Известно, что встроенная функция newID() широко используется разработчиками не только по прямому назначению - то есть для генерации уникальных первичных ключей, но и в качестве средства для генерации массивов псевдослучайных данных.
В составе встроенных функций, newID() фактически единственная, которая не только non-deterministic, но можно сказать и "super-non-deterministic", т.к. в отличие от всех остальных, она способна выдавать новое значение для каждой новой строки, а не одно и то же для всего батча - что делает ее чрезвычайно полезной для подобной массовой генерации. Кроме newID() этим свойством обладает еще newSequentialID(), однако ее использование где-либо, кроме как в задании дефолтного значения колонок типа uniqueidentifier, запрещено.
За примерами далеко ходить не надо - ниже код:
SELECT TOP 100 ABS(CHECKSUM(NEWID())) % 1000 FROM sysobjects A CROSS JOIN sysobjects B
или вот этот (если кажется, что checksum - трудоемкая операция):
SELECT TOP 100 ABS(CONVERT(INT, (CONVERT(BINARY(4), (NEWID()))))) % 1000 FROM sysobjects A CROSS JOIN sysobjects B
Сгенерирует нам таблицу из 100 случайных целых чисел в диапазоне от 0 до 999.
Для плавающих чисел можно использовать свойство функции rand() инициализировать генератор целым числом:
SELECT TOP 100 RAND(CHECKSUM(NEWID())) FROM sysobjects A CROSS JOIN sysobjects B
В данном случае rand() используется по сути просто как преобразователь диапазона int32 в диапазон [0..1). Статистическая проверка качества распределения этим методом на количестве записей порядка миллиона показывает, что оно не уступает стандартному использованию rand(), инициализированному один раз, и далее используемому в цикле. Поэтому - можете смело использовать.
Еще один интересный вариант - генерация нормально-распределенных данных. Здесь будем использовать метод Бокса-Мюллера:
SELECT TOP 1000 COS(2 * PI() * RAND(BINARY_CHECKSUM(NEWID()))) * SQRT(-2 * LOG(RAND(BINARY_CHECKSUM(NEWID())))) FROM sysobjects A CROSS JOIN sysobjects B CROSS JOIN sysobjects C
Желающие могут проверить, что сгенерированное распределение очень близко к нормальному, построив график.
Все это хорошо работает и позволяет очень быстро сгенерировать хоть десяток миллионов записей, не используя решения "в лоб" типа циклов, курсоров, или даже вставки записей по одной в базу из слоя приложения. Нужно только убедиться, что таблицы, которые вы используете как источник строк, имеют достаточную емкость, и либо увеличить количество CROSS JOIN'ов, либо использовать табличные переменные с нужным количеством строк в качестве источника.
Однако, тема не только об этом. В подавляющем большинстве случаев сгенерированные строки материализуются, то есть вставляются в постоянную или временную таблицу, либо в табличную переменную. Если это так, то дальше можно не читать - материализованные данные будут работать отлично. Однако, встречаются случаи, когда вышеуказанные стейтменты используются в подзапросах. И вот здесь появляются труднообъяснимые на первый взгляд особенности поведения SQL engine. Рассмотрим их на примерах, а затем попытаемся проанализировать, почему так происходит, и как с этим бороться:
Для начала просто напишем statement с newID() в subquery и запустим его несколько раз в цикле:
declare @c int = 0 while @c < 5 begin SELECT * FROM ( SELECT ABS(CONVERT(INT, CONVERT(BINARY(4), NEWID()))) % 5 AS RNDIDX FROM ( SELECT 1 AS ID ) ROWSRC ) SUBQ set @c = @c + 1 end
Код работает ожидаемо - выдает 5 резалтсетов, в каждом строго одна запись с числом в диапазоне от 0 до 4. Скриншота результатов я не привожу - когда и так все в порядке, смысла в них мало.
Теперь интереснее. Пробуем поджойнить результат из SUBQ на какую-нибудь другую таблицу. Ее можно создать, а можно поджойнить subquery на subquery - результат от этого не изменится. Пишем:
declare @c int = 0 while @c < 5 begin SELECT * FROM ( SELECT ABS(CONVERT(INT, CONVERT(BINARY(4), NEWID()))) % 5 AS RNDIDX FROM ( SELECT 1 AS ID ) ROWSRC ) SUBQ INNER JOIN ( SELECT 0 AS VAL UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 ) NUM ON SUBQ.RNDIDX = NUM.VAL set @c = @c + 1 end
Смоторим на скриншот результата выполнения - и медленно сползаем под стул - количество строк в каждом резалтсете не равно строго 1. Где-то пусто (это еще можно хоть как-то объяснить - не сработал INNER JOIN из-за выхода RNDIDX из диапазона [0..4] (что само по себе невероятно!)), а где-то - больше одной (!) записи.
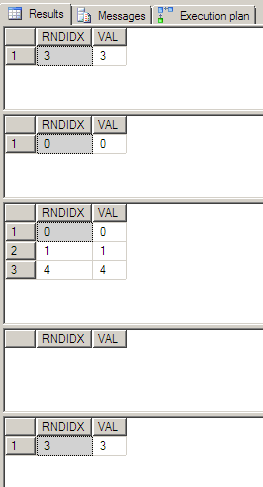
Теперь делаем невинное изменение - меняем INNER на LEFT:
declare @c int = 0 while @c < 5 begin SELECT * FROM ( SELECT ABS(CONVERT(INT, CONVERT(BINARY(4), NEWID()))) % 5 AS RNDIDX FROM ( SELECT 1 AS ID ) ROWSRC ) SUBQ LEFT JOIN ( SELECT 0 AS VAL UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 ) NUM ON SUBQ.RNDIDX = NUM.VAL set @c = @c + 1 end
Выполняем - все стало работать правильно (!) - проверерьте плз сами, скриншота для правильной работы я не делал. Заметьте, что поскольку для любого значения RNDIDX из диапазона [0..4], которое способно выдать сабквери SUBQ, всегда есть значение VAL из сабквери NUM, то с точки зрения логики результат LEFT и INNER JOIN должен быть одинаков. Однако по факту это не так!
Еще один тест - возвращаем INNER, но добавляем TOP / ORDER BY в первый сабквери. Зачем - об этом позже, давайте просто попробуем:
declare @c int = 0 while @c < 5 begin SELECT * FROM ( SELECT TOP 1 ABS(CONVERT(INT, CONVERT(BINARY(4), NEWID()))) % 5 AS RNDIDX FROM ( SELECT 1 AS ID ) ROWSRC ORDER BY RNDIDX ) SUBQ INNER JOIN ( SELECT 0 AS VAL UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 ) NUM ON SUBQ.RNDIDX = NUM.VAL set @c = @c + 1 end
Все опять работает правильно! Мистика!
Погуглив, выясняем, что с подобным поведением периодически сталкиваются SQL-разработчики со всего мира - примеры здесь, или здесь
Люди предполагают, что материализация subquery помогает. Действительно, если переписать пример, выбрав сначала записи в явном виде во временную таблицу, а затем только поджойнив, все работает нормально. Почему же на нормальную работу влияет замена INNER на LEFT, или добавление TOP / ORDER BY там, где это не нужно? Все потому же - в одном случае присутствует материализация результатов subquery, в другом - нет. Нагляднее разницу может показать анализ плана более развернутого случая, например вот этого:
DECLARE @B TABLE (VAL INT) INSERT INTO @B VALUES (0), (1), (2), (3), (4) SELECT * FROM ( SELECT ABS(CONVERT(INT, CONVERT(BINARY(4), NEWID()))) % 5 AS RNDIDX FROM @B ) SUBQ INNER JOIN @B B ON SUBQ.RNDIDX = B.VAL Смотрим естественно, только выборку (query 2), заполнение таблицы @B нам ни к чему: 
Мы видим, что запрос сращивает два потока строк до вычисления значения колонки, зависящей от newID(). Это может происходить потому, что SQL engine считает, что значение, возвращаемое newID(), хоть и non-deterministic, но не изменяется в течение всего батча. Однако, это не так - и скорее всего поэтому запрос работает неправильно. Теперь меняем INNER на LEFT, и смотрим план:

Ага, LEFT JOIN заставил SQL engine выполнить Compute Scalar перед объединением потоков, поэтому наш запрос стал работать правильно.
И наконец, проверим версию с добавлением TOP / ORDER BY:

Собственно, диагноз ясен. MS SQL не учитывает особенности newID(), и соответственно, неправильно строит планы, полагаясь на константное значение, возвращаемое функцией в скоупе батча. На эту особенность есть воркэраунд - заставлять SQL engine любыми способами материализовать выборку, перед тем как ее использовать в зависимых запросах. Каким способом вы будете материализовать - дело ваше, однако лучше всего, наверное, использовать табличные переменные, особенно если размер подвыборки невелик. Иначе результат, мягко говоря, не 100% гарантирован; кроме того, нет никакой гарантии, что однажды вы сами, или кто-нибудь другой не отревьюит код, выкинув "ненужные" TOP / ORDER BY или мудро заменив LEFT на INNER.
Собственно, все. Удачного SQL-программирования!