Проблема постраничной выборки информации из БД стара, как сама БД, и соответственно, обсуждена не одну тысячу раз. Нет, пожалуй, ни одной клиент-серверной системы, в которой эта проблема так или иначе не была бы адресована и решена. Сегодня я хочу рассказать об одном немного нестандартном способе взаимодействия клиентского слоя и MS SQL-бакенда при организации постраничной выборки в типичном публичном веб-приложении.
Для начала очертим типичные бизнес-требования и выведем из них входные условия - мы выбираем данные из некоторого списка (пользователей, товаров, транзакций) страницами по N записей на каждой, начиная с M-ной. Выборка осуществляется с примемением одного или более фильтров и некоторого критерия сортировки. Проблемы чисто клиентских решений типа интерактивных гридов на джаваскрипте, в которые нужно загрузить все данные, здесь рассматривать не будем, а остановимся на более умеренных вариантах, в которых постраничная выдача делается на сервере.
Как это делается традиционно? Слой приложения передает в бакенд значения фильтров, индекс первой нужной записи, и требуемое количество записей на страницу. В ответ база данных, прикладывая фильтры ко всей выборке, упорядочивает весь фильтрованный поднабор, и отдает назад записи с M до M+N-1. То, каким конкретно образом это сделает тот или иной разработчик и/или та или иная версия RDBMS, сейчас для нас несущественно - важно лишь что, что какой бы способ не использовался (временная таблица в MS SQL 2000, ROW_NUMBER OVER () в 2005-2008, или TOP / OFFSET в 2011), необходимость выдачи нумерованного подмножества из фильтрованного упорядоченного множества обязательно означает раскручивание всего промежуточного результата после фильтра и его сортировку. Несущественно также и то, где будет произведено это раскручивание - непосредственно на пространстве данных, или на поле индексов (например, при использовании полного индексного покрытия или INCLUDED-колонок) - принципа эта разница не меняет.
Понятно, что если коэффициент фильтрации невысок, а фильтр - трудоемкий (например, полнотекстовый поиск), то КПД подобного метода будет очень низок, особенно по мере приближения к последним страницам выборки. И даже если фильтр - параметрический (например, по типу пользователя в таблице пользователей), и работает по специально созданному индексу, выкидывание в помойку почти 100% усилий сервера для каждого запроса последних страниц вызывает искреннюю жалость к железке, на которой сам RDBMS, собственно, и крутится.
В реальных же клиент-серверных приложениях существуют еще несколько моментов, усложняющих ситуацию:
a) чтобы правильно отрендерить страницу с пагинацией (прошу прощения за термин), слой приложения должен знать общее количество записей, проходящих через фильтр - для того, чтобы разделив его на N и округлив вверх (с очевидной оговоркой), получить количество страниц, нужное для меню навигации. Чтобы этого достичь, бакенд должен фактически либо выполнять при выборке каждой страницы поисковый запрос дважды - первый раз в усеченном варианте - выбирая просто… COUNT (1)… WHERE , без частичной выборки и сортировки, а второй - уже в полном, с выборкой нужного набора записей. Либо выполнять COUNT при первом переходе к фильтрованному выводу, и запоминать это значение.
б) если за время навигации пользователя по страницам в базе появится новая (или удалится существующая) запись, попадающая под условие фильтра - навигация съедет, и юзер имеет все шансы либо пропустить, либо повторно просмотреть одну или более записей.
в) вообще говоря, БД является наименее масштабируемым звеном в публичных системах, построенных по ACID-принципу. Отсюда вывод, что если вы однажды спроектировали вашу систему как достоверно имеющую все данные одновременно, то есть прямой смысл экономить ресурсы БД в первую очередь, и все, что возможно, разносить на легко масштабируемые сервера приложения.
Типичный алгоритм операций при постраничной навигации выглядит на си-подобном коде так (функции с префиксом DB выполняются в базе данных):while (1) { create_filter(FormData, &F, &S); // создаем фильтр F и дефолтный критерий сортировки S // из параметров поиска на форме FormData DB_get_count(F, &C); // запрашиваем фильтрованное кол-во записей для построения меню навигации while (1) // навигируемся, пока F и S неизменны (иначе начинаем сначала) { DB_get_records(F, N, M, S); // выбираем N записей, начиная с M по фильтру F и сортировке S if (SORT_OR_FILTER_CHANGED == do_navigation(FormData, C, &N, &M, &S)) // обрабатываем пользовательскую навигацию { break; // если сортировка или фильтр поменялись - все сначала } } }
Попробуем теперь его улучшить, избавившись от повторной фильтрации записей в DB_get_records при первом просмотре и каждой последующей навигации. Для этого вместо запроса выборки количества записей, подходящих под фильтр, выбираем весь отсортированный в нужном порядке массив их первичных ключей. Здесь предполагается, что первичные ключи записей компактны (например, int или bigint), а выборка даже с минимальной фильтрацией дает разумное количество записей. Если это не так, то в первом случае можно использовать суррогатные ключи (в подавляющем большинстве случаев так и делается), а во втором - ограничивать выборку разумным количеством (скажем, 100 000), или делать паллиативное решение, выбирая ключи порциями.
По аналогии с функцией DB_get_count псевдокода назовем ее DB_get_keys
Вторым шагом будет переписывание функции выборки данных с N по N+M-1 по заданным фильтрам и сортировке на функцию, которая выберет N записей с ключами, соответствующими переданному ей массиву ключей строго в порядке их нахождения в массиве. Сигнатура ее пусть будетDB_get_records_by_keys(*K, N), где K - адрес массива ключей с нужной точки (то есть с M, а N - количество записей, которое нужно выбрать по этим ключам. Наш псевдоалгоритм теперь будет выглядеть так:
while (1) { create_filter(FormData, &F, &S); // создаем фильтр F и дефолтный критерий сортировки S // из параметров поиска на форме FormData DB_get_keys(F, S, K); // заполняем массив ключей K по фильтру F и сортировке S while (1) // навигируемся, пока F и S неизменны (иначе начинаем сначала) { DB_get_records_by_keys(&(K[M]), N); // выбираем N записей, начиная с M if (SORT_OR_FILTER_CHANGED == do_navigation(FormData, C, &N, &M, &S)) // обрабатываем пользовательскую навигацию { break; // если сортировка или фильтр поменялись - все сначала } } }
Теперь попытаемся дать качественную оценку скорости его выполнения относительно классического. Примем допущение, что время передачи выбранного массива ключей от бакенда ничтожно мало по сравнению с временем поиска нужных данных (так это обычно и есть при передаче небольшого их количества и хорошем сетевом интерфейсе между сервером БД и серверами приложения). Так как общий алгоритм работы остается неизменным, нам достаточно только сопоставить разницу между функциями БД DB_get_count ?? DB_get_keys и DB_get_records ?? DB_get_records_by_keys.
Скорее всего, DB_get_count будет работать немного быстрее, в основном из-за того, что подсчет выбранных фильтром строк (то есть подсчет первичных ключей строк) не потребует внутренней сортировки, плюс отсутствие необходимости выдавать эти ключи из SQL engine наружу. Для сравнения - два execution plan'а: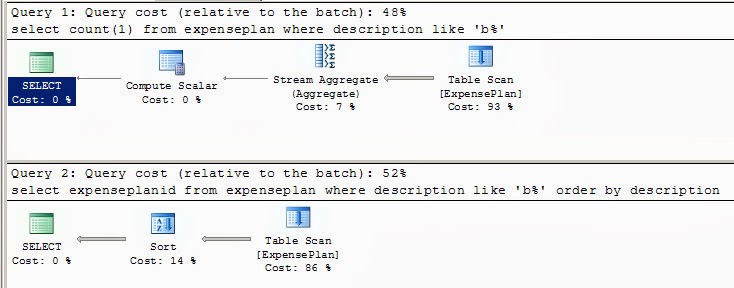
Сравнение же DB_get_records и DB_get_records_by_keys будет в любом случае явно не в пользу первого метода, т.к. выборка записей по первичным ключам является только малой частью операций их поиска.
В итоге мы прогнозируем, что новый метод даст выигрыш, и тем больший, чем более трудоемок фильтр и больше среднее количество перелистываний страниц юзером на одну операцию изменения фильтра или критерия сортировки. Заметим также, что изменение критерия сортировки на обратный по тому же полю (статистически довольно частая операция) при данном способе может вообще производиться без обращения к БД простой инверсией движения указателя на начальный элемент при навигации и добавлению параметра в DB_get_records_by_keys, выбирающего записи по ключам в инверсном переданному порядке.
С точки зрения реализации всей идеи БД, остается лишь один момент - как эффективно передать [под]массив ключей в качестве параметра в статемент или процедуру так, чтобы результирующий вывод сохранил порядок ключей в массиве?
Разобъем эту задачу на две - передача массива в качестве параметра в код БД и собственно, сохранение порядка. Решений первой задачи несколько - основанных на XML или CSV-представлении, либо создании и заполнении табличной переменной. Сам же SQL-код, преобразовывающий входной массив в набор строк может быть выполнен как динамический SQL-запрос, процедура, или табличная функция.
Наиболее гибкой оказывается версия, выполненная без динамики как table function (TF) с использованием CTE - так называемых Common Table Expressions, позволяющих в MS SQL 2008 строить рекурсивные запросы для обработки вложенных данных.
Эту возможность CTE, наряду с возможностью TF быть использованной в качестве table source в составных запросах, мы и используем.
Задачу же сохранения порядка сортировки решим добавлением в структуру возвращаемой TF таблицы поля identity с нужным значением seed и increment (чтобы можно было сортировать снаружи), и указанием явного порядка вставки записей в возвращаемую таблицу (внутри). Функция в итоге получилась такая:
CREATE FUNCTION [dbo].[TF_IDListToTableWithOrder] ( @ListString varchar(MAX), @Delim char(1) ) RETURNS @ID TABLE ( RowIdx INT IDENTITY(0, 1) PRIMARY KEY CLUSTERED, -- поле для внешней сортировки ID INT -- здесь храним значения ключей ) AS BEGIN SET @ListString = REPLACE(@ListString, ' ', '') IF LTRIM(RTRIM(ISNULL(@ListString, ''))) = '' RETURN -- список пуст, выходим с пустой таблицей SET @ListString = @ListString + @Delim -- добавляем хвостовой разделитель, чтобы CHARINDEX всегда давал > 0, включая последний ключ ; -- CTE требует этого разделителя WITH IDRows (ID, Pos) AS ( -- якорная часть (первый ключ) SELECT CONVERT(INT, SUBSTRING(@ListString, 1, CHARINDEX(@Delim, @ListString, 1) - 1)), CHARINDEX(@Delim, @ListString, 1) + 1 UNION ALL -- рекурсивная часть (следующий ключ с позицией, большей последней найденной) SELECT CONVERT(INT, SUBSTRING(@ListString, Pos, CHARINDEX(@Delim, @ListString, Pos) - Pos)), CHARINDEX(@Delim, @ListString, Pos) + 1 FROM IDRows WHERE Pos < LEN(@ListString) -- условие окончания рекурсии ) -- переписываем все CTE в возвращаемую таблицу INSERT INTO @ID (ID) SELECT ID FROM IDRows ORDER BY Pos -- упорядоченную по позиции разделителя - т.е. по позиции ключа во входном массиве OPTION (MAXRECURSION 32767) -- глубина рекурсии по умолчанию 100 (может не хватить, поэтому ставим макс возможную) RETURN END
Проиллюстрируем использование на примере.
Создаем таблицу с тестовыми данными и убеждаемся, что они достаточно разнообразны ;):DECLARE @testdata TABLE (ID INT IDENTITY PRIMARY KEY CLUSTERED, Name VARCHAR(128)) INSERT INTO @testdata SELECT TOP 1000 A.name + B.name FROM sysobjects A CROSS JOIN sysobjects B ORDER BY NEWID() SELECT * FROM @testdata
Имитируем выборку ключей нашей функцией DB_get_keys с обратной сортировкой по искомому полю и сразу конвертим ее в CSV:DECLARE @STR VARCHAR(MAX) = '' SELECT TOP 20 @STR = @STR + ',' + CONVERT(VARCHAR, ID) FROM @testdata WHERE Name LIKE 'C%' ORDER BY Name DESC IF LEN(@STR) > 0 SET @STR = RIGHT(@STR, LEN(@STR)-1) SELECT @STR
И наконец, имитируем DB_get_records_by_keys:SELECT TD.* FROM @testdata TD INNER JOIN dbo.TF_IDListToTableWithOrder(@STR, ',') LTT ON TD.ID = LTT.ID ORDER BY LTT.RowIdx
Чтобы заставить все это работать в связке с сервером приложения, нужно сохранять в пользовательском контексте (для веба - в сессии) массив значений ключей на время навигации, что казалось бы, потребует большого объема памяти. Однако, если ключи целочисленные, и хранятся в простом скалярном массиве, а не в массиве объектов (разница принципиальная!), то скажем 100 000 ключей займет на сервере приложения всего 400 кБайт, что по современным меркам совсем немного.
Теперь про чувствительность метода к добавленным/удаленным во время навигации записям. Понятно, что вновь добавленные записи, попадающие под критерий фильтра пользователь не увидит - т.к. значения их ключей появятся позже момента выборки всего списка. Что же касается удаления, то, естественно, отсутствующая запись не будет возвращена, и количество фактически полученных записей по набору ключей может оказаться меньше затребованного. Эту ситуацию можно обработать на слое приложения, сравнив ID полученных записей с запрошенными, и выведя на месте отсутствующих какую-нибудь заглушку типа "Просматриваемая запись была удалена", чтобы не нарушать layout из-за изменения общего количества. А можно и сделать LEFT JOIN результата табличной функции с бизнес-таблицей - в таком случае для удаленной записи все поля будут NULL - и уже этот факт обработать на клиенте. В общем, варианты имеются.
И последнее. Этот метод был применен при апгрейде системы онлайн-аукциона для просмотра выбранных по фильтру лотов (страницами или одного за одним - вперед и назад) с возможностью биддинга и продолжения навигации. Для такого применения среднее количество навигаций на одном фильтре довольно велико, поэтому замена классической пагинации на эту была одной из эффективных мер, позволивших заметно облегчить участь SQL-сервера в моменты пиковых нагрузок.