Мы работаем над DWH в телекоммуникациях, поэтому пример, который я рассматриваю, называется "Абонент". Принцип универсален и это мог быть "Клиент" или "Пациент" - в зависимости от отрасли. Я надеюсь методику найдут полезной разработчики DWH из разных отраслей.
Если Вы не понимаете, что такое DWH, измерения и факты, я рекомендую прочитать книгу Ральфа Кимбалла "Dimensional Modeling". Речь идёт о базе данных для аналитики и консолидированной отчетности предприятия, конкретно о формировании и актуализации измерений - таблиц, которые хранят атрибуты (поля) для отбора (WHERE) в будущих запросах.
Наша методика предназначена для Microsoft SQL Server.
Принцип определения изменений
Определение изменения атрибутов типа 1 (перезаписываемый) и 2 (с хранением истории в записях измерения) выполняется на основе сравнения контрольных сумм полей.
Для вычисления контрольных сумм используется функция T-SQL CHECKSUM, не поддерживающая типы text, ntext, image, которые и не должны помещаться в измерения. Использование BINARY_CHECKSUM на практике показало, что возможно ложное детектирование изменений в полях, содержащих NULL. С данной методикой возможно использование кастомных функций контрольной суммы, разработанных на .NET.
Объявление измерения
Измерение должно быть объявлено с первичным ключом, содержащим кластерный индекс.
Пример SQL скрипта объявления измерения "Абонент":
USE [DWH] GO /* Убедиться в существовании схемы Dim */ IF SCHEMA_ID('Dim') IS NULL EXECUTE('CREATE SCHEMA [Dim] AUTHORIZATION [dbo]') GO /* Удалить Абонент */ IF EXISTS ( SELECT * FROM dbo.sysobjects WHERE id = OBJECT_ID(N'[Dim].[Абонент]') AND OBJECTPROPERTY(id, N'IsUserTable') = 1 ) DROP TABLE [Dim].[Абонент] GO /* Создать Абонент */ CREATE TABLE [Dim].[Абонент] ( [AccountKey] INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED, [Лицевой счёт] INT NULL, [Тип абонента] NVARCHAR(13) NOT NULL CHECK ([Тип абонента] IN (N'Физ.лицо', N'Юр.лицо', N'Не определено')) DEFAULT N'Не определено', [Провайдер] NVARCHAR(16) NOT NULL DEFAULT N'Не определено', [Номер договора] NVARCHAR(50) NOT NULL DEFAULT 'Нет в базе данных', [Дата заключения договора] DATE, [Дата расторжения договора] DATE, [Имя] NVARCHAR(100) NOT NULL DEFAULT 'Нет в базе данных', [Фамилия] NVARCHAR(100) NOT NULL DEFAULT 'Нет в базе данных', [Отчество] NVARCHAR(100) NOT NULL DEFAULT 'Нет в базе данных', [Дата рождения] DATE, [ФИО] AS [Фамилия] + CASE WHEN [Имя] != N'Нет в базе данных' THEN N' ' + [Имя] ELSE N'' END + CASE WHEN [Отчество] != N'Нет в базе данных' THEN N' ' + [Отчество] ELSE N'' END, [Наименование организации] NVARCHAR(100) NOT NULL DEFAULT N'Нет в базе данных', ... [Телефоны] NVARCHAR(200) NOT NULL DEFAULT N'Нет в базе данных', [Телефон для SMS] NVARCHAR(20) NOT NULL DEFAULT N'Нет в базе данных', [Факс] NVARCHAR(200) NOT NULL DEFAULT N'Нет в базе данных', [E-mail] NVARCHAR(50) NOT NULL DEFAULT N'Нет в базе данных', [Средства связи] AS N'Телефоны: ' + [Телефоны] + N', ' + N'Телефон для SMS: ' + [Телефон для SMS] + N', ' + N'Факс: ' + [Факс] + N', ' + N'E-mail: ' + [E-mail], [StartTime] DATETIME2 NOT NULL, [EndTime] DATETIME2 NULL, [Checksum1] INT NULL, [Checksum2] INT NULL ) /* Запись неопределенного Абонента */ SET IDENTITY_INSERT [Dim].[Абонент] ON INSERT INTO [Dim].[Абонент] ([AccountKey],[Лицевой счёт],[StartTime]) VALUES (-1, NULL, GETDATE()) SET IDENTITY_INSERT [Dim].[Абонент] OFF GO
Нужно наложить на измерение условный индекс по бизнес-ключу с условием [EndTime] IS NULL, содержащий поля контрольных сумм. Включение в индекс контрольных сумм, при условии кластерного индекса первичного ключа таблицы измерения ([AccountKey]), позволяет не считывать саму таблицу измерения при выполнении начального запроса. При этом, индекс выполняет функцию контроля уникальности - одна действующая запись для одного бизнес-ключа.
Пример индекса для измерения "Абонент":
CREATE UNIQUE INDEX IX_Абонент_Уникальность ON [Dim].[Абонент] ([Лицевой счёт], [EndTime]) INCLUDE ([Checksum1], [Checksum2]) WHERE [EndTime] IS NULL
Типовой начальный SQL запрос
Начальный SQL запрос содержит внутренний подзапрос [i], который получает поля из исходных таблиц-копий и внешний запрос [o], который формирует контрольные суммы, и присоединение актуальной строки измерения по бизнес-ключу.
Пример начального запроса для измерения "Абонент":
SELECT [o].*, [Абонент].[Checksum2] AS [OLD_CHECKSUM2], [Абонент].[Checksum1] AS [OLD_CHECKSUM1], [Абонент].[AccountKey] AS [OLD_AccountKey] FROM ( SELECT i.*, CHECKSUM( [Тип абонента], [Провайдер], [Номер договора], [Дата заключения договора], [Имя], [Фамилия], [Отчество], [Название организации], [Город], [Улица], [Дом], [Квартира], [Адрес прописки], [Паспортные данные] ) AS [CHECKSUM2], CHECKSUM( [Телефоны], [Телефон для SMS], [E-mail], [Дата рождения] ) AS [CHECKSUM1] FROM ( SELECT FROM [Raw].... LEFT JOIN [Raw].... ) AS [i] -- внутренний запрос собирает строку ) AS [o] -- внешний запрос считает контрольные суммы LEFT JOIN [Dim].[Абонент] ON [o].[Лицевой счёт] = [Абонент].[Лицевой счёт] AND [Абонент].[EndTime] IS NULL -- присоединяем последнюю действующую запись измерения
Приведение типов (это как правило CAST(… AS NVARCHAR(..)) или IIF(ISDATE([...]) = 1, CAST([...] AS DATE), NULL)), а так же всё связывание исходных таблиц (LEFT JOIN) и условное формирование полей (CASE, IIF) нужно делать во внутреннем запросе - внутри FROM (...) AS [i].
Если логика связывания исходных таблиц слишком сложная (например, нужно вытащить какие-то данные из иерархии) и её невозможно выполнить внутри FROM, тогда перед потоком данных в SSIS, Вам придется вставить SQL Task, формирующий промежуточные данные в отдельных таблицах (соблюдая вашу схему именования объектов). Временные таблицы не подойдут, поскольку по ним SSIS не сможет определить метаданные выходного потока.
Убедиться в корректности взаимодействия индекса и начального запроса можно, посмотрев его план выполнения. В конце плана выполнения не должно быть обращения к таблице:
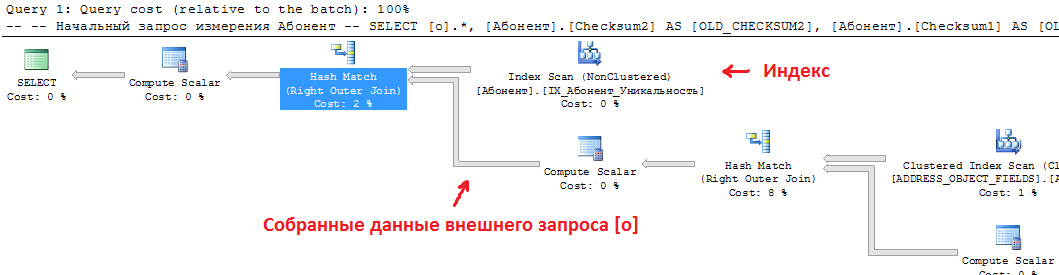
Типовой поток данных
Поток данных формирования измерения выходит из начального SQL запроса, описанного выше, и реализует дальнейшую логику изменения.
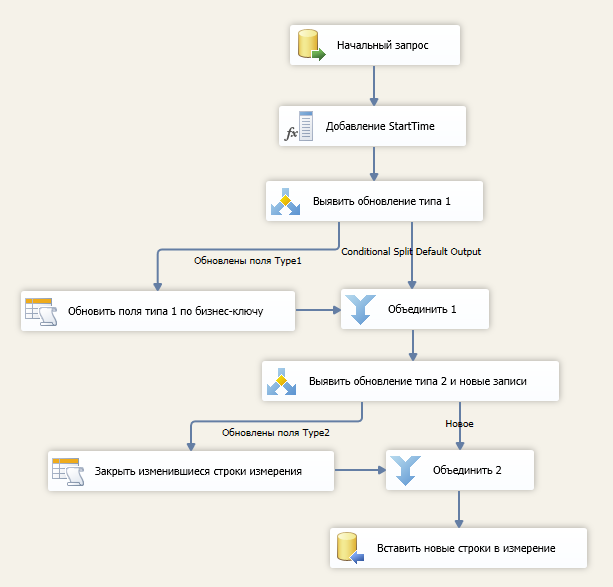
В операции "Добавление StartTime" добавляем в поток StartTime, используя время запуска пакета SSIS (берем переменную @[System::StartTime])
В операции "Выявить обновление типа 1" выделяем один поток - "Обновлены поля Type1" на основе выражения !ISNULL(OLD_CHECKSUM1) && CHECKSUM1 != OLD_CHECKSUM1.
В операции "Обновить поля типа 1 по бизнес-ключу" обновляем все записи измерения (в том числе уже закрытые записи, содержащие исторические значения полей типа 2), в которых изменились атрибуты первого типа - для этого используем бизнес-ключ без условия отсечения неактуальных записей (без условия по [EndTime]). Пример для "Абонент":
UPDATE [Dim].[Абонент] SET [Телефоны] = ?, [Телефон для SMS] = ?, [E-mail] = ?, [Дата рождения] = ? [Checksum1] = ? WHERE [Лицевой счёт] = ?
В операции "Выявить обновление типа 2 и новые записи" выделяем два потока:
- "Новое" на основе выражения ISNULL(OLD_AccountKey)
- "Обновлены поля Type2" на основе выражения CHECKSUM2 != OLD_CHECKSUM2
В операции "Закрыть изменившиеся строки измерения" обновляем [EndTime] для записей измерения значением StartTime из потока. Пример для "Абонент":
UPDATE [Dim].[Абонент] SET [EndTime] = ? WHERE [AccountKey] = ?
В операции "Вставить строки в измерение" вставляем новые строки, при этом, в поле [StartTime] вставляем StartTime из потока, ключ измерения и [EndTime] игнорируем (NULL образующийся в поле [EndTime] будет признаком актуальной записи).
При вставке на последней операции не получится использовать режим Fast Load потому, что вставка, выполняемая в одном потоке с обновлениями, должна оперировать строкой, не расширяя блокировку до уровня таблицы, иначе будут конфликты между одновременно выполняемыми операциями. Альтернативно, Вы можете разнести операции по разным шагам управляющего потока, сохраняя промежуточные результаты в Raw или Cache и соблюдая порядок операций.
Использование транзакции
На уровне контейнера потока данных (или общего контейнера, если Вы разнесли операции по шагам управляющего потока) желательно включить транзакцию. Для этого установите TransactionOption = Required (требует DTC) и IsolationLevel не ниже ReadCommitted.
Если транзакции не будет, при прерывании потока данных часть записей измерения может остаться закрытой без вставки соответствующих актуальных записей. При следующем запуске, отсутствующие записи будут вставлены как новые, но со стартовым временем, отличающимся от времени закрытия предыдущей строки. Это следует учитывать, если факты привязываются к измерению способом присоединения записи актуальной на момент возникновения факта - оперировать при привязке измерений только временем закрытия.
Сравнение с другими методами
По сравнению с использованием стандартного компонента SQL Server Integration Services, под названием Slowly Changing Dimension, данный метод не использует сравнение каждого поля с каждым полем в строке измерения - он даже не обращается к таблице для выполнения такого сравнения. Это дает основное преимущество - скорость. Кроме того, стандартный Slowly Changing Dimension управляет сразу целой цепочкой элементов и это создает сложность с их кастомизацией. По неизвестным мне причинам, стандартный компонент SSIS может ложно определять изменения (возможно, это так же связано с полями NULL).
Перед коммерческими компонентами сторонних поставщиков есть принципиальное преимущество метода в том, что он базируется на стандартных компонентах и функциях поставляемых с выпуском SQL Server. Таким образом, не требуется ожидать обновленных компонентов для перехода на следующую версию SQL Server.
Модификации метода
Возможен модифицированный метод, при котором присоединение выполняется не в SQL запросе, а в потоке данных SSIS через в операцию Lookup. Это приводит к большему количеству обращений к базе и замене эффективного Hash Match на менее эффективные одиночные запросы. С другой стороны, это позволяет разделить исходные таблицы (таблицы-копии, формируемые на стадии загрузки из исходных систем) и таблицы измерений на разные сервера. Но польза от такой возможности у меня вызывает сомнения.
Возможно присоединение в потоке SSIS через операцию Merge Join, но она потребует извлечения таблицы и её сортировки, что сведет на нет преимущества индекса.
Расчёт контрольной суммы так же возможен в потоке данных, например отдельным компонентом, но в этом случае исчезает преимущество отсутствия необходимости в отдельных компонентах.
Расчёт контрольной суммы в потоке данных с помощью Script Transformation на C# - возможный вариант модификации, если в этом усложнении есть смысл.