList pl on bpl.partListID = pl.partListID left join dbo.part p on pl.partID =p.partID where b2.billPath.IsDescendantOf(@sourceBillPath)=1;
Определение того, в каких ведомостях используется определенная деталь, можно запросить с помощью метода GetAncestor. Этот метод позволяет произвести запрос вверх по иерархии. Здесь необходимо использовать рекурсию, чтобы пройти вверх по списку ведомостей:
declare @partID int = 20; with c(billPath,descr) as ( select b.billPath,b.descr from dbo.part p join dbo.partList pl on p.partID = pl.partID join dbo.billPartList bpl on pl.partListID = bpl.partListID join dbo.bill2 b on bpl.billID = b.billID where p.partID = @partID union all select b.billPath,b.descr from dbo.bill2 b join c on b.billPath = c.billPath.GetAncestor(1)) select distinct descr,billPath from c where billPath <> hierarchyID::GetRoot() order by billPath;
На рис. 6 добавлены новые деталь и ведомость. Для вставки этой детали или создания списка деталей не нужно изменять код. Для создания ведомости, с другой стороны, предоставляется возможность использовать такие методы HierarchyID, как GetDescendant и GetReparentedValue. Я могу начать процесс следующим фрагментом кода:
begin begin transaction declare @mp int; declare @mpl int; select @mp = MAX(partID)+10 from dbo.part; insert into dbo.part(partID,descr,cost) output inserted.* values (@mp,'4GB USB 2.0 Memory Stick',20.0); select @mpl = MAX(partListID)+10 from dbo.partList; insert into dbo.partList(partListID,partID,quantity) output inserted.* values (@mpl,@mp,1);
Создав деталь и список деталей, я теперь могу создать соответствующую ведомость. Идея состоит в том, чтобы вставить новую ведомость в иерархию справа ото всех прочих ведомостей, составляющих систему домашнего кинотеатра Super X100 Home Theatre System. Для этого мне нужно знать две вещи: путь к родительской ведомости и путь к самой правой дочерней.
Получение пути для родительской ведомости - это простой запрос. Для нахождения самой правой дочерней требуется использование методов IsDescendantOf и GetLevel следующим образом:
declare @root hierarchyID; declare @newBillPath hierarchyID; declare @newBillID int; select @root = billPath from dbo.bill2 where billID = 110; select @newBillPath = max(billPath) from dbo.bill2 where billPath.IsDescendantOf(@root) =1 and billPath.GetLevel() = @root.GetLevel()+1;
Я ищу все непосредственные потомки корневого узла. Поскольку пути упорядочиваются по значению, ведомостью с наибольшим значением для HierarchyID будет крайний справа экземпляр. Зная крайний справа узел одного уровня, я теперь должен создать новый путь рядом с ним. Здесь-то и вступает в дело GetDescendant. Параметры к этому методу контролируют, где создается новый путь. Когда я оставляю значение второго параметра в этом списке нулевым, я указываю создать узел справа от первого параметра:
select @newBillPath =@root.GetDescendant(@newBillPath,null);
Теперь у меня есть путь для новой ведомости, и этот путь будет иметь значение для newBillID, так что мне просто нужно извлечь его. Ранее добавленная функция, возвращающая табличное значение, может помочь в этом:
select @newBillID = nodeValue from dbo.Vectorize(@newBillPath) where position = @newBillPath.GetLevel();
Наконец, я могу завершить эту транзакцию, вставив новую ведомость в таблицу dbo.bill2 и вставив billID, а также partListID в таблицу dbo.billPartList:
insert into dbo.bill2 output inserted.* values (@newBillPath,@newBillID,'Summer Bonus Package'); insert into dbo.billPartList(billID,partListID) output inserted.* values (@newBillID,@mpl); commit; end;
Сделать ведомость "Дополнительного летнего предложения" из прямого потомка Super X100 Home Theatre System потомком модуля дисковода не особенно сложно при условии, что не требуется изменять billID (см. рис. 10). Ключевая вещь, которую следует помнить об использовании GetReparentedValue, состоит в том, что ее вызов сам по себе, не сказывается на изменениях значений, сохраненных в таблице. Чтобы повлиять на это изменение, необходимо использовать обновление.
 Рис. 10. Перемещение ведомости
Рис. 10. Перемещение ведомостиbegin begin transaction declare @oldPath hierarchyID,@newRoot hierarchyID; declare @newPath hierarchyID; declare @billIDToMove int = 251; declare @billIDToMoveTo int = 320; select @oldPath = billPath from dbo.bill2 where BillID = @billIDToMove; select @newRoot = b.billPath from dbo.bill2 b where billID = @billIDToMoveTo select @newPath = @oldPath.GetReparentedValue( @oldPath.GetAncestor(1),@newRoot); update dbo.bill2 set billPath = @newPath output inserted.* where billID = 251; commit; end;
Удаление детали и ее ведомостей matchingID может либо быть довольно простым процессом, либо потребовать значительных усилий. Многое зависит от того, является ли удаляемая ведомость родительской для другой ведомости. Если нет, как в случае "Дополнительного летнего предложения", можно просто удалить и ведомость, и деталь:
begin declare @partToDelete int = 45; begin transaction delete from dbo.bill2 where billID in ( select billID from dbo.billPartList bpl join dbo.partList pl on bpl.partListID = pl.partListID join dbo.part p on pl.partID = p.partID where p.partID = @partToDelete); delete from dbo.part where partID = @partToDelete; commit; end;
В архитектуре, подобной представленной здесь, для удаления ведомости, являющейся родителем одной или нескольких других ведомостей, требуется более сложный код. Проблема состоит в том, что у меня имеется ограничение внешнего ключа, требующее от каждой ведомости иметь непосредственного родителя. При попытке удалить родительскую ведомость возникает ошибка. Чтобы исправить ее, мне сперва нужно переместить все дочерние ведомости к ведомости, которая сохранится. Чтобы сделать это, мне придется временно отбросить ограничения внешнего ключа и вычислить пути для новых узлов, используя метод GetReparentedValue.
Заключение
Новый тип HierarchyID в SQL Server 2008 предоставляет компактные типы данных с возможностью хранить упорядоченные пути, определяющие узлы, и работать с ними. Используя этот новый тип данных, можно реализовать почти любую систему, полагающуюся на иерархическую модель данных.
Основные его преимущества состоят в возможностях уменьшить объем данных, физически хранимых на диске, и писать менее сложные запросы. Заметьте, что встроенную поддержку ограничений для обеспечения целостности каскадных данных в SQL Server можно использовать и вместе с этим типом. Ключевой момент, который следует помнить, состоит в том, что в отличие от традиционных подходов к моделированию иерархии с помощью скалярных значений для идентификаторов дочерних и родительских элементов, в HierarchyID каждый узел содержит свой полный путь в качестве своей идентификации.
Кент Тегельс (Kent Tegels) - технический руководитель по учебным программам данных в компании Developmentor. Он разрабатывает и ведет учебные курсы для SQL Server, .NET и XML.