Настоящая мощь архитектуры распределенных вычислений Hadoop заключается в параллельной обработке заданий. Другими словами, возможность распределять задачи по нескольким параллельно работающим узлам позволяет использовать Hadoop в масштабах большой инфраструктуры и обрабатывать большие объемы данных. Эту статью мы начнем с рассмотрения архитектуры Hadoop, после чего рассмотрим настройку и работу Hadoop в распределенной конфигурации.
Распределенная архитектура Hadoop
Из первой статьи этой серии вы узнали, что все демоны Hadoop работали на одном физическом хосте. Хотя в этом примере не была рассмотрена распределенная суть фреймворка Hadoop, данная псевдораспределенная конфигурация являлась простым способом тестирования его возможностей, требующим минимальной настройки. Давайте теперь рассмотрим распределенную суть Hadoop, задействовав группу компьютеров.
В первой статье Hadoop был сконфигурирован таким образом, что все его демоны работали на одной машине. Итак, сначала выясним, как можно распределить Hadoop для выполнения параллельных операций. В распределенной конфигурации Hadoop имеется главный (master) узел и несколько подчиненных (slave) узлов (рисунок 1).
Рисунок 1. Разделение Hadoop на главный и подчиненные узлы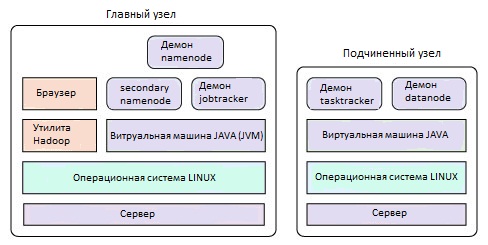
Как показано на рисунке 1, на главном узле работают демоны namenode, secondarynamenode и jobtracker (так называемые master-демоны). Кроме того, с этого узла осуществляется управление кластером (с помощью утилиты Hadoop и Web-браузера). На подчиненных узлах работают демоны tasktracker и datanode (slave-демоны). Отличие данной конфигурации заключается в том, что на главном узле работают демоны, отвечающие за управление и координирование кластера Hadoop, тогда как на подчиненных узлах работают демоны, обеспечивающие функции хранения данных в файловой системе HDFS и реализующие функционал MapReduce (функция обработки данных).
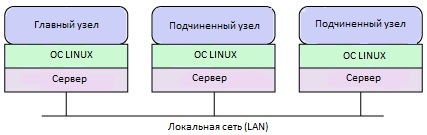
Для демонстрации этого мы создадим один главный и два подчиненных узла, расположенные в одном сегменте локальной сети. Эта конфигурация изображена на рисунке 2. Теперь рассмотрим установку и настройку Hadoop в многоузловой конфигурации.
Рисунок 2. Конфигурация кластера Hadoop
Чтобы упростить развертывание, будем использовать виртуализацию, которая позволяет получить некоторые преимущества. Несмотря на небольшое снижение производительности, виртуализация позволяет создать конфигурацию Hadoop и затем клонировать ее на другие узлы. Исходя из этого, ваш кластер Hadoop должен выглядеть так, как показано на рисунке 3: на компьютере установлен гипервизор, управляющий тремя виртуальными машинами - на одной из них развернут главный узел Hadoop, а на двух других - подчиненные узлы.
Рисунок 3. Конфигурация кластера Hadoop в виртуальной среде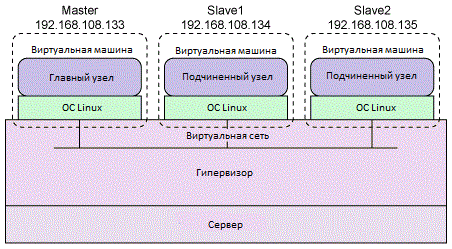
Обновление конфигурации Hadoop
В первой части мы настроили специальную конфигурацию Hadoop, в которой все узлы располагались на одном хосте (псевдораспределенная конфигурация). В этой статье обновим эту конфигурацию до распределенной. Если вы не читали первую статью этой серии, необходимо прочитать ее и настроить псевдораспределенную конфигурацию Hadoop, прежде чем вы сможете продолжать.
В псевдораспределенной конфигурации мы ничего не настраивали, и все работало на одном хосте с настройками по умолчанию. Сейчас необходимо обновить эту конфигурацию. Прежде всего, проверим текущую конфигурацию с помощью команды update-alternatives, как показано в листинге 1. Эта команда сообщает нам, что конфигурация использует файл conf.pseudo (наивысший приоритет).
$ update-alternatives --display hadoop-0.20-conf hadoop-0.20-conf - status is auto. link currently points to /etc/hadoop-0.20/conf.pseudo /etc/hadoop-0.20/conf.empty - priority 10 /etc/hadoop-0.20/conf.pseudo - priority 30 Current `best' version is /etc/hadoop-0.20/conf.pseudo. $ |
Далее, создадим новую конфигурацию, сделав копию файла уже существующей конфигурации (в нашем примере это файл conf.empty), как показано в листинге 1:
$ sudo cp -r /etc/hadoop-0.20/conf.empty /etc/hadoop-0.20/conf.dist $ |
В завершение активизируем и проверим новую конфигурацию.
Листинг 2. Активизация и проверка конфигурации Hadoop$ sudo update-alternatives --install /etc/hadoop-0.20/conf hadoop-0.20-conf /etc/hadoop-0.20/conf.dist 40 $ update-alternatives --display hadoop-0.20-conf hadoop-0.20-conf - status is auto. link currently points to /etc/hadoop-0.20/conf.dist /etc/hadoop-0.20/conf.empty - priority 10 /etc/hadoop-0.20/conf.pseudo - priority 30 /etc/hadoop-0.20/conf.dist - priority 40 Current `best' version is /etc/hadoop-0.20/conf.dist. $ |
Мы получили новый конфигурационный файл conf.dist, на основе которого будем создавать новую распределенную конфигурацию. На данном этапе создайте два клона этой виртуальной машины - они будут выступать в качестве узлов DataNode.
Конфигурация Hadoop для распределенной работы
Следующий шаг заключается в настройке взаимосвязей между узлами. Для этого используются файлы с именами masters и slaves, расположенные в директории /etc/hadoop-0.20/conf.dist. В нашем примере (листинг 3) имеются три узла, которым в файле /etc/hosts назначены статические IP-адреса:
Листинг 3. Записи для узлов Hadoop в файле /etc/hostsmaster 192.168.108.133 slave1 192.168.108.134 slave2 192.168.108.135 |
Итак, на главном узле обновите файл /etc/hadoop-0.20/conf.dist/masters, обозначив главный узел, как:
master |
На подчиненных узлах обновите файл /etc/hadoop-0.20/conf.dist/slaves, добавив следующие две строки:
slave1 slave2 |
Далее, с каждого узла подключитесь с помощью ssh к двум другим узлам, чтобы проверить, что беспарольный ssh работает. Каждый из этих файлов (masters, slaves) используется утилитами запуска и останова Hadoop, с которыми вы работали в первой части этой серии.
Продолжим настройку конфигурации Hadoop в директории /etc/hadoop-0.20/conf.dist. В соответствии с документацией Hadoop, необходимо выполнить на всех узлах (на главном и на обоих подчиненных) следующие действия. Во-первых, необходимо указать хозяина HDFS в файле core-site.xml (листинг 4), задав адрес и порт службы namenode (заметьте, что используется IP-адрес главного узла). В файле core-site.xml задаются основные параметры Hadoop.
Листинг 4. Определение хозяина HDFS в файле core-site.xml
<configuration>
<property>
<name>fs.default.name<name>
<value>hdfs://master:54310<value>
<description>The name and URI of the default FS.</description>
<property>
<configuration>
|
Во-вторых, необходимо задать параметры службы MapReduce jobtracker. Демон jobtracker может работать на своем собственном узле, но в этой конфигурации мы поместим его на главный узел, как показано в листинге 5. В файле mapred-site.xml задаются параметры функционала MapReduce.
Листинг 5. Задание параметров MapReduce jobtracker в файле mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker<name>
<value>master:54311<value>
<description>Map Reduce jobtracker<description>
<property>
<configuration>
|
И последнее, что необходимо сделать - задать фактор репликации по умолчанию (листинг 6). Этот параметр определяет количество реплик, которые будут созданы, и обычно его значение не превышает 3. В нашем примере зададим значение, равное 2 (количество узлов типа DataNode). Это значение определяется в файле hdfs-site.xml, содержащем параметры файловой системы HDFS.
Листинг 6. Определение фактора репликации данных по умолчанию в файле hdfs-site.xml
<configuration>
<property>
<name>dfs.replication<name>
<value>2<value>
<description>Default block replication<description>
<property>
<configuration>
|
Конфигурационные элементы, приведенные в листинге 4, листинге 5 и листинге 6, являются обязательными для распределенной конфигурации. Hadoop имеет большое количество конфигурационных параметров, позволяющих полностью настраивать рабочее окружение.
После того как вы создали конфигурацию, необходимо отформатировать узел namenode (главный узел HDFS). Для этого используйте утилиту hadoop-0.20, указав узел namenode и требуемую операцию (-format), как показано в листинге 7.
user@master:~# sudo su - root@master:~# hadoop-0.20 namenode -format 10/05/11 18:39:58 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = master/127.0.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.20.2+228 STARTUP_MSG: build = -r cfc3233ece0769b11af9add328261295aaf4d1ad; ************************************************************/ 10/05/11 18:39:59 INFO namenode.FSNamesystem: fsOwner=root,root 10/05/11 18:39:59 INFO namenode.FSNamesystem: supergroup=supergroup 10/05/11 18:39:59 INFO namenode.FSNamesystem: isPermissionEnabled=true 10/05/11 18:39:59 INFO common.Storage: Image file of size 94 saved in 0 seconds. 10/05/11 18:39:59 INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted. 10/05/11 18:39:59 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at master/127.0.1.1 ************************************************************/ root@master:~# |
После завершения форматирования можно запускать демоны Hadoop. Это делается точно так же, как и в случае псевдораспределенной конфигурации (листинг 8). Обратите внимание на то, что на этом узле запускаются демоны namenode и secondarynamenode (как видно из вывода команды jps):
root@master:~# /usr/lib/hadoop-0.20/bin/start-dfs.sh starting namenode, logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-root-namenode-mtj-desktop.out 192.168.108.135: starting datanode, logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-root-datanode-mtj-desktop.out 192.168.108.134: starting datanode, logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-root-datanode-mtj-desktop.out 192.168.108.133: starting secondarynamenode, logging to /usr/lib/hadoop-0.20/logs/hadoop-root-secondarynamenode-mtj-desktop.out root@master:~# jps 7367 NameNode 7618 Jps 7522 SecondaryNameNode root@master:~# |
Если вы запустите команду jps на подчиненных узлах (узлы типа DataNode), вы увидите, что на каждом из них запущен демон datanode (листинг 9).
root@slave1:~# jps 10562 Jps 10451 DataNode root@slave1:~# |
Следующий шаг - запуск демонов MapReduce (jobtracker и tasktracker). Команды для запуска приведены в листинге 10. Обратите внимание на то, что в результате выполнения сценария демон jobtracker запускается на главном узле (как это было определено в конфигурации, см. листинг 5), а демоны tasktracker - на каждом из подчиненных узлов. Выполнив команду jps на главном узле, мы увидим, что демон jobtracker теперь запущен (листинг 10).
root@master:~# /usr/lib/hadoop-0.20/bin/start-mapred.sh starting jobtracker, logging to /usr/lib/hadoop-0.20/logs/hadoop-root-jobtracker-mtj-desktop.out 192.168.108.134: starting tasktracker, logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-root-tasktracker-mtj-desktop.out 192.168.108.135: starting tasktracker, logging to /usr/lib/hadoop-0.20/bin/../logs/hadoop-root-tasktracker-mtj-desktop.out root@master:~# jps 7367 NameNode 7842 JobTracker 7938 Jps 7522 SecondaryNameNode root@master:~# |
Наконец, проверим с помощью команды jps подчиненные узлы. Здесь мы видим, что на каждом из них к демону datanode добавился демон tasktracker (листинг 11).
root@slave1:~# jps 7785 DataNode 8114 Jps 7991 TaskTracker root@slave1:~# |
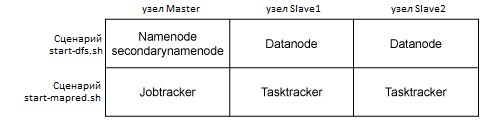
Взаимосвязь между сценариями запуска, узлами и демонами показана на рисунке 4. Как видно из рисунка, сценарий start-dfs запускает на соответствующих узлах демоны namenode и datanode, а сценарий start-mapred - демоны jobtracker и tasktracker.
Теперь, когда Hadoop запущен и работает в кластере, можно выполнить несколько тестов и убедиться, что все работает без ошибок (листинг 12). Сначала выполним команду fs с параметром df в контексте утилиты hadoop-0.20. Так же как и в ОС Linux®, эта команда просто показывает занятое и свободное дисковое пространство на выбранном устройстве. В новой, только что отформатированной файловой системе все пространство свободно. Далее, выполним команду ls для корневой директории HDFS, создадим поддиректорию, посмотрим ее содержимое и затем удалим ее. После этого проверим файловую систему с помощью команды fsck, запущенной в контексте утилиты hadoop-0.20. Результаты выполнения всех этих команд говорят о том, что файловая система в порядке. Кроме того, мы получили дополнительную информацию о том, что были обнаружены два узла datanode.
root@master:~# hadoop-0.20 fs -df File system Size Used Avail Use% / 16078839808 73728 3490967552 0% root@master:~# hadoop-0.20 fs -ls / Found 1 items drwxr-xr-x - root supergroup 0 2010-05-12 12:16 /tmp root@master:~# hadoop-0.20 fs -mkdir test root@master:~# hadoop-0.20 fs -ls test root@master:~# hadoop-0.20 fs -rmr test Deleted hdfs://192.168.108.133:54310/user/root/test root@master:~# hadoop-0.20 fsck / .Status: HEALTHY Total size: 4 B Total dirs: 6 Total files: 1 Total blocks (validated): 1 (avg. block size 4 B) Minimally replicated blocks: 1 (100.0 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 0 (0.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 2 Average block replication: 2.0 Corrupt blocks: 0 Missing replicas: 0 (0.0 %) Number of data-nodes: 2 Number of racks: 1 The filesystem under path '/' is HEALTHY root@master:~# |
Запустим задание MapReduce и убедимся, что вся конфигурация работает должным образом (листинг 13). Первое, с чего следует начать - это предоставить системе какие-то данные. Итак, давайте начнем с создания директории, в которой будут храниться наши входные данные (назовем эту директорию input). Для этого воспользуемся командой mkdir утилиты hadoop-0.20. После этого с помощью команды put поместим в файловую систему HDFS два файла. Содержимое директории input можно проверить с помощью команды ls.
root@master:~# hadoop-0.20 fs -mkdir input root@master:~# hadoop-0.20 fs -put /usr/src/linux-source-2.6.27/Doc*/memory-barriers.txt input root@master:~# hadoop-0.20 fs -put /usr/src/linux-source-2.6.27/Doc*/rt-mutex-design.txt input root@master:~# hadoop-0.20 fs -ls input Found 2 items -rw-r--r-- 2 root supergroup 78031 2010-05-12 14:16 /user/root/input/memory-barriers.txt -rw-r--r-- 2 root supergroup 33567 2010-05-12 14:16 /user/root/input/rt-mutex-design.txt root@master:~# |
Теперь передадим на выполнение функции MapReduce задачу wordcount (листинг 14). Как и в псевдораспределенной модели, необходимо указать входную директорию input (содержащую входные файлы) и выходную директорию output (эта директория не существует, но она будет создана и заполнена данными в результате работы узла namenode).
Листинг 14. Запуск функции MapReduce для выполнения задания wordcount в кластереroot@master:~# hadoop-0.20 jar /usr/lib/hadoop-0.20/hadoop-0.20.2+228-examples.jar wordcount input output 10/05/12 19:04:37 INFO input.FileInputFormat: Total input paths to process : 2 10/05/12 19:04:38 INFO mapred.JobClient: Running job: job_201005121900_0001 10/05/12 19:04:39 INFO mapred.JobClient: map 0% reduce 0% 10/05/12 19:04:59 INFO mapred.JobClient: map 50% reduce 0% 10/05/12 19:05:08 INFO mapred.JobClient: map 100% reduce 16% 10/05/12 19:05:17 INFO mapred.JobClient: map 100% reduce 100% 10/05/12 19:05:19 INFO mapred.JobClient: Job complete: job_201005121900_0001 10/05/12 19:05:19 INFO mapred.JobClient: Counters: 17 10/05/12 19:05:19 INFO mapred.JobClient: Job Counters 10/05/12 19:05:19 INFO mapred.JobClient: Launched reduce tasks=1 10/05/12 19:05:19 INFO mapred.JobClient: Launched map tasks=2 10/05/12 19:05:19 INFO mapred.JobClient: Data-local map tasks=2 10/05/12 19:05:19 INFO mapred.JobClient: FileSystemCounters 10/05/12 19:05:19 INFO mapred.JobClient: FILE_BYTES_READ=47556 10/05/12 19:05:19 INFO mapred.JobClient: HDFS_BYTES_READ=111598 10/05/12 19:05:19 INFO mapred.JobClient: FILE_BYTES_WRITTEN=95182 10/05/12 19:05:19 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=30949 10/05/12 19:05:19 INFO mapred.JobClient: Map-Reduce Framework 10/05/12 19:05:19 INFO mapred.JobClient: Reduce input groups=2974 10/05/12 19:05:19 INFO mapred.JobClient: Combine output records=3381 10/05/12 19:05:19 INFO mapred.JobClient: Map input records=2937 10/05/12 19:05:19 INFO mapred.JobClient: Reduce shuffle bytes=47562 10/05/12 19:05:19 INFO mapred.JobClient: Reduce output records=2974 10/05/12 19:05:19 INFO mapred.JobClient: Spilled Records=6762 10/05/12 19:05:19 INFO mapred.JobClient: Map output bytes=168718 10/05/12 19:05:19 INFO mapred.JobClient: Combine input records=17457 10/05/12 19:05:19 INFO mapred.JobClient: Map output records=17457 10/05/12 19:05:19 INFO mapred.JobClient: Reduce input records=3381 root@master:~# |
Последнее, что нужно сделать - проанализировать полученные результаты. Поскольку задача wordcount обрабатывалась с помощью функции MapReduce, результатом будет являться один файл, собранный в единое целое из отдельных параллельно обработанных файлов. Этот результирующий файл содержит строки, каждая из которых содержит слово, найденное во всех входных файлах, и число, показывающее, сколько раз это слово было найдено (листинг 15).
Листинг 15. Просмотр выполнения операции MapReduce для функции wordcountroot@master:~# hadoop-0.20 fs -ls output Found 2 items drwxr-xr-x - root supergroup 0 2010-05-12 19:04 /user/root/output/_logs -rw-r--r-- 2 root supergroup 30949 2010-05-12 19:05 /user/root/output/part-r-00000 root@master:~# hadoop-0.20 fs -cat output/part-r-00000 / head -13 != 1 "Atomic 2 "Cache 2 "Control 1 "Examples 1 "Has 7 "Inter-CPU 1 "LOAD 1 "LOCK" 1 "Locking 1 "Locks 1 "MMIO 1 "Pending 5 root@master:~# |
Несмотря на универсальность и богатый функционал утилиты hadoop-0.20, иногда удобнее использовать графический интерфейс. Вы можете подключиться в Web-браузере к узлу namenode по адресу http://master:50070 и к узлу jobtracker по адресу http://master:50030. Через интерфейс namenode можно получать информацию о файловой системе HDFS, как показано на рисунке 5 (здесь мы просматриваем информацию о директории input).
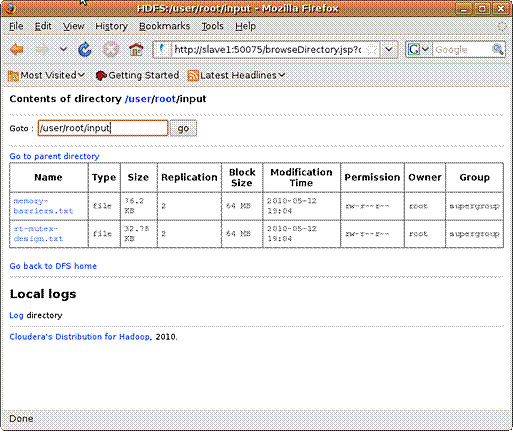
Через интерфейс jobtracker можно получать информацию о выполняющихся или завершенных заданиях. На рисунке 6 показана информация о вашем последнем задании (см. листинг 14), полученная в результате выполнения запроса к JAR-архиву, а также статус и количество заданий. Обратите внимание на то, что были выполнены две операции map (по одной для каждого входного файла) и одна операция reduce (чтобы собрать два фрагмента, на которые был разбит входной файл).
Рисунок 6. Проверка статуса завершенного задания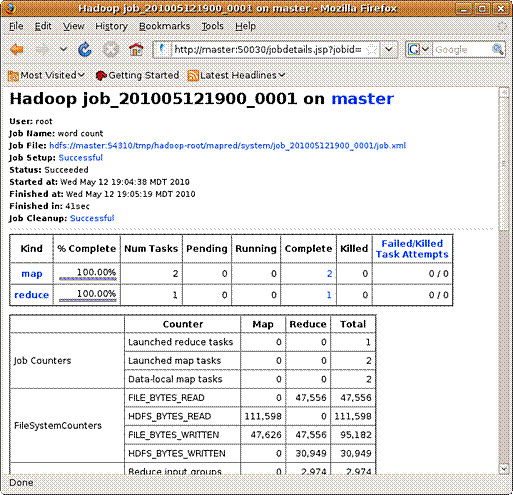
Наконец, через интерфейс namenode вы можете проверить статус всех узлов DataNode. На главной странице namenode показано количество работающих и неработающих узлов. Для каждого узла присутствует гиперссылка, позволяющая получить более подробную информацию. На рисунке 7 показаны работающие узлы типа DataNode и статистика для каждого из них.
Рисунок 7. Проверка статуса работающих узлов DataNode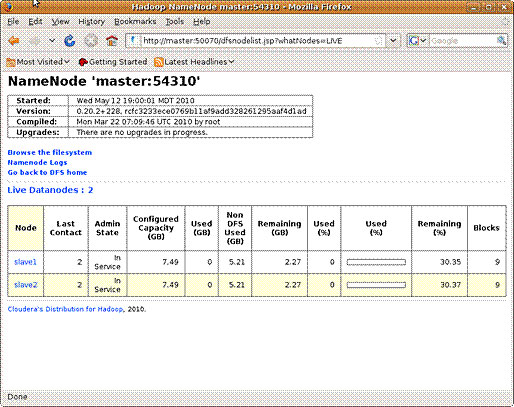
С помощью Web-интерфейсов namenode и jobtracker можно получить много другой информации - здесь приведен лишь небольшой пример. На этих Web-страницах вы найдете большое количество гиперссылок, с помощью которых сможете получить дополнительную информацию о конфигурации и работе Hadoop (включая журналы времени выполнения).
Из этой статьи вы узнали, как из псевдораспределенной конфигурации Hadoop от компании Cloudera можно получить полностью распределенную конфигурацию. Крайне малое количество требуемых действий, а также идентичный интерфейс для приложений MapReduce делают Hadoop исключительно полезным для распределенной обработки. Также интересно посмотреть на схему масштабирования Hadoop. Добавляя новые узлы DataNode, вы можете легко масштабировать Hadoop до еще более высокого уровня распределенной обработки. В третьей, последней части этой серии статей мы рассмотрим процесс создания приложения MapReduce для Hadoop.