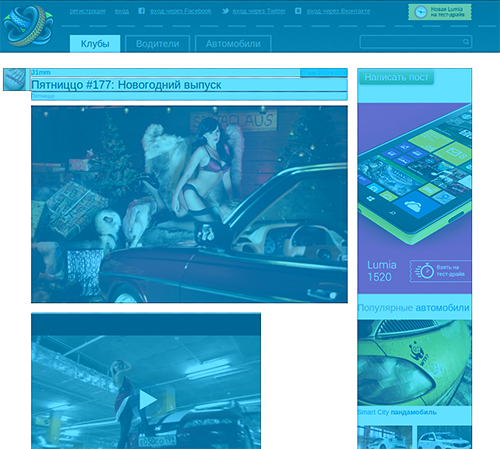
Пример работы алгоритма на сайте Автокадабра.
Задача
Наверное, все знают про сервис "Вебвизор", который позволяет записывать действия посетителей вашего сайта и просматривать их в режиме видео. Инструмент интересный, но когда на сайте много посетителей, составить картину жизни сайта проблематично, каждый ролик не посмотришь, и сгруппировать их нельзя.
Гораздо полезней отследить взаимодействие посетителей с сайтом, выяснить чем живёт сайт, с возможностью охватить одновременно множество посетителей. В итоге, появилась идея записывать информацию в виде осмысленного списка действий посетителей:
- Dima : переход на сайт с поисковой системы Yandex RU по запросу sepyra (3м. 10 сек. назад)
- Dima : переход со страницы " Веб-аналитика Sepyra / Официальный сайт " на страницу " О системе / Веб-аналитика Sepyra (1 м. 30 сек. назад)
- Dima : выделение текста " времени " в блоке " Одна из ключевых особенностей веб-аналитики Sepyra - возможность… кто хочет быть в курсе каждого шага посетителей " (40 сек. назад)
- Dima : средний интерес к подблоку " Подключиться " в блоке " Тарифы О системе FAQ Контакты Русский English Подключиться Войти " (20 сек. назад)
- Dima : заполнение/изменение поля " Ваше имя " в форме " Регистрация " (10 сек. назад)
Запись состоит из двух частей: блок в котором происходит действие посетителя и само действие, например - выделение текста " времени " в блоке " Одна из ключевых особенностей ... ". Для этого описания необходимо определить блок на странице и его имя. Если с именем было более-менее понятно, то над выделением блоков пришлось подумать.
Варианты решения
Первый шаг - поиск существующих решений этой задачи. Один из них "Метод разбиения веб-страниц на семантические блоки с целью выявления схожих документов" (Д. И. Косинов. Воронежский государственный университет). Здесь определялся наибольший элемент и вынимался из страницы, и так до тех пор пока оставался контент. Чтобы не вытащить сразу весь <BODY>, в функцию веса был введён показатель глубины узла с целью выделять блоки по возможности на более низких уровнях. В процессе реализации и тестирования, выяснилось что проблема возникает в нескольких местах, во первых, требуется правильно подобрать коэффициенты для функции веса, во-вторых, после удаления контента на странице остаются "дырки", и следующий блок получается рваным, например блок 4 на рисунке.

После этого начали прорабатываться свои решения, одним из вариантов было выделять блоки с определенной длиной контента, который оказался не совсем удачным. Как-то вечером пришло другое решение, ставшее окончательным. Суть была проста, зачем искать семантические блоки на странице, когда вёрстка в основном итак объединяет блоки по смыслу, необходимо только определить до какого уровня разбивать блоки и какие именно.
Окончательный вариант
Алгоритм разбиения веб-страницы на блоки
Основная идея алгоритма заключается в предположении, что объединённые общим смыслом элементы веб-страницы зачастую имеют общего родителя в дереве DOM. Экспериментальным путём было установлено, что число обособленных смысловых блоков на странице в среднем равно квадратному корню из числа элементов на самом нижнем уровне дерева DOM (т. е. квадратному корню из числа элементов, не имеющих дочерних).
Коротко алгоритм можно описать следующими шагами:
- Помещаем в массив корневой элемент дерева DOM
- Пока число элементов в массиве меньше квадратного корня из числа элементов на нижнем уровне дерева DOM повторяем следующий цикл:
-
- Выбираем элемент с наибольшим весом, имеющий дочерние элементы. Если такого нет, то выходим.
- Если же подходящий элемент был найден, удаляем его из массива, добавляем в массив дочерние элементы удалённого и возвращаемся к началу цикла.
Вес элемента
Вес определят, какой следующий элемент будет разбит на дочерние, он учитывает как размер содержимого, так и площадь элемента,
Вес_элемента = log(длина_текста * 0.1 + 1.01) * log(площадь * 0.9 + 0.11).
Больший приоритет отдаётся площади элемента, магические числа 1.01 и 0.11 ограничивают логарифм, чтобы вес оставался положительным числом. Пустые узлы алгоритмом исключаются, поэтому минимальные значения размеров текста и площади составляют единицу. Для объектов, которые не могут содержать внутри текст (изображения, встроенные объекты и т. д.), параметр длина_текста считается как площадь / 140 (140 - среднее значение площади одного символа текста). При подсчёте длины текста исключаются повторяющиеся пробелы, а также не учитывается внутренний текст элементов <STYLE> и <SCRIPT>.
Название блока
Поиск названия блока достаточно прост:
- Внутри блока ищутся заголовочные элементы (H1 - H6)
- Если заголовочных элементов не найдено, ищутся элементы с максимальным размером шрифта
- Если у всех элементов шрифт одинаковый, ищутся элементы с максимальной жирностью шрифта
- Если у всего текста одинаковая жирность шрифта, берётся начало и конец текста.
Что получилось
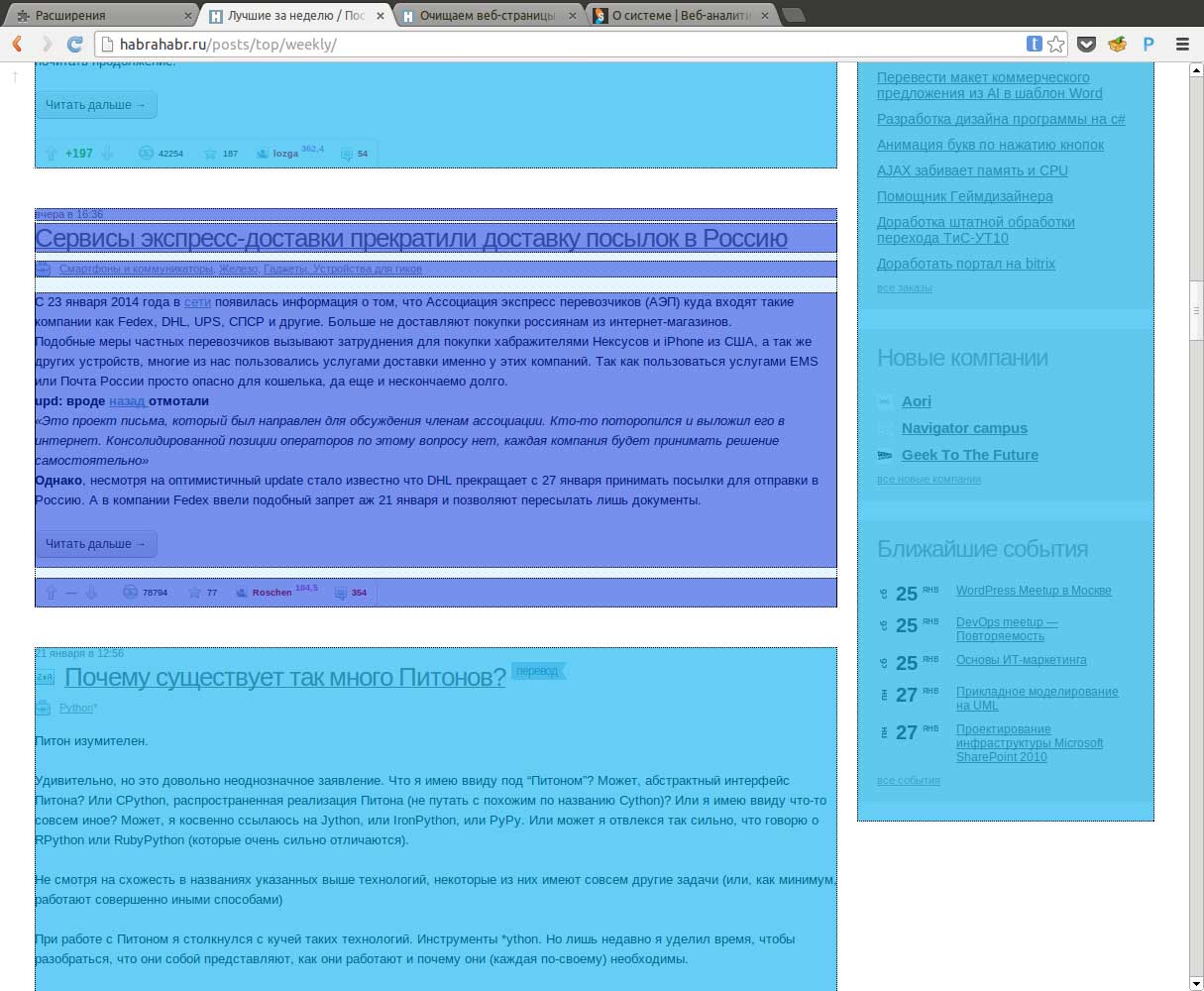
Ниже представлены примеры, того, что вышло в итоге (картинки кликабельны):
Автокадабра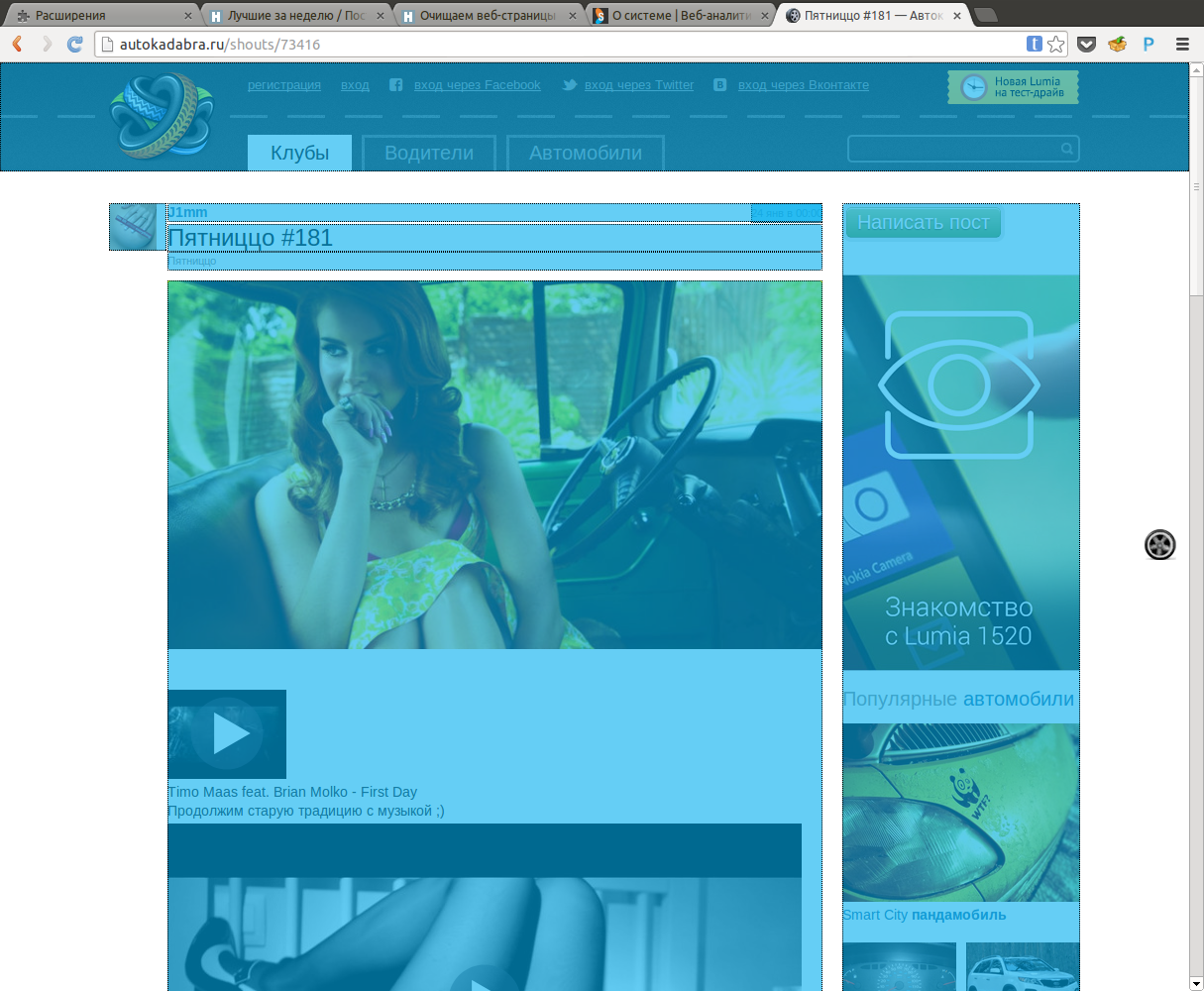
Sepyra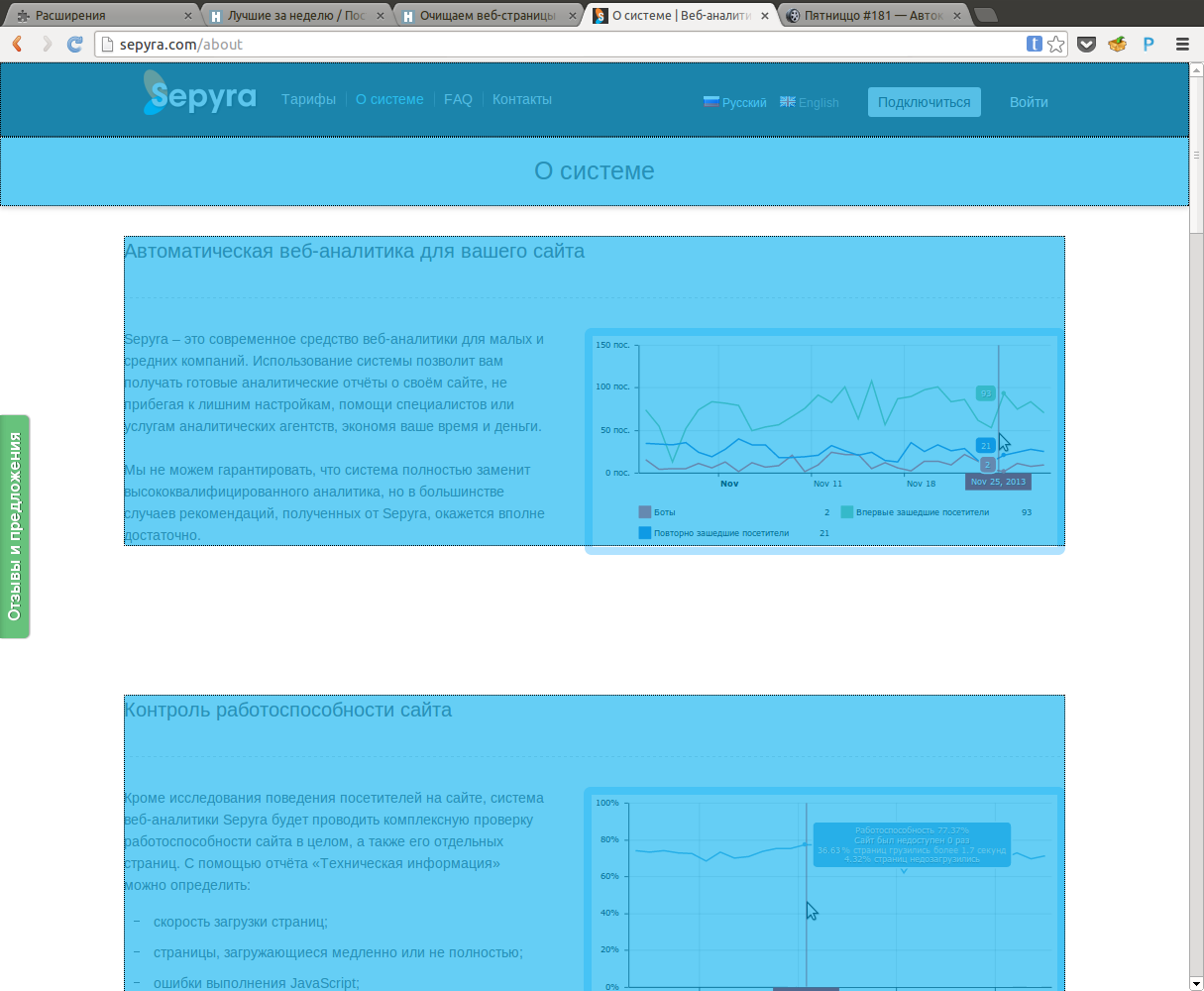
Список статей на Хабре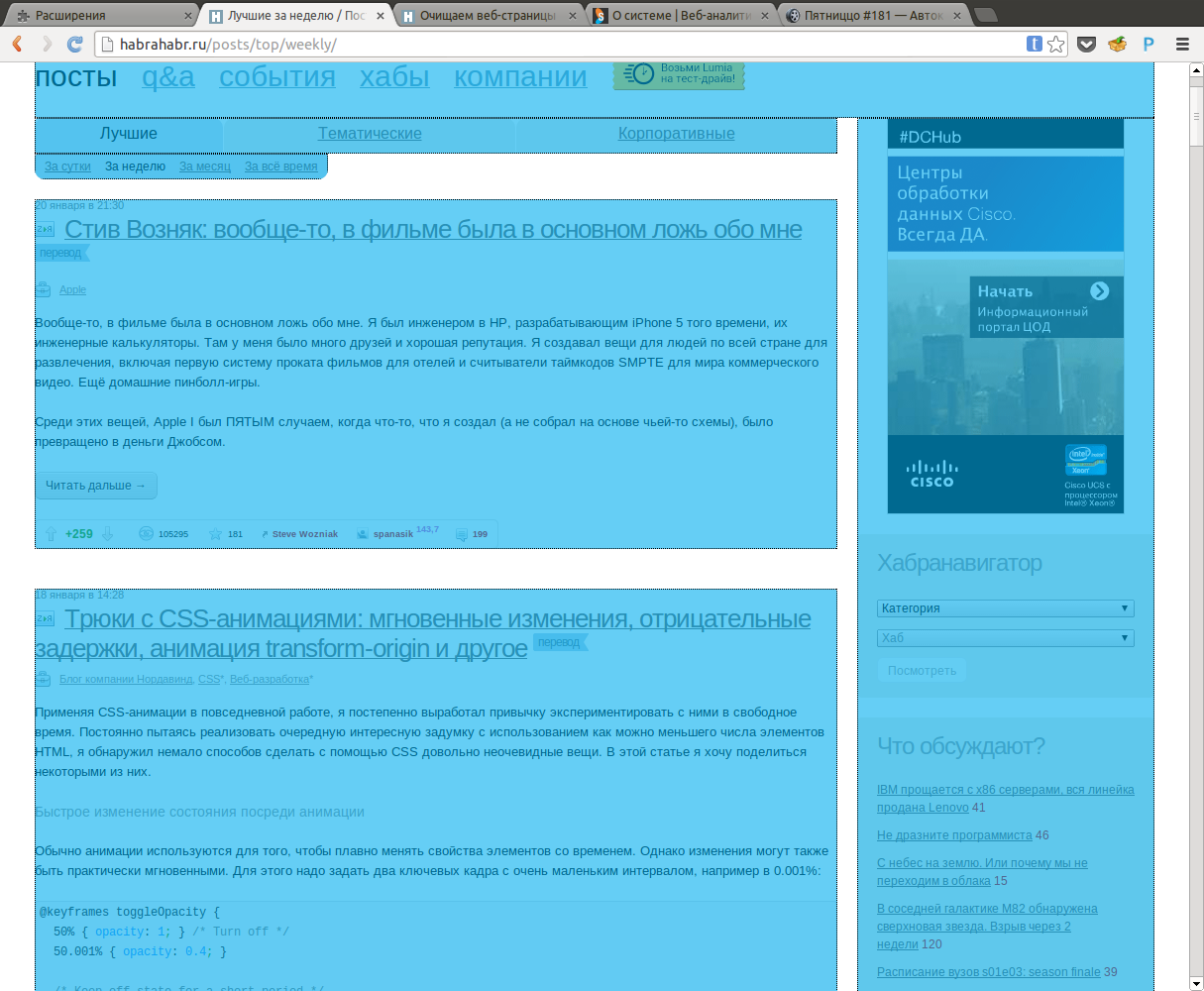
По такому же алгоритму, возможно разделить блок на подблоки:
В живую можно посмотреть здесь, также и другие примеры.
Похожие решения
Также нашлось множество патентов, по данной тематике, может кому пригодится.
- Патент "APPARATUS AND METHOD FOR DISPLAYING WEB PAGE IN MOBILE COMMUNICATION TERMINAL" (US 2007/0110037 A1), представляет метод разделения веб-страницы на блоки для отображения на мобильных устройствах (если далее по тексту - чтобы каждому блоку соответствовала своя клавиша, что удобно для навигации);
- Патент US 2011/0289435 A1, делит страницу на блоки для отображения на экране телевизора, когда для навигации используется пульт от телевизора;
- Патент US 2004/0103371 A1, страница делится на блоки, но уже для того, чтобы лучше отображаться на устройствах с маленьким экраном, причем блоки ранжируются в зависимости от интересности для пользователя, которая высчитывается по тому, как часто пользователь эти самые блоки просматривает;
- Патент US 2011/0285750 A1, для удобного отображения веб-страницы на разных экранах;
- Патент US 2012/0005573 A1 отслеживает, чем интересуется пользователь, потом подсвечивает ему эту область страницы;
- Патент US 2006/0149726 A1 сегментация веб-страницы, с учетом эвристического анализа;
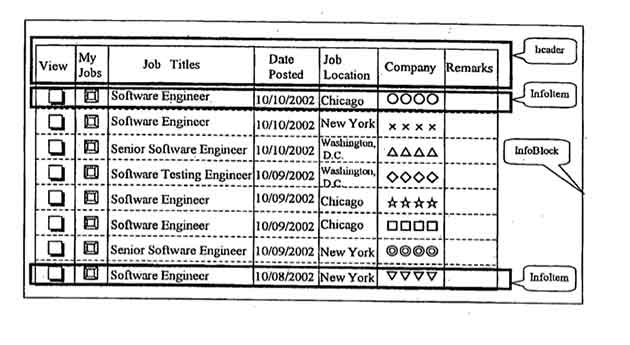
- Патент US 2005/0066269 A1 (Устройство и метод извлечения информационных блоков с веб-страниц), представлено несколько методов сегментирования веб-страницы на информационные блоки, на основе повторяющихся шаблонов
Вывод
Алгоритм получился рабочим, достаточно простым и понятным, что немаловажно. Из минусов, не слишком устойчив, небольшие изменения кода он переживёт, но при добавлении виджетов на страницу, других изменениях структуры документа, блоки могут разбиться иначе.