Abstract: Рассказ про некоторые возможности IPv6 на примере конфигурации сложной домашней IPv6-сети. Включает в себя описания мультикаста, подробности настройки и отладки router advertisement, stateless DHCP и т.д. Описано для linux-системы. Помимо самой конфигурации мы внимательно обсудим некоторые понятия IPv6 в теоретическом плане, а так же некоторые приёмы при работе с IPv6.
Зачем IPv6?
Вполне понятный вопрос: почему я ношусь с IPv6 сейчас, когда от него сейчас нет практически никакой пользы?
Сейчас с IPv6 можно возиться совершенно безопасно, без каких-либо негативных последствий. Можно мирно разбираться в граблях и особенностях, иметь его неработающим месяцами и nobody cares . Я не планирую в свои старшие годы становиться зашоренным коболистом-консерватором, который всю жизнь писал кобол и больше ничего, и все новинки для него "чушь и ерунда". А вот мой досточтимый воображаемый конкурент, когда IPv6 станет продакт-реальностью, будет либо мне не конкурентом, либо мучительно и в состоянии дистресса разбираться с DAD, RA, temporary dynamic addresses и прочими странными вещами, которым посвящено 30+ RFC. А что IPv6 станет основным протоколом ещё при моей жизни - это очевидно, так как альтернатив нет (даже если бы они были, их внедрение - это количество усилий бОльшее, чем завершение внедрения IPv6, то есть любая альтернатива всегда будет отставать). И что адреса таки заканчиваются видно, по тому, как процесс управления ими перешёл во вторую стадию - стадию вторичного рынка. Когда свободные резервы спекуляций и хомячаяния адресов закончится, начнётся этап суровой консолидации - то есть выкидывание всего неважного с адресов, перенос всех "на один адрес" и т.д. Примерно в это время IPv6 начнёт использоваться для реальной работы.
Впрочем, рассказ не про будущее IPv6, а про практику работы с ним. В Санкт-Петербурге есть такой провайдер - Tierа. И я их домашний пользователь. Это один из немногих провайдеров, или, может быть, единственный в городе, кто предоставляет IPv6 домашним пользователям. Пользователю выделяется один IPv6 адрес (для маршрутизатора или компьютера), плюс /64 сетка для всего остального (то есть в четыре миллиарда раз больше адресов, чем всего IPv4 адресов быть может - и всё это в одни руки). Я попробую не просто описать "как настроить IPv6", но разобрать базовые понятия протокола на практических примерах с теоретическими вставками.
Структура сети: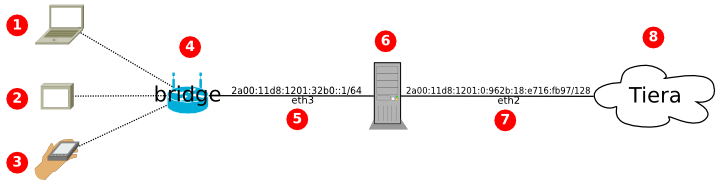
(Оригиналы картинок: github.com/amarao/dia_schemes)
- 1, 2, 3 - устройства в локальной сети, работают по WiFi
- 4 - WiFi-роутер, принужденный к работе в роле access point (bridge), то есть коммутатора между WiFi и LAN
- 5 - eth3 сетевой интерфейс, который раздаёт интернет в локальной сети
- 6 - мой домашний компьютер (основной) - desunote.ru/, который раздачей интернета и занимается, то есть работает маршрутизатором
- 7 - eth2, интерфейс подключения к сети Tiera
Я пропущу всю IPv4 часть (ничего интересного - обычный nat) и сконцентрируюсь на IPv6.
Полученные мною настройки от Tiera для IPv6:
- Адрес 2a00:11d8:1201:0:962b:18:e716:fb97/128 мне выдан для компьютера/шлюза
- Сеть 2a00:11d8:1201:32b0::/64 мне выдана для домашних устройств
У провайдера сеть 2a00:11d8:1201:32b0::/64 маршрутизируется через 2a00:11d8:1201:0:962b:18:e716:fb97 (то есть через мой компьютер). Заметим, это всё, что я получил. Никаких шлюзов и т.д. - тут начинается магия IPv6, и самое интересное. "Оно работает само".
Начнём с простого: настройка 2a00:11d8:1201:0:962b:18:e716:fb97 на eth2 для компьютера. Для удобства чтения все конфиги и имена файлов я оставлю на последнюю секцию.
Мы прописываем ipv6 адрес на интерфейсе eth2… И чудо, он начинает работать. Почему? Каким образом компьютер узнал, куда надо слать пакеты дальше? И почему /128 является валидной сетью для ipv6? Ведь /128 означает сеть размером в 1 ip-адрес и не более. Там не может быть шлюза!
Для того, чтобы понять, что происходит, нам надо взглянуть на конфигурацию сети (я вырежу всё лишнее, чтобы не пугать выводом):
# ip address show eth2 (обычно сокращают до ip a s eth2)
eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 (skip) inet6 2a00:11d8:1201:0:962b:18:e716:fb97/128 scope global valid_lft forever preferred_lft forever inet6 fe80::218:e7ff:fe16:fb97/64 scope link valid_lft forever preferred_lft forever
Упс. А почему у нас на интерфейсе два адреса? Мы же прописывали один? Наш адрес называется 'scope global', но есть ещё и 'scope link'…
Часть первая: scope
Тут нас встречает первая особенность IPv6 - в нём определено понятие 'scope' (область видимости) для адреса.
Есть следующие виды scope:
- global - "обычный" адрес, видимый всему Интернету
- local или link-local - адрес, видимый только в пределах сетевого сегмента. Ближайшим аналогом этого является configless IPv4 из диапазона 169.254.0.0/16, на который сваливается любая windows, которой сказали автоматически получить адрес, а DHCP-сервера вокруг нет. Эти адреса не могут быть маршрутизируемы (то есть тарфик с них не передаётся дальше своей сети). Подробнее про link-local address (wiki).
- host, он же interface - видимость в пределах хоста. Примерный аналог - loopback адреса для IPv4 (127.0.0.0/8)
- admin-local - в живую не видел, но какая-то промеждуточная стадия
- site-local - видимость в пределах офиса. Аналог серых 192.168.0.0/16, то есть адреса, которые не должны выходить за пределы локальной сети
- organization-local - адреса, которые не выходят за пределы организации.
В процессе проектирования IPv6 вопрос 'scope' много и тщательно обсуждался, потому что исходное деление IPv4, даже с последующими дополнениями, явно не соответствовало потребностям реальных конфигураций. Например, если у вас объединяются две организации, в каждой из которых используется сеть 10.0.0.0/8, то вас ждёт множество "приятных" сюрпризов. В IPv6 решили с самого начала сделать множество градаций видимости, что позволило бы более комфортно осуществлять дальнейшие манипуляции.
Из всего этого на практике я видел использование только host/interface, link/local и global. В свете /64 и пусть никто не уйдёт обиженным, специально возиться с site-local адресами будет только параноик.
Второй важной особенностью IPv6 является официальное (на всех уровнях спецификаций) признание того, что у интерфейса может быть несколько IP-адресов. Этот вопрос в IPv4 был крайне запутан и часто приводил к ужасным последствиям (например, запрос получали на один интерфейс, а отвечали на него через другой, но с адресом первого интерфейса).
Так как в отличие от IPv4 у IPv6 может быть несколько адресов на интефрейсе, то компьютеру не нужно выбирать "какой адрес взять". Он может брать несколько адресов. В случае IPv4 сваливание на link-local адрес происходило в режиме "последней надежды", то есть по большому таймауту.
А в IPv6 мы можем легко и просто с самого первого момента, как интерфейс поднялся, сделать ему link local (и уже после этого думать о том, какие там global адреса есть).
Более того, в IPv6 есть специальная технология автоматической генерации link-local адреса, которая гарантирует отсутствие дублей. Она использует MAC-адрес компьютера для генерации второй (младшей) половинки адреса. Поскольку MAC-адреса уникальны хотя бы в пределах сегмента (иначе L2 сломан и всё прочее автоматически не работает), то использование MAC-адреса даёт нам 100% уверенность в том, что наш IPv6 адрес уникален.
В нашем случае это inet6 fe80::218:e7ff:fe16:fb97/64 scope link. Обратите внимание на префикс - fe80 - это link-local адреса.
Как он делается?
Принцип довольно простой:
MAC-адрес eth2 - это 00:18:e7:16:fb:97, а локальный адрес ipv6 - F80:000218:e7ff:fe16:fb97. Да-да, именно так, как выделено жирным. Зачем было в середину всобачивать ff:fe - не знаю. Сам алгоритм называется modified EUI-64. Сам этот алгоритм очень мотивирован и полон деталей. С позиции системного администратора - пофигу. Адрес есть и есть. Интересным может быть, наверное, обратный алгоритм - из link-local узнать MAC и не более.
Итак, у нас на интерфейсе два адреса. Мы даже знаем, как появились они оба (один автоматически при подъёме интерфейса, второй прописали мы). Мы даже знаем, как система поняла, что адрес глобальный - он из "global" диапазона.
Но каким образом система узнала про то, кто его шлюз по умолчанию? И как вообще может жить /128?
Часть вторая, промежуточная: мультикасту мультикаст мультикастно мультикастит
Посмотрим на таблицу маршрутизации:
ip -6 route show (обычно сокращают до ip -6 r s, или даже ip -6 r):
2a00:11d8:1201:0:962b:18:e716:fb97 dev eth2 proto kernel metric 256 fe80::/64 dev eth2 proto kernel metric 256 default via fe80::768e:f8ff:fe93:21f0 dev eth2 proto ra metric 1024 expires 1779sec
Что мы тут видим? Первое - говорит нам, что наш IPv6 адрес - это адрес нашего интерфейса eth2. Второе говорит, что у нас есть link-local сегмент в eth2. У обоих источник - это kernel.
А вот третье - это интрига. Это шлюз по умолчанию, который говорит, что весь трафик надо отправлять на fe80::768e:f8ff:fe93:21f0 на интерфейсе eth2, и источником информации о нём является некое "ra", а ещё сказано, что оно протухает через 1779 секунд.
Что? Где? Куда? Кто? За что? Почему? Зачем? Кто виноват?
Но перед ответом на эти вопросы нам придётся познакомиться с ещё одной важной вещью - multicast. В IPv4 muticast был этакой технологией "не от мира сего". Есть, но редко используется в строго ограниченных случаях. В IPv6 эта технология - центральная часть всего и вся. IPv6 не сможет работать без мультикаста. И без понимания этого многие вещи в IPv6 будут казаться странными или ломаться в неожиданных местах.
Кратко о типах трафика, возможно кто-то пропустил эту информацию, когда изучал IPv4:
- unicast - пакет адресуется конкретному получателю. Обычный трафик идёт юникастом.
- broadcast - пакет адресуется всем, кто его слышит. Например, в IPv4 так рассылается запрос о mac-адресе для данного IP-адреса.
- multicast - пакет адресуется некоторому множеству узлов, которые слушают специальный multicast-адрес. И если получают сообщение, то реагируют на него.
- anycast - пакет адресуется на адрес, общий для кучи узлов. Кто к запрашивающему ближе (и готов ответить) - тот и отвечает
Так вот, в IPv6 НЕТ БРОДКАСТОВ. Вообще. Вместо них есть мультикаст. И некоторые из мультикаст-адресов являются ключевыми для работы IPv6.
Вот примеры таких адресов (они все link-local, то есть имеют смысл только в контексте конкретного интерфейса):
- FF02::1 - все узлы сети. Считайте, старинный бродкаст канального уровня.
- FF02::2 - все маршрутизаторы сети
Полный список адресов, вместе с нюансами link-local, site-local, etc, можно посмотреть тут: www.iana.org/assignments/ipv6-multicast-addresses/ipv6-multicast-addresses.xhtml
В практическом смысле это означает, что мы можем отправить бродкаст пинг всем узлам, или всем маршрутизаторам. Правда, нам для этого придётся указать имя интерфейса, в отношении которого мы интересуемся cоседями.
ping6 -I eth2 FF02::2
64 bytes from fe80::218:e7ff:fe16:fb97: icmp_seq=1 ttl=64 time=0.039 ms 64 bytes from fe80::768e:f8ff:fe93:21f0: icmp_seq=1 ttl=64 time=0.239 ms (DUP!) 64 bytes from fe80::211:2fff:fe23:5763: icmp_seq=1 ttl=64 time=1.38 ms (DUP!) 64 bytes from fe80::5a6d:8fff:fef5:6235: icmp_seq=1 ttl=64 time=5.68 ms (DUP!) 64 bytes from fe80::cad7:19ff:fed5:25b8: icmp_seq=1 ttl=64 time=7.20 ms (DUP!) 64 bytes from fe80::22aa:4bff:fe1e:9e88: icmp_seq=1 ttl=64 time=8.19 ms (DUP!) 64 bytes from fe80::5a6d:8fff:fe4a:c643: icmp_seq=1 ttl=64 time=8.69 ms (DUP!) 64 bytes from fe80::205:9aff:fe3c:7800: icmp_seq=1 ttl=64 time=11.1 ms (DUP!) 64 bytes from fe80::20c:42ff:fef9:807a: icmp_seq=1 ttl=64 time=16.0 ms (DUP!)
Сколько маршрутизаторов вокруг меня… Первым откликнулся мой компьютер. Это потому, что он тоже роутер. Но вопрос маршрутизации мы рассмотрим чуть позже. Пока что важно, что мы видим все роутеры и только роутеры (а, например, ping6 -I eth2 FF002::1 показывает порядка 60 соседей).
Мультикаст-групп (группой называют все узлы, которые слушают данный мультикаст-адрес) много. Среди них - специальная группа FF02::6A с названием "All-Snoopers". Именно этой группе и рассылаются routing advertisements. Когда мы хотим их получать - мы вступаем в соответствующую группу. Точнее не мы, а наш компьютер.
Часть третья: routing advertisements
В IPv6 придумали такую замечательную вещь - когда маршрутизатор рассылает всем желающим информацию о том, что он маршрутизатор. Рассылает периодически.
В отношении этого вопроса есть целый (всего один, что удивительно) RFC: tools.ietf.org/html/rfc4286, но нас интересует из всего этого простая вещь: маршрутизатор рассылает информацию о том, что он маршрутизатор. И, может быть, чуть-чуть ещё информации о том, что в сети происходит.
Вот откуда наш компьютер узнал маршрут. Некий маршрутизатор сказал ему "я маршрутизатор". И мы ему поверили. Почему мы выбрали именно его среди всех окружающих маршруштизаторов (см ответ на пинг на FF02::2 выше) мы обсудим чуть дальше. Пока что скажем, что этот "настоящий" маршрутизатор правильно себя анонсировал.
Таким образом, происходит следующая вещь:
У нас адрес 2a00:11d8:1201:0:962b:18:e716:fb97/128, и ещё есть link-local. Мы слышим мультикаст от роутера, верим ему, и добавляем в таблицу маршрутизации нужный нам адрес как default. С этого момента мы точно знаем, что адрес в сети. Таким образом, отправка трафика в интернет больше не проблема. Мы генерируем пакет с src=2a00:11d8:1201:0:962b:18:e716:fb97 и отправляем его на шлюз по умолчанию, который в нашем случае - fe80::768e:f8ff:fe93:21f0. Другими словами, мы отправляем трафик не своему "шлюзу" в сети, а совсем другому узлу совсем по другому маршруту. Вполне нормальная вещь как для IPv6, так и для IPv4, правда, для IPv4 это некая супер-крутая конфигурация, а для IPv6 - часть бытовой повседневности.
Но как трафик приходит обратно? Очень просто. Когда маршрутизатор провайдера получает пакет, адресованный 2a00:11d8:1201:0:962b:18:e716:fb97, то у него на одном из интерфейсов написано, что он там 2a00:11d8:1201::/64 via (я не знаю, как там называется интерфейс, но пусть) GE1/44/12. Маршрутизатор спрашивает всех соседей (neighbor discovery) об их адресах, и внезапно видит, что адрес такой-то в сети. Что может быть проще - мак есть, адрес есть, отправляем в интерфейс. Ура, наш компьютер видит трафик. Двусторонняя связь установлена.
Въедливый читатель может спросить несколько вопросов: что значит "написано на интерфейсе"? И что значит "neighbor discovery"?
Вопросы справедливые. Для начала попробуем выяснить, какие узлы у нас есть в сети из подсети 2a00:11d8:1201::/64
Для того, чтобы посмотреть router advertisement на интерфейсе нам поднадобится программа radvdump из пакета radvd. Она позволяет печатать анонсы, проходящие на интерфейсах, в человеческом виде. Заметим, сам пакет radvd нам ещё пригодится (так как его демон - radvd позволяет настроить анонсирование со своих интерфейсах).
Итак, посмотрим, что аносирует нам Tiera:
radvdump eth2 (и подождать прилично, ибо анонсы не очень часто рассылаются)
# # radvd configuration generated by radvdump 1.9.1 # based on Router Advertisement from fe80::768e:f8ff:fe93:21f0 # received by interface eth2 # interface eth2 { AdvSendAdvert on; # Note: {Min,Max}RtrAdvInterval cannot be obtained with radvdump AdvManagedFlag on; AdvOtherConfigFlag on; AdvReachableTime 0; AdvRetransTimer 0; AdvCurHopLimit 64; AdvDefaultLifetime 1800; AdvHomeAgentFlag off; AdvDefaultPreference medium; AdvSourceLLAddress on; AdvLinkMTU 9216; prefix 2a00:11d8:1201::/64 { AdvValidLifetime 2592000; AdvPreferredLifetime 604800; AdvOnLink on; AdvAutonomous on; AdvRouterAddr off; }; # End of prefix definition }; # End of interface definition
Из всего этого важным является:
- Адрес, с которого получен анонс (в нашем случае fe80::768e:f8ff:fe93:21f0) - это и есть адрес шлюза.
- Указание на сетевой сегмент, в котором можно автоконфигурировать себе адреса
- Флаг AdvAutonomous on, указывающий, что этот анонс имеет смысл. Если бы флаг был off, то его бы можно было смело игнорировать.
Таким образом всё просто - адрес мы указали, маршрутизатор нам "себя" прислал, ядро маршрут обновило. Вуаля, у нас IPv6 на компьютере заработал.
Белый IPv6-адрес для каждого в домашней сети
Получить IPv6 адрес для компьютера - этого маловато будет. Хочется так, чтобы каждое мобильное устройство сидело не за позорным NAT'ом, а голой задницей с белым адресом в Интернете. Желательно ещё при этом так, чтобы злые NSA/google не могли по хвостику моего адреса (в котором закодирован MAC) отслеживать мои перемещения между разными IPv6-сетями (хотя в условиях установленного play services эта параноидальность выглядит наивной и беззащитной).
Но, в любом случае, у нас задача раздать интернет дальше.
Tiera, выдавая мне ipv6, настроила у себя маршрут: 2a00:11d8:1201:32b0::/64 via 2a00:11d8:1201:0:962b:18:e716:fb97.
Так как fb97 уже является адресом моего компьютера, настройка машрутизации плёвое дело:
sysctl net.ipv6.conf.all.forwarding=1
… и у нас через пол-часика полностью отваливается IPv6 на компьютере? Почему? Кто виноват?
Оказывается, линукс не слушает routing advertisement, если сам является маршрутизатором. Что, в общем случае, правильно, потому что если два маршрутизатора будут объявлять себя маршрутизаторами и слушать маршруты друг друга, то мы быстро получим простейшую петлю из двух зацикленных друг на друга железных болванов.
Однако, в нашем случае мы всё-таки хотим слушать RA. Для этого нам надо включить RA силком.
Это делается так:
sysctl net.ipv6.conf.eth2.accept_ra=2
Заметим, важно, что мы слушаем RA не всюду, а только на одном интерфейсе, с которого ожидаем анонсы.
Теперь маршрутизация работает, маршрут получается автоматически, и можно на каждом мобильном устройстве вручную прописать IPv6 адрес и вручную указать IPv6 шлюз, и вручную прописать IPv6 DNS, и вручную… э… слишком много вручную.
Если мне выдали настройки автоматом, то я так же хочу раздавать их дальше автоматом. Благо, dhcpd отлично справляется с аналогичной задачей для IPv4.
Прелесть IPv6 в том, что мы можем решить эту задачу (раздачу сетевых настроек) без каких-либо специальных сервисов и в так называемом stateless режиме. Главная особенность stateless режима состоит в том, что никто не должен напрягаться и что-то сохранять, помнить и т.д. Проблемы с DHCP в IPv4 чаще всего вызывались тем, что один и тот же адрес выдавали двум разным устройствам. А происходило это из-за того, что злой админ стирал/забывал базу данных уже выданных аренд. А ещё, если железок много и они забывают "отдать аренду", то адреса заканчиваются. Другими словами, stateful - это дополнительные требования и проблемы.
Для решения тривиальной задачи "раздать адреса" в IPv6 придумали stateless режим, который основывается на routing advertisement. Клиентскую часть мы уже видели, теперь осталось реализовать серверную, дабы накормить IPv6 планшетик.
Настройка анонсов маршрутизации (radvd)
Для настройки анонсов используется специальная программа-демон - radvd. С утилитой из её комплекта (radvdump) мы познакомились чуть выше. Прелесть утилиты в том, что она выводит не просто полученные данные, а готовый конфиг radvd для рассылки аналогичных анонсов.
Итак, настраиваем radvd:
interface eth3 { AdvSendAdvert on; AdvHomeAgentFlag off; MinRtrAdvInterval 30; MaxRtrAdvInterval 100; prefix 2a00:11d8:1201:32b0::/64 { AdvOnLink on; AdvAutonomous on; AdvRouterAddr on; }; };
Главное тут - префикс и указание на AdvAutonomous.
Запускаем демона, берём ближайший ноутбук (обычная бытовая убунта с обычным бытовым network-manager'ом), рррраз, и получаем…
ip a show wlan0 3: wlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000 link/ether 10:0b:a9:bd:26:a8 brd ff:ff:ff:ff:ff:ff inet 10.13.77.167/24 brd 10.13.77.255 scope global wlan0 valid_lft forever preferred_lft forever inet6 2a00:11d8:1201:32b0:69b9:8925:13d9:a879/64 scope global temporary dynamic valid_lft 86339sec preferred_lft 14339sec inet6 2a00:11d8:1201:32b0:120b:a9ff:febd:26a8/64 scope global dynamic valid_lft 86339sec preferred_lft 14339sec inet6 fe80::120b:a9ff:febd:26a8/64 scope link valid_lft forever preferred_lft forever
Откуда у нас столько ipv6 мы поговорим в следующем разделе, а пока что отметим, что адреса сконфигурировались автоматически. И маршруты у нас такие:
ip -6 r 2a00:11d8:1201:32b0::/64 dev wlan0 proto kernel metric 256 expires 86215sec fe80::/64 dev wlan0 proto kernel metric 256 default via fe80::5ed9:98ff:fef5:68bf dev wlan0 proto ra metric 1024 expires 115sec
Надеюсь, читатель уже вполне понимает, что происходит. Однако… Чего-то не хватает. У нас нет dns-resolver'а. Точнее есть, но выданный dhcpd по IPv4. А у нас пятиминутка любви к IPv6, так то ресолвер нам тоже нужен IPv6.
Тяжело расчехляя aptitude ставим dhcpv6 и прописываем опции nameserver Как бы не так!
К счастью, IPv6 очень долго продумывался и совершенствовался. Так что мы можем решить проблему без участия DHCP-сервера. Для этого нам надо добавить к анонсу маршрута ещё указание на адреса DNS-серверов.
RDNSS в RA
Описывается вся эта примудрость в RFC 6106. По сути - у нас есть возможность указать адрес рекурсивного DNS-сервера (то есть "обычного ресолвера") в анонсе, распространяемом маршрутизатором.
По большому счёту это всё, что мы хотим от DHCP, так что DHCP там тут не нужен. Компьютеры сами делают себе адреса непротиворечивым образом (то есть для исключения коллизий), знают адреса DNS-серверов. Интернетом можно пользоваться.
Для этого мы дописываем в конфиг radvd соответствующую опцию:
RDNSS 2001:4860:4860::8888 2001:4860:4860::8844 { };
(полный конфиг - см. в конце статьи).
Пробуем подключиться снова - и, ура, всё работает.
ping6 google.com PING google.com(lb-in-x66.1e100.net) 56 data bytes 64 bytes from lb-in-x66.1e100.net: icmp_seq=1 ttl=54 time=25.3 ms ^C --- google.com ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 25.312/25.312/25.312/0.000 ms
google.com выбран был не случайно. Сервисы гугля (в немалой степени youtube) - это едва ли не основной источник IPv6 трафика в настоящий момент. Второй источник - торренты, где можно увидеть аж 5-10% пиров в IPv6 варианте.
На этом рассказ можно было закончить, если бы не ещё одна важная деталь - что за третий IPv6-адрес на интерфейсе ноутбука? И что это за temporary dynamic?
Privacy extension
Как я уже упомянул выше, автоматическое конфигурирование IPv6-адреса на основе MAC-адреса сетевого адаптера хорошо всем, кроме того, что создаёт практически идеальное средство для отслеживания пользователей в сети. Вы можете брать любые браузеры и операционные системы, использовать любых провайдеров (использующих IPv6, так что это всё пишется с прицелом на будущее) - но у вас будет один и тот же MAC-адрес, и любой гугуль, NSA или просто спамер смогут вас отслеживать по младшим битам вашего IPv6 адреса. Старшие будут меняться в зависимости от провайдера, а младшие сохраняться как есть.
Для решения этой проблемы были придуманы специальные расширения для IPv6, называющиеся privacy extensions (RFC 4941). Как любое RFC, его чтение - это обычно признак отчаяния, так что по сути этот стандарт описывает как с помощью шаманства и md5 генерировать случайные автоконфигурируемые адреса.
Как это работает?
Хост, в нашем случае обычная убунта на обычном ноутбуке, генерирует штатным образом IPv6 адрес из анонса маршрутизатора. После этого она придумывает себе другой адрес, проверяет, что этот адрес не является зарезервированным (например, нам так повезло, и md5 хеш сгенерировал нам все нули - вместо того, чтобы трубить об этом на всех углах, этот изумительный md5 хеш будет выкинут и вместо него будет взят следующий), и, главное, проверяет, что такого адреса в сети нет. Для этого используется штатный механизм DAD (см ниже). Если всё ок, то на интерфейс назначается новосгенерированный случайный адрес, и именно он используется для общения с узлами Интернета. Хотя наш ноутбук с тем же успехом ответит на пинг и по основному адресу.
Этот адрес периодически меняется и он же меняется при подключении к другим IPv6-сетям (и много вы таких знаете в городе?.. вздох ). В любом случае, даже если мы намертво обсыпаны куками и отпечатками всех браузеров, всё-таки маленький кусочек сохраняемой приватности - это лучше, чем не сохраняемый кусочек.
Duplicate Address Detection
Последняя практически важная фича IPv6 - это DAD. Во времена IPv4 на вопрос "а что делать, если адрес, назначаемый на хост, уже кем-то используется в сети" отвечали "а вы не используйте адреса повторно и всё будет хорошо".
На самом деле все вендоры реализовывали свою версию защиты от повторяющегося адреса, но работало это плохо. В частности, линукс пишет о конфликте IPv4 адресов в dmesg, Windows - в syslog… Event… Короче, забыл. В собственную версию журнала и показывает жёлтенко-тревожненький попапик в трее, мол, бида-бида. Однако, это не мешает использовать дублирующийся адрес, если он назначен статикой, и приводит к головоломным проблемам в районе ARP и времени его протухания (выглядит это так: с одного компьютера по сети по заданному адресу отвечает сервер, а с другого, по тому же адресу, допустим, залётный ноутбук, и они ролями периодически меняются).
Многие DHCP-сервера (циски, например), даже имели специальную опцию "проверять пингом" перед выдачей адреса.
Но всё это были доморощенные костыли для подпирания "а вы не нажимайте, больно и не будет".
В IPv6 проблему решили куда более изящно. При назначении IPv6 адреса запускается прописаный в RFC алгоритм (то есть выполняемый всеми, а не только premium grade enterprise ready cost saving proprietary solution за -цать тысяч). Этот алгоритм называется Optimistic DAD (RFC 4429), и его суть сводится к простому: кто первый встал, того и тапки. Включая прилагающийся IPv6 адрес.
Сам DAD работает отлично, но у него есть мааааленькая подлость, с которой я как-то столкнулся. Если (дополнительный) адрес на интерфейс вешать простым ip -6 address add, то ip отработает раньше, чем закончится DAD. Так что если этот адрес используется дальше в скрипте или конфигах автостартующих демонов, то демоны могут отвалиться по причине "нет такого адреса" - линукс не экспортирует в список доступных для приложений те адреса, про которые нет уверенности, что их можно использовать.
Конфиги
Эту часть большинство пропустит не читая, ну, такова судьба конфигов - быть писанными, но не читанными.
/etc/network/interfaces:
auto lo eth2 eth3 iface lo inet loopback allow-hotplug eth2 eth3 iface eth2 inet static address 95.161.2.76 netmask 255.255.255.0 gateway 95.161.2.1 dns-nameservers 127.0.0.1 #У меня локальный ресолвер на базе bind'а iface eth2 inet6 static address 2a00:11d8:1201:0:962b:18:e716:fb97/128 dns-nameservers ::1 iface eth3 inet static address 10.13.77.1 netmask 255.255.255.0 iface eth3 inet6 static address 2a00:11d8:1201:32b0::1/64
/etc/sysctl.d/ra2.conf
net.ipv6.conf.eth2.accept_ra=2
/etc/sysctl.d/ip_forwarding.conf
net.ipv4.conf.all.forwarding = 1 net.ipv6.conf.all.forwarding = 1
/etc/radvd.conf
interface eth3 { AdvSendAdvert on; AdvHomeAgentFlag off; MinRtrAdvInterval 30; MaxRtrAdvInterval 100; prefix 2a00:11d8:1201:32b0::/64 { AdvOnLink on; AdvAutonomous on; AdvRouterAddr on; }; RDNSS 2001:4860:4860::8888 2001:4860:4860::8844 { }; };
/etc/dhcp/dhcpd.conf
ddns-update-style none; option domain-name "example.org"; option domain-name-servers ns1.example.org, ns2.example.org; default-lease-time 600; max-lease-time 7200; log-facility local7; subnet 10.13.77.0 netmask 255.255.255.0 { range 10.13.77.160 10.13.77.199; option routers 10.13.77.1; option domain-name-servers 10.13.77.1; }
Используется ли IPv6?
У меня обычный домашний компьютер. Чуть-чуть raid, LVM XFS, BTRFS, LUCKS, свой почтовый и веб-сервера, dns-сервер и т.д. Я подключен к обычному домашнему провайдеру с IPv6.
Вот статистика использования интернета за четыре дня. Собиралась она простым способом:
iptables -t filter -A INPUT ip6tables -t filter -A INPUT (смотреть счётчики - iptables -L -v, и ip6tables -L -v)
И вот какая она получилась: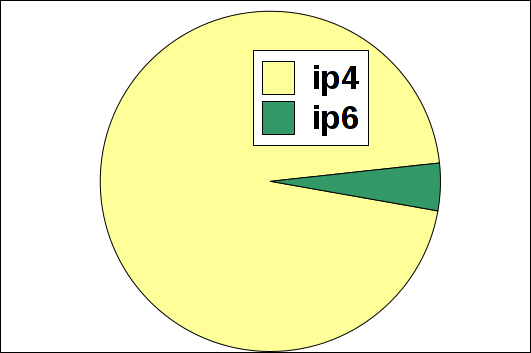
- 4.5% (2.7 Гб) IPv6
- 95.5% (59 Гб) - представители прочих, устаревающих, версий IP
Таким образом, IPv6 занимает второе место по распространённости в Интернете (если Майкрософту с виндофонами так желтить можно, почему мне нельзя?).
Если серьёзно, то столь значительные достижения IPv6 (только представьте себе - почти гигабайт трафика в день) большей частью объясняются ютубом и прочими сервисами гугла. Ещё небольшую долю IPv6 принёс пиринг, причём там львиная доля людей - это всякие туннели и teredo (то есть ненастоящие IPv6, использующиеся от безысходности).
С другой стороны, этот показатель почти в три раза больше моего прошлого замера (полтора года назад), когда доля IPv6 едва-едва переваливала за полтора процента.
О поддержке в оборудовании
Десктопные линуксы, понятно, IPv6 поддерживают и используют.
Андроиды (4+) тоже умеют и используют. Пока что найдена только одна забавная бага, это неответ на пинги по IPv6 (но ответ по IPv4) в deep sleep режимах.
Насколько я знаю, IOS'ы IPv6 поддерживают и используют.