Объемы информации, поступающей из различных источников, растут сегодня ошеломляющими темпами. В 2012 году количество пользователей Интернета достигло 2,27 миллиардов. Ежедневно социальная сеть Twitter генерирует более 12 ТБ данных твитов, Facebook - более 25 ТБ данных материалов, а Нью-Йоркская биржа New York Stock Exchange - более 1 ТБ данных о торгах. Каждый день создается более 30 миллиардов меток радиочастотной идентификации (RFID). Добавьте сюда же данные, генерируемые сотнями миллионов GPS-устройств, которые продаются каждый год, а также более 30 миллионами сетевых датчиков, количество которых увеличивается ежегодно на 30%. Ожидается, что объем этих данных будет удваиваться каждые два года в течение следующих 10 лет.
В течение года в организациях может генерироваться до нескольких петабайтов информации: Web-страницы, блоги, счетчики посещаемости сайтов, поисковые индексы, форумы, системы мгновенных сообщений, текстовые сообщения, электронная почта, документы, демографические характеристики потребителей, данные активных и пассивных систем мониторинга и многое другое. По различным оценкам около 80% этих данных слабо структурированы или не структурированы вообще. Организации всегда стремятся стать более гибкими в своей деятельности и более новаторскими в плане анализа данных и принятия решений. Они понимают, что лишнее время, потраченное на это, может привести к упущенным возможностям для их бизнеса. Основной задачей для компаний, работающих с большими данными, является получение возможности анализа и работы с информацией в масштабах Интернета с такой же легкостью, как при работе с небольшими объемами структурированных данных.
На рисунке 1 проиллюстрирована проблема извлечения знаний из огромного объема разнородных данных в движении - проблема, решить которую до сих пор не представлялось возможным.
Рисунок 1. Проблема больших данных
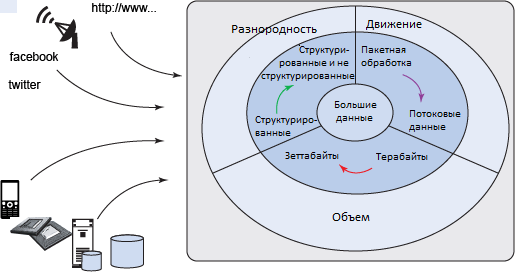
На рисунке 1 термин объем характеризует масштаб данных - от терабайтов до зеттабайтов. Термин разнородность характеризует сложность различных структур, содержащих данные - от реляционных БД до простых текстовых файлов. Термин в движении характеризует потоковые данные и перемещение больших объемов информации.
IBM помогает компаниям в решении проблем больших данных и предлагает воспользоваться инструментами для интеграции и управления объемом и многообразием данных, привычными средствами анализа, функциями визуализации данных для анализа ad-hoc, а также многими другими возможностями. Эта статья познакомит вас с InfoSphere Streams - технологией, позволяющей одновременно анализировать данные многих типов и выполнять сложные вычисления в реальном времени. Вы узнаете о том, как работает платформа InfoSphere Streams и в каких случаях она может оказаться полезной, а также о том, как использовать ее совместно с другим продуктом IBM для анализа больших данных - IBM InfoSphere BigInsights - для выполнения многосложного анализа.
Познакомившись с InfoSphere BigInsights, вы сможете лучше понять предназначение InfoSphere Streams и оценить значимость этого продукта. Если вы уже знакомы с BigInsights, то можете сразу перейти к следующему разделу.
BigInsights - это платформа для анализа данных, позволяющая компаниям превращать сложные наборы данных масштаба Интернета в знания. В состав этой платформы входят легко устанавливаемый дистрибутив Apache Hadoop, а также набор связанных инструментов, необходимых для разработки приложений, переноса данных и управления кластером. Благодаря своей простоте и масштабируемости Hadoop, представляющий собой Open Source-реализацию инфраструктуры MapReduce, пользуется заслуженным признанием в различных отраслях промышленности и науки. Помимо Hadoop, в состав BigInsights входят следующие Open Source-технологии (все они, за исключением Jaql, являются проектами Apache Software Foundation):
- Pig - платформа, включающая в себя высокоуровневый язык описания программ, анализирующих большие наборы данных. В состав Pig входит компилятор, преобразующий приложения Pig в последовательности заданий MapReduce, исполняемых в среде Hadoop.
- Hive - решение для организации хранилищ данных, разработанное на основе среды Hadoop. В нем реализованы знакомые принципы реляционных баз данных - таблицы, столбцы, разделы. Также в его состав входит набор SQL-операторов (HiveQL) для работы в неструктурированной среде Hadoop. Запросы Hive компилируются в задания MapReduce, исполняемые в среде Hadoop.
- Jaql - язык запросов с SQL-подобным интерфейсом, разработанный IBM и предназначенный для JavaScript Object Notation (JSON). Jaql отлично поддерживает вложенность, является в высокой степени функционально-ориентированным и чрезвычайно гибким. Этот язык хорошо подходит для работы со слабо структурированными данными; также он служит интерфейсом хранилища столбцов HBase и используется для анализа текста.
- HBase - ориентированная на столбцы не-SQL среда хранения данных, предназначенная для поддержки больших таблиц с малой степенью наполненности в Hadoop.
- Flume - распределенная, надежная и доступная служба, предназначенная для эффективного перемещения больших объемов генерируемых данных. Flume хорошо подходит для получения журналов событий из нескольких систем и их перемещения в файловую систему Hadoop (Hadoop Distributed File System, HDFS) по мере их генерации.
- Lucene - библиотека поисковой системы, обеспечивающая высокую производительность и полноценный текстовый поиск.
- Avro - технология последовательного упорядочивания данных, использующая JSON для определения типов данных и протоколов. Упорядочивает данные в компактном двоичном формате.
- ZooKeeper - централизованная служба, предназначенная для поддержки конфигурационной информации и именования; обеспечивает распределенную синхронизацию и групповое обслуживание.
- Oozie - система планирования поточной обработки заданий, предназначенная для организации и управления выполнением заданий Apache Hadoop.
В дополнение к вышеперечисленным продуктам в дистрибутив BigInsights включены следующие технологии IBM:
- BigSheets - браузерный интерфейс в виде электронной таблицы, предназначенный для поиска и анализа данных и использующий всю мощь Hadoop; позволяет пользователям легко собирать и анализировать данные. Содержит встроенные программы просмотра данных, умеющие работать с несколькими распространенными форматами, включая JSON, CSV (значения, разделенные запятыми) и TSV (значения, разделенные знаками табуляции).
- Text analytics - предварительно собранная библиотека текстовых аннотаторов для распространенных бизнес- объектов. Содержит богатый язык и инструментарий для создания пользовательских аннотаторов местоположений.
- Adaptive MapReduce - решение, разработанное IBM Research и предназначенное для ускорения выполнения небольших заданий MapReduce путем изменения способа их обработки.
Вообще продукт BigInsights не предназначен для замены традиционных систем управления реляционными базами данных (СУБД) или систем хранения данных. В частности, BigInsights не оптимизирован для выполнения интерактивных запросов к табличным структурам данных, оперативного анализа данных (OLAP) или оперативной обработки транзакций (OLTP). Тем не менее, являясь частью платформы IBM Big Data, BigInsights содержит точки интеграции с другими ее компонентами, включая системы хранения и интеграции данных, механизмы управления и сторонние инструменты для анализа данных. Далее в этой статье вы увидите, что BigInsights можно также интегрировать с платформой InfoSphere Streams.
Потоковые вычисления: новая парадигма
Потоковые вычисления - это новая парадигма, потребность в которой вызвана новыми сценариями генерации данных - повсеместное использование мобильных устройств, службы по определению местоположения и широкая распространенность всевозможных датчиков. Все это породило острую потребность в масштабируемых вычислительных платформах и параллельных архитектурах, способных обрабатывать огромные объемы генерируемых потоковых данных.
Технологии BigInsights не подходят для обработки потоковых данных в реальном времени, поскольку ориентированы в основном на пакетную обработку статичных данных. При обработке статичных данных ответом на запрос " Выбрать всех пользователей, подключавшихся к сети " будет являться один результирующий набор значений. При обработке потоковых данных в реальном времени можно выполнять непрерывный запрос, например " Выбрать всех пользователей, подключавшихся к сети за последние 10 минут ". Этот запрос будет непрерывно обновлять результаты. В мире статичных данных пользователь будет искать пресловутую иголку в стоге сена, тогда как в мире потоковых данных он будет искать эту иголку по мере того, как ветер сдувает сено со стога.
На рисунке 2 проиллюстрирована разница между вычислениями, выполняемыми над статичными данными, и вычислениями, выполняемыми над потоковыми данными.
Рисунок 2. Сравнение обработки статичных данных и обработки потоковых данных
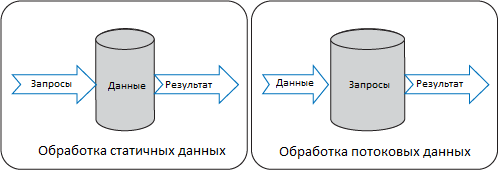
При обработке статичных данных (левая часть рисунка 2) выполняются запросы к статичным данным. При обработке потоковых данных (правая часть рисунка 2) данные непрерывно проходят через статические запросы.
Платформа InfoSphere Streams поддерживает обработку потоковых данных в реальном времени, обеспечивая периодическое обновление результатов непрерывных запросов. Нужные знания могут быть извлечены из потоков данных, которые еще находятся в движении.
Обзор платформы InfoSphere Streams
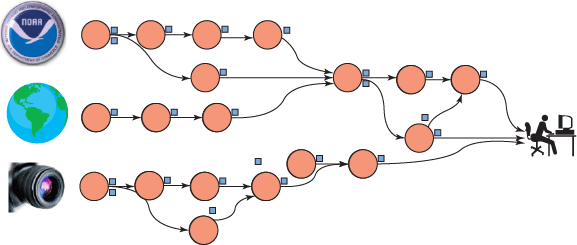
Платформа InfoSphere Streams предназначена для извлечения элементов, соответствующих заданным шаблонам, из данных, находящихся "в движении" (потоки данных), за время, варьирующееся от нескольких минут до нескольких часов. Эта платформа полезна для бизнеса благодаря возможности оперативного получения нужных данных и лучшим результатам при работе с приложениями, чувствительными к времени отклика (таким как выявление случаев мошенничества или управление сетью). InfoSphere Streams может также объединять потоки, позволяя получать новые знания из нескольких потоков, как показано на рисунке 3.
Рисунок 3. Обработка объединенных потоков
Главными задачами InfoSphere Streams являются:
- Быстрое реагирование на события и на изменения условий и требований бизнеса.
- Поддержка непрерывного анализа данных на скоростях, превышающих на порядки скорости существующих систем.
- Быстрая адаптация к изменениям форм и типов данных.
- Обеспечение высокой доступности, управление неоднородными данными и реализация новой потоковой парадигмы.
- Обеспечение защиты и конфиденциальности информации, предоставляемой для общего доступа.
InfoSphere Streams содержит модель программирования и интегрированную среду разработки для определения источников данных, а также программные аналитические модули, называемые операторами, объединенные в исполнительные модули обработки. Также InfoSphere Streams содержит инфраструктуру, позволяющую составлять из этих компонентов масштабируемые приложения для обработки потоков. Основными компонентами платформы являются:
- Среда времени выполнения - включает в себя стандартизированные сервисы и планировщик для развертывания и мониторинга Streams-приложений на одном или нескольких интегрированных узлах.
- Модель программирования - позволяет создавать Streams-приложения при помощи декларативного языка Streams Processing Language (SPL). Этот язык позволяет описывать требуемые факты, а среда времени выполнения отвечает за выбор наилучшего способа обработки запроса. В этой модели Streams-приложения представляются в виде графов, которые состоят из операторов и соединяющих их потоков.
- Инструменты мониторинга и интерфейсы администрирования - скорость работы Streams-приложений с данными намного больше, чем та, которую могут отследить обычные средства мониторинга операционной системы. InfoSphere Streams содержит инструменты, предназначенные для работы в такой среде.
Язык Streams Processing Language
SPL - это язык программирования для InfoSphere Streams, являющийся языком построения распределенных потоков данных. SPL представляет собой полнофункциональный язык программирования наподобие C++ или Java™, поддерживающий пользовательские типы данных. Собственные функции можно писать как на SPL, так и на языках C++ или Java. Определяемые пользователем операторы можно писать на C++ или Java.
Непрерывное приложение InfoSphere Streams описывает ориентированный граф, состоящий из отдельных операторов, соединенных и работающих с несколькими потоками данных. Потоки данных могут попадать в систему как извне, так и генерироваться приложениями внутри нее. SPL-приложения состоят из следующих основных составных элементов:
- Поток - бесконечная последовательность структурированных записей. Может обрабатываться операторами построчно или на основе заданного окна.
- Запись - структурированный список атрибутов и их типов. Каждая запись потока соответствует форме, определяемой типом потока.
- Тип потока - определяет имя и тип данных для каждого атрибута записи.
- Окно - ограниченная последовательная группа записей. Окно может быть основано на счетчике, времени, значении атрибута или знаках препинания.
- Оператор - главный составной элемент SPL. Операторы обрабатывают данные потоков и могут порождать новые потоки.
- Обрабатывающий элемент - главный исполнительный блок, может состоять из одного или нескольких операторов.
- Задание - Streams-приложение, развертываемое для выполнения, состоит из одного или нескольких обрабатывающих элементов. Помимо обрабатывающих элементов компилятор SPL генерирует файл на языке Application Description Language (ADL), описывающий структуру приложения. ADL-файл содержит подробную информацию о каждом обрабатывающем элементе: информацию о том, какой двоичный файл необходимо загрузить и выполнить, данные об ограничениях планировщика, описания форматов потока и внутренний граф потока данных оператора.
На рисунке 4 проиллюстрирован рабочий цикл SPL-приложения в среде InfoSphere Streams.
Рисунок 4. Рабочий цикл InfoSphere
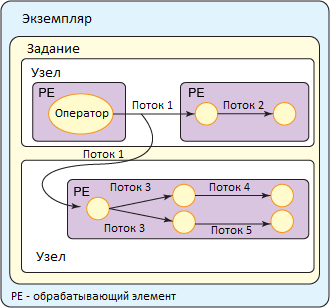
Оператор представляет собой преобразователь потока с возможностью многократного использования и преобразовывает входные потоки в выходные. В SPL-приложениях вызов оператора приводит к его специфическому использованию, которое заключается в назначении особых входного и выходного потоков, а также локально заданных параметров и логики. При каждом вызове оператора входному и выходному потокам назначаются имена. Ниже приводится список встроенных операторов InfoSphere Streams, выполняющих различные функции:
Source- считывает входящие данные в формате потоков.Sink- записывает данные в исходящие потоки, передаваемые во внешние хранилища или системы.Functor- фильтрует, преобразовывает и выполняет функции над данными входного потока.Sort- сортирует потоки данных по заданным ключам.Split- разделяет входные потоки на несколько выходных.Join- объединяет данные входных потоков по заданным ключам.Aggregate- группирует данные потоков по заданным ключам.Barrier- объединяет и приводит в соответствие данные потоков.Delay- приостанавливает поток данных.Punctor- идентифицирует группы данных, которые следует обрабатывать вместе.
Место, в котором потоки присоединяются к оператору, называется портом. Многие операторы (например, Functor) имеют один входной порт и один выходной порт. Некоторые операторы могут не иметь как входного (Source), так и выходного (Sink) порта, а могут, наоборот, иметь несколько входных или выходных портов (например, операторы Split и Join). В листинге 1 показан пример оператора Sink, имеющего один входной порт и записывающего исходящий поток в файл на диске.
Листинг 1. Пример оператора Sink
() as Sink = FileSink(StreamIn) {
param
file : "/tmp/people.dat";
format : csv;
flush : 20u;
}Параметр file в листинге 1 является обязательным и содержит путь к выходному файлу. Параметр flush сбрасывает буфер вывода после заданного количества записей. Параметр format задает формат выходного файла.
Составной оператор - это набор операторов, представляющий собой инкапсуляцию подграфов простых (не составных) или составных (вложенных) операторов. Составной оператор является аналогом макроса в процедурных языках.
Приложение представляется в виде главного составного оператора, не имеющего входных и выходных портов. Данные передаются внутрь и наружу, но не в потоки внутри графа; потоки можно экспортировать и импортировать из других приложений, запущенных в том же экземпляре. В листинге 2 представлена структура главного составного оператора.
Листинг 2. Структура главного составного оператора
composite Main {
graph
stream ... {
}
stream ... {
}
...
}В качестве примера рассмотрим простое потоковое приложение под названием WordCount, которое подсчитывает количество строк и слов в файле. Это приложение состоит из следующих потоковых графов:
- Вызов оператора
Source, который считывает файл и отправляет строки в поток данных. - Вызов оператора
Functor, который подсчитывает количество строк и количество слов в каждой отдельной строке и отправляет статистику в свой исходящий поток. - Вызов оператора
Counter, который суммирует статистику для всех строк файла и выводит результат.
Прежде чем перейти к рассмотрению главного составного оператора приложения WordCount, я определю несколько вспомогательных функций. Для хранения статистики по каждой строке я определю тип LineStat. Кроме того, мне потребуется создать функцию countWords(rstring line) для подсчета слов в строке и функцию addM(mutable LineStat x, LineStat y) для суммирования двух значений типа LineStat и сохранения результата. Эти вспомогательные функции представлены в листинге 3.
Листинг 3. Определение вспомогательных функций для приложения WordCount
type LineStat = tuple<int32 lines, int32 words>;
int32 countWords(rstring line) {
return size(tokenize(line, " \t", false));
}
void addM(mutable LineStat x, LineStat y) {
x.lines += y.lines;
x.words += y.words;
}Теперь можно определить главный составной оператор, как показано в листинге 4.
Листинг 4. Главный составной оператор приложения WordCount
composite WordCount {
graph
stream<rstring line> Data = FileSource() {
param file : getSubmissionTimeValue("file");
format : line;
}
stream<LineStat> OneLine = Functor(Data) {
output OneLine : lines = 1, words = countWords(line);
}
() as Counter = Custom(OneLine) {
logic state : mutable LineStat sum = { lines = 0, words = 0 };
onTuple OneLine : addM(sum, OneLine);
onPunct OneLine : if (currentPunct() == Sys.FinalMarker)
println(sum);
}
}Среда разработки
В InfoSphere Streams включена удобная среда разработки, состоящая из Eclipse IDE, Streams Live Graph, и Streams Debugger. Кроме того, в состав платформы включены наборы инструментов, ускоряющие и облегчающие разработку решений для определенных типов задач или направлений:
- Стандартный набор инструментов - содержит операторы, поставляемые в продукте по умолчанию:
- Операторы отношения -
Filter,Sort,Functor,Join,PunctorиAggregate - Операторы сопряжения -
FileSource,FileSink,DirectoryScanиExport - Вспомогательные операторы -
Custom Split,DeDuplicate,Throttle,Union,Delay,ThreadedSplit,BarrierиDynamicFilter
- Операторы отношения -
- Набор инструментов для Интернета - содержит операторы
HTTP,FTP,HTTPS,FTPSиRSS. - Набор инструментов для работы с базами данных - поддерживает различные СУБД, включая DB2®, Netezza, Oracle Database, SQL Server и MySQL.
- Другие встроенные инструменты для работы с финансами, текстом и "большими данными", а также для глубинного анализа данных.
Кроме того, вы можете выбрать другие необходимые вам наборы инструментов, содержащие операторы и функции, которые позволяют создавать кросс-доменные укорители и ускорители, ориентированные на домены. Эти наборы инструментов могут включать в себя примитивы и составные операторы, и использовать как встроенные функции, так и функции языка SPL.
Интеграция и взаимодействие BigInsights и InfoSphere Streams
Компании, в которых постоянно генерируются большие объемы ценной информации, пытаются решать проблему анализа данных по двум важным причинам: необходимость своевременного распознавания и реагирования на возникающие события и прогнозирование будущих действий на основе уже накопленной информации. Эти причины приводят к необходимости обеспечения следующих функций: прозрачная работа с данными, находящимися "в движении" (текущие данные), анализ данных, находящихся "в покое" (накопленные данные), работа с огромными объемами разнородных данных "в движении". Интеграция IBM InfoSphere Streams (данные "в движении") и BigInsights (данные "в покое") хорошо подходит для следующих сценариев:
- Масштабируемый процесс захвата информации - процесс непрерывной передачи данных из Streams в BigInsights. Например, неструктурированные текстовые данные социальных сетей (подобных Twitter и Facebook), как правило, подвергают обработке для того, чтобы узнать о различных мнениях или тенденциях. В этом случае гораздо эффективнее будет извлекать нужные данные по мере их получения, а ненужные данные (например, спам) уничтожать на ранних этапах. Такая интеграция позволит компаниям избежать лишних затрат на хранение огромных объемов ненужной информации.
- Усовершенствование и обогащение - исторический контекст, генерируемый BigInsights для усовершенствованного анализа и обогащения входящих данных Streams. BigInsights можно использовать для анализа интегрированных данных, полученных из различных динамических и статических источников за длительный период времени. Результаты этого анализа формируют содержимое для различных методов анализа в реальном времени, и эти результаты можно привести к требуемому состоянию. Если мы снова рассмотрим социальные сети, то увидим, что в сообщении сети Twitter содержится только идентификатор человека, написавшего это сообщение. Однако накопленные исторические данные могут дополнить эту информацию различными атрибутами (например, первопричина сообщения), создав возможность проанализировать данные на более низком уровне и правильно отреагировать на настроение этого пользователя.
- Адаптивные модели анализа - модели, генерируемые в BigInsights в процессе анализа (такими моделями могут являться глубинный анализ данных, машинное самообучение или статистическое моделирование). Эти модели могут служить базой для анализа входящих данных в Streams и обновляться на основе наблюдений в реальном времени.
Данные "в движении" и данные "в покое", являющиеся частью платформы IBM Big Data, можно интегрировать с помощью трех основных типов компонентов:
- Общие средства анализа - как в Streams, так и в BigInsights можно использовать одни и те же средства анализа данных.
- Общие форматы данных - операторы форматирования Streams могут преобразовывать данные из формата записей Streams в форматы, используемые в BigInsights.
- Адаптеры обмена данными - для обмена данными с BigInsights можно использовать адаптеры
SourceиSinkплатформы Streams.
Заключение
Ключевая задача платформы IBM Big Data - помогать компаниям обрабатывать "большие данные", анализировать их и извлекать из них выгоду. В этой статье вы познакомились с InfoSphere Streams - программной платформой IBM для хранения и анализа данных "в движении" (потоковые данные). Также было рассказано, как интегрировать InfoSphere Streams с BigInsights - другой программной платформой IBM для хранения и анализа уже накопленных данных, позволяющей выполнять более сложный расширенный анализ. Многие компании понимают, что капитализация "больших данных" является важным инструментом управления информацией, позволяющим получать уникальные и ценные преимущества в бизнесе.