Семантический Паук - собиратель информации из Всемирной Паутины.
Найти и классифицировать
Когда-нибудь, когда он вырастет, наш Паучок будет бегать по Паутине, читать информацию, написанную людьми и для людей и выделять из нее данные, пригодные для машин. Потом уже большие Машины начнут пользоваться этой информацией и вот тут-то и наступит время Терминаторов, но до этого еще далеко. А пока Семантический Паук делает первые шаги.
Зачем это нужно?
Глобальная цель - научиться в автоматическом режиме составлять онтологии, которые в дальнейшем станут базой для получения новых знаний.
Постановка задачи
Есть набор страниц из интернет, есть онтология некой предметной области (Tbox в owl). Необходимо в автоматическом режиме выделить на рассматриваемых страницах объекты онтологии и дополнить онтологию (Abox).
Метод решения
Язык программирования - java, основа краулера - проект crawler4j, первая онтология - онтология работы над проектами (MoWoP).
Проект "Базовая самоформирующаяся онтология"
ToDo:
- Составить базовую онтологию
- Выбрать модель хранения ont в памяти, научиться считывать онтологию в память
- Составить список базовых сайтов
- Настроить crawler4j на обход п.3
- Сделать алгоритм "разумного" пополнения данных. Например, как написано ниже.
Тестовый запуск: человек + фирма. Ч.1
Решено работать в онлайн режиме: все черновые записи - в блоге, все тестовые запуски и полученные результаты (или не полученные :-) ) - на соответствующие страницы сайта. А почему бы и нет? Возможно, только алгоритмы будут закрытыми, хотя на текущий момент закрывать особо нечего
Итак, эксперимент №1
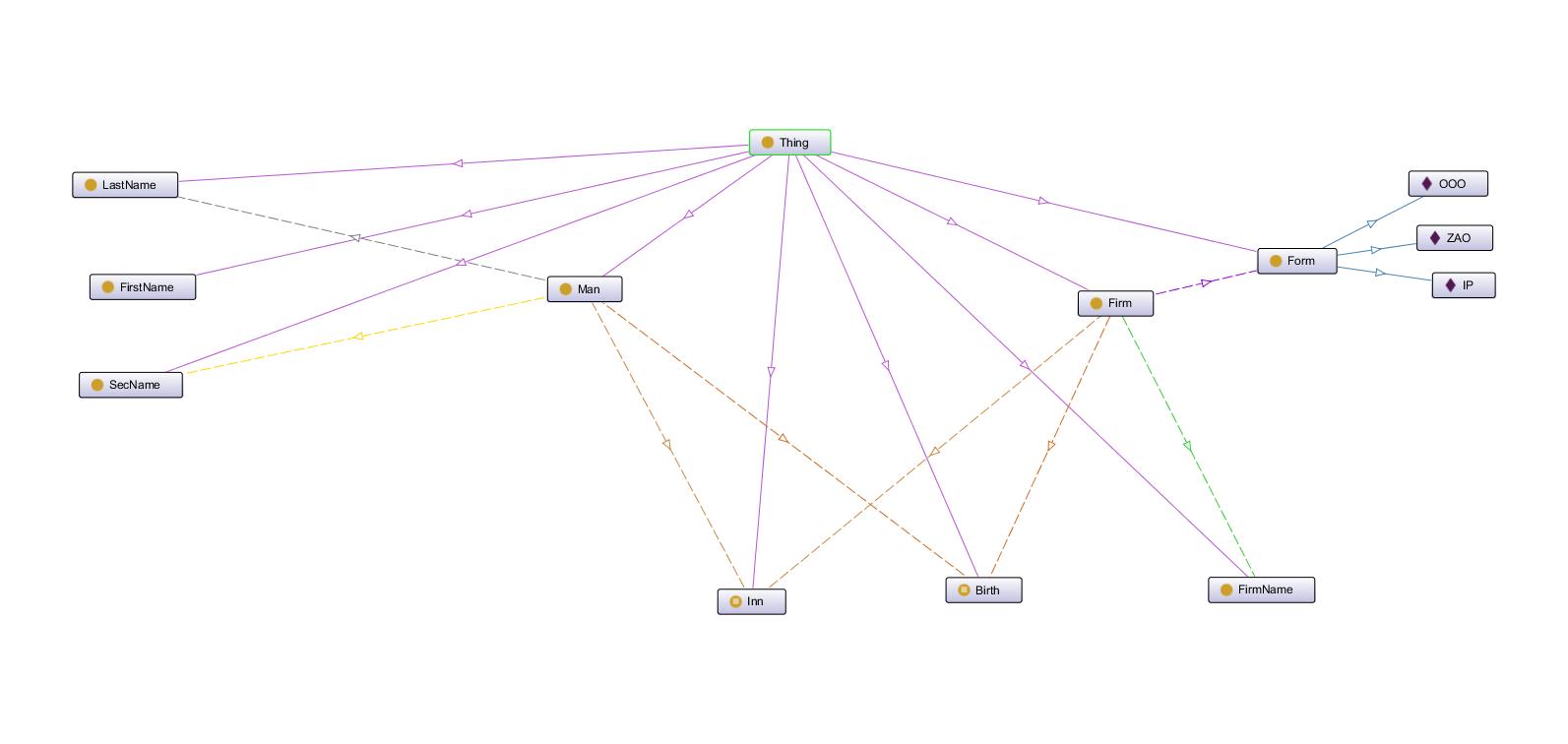
Имеется набор данных ("триплетов", "троек") по а) человеку и б) организации. Представим этот набор данных следующим образом:
Человек
- Фамилия
- Имя
- Отчество
- Дата рождения
- ИНН
Организация
- Название
- Организационно-правовая форма
- Дата регистрации
- ИНН
Данные связаны следующим образом:
| Субъект | Связь | Объект | Примечание |
| Человек | имеет_имя | Имя | |
| Человек | имеет_фамилию | Фамилия | |
| Человек | имеет_отчество | Отчество | |
| Человек | родился | Дата_рождения | |
| Человек | имеет_инн | ИНН_человека | |
| Человек | владелец | Организация | |
| Организация | имеет_название | Название | |
| Организация | зарегистрирована_как | Орг_прав_форма | |
| Организация | зарегистрирована_когда | Дата_регистрации | |
| Организация | имеет_инн | ИНН_организации |
Весь этот набор данных представляется собой мини-онтологию. Ну хорошо, конечно не онтологию, но основные принципы соблюдены и ничто не мешает дальнейшему маштабированию схемы.
Задача семантического паука - на основе имеющихся данных (онтология частично заполнена, т.е. присутствует A-Box и частично Е-box) и массива данных постараться заполнить остальные поля.
В случае спорных моментов данные должны предоставляться человеку-эксперту. Алгоритм работы семанического паука должен быть в разумных пределах общим, однако это не должно мешать заложить разумные подсказки типа использования соцсетей и реестров налоговых служб.
Для начала предположим, что нам известны ФИО человека и название компании, далее в схему должны быть добавлены шаблоны, потом - словари синонимов и т.д.
Вопрос 1: По каким страницам искать.
Очевидно, что на данном этапе выпускать маленького и неокрепшего паучка на просторы интернета глупо и бессмысленно. Да и задача такая, что можно не задумываясь выделить несколько ресурсов (сайтов), которые в первую очередь необходимо изучить. Итак, решение первое: жестко ограничим набор целевых сайтов:
- facebook.com
- vk.com
- odnoklassniki.ru
- реестры налоговой и регистрации юр.лиц
Вопрос 2: хранение "онтологии" и найденных данных
Очевидно, что с точки зрения дальнейшей совместимости не стоит пренебрегать стандартами. Следовательно, и А-box, и начальные, и получаемые данные следует хранить в owl-файле.
Вопрос 3: алгоримт перебора страниц и выделения релевантных данных
Самый сложный вопрос, но, так как сравнивать все равно не с чем, пусть будет такой алгоритм:
- Берем первый сайт из списка
- Делаем поиск по этому сайту первой тройки из онтологии (возможно, стоит ввести поисковые коэффициенты-веса??)
- на первых n страницах из выдачи ищем все оставшиеся тройки
- В случае обнаружения данных дописываем их в онтологию
- В случае подозрения на обнаружение данных выводим запрос эксперту
- Переходим к следующему сайту и пункту 2.
Тестовый запуск: человек + фирма. Ч.2
Мини-онтология, несмотря на то, что она мини, будет у нас носить все черты полноценной предметной онтологии - т.е. разрабатываться в protege, храниться в owl-файле и обрабатываться по правилам и логике "больших" баз знаний.
В первом приближении выглядит это так: